Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Shen, P.; Sun, N.; Hu, K.; Ye, X.; Wang, P.; Xia, Q.; Wei, C. Non-Contact Video Fire Detection. Encyclopedia. Available online: https://encyclopedia.pub/entry/51804 (accessed on 26 July 2026).
Shen P, Sun N, Hu K, Ye X, Wang P, Xia Q, et al. Non-Contact Video Fire Detection. Encyclopedia. Available at: https://encyclopedia.pub/entry/51804. Accessed July 26, 2026.
Shen, Pengfei, Ning Sun, Kai Hu, Xiaoling Ye, Pingping Wang, Qingfeng Xia, Chen Wei. "Non-Contact Video Fire Detection" Encyclopedia, https://encyclopedia.pub/entry/51804 (accessed July 26, 2026).
Shen, P., Sun, N., Hu, K., Ye, X., Wang, P., Xia, Q., & Wei, C. (2023, November 20). Non-Contact Video Fire Detection. In Encyclopedia. https://encyclopedia.pub/entry/51804
Shen, Pengfei, et al. "Non-Contact Video Fire Detection." Encyclopedia. Web. 20 November, 2023.
Copy Citation
Fire accidents pose a major threat to the safety of human life and property. Accurate fire detection plays a vital role in responding to fire outbreaks in a timely manner and ensuring the smooth conduct of subsequent firefighting efforts.
CNN and transformer
lightweight
fire detection
1. Introduction
Hazards caused by fire are a serious threat to human life and property. According to data from the Global Disaster Database, from 2013 to 2022 the average number of deaths and missing persons due to forest and grassland fires alone reached 904,000 people. Data released by Global Forest Watch (GFW) and the World Resources Institute (WRI) indicate that on a global scale the forest area destroyed by wildfires is now double what it was at the beginning of this century. According to satellite data, the annual forest area destroyed by wildfires has increased by approximately 3 million hectares compared to the year 2001. In addition to forest fires, the increasing impact of other types of fires, such as electrical fires, is becoming more severe as society continues to progress and develop. The frequency of these incidents is on the rise. Real-time monitoring of fire-prone areas, timely fire alarms, and rapid localization of fire incidents are of paramount importance for safeguarding human life, property, and industrial safety.
Traditional fire detection methods primarily involve contact-based fire detectors, such as carbon monoxide sensors, temperature sensors, smoke detectors, etc. Rachman, F. et al. [1] proposed a fuzzy logic-based early fire detection system using KY-026 (fire detection), MQ-9 (smoke detection), and DS18b20 (temperature detection) sensors. Huang Ye et al. [2] proposed a wireless fire detection node design method based on multi-source sensor data fusion and provided a complete hardware selection and software data fusion processing method. Solorzano Soria, A.M. et al. [3] proposed a gas sensor-based array to speed up fire alarm response. Li Yafei et al. [4] developed a mid-infrared carbon monoxide (CO) and carbon dioxide (CO22) dual gas sensor system for early fire detection. Liu Xiaojiang et al. [5] proposed a sensor optimization strategy and an intelligent fire detection method based on the combination of particle swarm optimization algorithm. Although contact fire detectors are commonly used in various public scenes, their detection range is limited to small indoor spaces, and it is difficult to apply them to large indoor spaces and outdoor open spaces where open flames are strictly prohibited. Moreover, traditional contact fire detectors are prone to age-related failures and require a lot of manpower and resources for maintenance and management.
Compared to contact fire detection using sensors, non-contact video fire detection technology has the advantages of no additional hardware, intuitive and comprehensive fire information, and large detection range. While real-time monitoring of fire appears to be a binary classification problem for images, in practice it requires further detection of fire images based on the classification. The use of fire image detection is justified due to the extensive coverage of video surveillance systems. Early fire incidents are often challenging to detect, and sometimes fires can escalate to an uncontrollable stage within a short timeframe. Therefore, relying solely on image classification is insufficient for accurately pinpointing the actual location of a fire. This limitation could undoubtedly hinder the timely response and effective management of fire incidents. Traditional fire target detection algorithms include region selection, feature extraction, and classifier design. Qiu, T. et al. [6] proposed an adaptive canny edge detection algorithm for fire image processing. Ji-neng, O. et al. [7] proposed an early flame detection method based on edge gradient features. Khalil, A. et al. [8] proposed a fire detection method based on multi-color space and background modeling. However, in traditional fire target detection algorithms, manually designed features lack strong generalization and exhibit limited robustness. The emergence of CNNs has gradually replaced traditional handcrafted feature methods, offering superior generalization and robustness compared to traditional fire detection approaches. Majid, S. et al. [9] proposed an attention-based CNN model for the detection and localization of fires. Chen, G. et al. [10] proposed a lightweight model for forest fire smoke detection based on YOLOv7. Dogan, S. et al. [11] proposed an automated accurate fire detection system using ensemble pretrained residual network. In recent years, a new generation of transformer-based deep learning network architectures has gradually started to shine. Li, A. et al. [12] proposed a combination of BiFPN and Swin transformer for the detection of smoke from forest fires. Huang, J. et al. [13] proposed a small target smoke detection method based on a deformable transformer. Although these transformer-based network architectures have achieved good results in fire detection, they tend to be more complex (i.e., the number of parameters reaches about 20 M or 30 M) and not very lightweight. In order to ensure a lightweight transformer architecture-based model, scholars have started to research solutions such as EfficientViT [14], EfficientFormerV2 [15], MobileViT [16], etc., although these network models have not become widely used in fire detection to date.
2. MobileViT
The emergence of ViT [18] has led people to realize the tremendous potential of transformers in the field of computer vision. The transformer architecture has become a new neural network paradigm in the field of computer vision, following the advent of CNNs, with and more researchers starting to use networks with the transformer architecture. However, although transformers are powerful, they have a number of problems; the pure transformer model structures are usually bulky and not very lightweight; furthermore, inductive bias is a form of prior knowledge, and unlike CNNs, transformers do not have the same kind of induction bias, meaning that transformers require a substantial amount of data to learn such prior information.
The inductive bias of CNNs can generally be categorized into two types. The first is locality; CNNs convolve input feature maps using a sliding window approach, which means that objects that are closer together exhibit stronger correlations. Locality helps to control the complexity of the model. The second type is translation equivariance; regardless of whether object features in an image are first convolved and then translated, or first translated and then convolved, the resulting features are the same. Translation equivariance enhances the model’s generalization capabilities.
However, CNNs are not without imperfections. The spatial features they extract are inherently local in nature, which to a certain extent constrains the model’s performance, whereas transformers can obtain global information through their self-attention mechanism.
MobileViT is a lightweight network that combines the strengths of both CNN and ViT. MobileViT is available in three versions depending on model size: MobileViT-S, MobileViT-XS, and MobileViT-XXS. MobileViT primarily consists of standard convolutions, inverted residual blocks from MobileNetV2 (MV2), MobileViT blocks, global pooling, and fully connected layers. The network architecture is illustrated in Figure 1.

图 1.MobileViT网络的结构;“(3 × 3)”和“(1 × 1)”表示卷积核的大小,“MV2”表示MobileNetV2中的倒置残差块,“↓2”表示下采样操作,“L”表示Transformer块中的层数。
3. 预测头
目标检测是准确定位图像中感兴趣对象的能力;需要预测头(预测部分或输出部分)来执行分类和回归任务。检测头有两种类型,即耦合检测头和解耦检测头。耦合检测头意味着分类和回归任务共享其输入参数的很大一部分。在[19]中,作者指出,在输入参数的学习过程中,分类和回归任务的感兴趣特征是不同的。这两个子任务是耦合的,导致空间错位问题,从而显著影响网络收敛速度。解耦检测头解决了这个问题。解耦检测头分别处理分类和回归任务的输入参数,提高了检测网络的检测精度和收敛速度。YOLOX [20] 网络使用解耦头进行目标检测,与 YOLOv1 [1] 相比,mAP 提高了 3.21%。因此,包括PPYOLO-E [22]、YOLOv6 [23]和YOLOv8 [24]在内的大多数目标检测网络都已开始采用这种范式。
YOLOv8 的预测头使用解耦的分类和回归分支;详细结构如图2所示。分类分支使用二元交叉熵 (BCE) 损失。回归分支采用完全并集交叉(CIoU)损失[25],并利用一种称为分布焦点损失(DFL)的新损失函数[26]。DFL 旨在以类似于交叉熵的方式优化最接近标签 y 的左侧 (y i) 和右侧 (yi+1) 位置的概率。这使网络能够快速关注目标位置附近的分布。公式表示为公式(1):
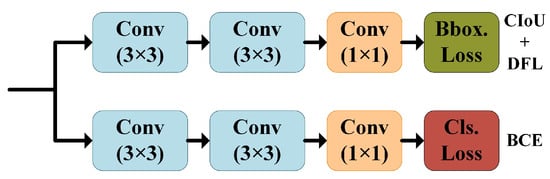
图2.YOLOv8 预测头结构;CIOU是并集损失的完全交集,DFL是分布焦点损失,BCE是二元交叉熵损失。
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
471
Revisions:
2 times
(View History)
Update Date:
20 Nov 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No