Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Charles Diel Jaranilla | -- | 2203 | 2023-10-26 13:19:56 | | | |
| 2 | Camila Xu | + 37 word(s) | 2240 | 2023-10-27 03:20:47 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Jaranilla, C.; Choi, J. Requirements of Compression in Key-Value Stores. Encyclopedia. Available online: https://encyclopedia.pub/entry/50832 (accessed on 14 June 2026).
Jaranilla C, Choi J. Requirements of Compression in Key-Value Stores. Encyclopedia. Available at: https://encyclopedia.pub/entry/50832. Accessed June 14, 2026.
Jaranilla, Charles, Jongmoo Choi. "Requirements of Compression in Key-Value Stores" Encyclopedia, https://encyclopedia.pub/entry/50832 (accessed June 14, 2026).
Jaranilla, C., & Choi, J. (2023, October 26). Requirements of Compression in Key-Value Stores. In Encyclopedia. https://encyclopedia.pub/entry/50832
Jaranilla, Charles and Jongmoo Choi. "Requirements of Compression in Key-Value Stores." Encyclopedia. Web. 26 October, 2023.
Copy Citation
A key–value store is a de facto standard database for unstructured big data. Key–value stores, such as Google’s LevelDB and Meta’s RocksDB, have emerged as a popular solution for managing unstructured data due to their ability to handle diverse data types with a simple key–value abstraction. Simultaneously, a multitude of data management tools have actively adopted compression techniques, such as Snappy and Zstd, to effectively reduce data volume.
key–value store
compression
log-structured merge tree
evaluation
1. Introduction
Data compression is the technology of condensing information into a more concise format, hence minimizing the storage space, the amount of storage required to store, and the number of I/Os needed to access data [1][2][3]. One prominent advantage of data compression is the efficient utilization of storage space, resulting in a proportional expansion of the storage medium’s capacity. Furthermore, it has the potential to enhance performance by reducing the volume of data that needs to be accessed and transmitted through the I/O system and interconnection network. Nevertheless, the process of compression and decompression necessitates supplementary CPU and memory resources, potentially leading to a decline in data access latency. Hence, it is imperative to thoroughly evaluate these trade-offs prior to implementing compression in data management systems.
A key–value store is a de facto standard database for unstructured big data [4][5]. Several data service providers have their own key–value stores, including Google’s LevelDB [6], Meta’s RocksDB [7], Amazon’s Dynamo [8], and LinkedIn’s Voldemort [9], among others. Due to their ability to accommodate many data formats and their support for a straightforward key–value abstraction, they are actively adopted for various services, including social graph analysis, AI/ML services, and distributed databases [10]. Key–value stores utilize a range of compression techniques [11][12][13], including Snappy [14], Zstandard (Zstd) [15], and LZ4 [16]. These approaches will be discussed further in Table 1.
Table 1. Compression techniques adopted by modern key–value stores.
| Brotli | Gzip | LZ4 1 | LZMA | LZO | Snappy | Zlib | Zstd | |
| LevelDB [6] | ✓ | ✓ | ||||||
| RocksDB [7] | ✓ | ✓ | ✓ | ✓ | ||||
| Cassandra [17] | ✓ | ✓ | ✓ | ✓ | ||||
| WiredTiger [18] | ✓ | ✓ | ✓ | |||||
| HBase [19] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
1 Implementations of LZ4 also include LZ4HC (LZ4 High-Compression version).
The fundamental data structure used by most key–value stores is the log-structured merge tree (hereafter, LSM-tree) [20], which has distinct characteristics suitable for compression. Initially, the system records key–value pairs in a log-structured manner. More precisely, it manipulates two fundamental components, namely Memtable, which is a memory component, and SSTable, which is a storage component. The concept of a Memtable refers to a specific type of write buffer that serves as a cache for key–value pairs. These pairs are then written to storage in a batch style, with a default size of 64 MB. The utilization of bigger block sizes in compression techniques can be leveraged to improve the compression ratio in the context of this expansive batch writing. Nevertheless, the increased block size has both advantages and disadvantages, with one of the drawbacks being a detrimental effect on read latency. The consideration of this trade-off necessitates careful consideration when employing compression in a key–value store.
Another notable characteristic of the LSM-tree is its utilization of the out-of-place update method, wherein updated data is written to a new location while simultaneously rendering the old data in the original location invalid. Consequently, in order to reclaim the invalidated location, it introduces an internal operation called compaction. SSTable files are structured hierarchically, encompassing numerous levels. A Memtable is flushed into storage, transforming into an SSTable file located at level 0. Compaction is triggered when the size of a given level exceeds a predetermined threshold. It consists of three steps: (1) read existing SSTable files from the level and one higher level; (2) conduct merge-sort while removing the outdated key–value pairs; and (3) write new SSTable files into the higher level and delete the compacted files. This implies that compression and decompression operations are frequent in a key–value store, occurring not just during data retrieval but also during the compaction process. Hence, compression time becomes more critical than compression ratio, especially for SSTable files at lower levels, which will be compacted and deleted in the near future.
2. Issues of Compression in Key–Value Stores
2.1. Internal Structure and Operations of Key–Value Stores
Figure 1 presents the internals of an LSM-tree-based key–value store. It stores and retrieves data using a set of key–value interfaces such as put(), get(), and delete(). It consists of two components: the Memtable in memory and the SSTable in storage. The Memtable is an in-memory data structure holding data before it is flushed to storage. Once a Memtable is full, it becomes immutable and replaced by a new Memtable. A background thread will flush the content of the immutable Memtable into an SSTable file, after which the Memtable is set to be removed. The SSTable is a collection of files that are organized in multiple levels, from 𝐿0 to 𝐿𝑁 in this figure, where the default value of N is six in RocksDB.
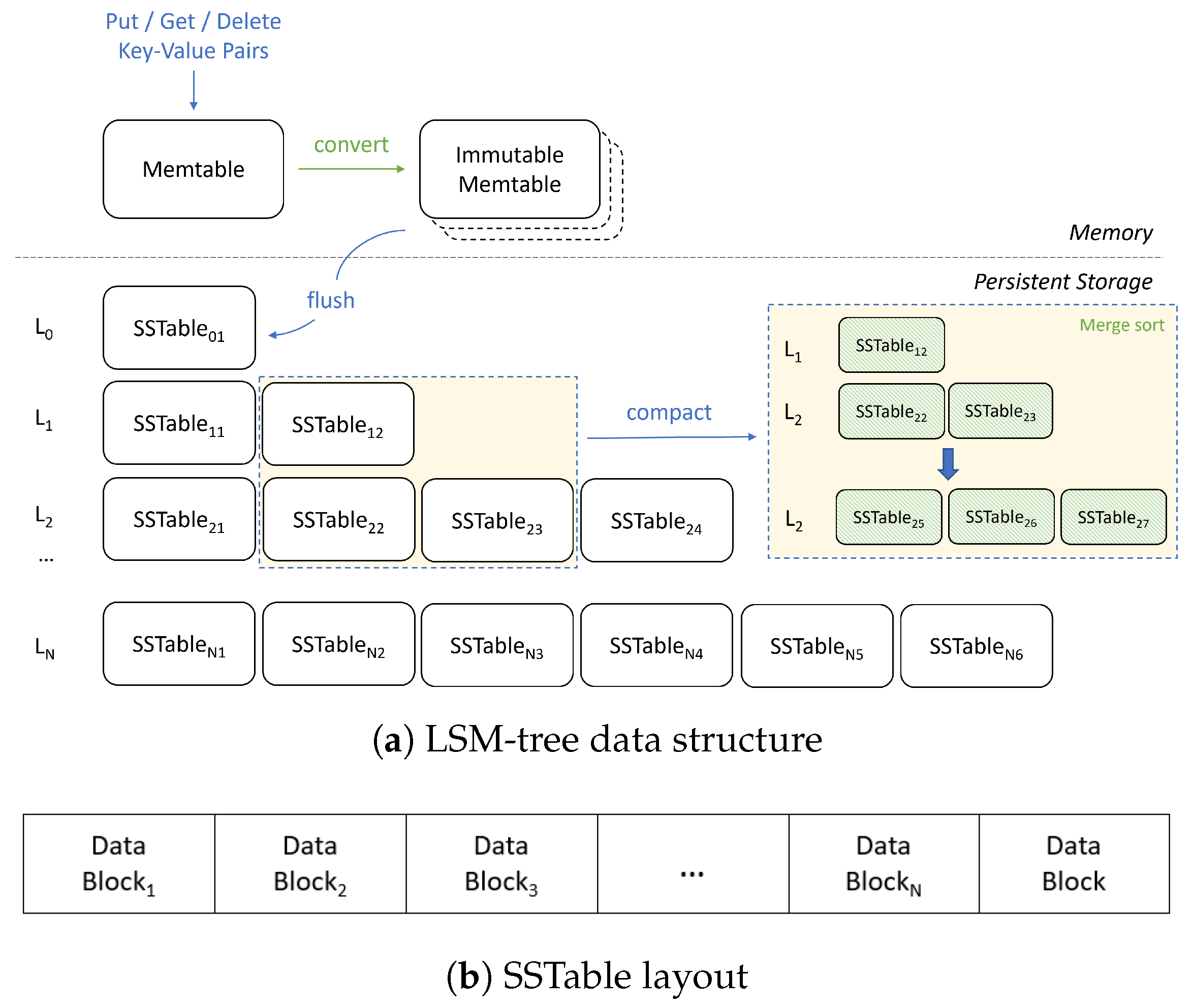
Figure 1. Internals of an LSM-tree based key–value store and SSTable layout. This image is a modified version of the one presented by Zhang et al. [21].
LSM-tree is a write-optimized data structure. The basic idea of LSM-tree is writing data in a log-structured manner and conducting out-of-place updates instead of in-place updates. Specifically, it keeps incoming key–value pairs in Memtable. When the size of Memtable is beyond a threshold (e.g., 64 MB), the Memtable becomes immutable and is eventually written to storage. This operation is called 𝑓𝑙𝑢𝑠ℎ. One characteristic of LSM-tree is to buffer incoming writes in memory using Memtable, and flush it to storage as a new SSTable file in a batch style. Note that when a key is updated with a new value, a new key–value pair is written into a new SSTable file, while the outdated pair is also maintained in an existing SSTable file.
SSTable files are then merge-sorted on a regular basis using an internal operation called 𝑐𝑜𝑚𝑝𝑎𝑐𝑡𝑖𝑜𝑛. The compaction operation is illustrated in a box shown on the right side of Figure 1a. When the number of SSTable files at level 𝐿𝑖 is beyond a threshold, compaction is triggered. It first selects a file at level 𝐿𝑖 according to a selection policy (e.g., the oldest file or the largest file). Then, it reads all files, from both level 𝐿𝑖 and level 𝐿𝑖+1, that have overlapped key ranges with the selected file. Then, it performs merge-sort while deleting outdated key–value pairs. Finally, it writes new SSTable files at level 𝐿𝑖+1. After compaction, old SSTable files are removed and their space is reclaimed.
When a lookup request arrives, it first checks the Memtables (both mutable and immutable) and serves it if the requested key–value pair exists there. Otherwise, it checks SSTable files, from the lowest level (𝐿0) to the higher levels, to identify a file whose key range contains the requested key. Note that the lower level always has the most up-to-date pair in the LSM-tree. Finally, it reads the data block from the identified file with the help of an index block stored at the end of the file that maps keys into data blocks. Note that, since the SSTable file is identified using key ranges, it does not actually contain the requested key, which causes an unnecessary read. To avoid this, key–value stores make use of the bloomfilter to test the non-existence of a key in a file.
The put interface is used for either adding a new key–value pair or updating an existing pair. Since a key–value pair is first managed in Memtable and later flushed into a SSTable file, a sudden power failure may cause data loss. To overcome this problem, most key–value stores employ a write-ahead log (WAL) on storage in order to support durability. The get interface is used for a lookup, checking the Memtables first and then SSTable files from Level 0 to the higher levels until the key is either found or determined to be absent. Finally, the delete interface is used for removing an existing pair. A specific tombstone marker is inserted into Memtable and written to the WAL during a deletion, indicating that the key should be deemed deleted.
Updating data in a log-structured manner in key–value stores can enhance write performance by converting random writes into sequential ones. However, it increases the write amplification due to compaction. Furthermore, it degrades storage utilization by storing not only up-to-date data but also old data until compaction. Compression can be a practical solution to overcome these issues.
2.2. Compression in Key–Value Stores
Data compression is a powerful tool with numerous advantages that can be used for a wide range of applications. Saving storage space is the most important benefit that can be expected from compression.
In the context of key–value stores, two characteristics driven by the LSM-tree are needed to be contemplated. First is the bulky batch writing. Incoming key–value pairs are buffered in Memtable, whose default size is 64 MB, and written into storage in batch style. It gives the encoder a chance to find a lot of repeated patterns, providing a positive impact on compression. The second characteristic is that, in key–value stores, compression and decompression occur not only during data access time but also during flush and compaction time. It implies that key–value stores carry out compression and decompression more frequently than other databases.
As a result, this high frequency leads to compression speed being considered as a top priority. This is why most key–value stores choose dictionary-based coding among the four categories shown in Figure 2, since it has the lowest compression overhead. In addition, key–value stores apply compression based on a data block instead of a SSTable file, as illustrated in Figure 1b. This block-based compression can provide better read latency since, when a lookup is requested, it requires access to only the related block. On the contrary, file-based compression may degrade read latency to access whole blocks for decompression, whereas it can yield a better compression ratio.
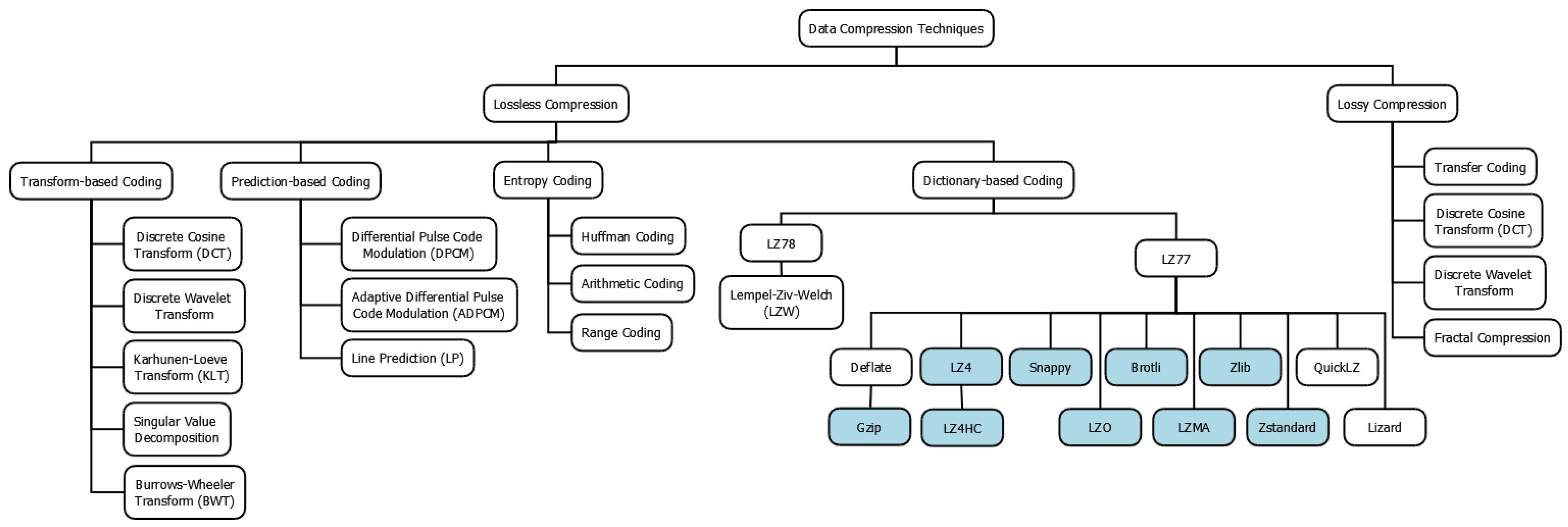
Figure 2. Taxonomy of compression techniques. They can be classified into lossy and lossless approaches, and then classified further based on their mechanisms. Note that compression techniques actively used by modern key–value stores are highlighted in blue.
In key–value stores, compression and decompression are conducted at three main points: flush, compaction, and block read. For instance, when enable compression, compaction procedures can be divided into five steps: (1) read, (2) decompress, (3) merge–sort, (4) compress, and (5) write [21]. During compression, a block is fed into an interface where a repeated pattern is replaced with a reference to the previous offset and length of the pattern. During decompression, the reference is converted into a pattern, recreating the original data. Note that, in the current implementation, decompression and merge–sort are performed separately, meaning that the merge–sort step starts after completing decompression.
2.3. Key Factors That Affect Compression in Key–Value Stores
There are a variety of factors in key–value stores that influence compression ratio and performance significantly.
First, the choice of compression technique can significantly affect the overall behavior of key–value stores. Techniques such as Snappy and LZ4 are designed to provide fast compression and decompression with low CPU usage, making them ideal for systems that require high read and write throughput. However, these techniques do not necessarily provide a superior compression ratio. On the other hand, techniques such as Zstd or LZ4HC can provide a higher compression ratio, but compression and decompression can take longer and require more CPU.
Second, the size of blocks is another influential factor that affects the compression ratio and throughput of key–value stores. For dictionary-based compression techniques, having a bigger block size positively impacts the compression ratio since more data can be fed through compression. Within a larger pool of data, more data patterns can potentially be identified as repetitive, which improves the compression ratio. However, larger blocks require more memory and increase read latency for decompression.
The third factor is workload. Two features of a workload are recognized that determine the effectiveness of compression in key–value stores, one of which is compressibility [22]. If the data has high randomness and does not have enough repeated patterns, compression may not be beneficial. The other feature is the lifetime. In key–value stores, SSTable files in lower levels, especially level 0, will be compacted and deleted in the near future. In contrast, SSTable files at higher levels have a long lifetime. The compression ratio is more critical for long-term data, while compression speed is more important for short-term data.
Fourth, system resources such as CPU capability and storage type are important factors. Note that compaction itself is a CPU-intensive job, consuming a large portion of CPU utilization. Therefore, it is better to use a lightweight compression technique unless there are abundant CPU resources. For slow storage such as HDDs (hard disk drives), the latency for compression is relatively small compared to the I/O latency, meaning that it is possible to employ more powerful techniques to enhance the compression ratio. On the contrary, for fast storage such as NVMe SSDs (solid state drives), employing more powerful techniques could increase the overall data access latency considerably.
Finally, key–value store configurations are also crucial factors. For instance, key–value stores use two different compaction mechanisms: leveled and tiered compaction [10]. The leveled mechanism applies compaction aggressively, obtaining better storage utilization at the cost of increased compaction counts, while the tiered mechanism applies compaction in a lazy manner, reducing compaction counts at the cost of worse space utilization.
References
- Sayood, K. Introduction to Data Compression, 5th ed.; Morgan Kaufmann: Cambridge, MA, USA, 2018; ISBN 978-0-12-809474-4.
- Salomon, D. Data Compression: The Complete Reference, 4th ed.; Springer: London, UK, 2007; ISBN 978-1-84628-602-5.
- Jayasankar, U.; Thirumal, V.; Ponnurangam, D. A survey on data compression techniques: From the perspective of data quality, coding schemes, data type and applications. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 119–140.
- Kleppmann, M. Designing Data-Intensive Applications: The Big Ideas behind Reliable, Scalable, and Maintainable Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017; ISBN 978-1-449-37332-0.
- Ramadhan, A.R.; Choi, M.; Chung, Y.; Choi, J. An Empirical Study of Segmented Linear Regression Search in LevelDB. Electronics 2023, 12, 1018.
- LevelDB: A Fast Key-Value Storage Library Written at Google. Available online: https://github.com/google/leveldb (accessed on 30 July 2023).
- Dong, S.; Kryczka, A.; Jin, Y.; Stumm, M. Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience. In Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST’21), Online Conference, 23–25 February 2021; pp. 33–49.
- Elhemali, M.; Gallagher, N.; Gordon, N.; Idziorek, J.; Krog, R.; Lazier, C.; Mo, E.; Mritunjai, A.; Perianayagam, S.; Rath, T.; et al. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. In Proceedings of the 2022 USENIX Annual Technical Conference (ATC’22), Carlsbad, CA, USA, 11–13 July 2022; pp. 1037–1048.
- Sumbaly, R.; Kreps, J.; Gao, L.; Feinberg, A.; Soman, C.; Shah, S. Serving Large-scale Batch Computed Data with Project Voldemort. In Proceedings of the 10th USENIX Conference on File and Storage Technologies (FAST’12), San Jose, CA, USA, 14–17 February 2012.
- Cao, Z.; Dong, S.; Vemuri, S.; Du, D. Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20), Santa Clara, CA, USA, 25–27 February 2020; pp. 209–223.
- Dong, S.; Callaghan, M.; Galanis, L.; Borthakur, D.; Savor, T.; Strum, M. Optimizing Space Amplification in RocksDB. In Proceedings of the CIDR, Chaminade, CA, USA, 8–11 January 2017.
- Kim, J.; Vetter, J.S. Implementing efficient data compression and encryption in a persistent key-value store for HPC. Int. J. High Perform. Comput. Appl. 2019, 33, 1098–1112.
- Aghav, S. Database compression techniques for performance optimization. In Proceedings of the 2010 2nd International Conference on Computer Engineering and Technology, Chengdu, China, 16–19 April 2010.
- Snappy: A Fast Compressor/Decompressor. Available online: https://github.com/google/snappy (accessed on 30 July 2023).
- Zstandard—Fast Real-Time Compression Algorithm. Available online: https://github.com/facebook/zstd (accessed on 30 July 2023).
- LZ4: Extremely Fast Compression Algorithm. Available online: https://github.com/lz4/lz4 (accessed on 30 July 2023).
- Apache Cassandra: Open Source NoSQL Database. Available online: https://cassandra.apache.org/ (accessed on 30 July 2023).
- WiredTiger Storage Engine. Available online: https://www.mongodb.com/docs/manual/core/wiredtiger/ (accessed on 30 July 2023).
- Welcome to Apache HBaseTM. Available online: https://hbase.apache.org/ (accessed on 30 July 2023).
- O’Neil, P.; Cheng, E.; Gawlick, D.; O’Neil, E. The log-structured merge-tree (LSM-tree). Acta Inform. 1996, 33, 351–385.
- Zhang, Z.; Yue, Y.; He, B.; Xiong, J.; Chen, M.; Zhang, L.; Sun, N. Pipelined compaction for the LSM-tree. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 777–786.
- Lim, H.; Andersen, D.G.; Kaminsky, M. Towards Accurate and Fast Evaluation of Multi-Stage Log-structured Designs. In Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST ’16), Santa Clara, CA, USA, 22–25 February 2016; pp. 149–166.
More
Information
Subjects:
Mathematics, Applied
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.3K
Revisions:
2 times
(View History)
Update Date:
27 Oct 2023
Table of Contents




Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No