 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Hiren K Mewada | -- | 2367 | 2023-10-18 08:54:43 | | | |
| 2 | Lindsay Dong | + 7 word(s) | 2374 | 2023-10-19 02:26:08 | | |
Video Upload Options
Voice-controlled devices are in demand due to their hands-free controls. However, using voice-controlled devices in sensitive scenarios like smartphone applications and financial transactions requires protection against fraudulent attacks referred to as “speech spoofing”. The algorithms used in spoof attacks are practically unknown; hence, further analysis and development of spoof-detection models for improving spoof classification are required. A study of the spoofed-speech spectrum suggests that high-frequency features are able to discriminate genuine speech from spoofed speech well. Typically, linear or triangular filter banks are used to obtain high-frequency features. However, a Gaussian filter can extract more global information than a triangular filter. In addition, mel frequency cepstral coefficients (MFCCs) features are preferable among other speech features because of their lower covariance.
1. Introduction
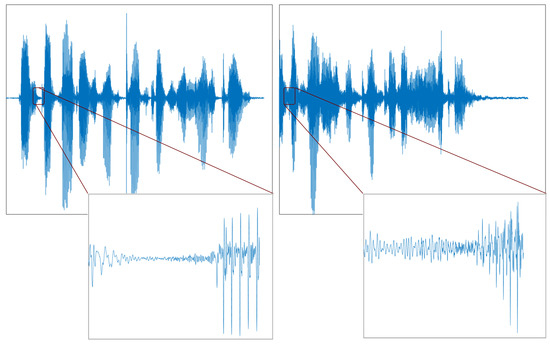
2. Genuine and Spoof Speech Signal Classification
References
- Wu, Z.; Evans, N.; Kinnunen, T.; Yamagishi, J.; Alegre, F.; Li, H. Spoofing and countermeasures for speaker verification: A survey. Speech Commun. 2015, 66, 130–153.
- Kinnunen, T.; Sahidullah, M.; Delgado, H.; Todisco, M.; Evans, N.; Yamagishi, J.; Lee, K.A. The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection; The International Speech Communication Association: Berlin, Germany, 2017.
- Ghaderpour, E.; Pagiatakis, S.D.; Hassan, Q.K. A survey on change detection and time series analysis with applications. Appl. Sci. 2021, 11, 6141.
- Mewada, H.K.; Patel, A.V.; Chaudhari, J.; Mahant, K.; Vala, A. Wavelet features embedded convolutional neural network for multiscale ear recognition. J. Electron. Imaging 2020, 29, 043029.
- Alim, S.A.; Rashid, N.K.A. Some Commonly Used Speech Feature Extraction Algorithms; IntechOpen: London, UK, 2018.
- Mewada, H. 2D-wavelet encoded deep CNN for image-based ECG classification. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–17.
- Witkowski, M.; Kacprzak, S.; Zelasko, P.; Kowalczyk, K.; Galka, J. Audio Replay Attack Detection Using High-Frequency Features. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 27–31.
- Singh, M.; Pati, D. Usefulness of linear prediction residual for replay attack detection. AEU-Int. J. Electron. Commun. 2019, 110, 152837.
- Yang, J.; Das, R.K. Low frequency frame-wise normalization over constant-Q transform for playback speech detection. Digit. Signal Process. 2019, 89, 30–39.
- Sriskandaraja, K.; Sethu, V.; Ambikairajah, E. Deep siamese architecture based replay detection for secure voice biometric. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 671–675.
- Huang, L.; Pun, C.M. Audio Replay Spoof Attack Detection by Joint Segment-Based Linear Filter Bank Feature Extraction and Attention-Enhanced DenseNet-BiLSTM Network. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1813–1825.
- Zaw, T.H.; War, N. The combination of spectral entropy, zero crossing rate, short time energy and linear prediction error for voice activity detection. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; pp. 1–5.
- Singh, S.; Rajan, E. Vector quantization approach for speaker recognition using MFCC and inverted MFCC. Int. J. Comput. Appl. 2011, 17, 1–7.
- Singh, S.; Rajan, D.E. A Vector Quantization approach Using MFCC for Speaker Recognition. In Proceedings of the International Conference Systemic, Cybernatics and Informatics ICSCI under the Aegis of Pentagram Research Centre Hyderabad, Hyderabad, India, 4–7 January 2007; pp. 786–790.
- Chakroborty, S.; Saha, G. Improved text-independent speaker identification using fused MFCC & IMFCC feature sets based on Gaussian filter. Int. J. Signal Process. 2009, 5, 11–19.
- Jelil, S.; Das, R.K.; Prasanna, S.M.; Sinha, R. Spoof detection using source, instantaneous frequency and cepstral features. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 22–26.
- Sahidullah, M.; Kinnunen, T.; Hanilçi, C. A comparison of features for synthetic speech detection. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015.
- Loweimi, E.; Barker, J.; Hain, T. Statistical normalisation of phase-based feature representation for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5310–5314.
- Pal, M.; Paul, D.; Saha, G. Synthetic speech detection using fundamental frequency variation and spectral features. Comput. Speech Lang. 2018, 48, 31–50.
- Patil, A.T.; Patil, H.A.; Khoria, K. Effectiveness of energy separation-based instantaneous frequency estimation for cochlear cepstral features for synthetic and voice-converted spoofed speech detection. Comput. Speech Lang. 2022, 72, 101301.
- Kadiri, S.R.; Yegnanarayana, B. Analysis and Detection of Phonation Modes in Singing Voice using Excitation Source Features and Single Frequency Filtering Cepstral Coefficients (SFFCC). In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 441–445.
- Kethireddy, R.; Kadiri, S.R.; Gangashetty, S.V. Deep neural architectures for dialect classification with single frequency filtering and zero-time windowing feature representations. J. Acoust. Soc. Am. 2022, 151, 1077–1092.
- Kethireddy, R.; Kadiri, S.R.; Kesiraju, S.; Gangashetty, S.V. Zero-Time Windowing Cepstral Coefficients for Dialect Classification. In Proceedings of the The Speaker and Language Recognition Workshop (Odyssey), Tokyo, Japan, 2–5 November 2020; pp. 32–38.
- Kadiri, S.R.; Alku, P. Mel-Frequency Cepstral Coefficients of Voice Source Waveforms for Classification of Phonation Types in Speech. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2508–2512.
- Mewada, H.K.; Chaudhari, J. Low computation digital down converter using polyphase IIR filter. Circuit World 2019, 45, 169–178.
- Loweimi, E.; Ahadi, S.M.; Drugman, T. A new phase-based feature representation for robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7155–7159.
- Dua, M.; Aggarwal, R.K.; Biswas, M. Discriminative training using noise robust integrated features and refined HMM modeling. J. Intell. Syst. 2020, 29, 327–344.
- Rahmeni, R.; Aicha, A.B.; Ayed, Y.B. Speech spoofing detection using SVM and ELM technique with acoustic features. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 2–5 September 2020; pp. 1–4.
- Muckenhirn, H.; Korshunov, P.; Magimai-Doss, M.; Marcel, S. Long-term spectral statistics for voice presentation attack detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2098–2111.
- Zhang, C.; Yu, C.; Hansen, J.H. An investigation of deep-learning frameworks for speaker verification antispoofing. IEEE J. Sel. Top. Signal Process. 2017, 11, 684–694.
- Ghosh, R.; Phadikar, S.; Deb, N.; Sinha, N.; Das, P.; Ghaderpour, E. Automatic Eyeblink and Muscular Artifact Detection and Removal From EEG Signals Using k-Nearest Neighbor Classifier and Long Short-Term Memory Networks. IEEE Sens. J. 2023, 23, 5422–5436.
- Jo, J.; Kung, J.; Lee, Y. Approximate LSTM computing for energy-efficient speech recognition. Electronics 2020, 9, 2004.
- Gong, P.; Wang, P.; Zhou, Y.; Zhang, D. A Spiking Neural Network With Adaptive Graph Convolution and LSTM for EEG-Based Brain-Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 1440–1450.
- Wu, Z.; Kinnunen, T.; Evans, N.; Yamagishi, J.; Hanilçi, C.; Sahidullah, M.; Sizov, A. ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015.
- Todisco, M.; Delgado, H.; Evans, N.W. A new feature for automatic speaker verification anti-spoofing: Constant q cepstral coefficients. In Proceedings of the Odyssey, Bilbao, Spain, 21–24 June 2016; Volume 2016, pp. 283–290.
- Xue, J.; Zhou, H.; Song, H.; Wu, B.; Shi, L. Cross-modal information fusion for voice spoofing detection. Speech Commun. 2023, 147, 41–50.
- Alluri, K.R.; Achanta, S.; Kadiri, S.R.; Gangashetty, S.V.; Vuppala, A.K. Detection of Replay Attacks Using Single Frequency Filtering Cepstral Coefficients. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 2596–2600.
- Bharath, K.; Kumar, M.R. Replay spoof detection for speaker verification system using magnitude-phase-instantaneous frequency and energy features. Multimed. Tools Appl. 2022, 81, 39343–39366.
- Woubie, A.; Bäckström, T. Voice Quality Features for Replay Attack Detection. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 384–388.
- Chaudhari, A.; Shedge, D. Integration of CQCC and MFCC based Features for Replay Attack Detection. In Proceedings of the 2022 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 9–11 March 2022; pp. 1–5.
- Rahmeni, R.; Aicha, A.B.; Ayed, Y.B. Voice spoofing detection based on acoustic and glottal flow features using conventional machine learning techniques. Multimed. Tools Appl. 2022, 81, 31443–31467.
- Naith, Q. Thesis title: Crowdsourced Testing Approach For Mobile Compatibility Testing. Ph.D. Thesis, University of Sheffield, Sheffield, UK, 2021.
- Sizov, A.; Khoury, E.; Kinnunen, T.; Wu, Z.; Marcel, S. Joint speaker verification and antispoofing in the i-vector space. IEEE Trans. Inf. Forensics Secur. 2015, 10, 821–832.
- Luo, A.; Li, E.; Liu, Y.; Kang, X.; Wang, Z.J. A Capsule Network Based Approach for Detection of Audio Spoofing Attacks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6359–6363.
- Monteiro, J.; Alam, J.; Falk, T.H. An ensemble based approach for generalized detection of spoofing attacks to automatic speaker recognizers. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6599–6603.
- Alluri, K.R.; Achanta, S.; Kadiri, S.R.; Gangashetty, S.V.; Vuppala, A.K. SFF Anti-Spoofer: IIIT-H Submission for Automatic Speaker Verification Spoofing and Countermeasures Challenge 2017. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 107–111.
- Patil, A.T.; Acharya, R.; Patil, H.A.; Guido, R.C. Improving the potential of Enhanced Teager Energy Cepstral Coefficients (ETECC) for replay attack detection. Comput. Speech Lang. 2022, 72, 101281.
- Tom, F.; Jain, M.; Dey, P. End-To-End Audio Replay Attack Detection Using Deep Convolutional Networks with Attention. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 681–685.
- Lai, C.I.; Chen, N.; Villalba, J.; Dehak, N. ASSERT: Anti-spoofing with squeeze-excitation and residual networks. arXiv 2019, arXiv:1904.01120.
- Scardapane, S.; Stoffl, L.; Röhrbein, F.; Uncini, A. On the use of deep recurrent neural networks for detecting audio spoofing attacks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3483–3490.
- Mittal, A.; Dua, M. Static–dynamic features and hybrid deep learning models based spoof detection system for ASV. Complex Intell. Syst. 2022, 8, 1153–1166.
- Dinkel, H.; Qian, Y.; Yu, K. Investigating raw wave deep neural networks for end-to-end speaker spoofing detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2002–2014.
- Mittal, A.; Dua, M. Automatic speaker verification system using three dimensional static and contextual variation-based features with two dimensional convolutional neural network. Int. J. Swarm Intell. 2021, 6, 143–153.
- Chintha, A.; Thai, B.; Sohrawardi, S.J.; Bhatt, K.; Hickerson, A.; Wright, M.; Ptucha, R. Recurrent convolutional structures for audio spoof and video deepfake detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1024–1037.
- Alzantot, M.; Wang, Z.; Srivastava, M.B. Deep residual neural networks for audio spoofing detection. arXiv 2019, arXiv:1907.00501.
- Wu, Z.; Das, R.K.; Yang, J.; Li, H. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks. arXiv 2020, arXiv:2009.09637.
- Li, J.; Wang, H.; He, P.; Abdullahi, S.M.; Li, B. Long-term variable Q transform: A novel time-frequency transform algorithm for synthetic speech detection. Digit. Signal Process. 2022, 120, 103256.

