 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Alessandro Midolo | -- | 2153 | 2023-09-19 15:37:01 | | | |
| 2 | Rita Xu | -3 word(s) | 2150 | 2023-09-20 03:36:04 | | |
Video Upload Options
Sequential programs can benefit from parallel execution to improve their performance. When developing a parallel application, several techniques are employed to achieve the desired behavior: identifying parts that can run in parallel, synchronizing access to shared data, tuning performance, etc. Admittedly, manually transforming a sequential application to make it parallel can be tedious due to the large number of lines of code to inspect, the possibility of errors arising from inaccurate data dependence analysis leading to unpredictable behavior, and inefficiencies when the workload between parallel threads is unbalanced. This entry proposes an automatic approach that analyzes Java source code to identify method calls that are suitable for parallel execution and transforms them so that they run in another thread. The approach is based on data dependence and control dependence analyses to determine the execution flow and data accessed. Based on the proposed method, a tool has been developed to enhance applications by incorporating parallelism, i.e., transforming suitable method calls to execute on parallel threads, and synchronizing data access where needed.
1. Introduction
2. Proposed Approach
The proposed approach uses static analysis to gather data from the source code of the analysed software. The procedure takes the source code of the analyzed application as input, and, after parsing, it returns the instances of CompilationUnit for the application. A CompilationUnit is a class modeling a single Java file represented as an AST. Afterward, the method’s declarations are extracted from each CompilationUnit instance to obtain a list containing all the methods implemented in the source code. A method body generally contains many instructions; researchers focus on method calls since they are the instructions that will be evaluated to be run in parallel among all the instructions in the method’s body. Each method call is analyzed according to its context, data dependence, and the number of instructions performed. Once a method call passes all the checks, it is transformed to a parallel version and the method is updated with the proper synchronization statement, according to the data-dependent statement found. Finally, all the compilation units containing at least one transformed method will be written in new Java files.
3. Method Call Analysis
Running methods could take considerable execution times since such methods could have a large number of instructions or encapsulate nested method calls within them. To speed up the execution, some methods could be executed in a new dedicated thread. Researchers performed three different analyses to ensure that the proposed automatic source transfor- mation into a parallel version preserves the behavior and the correctness of the original version. Firstly, researchers analyze the context of the method call to assess that inserting a parallel construct is safe; secondly, they check data dependencies between concurrent instructions to avoid race conditions; thirdly, they evaluate the number of instructions that threads would run before synchronization is needed, to determine whether the workload is balanced between them and if the number of instructions is sufficiently large to obtain performance gain.
3.1 Method Context Analysis
The context of the method call has crucial significance when evaluating whether there is a gain when running the method call in parallel. The context is the statement where the method call is retrieved; it could be the method call itself, or a more complex statement containing it. For the former case, further analysis of the same statement is not needed since the method call is the only instruction in the statement; hence, researchers can check further conditions to determine whether parallel execution is possible and desired. Conversely, for the latter cases, i.e., the method call is found within another statement. There could be some cases where parallel execution is unsuitable; hence, researchers avoid further analysis aimed at parallelization.
The first example in the table below shows a of method call that is unsuitable for parallel execution because it is part of the condition expression in a if statement. Parallel execution is unsuitable in such case because the returned value of the method call is immediately used to determine whether to execute the following statements. The second example shows a method call that can be transformed to run in parallel. The result of the method call is not used to determine whether to execute the following statements. Indeed, the aim is to evaluate whether the whole statement (which could consist of several expressions) could run in a thread parallel to the thread that runs the following statements.
|
// Method call checkForFileAndPatternCollisions() in a condition statement 1. if (checkForFileAndPatternCollisions()) { // Variable declaration expression using a method call |
3.2 Data Dependence Analysis
Accessing data shared among threads should be properly guarded. Researchers used a tool proposed in one of the previous works, which provides a set of APIs to extract data dependence for methods [9]. This approach analyzes both variables and method calls inside a method to define its input set (i.e., the set of variables read) and output set (i.e., the set of variables written).
Table below shows an example of the data dependence analysis. For line 74, method getRandomlyNamedLoggerContextVO() is the one researchers are analyzing, and the method call is found within a variable declaration expression; hence, as stated before, researchers consider this instruction feasible. Then, starting from line 75, the data dependence analysis is performed to find a data-dependent statement, which is found on line 79 because variable lcVO is assigned to e.loggerContextVO field. The data-dependent statement represents the point where the main thread will have to wait for the forked thread to finish before it can continue with its execution.
|
74. LoggerContextVO lcVO = corpusModel.getRandomlyNamedLoggerContextVO(); |
3.3 Control Flow Graph Analysis
Having found all data dependencies among statements, the analysis aims at finding the paths that could execute in parallel. Possible parallel paths are basically found by analyzing the control flow graph(CFG) [8] , i.e., a representation by means of a graph of all the paths that could be executed by a program. Then, a further assessment is performed to determine whether the introduced parallelism will provide performance gains. Therefore, the last part of the proposed analysis determines if the amount of work that will be assigned to both threads is balanced and adequately large to make it worth the effort required to start a new thread.
To evaluate the workload that will be assigned to each thread, it is necessary that the execution paths are clearly defined and there is no ambiguity. Hence, given a pair of nodes in the graph, just one path should exist connecting them. This assumption must be satisfied by all nodes in the CFG. To ensure that, researchers need to properly handle conditional branches and loops. For conditional statements, having two alternative paths, it would be necessary to prune one branch from the graph. Researchers follow the worst-case execution time (WCET) approach [10], i.e., researchers select the branch with the highest number of instructions, as this is likely the one with the lengthiest execution time, while the other branch is disconnected from the graph. Therefore, pruned nodes are not connected to any other node; however, researchers keep these nodes in the representation because they could be reconnected to the graph when needed for further analysis.
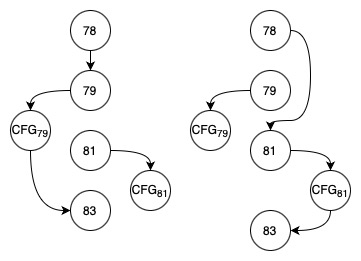
Table below shows an example where a conditional statement has a method call in each branch. When the analysis decides to parallelize the method call within the then branch (i.e., line 79) because of the WCET, the else branch will be removed from the graph; the resulting CFG is shown on the left side of the figure below. Otherwise, the then branch will be removed; see the right side of the figure.
|
78. if (ruleEntry.type == RuleEntry.TYPE_TEST_RULE) { |
3.4 Define and Evaluate the Two Parallel Paths
The last step of the approach consists of evaluating the instructions that compose the two paths, each of which could be assigned to a thread. The first path will be from the node containing the instruction researchers want to run in parallel and the following instruction, while the other path is from the latter to the data-dependent statement. The paths are computed as Dijkstra shortest path algorithm, using the API provided by the third-party library JGraphT. By construction, the shortest path is the only path between two given nodes. The length of a path represents the number of nodes (instructions) within it; therefore, researchers check the lengths of both paths by filtering out paths with short lengths and paths with differences between their lengths that are bigger than a threshold. The function returns true if the paths satisfy these two requirements, and false otherwise.
Table below shows the code of the method refactored for parallel execution by using CompletableFuture, as it allows running the method at line 96 asynchronously (using runasync()). The instruction at line 99, future.join(), is the waiting point for the main thread until the task defined at line 96 finishes.
|
public void start () { |
4. Conclusion
This research presents an approach and a corresponding tool that statically analyze the source code of an application, to identify opportunities for parallel execution. The approach is based on the analysis of the control flow and data dependence to assess the possibility of executing some statements in parallel while preserving the program’s correctness. For the proposed approach, the control flow graph of an application under analysis is automatically obtained; this graph is used to find possible parallel paths and estimate potential performance gains.
A transformed parallel version of the application can then be automatically generated to have methods that execute in a new thread by using a Java CompletableFuture. The changes to the source code are minimal, making the transformation clean and effective. The produced tool can be very useful for updating legacy applications and supporting the development of new applications.
The comparison with the state of the art, the results and the experiments conducted can be found in the related paper.
References
- Ahmed, S.; Bagherzadeh, M. What Do Concurrency Developers Ask about? A Large-Scale Study Using Stack Overflow. In Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Oulu, Finland, 11–12 October 2018.
- Pinto, G.; Torres, W.; Castor, F. A Study on the Most Popular Questions about Concurrent Programming. In Proceedings of the 6th Workshop on Evaluation and Usability of Programming Languages and Tools, Pittsburgh, PA, USA, 26 October 2015; pp. 39–46.
- Pinto, G.; Torres, W.; Fernandes, B.; Castor, F.; Barros, R.S. A large-scale study on the usage of Java’s concurrent programming constructs. J. Syst. Softw. 2015, 106, 59–81.
- Fox, G.C.; Williams, R.D.; Messina, P.C. Parallel Computing Works! Morgan Kaufmann: Cambridge, MA, USA, 2014.
- Bernstein, A.J. Analysis of Programs for Parallel Processing. IEEE Trans. Electron. Comput. 1966, EC-15, 757–763.
- Maydan, D.E.; Hennessy, J.L.; Lam, M.S. Efficient and Exact Data Dependence Analysis. SIGPLAN Not. 1991, 26, 1–14.
- Wolfe, M.; Banerjee, U. Data Dependence and Its Application to Parallel Processing. Int. J. Parallel Program. 1987, 16, 137–178.
- Allen, F.E. Control flow analysis. ACM Sigplan Notices 1970, 5, 1–19.
- Midolo, A.; Tramontana, E. An API for Analysing and Classifying Data Dependence in View of Parallelism. In Proceedings of the ACM International Conference on Computer and Communications Management (ICCCM), Okayama, Japan, 29–31 July 2022; pp. 61–67
- Gustafsson, J.; Betts, A.; Ermedahl, A.; Lisper, B. The Mälardalen WCET benchmarks: Past, present and future. In Proceedings of the 10th International Workshop on Worst-Case Execution Time Analysis (WCET), Brussels, Belgium, 6 July 2010; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2010

