Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Azam Amir | -- | 1406 | 2023-07-18 02:45:29 | | | |
| 2 | Sirius Huang | Meta information modification | 1406 | 2023-07-19 02:54:17 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Amir, A.; Henry, M. Decision Tree Analysis for Highway Network Management. Encyclopedia. Available online: https://encyclopedia.pub/entry/46895 (accessed on 24 July 2026).
Amir A, Henry M. Decision Tree Analysis for Highway Network Management. Encyclopedia. Available at: https://encyclopedia.pub/entry/46895. Accessed July 24, 2026.
Amir, Azam, Michael Henry. "Decision Tree Analysis for Highway Network Management" Encyclopedia, https://encyclopedia.pub/entry/46895 (accessed July 24, 2026).
Amir, A., & Henry, M. (2023, July 18). Decision Tree Analysis for Highway Network Management. In Encyclopedia. https://encyclopedia.pub/entry/46895
Amir, Azam and Michael Henry. "Decision Tree Analysis for Highway Network Management." Encyclopedia. Web. 18 July, 2023.
Copy Citation
One important aspect of network-level highway management is the rational distribution of the maintenance budget to the necessary assets. However, the decision making underlying budget allocation is often unclear, making it difficult to determine whether the budget is being allocated effectively.
highway management
decision tree algorithm
maintenance planning
decision making
machine learning
data analytics
PDCA
1. Introduction
Highway network management planning involves the allocation of the available budget to specific road sections based on their condition and prescribed maintenance and rehabilitation requirements. Realizing the effective and rational maintenance of highway assets requires an integrated maintenance management system that carries out data collection and maintenance activity reports at levels where the information can actually improve or change the way planning and implementation is carried out. Figure 1a shows a conceptual integrated management system scheme to guide road agencies. It was established in the scheme that, regardless of whatever level of integration the road agency chooses to pursue, the maintenance management system (MMS) should be integrated across maintenance and other functional area databases within a department and among the various maintenance activities [1].
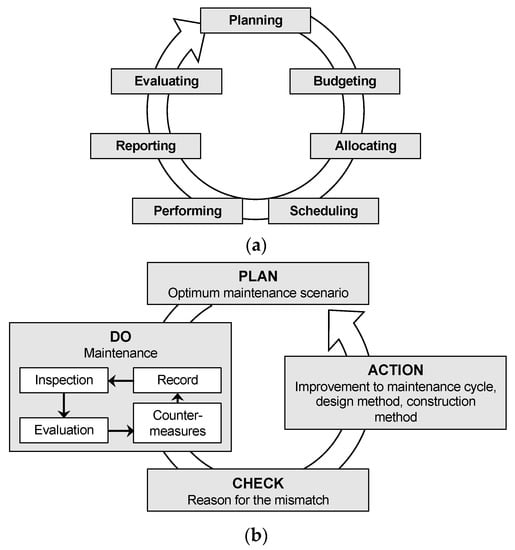
Figure 1. Approaches to the effective management of road infrastructure. (a) Maintenance management activity flow. (b) PDCA cycle for maintenance management.
The same concept can also be explained using a PDCA (plan–do–check–action) cycle. The maintenance management plan as defined by the PDCA cycle is a management system used to control and constantly improve processes. As shown in Figure 1b, it consists of four stages. The first stage of the PDCA cycle is PLAN, which is the current established plan for carrying out road maintenance. Thus, it is necessary to fully understand an agency’s current practice for selecting road sections for a maintenance plan before improvements can be considered. The second stage is DO, which is to perform the maintenance activities: inspecting the road infrastructure, determining the condition based on the inspection results, choosing the appropriate countermeasures, and carrying them out, and recording all data involved in these processes. The CHECK part of the PDCA involves finding mismatches between the assumptions or expectations under the original maintenance plan and the newly obtained results. Based on the knowledge obtained from the check stage, the last step, ACTION, explores improvements for future maintenance planning by analyzing the various potential courses of action based on observations from the previous maintenance and then planning a more optimized maintenance plan to be carried out in the next PDCA cycle. Hence, it has been established that effective road asset maintenance is not restricted only to the planning or implementation stage but also includes the development of improvement strategies for future maintenance planning based on the data gathered during maintenance.
The improvement of the future maintenance plan by evidence-based decision making is challenging as it involves diversified data, such as road inventory and its conditions, climate conditions, traffic volume, and loading, allocated maintenance costs, and others. The complexity in these domains is matched by increasingly subjective objectives to be achieved in road maintenance planning, including the consideration of sustainability, levels of services, and resilience [2]. As suggested by the PDCA cycle, this problem can be tackled by analyzing past road-related data to find sub-optimal decisions or actions in the existing planning and to explore how to improve the future maintenance planning. Furthermore, advancements in machine learning algorithms offer the potential to automate this process, which will help realize more data-driven and rational highway management by reducing human subjectivity in the decision-making process.
2. Decision Making for Road Network Management
Effective decision making plays an important role in highway network management, especially for the rational allocation of maintenance budgets [3]. However, these decision-making processes are not always simple, as they must juggle many different challenges, such as large networks, limited resources, and conflicting goals, as well as the uncertainties inherent in both data and decision making [4][5]. Traditionally, decision making for highway management was based primarily on the subjective perspectives of decision makers and, consequently, it was not possible to evaluate the rationality of the maintenance planning. With the evolution of data analytics, however, a shift has occurred in decision making in the transportation engineering field towards extracting knowledge from complex datasets utilizing tools and techniques from the data science field. Researchers have adopted various algorithms for determining how to prioritize road sections for maintenance planning through the analysis of highway network data. Fwa et al. proposed a model based on a genetic algorithm, which served as an analytical tool for pavement maintenance [6]. The study also highlighted the importance of effective budget planning strategies for ensuring cost-efficient maintenance practice by analyzing the impacts of poor budget planning during the initial years of pavement maintenance. Mbwana et al. developed an optimization model using Markov transition probabilities to identify specific road links for optimization in a network-level pavement management system [7]. The fuzzy logic technique was similarly utilized for pavement condition ratings and decision making related to pavement maintenance for road networks [8]. Mahpour et al. tested seven machine learning algorithms, which included boosting regression, lasso, ridge, random forest regression, elastic net, neural network, and multiple linear regression, for determining the most cost-effective and efficient maintenance policies for a road network in Iran, and it was concluded that the gradient boosting regression was the most accurate algorithm for predicting the cost of maintenance policies [9]. Finally, Han et al. proposed a decision-making method for improving the accuracy and efficiency of maintenance decisions for asphalt pavement maintenance management by utilizing an improved weight random forest algorithm (IWRF) based on correlation analysis and analytic hierarchy process (AHP) [10].
3. Decision Tree Analysis
Decision tree analysis is a type of supervised machine learning, wherein the objective is to predict the class or value of a target variable using a set of decision rules inferred from training data, which are then presented graphically as a tree-shaped structure that is easy to understand via a decision maker [11][12]. The decision tree consists of a root node, branches, and leaf nodes. The topmost node is the root node, the testing of an attribute occurs at each internal node, and the outcome of the test appears in a branch and the class label appears in a leaf node [13]. Hence, in a decision tree, each node represents a feature (attribute), each link represents a decision (rule), and each leaf represents an outcome (the predicted categorical or continuous value). A typical decision tree model is shown in Figure 2.
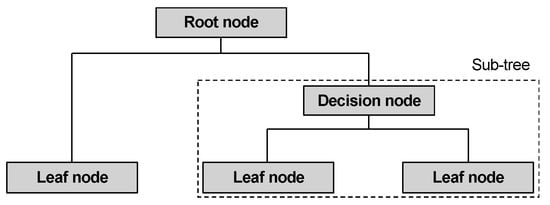
Figure 2. Structure of decision model.
The decision tree can be used for classification or regression depending on the type of the outcome variable, and there are different decision tree algorithms, such as C5.0 (Quinlan, 1993), iterative dichotomiser 3 (ID3) (Quinlan, 1986), chi-squared automatic interaction detection (CHAID) (Kass, 1980), and classification and regression tree (CART). The characteristics of these different decision tree algorithms are shown in Table 1. C5.0 is the most recent Quinlan iteration and uses information gain (entropy) as its splitting criteria to produce a multi-branched tree. ID3 was the first developed algorithm and can only be used for classification problems with nominal variables. CHAID uses the chi-square test to predict the most dominant feature and can only be applied to classification problems. With CART, the tree model is visualized as a binary tree, and the decision rules are generated by splitting the predictor variables repeatedly until some predetermined stopping criteria are met [14]. Each node relates to a predictor variable and a split cutoff on that variable, and the leaf nodes represent the predicted outcomes of a target variable.
Table 1. Decision tree algorithms.
| Decision Tree Algorithm | Data Types | Splitting Method |
|---|---|---|
| C 5.0 | Categorical, Numerical | No Restriction |
| ID3 | Categorical | No Restriction |
| CHAID | Categorical | n/a |
| CART | Categorical, Numerical | Binary Splits |
4. Applications of Decision Tree Analysis
The process of analyzing data by using the decision tree method has been successfully applied in many fields, such as medicine [15][16][17][18], business management [19][20], crime prediction [21][22], urban transport [12], and construction engineering [23][24], but there are few examples of its application to solving road asset management problems. Behrouz et al. used the cloud decision tree for selecting the most optimal maintenance and repair strategies for Iran’s national road network [25]. They developed various decision tree models for every province of Iran and concluded that fatigue cracking and international roughness index (IRI) were the most important parameters for determining the most appropriate maintenance and repair scenario. Chen et al. (2015) analyzed road maintenance data and statistical data (distress, IRI, crack, pavement contract, etc.) of Taipei city and performed decision tree analysis (C5.0 and ID3) and support vector machine to develop maintenance recommendations [26].
References
- Brewer, K.A. AASHTO Maintenance Manual for Roadways and Bridges; Aashto: Washington, DC, USA, 2007.
- Piryonesi, S.M.; El-Diraby, T.E. Data analytics in asset management: Cost-effective prediction of the pavement condition index. J. Infrastruct. Syst. 2020, 26, 04019036.
- Chen, L.; Bai, Q. Optimization in decision making in infrastructure asset management: A review. Appl. Sci. 2019, 9, 1380.
- Bai, Q.; Labi, S.; Sinha, K.C. Trade-off analysis for multiobjective optimization in transportation asset management by generating Pareto frontiers using extreme points nondominated sorting genetic algorithm II. J. Transp. Eng. 2012, 138, 798–808.
- Chen, L. Development of a Multi-Objective Optimisation Technique for Long-Term and Network-Level Decision Making in Infrastructure Asset Management. Ph.D. Thesis, The University of Auckland, Auckland, New Zealand, 2016.
- Fwa, T.F.; Tan, C.Y.; Chan, W.T. Road-maintenance planning using genetic algorithms. II: Analysis. J. Transp. Eng. 1994, 120, 710–722.
- Mbwana, J.R.; Turnquist, M.A. Optimization modeling for enhanced network-level pavement management system. Transp. Res. Rec. 1996, 1524, 76–85.
- Fwa, T.F.; Shanmugam, R. Fuzzy logic technique for pavement condition rating and maintenance-needs assessment. In Fourth International Conference on Managing Pavements; National University of Singapore: Singapore, 1998; Volume 1.
- Mahpour, A.; El-Diraby, T. Application of Machine-Learning in Network-Level Road Maintenance Policy-Making: The Case of Iran. Expert Syst. Appl. 2022, 191, 116283.
- Han, C.; Ma, T.; Xu, G.; Chen, S.; Huang, R. Intelligent decision model of road maintenance based on improved weight random forest algorithm. Int. J. Pavement Eng. 2022, 23, 985–997.
- Patel, H.H.; Prajapati, P. Study and analysis of decision tree-based classification algorithms. Int. J. Comput. Sci. Eng. 2018, 6, 74–78.
- Tsami, M.; Adamos, G.; Nathanail, E.; Budiloviča, E.B.; Jackiva, I.Y.; Magginas, V. A decision tree approach for achieving high customer satisfaction at urban interchanges. Transp. Telecommun. 2018, 19, 194.
- Gershman, A.; Meisels, A.; Lüke, K.H.; Rokach, L.; Schclar, A.; Sturm, A. A decision tree-based recommender system. In Proceedings of the 10th International Conference on Innovative Internet Community Systems (I2CS)—Jubilee Edition 2010, Bangkok, Thailand, 3–5 June 2010.
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Abingdon, UK, 2017.
- Rahman, R.M.; Hasan, F.R.M. Using and comparing different decision tree classification techniques for mining ICDDR, B Hospital Surveillance data. Expert Syst. Appl. 2011, 38, 11421–11436.
- Bae, J.M. The clinical decision analysis using a decision tree. Epidemiol. Health 2014, 36, e2014025.
- Si, T.; Sun, L.; Zhang, Y.; Zhang, L. Dose Adjustment Model of Paliperidone in Patients with Acute Schizophrenia: A post hoc Analysis of an Open-Label, Single-Arm Multicenter Study. Front. Psychiatry 2021, 12, 723245.
- Heldner, M.R.; Chalfine, C.; Houot, M.; Umarova, R.M.; Rosner, J.; Lippert, J.; Gallucci, L.; Leger, A.; Baronnet, F.; Samson, Y.; et al. Cognitive Status Predicts Return to Functional Independence After Minor Stroke: A Decision Tree Analysis. Front. Neurol. 2022, 13, 833020.
- Chen, C.Y.; Shih, B.Y.; Chen, Z.S.; Chen, T.H. The exploration of internet marketing strategy by search engine optimization: A critical review and comparison. Afr. J. Bus. Manag. 2011, 5, 4644–4649.
- Aviad, B.; Roy, G. Classification by clustering decision tree-like classifier based on adjusted clusters. Expert Syst. Appl. 2011, 38, 8220–8228.
- Ahishakiye, E.; Taremwa, D.; Omulo, E.O.; Niyonzima, I. Crime prediction using decision tree (J48) classification algorithm. Int. J. Comput. Inf. Technol. 2017, 6, 188–195.
- Saltos, G.; Cocea, M. An exploration of crime prediction using data mining on open data. Int. J. Inf. Technol. Decis. Mak. 2017, 16, 1155–1181.
- Sikder, I.U.; Munakata, T. Application of rough set and decision tree for characterization of premonitory factors of low seismic activity. Expert Syst. Appl. 2009, 36, 102–110.
- Shin, Y.; Kim, T.; Cho, H.; Kang, K.I. A formwork method selection model based on boosted decision trees in tall building construction. Autom. Constr. 2012, 23, 47–54.
- Mataei, B.; Nejad, F.M.; Zakeri, H. Pavement maintenance and rehabilitation optimization based on cloud decision tree. Int. J. Pavement Res. Technol. 2021, 14, 740–750.
- Chen, C.T.; Hung, C.T.; Lin, J.D.; Sung, P.H. Application of a decision tree method with a spatiotemporal object database for pavement maintenance and management. J. Mar. Sci. Technol. 2015, 23, 5.
More
Information
Subjects:
Engineering, Civil
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
639
Revisions:
2 times
(View History)
Update Date:
19 Jul 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No