Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Boris Galitsky | -- | 3673 | 2023-06-30 05:01:00 | | | |
| 2 | Rita Xu | -6 word(s) | 3667 | 2023-06-30 07:21:18 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Galitsky, B.; Ilvovsky, D.; Goldberg, S. Shaped-Charge Learning Architecture for the Human–Machine Teams. Encyclopedia. Available online: https://encyclopedia.pub/entry/46251 (accessed on 26 July 2026).
Galitsky B, Ilvovsky D, Goldberg S. Shaped-Charge Learning Architecture for the Human–Machine Teams. Encyclopedia. Available at: https://encyclopedia.pub/entry/46251. Accessed July 26, 2026.
Galitsky, Boris, Dmitry Ilvovsky, Saveli Goldberg. "Shaped-Charge Learning Architecture for the Human–Machine Teams" Encyclopedia, https://encyclopedia.pub/entry/46251 (accessed July 26, 2026).
Galitsky, B., Ilvovsky, D., & Goldberg, S. (2023, June 30). Shaped-Charge Learning Architecture for the Human–Machine Teams. In Encyclopedia. https://encyclopedia.pub/entry/46251
Galitsky, Boris, et al. "Shaped-Charge Learning Architecture for the Human–Machine Teams." Encyclopedia. Web. 30 June, 2023.
Copy Citation
In spite of great progress in recent years, deep learning (DNN) and transformers have strong limitations for supporting human–machine teams due to a lack of explainability, information on what exactly was generalized, and machinery to be integrated with various reasoning techniques, and weak defense against possible adversarial attacks of opponent team members.
machine-learning support for human–machine teams
deep and nearest-neighbor learning
structural entropy production
1. Examples of Failures of Human–Machine Teams
Team failures represent wasted maximum entropy structure costs and minimum entropy productivity or effectiveness.
In November 2022, Meta (Facebook) gave access to its new language model (LM) called Galactica, intended to help researchers. However, instead of earning the great success that Meta was expecting, Galactica was shut down after three days of intense criticism. A main flaw with Galactica is that it is not able to differentiate true from false facts. Users were receiving fake papers attributed to real authors. For example, Galactica produced Wiki articles about the history of animals in space. Users can identify misrepresentations when they involve entities such as space bears while having difficulties with a subject they may not be familiar with.
The exaggeration of DNN usability is a big problem in the self-driving auto domain. Tesla has been criticized by the Department of Motor Vehicles in California, USA, when it made claims about its autopilot and self-driving features (which are based on DNNs). These claims are believed to be deceptive. Tesla is at risk of having its licenses to operate as a vehicle manufacturer and auto dealer in California revoked. Tesla has also been criticized for how it positions its Advanced Driver Assistance System. One of the main concerns has been the actual names of the systems: Autopilot and Full Self-Driving Capability. Some people believe the names suggest that the systems are autonomous, even though they are only driver-assisted systems.
The field of DNN is especially subject to fake claims as the technology looks magical, but it is hard for a general audience to understand how it works. Many businesses that claim to have developed DNN algorithms for images or texts do not always disclose that human agents are acting behind the scenes. This tradition of hiding human input in DN systems is a known “secret” in the AI business community. MMC Ventures found in 2019 that almost half of all startups claiming to use AI technology are not actually using AI in their products.
Another example of a failure of human–machine teams is in the CRM (customer relationship management) domain, where a subpar performance of a business, such as a call center, is due to faulty ML support. The concept of Distributed Incompetence (DI), opposite to Distributed Knowledge, was discovered [1]. In a business overwhelmed with DI, a team of customer support employees is managed in a way that, being rational, impresses a customer but with total irrationality and incompetence and a lack of capability to get things done. In most cases, the whole business or a particular team member gains from DI by means of refusing monetary compensation to customers who received faulty products or services. DI has been identified in a variety of organizations, and its commonality, together with specific DI features, has been analyzed. A DI rate has been assessed in financial organizations, and a solution to tackle it based on conversational AI has been proposed.
Distributed Incompetence is frequently connected with misrepresentations. When a team is eager to achieve a goal, it can ignore rationality by dissembling and lying. In most cases, such a team lacks competence in what they attempt to do. Nonetheless, team members intensely try to convince their peers of the opposite. This is aggressive Distributed Incompetence.
There have always been impressive stories of lies and deceit, tales about founders sharing partial truths about how their companies were founded and which products were developed, and CEOs exaggerating the features of their products to mislead an audience. Some CEOs misrepresent the number of users (such as Twitter); some provide misrepresentations to Congress concerning privacy issues, assuring they have full control over the personal data of their users (Facebook). One of the most striking stories is that of Elizabeth Holmes, the founder of Theranos, who developed blood test technology [2].
Over the last half-decade, the first and second authors leveraged Theranos’ texts as a dataset for argumentation analysis. Texts from the Wall Street Journal with claims that the company’s conduct was fraudulent were subjected to discourse analysis. The authors were developing argumentation mining and reasoning algorithms [3] witnessing the Theranos story, and obtaining content from the Theranos website. A part of the audience believed that the case was initiated by Theranos’ competitors, who felt threatened by the proposed blood test technique of Theranos.
2. Limitations of Stand-Alone DNN
AI in general and DNN in particular are important in our lives, having made a huge impact in a broad range of domains, including medical imaging, process controls, navigation, and language modeling. Carefully designed feature engineering used in traditional ML, such as classification and pattern recognition systems, is not always scalable for complex problem domains and big data. In many domains, depending on how sophisticated the task is, DNN can outperform shallow neural networks that prevented fast training and building hierarchical models of complex training data [4]. However, DNNs have strong limitations in human–machine environments in comparison with traditional logical AI.
In general, any task that requires reasoning (including software development programming, leveraging the scientific method, or planning and algorithmic data processing) is beyond the DNN skillset. Even learning a sorting algorithm is extremely difficult for DNN since it is a chain of continuous topological transformations of one representation space into another. DNNs are capable of mapping one data representation, D1, into another data representation, D2, if a learnable continuous transformation from D1 to D2 exists and if having the training data in D1–D2 format is available. Although a DNN model can be viewed as a sequence of instructions, most programs cannot be encoded as DNNs. For most problems, either a respective reasonably sized DNN that solves the task does not exist, or even if it does exist, it may not be learnable, i.e., encoded topological transformations may be overly complex, or there may be a lack of data to train it [5].
Boosting current DNN architectures by forming additional layers and involving a higher amount of training data can only superficially alleviate some of these limitations. Scaling up DNNs is not expected to solve the essential limitation of the DNNs that are limited in what they can represent and that most of the algorithms that need to be learned cannot be expressed as a continuous topological transformation. Although DNNs are good at image recognition, machine translation, and malware detection, their use is often critiqued for their lack of robustness in adversarial settings and a lack of capability to back up their predictions.
One of the risks of neural AI is that of misinterpreting what DNN models do and overestimating their abilities. A fundamental feature of the human mind is the “theory of mind”, the human ability to reason about intentions, beliefs, and knowledge of subjects in the real world and themselves (introspection). Applied to a DNN, this is interpreted that when a model is trained to generate captions to describe pictures, researchers expect this model to “understand” the contents of the pictures, as well as the captions it generates. “Understanding” here is, in a sense, mapping the real world into a symbolic representation of it. DNN users are then astonished when any deviation from the type of images in the training dataset leads a DNN to yield meaningless text for images.
Researchers now enumerate the limitations of DNN confirmed by an expert community [6] and how the shaped-charge approach can overcome them:
Representation of the environment. An insufficient capability exists to form representations of the real world with a high level of generality to allow easy and efficient manipulation of representations. Researchers will apply Inductive Logic Programming when/if users request an explicit generalization result. For question answering, researchers will show syntactic and semantic generalizations as a measure of answer relevance.
Abstract concept formulation. A limited ability to comprehend, manipulate, and formulate abstract concepts to reduce the high dimension of a stimulus or express the meaning of an NL expression. The integration of a DNN with a formal concept analysis [7] in chatbot dialogue management helped to alleviate this shortcoming.
Causal links. A limited ability to identify the causal direction in which features lead to which other features and a lack of skill in the generalization of learned causal relations. Combining induction and deduction is essential to reason causal relationships; these relationships are also essential to team collaboration.
Meta-reasoning and meta-learning. Limited acquisition skills in how to learn and how to introspect. These are reflected by difficulties in selecting which algorithmic adaptation learns optimally in each domain-specific learning task, leveraging the meta-data about the learning tasks.
DNN systems do not really “understand” their input, in any sense, from the human standpoint. Human representation of images, sounds, and language, as well as tactile feeling, is grounded in the sensory experience of humans [5]. ML is unable to rely on “human sensor” experiences and thus cannot “understand” its inputs. By digesting large numbers of training examples, DNNs learn a topological transformation that maps data to human concepts for this specific set of examples. However, this topological mapping is just an approximation of the original model in human minds, yielding from human experience as embodied agents (Figure 1). Hence, it is necessary to wrap a DNN by some formalization of human sense.
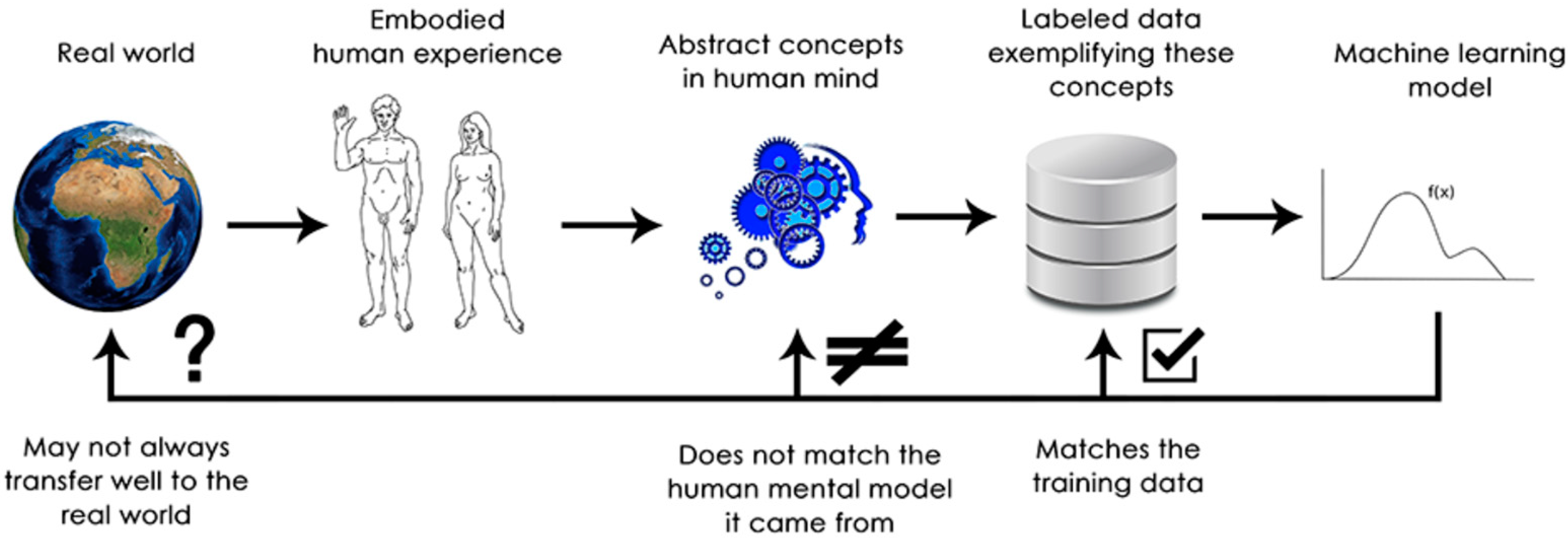
Figure 1. Approximation of the real world with DNN and human cognition.
DNNs are often criticized for their poor performance in adversarial settings and a lack of skills to make predictions rationally. Papernot and McDaniel [8] leverage the DNN structure to improve learning-based reasoning and achieve robust and interpretable decision methodologies. The authors introduce the Deep k-Nearest Neighbors that combine the kNN with data distribution learned by each DNN layer. A test input is matched with its neighboring training samples with respect to the distance between these samples in the DNN layer representations. Ref. [8] demonstrate that the confidence estimates of the labels of these points obtained by kNN can be made outside the training set’s vicinity. A kNN is used to estimate a lack of support for a prediction in the training data. Confidence levels can also be computed for malicious inputs such as adversarial examples; this assures stability in performance with respect to inputs that are outside the DNN “understanding”. A kNN component also supports human-interpretable explanations of predictions. Papernot and McDaniel apply the Deep k-Nearest Neighbors algorithm to several datasets to demonstrate that the confidence estimates properly compute inputs outside the training dataset. Explanations produced by a kNN are comprehensive and assist in handling DNN failures.
Analogical reasoning is another domain essential for team support. DNN can imitate it only when somewhat similar reasoning chains are available for training. As a result, when asked the same ‘free fall’ or ‘ice in the water’ question, GPT-3 returns the wrong answer: “The heavier object will fall faster”. Due to their lack of grounded reasoning, current LMs also have issues with truthfulness [9] and factuality [10], which researchers addressed in the earlier studies [11].
3. Limitations of Stand-Alone Inductive Learning
In comparison to most ML approaches, Inductive Logic Programming has several advantages, primarily by being able to generalize from a small number of samples, sometimes even from a single example. Given a set of clauses for a target predicate and background knowledge, the ILP problem is formulated as an induction of a hypothesis that correctly generalizes the available examples with the background knowledge. A key characteristic of ILP is that it contains the samples, background knowledge, and hypotheses as logic programs. These programs include sets of logical rules in the form of clauses. The feature of an ML system to have team members review generalizations is essential for successful applications. Because hypotheses are logic programs, they can be read by humans, which is essential for explainable AI. Being symbolic systems, ILP naturally supports lifelong transfer learning [12] and learning for team support.
The fundamental limitation of ILP is a slow search in the extended space of a hypothesis. One possibility is to use a set covering algorithm to acquire the hypothesis one clause at a time. Such algorithms are often efficient because they are based on examples [13]. However, these ILP approaches sometimes over-generalize; they learn overly specific solutions and experience difficulties learning programs with nontrivial flows that are recursive [14]. An ILP would benefit from control at the meta-level of how deeply generalized clauses are and which clause structures to maintain. Researchers will apply such a meta-level control to a DNN and a kNN/ILP working together.
Another approach is to encode the ILP as answer set programming. Such algorithms frequently acquire optimal and recursive programs efficiently and serve as a basis for state-of-the-art answer set programming solvers but are limited in performance in large domains with extensive background knowledge [15].
4. A Promise of Hybrid Architecture
Due to the success of DNNs, one of the main integrated techniques is to combine them with logical reasoning, which is called neuro-symbolic computation [16][17]. The main goal is to establish a unified framework that can make flexible approximations using DNNs and perform tractable and multi-hop reasoning using first-order logic. Such a framework is based on a sequential DNN → kNN hybrid controlled in meta-language.
Inductive Logic Programming (ILP) [18] is a sound formalization for finding theories from given examples using first-order logic as its language [19]. Ref. [20] introduce an approach from the ILP family called “learning from failures” where a problem is split into three separate stages: generate, verify, and constrain. In the generate stage, the learner generates a hypothesis (a logic program) that satisfies a set of syntactic constraints. In the verify stage, ILP verifies how training examples satisfy the hypothesis. A failure of the hypothesis means that it does not yield all of the desired positive examples or it yields a negative example. In the case of a hypothesis failure, at the constraint stage, ILP acquires hypothesis constraints from the failed hypothesis to reduce the hypothesis space. Such a reduction constrains the hypothesis to be generated in further iterations.
ILP algorithms use syntactic bias, which forces syntax constraints on hypotheses, such as the number of variables allowed in a clause, and also semantic bias, which reduces the number of hypotheses based on their semantics, such as whether they are irreflexive or functional.
Metarules control syntactic bias used by many ILP approaches [21], including Metagol and ∂ILP [22]. A metarule is a higher-order clause that defines the exact form of clauses in the hypothesis space in an ILP and defines the learning configuration for an arbitrary learner, such as a DNN. For instance, the chain metarule is of the form l(A,B) ← m(A,C),n(C,B), where l, m, and n are predicates, A, B, and C denote predicate variables, and the result allows for instantiated clauses such as final_processing_step(A,B):- reorder(A,C), first_processing_step(C,B). A human team member must either supply a set of metarules or rely on a set of metarules constrained to a specific fragment of logic, such as dyadic Datalog [23] for ILP.
One implementation of shaped-charge ML is question answering based on a neural machine-learning subsystem, first followed by a syntactic match with a candidate answer. Another architecture is a transformer-based content generation that is corrected by a web mining fact-checking component.
A boost of performance in large language models can be facilitated by one of the following approaches:
- (1)
-
Increasing the size of the models in both depth and width;
- (2)
-
Enlarging the number of tokens that the model was trained on;
- (3)
-
Building cleaner datasets from more diverse sources;
- (4)
-
Improving model capacity through sparsely activated modules.
These improvements include maintaining the size of a model and token set, corpus consistency, and completeness, as well as sparse model activation, which can be assessed and controlled from the meta-level. Instead of intervening by a team member, these responsibilities are automated in the form of meta-rules.
Combining DNN and explainable ML approaches, which both implement gradient descent [22], addresses a DNN’s lack of explainability of predictions and assures a “smooth” transition from the former to the latter in the course of a prediction session. The knowledge that deep networks are effectively path kernel machines can significantly improve interpretability. The weights of synaptic connections in a DNN have a direct interpretation as a superposition of the training samples in a gradient space, where each sample can be mapped into the corresponding gradient of the model. Combining deep and nearest-neighbor learning under the single gradient descent umbrella leverages both the high-level performance of the former and the interpretability of the latter. Moreover, a meta-learning control automates routines associated with feature and training datasets engineering.
Evans and Grefenstette [22] proposed Differentiable Inductive Logic Programming (∂ILP), which is an environment for building logic programs from given samples relying on differentiation. The ∂ILP framework reduces an ILP to an optimization process that can be solved via gradient descent. Its differentiability establishes a promising merge of ILP and neural networks to deal with sub-symbolic and noisy data.
There are the following bottlenecks for learning complex programs and structured data:
- (1)
-
The number of clauses grows;
- (2)
-
A high number of ground atoms can be generated with function symbols;
- (3)
-
As the search space grows, the computational costs and space required increase quadratically.
Shindo et al. (2021) [24] resolve these issues by proposing a new differentiable algorithm for acquiring logic programs that merge adaptive symbolic search and continuous optimization methods.
Hence, shaped-charge learning functions as follows: a kNN completes an operational DNN, and meta-reasoning controls them both by verifying and correcting. DNN models and kNN cases are domain-specific, but meta-reasoning is not. Meta-reasoning controls active learning, the current dataset, generalizes cases of failure of object level, decides which ontologies to involve, and controls how the whole ML agent communicates with its peers. Explanation chain rules are also parts of the meta-level, along with rules extracted by an ILP.
The contribution of shaped-charge learning in comparison with other hybrid DNN + logical architectures is as follows:
- (1)
-
Researchers rely on kNN for explainability as it is the most simple and intuitive representation of learning via similarity, applicable for both metric learning spaces and structures. For structured learning, similarity is defined as a cardinality measure of maximum common substructures such as subtrees (parse trees in linguistic representation).
- (2)
-
While a parallel kNN + DNN configuration has been explored [8], a consecutive DNN → kNN architecture has not, providing a uniform framework for gradient descent in large but unexplainable followed by reduced and explainable subspaces. The gradient descent in the same space for multiple learning methods also assures higher interpretability.
- (3)
-
While hybrid architectures combining unexplainable but efficient traits with explainable but reduced efficiency have been proposed, shaped-charge defines a clear boundary between which method is applied to which part of the dataset at a certain level of granularity.
- (4)
-
While meta-reasoning and meta-learning have been broadly used in ML, the meta-level support of the gradient descent in DNN → kNN allows for better manual feature engineering, handling unbalanced datasets, out-of-distribution data, and guided active learning capabilities. Active learning supported by meta-learning then facilitates fine-tuning.
5. Background Information
K-Nearest Neighbors [25] is a supervised machine learning algorithm used for classification and regression problems. The aim is to find the K-Nearest data points in the training dataset and classify new data points according to the labels of their nearest neighbors. KNN is a non-parametric approach, which means that it does not make any assumptions about the underlying data distribution. KNN is a popular choice for many classification tasks due to its simplicity and ease of implementation. It is based on the assumption that similar data points are more likely to belong to the same class. This assumption is based on the idea of similarity measurement, which is performed using a distance metric such as Euclidean distance. KNN is also a lazy learner, which means that it does not learn a discriminative function from the training data but rather simply stores the training data and uses it as a reference when a new data point is encountered. KNN has several advantages, such as its simplicity and ability to handle large datasets. It is also robust to outliers since they have less of an impact on the average of the k-Nearest Neighbors. In addition, it is non-parametric, which means that it does not make any additional assumptions about the dataset.
Deep Neural Networks (DNNs) are a class of Artificial Neural Networks (ANNs) that are composed of multiple layers of neurons and are used for a variety of applications such as image recognition, speech recognition, natural language processing, and reinforcement learning. DNNs have become increasingly popular due to their ability to model complex nonlinear relationships between inputs and outputs. Unlike traditional ANNs, DNNs are able to learn complex functions through the use of multiple layers of neurons, allowing them to effectively represent complex data. Additionally, DNNs are capable of leveraging large datasets to learn patterns and make predictions.
DNNs have become increasingly popular in the field of natural language processing (NLP) due to their ability to learn complex relationships between words and phrases. DNNs are able to learn word embeddings, which are representations of words that capture their semantic and syntactic information. DNNs have been used in a variety of NLP tasks, such as sentiment analysis, text classification, question answering, and machine translation. DNNs have been shown to outperform traditional methods in these tasks due to their ability to capture complex relationships in data. DNNs have also been used for language modeling, which involves predicting the next word in a sentence. This has been applied to speech recognition systems and has improved their accuracy significantly. In addition, DNNs have been used for text generation, which involves generating new text from a given input. This has been used for applications such as automated summarization, automatic poetry generation, and conversation.
References
- Galitsky, B. Identifying distributed incompetence in an organization. In Human-Machine Shared Contexts; Lawless, W.F., Mittu, R., Sofge, D.A., Eds.; Academic Press: Cambridge, MA, USA, 2020.
- Bilton, N. She Absolutely Has Sociopathic. VanityFair. Tendencies. 2018. Available online: https://www.vanityfair.com/news/2018/06/elizabeth-holmes-is-trying-to-start-a-new-company (accessed on 1 December 2022).
- Galitsky, B. Employing abstract meaning representation to lay the last-mile toward reading comprehension. In Artificial Intelligence for Customer Relationship Management; Springer: Berlin/Heidelberg, Germany, 2020; pp. 57–86.
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures; IEEE: Piscataway, NJ, USA, 2019; Volume 7, pp. 53040–53065.
- Chollet, F. The Limitations of Deep Learning. The Keras Blog. 2017. Available online: https://blog.keras.io/the-limitations-of-deep-learning.html (accessed on 1 December 2022).
- Cremer, C.Z. Deep limitations? Examining expert disagreement over deep learning. Prog. Artif. Intell. 2021, 10, 449–464.
- Galitsky, B. Finding a lattice of needles in a haystack: Forming a query from a set of items of interest. In IJCAI; HAL (Open Archive): Lyon, France, 2015; pp. 99–106.
- Papernot, N.; Mcdaniel, P. Deep k-Nearest Neighbors: Towards Confident, Interpretable and Robust Deep Learning. arXiv 2018, arXiv:1803.04765.
- Lin, S.; Hilton, J.; Evans, O. TruthfulQA: Measuring how models mimic human falsehoods. arXiv 2021, arXiv:2109.07958.
- Petroni, F.; Lewis, P.; Piktus, A.; Rockta, T.; Wu, Y.; Alexander; Miller, H.; Riedel, S. How Context Affects Language Models’ Factual Predictions. In Automated Knowledge Base Construction. 2020. Available online: https://openreview.net/forum?id=025X0zPfn (accessed on 1 December 2022).
- Galitsky, B. Improving open domain content generation by text mining and alignment. In Artificial Intelligence for Healthcare Applications and Management; Galitsky, B., Golberg, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2022.
- Lake, B.M.; Ullman, T.D.; Tenenbaum, J.B.; Gershman, S.J. Building machines that earn and think like people. Behav. Brain Sci. 2016, 40, e253.
- Ahlgren, J.; Yuen, S.Y. Efficient program synthesis using constraint satisfaction in inductive logic programming. J. Mach. Learn. Res. 2013, 14, 3649–3682.
- Cropper, A.; Dumančić, S.; Muggleton, S.H. Turning30: New ideas in inductive logic programming. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, Yokohama, Japan, 11–17 July 2020; pp. 4833–4839.
- Kaminski, T.; Eiter, T.; Inoue, K. Exploiting answer set programming with external sources for meta-interpretive learning. Theory Pract. Log. Program. 2018, 18, 571–588.
- De Raedt, L.; Dumancic, S.; Manhaeve, R.; Marra, G. From Statistical Relational to Neuro-Symbolic Artificial Intelligence. In Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI 2020), Yokohama, Japan, 11–17 July 2020; pp. 4943–4950.
- d’Garcez, A.S.; Lamban, L.C.; Gabbay, D.M. Neural-Symbolic Cognitive Reasoning; Cognitive Technologies, Springer: Berlin/Heidelberg, Germany, 2009; ISBN 978-3-540-73245-7.
- Muggleton, S. (Ed.) Inductive Logic Programming; Academic Press: Cambridge, MA, USA, 1992.
- Nienhuys-Cheng, S.-H.; Wolf, R.d.; Siekmann, J.; Carbonell, J.G. Foundations of Inductive Logic Programming; Springer: Berlin/Heidelberg, Germany, 1997.
- Cropper, A.; Morel, R. Learning programs by learning from failures. Mach. Learn. 2021, 110, 801–856.
- Wang, W.Y.; Mazaitis, K.; William; Cohen, W. Structure learning via parameter learning. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, CIKM 2014, Shanghai, China, 3–7 November 2014; pp. 1199–1208.
- Evans, R.; Grefenstette, E. Learning Explanatory Rules from Noisy Data. IJCAI 2018, 5598–5602.
- Cropper, A.; Tourret, S. Logical reduction of metarules. Mach. Learn. 2020, 109, 1323–1369.
- Shindo, H.; Nishino, M.; Yamamoto, A. Differentiable Inductive Logic Programming for Structured Examples. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021.
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties (PDF) (Report); USAF School of Aviation Medicine: Randolph Field, TX, USA, 1951.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
681
Revisions:
2 times
(View History)
Update Date:
30 Jun 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No