Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Ronald Keng'ara Tombe | -- | 2156 | 2023-06-20 10:47:47 | | | |
| 2 | Sirius Huang | + 6 word(s) | 2162 | 2023-06-21 03:24:23 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Tombe, R.; Viriri, S. Remote Sensing Image Feature Learning Approaches. Encyclopedia. Available online: https://encyclopedia.pub/entry/45844 (accessed on 25 June 2026).
Tombe R, Viriri S. Remote Sensing Image Feature Learning Approaches. Encyclopedia. Available at: https://encyclopedia.pub/entry/45844. Accessed June 25, 2026.
Tombe, Ronald, Serestina Viriri. "Remote Sensing Image Feature Learning Approaches" Encyclopedia, https://encyclopedia.pub/entry/45844 (accessed June 25, 2026).
Tombe, R., & Viriri, S. (2023, June 20). Remote Sensing Image Feature Learning Approaches. In Encyclopedia. https://encyclopedia.pub/entry/45844
Tombe, Ronald and Serestina Viriri. "Remote Sensing Image Feature Learning Approaches." Encyclopedia. Web. 20 June, 2023.
Copy Citation
Deep learning approaches are gaining popularity in image feature analysis and in attaining state-of-the-art performances in scene classification of remote sensing imagery. There is an increase of remote sensing datasets with diverse scene semantics; this renders computer vision methods challenging to characterize the scene images for accurate scene classification effectively.
deep learning
computer vision
artificial intelligence
contrastive learning
transformer-based learning
CNNs Feature extraction
geography-aware deep learning
remote sensing
1. Introduction
Remote sensing (RS) is an active research subject in the area of satellite image analysis for the discrete categorization of images into various scene category classes based on image content [1][2][3]. The satellite sensors periodically generate volumes of images that require effective feature processing for various computer vision applications, such as scene labeling [4], feature localization [5], image recognition [6], scene parsing [7], street scene segmentation [8], and many others. Several image feature analysis methods have been developed to this effect. References [2][3] groups the feature analysis methods into three categories: (a) low-level, which focuses on human-engineering skills, (b) medium-level, i.e., unsupervised methods that automatically learn features from images, and (c) high-level, i.e., deep learning methods that rely on supervised learning for feature analysis and representation.
The satellite-generated images vary in texture, shape, color, spectrum information, scale, etc. Additionally, remote sensing images exhibit the following characteristics:
-
Complex spatial arrangements. Remotely sensed images have significant variations in the semantics (for instance, the scene images; of agriculture, airport, commercial areas, and residential areas are typical examples of varying scene image semantics). Extracting the semantic features from images requires effective computer vision techniques.
-
Low inter-class variance. Some scene images are similar (e.g., agriculture and forest, dense residential areas, and residential-area). This characteristic is referred to as low intra-class variance. Achieving accurate scene classification under this circumstance requires well-calibrated computer vision techniques.
-
High intra-class variance. Those same class scene images are commonly taken at varying angles, scales, and viewpoints. This diverse variation of same-class images requires well-designed computer vision approaches that can extract the same pattern features from the remotely sensed images regardless of their variations.
-
Noise: Remotely sensed images are taken under varying atmospheric conditions and at different seasons. The scene images may have variable illumination conditions and require robust feature-learning techniques against varying weather circumstances.
Recent studies have indicated that data-driven deep learning models [2][9][10] attain state-of-the-art results in scene classification owing to their abilities in learning high-level abstract features from images. Developments in hardware for graphic processing units (GPUs) provide the capabilities to process the vast amount of data on deep learning frameworks. Deep learning [11] gives an architecture platform for feature learning methods that comprise several processing steps to learn remote sensing image features at different abstraction levels. Convolutional neural networks (CNNs) are good at abstracting local features and progressively expanding their receptive fields for more abstractions [12]. Transfer-based deep learning models [13][14] work on the premise that fundamental elements of images are the same; thus, they utilize pre-trained models that are trained on large-scale datasets for remote sensing applications. Other studies [15][16] develop models that fuse different CNNs in exploring their performances in scene classification. The application of transfer CNNs pre-trained models for feature extraction in remote sensing is limiting because they need to consider the features of remote sensing images. That is, remote sensing images are unique and vary in terms of background information, imaging angle, and spatial layout, factors that the CNNs pre-training models assume [17]. Successful CNN-based deep learning models in scene classification [9][18], object detection [19], and semantic segmentation [20][21][22][23] were incorporated into remote sensing subject to resolve the classic challenges efficiently since deep learning networks demonstrate to perform better in image classification, object detection, and semantic segmentation jobs.
Transformer-based deep learning methods such as the excellent teacher network guiding small networks (ET-GSNet) [24], and the label-free self-distillation contrastive with transformer architecture (LaST) [25] can learn long-range contextual information. An integration framework [26] combines vision-transformer and CNNs to attain impressive results with remote sensing public datasets. Although deep learning methods attain awe-inspiring results in scene classification and object detection, they must improve to deliver practical and scientific problems. First, deep learning methods rely on available datasets and do not utilize geography knowledge or features, often resulting in inaccurate predictions [27]. Second, lack of sufficient labeled datasets for training deep learning methods to generalize in new geographical regions [28]. Due to these challenges, new research directions in geography-aware deep learning models are emerging [27][28]. This research paradigm fuses knowledge and data in designing deeply blended deep learning models differently. Geography-aware deep learning is an emerging research area in remote sensing, and the research directions in this area include regional knowledge/features, physical knowledge/features, and spatial knowledge/features. The deep learning approaches for fusing geography knowledge and feature are majorly focusing on (1) rule-based, (2) semantic-networks, (3) object-based, (4) physical model-based, and (5) neural network-based [27].
2. Image Feature Learning Approaches
Remote sensing image scene classification aims at annotating scene image patches to a semantic class depending on its contents. Figure 1 puts this concept into perspective. The feature-learning methods can be grouped into three categories: (a) pixel-based scene classification aimed at annotating every pixel to a category; (b) mid-level scene classification focused on identifying objects in remote sensing objects; (c) high-level scene classification, categorizing every remote sensing feature patch into a semantic category.
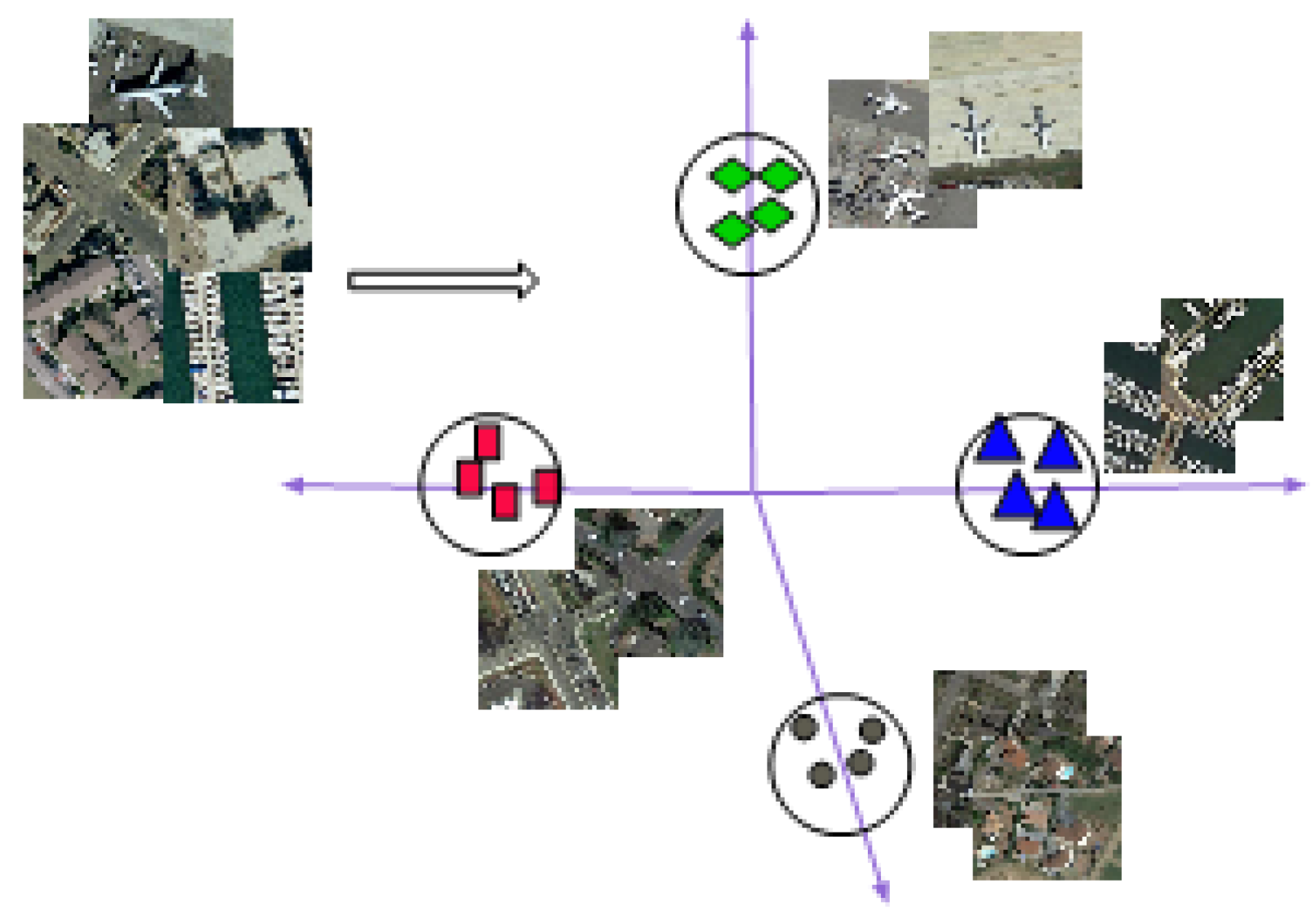
Figure 1. Scene classification of remote sensing images based on their features.
2.1. Pixel-Based Feature Learning Methods
2.1.1. Local Binary Patterns
This method identifies “uniform” local binary patterns (LBP) as critical attributes representing image texture. The uniform local binary patterns apply to generate occurrence histograms powerful for texture-feature representation [29]. LBPs characterize an image using the spatial information of the image texture structure. The LBP is calculated by thresholding neighbor pixels with the center pc pixel to compute an n-bit binary number, which is then converted to decimal as per Equation (1).
where dp=(pc−pi) denotes the difference among center and neighbor (P) pixels describing the spatial structure of the central location with a local difference vector [d0,d1,…,dP−1], LBP then generates a histogram as depicted in Equation (2).
Here m denotes the maximum LBP pattern number.
LBP partitions an image into a fixed-size grid of cells to accomplish the pooling of local texture descriptors. The coarse quantization of spatial features is unrestricted, thus not well turned to the image morphology. This inevitably results in the loss of some discriminative information.
2.1.2. Multi-Scale Completed Local Binary Pattern
The multi-scale completed local binary pattern descriptor (MS-CLBP) [30] combines texture features in multiple scales sufficiently to cope with the limitations of a single-scale with the LBPs. MS-CLBP works similarly to LBP [29] where the circle radius, r, is modified to vary spatial image resolution. Combining operators CLBP_S (S is for sign) and CLBP_M (M is for magnitude) while varying(scale(m) and radius(r)) information parameter values achieves Multi-scale. Technically, this means combining CLBP_S and the CLBP_M histogram features extracted on each scale to form an MS-CLBP descriptor. The MS-CLBP method is applied in remote sensing [30], giving improved results on scene classification compared to LBP.
2.1.3. Distinctive Features Scale-Invariant
The distinctive feature scale-invariant (SIFT) [31] is a prominent descriptor in terms of distinctiveness. A single feature finds its correct match with great probability in a database of features. The SIFT constructs a feature-representation vector in four major steps that include:
-
Scale-space extrema detection: a cascading algorithm identifies candidate points, which are further inspected. Once key candidate locations and scales were established that can be replicated with different views on the same object, the detection of locations follows that are invariant to scale changes of an image through looking for possible features across every probable scale. The Scale-space search algorithm accomplishes the task mentioned above.
-
Localization of keypoint features: This is the process of establishing key candidate features by comparing neighbors to find a precise fit of the nearby data for location and scales of the primary curvatures. Points with low contrast (sensitive to noise) or unsatisfactorily localized along the edges are rejected.
-
Orientation allocation: A consistent assignment is done for every keypoint depending on local image feature attributes in this step. The keypoint descriptor is formulated for orientation; therefore, they are invariant to image rotations. The keypoint descriptors then generate orientation histograms from gradient orientations based on sample points within a region surrounding the keypoint. A histogram contains 36 bins spanning 360 degrees of orientation. The gradient magnitudes determine every sample on the histogram, and a Gaussian-weighted circular window [31]. Dominant directions of local gradients are ’peaks’ of orientation histograms. The highest peak detected in the histogram and other local peaks above 80% of the highest peak apply to generate a key point on an orientation histogram.
-
Local image descriptor: The operations described above, i.e., (detection of scale-space, keypoint localization, and orientation assignment) assigned to an image the (scale, orientation, and location) for each keypoint. These parameters create a repeatable local 2D coordinate system that characterizes the local region of an image, thereby providing an invariant feature descriptor [31]
The experiment results [3] demonstrate that the SIFT method performs poorly when it is used as a low-level-visual feature descriptor on remotely sensed scene images.
2.2. Mid-Level Feature Learning Methods
2.2.1. The Bag of Visual Words
The bag of visual words (BoVWs) is an invariant statistical keypoints feature vector representation [32]. BoVWs quantize the patches generated with either the SIFT or by the LBP feature descriptor methods and then use the k-means algorithm to learn the holistic scene image feature representations [3]. Equation (3) shows the BoVWs workings to generate a histogram of the visual words, i.e., feature representation.
where tm is the occurrence counts of features m contained in an image and M is the feature dictionary size. The BoVWs method is applied to scene classification [2][3] in several datasets, such as (the UC Merced, AID, and RESISC45) where it demonstrates better scene classification accuracy results compared to low-level methods such as the LBP and SIFT.
2.2.2. Fisher Vectors
A Fisher kernel coding framework [33] extends the BoVWs model to characterize the low-level features using a gradient rather than the count statistics in the BoVWs framework. This reduces the codebook size, accelerating the codebook’s learning process. Experimental results by [33] on scene classification show that the Fisher kernel coding framework reduces the computational cost significantly to achieve better scene classification accuracy than methods based on the traditional BOVW model. Previous experiments [2][3] demonstrate this with different remote sensing datasets where the Fisher vector encodes low-level method features for image classification, and it achieves superior performance than traditional BoVWs.
2.3. High-Level Feature Learning Methods
2.3.1. Bag of Convolutional Features
The bag of convolutional feature (BoCF) [34] extracts image features in four stages, i.e., (1) convolution feature extraction, (2) codebook generation, (3) BoCF feature encoding, and (4) scene classification. The BoCFs use CNNs to automatically learn the image features, encoding histogram representations on every image. This is accomplished by quantizing every feature descriptor into visual words in the codebook. A linear classifier is a support vector machine (SVM) that learns the convolutional features fed to it for scene classification.
2.3.2. Adaptive Deep Pyramid Matching
The adaptive deep pyramid matching (ADPM) [35] method considers convolutional features as “multi-resolution deep-feature-representation” of the input image. The ADPM extracts image features of varying scales and then fuses them optimally. The ADPM extracts features from different layers in a deep spatial-pyramid matching manner following Equation (4). Assume Hl,1 and Hl,2 are the histograms of two images at layer l (corresponding to different layer resolution), then, the feature match at layer l is calculated as the histogram intersection with Equation (4)
L is the number of convolution layers, the fusing weight of the lth layer, and =
2.3.3. Deep Salient Feature-Based Anti-Noise Transfer Network (DSFBA-NTN)
This technique comprises two significant steps, 1. deep salient feature (DSF) extraction step, which extracts scene patches utilizing visual-attention mechanisms. In this step, the salient regions and scales are detected from an image [36]. These features feed to a pre-trained CNN model to extract the DSF. In step 2, the anti-noise transfer network suppresses the effects of different scales and noises of scene images. The anti-noise network imposes a constraint to enforce training samples before and after inducing noise to scene images while learning the inputs of original scenes and different noises. The anti-noise network acts as a classifier.
2.3.4. Joint Learning Center Points and Deep Metrics
Conventional deep CNN with the softmax function can hardly distinguish the scene classes with great similarity [37]. To address this problem, the supervised joint-learning with the softmax hinge loss and the center-based organized learning metrics minimize the intra-class variances and maximize the inter-class variances of the remote sensing scene images, which results in better accuracy in scene classification.
References
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756.
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883.
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981.
- Zhou, Q.; Zheng, B.; Zhu, W.; Latecki, L.J. Multi-scale context for scene labeling via flexible segmentation graph. Pattern Recognit. 2016, 59, 312–324.
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 2921–2929.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778.
- Bu, S.; Han, P.; Liu, Z.; Han, J. Scene parsing using inference embedded deep networks. Pattern Recognit. 2016, 59, 188–198.
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-resolution residual networks for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4151–4160.
- Tombe, R.; Viriri, S. Adaptive Deep Co-Occurrence Feature Learning Based on Classifier-Fusion for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 14, 155–164.
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote Sensing Scene Classification Using Convolutional Features and Deep Forest Classifier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948.
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707.
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating Multilayer Features of Convolutional Neural Networks for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665.
- Yuan, B.; Han, L.; Gu, X.; Yan, H. Multi-deep features fusion for high-resolution remote sensing image scene classification. Neural Comput. Appl. 2020, 33, 2047–2063.
- Liu, N.; Wan, L.; Zhang, Y.; Zhou, T.; Huo, H.; Fang, T. Exploiting Convolutional Neural Networks With Deeply Local Description for Remote Sensing Image Classification. IEEE Access 2018, 6, 11215–11228.
- Xu, K.; Huang, H.; Deng, P.; Shi, G. Two-stream feature aggregation deep neural network for scene classification of remote sensing images. Inf. Sci. 2020, 539, 250–268.
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple Yet Effective Fine-Tuning of Deep CNNs Using an Auxiliary Classification Loss for Remote Sensing Scene Classification. Remote Sens. 2019, 11, 2908.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems. Available online: https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html (accessed on 30 December 2022).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241.
- Jing, W.; Zhang, M.; Tian, D. Improved U-Net model for remote sensing image classification method based on distributed storage. J. Real-Time Image Process. 2020, 18, 1607–1619.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495.
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774.
- Xu, K.; Deng, P.; Huang, H. Vision Transformer: An Excellent Teacher for Guiding Small Networks in Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15.
- Wang, X.; Zhu, J.; Yan, Z.; Zhang, Z.; Zhang, Y.; Chen, Y.; Li, H. LaST: Label-Free Self-Distillation Contrastive Learning With Transformer Architecture for Remote Sensing Image Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5.
- Deng, P.; Xu, K.; Huang, H. When CNNs Meet Vision Transformer: A Joint Framework for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5.
- Ge, Y.; Zhang, X.; Atkinson, P.M.; Stein, A.; Li, L. Geoscience-aware deep learning: A new paradigm for remote sensing. Sci. Remote Sens. 2022, 5, 100047.
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-aware self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10181–10190.
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987.
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2015, 10, 745–752.
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110.
- Yang, Y.; Newsam, S. November. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279.
- Zhao, B.; Zhong, Y.; Zhang, L.; Huang, B. The Fisher Kernel Coding Framework for High Spatial Resolution Scene Classification. Remote Sens. 2016, 8, 157.
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote Sensing Image Scene Classification Using Bag of Convolutional Features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739.
- Liu, Q.; Hang, R.; Song, H.; Zhu, F.; Plaza, J.; Plaza, A. Adaptive deep pyramid matching for remote sensing scene classification. arXiv 2016, arXiv:1611.03589.
- Gong, X.; Xie, Z.; Liu, Y.; Shi, X.; Zheng, Z. Deep Salient Feature Based Anti-Noise Transfer Network for Scene Classification of Remote Sensing Imagery. Remote Sens. 2018, 10, 410.
- Gong, Z.; Zhong, P.; Hu, W.; Hua, Y. Joint Learning of the Center Points and Deep Metrics for Land-Use Classification in Remote Sensing. Remote Sens. 2019, 11, 76.
More
Information
Subjects:
Remote Sensing
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
537
Revisions:
2 times
(View History)
Update Date:
21 Jun 2023
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No