 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Taha Adbelhamid Yehia | -- | 3341 | 2023-06-09 17:59:30 | | | |
| 2 | Taha Adbelhamid Yehia | Meta information modification | 3341 | 2023-06-09 18:46:24 | | | | |
| 3 | Sirius Huang | Meta information modification | 3341 | 2023-06-12 04:22:16 | | |
Video Upload Options
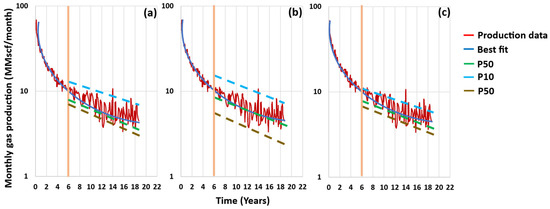
The decline curve analysis (DCA) technique is the simplest, fastest, least computationally demanding, and least data-required reservoir forecasting method. Assuming that the decline rate of the initial production data will continue in the future, the estimated ultimate recovery (EUR) can be determined at the end of the well/reservoir lifetime based on the declining mode. Many empirical DCA models have been developed to match different types of reservoirs as the decline rate varies from one well/reservoir to another. In addition to the uncertainties related to each DCA model’s performance, structure, and reliability, any of them can be used to estimate one deterministic value of the EUR, which, therefore, might be misleading with a bias of over- and/or under-estimation. To reduce the uncertainties related to the DCA, the EUR could be assumed to be within a certain range, with different levels of confidence. Probabilistic decline curve analysis (pDCA) is the method used to generate these confidence intervals (CIs), and many pDCA approaches have been introduced to reduce the uncertainties that come with the deterministic DCA.
1. Introduction
2. pDCA Approaches
2.1. Jochen’s Approach (1996) [10]
2.2. Cheng’s Approach (2010) [11]
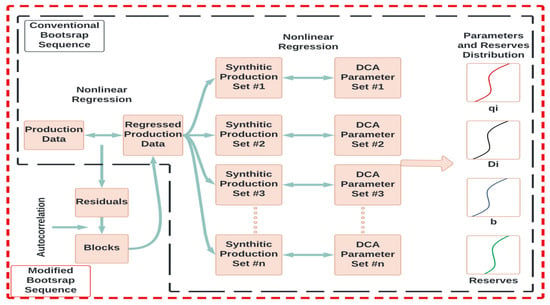
| Jochen’s Approach | Cheng’s Approach |
|---|---|
| Uses bootstrap as a sampling technique | |
| Uses Arps’ models as the DCA model | |
| Assumes no correlation between the data points | Assumes a time-series-data structure |
| Resampled the original data | Resampled the fitted data obtained from a DCA model (Arps) |
| Random samples from the original data are generated | Samples are generated based on autocorrelated residual blocks |
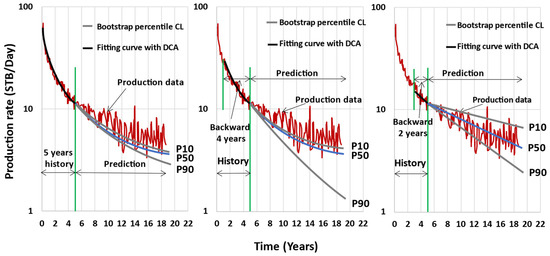
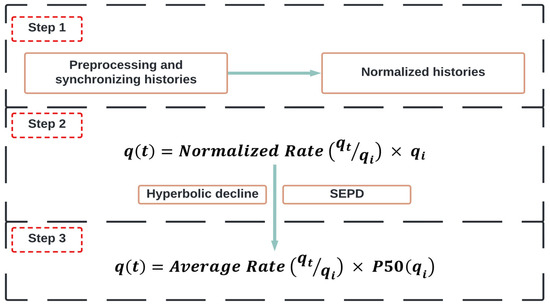
2.3. Minin’s Approach (2011) [13]
2.4. Gong’s Approach (2011) [12]
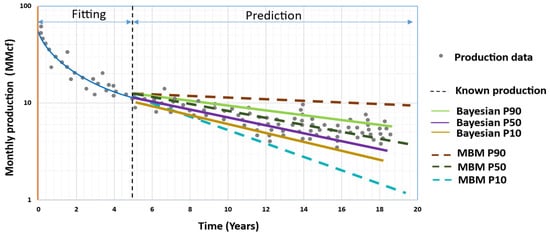
2.5. Brito’s Approach (2012) [14]
2.6. Gonzalez’s Approach (2012) [9]
2.7. Fanchi’s Approach (2013) [16]
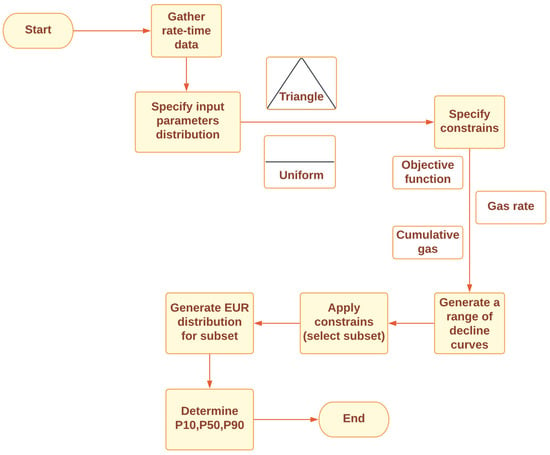
2.8. Kim’s Approach (2014) [17]
2.9. Zhukovsky Approach (2016) [18]
2.10. Paryani’s Approach (2017) [19]
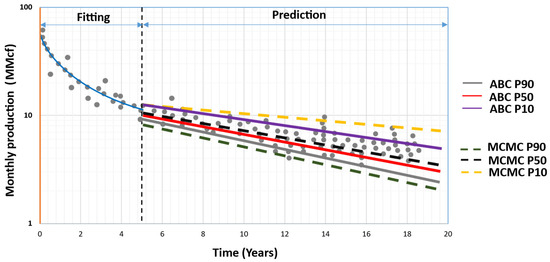
2.11. Jimenez’s Approach (2017) [21]
2.12. Joshi’s Approach (2018) [22]
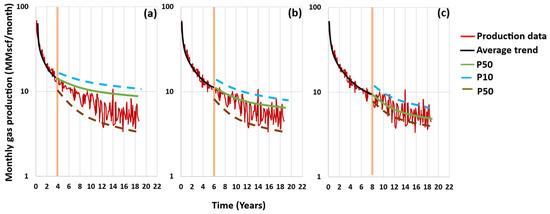
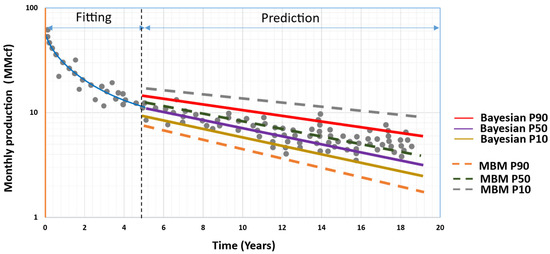
2.13. Hong’s Approach (2019) [23]
2.14. Fanchi’s New Approach (2020) [24]
2.15. Korde’s Approach (2021) [25]
| pDCA Model | Probabilistic Technique | Sampling Technique(s) |
No. of Integrations | Computational Time | Used Probability Distribution |
|---|---|---|---|---|---|
| Jochen (1996) | Frequentist Analysis | MC Bootstrap |
>100 | 6.5 h | - |
| Cheng (2010) | Frequentist Analysis | MC Bootstrap |
More than 6.5 h | - | |
| Minin (2011) | Bayesian Analysis | MC Latin Hypercube |
- | - | Uniform |
| Brito (2012) | Bayesian Analysis | MC | - | - | Uniform |
| Gong (2011) | Bayesian Analysis | MCMC MH |
2000 | 25 min | Approximate posterior |
| Gonzalez (2012) | Bayesian Analysis | MCMC MH |
1000 | 25 min | Approximate posterior |
| Fanchi (2013) | Bayesian Analysis | MC | 1000 | - | Uniform |
| Kim (2014) | Bayesian Analysis | MC | 5000 | - | Triangle |
| Zhukovsky (2016) | Bayesian Analysis | MCMC MH |
100,000 | 25 min | Approximate posterior |
| Paryani (2017) | Bayesian Analysis | MCMC ABC MC ABC Rejection ABC |
10,000 | Faster than Gong (2011) | Likelihood-free approximation |
| Jimenez (2017) | Bayesian Analysis | MC | - | - | Chi-square |
| Joshi (2018) | Frequentist Analysis | Time series | |||
| Hong (2019) | Bayesian Analysis | MC | - | - | Uniform |
| Fanchi (2020) | Bayesian Analysis | MC | 1000 | - | Uniform |
| Korde (2021) | Bayesian Analysis | MCMC Gibbs MH ABC |
20,000 | 5–25 s | Likelihood |
| pDCA Model | The Study Domain | The Combined DCA Model(s) | Reference | ||
| Jochen (1996) | Conventional oil wells, two different fields |
Arps | [10] | ||
| Cheng (2010) | Conventional mature oil and gas wells; 100 wells |
Arps | [11] | ||
| Minin (2011) | Shale gas reservoirs; 150 gas wells |
Arps | [13] | ||
| Brito (2012) | Conventional oil wells | PDE | [14] | ||
| Gong (2011) | Shale gas reservoirs; 197 gas wells |
Arps | [12] | ||
| Gonzalez (2012) | Shale gas reservoirs; 197 gas wells |
Arps, PLE, SEPD, and Duong |
[9] | ||
| Fanchi (2013) | Shale gas reservoirs; 110 gas wells |
Arps and SEPD | [16] | ||
| Kim (2014) | Shale gas reservoirs; 4 gas wells |
Arps, SEPD, and PDE |
[17] | ||
| Zhukovsky Approach (2016) | Shale reservoirs; 199 shale oil wells |
EEDCA | [18] | ||
| Paryani (2017) | Unconventional reservoirs; 21 oil wells (Eagle Ford) and 100 gas wells (Barnett Shale) |
Arps and LGM | [19][20] | ||
| Jimenez Approach (2017) | Tight gas reservoir; 1 gas well |
Arps, SEPD, PLE, LGM, and Duong | [21] | ||
| Joshi Approach (2018) | Shale reservoirs; 100 shale gas wells |
LGM and SEPD | [22] | ||
| Hong (2019) | Unconventional shale oil; Bakken field, 28 wells, and Midland field, 31 wells |
Arps, SEPD, LGM, and Pan | [23] | ||
| Fanchi (2020) | Unconventional shale oil; Bakken field, 9 wells, and Eagle Ford, 6 wells |
Arps and SEPD | [24] | ||
| Korde (2021) | Conventional and unconventional reservoirs; 23 oil wells and 51 gas wells |
Arps, SEPD, PLE, Duong, and LGM | [25] | ||
References
- Liang, H.-B.; Zhang, L.-H.; Zhao, Y.-L.; Zhang, B.-N.; Chang, C.; Chen, M.; Bai, M.-X. Empirical Methods of Decline-Curve Analysis for Shale Gas Reservoirs: Review, Evaluation, and Application. J. Nat. Gas Sci. Eng. 2020, 83, 103531.
- Joshi, K.; Lee, J. Comparison of Various Deterministic Forecasting Techniques in Shale Gas Reservoirs. In Proceedings of the SPE Hydraulic Fracturing Technology Conference, The Woodlands, TX, USA, 4–6 February 2013; OnePetro: Richardson, TX, USA, 2013.
- Yehia, T.; Khattab, H.; Tantawy, M.; Mahgoub, I. Removing the Outlier from the Production Data for the Decline Curve Analysis of Shale Gas Reservoirs: A Comparative Study Using Machine Learning. ACS Omega 2022, doi:10.1021/acsomega.2c03238.
- Chen, Q.; Wang, N.; Ruan, K.; Zhang, M. Selection of Production Decline Analysis Method of Shale Gas Well. Reserv. Eval. Dev. 2018, 8, 76–79.
- Mahmoud, O. Machine Learning Outlier Detection Algorithms for Enhancing Production Data Analysis of Shale Gas Machine Learning Outlier Detection Algorithms for Enhancing Production Data Analysis of Shale Gas. In; 2023; pp. 127–163 ISBN 978-81-19-21749-6. https://doi.org/10.9734/bpi/fraps/v4/6060A
- Yehia, T.; Wahba, A.; Mostafa, S.; Mahmoud, O. Suitability of Different Machine Learning Outlier Detection Algorithms to Improve Shale Gas Production Data for Effective Decline Curve Analysis. Energies 2022, 15, 8835, doi:10.3390/en15238835.
- Yuan, J.; Luo, D.; Feng, L. A Review of the Technical and Economic Evaluation Techniques for Shale Gas Development. Appl. Energy 2015, 148, 49–65.
- Yehia, T.; Khattab, H.; Tantawy, M.; Mahgoub, I. Improving the Shale Gas Production Data Using the Angular- Based Outlier Detector Machine Learning Algorithm. JUSST 2022, 24, 152–172, doi:http://doi.org/10.51201/JUSST/22/08150.
- Gonzalez, R.; Gong, X.; McVay, D. Probabilistic decline curve analysis reliably quantifies uncertainty in shale gas reserves regardless of stage of depletion. In Proceedings of the SPE Eastern Regional Meeting, Lexington, KY, USA, 3–5 October 2012.
- Jochen, V.A.; Spivey, J.P. Probabilistic Reserves Estimation Using Decline Curve Analysis with the Bootstrap Method. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 6 October 1996; OnePetro: Richardson, TX, USA, 1996.
- Cheng, Y.; Wang, Y.; McVay, D.A.A.; Lee, W.J.J. Practical Application of a Probabilistic Approach to Estimate Reserves Using Production Decline Data. SPE Econ. Manag. 2010, 2, 19–31.
- Gong, X.; Gonzalez, R.; McVay, D.A.; Hart, J.D. Bayesian Probabilistic Decline-Curve Analysis Reliably Quantifies Uncertainty in Shale-Well-Production Forecasts. SPE J. 2014, 19, 1047–1057.
- Minin, A.; Guerra, L.; Colombo, I. Unconventional Reservoirs Probabilistic Reserve Estimation Using Decline Curves. In Proceedings of the International Petroleum Technology Conference, Bangkok, Thailand, 15 November 2011; p. IPTC-14801-MS.
- Brito, L.E.; Paz, F.; Belisario, D. Probabilistic Production Forecasts Using Decline Envelopes. In Proceedings of the SPE Latin America and Caribbean Petroleum Engineering Conference, Mexico City, Mexico, 16 April 2012; p. SPE-152392-MS.
- Gong, X.; Gonzalez, R.; McVay, D.; Hart, J. Bayesian Probabilistic Decline Curve Analysis Quantifies Shale Gas Reserves Uncertainty. In Proceedings of the Canadian Unconventional Resources Conference, Calgary, AB, Canada, 15 November 2011; p. SPE-147588-MS.
- Fanchi, J.R.; Cooksey, M.J.; Lehman, K.M.; Smith, A.; Fanchi, A.C.; Fanchi, C.J. Probabilistic Decline Curve Analysis of Barnett, Fayetteville, Haynesville, and Woodford Gas Shales. J. Pet. Sci. Eng. 2013, 109, 308–311.
- Kim, J.-S.; Shin, H.-J.; Lim, J.-S. Application of a Probabilistic Method to the Forecast of Production Rate Using a Decline Curve Analysis of Shale Gas Play. In Proceedings of the Twenty-Fourth International Ocean and Polar Engineering Conference, Busan, Republic of Korea, 15–20 June 2014; p. ISOPE-I-14-158.
- Zhukovsky, I.D.; Mendoza, R.C.; King, M.J.; Lee, W.J. Uncertainty Quantification in the EUR of Eagle Ford Shale Wells Using Probabilistic Decline-Curve Analysis with a Novel Model. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, United Arab Emirates, 7 November 2016; p. D021S049R005.
- Paryani, M. Approximate Bayesian Computation for Probabilistic Decline Curve Analysis in Unconventional Reservoirs. Master’s Thesis, University of Alaska Fairbanks, College, AK, USA, 2015. Available online: https://hdl.handle.net/11122/6383 (accessed on 15 December 2022).
- Paryani, M.; Awoleke, O.O.; Ahmadi, M.; Hanks, C.; Barry, R. Approximate Bayesian Computation for Probabilistic Decline-Curve Analysis in Unconventional Reservoirs. SPE Reserv. Eval. Eng. 2017, 20, 478–485.
- Jiménez, E.T.; Cervantes, R.J.; Magnelli, D.E.; Dabrowski, A. Probabilistic Approach of Advanced Decline Curve Analysis for Tight Gas Reserves Estimation Obtained from Public Data Base. In Proceedings of the SPE Latin America and Caribbean Petroleum Engineering Conference, Buenos Aires, Argentina, 17 May 2017; p. D021S009R006.
- Joshi, K.G.; Awoleke, O.O.; Mohabbat, A. Uncertainty Quantification of Gas Production in the Barnett Shale Using Time Series Analysis. In Proceedings of the SPE Western Regional Meeting, Garden Grove, CA, USA, 22 April 2018; OnePetro: Richardson, TX, USA, 2018.
- Hong, A.; Bratvold, R.B.; Lake, L.W.; Ruiz Maraggi, L.M. Integrating Model Uncertainty in Probabilistic Decline-Curve Analysis for Unconventional-Oil-Production Forecasting. SPE Reserv. Eval. Eng. 2019, 22, 861–876.
- Fanchi, J. Decline Curve Analysis of Shale Oil Production Using a Constrained Monte Carlo Technique. J. Basic Appl. Sci. 2020, 16, 61–67.
- Korde, A.; Goddard, S.D.; Awoleke, O.O. Probabilistic Decline Curve Analysis in the Permian Basin Using Bayesian and Approximate Bayesian Inference. SPE Reserv. Eval. Eng. 2021, 24, 536–551.
- Yehia, T.; Naguib, A.; Abdelhafiz, M.M.; Hegazy, G.M.; Mahmoud, O. Probabilistic Decline Curve Analysis: State-of-the-Art Review. Energies 2023, 16, 4117, doi:10.3390/en16104117.



