 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Camila Xu | -- | 1702 | 2022-11-29 01:31:01 |
Video Upload Options
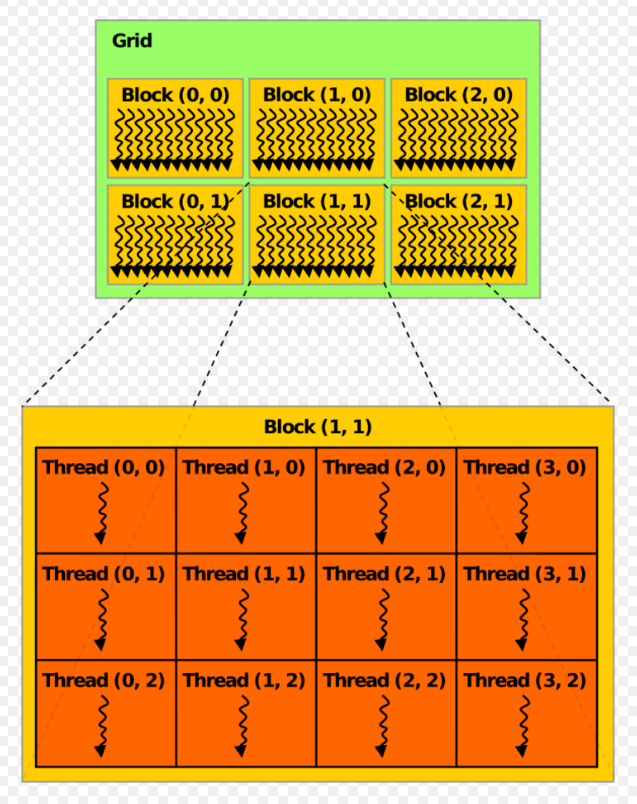
A thread block is a programming abstraction that represents a group of threads that can be executed serially or in parallel. For better process and data mapping, threads are grouped into thread blocks. The number of threads varies with available shared memory. 'The number of threads in a thread block is also limited by the architecture to a total of 512 threads per block.' The threads in the same thread block run on the same stream processor. Threads in the same block can communicate with each other via shared memory, barrier synchronization or other synchronization primitives such as atomic operations. Multiple blocks are combined to form a grid. All the blocks in the same grid contain the same number of threads. Since the number of threads in a block is limited to 512, grids can be used for computations that require a large number of thread blocks to operate in parallel. CUDA is a parallel computing platform and programming model that higher level languages can use to exploit parallelism. In CUDA, the kernel is executed with the aid of threads. The thread is an abstract entity that represents the execution of the kernel. A kernel is a small program or a function. Multi threaded applications use many such threads that are running at the same time, to organize parallel computation. Every thread has an index, which is used for calculating memory address locations and also for taking control decisions.
1. Dimensions
CUDA operates on a heterogeneous programming model which is used to run host device application programs. It has an execution model that is similar to OpenCL. In this model, we start executing an application on the host device which is usually a CPU core. The device is a throughput oriented device, i.e., a GPU core which performs parallel computations. Kernel functions are used to do these parallel executions. Once these kernel functions are executed the control is passed back to the host device that resumes serial execution.
As many parallel applications involve multidimensional data, it is convenient to organize thread blocks into 1D, 2D or 3D arrays of threads. The blocks in a grid must be able to be executed independently, as communication or cooperation between blocks in a grid is not possible. 'When a kernel is launched the number of threads per thread block, and the number of thread blocks is specified, this, in turn, defines the total number of CUDA threads launched.[1]' The maximum x, y and z dimensions of a block are 512, 512 and 64, and it should be allocated such that x × y × z ≤ 512, which is the maximum number of threads per block.[1] Blocks can be organized into one- or two-dimensional grids of up to 65,535 blocks in each dimension.[1] The limitation on the number of blocks in a thread is actually imposed because the number of registers that can be allocated across all threads is limited.[1]
2. Indexing
2.1. 1D-Indexing
Every thread in CUDA is associated with a particular index so that in can calculate and access memory locations in an array.
Consider an example in which there is an array of 512 elements. One of the organization structure is taking a grid with a single block that has a 512 threads. Consider that there is an array C of 512 elements that is made of element wise multiplication of two arrays A and B which are both 512 elements each. Every thread has an index i and it performs the multiplication of ith element of A and B and then store the result in the ith element of C. i is calculated by using blockIdx (which is 0 in this case as there is only one block), blockDim (512 in this case as the block has 512 elements) and threadIdx that varies from 0 to 511 for each block.
The thread index i is calculated by the following formula :
[math]\displaystyle{ i = blockIdx.x * blockDim.x + threadIdx.x }[/math]
blockIdx.x is the x dimension block identifier
blockDim.x is the x dimension of the block dimension
threadIdx.x is the x dimension of the thread identifier
Thus ‘i’ will have values ranging from 0 to 511 that covers the entire array.
If we want to consider computations for an array that is larger than 512 we can have multiple blocks with 512 threads each. Let us consider an example with 1024 array elements. In this case we have 2 thread blocks with 512 threads each. Thus the thread identifiers' values will vary from 0 to 511, the block identifier will vary from 0 to 1 and the block dimension will be 512. Thus the first block will get index values from 0 to 511 and the last one will have index values from 512 to 1023.
Thus each thread will first calculate the index of memory that it has to access and then proceed with the calculation. Consider an example in which elements from arrays A and B are added in parallel by using threads and the results is stored in an array C. The corresponding code in a thread is shown below :[3]
__global__ void vecAddKernel (float *A , float *B , float * C , int n) { int index = blockIdx.x * blockDim.x + threadIdx.x ; if( index < n ) { C[index] = A[index] + B[index] ; } }
2.2. 2D-Indexing
In the same way in particularly complex grids, the blockId as well as the threadId need to be calculated by each thread depending on geometry of the grid. Consider, a 2-dimensional Grid with 2-dimensional blocks. The threadId and the blockId will be calculated by the following formulae :
[math]\displaystyle{ blockId = blockIdx.x + blockIdx.y * gridDim.x; }[/math] [math]\displaystyle{ threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; }[/math][4]
3. Hardware Perspective
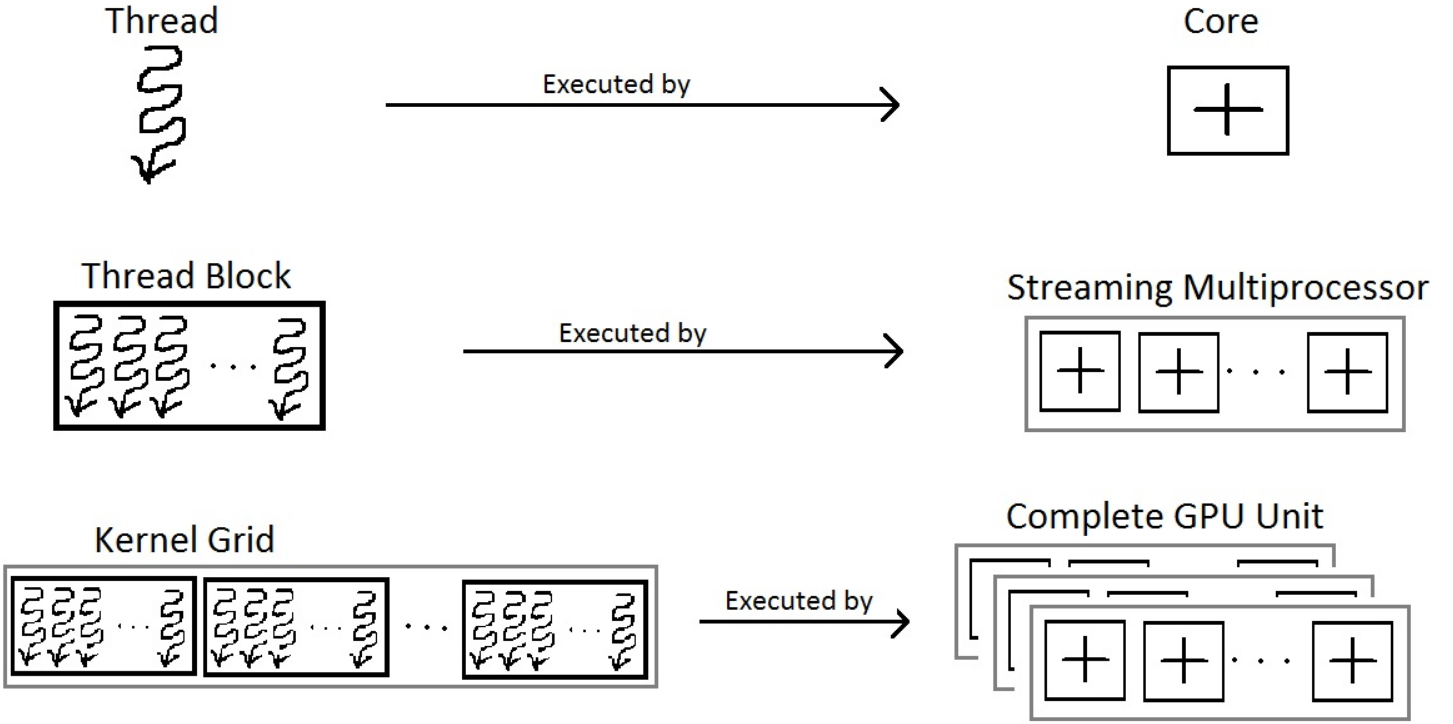
Although we have stated the hierarchy of threads, we should note that, threads, thread blocks and grid are essentially a programmer’s perspective. In order to get a complete gist of thread block, it is critical to know it from a hardware perspective. Hardware groups threads that execute the same instruction in to warps. Several warps constitute a thread block. Several thread blocks are assigned to a Streaming Multiprocessor (SM). Several SM constitute the whole GPU unit (which executes the whole Kernel Grid).
3.1. Streaming Multiprocessors
Each architecture in GPU (say Kepler or Fermi) consists of several SM or Streaming Multiprocessors. These are general purpose processors with a low clock rate target and a small cache. The primary task of an SM is that it must execute several thread blocks in parallel. As soon as one of its thread block has completed execution, it takes up the serially next thread block. In general, SMs support instruction-level parallelism but not branch prediction.[6]
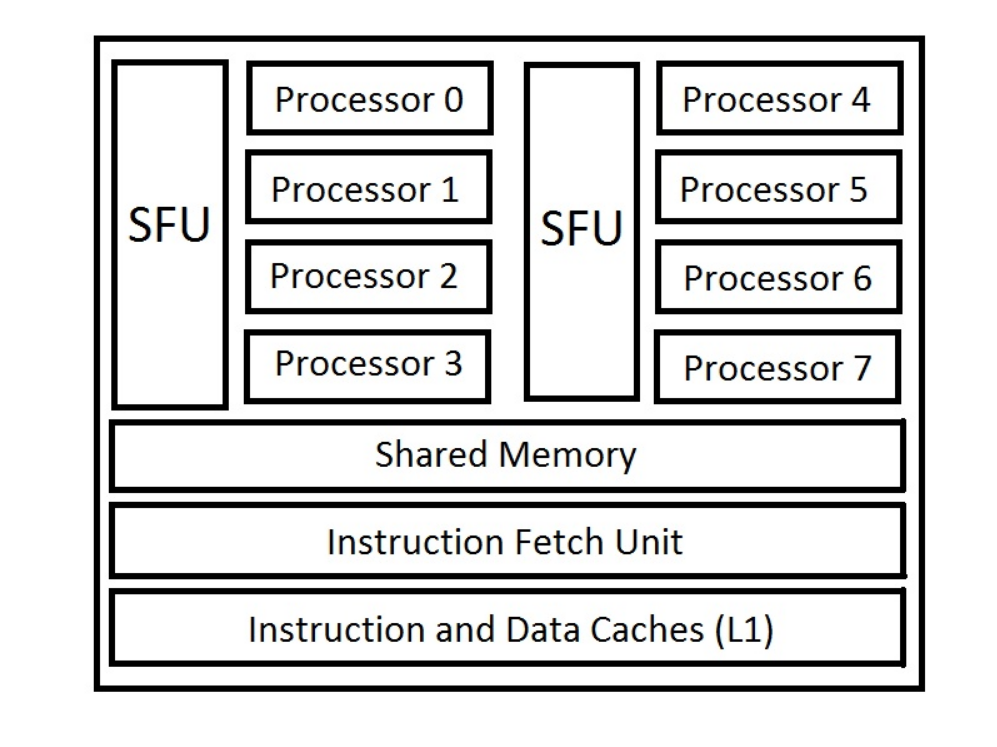
To achieve this purpose, an SM contains the following:[6]
- Execution cores. (single precision floating-point units, double precision floating-point units, special function units (SFUs)).
- Caches:
- L1 cache. (for reducing memory access latency).
- Shared memory. (for shared data between threads).
- Constant cache (for broadcasting of reads from a read-only memory).
- Texture cache. (for aggregating bandwidth from texture memory).
- Schedulers for warps. (these are for issuing instructions to warps based on a particular scheduling policies).
- A substantial number of registers. (an SM may be running a large number of active threads at a time, so it is a must to have registers in thousands.)
The hardware schedules thread blocks to an SM. In general an SM can handle multiple thread blocks at the same time. An SM may contains up to 8 thread blocks in total. A thread ID is assigned to a thread by its respective SM.
Whenever an SM executes a thread block, all the threads inside the thread block are executed at the same time. Hence to free a memory of a thread block inside the SM, it is critical that the entire set of threads in the block have concluded execution. Each thread block is divided in scheduled units known as a warp. These are discussed in detail in the following section.
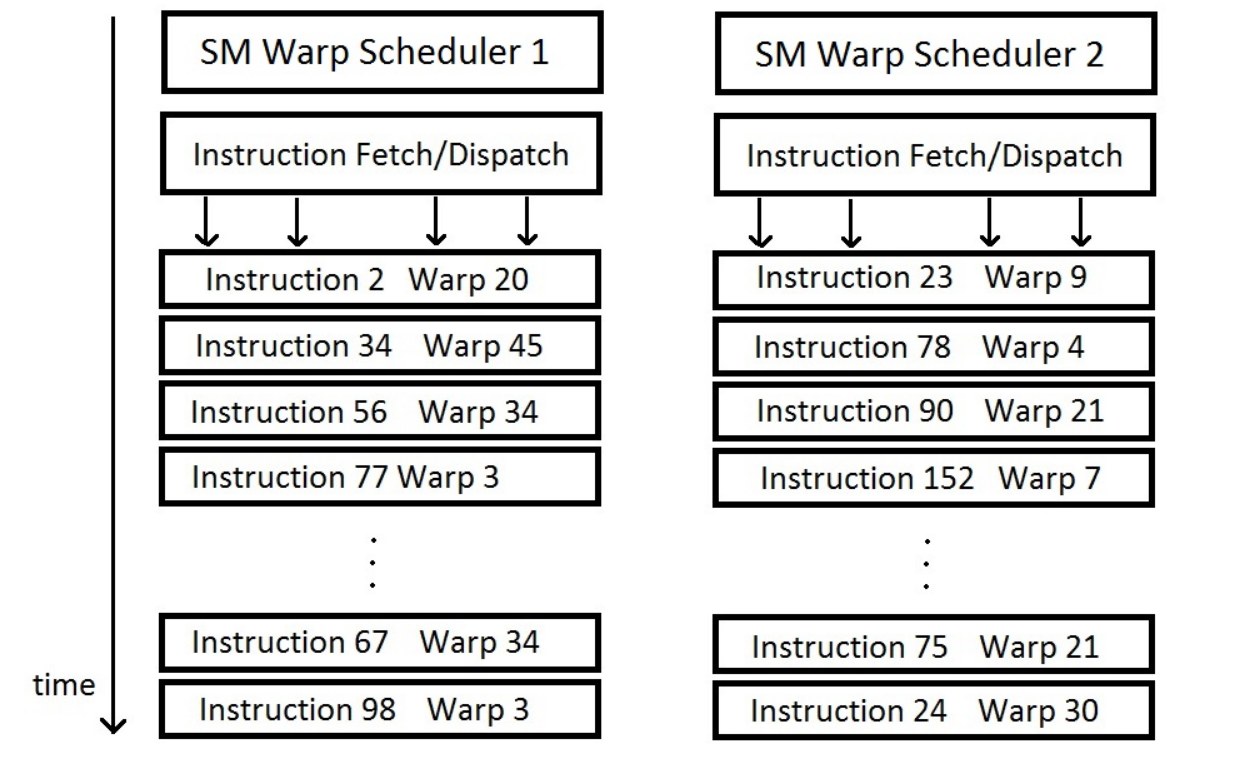
The warp scheduler of SM decides which of the warp gets prioritized during issuance of instructions.[9]
Some of the warp prioritizing policies have also been discussed in the following sections.
3.2. Warps
On the hardware side, a thread block is composed of ‘warps’. A warp is a set of 32 threads within a thread block such that all the threads in a warp execute the same instruction. These threads are selected serially by the SM.
Consider a warp of 32 threads executing an instruction. If one or both of its operands are not ready, a process called ‘context switching’ takes place which transfers control to another warp.[10] When an instruction has no data dependencies, that is, both of its operands are ready, the respective warp is considered to be ready for execution. If more than one warps are eligible for execution, the parent SM uses a warp scheduling policy for deciding which warp gets the next fetched instruction.
Different policies for scheduling warps that are eligible for execution are discussed below:[11]
- Round Robin (RR) - Instructions are fetched in round robin manner. RR makes sure - SMs are kept busy and no clock cycles are wasted on memory latencies.
- Least Recently Fetched (LRF) - In this policy, warp for which instruction has not been fetched for the longest time gets priority in the fetching of an instruction.
- Fair (FAIR)[11] - In this policy, the scheduler makes sure all warps are given ‘fair’ opportunity in the number of instruction fetched for them. It fetched instruction to a warp for which minimum number of instructions have been fetched.
- Thread block-based CAWS[12] (criticality aware warp scheduling) - The emphasis of this scheduling policy is on improving the execution time of the thread blocks. It allocated more time resources to the warp that shall take the longest time to execute. By giving priority to the most critical warp, this policy allows thread blocks to finish faster, such that the resources become available quicker.
References
- "CUDA Thread Model". https://www.olcf.ornl.gov/kb_articles/cuda-thread-model/.
- "Thread Hierarchy in CUDA Programming". http://cuda-programming.blogspot.com/2012/12/thread-hierarchy-in-cuda-programming.html.
- Kirk, David; Hwu, Wen-mei W (January 28, 2010). Programming Massively Parallel Processors: A Hands-on Approach.
- "Thread Indexing Cheatsheet". https://cs.calvin.edu/courses/cs/374/CUDA/CUDA-Thread-Indexing-Cheatsheet.pdf.
- "Thread Optimizations (University of Mayland)". http://www.umiacs.umd.edu/~ramani/cmsc828e_gpusci/lecture9.pdf.
- Wilt, Nicholas (2013). The CUDA Handbook: A Comprehensive Guide to GPU Programming.
- "Thread Optimizations (University of Mayland)". http://www.umiacs.umd.edu/~ramani/cmsc828e_gpusci/lecture9.pdf.
- "Thread Optimizations (University of Mayland)". http://www.umiacs.umd.edu/~ramani/cmsc828e_gpusci/lecture9.pdf.
- "GPU Computing with CUDA Lecture 2 - CUDA Memories". http://www.bu.edu/pasi/files/2011/07/Lecture2.pdf.
- "Memory Issues in CUDA and Execution Scheduling in CUDA". http://sbel.wisc.edu/Courses/ME964/2012/Lectures/lecture0223.pdf.
- "Effect of Instruction Fetch and Memory Scheduling on GPU Performance". http://www.cc.gatech.edu/fac/hyesoon/gputhread.pdf.
- "CAWS: Criticality-Aware Warp Scheduling for GPGPU Workloads". http://faculty.engineering.asu.edu/carolewu/wp-content/uploads/2012/12/PACT14_CAWS_Lee_final.pdf.

