 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Sirius Huang | -- | 1354 | 2022-11-28 01:38:53 |
Video Upload Options
The European Nucleotide Archive (ENA) is a repository providing free and unrestricted access to annotated DNA and RNA sequences. It also stores complementary information such as experimental procedures, details of sequence assembly and other metadata related to sequencing projects. The archive is composed of three main databases: the Sequence Read Archive, the Trace Archive and the EMBL Nucleotide Sequence Database (also known as EMBL-bank). The ENA is produced and maintained by the European Bioinformatics Institute and is a member of the International Nucleotide Sequence Database Collaboration (INSDC) along with the DNA Data Bank of Japan and GenBank. The ENA has grown out of the EMBL Data Library which was released in 1982 as the first internationally supported resource for nucleotide sequence data. As of early 2012, the ENA and other INSDC member databases each contained complete genomes of 5,682 organisms and sequence data for almost 700,000. Moreover, the volume of data is increasing exponentially with a doubling time of approximately 10 months.
1. History
The European Nucleotide Archive originated from separate databases, the earliest of which was the EMBL Data Library, established in October 1980 at the European Molecular Biology Laboratory (EMBL), Heidelberg.[1] The first release of this database was made in April 1982 and contained a total of 568 separate entries consisting of around 500,000 base pairs.[2] In 1984, referring to the EMBL Data Library, Kneale and Kennard remarked that "it was clear some years ago that a large computerized database of sequences would be essential for research in Molecular Biology".[2]

Despite the primary distribution method at the time being via magnetic tape, by 1987, the EMBL Data Library was being used by an estimated 10,000 scientists internationally.[3] The same year, the EMBL File Server was introduced to serve database records over BITNET, EARN and the early Internet.[4] In May 1988 the journal Nucleic Acids Research introduced a policy stating that "manuscripts submitted to [Nucleic Acids Research] and containing or discussing sequence data must be accompanied by evidence that the data have been deposited with the EMBL Data Library."[5]

During the 1990s the EMBL Data Library was renamed the EMBL Nucleotide Sequence Database[6] and was formally relocated to the European Bioinformatics Institute (EBI) from Heidelberg.[7] In 2003, the Nucleotide Sequence Database was extended with the addition of the Sequence Version Archive (SVA), which maintains records of all current and previous entries in the database.[8] A year later in June 2004, limits on the maximum sequence length for each record (then 350 kilobases) were removed, allowing entire genome sequences to be stored as a single database entry.[9]
Following the uptake of Sanger sequencing, the Wellcome Trust Sanger Institute (then known as The Sanger Centre) had begun cataloguing sequence reads along with quality information in a database called The Trace Archive.[10] The Trace Archive grew substantially with the commercialisation of high-throughput parallel sequencing technologies by companies such as Roche and Illumina.[11] In 2008, the EBI combined the Trace Archive, EMBL Nucleotide Sequence Database (now also known as EMBL-Bank)[12] and a newly developed Sequence (or Short) Read Archive (SRA) to make up the ENA, aimed at providing a comprehensive nucleotide sequence archive.[10] As a member of the International Nucleotide Sequence Database Collaboration, the ENA exchanges data submissions each day with both the DNA Data Bank of Japan and GenBank.[13]
2. EMBL Nucleotide Sequence Database
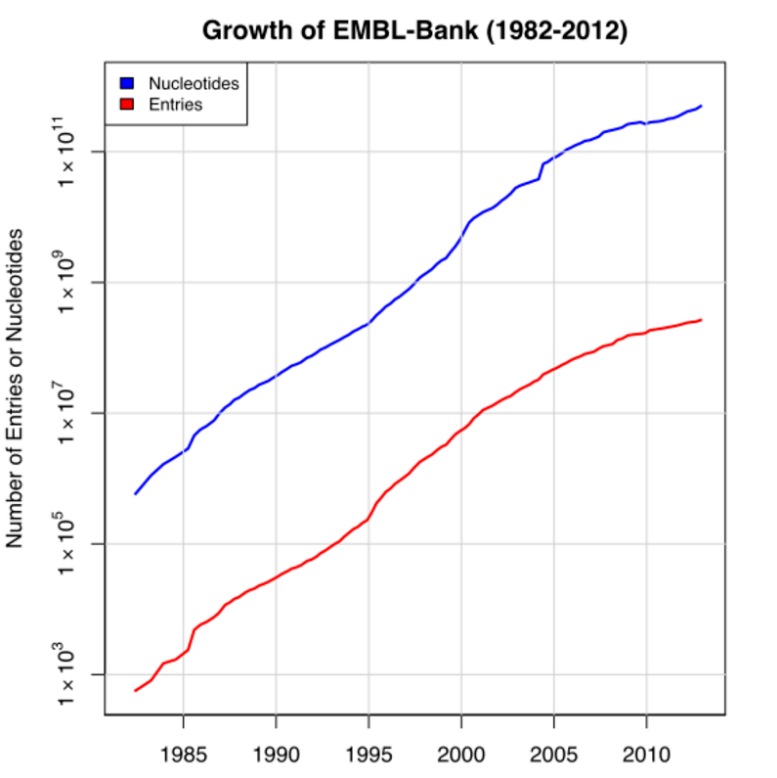
The EMBL Nucleotide Sequence Database (also known as EMBL-Bank) is the section of the ENA which contains high-level genome assembly details, as well as assembled sequences and their functional annotation.[9][15] EMBL-Bank is contributed to by direct submission from genome consortia and smaller research groups as well as by the retrieval of sequence data associated with patent applications.[12][16]
As of release 114 (December 2012), the EMBL Nucleotide Sequence Database contains approximately 5×1011 nucleotides with an uncompressed filesize of 1.6 terabytes.[14]
2.1. Data Classes
The EMBL Nucleotide Sequence Database supports a variety of data derived from different sources including, but not limited to:[17]
- Expressed sequence tags with their associated sample data.
- Nucleotide sequence being generated from whole genome sequencing projects at varying stages of assembly, including complete contigs and annotated, fully assembled sequence.
- Data relating to transcriptomics, such as complementary DNA, with optional annotation.
- Novel or extended annotations of existing coding sequences, for example new sequence versions with corrected start or stop codons.
2.2. EMBL-Bank Format
The EMBL Nucleotide Sequence Database uses a flat file plaintext format to represent and store data which is typically referred to as EMBL-Bank format.[18] EMBL-Bank format uses a different syntax to the records in DDBJ and GenBank, though each format uses certain standardised nomenclature, such as taxonomies as defined by the NCBI Taxon database. Each line of an EMBL-format file beings with a two-letter code, such as AC to label the accession number and KW for a list of keywords relevant to the record; each record ends with //.[18]
3. Sequence Read Archive
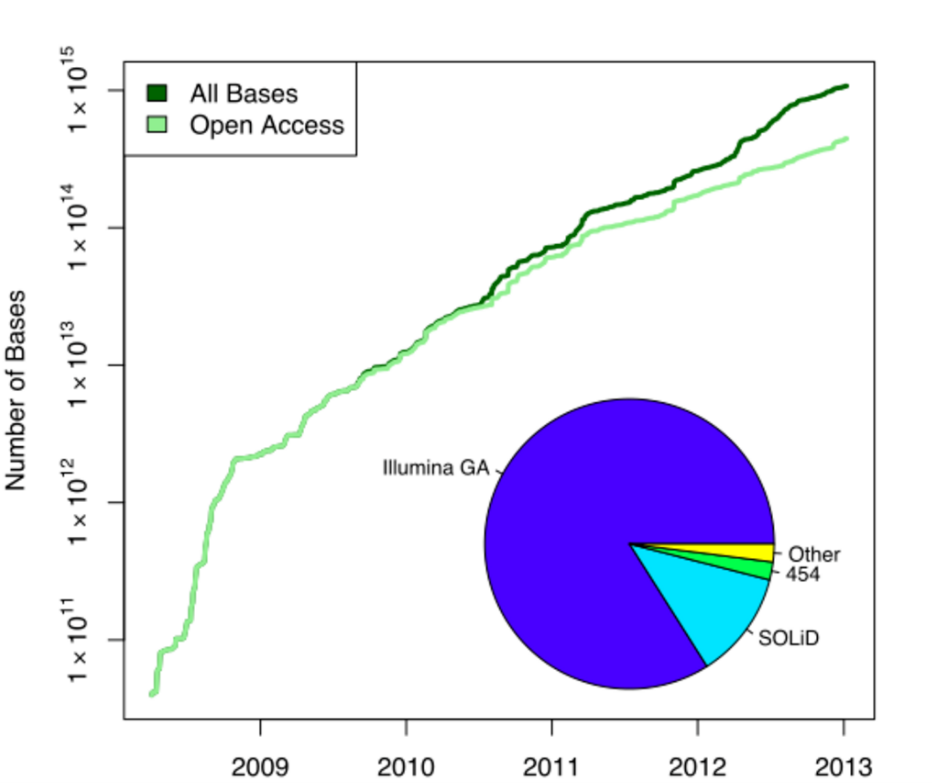
The ENA operates an instance of the Sequence Read Archive (SRA), an archival repository of sequence reads and analyses which are intended for public release.[21] Originally called the Short Read Archive, the name was changed in anticipation of future sequencing technologies being able to produce longer sequence reads.[22] Currently, the archive accepts sequence reads generated by next-generation sequencing platforms such as the Illumina Genome Analyzer and ABI SOLiD as well as some corresponding analyses and alignments.[23] The SRA operates under the guidance of the International Nucleotide Sequence Database Collaboration (INSDC)[21] and is the fastest-growing repository in the ENA.[11]
In 2010 the Sequence Read Archive made up approximately 95% of the base pair data available through the ENA,[10] encompassing over 500,000,000,000 sequence reads made up of over 60 trillion (6×1013) base pairs.[21] Almost half of this data was deposited in relation to the 1000 Genomes Project[21] wherein the researchers published their sequence data to the SRA in real-time.[24] In total, as of September 2010, 65% of the Sequence Read Archive was human genomic sequence, with another 16% relating to human metagenome sequence reads.[21]
The preferred data format for files submitted to the SRA is the BAM format, which is capable of storing both aligned and unaligned reads.[21] Internally the SRA relies on the NCBI SRA Toolkit, used at all three INSDC member databases, to provide flexible data compression, API access and conversion to other formats such as FASTQ.[20]
4. Data Access
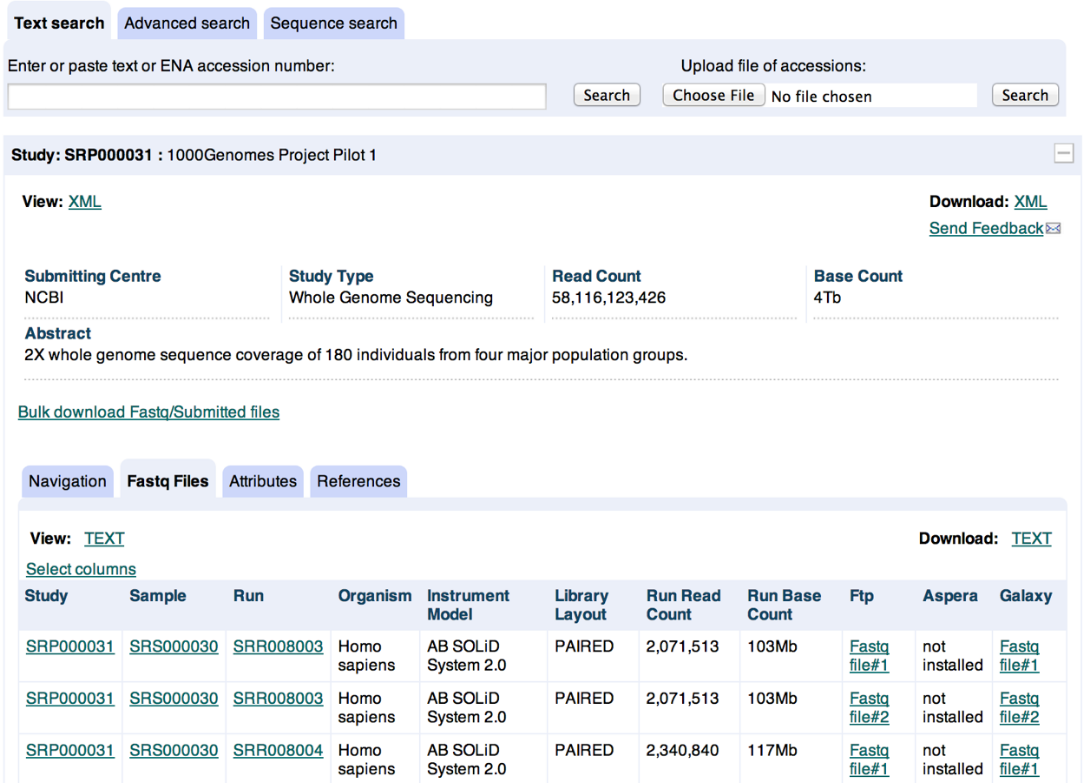
The data contained in the ENA can be accessed manually or programmatically via REST URL through the ENA browser. Initially limited to the Sequence Read Archive,[11] the ENA browser now also provides access to the Trace Archive and EMBL-Bank, allowing file retrieval in a range of formats including XML, HTML, FASTA and FASTQ.[10] Individual records can be accessed using their accession numbers and other text queries are enabled through the EB-eye search engine.[10] Additionally, sequence similarity-based searches implemented using De Bruijn graphs offer another method of retrieving records from the ENA.[11]
The ENA is accessible via the EBI SOAP and REST APIs, which also offer access to other databases hosted at the EBI, such as Ensembl and InterPro.[25]
5. Storage
The European Nucleotide Archive handles large volumes of data which pose a significant storage challenge.[26][27] As of 2012, the ENA's storage requirements continue to grow exponentially, with a doubling time of approximately 10 months.[26] To manage this increase, the ENA selectively discards less-valuable sequencing platform data and implements advanced compression strategies.[21][28] The CRAM reference-based compression toolkit was developed to help reduce ENA storage requirements.[26][29]
6. Funding
Currently the ENA is funded jointly by the European Molecular Biology Laboratory, the European Commission and the Wellcome Trust.[10] The emerging ELIXIR framework, coordinated by EBI director Janet Thornton, aims to secure a sustainable European funding infrastructure to support the continued availability of life science databases such as the ENA.[28][30][31]
References
- Hamm, G. H.; Cameron, G. N. (1986). "The EMBL data library". Nucleic Acids Research 14 (1): 5–9. doi:10.1093/nar/14.1.5. PMID 3945550. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=339348
- Kneale, G.; Kennard, O. (1984). "The EMBL nucleotide sequence data library". Biochemical Society Transactions 12 (6): 1011–1014. doi:10.1042/bst0121011. PMID 6530028. https://dx.doi.org/10.1042%2Fbst0121011
- Cameron, G. N. (1988). "The EMBL data library". Nucleic Acids Research 16 (5): 1865–1867. doi:10.1093/nar/16.5.1865. PMID 3353226. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=338182
- Fuchs, R.; Stoehr, P.; Rice, P.; Omond, R.; Cameron, G. (1990). "New services of the EMBL Data Library". Nucleic Acids Research 18 (15): 4319–4323. doi:10.1093/nar/18.15.4319. PMID 2388823. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=331247
- Kahn, P.; Hazledine, D. (1988). "NAR's new requirement for data submission to the EMBL data library: Information for authors". Nucleic Acids Research 16 (10): I-IV. PMID 16617480. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=336623
- "What is the European Nucleotide Archive?". EMBL-EBI. http://www.ebi.ac.uk/training/online/course/european-nucleotide-archive-quick-tour/what-european-nucleotide-archive. Retrieved 2013-01-06.
- Rodriguez-Tomé, P.; Stoehr, P. J.; Cameron, G. N.; Flores, T. P. (1996). "The European Bioinformatics Institute (EBI) databases". Nucleic Acids Research 24 (1): 6–12. doi:10.1093/nar/24.1.6. PMID 8594602. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=145572
- Cochrane, G.; Akhtar, R.; Aldebert, P.; Althorpe, N.; Baldwin, A.; Bates, K.; Bhattacharyya, S.; Bonfield, J. et al. (2007). "Priorities for nucleotide trace, sequence and annotation data capture at the Ensembl Trace Archive and the EMBL Nucleotide Sequence Database". Nucleic Acids Research 36 (Database): D5–D12. doi:10.1093/nar/gkm1018. ISSN 0305-1048. PMID 18039715. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2238915
- Stoesser, G.; Baker, W; Van Den Broek, A; Garcia-Pastor, M; Kanz, C; Kulikova, T; Leinonen, R; Lin, Q et al. (2003). "The EMBL Nucleotide Sequence Database: major new developments". Nucleic Acids Research 31 (1): 17–22. doi:10.1093/nar/gkg021. ISSN 1362-4962. PMID 12519939. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=165468
- "The European Nucleotide Archive". Nucleic Acids Res. 39 (Database issue): D28–31. January 2011. doi:10.1093/nar/gkq967. PMID 20972220. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3013801
- Leinonen, R.; Akhtar, R.; Birney, E.; Bonfield, J.; Bower, L.; Corbett, M.; Cheng, Y.; Demiralp, F. et al. (2009). "Improvements to services at the European Nucleotide Archive". Nucleic Acids Research 38 (Database): D39–D45. doi:10.1093/nar/gkp998. ISSN 0305-1048. PMID 19906712. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2808951
- EMBL-EBI. "EMBL Nucleotide Sequence Database". http://www.ebi.ac.uk/embl/. Retrieved 2013-01-08.
- EMBL-EBI. "About the European Nucleotide Archive". http://www.ebi.ac.uk/ena/about/about. Retrieved 2013-01-07.
- "EMBL Nucleotide Sequence Database: Release Notes". EMBL-Bank Release Notes 114. EMBL-EBI. Dec 2012. http://www.ebi.ac.uk/embl/Documentation/Release_notes/current/relnotes.html. Retrieved 2013-01-07.
- Amid, C.; Birney, E.; Bower, L.; Cerdeno-Tarraga, A.; Cheng, Y.; Cleland, I.; Faruque, N.; Gibson, R. et al. (2011). "Major submissions tool developments at the European nucleotide archive". Nucleic Acids Research 40 (D1): D43–D47. doi:10.1093/nar/gkr946. ISSN 0305-1048. PMID 22080548. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3245037
- Stoesser, G.; Baker, W; Van Den Broek, A; Camon, E; Garcia-Pastor, M; Kanz, C; Kulikova, T; Leinonen, R et al. (2002). "The EMBL Nucleotide Sequence Database". Nucleic Acids Research 30 (1): 21–26. doi:10.1093/nar/30.1.21. ISSN 1362-4962. PMID 11752244. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=99098
- "EMBL-Bank data classes". EBML-EBI. 2012. http://www.ebi.ac.uk/ena/about/embl_bank_format. Retrieved 2013-01-08.
- "EMBL-Bank User Manual (Release 129)" (Plaintext). EMBL-EBI. Sep 2016. ftp://ftp.ebi.ac.uk/pub/databases/embl/doc/usrman.txt. Retrieved 2016-11-03.
- "NCBI SRA Overview". NCBI. 1 Jan 2013. Archived from the original on February 8, 2013. https://web.archive.org/web/20130208055746/http://0-www.ncbi.nlm.nih.gov.elis.tmu.edu.tw/Traces/sra/. Retrieved 2013-01-08.
- Kodama, Y.; Shumway, M.; Leinonen, R. (2011). "The sequence read archive: explosive growth of sequencing data". Nucleic Acids Research 40 (D1): D54–D56. doi:10.1093/nar/gkr854. ISSN 0305-1048. PMID 22009675. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3245110
- "The sequence read archive". Nucleic Acids Res. 39 (Database issue): D19–21. January 2011. doi:10.1093/nar/gkq1019. PMID 21062823. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3013647
- Ostell, Jim (2009). "NCBI's Sequence Read Archive: A Core Enabling Infrastructure". Bio IT World. http://www.bio-itworld.com/BioIT_Article.aspx?id=94069. Retrieved 2013-01-08.
- "About the NCBI Sequence Read Archive". NCBI. 8 Jan 2013. http://0-www.ncbi.nlm.nih.gov.elis.tmu.edu.tw/Traces/sra/sra.cgi?view=about. Retrieved 2013-01-10.
- Shumway, M.; Cochrane, G.; Sugawara, H. (2009). "Archiving next generation sequencing data". Nucleic Acids Research 38 (Database): D870–D871. doi:10.1093/nar/gkp1078. ISSN 0305-1048. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2808927
- Mcwilliam, H.; Valentin, F.; Goujon, M.; Li, W.; Narayanasamy, M.; Martin, J.; Miyar, T.; Lopez, R. (2009). "Web services at the European Bioinformatics Institute-2009". Nucleic Acids Research 37 (Web Server): W6–W10. doi:10.1093/nar/gkp302. ISSN 0305-1048. PMID 19435877. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2703973
- Cochrane, G.; Alako, B.; Amid, C.; Bower, L.; Cerdeno-Tarraga, A.; Cleland, I.; Gibson, R.; Goodgame, N. et al. (2012). "Facing growth in the European Nucleotide Archive". Nucleic Acids Research 41 (D1): D30–D35. doi:10.1093/nar/gks1175. ISSN 0305-1048. PMID 23203883. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3531187
- Cochrane, G.; Akhtar, R.; Bonfield, J.; Bower, L.; Demiralp, F.; Faruque, N.; Gibson, R.; Hoad, G. et al. (2009). "Petabyte-scale innovations at the European Nucleotide Archive". Nucleic Acids Research 37 (Database): D19–D25. doi:10.1093/nar/gkn765. ISSN 0305-1048. PMID 18978013. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2686451
- "EMBL-EBI will continue to support the Sequence Read Archive for raw data". Press Release (EMBL-EBI). 16 Feb 2011. http://www.ebi.ac.uk/ena/sites/ebi.ac.uk.ena/files/documents/sra_announcement_feb_2011.pdf. Retrieved 2013-01-07.
- Hsi-Yang Fritz, M.; Leinonen, R.; Cochrane, G.; Birney, E. (2011). "Efficient storage of high throughput DNA sequencing data using reference-based compression". Genome Research 21 (5): 734–740. doi:10.1101/gr.114819.110. ISSN 1088-9051. PMID 21245279. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3083090
- "About ELIXIR". ELIXIR. http://www.elixir-europe.org/about. Retrieved 2013-01-09.
- Crosswell, Lindsey C.; Thornton, Janet M. (2012). "ELIXIR: a distributed infrastructure for European biological data". Trends in Biotechnology 30 (5): 241–242. doi:10.1016/j.tibtech.2012.02.002. ISSN 0167-7799. PMID 22417641. https://dx.doi.org/10.1016%2Fj.tibtech.2012.02.002

