 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Sirius Huang | -- | 4920 | 2022-11-24 01:42:13 |
Video Upload Options
The convolutional sparse coding paradigm is an extension of the global Sparse Coding model, in which a redundant dictionary is modeled as a concatenation of circulant matrices. While the global sparsity constraint describes signal [math]\displaystyle{ \mathbf{x}\in \mathbb{R}^{N} }[/math] as a linear combination of a few atoms in the redundant dictionary [math]\displaystyle{ \mathbf{D}\in\mathbb{R}^{N\times M}, M\gg N }[/math], usually expressed as [math]\displaystyle{ \mathbf{x}=\mathbf{D}\mathbf{\Gamma} }[/math] for a sparse vector [math]\displaystyle{ \mathbf{\Gamma}\in \mathbb{R}^{M} }[/math], the alternative dictionary structure adopted by the Convolutional Sparse Coding model allows the sparsity prior to be applied locally instead of globally: independent patches of [math]\displaystyle{ \mathbf{x} }[/math] are generated by "local" dictionaries operating over stripes of [math]\displaystyle{ \mathbf{\Gamma} }[/math]. The local sparsity constraint allows stronger uniqueness and stability conditions than the global sparsity prior, and has shown to be a versatile tool for inverse problems in fields such as Image Understanding and Computer Vision. Also, a recently proposed multi-layer extension of the model has shown conceptual benefits for more complex signal decompositions, as well as a tight connection the Convolutional Neural Networks model, allowing a deeper understanding of how the latter operates.
1. Overview
Given a signal of interest [math]\displaystyle{ \mathbf{x}\in \mathbb{R}^{N} }[/math] and a redundant dictionary [math]\displaystyle{ \mathbf{D}\in\mathbb{R}^{N\times M}, M\gg N }[/math], the Sparse Coding problem consist of retrieving a sparse vector [math]\displaystyle{ \mathbf{\Gamma}\in \mathbb{R}^{M} }[/math], denominated the Sparse representation of [math]\displaystyle{ \mathbf{x} }[/math], such that [math]\displaystyle{ \mathbf{x}= \mathbf{D}\mathbf{\Gamma} }[/math]. Intuitively, this implies [math]\displaystyle{ \mathbf{x} }[/math] is expressed as a linear combination of a small number of elements in [math]\displaystyle{ \mathbf{D} }[/math]. The global sparsity constraint prior has been shown to be useful in many ill-posed inverse problems such as image inpainting, super-resolution, and coding.[1][2][3] It has been of particular interest for image understanding and computer vision tasks involving natural images, allowing redundant dictionaries to be efficiently inferred [4][5][6]
As an extension to the global sparsity constraint, recent pieces in the literature have revisited the model to reach a more profound understanding of its uniqueness and stability conditions.[6] Interestingly, by imposing a local sparsity prior in [math]\displaystyle{ \mathbf{\Gamma} }[/math], meaning that its independent patches can be interpreted as sparse vectors themselves, the structure in [math]\displaystyle{ \mathbf{D} }[/math] can be understood as a “local" dictionary operating over each independent patch. This model extension is denominated Convolutional Sparse Coding (CSC) and drastically reduces the burden of estimating signal representations while being characterized by stronger uniqueness and stability conditions. Furthermore, it allows for [math]\displaystyle{ \mathbf{\Gamma} }[/math] to be efficiently estimated via projected gradient descent algorithms such as Orthonormal Matching Pursuit and Basis Pursuit, while performing in a local fashion[5]
Besides its versatility in inverse problems, recent efforts have focused on the multi-layer version of the model and provided evidence of its reliability for recovering multiple underlying representations.[7] Moreover, a tight connection between such a model and the well-established Convolutional Neural Network model (CNN) was revealed, providing a new tool for a more rigurous understanding of its theoretical conditions.
The convolutional sparse coding model provides a very efficient set of tools to solve a wide range of inverse problems, including image denoising, image inpainting, and image superresolution. By imposing local sparsity constraints, it allows to efficiently tackle the global coding problem by iteratively estimating disjoint patches and assembling them into a global signal. Furthermore, by adopting a multi-layer sparse model, which results from imposing the sparsity constraint to the signal inherent representations themselves, the resulting “Layered" Pursuit algorithm keeps the strong uniqueness and stability conditions from the single-layer model. This extension also provides some interesting notions about the relation between its sparsity prior and the forward pass of the Convolutional Neural Network, which allows to understand how the theoretical benefits of the CSC model can provide a strong mathematical meaning of the CNN structure.
2. Sparse Coding Paradigm
Basic concepts and models are presented to explain into detail the Convolutional Sparse Representation framework. On the grounds that the sparsity constraint has been proposed under different models, a short description of them is presented to show its evolution up to the model of interest. Also included are the concepts of Mutual Coherence and Restricted Isometry Property to establish uniqueness stability guarantees.
2.1. Global Sparse Coding Model
Allow signal [math]\displaystyle{ \mathbf{x}\in \mathbb{R}^N }[/math] to be expressed as a linear combination of a small number of atoms from a given dictionary [math]\displaystyle{ \mathbf{D}\in \mathbb{R}^{N \times M}, M\gt N }[/math]. Alternatively, the signal can be expressed as [math]\displaystyle{ \mathbf{x}=\mathbf{D}\mathbf{\Gamma} }[/math], where [math]\displaystyle{ \mathbf{\Gamma}\in \mathbb{R}^M }[/math] corresponds to the sparse representation of [math]\displaystyle{ \mathbf{x} }[/math], which selects the atoms to combine and their weights. Subsequently, given [math]\displaystyle{ \mathbf{D} }[/math], the task of recovering [math]\displaystyle{ \mathbf{\Gamma} }[/math] from either the noise-free signal itself or an observation is denominated sparse coding. Considering the noise-free scenario, the coding problem is formulated as follows: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}_{\text{ideal}}&= \underset{\mathbf{\Gamma}}{\text{argmin}}\; \| \mathbf{\Gamma}\|_{0}\; \text{s.t.}\; \mathbf{D}\mathbf{\Gamma}=\mathbf{x}.\end{aligned} }[/math] The effect of the [math]\displaystyle{ \ell_{0} }[/math] norm is to favor solutions with as much zero elements as possible. Furthermore, given an observation affected by bounded energy noise: [math]\displaystyle{ \mathbf{Y}= \mathbf{D}\mathbf{\Gamma}+ \mathbf{E},\|\mathbf{E}\|_{2}\lt \varepsilon }[/math], the pursuit problem is reformulated as: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}_{\text{noise}}&= \underset{\mathbf{\Gamma}}{\text{argmin}}\; \| \mathbf{\Gamma}\|_{0}\; \text{ s.t. } \|\mathbf{D}\mathbf{\Gamma}-\mathbf{Y}\|_{2}\lt \varepsilon.\end{aligned} }[/math]
2.2. Stability and Uniqueness Guarantees for the Global Sparse Model
Let the spark of [math]\displaystyle{ \mathbf{\mathbf{D}} }[/math] be defined as the minimum number of linearly independent columns: [math]\displaystyle{ \begin{aligned} \sigma(\mathbf{D})=\underset{\mathbf{\Gamma}}{\text{min}} \quad \|\mathbf{\Gamma}\|_{0} \quad \text{s.t.}\quad \mathbf{D \Gamma}=0, \quad \mathbf{\Gamma}\neq 0.\end{aligned} }[/math]
Then, from the triangular inequality, the sparsest vector [math]\displaystyle{ \mathbf{\Gamma} }[/math] satisfies: [math]\displaystyle{ \|\mathbf{\Gamma}\|_{0}\lt \frac{\sigma(\mathbf{D})}{2} }[/math]. Although the spark provides an upper bound, it is unfeasible to compute in practical scenarios. Instead, let the mutual coherence be a measure of similarity between atoms in [math]\displaystyle{ \mathbf{D} }[/math]. Assuming [math]\displaystyle{ \ell_{2} }[/math]-norm unit atoms, the mutual coherence of [math]\displaystyle{ \mathbf{D} }[/math] is defined as: [math]\displaystyle{ \mu(\mathbf{D})= \max_{i\neq j} \|\mathbf{d_i^T}\mathbf{d_j}\|_2 }[/math], where [math]\displaystyle{ \mathbf{d}_{i} }[/math] are atoms. Based on this metric, it can be proven that the true sparse representation [math]\displaystyle{ \mathbf{\Gamma}^{*} }[/math] can be recovered if and only if [math]\displaystyle{ \|\mathbf{\Gamma}^{*}\|_0 \lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D})} \big) }[/math].
Similarly, under the presence of noise, an upper bound for the distance between the true sparse representation [math]\displaystyle{ \mathbf{\Gamma^{*}} }[/math] and its estimation [math]\displaystyle{ \hat{\mathbf{\Gamma}} }[/math] can be established via the Restricted Isometry Property (RIP). A k-RIP matrix [math]\displaystyle{ \mathbf{D} }[/math] with constant [math]\displaystyle{ \delta_{k} }[/math] corresponds to: [math]\displaystyle{ (1-\delta_k)\|\mathbf{\Gamma}\|_2^2 \leq \|\mathbf{D\Gamma}\|_2^2 \leq (1+\delta_k)\|\mathbf{\Gamma}\|_2^2 }[/math], where [math]\displaystyle{ \delta_k }[/math] is the smallest number that satisfies the inequality for every [math]\displaystyle{ \|\mathbf{\Gamma}\|_{0}=k }[/math]. Then, assuming [math]\displaystyle{ \|\mathbf{\Gamma}\|_0\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D})} \big) }[/math], it is guaranteed that [math]\displaystyle{ \|\mathbf{\hat{\Gamma}-\Gamma^{*}}\|_{2}^{2}\leq \frac{4\varepsilon^2}{1-\mu(\mathbf{D})(2\|\mathbf{\Gamma}\|_0-1)} }[/math].
Solving such a general pursuit problem is a hard task if no structure is imposed on dictionary [math]\displaystyle{ \mathbf{D} }[/math]. This implies learning large, highly overcomplete representations, which is extremely expensive. Assuming such a burden has been met and a representative dictionary has been obtained for a given signal [math]\displaystyle{ \mathbf{x} }[/math], typically based on prior information, [math]\displaystyle{ \mathbf{\Gamma}^{*} }[/math] can be estimated via several pursuit algorithms.
Pursuit algorithms for the global sparse model
Two basic methods for solving the Global Sparse Coding problem are Orthogonal Matching Pursuit (OMP) and Basis Pursuit (BP) . OMP is a greedy algorithm that iteratively selects the atom best correlated with the residual between [math]\displaystyle{ \mathbf{x} }[/math] and a current estimation, followed by a projection onto a subset of pre-selected atoms. On the other hand, BP is a more sophisticated approach that replaces the original coding problem by a linear programming problem. Based on this algorithms, the Global Sparse Coding provides considerably loose bounds for the uniqueness and stability of [math]\displaystyle{ \hat{\mathbf{\Gamma}} }[/math]. To overcome this, additional priors are imposed over [math]\displaystyle{ \mathbf{D} }[/math] to guarantee tighter bounds and uniqueness conditions. The reader is referred to (,[5] section 2) for details regarding this properties.
2.3. Convolutional Sparse Coding Model
A local prior is adopted such that each overlapping section of [math]\displaystyle{ \mathbf{\Gamma} }[/math] is sparse. Let [math]\displaystyle{ \mathbf{D}\in \mathbb{R}^{N \times Nm} }[/math] be constructed from shifted versions of a local dictionary [math]\displaystyle{ \mathbf{D_{L}}\in\mathbb{R}^{n \times m}, m\ll M }[/math]. Then, [math]\displaystyle{ \mathbf{x} }[/math] is formed by products between [math]\displaystyle{ \mathbf{D_{L}} }[/math] and local patches of [math]\displaystyle{ \mathbf{\Gamma}\in\mathbb{R}^{mN} }[/math].
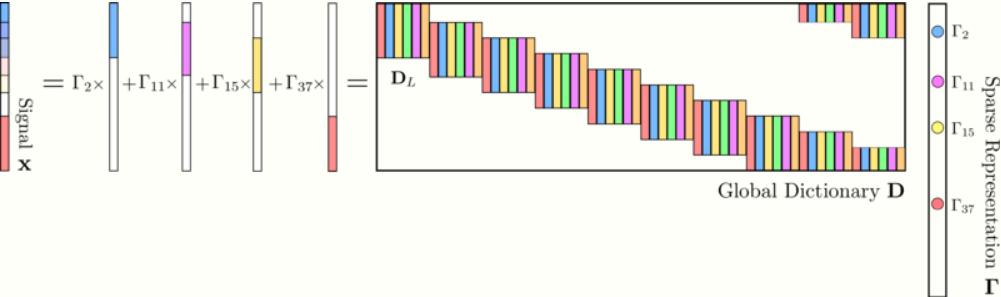
From the latter, [math]\displaystyle{ \mathbf{\Gamma} }[/math] can be re-expressed by [math]\displaystyle{ N }[/math] disjoint sparse vectors [math]\displaystyle{ \alpha_{i}\in \mathbb{R}^{m} }[/math]: [math]\displaystyle{ \mathbf{\Gamma}\in \{\alpha_{1},\alpha_{2},\dots, \alpha_{N}\}^{T} }[/math]. Similarly, let [math]\displaystyle{ \gamma }[/math] be a set of [math]\displaystyle{ (2n-1) }[/math] consecutive vectors [math]\displaystyle{ \alpha_{i} }[/math]. Then, each disjoint segment in [math]\displaystyle{ \mathbf{x} }[/math] is expressed as: [math]\displaystyle{ \mathbf{x}_{i}=\mathbf{R}_{i}\mathbf{D}\mathbf{\Gamma} }[/math], where operator [math]\displaystyle{ \mathbf{R}_{i}\in \mathbb{R}^{n\times N} }[/math] extracts overlapping patches of size [math]\displaystyle{ n }[/math] starting at index [math]\displaystyle{ i }[/math]. Thus, [math]\displaystyle{ \mathbf{R}_{i}\mathbf{D} }[/math] contains only [math]\displaystyle{ (2n-1)m }[/math] nonzero columns. Hence, by introducing operator [math]\displaystyle{ \mathbf{S}_{i}\in \mathbf{R}^{(2n-1)m \times Nm} }[/math] which exclusively preserves them: [math]\displaystyle{ \begin{aligned} \mathbf{x}_{i}&= \underset{\Omega}{\underbrace{\mathbf{R}_{i}\mathbf{D}\mathbf{S}_{i}^{T}}}\underset{\gamma_{i}}{\underbrace{(S_{i}\mathbf{\Gamma})}},\end{aligned} }[/math] where [math]\displaystyle{ \Omega }[/math] is known as the stripe dictionary, which is independent of [math]\displaystyle{ i }[/math], and [math]\displaystyle{ \gamma_{i} }[/math] is denominated the i-th stripe. So, [math]\displaystyle{ \mathbf{x} }[/math] corresponds to a patch aggregation or convolutional interpretation: [math]\displaystyle{ \begin{aligned} \mathbf{x}&= \sum_{i=1}^{N}\mathbf{R}_{i}^{T}\mathbf{D}_{L}\alpha_{i}= \sum_{i=1}^{m}\mathbf{d}_{i}\ast \mathbf{z_{i}}.\end{aligned} }[/math] Where [math]\displaystyle{ \mathbf{d}_{i} }[/math] corresponds to the i-th atom from the local dictionary [math]\displaystyle{ \mathbf{D}_{L} }[/math] and [math]\displaystyle{ \mathbf{z_{i}} }[/math] is constructed by elements of patches [math]\displaystyle{ \alpha }[/math]: [math]\displaystyle{ \mathbf{z_{i}}\triangleq (\alpha_{1,i}, \alpha_{2,i},\dots, \alpha_{N,i})^{T} }[/math]. Given the new dictionary structure, let the [math]\displaystyle{ \ell_{0,\infty} }[/math] pseudo-norm be defined as: [math]\displaystyle{ \|\mathbf{\Gamma}\|_{0,\infty}\triangleq \underset{i}{\text{ max}}\; \|\gamma_{i}\|_{0} }[/math]. Then, for the noise-free and noise-corrupted scenarios, the problem can be respectively reformulated as: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}_{\text{ideal}}&= \underset{\mathbf{\Gamma}}{\text{argmin}}\; \| \mathbf{\Gamma}\|_{0,\infty}\; \text{s.t.}\; \mathbf{D}\mathbf{\Gamma}=\mathbf{x},\\ \hat{\mathbf{\Gamma}}_{\text{noise}}&= \underset{\mathbf{\Gamma}}{\text{argmin}}\; \| \mathbf{\Gamma}\|_{0,\infty}\; \text{s.t.}\; \|\mathbf{Y}-\mathbf{D}\mathbf{\Gamma}\|_{2}\lt \varepsilon.\end{aligned} }[/math]
Stability and uniqueness guarantees for the convolutional sparse model
For the local approach, [math]\displaystyle{ \mathbf{D} }[/math] mutual coherence satisfies: [math]\displaystyle{ \mu(\mathbf{D})\geq \big(\frac{m-1}{m(2n-1)-1}\big)^{1/2}. }[/math] So, if a solution obeys [math]\displaystyle{ \|\mathbf{\Gamma}\|_{0,\infty}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D})}\big) }[/math], then it is the sparsest solution to the [math]\displaystyle{ \ell_{0,\infty} }[/math] problem. Thus, under the local formulation, the same number of non-zeros is permitted for each stripe instead of the full vector!
Similar to the global model, the CSC is solved via OMP and BP methods, the latter contemplating the use of the Iterative Shrinkage Thresholding Algorithm (ISTA)[8] for splitting the pursuit into smaller problems. Based on the [math]\displaystyle{ \ell_{0,\infty} }[/math] pseudonorm, if a solution [math]\displaystyle{ \mathbf{\Gamma} }[/math] exists satisfying [math]\displaystyle{ \|\mathbf{\Gamma}\|_{0,\infty}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D})} \big) }[/math], then both methods are guaranteed to recover it. Moreover, the local model guarantees recovery independently of the signal dimension, as opposed to the [math]\displaystyle{ \ell_{0} }[/math] prior. Stability conditions for OMP and BP are also guaranteed if its Exact Recovery Condition (ERC) is met for a support [math]\displaystyle{ \mathcal{T} }[/math] with a constant [math]\displaystyle{ \theta }[/math]. The ERC is defined as: [math]\displaystyle{ \theta= 1-\underset{i\notin \mathcal{T}}{\text{max}} \|\mathbf{D}_{\mathcal{T}}^{\dagger}\mathbf{d}_{i}\|_{1}\gt 0 }[/math], where [math]\displaystyle{ \dagger }[/math] denotes the Pseudo-inverse. Algorithm 1 shows the Global Pursuit method based on ISTA.
Algorithm 1: 1D CSC via local iterative soft-thresholding.
Input:
[math]\displaystyle{ \mathbf{D}_{L} }[/math]: Local Dictionary,
[math]\displaystyle{ \mathbf{y} }[/math]: observation,
[math]\displaystyle{ \lambda }[/math]: Regularization parameter,
[math]\displaystyle{ c }[/math]: step size for ISTA,
tol: tolerance factor,
maxiters: maximum number of iterations.
-
-
- [math]\displaystyle{ \{\boldsymbol{\alpha}_{i}\}^{(0)}\gets \{\mathbf{0}_{N\times 1}\} }[/math] (Initialize disjoint patches.)
-
-
-
- [math]\displaystyle{ \{\mathbf{r}_{i}\}^{(0)}\gets \{\mathbf{R}_{i}\mathbf{y}\} }[/math] (Initialize residual patches.)
-
-
-
- [math]\displaystyle{ k\gets 0 }[/math]
-
Repeat
-
-
- [math]\displaystyle{ \{\boldsymbol{\alpha}_i\}^{(k)}\gets \mathcal{S}_{\frac{\lambda}{c}}\big( \{\boldsymbol{\alpha}_i\}^{(k-1)}+\frac{1}{c}\{\mathbf{D}_{L}^{T}\mathbf{r}_i\}^{(k-1)} \big) }[/math] (Coding along disjoint patches)
-
-
-
- [math]\displaystyle{ \boldsymbol{\alpha}_i }[/math] [math]\displaystyle{ \hat{\mathbf{x}}^{(k)}\gets \sum_{i}\mathbf{R}_{i}^{T}\mathbf{D}_{L}\boldsymbol{\alpha}_{i}^{(k)} }[/math] (Patch Aggregation)
-
-
-
- [math]\displaystyle{ \{\mathbf{r}_{i}\}^{(k)}\gets \mathbf{R}_{i}\big( \mathbf{y}-\hat{\mathbf{x}}^{(k)} \big) }[/math] (Update residuals)
-
-
-
- [math]\displaystyle{ k \gets k+ 1 }[/math]
-
Until [math]\displaystyle{ \|\hat{\mathbf{x}}^{(k)}- \hat{\mathbf{x}}^{(k-1)}\|_{2}\lt }[/math] tol or [math]\displaystyle{ k\gt }[/math] maxiters.
2.4. Multi-Layered Convolutional Sparse Coding Model
By imposing the sparsity prior in the inherent structure of [math]\displaystyle{ \mathbf{x} }[/math], strong conditions for a unique representation and feasible methods for estimating it are granted. Similarly, such a constraint can be applied to its representation itself, generating a cascade of sparse representations: Each code is defined by a few atoms of a given set of convolutional dictionaries.
Based on this criteria, yet another extension denominated Multi-layer Convolutional Sparse Coding (ML-CSC) is proposed. A set of analytical dictionaries [math]\displaystyle{ \{\mathbf{D}\}_{k=1}^{K} }[/math] can be efficiently designed, where sparse representations at each layer [math]\displaystyle{ \{\mathbf{\Gamma}\}_{k=1}^{K} }[/math] are guaranteed by imposing the sparsity prior over the dictionaries themselves.[7] In other words, by considering dictionaries to be stride convolutional matrices i.e. atoms of the local dictionaries shift [math]\displaystyle{ m }[/math] elements instead of a single one, where [math]\displaystyle{ m }[/math] corresponds to the number of channels in the previous layer, it is guaranteed that the [math]\displaystyle{ \|\mathbf{\Gamma}\|_{0,\infty} }[/math] norm of the representations along layers is bounded.
For example, given the dictionaries [math]\displaystyle{ \mathbf{D}_{1} \in \mathbb{R}^{N\times Nm_{1}}, \mathbf{D}_{2} \in \mathbb{R}^{Nm_{1}\times Nm_{2}} }[/math], the signal is modeled as [math]\displaystyle{ \mathbf{D}_{1}\mathbf{\Gamma}_{1}= \mathbf{D}_{1}(\mathbf{D}_{2}\mathbf{\Gamma}_{2}) }[/math], where [math]\displaystyle{ \mathbf{\Gamma}_{1} }[/math] is its sparse code, and [math]\displaystyle{ \mathbf{\Gamma}_{2} }[/math] is the sparse code of [math]\displaystyle{ \mathbf{\Gamma}_{1} }[/math]. Then, the estimation of each representation is formulated as an optimization problem for both noise-free and noise-corrupted scenarios, respectively. Assuming [math]\displaystyle{ \mathbf{\Gamma}_{0}=\mathbf{x} }[/math]: [math]\displaystyle{ \begin{aligned} \text{Find}\; \{\mathbf{\Gamma}_{i}\}_{i=1}^{K}\;\text{s.t.}&\; \mathbf{\Gamma}_{i-1}=\mathbf{D}_{i}\mathbf{\Gamma}_{i},\; \|\mathbf{\Gamma}_{i}\|_{0,\infty}\leq \lambda_{i}\\ \text{Find}\; \{\mathbf{\Gamma}_{i}\}_{i=1}^{K}\; \text{s.t.} &\;\|\mathbf{\Gamma}_{i-1}-\mathbf{D}_{i}\mathbf{\Gamma}_{i}\|_{2}\leq \varepsilon_{i},\; \|\mathbf{\Gamma}_{i}\|_{0,\infty}\leq \lambda_{i}\end{aligned} }[/math]
In what follows, theoretical guarantees for the uniqueness and stability of this extended model are described.
Theorem 1: (Uniqueness of Sparse Representations) Consider signal [math]\displaystyle{ \mathbf{x} }[/math] satisfies the (ML-CSC) model for a set of convolutional dictionaries [math]\displaystyle{ \{\mathbf{D}_{i}\}_{i=1}^{K} }[/math] with mutual coherence [math]\displaystyle{ \{\mu(\mathbf{D}_{i})\}_{i=1}^{K} }[/math]. If the true sparse representations satisfy [math]\displaystyle{ \{\mathbf{\Gamma}\}_{i=1}^{K}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D}_{i})}\big) }[/math], then a solution to the problem [math]\displaystyle{ \{\hat{\mathbf{\Gamma}_{i}}\}_{i=1}^{K} }[/math] will be its unique solution if the thresholds are chosen to satisfy: [math]\displaystyle{ \lambda_{i}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D}_{i})} \big) }[/math].
Theorem 2: (Global Stability of the noise-corrupted scenario) Consider signal [math]\displaystyle{ \mathbf{x} }[/math] satisfies the (ML-CSC) model for a set of convolutional dictionaries [math]\displaystyle{ \{\mathbf{D}_{i}\}_{i=1}^{K} }[/math] is contaminated with noise [math]\displaystyle{ \mathbf{E} }[/math], where [math]\displaystyle{ \|\mathbf{E}\|_{2}\leq \varepsilon_{0} }[/math]. resulting in [math]\displaystyle{ \mathbf{Y=X+E} }[/math]. If [math]\displaystyle{ \lambda_{i}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D}_{i})}\big) }[/math] and [math]\displaystyle{ \varepsilon_{i}^{2}=\frac{4\varepsilon_{i-1}^{2}}{1-(2\|\mathbf{\Gamma}_{i}\|_{0,\infty}-1)\mu(\mathbf{D}_{i})} }[/math], then the estimated representations [math]\displaystyle{ \{\mathbf{\Gamma}_{i}\}_{i=1}^{K} }[/math] satisfy the following: [math]\displaystyle{ \|\mathbf{\Gamma}_{i}-\hat{\mathbf{\Gamma}}_{i}\|_{2}^{2}\leq \varepsilon_{i}^{2} }[/math].
2.5. Projection-Based Algorithms
As a simple approach for solving the ML-CSC problem, either via the [math]\displaystyle{ \ell_{0} }[/math] or [math]\displaystyle{ \ell_{1} }[/math] norms, is by computing inner products between [math]\displaystyle{ \mathbf{x} }[/math] and the dictionary atoms to identify the most representatives ones. Such a projection is described as: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}_{\ell_p}&= \underset{\mathbf{\Gamma}}{\operatorname{argmin}} \frac{1}{2}\|\mathbf{\Gamma}-\mathbf{D}^{T}\mathbf{x}\|_2^2 +\beta\|\mathbf{\Gamma}\|_p & p\in\{0,1\},\end{aligned} }[/math]
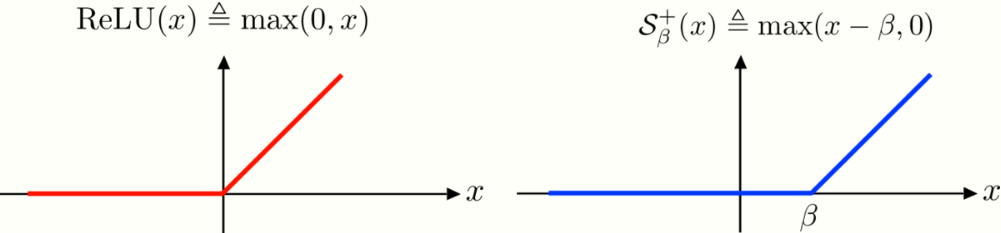
which have closed-form solutions via the hard-thresholding [math]\displaystyle{ \mathcal{H}_{\beta}(\mathbf{D}^{T}\mathbf{x}) }[/math] and soft-thresholding algorithms [math]\displaystyle{ \mathcal{S}_{\beta}(\mathbf{D}^{T}\mathbf{x}) }[/math], respectively. If a nonnegative constraint is also contemplated, the problem can be expressed via the [math]\displaystyle{ \ell_{1} }[/math] norm as: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}&= \underset{\mathbf{\Gamma}}{\text{argmin}}\; \frac{1}{2}\|\mathbf{\Gamma}-\mathbf{D}^T\mathbf{x}\|_2^2+\beta\|\mathbf{\Gamma}\|_1,\; \text{ s.t. } \mathbf{\Gamma}\geq 0,\end{aligned} }[/math] which closed-form solution corresponds to the soft nonnegative thresholding operator [math]\displaystyle{ \mathcal{S}_{\beta}^{+}(\mathbf{D}^{T}\mathbf{x}) }[/math], where [math]\displaystyle{ \mathcal{S}_{\beta}^{+}(z)\triangleq \max(z-\beta,0) }[/math]. Guarantees for the Layered soft-thresholding approach are included in the Appendix (Section 6.2).
Theorem 3: (Stable recovery of the multi-layered soft-thresholding algorithm) Consider signal [math]\displaystyle{ \mathbf{x} }[/math] that satisfies the (ML-CSC) model for a set of convolutional dictionaries [math]\displaystyle{ \{\mathbf{D}_i\}_{i=1}^K }[/math] with mutual coherence [math]\displaystyle{ \{\mu(\mathbf{D}_i)\}_{i=1}^K }[/math] is contaminated with noise [math]\displaystyle{ \mathbf{E} }[/math], where [math]\displaystyle{ \|\mathbf{E}\|_2\leq \varepsilon_0 }[/math]. resulting in [math]\displaystyle{ \mathbf{Y=X+E} }[/math]. Denote by [math]\displaystyle{ |\mathbf{\Gamma}_i^{\min}| }[/math] and [math]\displaystyle{ |\mathbf{\Gamma}_i^{\max}| }[/math] the lowest and highest entries in [math]\displaystyle{ \mathbf{\Gamma}_i }[/math]. Let [math]\displaystyle{ \{\hat{\mathbf{\Gamma}}_i\}_{i=1}^K }[/math] be the estimated sparse representations obtained for [math]\displaystyle{ \{\beta_i\}_{i=1}^K }[/math]. If [math]\displaystyle{ \|\mathbf{\Gamma}_i\|_{0,\infty}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D}_{i})}\frac{|\mathbf{\Gamma}_i^{\min}|}{|\mathbf{\Gamma}_i^{\min}|}\big)-\frac{1}{\mu(\mathbf{D}_{i})} \frac{\varepsilon_{i-1}}{|\mathbf{\Gamma}_i^{\max}|} }[/math] and [math]\displaystyle{ \beta_i }[/math] is chosen according to: [math]\displaystyle{ \begin{aligned} \|\mathbf{\Gamma}_i\|_{0,\infty}^s\lt \frac{1}{2}\big( 1+\frac{1}{\mu(\mathbf{D}_i)} frac{|\mathbf{\Gamma}_i^{\min}|}{|\mathbf{\Gamma}_i^{\max}|} \big)-\frac{1}{\mu(\mathbf{D}_i)}\frac{\varepsilon_{i-1}}{|\mathbf{\Gamma}_i^{\max}|} \end{aligned} }[/math] Then, [math]\displaystyle{ \hat{\mathbf{\Gamma}}_{i} }[/math] has the same support as [math]\displaystyle{ \mathbf{\Gamma}_{i} }[/math], and [math]\displaystyle{ \|\mathbf{\Gamma}_{i}-\hat{\mathbf{\Gamma}_i}\|_{2,\infty}\leq \varepsilon_i }[/math], for [math]\displaystyle{ \varepsilon_i=\sqrt{\|\mathbf{\Gamma}_i\|_{0,\infty}}(\varepsilon_{i-1}+\mu(\mathbf{D}_i)(\|\mathbf{\Gamma}_i\|_{0,\infty}-1)|\mathbf{\Gamma}_i^{\max}|+\beta_{i}) }[/math]
2.6. Connections to Convolutional Neural Networks
Recall the Forward Pass of the Convolutional Neural Network (CNN) model, used in both training and inference steps. Let [math]\displaystyle{ \mathbf{x}\in \mathbb{R}^{Mm_{1}} }[/math] be its input and [math]\displaystyle{ \mathbf{W}_{k}\in\mathbb{R}^{N\times m_{1}} }[/math] the filters at layer [math]\displaystyle{ k }[/math], which are followed by the Rectified Linear Unit [math]\displaystyle{ \text{ReLU}(\mathbf{x})= \max(0, x) }[/math], for bias [math]\displaystyle{ \mathbf{b}\in \mathbb{R}^{Mm_{1}} }[/math]. Based on this elementary block, taking [math]\displaystyle{ K=2 }[/math] as example, the CNN output can be expressed as: [math]\displaystyle{ \begin{aligned} \mathbf{Z}_{2}&= \text{ReLU}\big(\mathbf{W}_{2}^{T}\; \text{ReLU}(\mathbf{W}_{1}^{T}\mathbf{x})+\mathbf{b}_{1})+\mathbf{b}_{2}\;\big).\end{aligned} }[/math] Finally, comparing the CNN algorithm and the Layered thresholding approach for the nonnegative constaint [sic?], it is straightforward to show that both are equivalent: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}&= \mathcal{S}^{+}_{\beta_{2}}\big(\mathbf{D}_{2}^{T}\mathcal{S}^{+}_{\beta_{1}}(\mathbf{D}_{1}^{T}\mathbf{x}) \big)\\ &= \text{ReLU}\big(\mathbf{W}_{2}^{T} \text{ReLU}(\mathbf{W}_{1}^{T}\mathbf{x}+\beta_{1})+\beta_{2}\big).\end{aligned} }[/math]
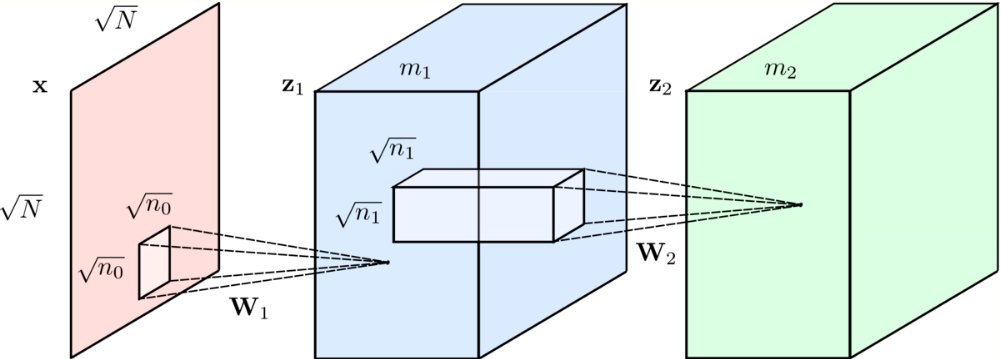
As explained in what follows, this naive approach of solving the coding problem is a particular case of a more stable projected gradient descent algorithm for the ML-CSC model. Equipped with the stability conditions of both approaches, a more clear understanding about the class of signals a CNN can recover, under what noise conditions can an estimation be accurately attained, and how can its structure be modified to improve its theoretical conditions. The reader is referred to (,[7] section 5) for details regarding their connection.
2.7. Pursuit Algorithms for the Multi-Layer CSC Model
A crucial limitation of the Forward Pass is it being unable to recover the unique solution of the DCP problem, which existence has been demonstrated. So, instead of using a thresholding approach at each layer, a full pursuit method is adopted, denominated Layered Basis Pursuit (LBP). Considering the projection onto the [math]\displaystyle{ \ell_{1} }[/math] ball, the following problem is proposed: [math]\displaystyle{ \begin{aligned} \hat{\mathbf{\Gamma}}_i & =\underset{\mathbf{\Gamma}_{i}}{\text{argmin}}\; \frac{1}{2}\|\mathbf{D}_{i}\mathbf{\Gamma}_{i}-\hat{\mathbf{\Gamma}}_{i}\|_{2}^{2}+\; \xi_{i}\|\mathbf{\Gamma}_{i}\|_{1},\end{aligned} }[/math] where each layer is solved as an independent CSC problem, and [math]\displaystyle{ \xi_{i} }[/math] is proportional to the noise level at each layer. Among the methods for solving the layered coding problem, ISTA is an efficient decoupling alternative. In what follows, a short summary of the guarantees for the LBP are established.
Theorem 4: (Recovery guarantee) Consider a signal [math]\displaystyle{ \mathbf{x} }[/math] characterized by a set of sparse vectors [math]\displaystyle{ \{\mathbf{\Gamma}_{i}\}_{i=1}^{K} }[/math], convolutional dictionaries [math]\displaystyle{ \{\mathbf{D}_{i}\}_{i=1}^{K} }[/math] and their corresponding mutual coherences [math]\displaystyle{ \{\mu\big(\mathbf{D}_{i}\big)\}_{i=1}^{K} }[/math]. If [math]\displaystyle{ \|\mathbf{\Gamma}_{i}\|_{0,\infty}\lt \frac{1}{2}\big(1+\frac{1}{\mu(\mathbf{D}_{i})}\big) }[/math], then the LBP algorithm is guaranteed to recover the sparse representations.
Theorem 5: (Stability in the presence of noise) Consider the contaminated signal [math]\displaystyle{ \mathbf{Y}=\mathbf{X+E} }[/math], where [math]\displaystyle{ \|\mathbf{E}\|_{0,\infty}\leq \varepsilon_{0} }[/math] and [math]\displaystyle{ \mathbf{x} }[/math] is characterized by a set of sparse vectors [math]\displaystyle{ \{\mathbf{\Gamma}_{i}\}_{i=1}^{K} }[/math] and convolutional dictionaries [math]\displaystyle{ \{\mathbf{D}_{i}\}_{i=1}^{K} }[/math]. Let [math]\displaystyle{ \{\hat{\mathbf{\Gamma}}_{i}\}_{i=1}^{K} }[/math] be solutions obtained via the LBP algorithm with parameters [math]\displaystyle{ \{\xi\}_{i=1}^{K} }[/math]. If [math]\displaystyle{ \|\mathbf{\Gamma}_{i}\|_{0,\infty}\lt \frac{1}{3}\big(1+\frac{1}{\mu(\mathbf{D}_{i})}\big) }[/math] and [math]\displaystyle{ \xi_{i}=4\varepsilon_{i-1} }[/math], then: (i) The support of the solution [math]\displaystyle{ \hat{\mathbf{\Gamma}}_i }[/math] is contained in that of [math]\displaystyle{ \mathbf{\Gamma}_{i} }[/math], (ii) [math]\displaystyle{ \|\mathbf{\Gamma}_{i}-\hat\mathbf{\Gamma}_i\|_{2,\infty}\leq \varepsilon_{i} }[/math], and (iii) Any entry greater in absolute value than [math]\displaystyle{ \frac{\varepsilon_{i}}{\sqrt{\|\mathbf{\Gamma}_{i}\|_{0\infty}}} }[/math] is guaranteed to be recovered.
3. Applications of the Convolutional Sparse Coding Model: Image Inpainting
As a practical example, an efficient image inpainting method for color images via the CSC model is shown.[6] Consider the three-channel dictionary [math]\displaystyle{ \mathbf{D} \in \mathbb{R}^{N \times M \times 3} }[/math], where [math]\displaystyle{ \mathbf{d}_{c,m} }[/math] denotes the [math]\displaystyle{ m }[/math]-th atom at channel [math]\displaystyle{ c }[/math], represents signal [math]\displaystyle{ \mathbf{x} }[/math] by a single cross-channel sparse representation [math]\displaystyle{ \mathbf{\Gamma} }[/math], with stripes denoted as [math]\displaystyle{ \mathbf{z}_{i} }[/math]. Given an observation [math]\displaystyle{ \mathbf{y}=\{\mathbf{y}_{r}, \mathbf{y}_{g}, \mathbf{y}_{b}\} }[/math], where randomly chosen channels at unknown pixel locations are fixed to zero, in a similar way to impulse noise, the problem is formulated as: [math]\displaystyle{ \begin{aligned} \{\mathbf{\hat{z}}_{i}\}&=\underset{\{\mathbf{z}_{i}\}}{\text{argmin}}\frac{1}{2}\sum_{c}\bigg\|\sum_{i}\mathbf{d}_{c,i}\ast \mathbf{z}_{i} -\mathbf{y}_{c}\bigg\|_{2}^{2}+\lambda \sum_{i}\|\mathbf{z}_{i}\|_{1}.\end{aligned} }[/math] By means of ADMM,[9] the cost function is decoupled into simpler sub-problems, allowing an efficient [math]\displaystyle{ \mathbf{\Gamma} }[/math] estimation. Algorithm 2 describes the procedure, where [math]\displaystyle{ \hat{D}_{c,m} }[/math] is the DFT representation of [math]\displaystyle{ D_{c,m} }[/math], the convolutional matrix for the term [math]\displaystyle{ \mathbf{d}_{c,i}\ast \mathbf{z}_{i} }[/math]. Likewise, [math]\displaystyle{ \hat{\mathbf{x}}_{m} }[/math] and [math]\displaystyle{ \hat{\mathbf{z}}_{m} }[/math] correspond to the DFT representations of [math]\displaystyle{ \mathbf{x}_{m} }[/math] and [math]\displaystyle{ \mathbf{z}_{m} }[/math], respectively, [math]\displaystyle{ \mathcal{S}_{\beta}(.) }[/math] corresponds to the Soft-thresholding function with argument [math]\displaystyle{ \beta }[/math], and the [math]\displaystyle{ \ell_{1,2} }[/math] norm is defined as the [math]\displaystyle{ \ell_{2} }[/math] norm along the channel dimension [math]\displaystyle{ c }[/math] followed by the [math]\displaystyle{ \ell_{1} }[/math] norm along the spatial dimension [math]\displaystyle{ m }[/math]. The reader is referred to (,[6] Section II) for details on the ADMM implementation and the dictionary learning procedure.
Algorithm 2: Color image inpainting via the convolutional sparse coding model.
Input:
[math]\displaystyle{ \hat{\mathbf{D}}_{c,m} }[/math]: DFT of convolutional matrices [math]\displaystyle{ \mathbf{D}_{c,m} }[/math],
[math]\displaystyle{ \mathbf{y}=\{\mathbf{y}_{r},\mathbf{y}_{g},\mathbf{y}_{b}\} }[/math]: Color observation,
[math]\displaystyle{ \lambda }[/math]: Regularization parameter,
[math]\displaystyle{ \{\mu, \rho\} }[/math]: step sizes for ADMM,
tol: tolerance factor,
maxiters: maximum number of iterations.
-
-
- [math]\displaystyle{ k\gets k+1 }[/math]
-
Repeat
-
-
- [math]\displaystyle{ \{\hat{\mathbf{z}}_{m}\}^{(k+1)}\gets\underset{\{\hat{\mathbf{x}}_{m}\}}{\text{argmin}}\;\frac{1}{2}\sum_{c}\big\|\sum_{m}\hat{\mathbf{D}}_{c,m} \hat{\mathbf{z}}_{m}-\hat{\mathbf{y}}_{c} \big\|+\frac{\rho}{2}\sum_{m}\|\hat{\mathbf{z}}_{m}- (\hat{\mathbf{y}}_{m}+\hat{\mathbf{u}}_{m}^{(k)})\|_{2}^{2}. }[/math]
-
-
-
- [math]\displaystyle{ \{\mathbf{y}_{c,m}\}^{(k+1)}\gets \underset{\{\mathbf{y}_{c,m}\}}{\text{argmin}}\;\lambda \sum_{c}\sum_{m}\|\mathbf{y}_{c,m}\|_{1}+\mu\|\{\mathbf{x}_{c,m}^{(k+1)}\}\|_{2,1}+\frac{\rho}{2}\sum_{m}\|\mathbf{z}_{m}^{(k+1)}- (\mathbf{y}+\mathbf{u}_{m}^{(k)})\|_{2}^{2}. }[/math]
-
-
-
- [math]\displaystyle{ \mathbf{y}_{m}^{(k+1)}=\mathcal{S}_{\lambda/\rho}\big( \mathbf{x}_{m}^{(k+1)}+\mathbf{u}_{m}^{(k)} \big). }[/math]
-
-
-
- [math]\displaystyle{ k \gets k+1 }[/math]
-
Until [math]\displaystyle{ \|\{\mathbf{z}_{m}\}^{(k+1)}-\{\mathbf{z}_{m}\}^{(k)}\|_{2}\lt }[/math]tol or [math]\displaystyle{ i\gt }[/math] maxiters.
References
- Jianchao Yang; Wright, John; Huang, Thomas S; Yi Ma (November 2010). "Image Super-Resolution Via Sparse Representation". IEEE Transactions on Image Processing 19 (11): 2861–2873. doi:10.1109/TIP.2010.2050625. PMID 20483687. Bibcode: 2010ITIP...19.2861Y. https://dx.doi.org/10.1109%2FTIP.2010.2050625
- Wetzstein, Gordon; Heidrich, Wolfgang; Heide, Felix (2015). Fast and Flexible Convolutional Sparse Coding. pp. 5135–5143. https://www.cv-foundation.org/openaccess/content_cvpr_2015/html/Heide_Fast_and_Flexible_2015_CVPR_paper.html.
- Wohlberg, Brendt (2017). "SPORCO: A Python package for standard and convolutional sparse representations". Proceedings of the 16th Python in Science Conference: 1–8. doi:10.25080/shinma-7f4c6e7-001. http://conference.scipy.org/proceedings/scipy2017/brendt_wohlberg.html.
- Mairal, Julien; Bach, Francis; Ponce, Jean; Sapiro, Guillermo (2009). "Online Dictionary Learning for Sparse Coding". Proceedings of the 26th Annual International Conference on Machine Learning (ACM): 689–696. doi:10.1145/1553374.1553463. ISBN 9781605585161. https://dl.acm.org/citation.cfm?id=1553463.
- Papyan, Vardan; Sulam, Jeremias; Elad, Michael (1 November 2017). "Working Locally Thinking Globally: Theoretical Guarantees for Convolutional Sparse Coding". IEEE Transactions on Signal Processing 65 (21): 5687–5701. doi:10.1109/TSP.2017.2733447. Bibcode: 2017ITSP...65.5687P. https://dx.doi.org/10.1109%2FTSP.2017.2733447
- Wohlberg, Brendt (6–8 March 2016). "Convolutional sparse representation of color images". 2016 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI): 57–60. doi:10.1109/SSIAI.2016.7459174. ISBN 978-1-4673-9919-7. https://dx.doi.org/10.1109%2FSSIAI.2016.7459174
- Papyan, Vardan; Romano, Yaniv; Elad, Michael (2017). "Convolutional Neural Networks Analyzed via Convolutional Sparse Coding". J. Mach. Learn. Res. 18 (1): 2887–2938. ISSN 1532-4435. Bibcode: 2016arXiv160708194P. http://dl.acm.org/citation.cfm?id=3122009.3176827.
- Beck, Amir; Teboulle, Marc (January 2009). "A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems". SIAM Journal on Imaging Sciences 2 (1): 183–202. doi:10.1137/080716542. https://dx.doi.org/10.1137%2F080716542
- Boyd, Stephen (2010). "Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers". Foundations and Trends in Machine Learning 3 (1): 1–122. doi:10.1561/2200000016. ISSN 1935-8237. https://dx.doi.org/10.1561%2F2200000016

