 +1 credit
+1 credit
Video Upload Options
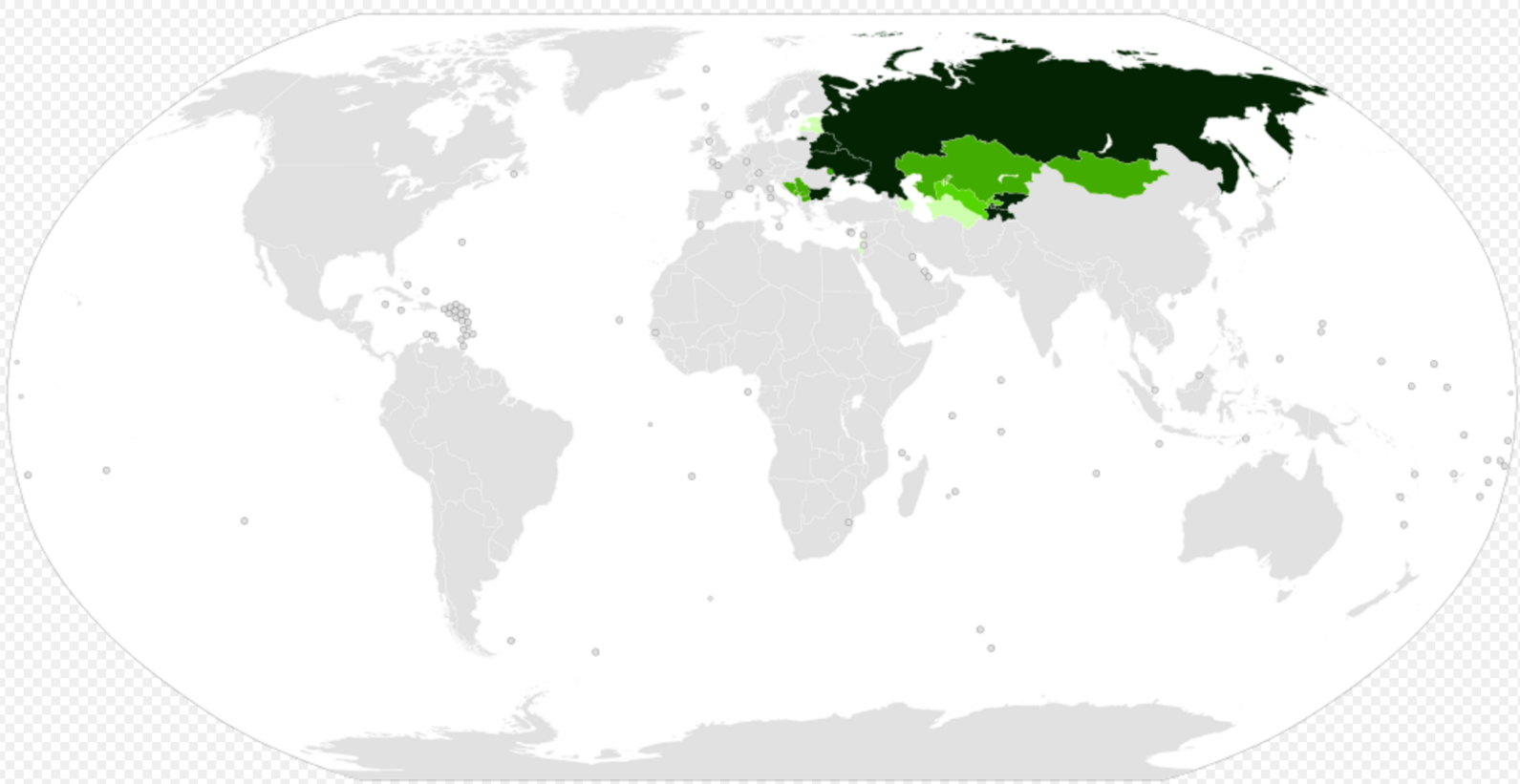
The Cyrillic script (/sɪˈrɪlɪk/ sə-RIL-ik) is a writing system used for various languages across Eurasia and is used as the national script in various Slavic, Turkic, Mongolic, Uralic, Caucasian and Iranic-speaking countries in Southeastern Europe, Eastern Europe, the Caucasus, Central Asia, North Asia and East Asia. (As of 2019), around 250 million people in Eurasia use Cyrillic as the official script for their national languages, with Russia accounting for about half of them. With the accession of Bulgaria to the European Union on 1 January 2007, Cyrillic became the third official script of the European Union, following the Latin and Greek alphabets. In the 9th century AD, the Bulgarian tsar Simeon I the Great – following the cultural and political course of his father Boris I – commissioned a new script, the Early Cyrillic alphabet, to be made at the Preslav Literary School in the First Bulgarian Empire, which would replace the Glagolitic script, produced earlier by Saints Cyril and Methodius and the same disciples that created the new Slavic script in Bulgaria. The usage of the Cyrillic script in Bulgaria was made official in 893. The new script became the basis of alphabets used in various languages, especially those of Orthodox Slavic origin, and non-Slavic languages influenced by Bulgarian. For centuries Cyrillic was used by Catholic and Muslim Slavs too (see Bosnian Cyrillic). Cyrillic is derived from the Greek uncial script, augmented by letters from the older Glagolitic alphabet, including some ligatures. These additional letters were used for Old Church Slavonic sounds not found in Greek. The script is named in honor of the Saint Cyril, one of the two Byzantine brothers, Saints Cyril and Methodius, who created the Glagolitic alphabet earlier on. Modern scholars believe that Cyrillic was developed and formalized by the early disciples of Cyril and Methodius in the Preslav Literary School, the most important early literary and cultural centre of the First Bulgarian Empire and of all Slavs. The school developed the Cyrillic script: The earliest datable Cyrillic inscriptions have been found in the area of Preslav. They have been found in the medieval city itself, and at nearby Patleina Monastery, both in present-day Shumen Province, in the Ravna Monastery and in the Varna Monastery. With the orthographic reform of Saint Evtimiy of Tarnovo and other prominent representatives of the Tarnovo Literary School (14th and 15th centuries) such as Gregory Tsamblak or Constantine of Kostenets the school influenced Russian, Serbian, Wallachian and Moldavian medieval culture. That is famous in Russia as the second South-Slavic influence. In the early 18th century, the Cyrillic script used in Russia was heavily reformed by Peter the Great, who had recently returned from his Grand Embassy in Western Europe. The new letterforms, called the Civil script, became closer to those of the Latin alphabet; several archaic letters were abolished and several letters were designed by Peter himself. Letters became distinguished between upper and lower case. West European typography culture was also adopted. The pre-reform forms of letters called 'Полуустав' were notably kept for use in Church Slavonic and are sometimes used in Russian even today, especially if one wants to give a text a 'Slavic' or 'archaic' feel.
1. Letters
Cyrillic script spread throughout the East Slavic and some South Slavic territories, being adopted for writing local languages, such as Old East Slavic. Its adaptation to local languages produced a number of Cyrillic alphabets, discussed below.
| А | Б | В | Г | Д | Е | Ж | Ꙃ[3] | Ꙁ | И | І | К | Л | М | Н | О | П | Р | С | Т | ОУ[4] | Ф |
| Х | Ѡ | Ц | Ч | Ш | Щ | Ъ | ЪІ[5] | Ь | Ѣ | Ꙗ | Ѥ | Ю | Ѫ | Ѭ | Ѧ | Ѩ | Ѯ | Ѱ | Ѳ | Ѵ | Ҁ[6] |
Capital and lowercase letters were not distinguished in old manuscripts.

Yeri (Ы) was originally a ligature of Yer and I (Ъ + І = Ы). Iotation was indicated by ligatures formed with the letter І: Ꙗ (not an ancestor of modern Ya, Я, which is derived from Ѧ), Ѥ, Ю (ligature of І and ОУ), Ѩ, Ѭ. Sometimes different letters were used interchangeably, for example И = І = Ї, as were typographical variants like О = Ѻ. There were also commonly used ligatures like ѠТ = Ѿ.
The letters also had numeric values, based not on Cyrillic alphabetical order, but inherited from the letters' Greek ancestors.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| А | В | Г | Д | Є | Ѕ | З | И | Ѳ |
| 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 |
| І | К | Л | М | Н | Ѯ | Ѻ | П | Ч (Ҁ) |
| 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
| Р | С | Т | Ѵ | Ф | Х | Ѱ | Ѿ | Ц |
The early Cyrillic alphabet is difficult to represent on computers. Many of the letterforms differed from those of modern Cyrillic, varied a great deal in manuscripts, and changed over time. Few fonts include glyphs sufficient to reproduce the alphabet. In accordance with Unicode policy, the standard does not include letterform variations or ligatures found in manuscript sources unless they can be shown to conform to the Unicode definition of a character.
The Unicode 5.1 standard, released on 4 April 2008, greatly improves computer support for the early Cyrillic and the modern Church Slavonic language. In Microsoft Windows, the Segoe UI user interface font is notable for having complete support for the archaic Cyrillic letters since Windows 8.
| Slavic Cyrillic letters | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| А A |
Б Be |
В Ve |
Г Ge (Ghe) |
Ґ Ghe upturn |
Д De |
Ђ Dje |
Ѓ Gje |
Е Ye |
Ё Yo |
Є Ukrainian Ye |
Ж Zhe |
| З Ze |
З́ Zje |
Ѕ Dze |
И I |
І Dotted I |
Ї Yi |
Й Short I |
Ј Je |
К Ka |
Л El |
Љ Lje |
М Em |
| Н En |
Њ Nje |
О O |
П Pe |
Р Er |
С Es |
С́ Sje |
Т Te |
Ћ Tje |
Ќ Kje |
У U |
Ў Short U |
| Ф Ef |
Х Kha |
Ц Tse |
Ч Che |
Џ Dzhe |
Ш Sha |
Щ Sha with descender (Shcha) |
Ъ Hard sign (Yer) |
Ы Yery |
Ь Soft sign (Yeri) |
Э E |
Ю Yu |
| Я Ya |
|||||||||||
| Examples of non-Slavic Cyrillic letters (see List of Cyrillic letters for more) | |||||||||||
| Ӑ A with breve |
Ә Schwa |
Ӕ Ae |
Ғ Ghayn |
Ҕ Ge with middle hook |
Ӻ Ghayn with hook |
Ӷ Ge with descender |
Ӂ Zhe with breve |
Ӝ Zhe with diaeresis |
Ӡ Abkhazian Dze |
Ҡ Bashkir Qa |
Ҟ Ka with stroke |
| Ӊ En with tail |
Ң En with descender |
Ӈ En with hook |
Ҥ En-ghe |
Ө Oe |
Ҩ O-hook |
Ҏ Er with tick |
Ҫ The |
У̃ U with tilde |
Ӯ U with macron |
Ӱ U with diaeresis |
Ӳ U with double acute |
| Ү Ue |
Ҳ Kha with descender |
Ӽ Kha with hook |
Ӿ Kha with stroke |
Һ Shha (He) |
Ҵ Te Tse |
Ҷ Che with descender |
Ӌ Khakassian Che |
Ҹ Che with vertical stroke |
Ҽ Abkhazian Che |
Ҍ Semisoft sign |
Ӏ Palochka |
| Cyrillic letters used in the past | |||||||||||
| Ꙗ A iotified |
Ѥ E iotified |
Ѧ Yus small |
Ѫ Yus big |
Ѩ Yus small iotified |
Ѭ Yus big iotified |
Ѯ Ksi |
Ѱ Psi |
Ꙟ Yn |
Ѳ Fita |
Ѵ Izhitsa |
Ѷ Izhitsa okovy |
| Ҁ Koppa |
ОУ Uk |
Ѡ Omega |
Ѿ Ot |
Ѣ Yat |
|||||||
2. Letterforms and Typography
The development of Cyrillic typography passed directly from the medieval stage to the late Baroque, without a Renaissance phase as in Western Europe. Late Medieval Cyrillic letters (categorized as vyaz' and still found on many icon inscriptions today) show a marked tendency to be very tall and narrow, with strokes often shared between adjacent letters.
Peter the Great, Tsar of Russia, mandated the use of westernized letter forms (ru) in the early 18th century. Over time, these were largely adopted in the other languages that use the script. Thus, unlike the majority of modern Greek fonts that retained their own set of design principles for lower-case letters (such as the placement of serifs, the shapes of stroke ends, and stroke-thickness rules, although Greek capital letters do use Latin design principles), modern Cyrillic fonts are much the same as modern Latin fonts of the same font family. The development of some Cyrillic computer typefaces from Latin ones has also contributed to the visual Latinization of Cyrillic type.
2.1. Lowercase Forms

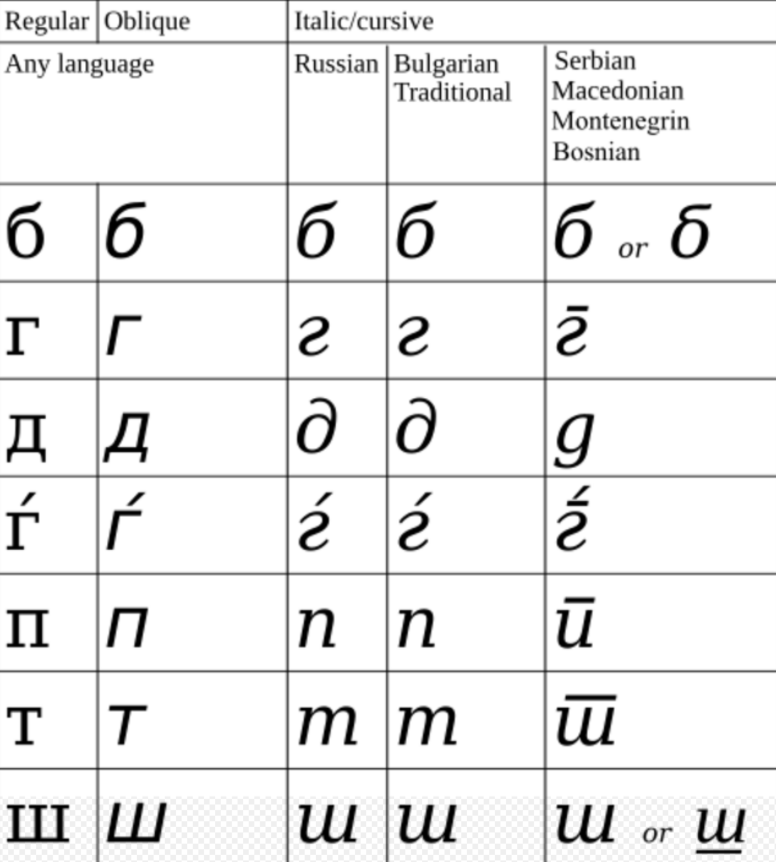
Cyrillic uppercase and lowercase letter forms are not as differentiated as in Latin typography. Upright Cyrillic lowercase letters are essentially small capitals (with exceptions: Cyrillic ⟨а⟩, ⟨е⟩, ⟨і⟩, ⟨ј⟩, ⟨р⟩, and ⟨у⟩ adopted Western lowercase shapes, lowercase ⟨ф⟩ is typically designed under the influence of Latin ⟨p⟩, lowercase ⟨б⟩, ⟨ђ⟩ and ⟨ћ⟩ are traditional handwritten forms), although a good-quality Cyrillic typeface will still include separate small-caps glyphs.[7]
Cyrillic fonts, as well as Latin ones, have roman and italic types (practically all popular modern fonts include parallel sets of Latin and Cyrillic letters, where many glyphs, uppercase as well as lowercase, are simply shared by both). However, the native font terminology in most Slavic languages (for example, in Russian) does not use the words "roman" and "italic" in this sense.[8] Instead, the nomenclature follows German naming patterns:
- Roman type is called pryamoy shrift ("upright type")—compare with Normalschrift ("regular type") in German
- Italic type is called kursiv ("cursive") or kursivniy shrift ("cursive type")—from the German word Kursive, meaning italic typefaces and not cursive writing
- Cursive handwriting is rukopisniy shrift ("handwritten type")—in German: Kurrentschrift or Laufschrift, both meaning literally 'running type'
- A (mechanically) sloped oblique type of sans-serif faces is naklonniy shrift ("sloped" or "slanted type").
- A boldfaced type is called poluzhirniy shrift ("semi-bold type"), because there existed fully boldfaced shapes that have been out of use since the beginning of the 20th century.
2.2. Italic and Cursive Forms
Similarly to Latin fonts, italic and cursive types of many Cyrillic letters (typically lowercase; uppercase only for handwritten or stylish types) are very different from their upright roman types. In certain cases, the correspondence between uppercase and lowercase glyphs does not coincide in Latin and Cyrillic fonts: for example, italic Cyrillic ⟨т⟩ is the lowercase counterpart of ⟨Т⟩ not of ⟨М⟩.
| upright | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| italic | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Note: in some fonts or styles, ⟨д⟩, i.e. the lowercase italic Cyrillic ⟨д⟩, may look like Latin ⟨g⟩, and ⟨т⟩, i.e. lowercase italic Cyrillic ⟨т⟩, may look like small-capital italic ⟨T⟩.
In Standard Serbian, as well as in Macedonian,[9] some italic and cursive letters are allowed to be different to more closely resemble the handwritten letters. The regular (upright) shapes are generally standardized in small caps form,[10].
| Russian | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Serbian | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
In Bulgarian typography, many lowercase letterforms may more closely resemble the cursive forms on the one hand and Latin glyphs on the other hand, e.g. by having an ascender or descender or by using rounded arcs instead of sharp corners.[11][12] Sometimes, uppercase letters may have a different shape as well, e.g. more triangular, Д and Л, like Greek delta Δ and lambda Λ.
| default | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ь | ю | я |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bulgarian | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ь | ю | я |
| faux | а | δ | ϐ | ƨ | ɡ | е | жl | ȝ | u | ŭ | k | ʌ | м | н | о | n | р | с | m | у | ɸ | х | u̡ | ч | ɯ | ɯ̡ | ъ | ƅ | lo | я |
Notes: Depending on fonts available, the Bulgarian row may appear identical to the Russian row. Unicode approximations are used in the faux row to ensure it can be rendered properly across all systems; in some cases, such as ж with k-like ascender, no such approximation exists.
2.3. Accessing Variant Forms
Computer fonts typically default to the Central/Eastern, Russian letterforms, and require the use of OpenType Layout (OTL) features to display the Western, Bulgarian or Southern, Serbian/Macedonian forms. Depending on the choices of the font manufacturer, they may either be automatically activated by the local variant locl feature for text tagged with an appropriate language code, or the author needs to opt-in by activating a stylistic set ss## or character variant cv## feature. These solutions only enjoy partial support and may render with default glyphs in certain software configurations.[13]
3. Cyrillic Alphabets
Among others, Cyrillic is the standard script for writing the following languages:
- Slavic languages: Belarusian, Bulgarian, Macedonian, Russian, Rusyn, Serbo-Croatian (Standard Serbian, Bosnian, and Montenegrin), Ukrainian
- Non-Slavic languages of Russia: Abkhaz, Adyghe, Azerbaijani (in Dagestan), Bashkir, Chuvash, Erzya, Kabardian, Kildin Sami, Komi, Dungan, Mari, Moksha, Ossetian, Romani, Sakha/Yakut, Tatar, Tuvan, Udmurt, Yuit (Yupik)
- Non-Slavic languages in other countries: Aleut (now mostly in church texts), Uzbek (officially replaced by Latin script, but still in wide use), Kazakh (to be replaced by Latin script by 2025[14]), Kyrgyz, Mongolian (to also be written with traditional Mongolian script by 2025[15]), Tajik, Tlingit (now only in church texts), Yupik (in Alaska)
The Cyrillic script has also been used for languages of Alaska,[16] Slavic Europe (except for Western Slavic and some Southern Slavic), the Caucasus, the languages of Idel-Ural, Siberia, and the Russian Far East.
The first alphabet derived from Cyrillic was Abur, used for the Komi language. Other Cyrillic alphabets include the Molodtsov alphabet for the Komi language and various alphabets for Caucasian languages.
4. Name

Since the script was conceived and popularised by the followers of Cyril and Methodius, rather than by Cyril and Methodius themselves, its name denotes homage rather than authorship. The name "Cyrillic" often confuses people who are not familiar with the script's history, because it does not identify a country of origin (in contrast to the "Greek alphabet"). Among the general public, it is often called "the Russian alphabet," because Russian is the most popular and influential alphabet based on the script. Some Bulgarian intellectuals, notably Stefan Tsanev, have expressed concern over this, and have suggested that the Cyrillic script be called the "Bulgarian alphabet" instead, for the sake of historical accuracy.[17] It must be noted here that 'alphabet' is not the same as 'script' (e.g. the letter Її has existed in the Cyrillic script since its very invention and is still used in Ukrainian, but is absent in the modern Bulgarian alphabet, that is Cyrillic as used in Bulgarian), so the accurate name is actually 'the Bulgarian script'.
In Bulgarian, Macedonian, Russian, Serbian, Czech and Slovak, the Cyrillic alphabet is also known as azbuka, derived from the old names of the first two letters of most Cyrillic alphabets (just as the term alphabet came from the first two Greek letters alpha and beta). In Czech and Slovak, which have never used Cyrillic, "azbuka" refers to Cyrillic and contrasts with "abeceda", which refers to the local Latin script and is composed of the names of the first letters (A, B, C, and D). In Russian, syllabaries, especially the Japanese kana, are commonly referred to as 'syllabic azbukas' rather than 'syllabic scripts'.
5. History

The Cyrillic script was created in the First Bulgarian Empire.[18] Its first variant, the Early Cyrillic alphabet, was created at the Preslav Literary School. A number of prominent Bulgarian writers and scholars worked at the school, including Naum of Preslav until 893; Constantine of Preslav; Joan Ekzarh (also transcr. John the Exarch); and Chernorizets Hrabar, among others. The school was also a centre of translation, mostly of Byzantine authors. The Cyrillic script is derived from the Greek uncial script letters, augmented by ligatures and consonants from the older Glagolitic alphabet for sounds not found in Greek. Tradition holds that Glagolitic and Cyrillic were formalized by Saints Cyril and Methodius and their disciples, like the Saints Naum, Clement, Angelar, and Sava. They spread and teach Christianity in the whole of Bulgaria.[19][20][21][22] Paul Cubberley posits that although Cyril may have codified and expanded Glagolitic, it was his students in the First Bulgarian Empire under Tsar Simeon the Great that developed Cyrillic from the Greek letters in the 890s as a more suitable script for church books.[18] Cyrillic spread among other Slavic peoples, as well as among non-Slavic Vlachs.
Cyrillic and Glagolitic were used for the Church Slavonic language, especially the Old Church Slavonic variant. Hence expressions such as "И is the tenth Cyrillic letter" typically refer to the order of the Church Slavonic alphabet; not every Cyrillic alphabet uses every letter available in the script. The Cyrillic script came to dominate Glagolitic in the 12th century
The literature produced in the Old Bulgarian language soon spread north and became the lingua franca of the Balkans and Eastern Europe, where it came to also be known as Old Church Slavonic.[23][24][25][26][27]
The alphabet used for the modern Church Slavonic language in Eastern Orthodox and Eastern Catholic rites still resembles early Cyrillic. However, over the course of the following millennium, Cyrillic adapted to changes in spoken language, developed regional variations to suit the features of national languages, and was subjected to academic reform and political decrees. A notable example of such linguistic reform can be attributed to Vuk Stefanović Karadžić who updated the Serbian Cyrillic alphabet by removing certain graphemes no longer represented in the vernacular, and introducing graphemes specific to Serbian (i.e. Љ Њ Ђ Ћ Џ Ј), distancing it from Church Slavonic alphabet in use prior to the reform. Today, many languages in the Balkans, Eastern Europe, and northern Eurasia are written in Cyrillic alphabets.
6. Usage of Cyrillic Versus Other Scripts
6.1. Latin Script
A number of languages written in a Cyrillic alphabet have also been written in a Latin alphabet, such as Azerbaijani, Uzbek, Serbian and Romanian (in the Republic of Moldova until 1989, in Romania throughout the 19th century). After the disintegration of the Soviet Union in 1991, some of the former republics officially shifted from Cyrillic to Latin. The transition is complete in most of Moldova (except the breakaway region of Transnistria, where Moldovan Cyrillic is official), Turkmenistan, and Azerbaijan. Uzbekistan still uses both systems, and Kazakhstan has officially begun a transition from Cyrillic to Latin (scheduled to be complete by 2025). The Russia n government has mandated that Cyrillic must be used for all public communications in all federal subjects of Russia, to promote closer ties across the federation. This act was controversial for speakers of many Slavic languages; for others, such as Chechen and Ingush speakers, the law had political ramifications. For example, the separatist Chechen government mandated a Latin script which is still used by many Chechens. Those in the diaspora especially refuse to use the Chechen Cyrillic alphabet, which they associate with Russian imperialism.

Standard Serbian uses both the Cyrillic and Latin scripts. Cyrillic is nominally the official script of Serbia's administration according to the Serbian constitution;[28] however, the law does not regulate scripts in standard language, or standard language itself by any means. In practice the scripts are equal, with Latin being used more often in a less official capacity.[29]
The Zhuang alphabet, used between the 1950s and 1980s in portions of the People's Republic of China, used a mixture of Latin, phonetic, numeral-based, and Cyrillic letters. The non-Latin letters, including Cyrillic, were removed from the alphabet in 1982 and replaced with Latin letters that closely resembled the letters they replaced.
6.2. Romanization
There are various systems for Romanization of Cyrillic text, including transliteration to convey Cyrillic spelling in Latin letters, and transcription to convey pronunciation.
Standard Cyrillic-to-Latin transliteration systems include:
- Scientific transliteration, used in linguistics, is based on the Bosnian and Croatian Latin alphabet.
- The Working Group on Romanization Systems[30] of the United Nations recommends different systems for specific languages. These are the most commonly used around the world.
- ISO 9:1995, from the International Organization for Standardization.
- American Library Association and Library of Congress Romanization tables for Slavic alphabets (ALA-LC Romanization), used in North American libraries.
- BGN/PCGN Romanization (1947), United States Board on Geographic Names & Permanent Committee on Geographical Names for British Official Use).
- GOST 16876, a now defunct Soviet transliteration standard. Replaced by GOST 7.79, which is ISO 9 equivalent.
- Various informal romanizations of Cyrillic, which adapt the Cyrillic script to Latin and sometimes Greek glyphs for compatibility with small character sets.
See also Romanization of Belarusian, Bulgarian, Kyrgyz, Russian, Macedonian and Ukrainian.
6.3. Cyrillization
Representing other writing systems with Cyrillic letters is called Cyrillization.
7. Computer Encoding
7.1. Unicode
As of Unicode version 13.0, Cyrillic letters, including national and historical alphabets, are encoded across several blocks:
- Cyrillic: U+0400–U+04FF
- Cyrillic Supplement: U+0500–U+052F
- Cyrillic Extended-A: U+2DE0–U+2DFF
- Cyrillic Extended-B: U+A640–U+A69F
- Cyrillic Extended-C: U+1C80–U+1C8F
- Phonetic Extensions: U+1D2B, U+1D78
- Combining Half Marks: U+FE2E–U+FE2F
The characters in the range U+0400 to U+045F are essentially the characters from ISO 8859-5 moved upward by 864 positions. The characters in the range U+0460 to U+0489 are historic letters, not used now. The characters in the range U+048A to U+052F are additional letters for various languages that are written with Cyrillic script.
Unicode as a general rule does not include accented Cyrillic letters. A few exceptions include:
- combinations that are considered as separate letters of respective alphabets, like Й, Ў, Ё, Ї, Ѓ, Ќ (as well as many letters of non-Slavic alphabets);
- two most frequent combinations orthographically required to distinguish homonyms in Bulgarian and Macedonian: Ѐ, Ѝ;
- a few Old and New Church Slavonic combinations: Ѷ, Ѿ, Ѽ.
To indicate stressed or long vowels, combining diacritical marks can be used after the respective letter (for example, U+0301 ◌́ COMBINING ACUTE ACCENT: ы́ э́ ю́ я́ etc.).
Some languages, including Church Slavonic, are still not fully supported.
Unicode 5.1, released on 4 April 2008, introduces major changes to the Cyrillic blocks. Revisions to the existing Cyrillic blocks, and the addition of Cyrillic Extended A (2DE0 ... 2DFF) and Cyrillic Extended B (A640 ... A69F), significantly improve support for the early Cyrillic alphabet, Abkhaz, Aleut, Chuvash, Kurdish, and Moksha.[31]
7.2. Other
Punctuation for Cyrillic text is similar to that used in European Latin-alphabet languages.
Other character encoding systems for Cyrillic:
- CP866 – 8-bit Cyrillic character encoding established by Microsoft for use in MS-DOS also known as GOST-alternative. Cyrillic characters go in their native order, with a "window" for pseudographic characters.
- ISO/IEC 8859-5 – 8-bit Cyrillic character encoding established by International Organization for Standardization
- KOI8-R – 8-bit native Russian character encoding. Invented in the USSR for use on Soviet clones of American IBM and DEC computers. The Cyrillic characters go in the order of their Latin counterparts, which allowed the text to remain readable after transmission via a 7-bit line that removed the most significant bit from each byte—the result became a very rough, but readable, Latin transliteration of Cyrillic. Standard encoding of early 1990s for Unix systems and the first Russian Internet encoding.
- KOI8-U – KOI8-R with addition of Ukrainian letters.
- MIK – 8-bit native Bulgarian character encoding for use in Microsoft DOS.
- Windows-1251 – 8-bit Cyrillic character encoding established by Microsoft for use in Microsoft Windows. The simplest 8-bit Cyrillic encoding—32 capital chars in native order at 0xc0–0xdf, 32 usual chars at 0xe0–0xff, with rarely used "YO" characters somewhere else. No pseudographics. Former standard encoding in some Linux distributions for Belarusian and Bulgarian, but currently displaced by UTF-8.
- GOST-main.
- GB 2312 – Principally simplified Chinese encodings, but there are also the basic 33 Russian Cyrillic letters (in upper- and lower-case).
- JIS and Shift JIS – Principally Japanese encodings, but there are also the basic 33 Russian Cyrillic letters (in upper- and lower-case).
7.3. Keyboard Layouts
Each language has its own standard keyboard layout, adopted from typewriters. With the flexibility of computer input methods, there are also transliterating or phonetic/homophonic keyboard layouts made for typists who are more familiar with other layouts, like the common English QWERTY keyboard. When practical Cyrillic keyboard layouts or fonts are unavailable, computer users sometimes use transliteration or look-alike "volapuk" encoding to type in languages that are normally written with the Cyrillic alphabet.
References
- А. Н. Стеценко. Хрестоматия по Старославянскому Языку, 1984.
- Cubberley, Paul. The Slavic Alphabets, 1996.
- Variant form: Also written S
- Variant form Ꙋ
- Variant form ЪИ
- Lunt, Horace G. Old Church Slavonic Grammar, Seventh Edition, 2001.
- Bringhurst (2002) writes "in Cyrillic, the difference between normal lower case and small caps is more subtle than it is in the Latin or Greek alphabets, ..." (p 32) and "in most Cyrillic faces, the lower case is close in color and shape to Latin small caps" (p 107).
- Name ital'yanskiy shrift (Italian font) in Russian refers to a particular font family JPG , whereas rimskiy shrift (roman font) is just a synonym for Latin font, Latin alphabet. http://citforum.univ.kiev.ua/open_source/fonts/theory/thumbs/ris320.jpg
- Pravopis na makedonskiot jazik. Skopje: Institut za makedonski jazik Krste Misirkov. 2017. p. 3. ISBN 978-608-220-042-2. http://www.pravopis.mk/sites/default/files/Pravopis-2017.PDF.
- Peshikan, Mitar; Jerković, Jovan; Pižurica, Mato (1994). Pravopis srpskoga jezika. Beograd: Matica Srpska. p. 42. ISBN 978-86-363-0296-5.
- What You Need to Know When Making Cyrillic Typefaces https://medium.com/type-thursday/what-you-need-to-know-when-making-cyrillic-typefaces-f8957a04ad94
- Cyrillicsly: Two Cyrillics: a critical history I https://cargocollective.com/cyrillicslyblog/Two-Cyrillics-a-critical-history-I
- Cyrillic script variations and the importance of localisation - Fontshare.com https://www.fontsmith.com/blog/2016/10/12/cyrillic-script-variations-and-the-importance-of-localisation
- "Alphabet soup as Kazakh leader orders switch from Cyrillic to Latin letters" (in en-GB). The Guardian. Reuters. 2017-10-26. ISSN 0261-3077. https://www.theguardian.com/world/2017/oct/26/kazakhstan-switch-official-alphabet-cyrillic-latin.
- The Times (2020-03-20). "Mongolia to restore traditional alphabet by 2025" (in en-GB). News.MN. https://news.mn/en/791396.
- "Orthodox Language Texts", Retrieved 2011-06-20 http://www.asna.ca/alaska/
- Tsanev, Stefan. Български хроники, том 4 (Bulgarian Chronicles, Volume 4), Sofia, 2009, p. 165
- Paul Cubberley (1996) "The Slavic Alphabets". In Daniels and Bright, eds. The World's Writing Systems. Oxford University Press. ISBN:0-19-507993-0.
- Columbia Encyclopedia, Sixth Edition. 2001–05, s.v. "Cyril and Methodius, Saints"; Encyclopædia Britannica, Encyclopædia Britannica Incorporated, Warren E. Preece – 1972, p.846, s.v., "Cyril and Methodius, Saints" and "Eastern Orthodoxy, Missions ancient and modern"; Encyclopedia of World Cultures, David H. Levinson, 1991, p.239, s.v., "Social Science"; Eric M. Meyers, The Oxford Encyclopedia of Archaeology in the Near East, p.151, 1997; Lunt, Slavic Review, June, 1964, p. 216; Roman Jakobson, Crucial problems of Cyrillo-Methodian Studies; Leonid Ivan Strakhovsky, A Handbook of Slavic Studies, p.98; V. Bogdanovich, History of the ancient Serbian literature, Belgrade, 1980, p.119
- The Columbia Encyclopaedia, Sixth Edition. 2001–05, O.Ed. Saints Cyril and Methodius "Cyril and Methodius, Saints) 869 and 884, respectively, "Greek missionaries, brothers, called Apostles to the Slavs and fathers of Slavonic literature."
- Encyclopædia Britannica, Major alphabets of the world, Cyrillic and Glagolitic alphabets, 2008, O.Ed. "The two early Slavic alphabets, the Cyrillic and the Glagolitic, were invented by St. Cyril, or Constantine (c. 827–869), and St. Methodii (c. 825–884). These men from Thessaloniki who became apostles to the southern Slavs, whom they converted to Christianity."
- Template:ODB
- "On the relationship of old Church Slavonic to the written language of early Rus'" Horace G. Lunt; Russian Linguistics, Volume 11, Numbers 2–3 / January, 1987
- Schenker, Alexander (1995). The Dawn of Slavic. Yale University Press. pp. 185–186, 189–190.
- Lunt, Horace (2001). Old Church Slavonic Grammar. Mouton de Gruyter. pp. 3–4. https://archive.org/details/oldchurchslavoni00lunt.
- Wien, Lysaght (1983). Old Church Slavonic (Old Bulgarian)-Middle Greek-Modern English dictionary. Verlag Bruder Hollinek.
- Benjamin W. Fortson. Indo-European Language and Culture: An Introduction, p. 374
- Serbian constitution http://www.ustavni.sud.rs/page/view/en-GB/235-100028/constitution
- "Serbian signs of the times are not in Cyrillic". Christian Science Monitor. 2008-05-29. http://www.csmonitor.com/World/Europe/2008/0529/p20s01-woeu.html.
- UNGEGN Working Group on Romanization Systems http://www.eki.ee/wgrs/
- "IOS Universal Multiple-Octet Coded Character Set". http://std.dkuug.dk/jtc1/sc2/wg2/docs/n3194.pdf.


{kind=link}