 +1 credit
+1 credit
Video Upload Options
Stencil codes are a class of iterative kernels which update array elements according to some fixed pattern, called a stencil. They are most commonly found in the codes of computer simulations, e.g. for computational fluid dynamics in the context of scientific and engineering applications. Other notable examples include solving partial differential equations, the Jacobi kernel, the Gauss–Seidel method, image processing and cellular automata. The regular structure of the arrays sets stencil codes apart from other modeling methods such as the Finite element method. Most finite difference codes which operate on regular grids can be formulated as stencil codes.
1. Definition
Stencil codes perform a sequence of sweeps (called timesteps) through a given array.[1] Generally this is a 2- or 3-dimensional regular grid.[2] The elements of the arrays are often referred to as cells. In each timestep, the stencil code updates all array elements.[1] Using neighboring array elements in a fixed pattern (called the stencil), each cell's new value is computed. In most cases boundary values are left unchanged, but in some cases (e.g. LBM codes) those need to be adjusted during the computation as well. Since the stencil is the same for each element, the pattern of data accesses is repeated.[3]
More formally, we may define stencil codes as a 5-tuple [math]\displaystyle{ (I, S, S_0, s, T) }[/math] with the following meaning:[2]
- [math]\displaystyle{ I = \prod_{i=1}^k [0, \ldots, n_i] }[/math] is the index set. It defines the topology of the array.
- [math]\displaystyle{ S }[/math] is the (not necessarily finite) set of states, one of which each cell may take on on any given timestep.
- defines the initial state of the system at time 0.
- is the stencil itself and describes the actual shape of the neighborhood. There are [math]\displaystyle{ l }[/math] elements in the stencil.
- [math]\displaystyle{ T\colon S^l \to S }[/math] is the transition function which is used to determine a cell's new state, depending on its neighbors.
Since I is a k-dimensional integer interval, the array will always have the topology of a finite regular grid. The array is also called simulation space and individual cells are identified by their index [math]\displaystyle{ c \in I }[/math]. The stencil is an ordered set of [math]\displaystyle{ l }[/math] relative coordinates. We can now obtain for each cell [math]\displaystyle{ c }[/math] the tuple of its neighbors indices [math]\displaystyle{ I_c }[/math]
- [math]\displaystyle{ I_c = \{j \mid \exists x \in s: j = c + x\} \, }[/math]
Their states are given by mapping the tuple [math]\displaystyle{ I_c }[/math] to the corresponding tuple of states [math]\displaystyle{ N_i(c) }[/math], where [math]\displaystyle{ N_i\colon I \to S^l }[/math] is defined as follows:
- [math]\displaystyle{ N_i(c) = (s_1, \ldots, s_l) \text{ with } s_j = S_i(I_c(j)) \, }[/math]
This is all we need to define the system's state for the following time steps with :
Note that [math]\displaystyle{ S_i }[/math] is defined on [math]\displaystyle{ \Z^k }[/math] and not just on [math]\displaystyle{ I }[/math] since the boundary conditions need to be set, too. Sometimes the elements of [math]\displaystyle{ I_c }[/math] may be defined by a vector addition modulo the simulation space's dimension to realize toroidal topologies:
- [math]\displaystyle{ I_c = \{j \mid \exists x \in s: j = ((c + x) \mod(n_1, \ldots, n_k))\} }[/math]
This may be useful for implementing periodic boundary conditions, which simplifies certain physical models.
Example: 2D Jacobi Iteration
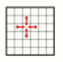
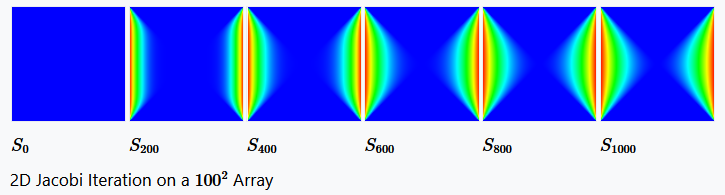
To illustrate the formal definition, we'll have a look at how a two dimensional Jacobi iteration can be defined. The update function computes the arithmetic mean of a cell's four neighbors. In this case we set off with an initial solution of 0. The left and right boundary are fixed at 1, while the upper and lower boundaries are set to 0. After a sufficient number of iterations, the system converges against a saddle-shape.
- [math]\displaystyle{ \begin{align} I & = [0, \ldots, 99]^2 \\ S & = \R \\ S_0 &: \Z^2 \to \R \\ S_0((x, y)) & = \begin{cases} 1, & x \lt 0 \\ 0, & 0 \le x \lt 100 \\ 1, & x \ge 100 \end{cases}\\ s & = ((0, -1), (-1, 0), (1, 0), (0, 1)) \\ T &\colon \R^4 \to \R \\ T((x_1, x_2, x_3, x_4)) & = 0.25 \cdot (x_1 + x_2 + x_3 + x_4) \end{align} }[/math]
2. Stencils
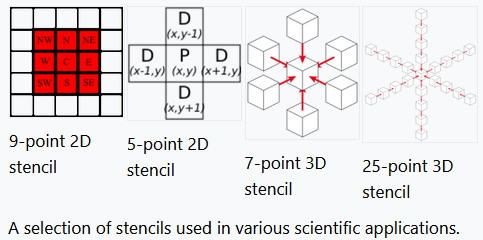
The shape of the neighborhood used during the updates depends on the application itself. The most common stencils are the 2D or 3D versions of the von Neumann neighborhood and Moore neighborhood. The example above uses a 2D von Neumann stencil while LBM codes generally use its 3D variant. Conway's Game of Life uses the 2D Moore neighborhood. That said, other stencils such as a 25-point stencil for seismic wave propagation[4] can be found, too.
3. Implementation Issues
Many simulation codes may be formulated naturally as stencil codes. Since computing time and memory consumption grow linearly with the number of array elements, parallel implementations of stencil codes are of paramount importance to research.[5] This is challenging since the computations are tightly coupled (because of the cell updates depending on neighboring cells) and most stencil codes are memory bound (i.e. the ratio of memory accesses to calculations is high).[6] Virtually all current parallel architectures have been explored for executing stencil codes efficiently;[7] at the moment GPGPUs have proven to be most efficient.[8]
4. Libraries
Due to both the importance of stencil codes to computer simulations and their high computational requirements, there are a number of efforts which aim at creating reusable libraries to support scientists in implementing new stencil codes. The libraries are mostly concerned with the parallelization, but may also tackle other challenges, such as IO, steering and checkpointing. They may be classified by their API.
4.1. Patch-Based Libraries
This is a traditional design. The library manages a set of n-dimensional scalar arrays, which the user code may access to perform updates. The library handles the synchronization of the boundaries (dubbed ghost zone or halo). The advantage of this interface is that the user code may loop over the arrays, which makes it easy to integrate legacy codes[9] . The disadvantage is that the library can not handle cache blocking (as this has to be done within the loops[10]) or wrapping of the code for accelerators (e.g. via CUDA or OpenCL). Notable implementations include Cactus, a physics problem solving environment, and waLBerla.
4.2. Cell-Based Libraries
These libraries move the interface to updating single simulation cells: only the current cell and its neighbors are exposed to the user code, e.g. via getter/setter methods. The advantage of this approach is that the library can control tightly which cells are updated in which order, which is useful not only to implement cache blocking,[8] but also to run the same code on multi-cores and GPUs.[11] This approach requires the user to recompile the source code together with the library. Otherwise a function call for every cell update would be required, which would seriously impair performance. This is only feasible with techniques such as class templates or metaprogramming, which is also the reason why this design is only found in newer libraries. Examples are Physis and LibGeoDecomp.
References
- Sloot, Peter M.A. et al. (May 28, 2002) Computational Science – ICCS 2002: International Conference, Amsterdam, The Netherlands, April 21–24, 2002. Proceedings, Part I. Page 843. Publisher: Springer. ISBN:3-540-43591-3. https://books.google.com/books?id=qVcLw1UAFUsC&pg=PA843&dq=stencil+array&sig=g3gYXncOThX56TUBfHE7hnlSxJg#PPA843,M1
- Fey, Dietmar et al. (2010) Grid-Computing: Eine Basistechnologie für Computational Science. Page 439. Publisher: Springer. ISBN:3-540-79746-7 https://books.google.com/books?id=RJRZJHVyQ4EC&pg=PA51&dq=fey+grid&hl=de&ei=uGk8TtDAAo_zsgbEoZGpBQ&sa=X&oi=book_result&ct=result&resnum=1&ved=0CCoQ6AEwAA#v=onepage&q&f=true
- Yang, Laurence T.; Guo, Minyi. (August 12, 2005) High-Performance Computing : Paradigm and Infrastructure. Page 221. Publisher: Wiley-Interscience. ISBN:0-471-65471-X https://books.google.com/books?id=qA4DbnFB2XcC&pg=PA221&dq=Stencil+codes&as_brr=3&sig=H8wdKyABXT5P7kUh4lQGZ9C5zDk
- Micikevicius, Paulius et al. (2009) 3D finite difference computation on GPUs using CUDA Proceedings of 2nd Workshop on General Purpose Processing on Graphics Processing Units ISBN:978-1-60558-517-8 http://portal.acm.org/citation.cfm?id=1513905
- Datta, Kaushik (2009) Auto-tuning Stencil Codes for Cache-Based Multicore Platforms , Ph.D. Thesis http://www.cs.berkeley.edu/~kdatta/pubs/EECS-2009-177.pdf
- Wellein, G et al. (2009) Efficient temporal blocking for stencil computations by multicore-aware wavefront parallelization, 33rd Annual IEEE International Computer Software and Applications Conference, COMPSAC 2009 http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=5254211
- Datta, Kaushik et al. (2008) Stencil computation optimization and auto-tuning on state-of-the-art multicore architectures, SC '08 Proceedings of the 2008 ACM/IEEE conference on Supercomputing http://portal.acm.org/citation.cfm?id=1413375
- Schäfer, Andreas and Fey, Dietmar (2011) High Performance Stencil Code Algorithms for GPGPUs, Proceedings of the International Conference on Computational Science, ICCS 2011 http://www.sciencedirect.com/science/article/pii/S1877050911002791
- S. Donath, J. Götz, C. Feichtinger, K. Iglberger and U. Rüde (2010) waLBerla: Optimization for Itanium-based Systems with Thousands of Processors, High Performance Computing in Science and Engineering, Garching/Munich 2009 https://doi.org/10.1007%2F978-3-642-13872-0_3
- Nguyen, Anthony et al. (2010) 3.5-D Blocking Optimization for Stencil Computations on Modern CPUs and GPUs, SC '10 Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis http://dl.acm.org/citation.cfm?id=1884658
- Naoya Maruyama, Tatsuo Nomura, Kento Sato, and Satoshi Matsuoka (2011) Physis: An Implicitly Parallel Programming Model for Stencil Computations on Large-Scale GPU-Accelerated Supercomputers, SC '11 Proceedings of the 2011 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis


