 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | min li | -- | 1614 | 2022-11-10 11:02:49 | | | |
| 2 | Peter Tang | + 4 word(s) | 1618 | 2022-11-11 02:31:02 | | |
Video Upload Options
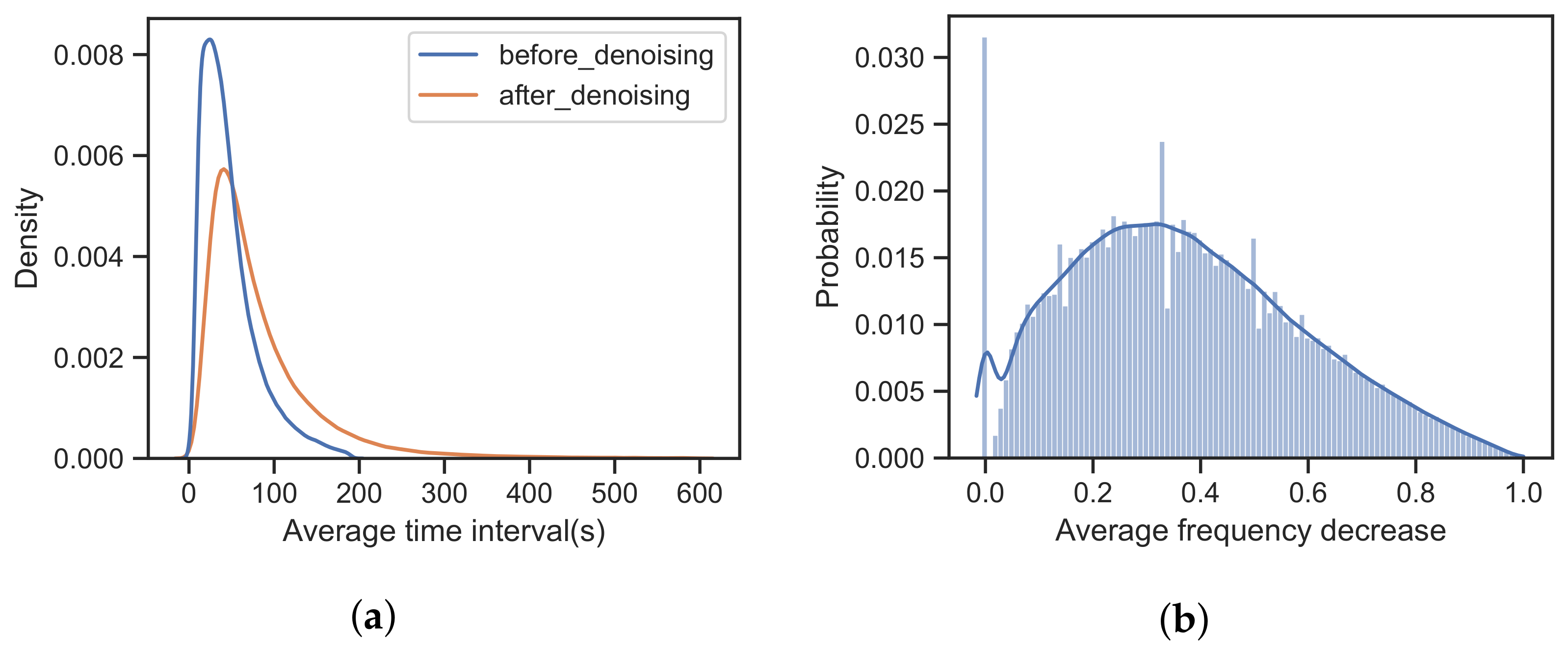
Human mobility prediction is a key task in smart cities to help improve urban management effectiveness. However, it remains challenging due to widespread intractable noises in large-scale mobility data. Based on previous research and the statistical analysis of real large-scale data, the researchers observe that there is heterogeneity in the quality of users’ trajectories, that is, the regularity and periodicity of one user's trajectories can be quite different from another. Inspired by this, the researchers propose a trajectory quality calibration framework for quantifying the quality of each trajectory and promoting high-quality training instances to calibrate the final prediction process. The main module of this approach is a calibration network that evaluates the quality of each user's trajectories by learning their similarity between them. It is designed to be model-independent and can be trained in an unsupervised manner. Finally, the mobility prediction model is trained with the instance-weighting strategy, which integrates quantified quality scores into the parameter updating process of the model. Experiments conducted on two citywide mobility datasets demonstrate the effectiveness of the approach when dealing with massive noisy trajectories in the real world.
1. Introduction
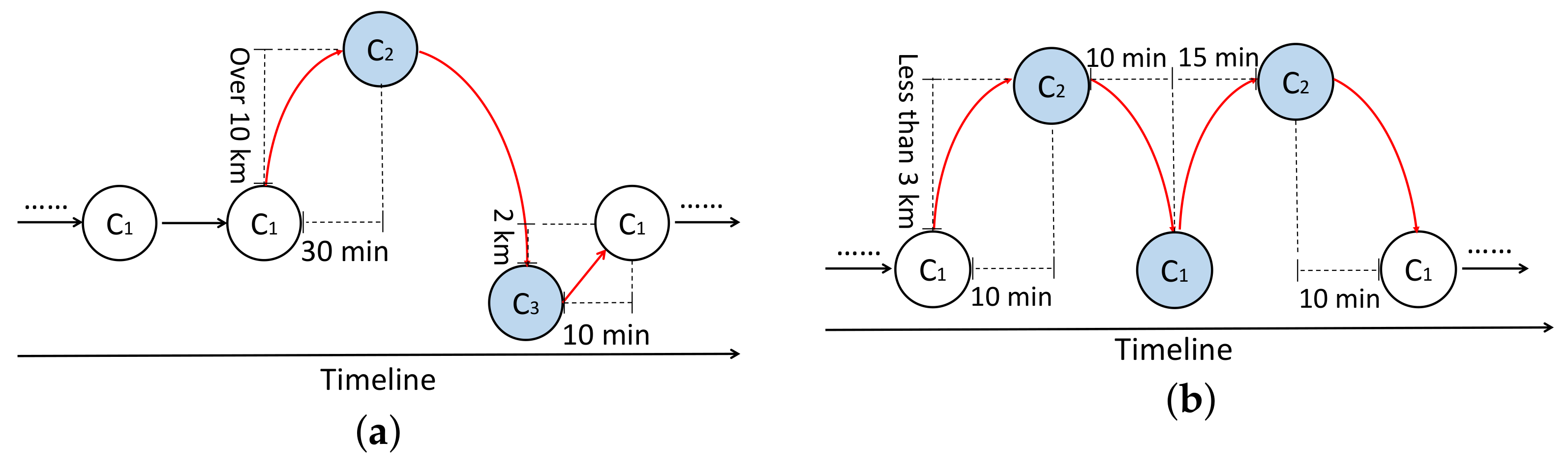
There have been some works that successfully learn with noisy data in dialogue systems for NLP. To evaluate the quality of training dialogues and generate more reasonable conversations, several methods[21][22] concentrate on quantifying the relatedness between queries and replies and train conversation models through an instance-weighting strategy.
Inspired by these, the researchers propose the trajectory quality calibration framework, which automatically estimates the quality of each training trajectory through a pre-trained calibration network and promotes high-quality training instances to calibrate the final prediction process. Several recurrent neural sub-networks with shared weights are used in the proposed calibration network to capture and quantify the consistency of the user's mobility transitions each day. Additionally, the quality score of that user's trajectory is evaluated by measuring the correlation between daily features. Then, in the unsupervised pre-training process of the calibration network through a negative sampling strategy, the quality score will be gradually updated by comparing the relatedness between the original trajectory and the corresponding trajectory injected with random noise. The impact of each training instance on the parameters of the final prediction model can be quantified as a weight value by a normalization process on their quality scores. Finally, the prediction model takes advantage of these normalized weight values to calibrate the training process by an instance-weighting method, which multiplies the weight values to loss functions and gradient descents when updating corresponding parameters.
2. Mobility Prediction
3. Instance Weighting
References
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021.
- Lu, X.; Wetter, E.; Bharti, N.; Tatem, A.J.; Bengtsson, L. Approaching the limit of predictability in human mobility. Sci. Rep. 2013, 3, 2923.
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090.
- Mathew, W.; Raposo, R.; Martins, B. Predicting future locations with hidden Markov models. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; pp. 911–918.
- Yan, M.; Li, S.; Chan, C.A.; Shen, Y.; Yu, Y. Mobility Prediction Using a Weighted Markov Model Based on Mobile User Classification. Sensors 2021, 21, 1740.
- Wang, H.; Li, Y.; Jin, D.; Han, Z. Attentional Markov Model for Human Mobility Prediction. IEEE J. Sel. Areas Commun. 2021, 39, 2213–2225.
- Ma, Z.; Rana, P.K.; Taghia, J.; Flierl, M.; Leijon, A. Bayesian estimation of Dirichlet mixture model with variational inference. Pattern Recognit. 2014, 47, 3143–3157.
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv, 2015; arXiv:1506.00019.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017.
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016.
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1459–1468.
- Dang, W.; Wang, H.; Pan, S.; Zhang, P.; Zhou, C.; Chen, X.; Wang, J. Predicting Human Mobility via Graph Convolutional Dual-attentive Networks. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Houston, Texas, USA, 21–25 February 2022; pp. 192–200.
- Wang, H.; Yu, Q.; Liu, Y.; Jin, D.; Li, Y. Spatio-Temporal Urban Knowledge Graph Enabled Mobility Prediction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–24.
- Jang, H.S.; Baek, J.H. Mobility Management Scheme with Mobility Prediction in Wireless Communication Networks. Appl. Sci. 2022, 12, 1252.
- Qi, L.; Qiao, Y.; Abdesslem, F.B.; Ma, Z.; Yang, J. Oscillation resolution for massive cell phone traffic data. In Proceedings of the First Workshop on Mobile Data, Porto, Portugal, 13–16 June 2016; pp. 25–30.
- Bayir, M.A.; Demirbas, M.; Eagle, N. Mobility profiler: A framework for discovering mobility profiles of cell phone users. Pervasive Mob. Comput. 2010, 6, 435–454.
- Calabrese, F.; Di Lorenzo, G.; Liu, L.; Ratti, C. Estimating origin-destination flows using mobile phone location data. In Proceedings of the IEEE Pervasive Computing, Seattle, WA, USA, 21–25 March 2011; pp. 36–44.
- Wu, W.; Wang, Y.; Gomes, J.B.; Anh, D.T.; Antonatos, S.; Xue, M.; Yang, P.; Yap, G.E.; Li, X.; Krishnaswamy, S.; et al. Oscillation resolution for mobile phone cellular tower data to enable mobility modelling. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management, Brisbane, QLD, Australia, 15–18 July 2014; Volume 1, pp. 321–328.
- Wang, F.; Chen, C. On data processing required to derive mobility patterns from passively-generated mobile phone data. Transp. Res. Part C Emerg. Technol. 2018, 87, 58–74.
- Xu, Y.; Li, X.; Shaw, S.L.; Lu, F.; Yin, L.; Chen, B.Y. Effects of Data Preprocessing Methods on Addressing Location Uncertainty in Mobile Signaling Data. Ann. Am. Assoc. Geogr. 2021, 111, 515–539.
- Feng, S.; Cong, G.; An, B.; Chee, Y.M. Poi2vec: Geographical latent representation for predicting future visitors. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017.
- Monreale, A.; Pinelli, F.; Trasarti, R.; Giannotti, F. Wherenext: A location predictor on trajectory pattern mining. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 637–646.
- Giannotti, F.; Nanni, M.; Pinelli, F.; Pedreschi, D. Trajectory pattern mining. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Nanjing, China, 22–25 May 2007; pp. 330–339.
- Peng, C.; Jin, X.; Wong, K.C.; Shi, M.; Liò, P. Collective human mobility pattern from taxi trips in urban area. PLoS ONE 2012, 7, e34487.
- Noulas, A.; Scellato, S.; Lathia, N.; Mascolo, C. Mining user mobility features for next place prediction in location-based services. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 1038–1043.
- Feng, S.; Li, X.; Zeng, Y.; Cong, G.; Chee, Y.M.; Yuan, Q. Personalized ranking metric embedding for next new poi recommendation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015.
- Gambs, S.; Killijian, M.O.; del Prado Cortez, M.N. Next place prediction using mobility markov chains. In Proceedings of the First Workshop on Measurement, Privacy, and Mobility, Bern, Switzerland, 10–12 April 2012; pp. 1–6.
- Chen, M.; Liu, Y.; Yu, X. Nlpmm: A next location predictor with markov modeling. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, Tainan, Taiwan, 13–16 May 2014; pp. 186–197.
- Amirrudin, N.A.; Ariffin, S.H.; Malik, N.A.; Ghazali, N.E. User’s mobility history-based mobility prediction in LTE femtocells network. In Proceedings of the 2013 IEEE International RF and Microwave Conference (RFM), Penang, Malaysia, 9–11 December 2013; pp. 105–110.
- Yu, S.Z.; Kobayashi, H. A hidden semi-Markov model with missing data and multiple observation sequences for mobility tracking. Signal Process. 2003, 83, 235–250.
- Kulkarni, V.; Garbinato, B. 20 Years of Mobility Modeling & Prediction: Trends, Shortcomings & Perspectives. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 492–495.
- Kulkarni, V.; Mahalunkar, A.; Garbinato, B.; Kelleher, J.D. Examining the limits of predictability of human mobility. Entropy 2019, 21, 432.
- Bao, Y.; Huang, Z.; Li, L.; Wang, Y.; Liu, Y. A BiLSTM-CNN model for predicting users’ next locations based on geotagged social media. Int. J. Geogr. Inf. Sci. 2021, 35, 639–660.
- Abideen, Z.U.; Sun, H.; Yang, Z.; Ahmad, R.Z.; Iftekhar, A.; Ali, A. Deep wide spatial-temporal based transformer networks modeling for the next destination according to the taxi driver behavior prediction. Appl. Sci. 2020, 11, 17.
- Zhang, H.; Dai, L. Mobility prediction: A survey on state-of-the-art schemes and future applications. IEEE Access 2018, 7, 802–822.
- Jiang, J.; Zhai, C. Instance weighting for domain adaptation in NLP. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 264–271.
- Wang, R.; Utiyama, M.; Liu, L.; Chen, K.; Sumita, E. Instance weighting for neural machine translation domain adaptation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1482–1488.
- Tao, C.; Mou, L.; Zhao, D.; Yan, R. Ruber: An unsupervised method for automatic evaluation of open-domain dialog systems. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018.
- Lison, P.; Bibauw, S. Not all dialogues are created equal: Instance weighting for neural conversational models. arXiv, 2017; arXiv:1704.08966.
- Shang, M.; Fu, Z.; Peng, N.; Feng, Y.; Zhao, D.; Yan, R. Learning to Converse with Noisy Data: Generation with Calibration. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4338–4344.

