 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Dean Liu | -- | 2094 | 2022-11-04 01:42:04 |
Video Upload Options
In Vapnik–Chervonenkis theory, the VC dimension (for Vapnik–Chervonenkis dimension) is a measure of the capacity (complexity, expressive power, richness, or flexibility) of a space of functions that can be learned by a statistical classification algorithm. It is defined as the cardinality of the largest set of points that the algorithm can shatter. It was originally defined by Vladimir Vapnik and Alexey Chervonenkis. Formally, the capacity of a classification model is related to how complicated it can be. For example, consider the thresholding of a high-degree polynomial: if the polynomial evaluates above zero, that point is classified as positive, otherwise as negative. A high-degree polynomial can be wiggly, so it can fit a given set of training points well. But one can expect that the classifier will make errors on other points, because it is too wiggly. Such a polynomial has a high capacity. A much simpler alternative is to threshold a linear function. This function may not fit the training set well, because it has a low capacity. This notion of capacity is made rigorous below.
1. Definitions
1.1. VC Dimension of a Set-Family
Let [math]\displaystyle{ H }[/math] be a set family (a set of sets) and [math]\displaystyle{ C }[/math] a set. Their intersection is defined as the following set-family:
- [math]\displaystyle{ H\cap C := \{h\cap C\mid h\in H\} }[/math]
We say that a set [math]\displaystyle{ C }[/math] is shattered by [math]\displaystyle{ H }[/math] if [math]\displaystyle{ H\cap C }[/math] contains all the subsets of [math]\displaystyle{ C }[/math], i.e:
- [math]\displaystyle{ |H\cap C| = 2^{|C|} }[/math]
The VC dimension of [math]\displaystyle{ H }[/math] is the largest integer [math]\displaystyle{ D }[/math] such that there exists a set [math]\displaystyle{ C }[/math] with cardinality [math]\displaystyle{ D }[/math] that is shattered by [math]\displaystyle{ H }[/math].
1.2. VC Dimension of a Classification Model
A classification model [math]\displaystyle{ f }[/math] with some parameter vector [math]\displaystyle{ \theta }[/math] is said to shatter a set of data points [math]\displaystyle{ (x_1,x_2,\ldots,x_n) }[/math] if, for all assignments of labels to those points, there exists a [math]\displaystyle{ \theta }[/math] such that the model [math]\displaystyle{ f }[/math] makes no errors when evaluating that set of data points.
The VC dimension of a model [math]\displaystyle{ f }[/math] is the maximum number of points that can be arranged so that [math]\displaystyle{ f }[/math] shatters them. More formally, it is the maximum cardinal [math]\displaystyle{ D }[/math] such that some data point set of cardinality [math]\displaystyle{ D }[/math] can be shattered by [math]\displaystyle{ f }[/math].
2. Examples
1. [math]\displaystyle{ f }[/math] is a constant classifier (with no parameters). Its VC-dimension is 0 since it cannot shatter even a single point. In general, the VC dimension of a finite classification model, which can return at most [math]\displaystyle{ 2^d }[/math] different classifiers, is at most [math]\displaystyle{ d }[/math] (this is an upper bound on the VC dimension; the Sauer–Shelah lemma gives a lower bound on the dimension).
2. [math]\displaystyle{ f }[/math] is a single-parametric threshold classifier on real numbers; i.e, for a certain threshold [math]\displaystyle{ \theta }[/math], the classifier [math]\displaystyle{ f_\theta }[/math] returns 1 if the input number is larger than [math]\displaystyle{ \theta }[/math] and 0 otherwise. The VC dimension of [math]\displaystyle{ f }[/math] is 1 because: (a) It can shatter a single point. For every point [math]\displaystyle{ x }[/math], a classifier [math]\displaystyle{ f_\theta }[/math] labels it as 0 if [math]\displaystyle{ \theta\gt x }[/math] and labels it as 1 if [math]\displaystyle{ \theta\lt x }[/math]. (b) It cannot shatter any set of two points. For every set of two numbers, if the smaller is labeled 1, then the larger must also be labeled 1, so not all labelings are possible.
3. [math]\displaystyle{ f }[/math] is a single-parametric interval classifier on real numbers; i.e, for a certain parameter [math]\displaystyle{ \theta }[/math], the classifier [math]\displaystyle{ f_\theta }[/math] returns 1 if the input number is in the interval [math]\displaystyle{ [\theta,\theta+4] }[/math] and 0 otherwise. The VC dimension of [math]\displaystyle{ f }[/math] is 2 because: (a) It can shatter some sets of two points. E.g, for every set [math]\displaystyle{ \{x,x+2\} }[/math], a classifier [math]\displaystyle{ f_\theta }[/math] labels it as (0,0) if [math]\displaystyle{ \theta \lt x - 4 }[/math] or if [math]\displaystyle{ \theta \gt x + 2 }[/math], as (1,0) if [math]\displaystyle{ \theta\in[x-4,x-2) }[/math], as (1,1) if [math]\displaystyle{ \theta\in[x-2,x] }[/math], and as (0,1) if [math]\displaystyle{ \theta\in(x,x+2] }[/math]. (b) It cannot shatter any set of three points. For every set of three numbers, if the smallest and the largest are labeled 1, then the middle one must also be labeled 1, so not all labelings are possible.
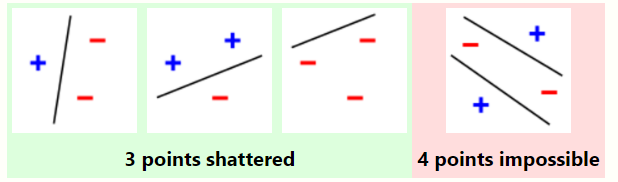
4. [math]\displaystyle{ f }[/math] is a straight line as a classification model on points in a two-dimensional plane (this is the model used by a perceptron). The line should separate positive data points from negative data points. There exist sets of 3 points that can indeed be shattered using this model (any 3 points that are not collinear can be shattered). However, no set of 4 points can be shattered: by Radon's theorem, any four points can be partitioned into two subsets with intersecting convex hulls, so it is not possible to separate one of these two subsets from the other. Thus, the VC dimension of this particular classifier is 3. It is important to remember that while one can choose any arrangement of points, the arrangement of those points cannot change when attempting to shatter for some label assignment. Note, only 3 of the 23 = 8 possible label assignments are shown for the three points.
5. [math]\displaystyle{ f }[/math] is a single-parametric sine classifier, i.e, for a certain parameter [math]\displaystyle{ \theta }[/math], the classifier [math]\displaystyle{ f_\theta }[/math] returns 1 if the input number [math]\displaystyle{ x }[/math] is larger than [math]\displaystyle{ \sin(\theta x) }[/math] and 0 otherwise. The VC dimension of [math]\displaystyle{ f }[/math] is infinite, since it can shatter any finite subset of the set [math]\displaystyle{ \{2^{-m} | m\in\mathbb{N}\} }[/math].[1]:57
3. Uses
3.1. In Statistical Learning Theory
The VC dimension can predict a probabilistic upper bound on the test error of a classification model. Vapnik[2] proved that the probability of the test error distancing from an upper bound (on data that is drawn i.i.d. from the same distribution as the training set) is given by:
- [math]\displaystyle{ \Pr \left(\text{test error} \leqslant \text{training error} + \sqrt{ \frac{1}{N} \left [ D \left (\log \left (\tfrac{2N}{D} \right )+1 \right )-\log \left (\tfrac{\eta}{4} \right ) \right]} \right )= 1 - \eta, }[/math]
where [math]\displaystyle{ D }[/math] is the VC dimension of the classification model, [math]\displaystyle{ 0 \leqslant \eta \leqslant 1 }[/math], and [math]\displaystyle{ N }[/math] is the size of the training set (restriction: this formula is valid when [math]\displaystyle{ D\ll N }[/math]. When [math]\displaystyle{ D }[/math] is larger, the test-error may be much higher than the training-error. This is due to overfitting).
The VC dimension also appears in sample-complexity bounds. A space of binary functions with VC dimension [math]\displaystyle{ D }[/math] can be learned with:
- [math]\displaystyle{ N = \Theta\left(\frac{D + \ln{1\over \delta}}{\epsilon}\right) }[/math]
samples, where [math]\displaystyle{ \epsilon }[/math] is the learning error and [math]\displaystyle{ \delta }[/math] is the failure probability. Thus, the sample-complexity is a linear function of the VC dimension of the hypothesis space.
3.2. In Computational Geometry
The VC dimension is one of the critical parameters in the size of ε-nets, which determines the complexity of approximation algorithms based on them; range sets without finite VC dimension may not have finite ε-nets at all.
4. Bounds
0. The VC dimension of the dual set-family of [math]\displaystyle{ \mathcal F }[/math] is strictly less than [math]\displaystyle{ 2^{\mathrm{vc}(\mathcal F)+1} }[/math], and this is best possible.
1. The VC dimension of a finite set-family [math]\displaystyle{ H }[/math] is at most [math]\displaystyle{ \log_2|H| }[/math].[1]:56 This is because [math]\displaystyle{ |H\cap C| \leq |H| }[/math] by definition.
2. Given a set-family [math]\displaystyle{ H }[/math], define [math]\displaystyle{ H_s }[/math] as a set-family that contains all intersections of [math]\displaystyle{ s }[/math] elements of [math]\displaystyle{ H }[/math]. Then:[1]:57
-
- [math]\displaystyle{ \text{VCDim}(H_s) \leq \text{VCDim}(H)\cdot (2 s \log_2(3s)) }[/math]
3. Given a set-family [math]\displaystyle{ H }[/math] and an element [math]\displaystyle{ h_0\in H }[/math], define [math]\displaystyle{ H\Delta h_0 := \{h\Delta h_0 \mid h\in H \} }[/math] where [math]\displaystyle{ \Delta }[/math] denotes symmetric set difference. Then:[1]:58
-
- [math]\displaystyle{ \text{VCDim}(H\Delta h_0) = \text{VCDim}(H) }[/math]
5. VC Dimension of a Finite Projective Plane
A finite projective plane of order n is a collection of n^2 +n + 1 sets (called "lines") over n^2 + n + 1 elements (called "points"). Each line contains exactly n + 1 points. Each line intersects every other line in exactly one point. The VC dimension of a finite projective plane is 2.[3]
Proof: (a) For each pair of distinct points, there is one line that contains both of them, lines that contain only one of them, and lines that contain none of them, so every set of size 2 is shattered. (b) For any triple of three distinct points, if there is a line x that contain all three, then there is no line y that contains exactly two (since then x and y would intersect in two points, which is contrary to the definition of a projective plane). Hence, no set of size 3 is shattered.
6. VC Dimension of a Boosting Classifier
Suppose we have a base class [math]\displaystyle{ B }[/math] of simple classifiers, whose VC dimension is [math]\displaystyle{ D }[/math].
We can construct a more powerful classifier by combining several different classifiers from [math]\displaystyle{ B }[/math]; this technique is called boosting. Formally, given [math]\displaystyle{ T }[/math] classifiers [math]\displaystyle{ h_1,\ldots,h_T \in B }[/math] and a weight vector [math]\displaystyle{ w\in \mathbb{R}^T }[/math], we can define the following classifier:
- [math]\displaystyle{ f(x) = \operatorname{sign}(\sum_{t=1}^T w_t\cdot h_t(x)) }[/math]
The VC dimension of the set of all such classifiers (for all selections of [math]\displaystyle{ T }[/math] classifiers from [math]\displaystyle{ B }[/math] and a weight-vector from [math]\displaystyle{ \mathbb{R}^T }[/math]) is at most:[4]:108-109
- [math]\displaystyle{ T\cdot (D+1) \cdot (3\cdot \log(T\cdot (D+1)) + 2) }[/math]
7. VC Dimension of a Neural Network
A neural network is described by a directed acyclic graph G(V,E), where:
- V is the set of nodes. Each node is a simple computation cell.
- E is the set of edges, Each edge has a weight.
- The input to the network is represented by the sources of the graph - the nodes with no incoming edges.
- The output of the network is represented by the sinks of the graph - the nodes with no outgoing edges.
- Each intermediate node gets as input a weighted sum of the outputs of the nodes at its incoming edges, where the weights are the weights on the edges.
- Each intermediate node outputs a certain increasing function of its input, such as the sign function or the sigmoid function. This function is called the activation function.
The VC dimension of a neural network is bounded as follows:[4]:234-235
- If the activation function is the sign function and the weights are general, then the VC dimension is at most [math]\displaystyle{ O(|E|\cdot \log(|E|)) }[/math].
- If the activation function is the sigmoid function and the weights are general, then the VC dimension is at least [math]\displaystyle{ \Omega(|E|^2) }[/math] and at most [math]\displaystyle{ O(|E|^2\cdot |V|^2) }[/math].
- If the weights come from a finite family (e.g. the weights are real numbers that can be represented by at most 32 bits in a computer), then, for both activation functions, the VC dimension is at most [math]\displaystyle{ O(|E|) }[/math].
8. Generalizations
The VC dimension is defined for spaces of binary functions (functions to {0,1}). Several generalizations have been suggested for spaces of non-binary functions.
- For multi-valued functions (functions to {0,...,n}), the Natarajan dimension[5] can be used. Ben David et al[6] present a generalization of this concept.
- For real-valued functions (e.g. functions to a real interval, [0,1]), Pollard's pseudo-dimension[7][8][9] can be used.
- The Rademacher complexity provides similar bounds to the VC, and can sometimes provide more insight than VC dimension calculations into such statistical methods such as those using kernels.
References
- Mohri, Mehryar; Rostamizadeh, Afshin; Talwalkar, Ameet (2012). Foundations of Machine Learning. USA, Massachusetts: MIT Press. ISBN 9780262018258.
- Vapnik 2000.
- Alon, N.; Haussler, D.; Welzl, E. (1987). "Partitioning and geometric embedding of range spaces of finite Vapnik-Chervonenkis dimension". Proceedings of the third annual symposium on Computational geometry - SCG '87. pp. 331. doi:10.1145/41958.41994. ISBN 978-0897912310. https://dx.doi.org/10.1145%2F41958.41994
- Shalev-Shwartz, Shai; Ben-David, Shai (2014). Understanding Machine Learning – from Theory to Algorithms. Cambridge University Press. ISBN 9781107057135.
- Natarajan 1989.
- Ben-David, Cesa-Bianchi & Long 1992.
- Pollard 1984.
- Anthony & Bartlett 2009.
- Morgenstern & Roughgarden 2015.

