 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Yuman Fong | + 4606 word(s) | 4606 | 2020-11-16 04:17:19 | | | |
| 2 | Bruce Ren | Meta information modification | 4606 | 2020-11-25 04:37:51 | | |
Video Upload Options
Laser Raman spectroscopy (LRS) is a highly specific biomolecular technique which has been shown to have the ability to distinguish malignant and normal breast tissue. This paper discusses significant advancements in the use of LRS in surgical breast cancer diagnosis, with an emphasis on statistical and machine learning strategies employed for precise, transparent and real-time analysis of Raman spectra. When combined with a variety of “machine learning” techniques LRS has been increasingly employed in oncogenic diagnostics. This paper proposes that the majority of these algorithms fail to provide the two most critical pieces of information required by the practicing surgeon: a probability that the classification of a tissue is correct, and, more importantly, the expected error in that probability. Stochastic backpropagation artificial neural networks inherently provide both pieces of information for each and every tissue site examined by LRS. If the networks are trained using both human experts and an unsupervised classification algorithm as gold standards, rapid progress can be made understanding what additional contextual data is needed to improve network classification performance. Our patients expect us to not simply have an opinion about their tumor, but to know how certain we are that we are correct. Stochastic networks can provide that information.
1. Introduction
Breast cancer is the second most commonly diagnosed cancer among American women after skin cancer, with approximately 1 in 8 women (12.8%) receiving a diagnosis of invasive breast cancer within their lifetime [1]. Early detection of tumors has become possible due to technological advancement of screening techniques as well as public education and awareness [2]. The standard of care for early stage invasive breast cancer includes breast irradiation and breast conserving surgery (BCS), during which the surgeon attempts to excise all tumors with a negative margin, that is margins of the resected tissue have no evidence of tumor [2][3]. Current gold standard definition of a negative surgical margin is defined as no malignant cells at the surface of resected tissue specimen [4]. Large studies have been conducted to compare outcomes between BCS and traditional mastectomy procedures, showing equivalent overall survival rates[4] . Mastectomy procedures include undesirable cosmetic outcomes for the patient, increased psychological burden and increased wound infection risk [5]. Unfortunately, the biggest risk with BCS is the chance of local reoccurrence (LR) with 15% to 35% of patients who opt for BCS requiring a second surgery to obtain negative margins [4][5]. Current standard of care after BCS includes a pathological investigation of tumor margins using hematoxylin and eosin (H&E) stains [4]. During this process the excised tissue is fixed, processed, sectioned and stained with H&E and studied under a microscope. This process is time and labor intensive, with results only becoming available days after initial surgery. If the surgical pathologist finds positive or close to positive margins, the patient has to undergo a second surgery. Hence, the accurate detection of tumor margins during surgery has become an area of intense investigation and technology development. Some intraoperative modalities that are under investigation to tackle this problem include radiofrequency spectroscopy [6], bioimpedance spectroscopy [7], photoacoustic tomography [8], spatial frequency domain imaging (SFDI) [9], fluorescence imaging [10][11], elastic scattering spectroscopy [12], microscopy with ultraviolet surface excitation (MUSE) [13], light-sheet microscopy [14], nonlinear microscopy [15], optical coherence tomography [16] and laser Raman spectroscopy (LRS) [17]. Maloney et al. review all of these intraoperative techniques as well as pre-operative imaging technologies for margin detection during BCS [4]. Their recommendation is a hybrid system of imaging modalities and optical scanning techniques to achieve desired sensitivity and specificity required for margin detection. In recent years, many investigators have pointed out the advantages of using a highly specific biomolecular probe, laser Raman spectroscopy (LRS), to distinguish breast cancer tumors from healthy breast tissue and benign masses [17][18][19][20][21].
This article focuses on LRS as a real-time tool for breast tumor detection during surgery. LRS is a non-destructive and label free technique that harnesses the biochemical specificity of the Raman effect [22]. A tiny fraction of incident light on an object is absorbed by its molecules which are set into vibrational motion and the subsequent frequency change of the scattered light is equal to the vibrational frequency of the these molecules [22]. The metric for Raman spectroscopy is known as the Stokes shift, named after Irish physicist George Gabriel Stokes. In the mid-19th century, Stokes noted that while most light incident on matter was either absorbed or reflected back at the same wavelength as the illuminating light (Rayleigh scatter) some light came back from the interaction at a longer wavelength; he coined the term “fluorescence” for this lower energy light [23]. This shift in wavelength to lower energy state occurs in both fluorescence and Raman scattering and was ultimately referred to as a Stokes shift in his honor. The origin of the Stokes shift is commonly represented in a Perrin-Jablonski diagram (Figure 1).
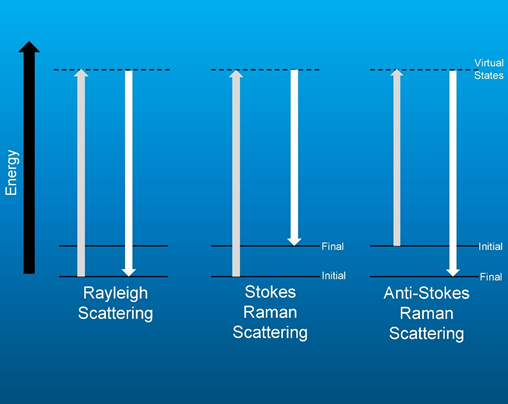
Figure 1. Energy level diagram of the Raman effect.
The energy transfer occurs between the incident photons and the electrons of the target atoms. If the electrons are in the ground state a Stokes shift occurs with a loss of photon energy. If the electrons are in an excited state, the photons can gain energy in what is termed an anti-Stokes shift. This scattered light is collected by a spectrometer, creating a spectrum, which showcases a series of peaks, also referred to as bands, corresponding to the characteristic vibrational frequencies of the scattering molecules [22]. This creates a unique biomolecular ‘fingerprint’ of the sample. When applied to cancer diagnostics, this unique fingerprint can be a direct indicator of the inherent biochemical differences between malignant and healthy tissue. Such biochemical specificity obtained from the surgical field can be instrumental in helping a surgeon achieve negative margins during BCS.
This paper discusses the most significant research advancements in the use of LRS as a real-time in vivo tool for surgical breast cancer detection, with an emphasis on the statistical and machine learning methods employed for spectral classification. The choice and implementation of machine learning diagnostic algorithms is critical for precise, real-time and transparent spectral classification. We start by describing various statistical and machine language algorithms commonly used for LRS data processing; followed by a brief review of multiple efforts using LRS to diagnose breast cancer using these algorithms. We will point out the variety of statistical analysis and classification techniques employed in these studies with emphasis on the absence of a standard methodology for [1] spectral data collection, [2] signal pre-processing, and [3] final classification. We posit that agreement on those three steps will be critical to the creation of national database development for the use of LRS in biomolecular breast cancer diagnostics. We suspect that stochastic neural networks will become the classification strategy of choice in oncogenic diagnostics due to their ability to [1] identify complex, non-linear boundaries between classes; [2] produce probabilistic estimates of the likelihood their predictions are correct; and, [3] estimate the expected error in their own prediction. We posit that [1] the majority of so called “machine learning” algorithms are, in fact simply statistical tools; and, [2] that stochastic backpropagation algorithms are the only true learning algorithm inherently providing the two most critical pieces of information: the Bayesian probability of correct classification and an estimate of the certainty of each classification probability for each target.
2. Statistical and Machine Learning Methods
The preparation and use of LRS data proceeds in most studies through several steps generally summarized as [1] pre-process cleaning of the raw incoming signal; [2] identification and extraction of the portion(s) of the data containing the lion’s share of the information (dimensionality reduction); [3] the pure unsupervised preliminary clustering of the LRS target sites driven only by the extracted features without human bias; and [4] a formal classification of all targets using a gold standard for training. The gold standard can be either the output of an unsupervised clustering algorithm, or the opinion of a human expert after evaluating other data, e.g., H&E photomicrographs of the LRS targets, or, preferably, both.
Until recently, a fifth stage has often been omitted or minimized: rigorously estimating the likelihood that the putative classification decision is correct and then evaluating the replicability of that decision. We will briefly describe several algorithms commonly employed in each of the first four tasks and then describe an easily implemented stochastic neural network method to generate both a Bayesian probabilistic classification as well as error estimation for classification replicability. Figure 2 includes a flowchart of these five data processing steps as well as commonly used algorithms for each step.
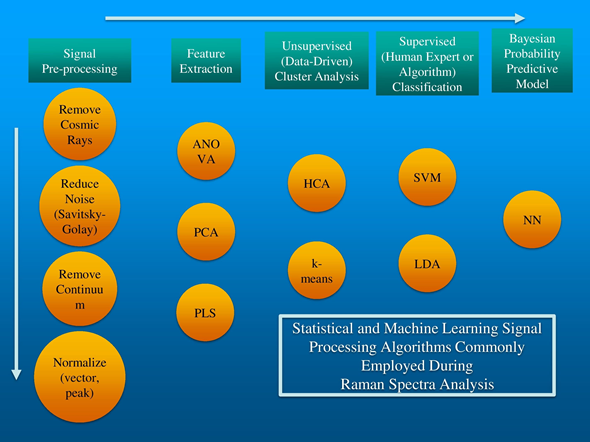
Figure 2. The data processing steps required for robust Raman spectral analysis with the various algorithms that can be used for each step.
2.1. Data Pre-Processing
Raman scattering is an example of an inelastic scattering of a photon after it interacts with the electron cloud generated by a wide variety of molecular bonds, e.g., C—H, C—H2, C—H3, —OH, etc. The change in energy is recorded in the Raman spectral data as a Stokes shift in the photon’s wavelength towards the red end of the spectrum (lower frequency, lower energy) if the electron cloud is in the ground state, and toward the blue end (higher frequency, higher energy) if the molecular bond has been excited to a higher energy state by some previous event. The molecular specificity of an LRS spectrum comes with a price. Very few laser photons striking a target will carry the vibrational energy signature of one of the molecular bonds in the target. The vast majority will be either scattered elastically without carrying vibrational information (Rayleigh scatter) or absorbed to be subsequently dissipated as heat or fluorescence.
Since the Raman effect is such a rare event, to minimize data acquisition time highly sensitive CCD and CMOS chips and thermal cooling systems are now the core sensor components for collecting Raman photons present at just above sensor thermal background levels. The sensitivities are such that an LRS spectrometer makes an excellent cosmic ray detector. Signal pre-processing starts in modern systems with a series of embedded software routines that look for spike events involving only one or two spectral bins which are characteristic of cosmic ray events [24]. Once a spike is detected, the embedded algorithm then uses any one of a number of nearest neighbor routines to interpolate and replace the affected pixels. The next step in most pre-processing protocols is usually called noise reduction or smoothing. The most common choice of algorithm for the past three decades has been that devised by Savitsky and Golay [25]. The algorithm uses a moving window based local polynomial fitting routine requiring operator decisions about parameters such the size of the moving window and polynomial order. The inherent danger in the smoothing is that as the moving window size increases, some Raman bands of interest with broad FWHM (full width half maximum) and low S/N characteristics may be lost. The third stage of preprocessing is the removal of the red-shifted fluorescence and other continuum distortions arising from variables such as changes in sample absorption characteristics as a function of wavelength, laser bleed-through, or CCD inhomogeneities. The baseline corrections that must be accomplished without distorting the information in the raw data, are quite critical, but relatively simple to automate. A wide variety of techniques have been investigated including wavelets [26], FFTs [27], first and second derivatives [28], and polynomial fitting [29]. At present the most commonly implemented baseline correction techniques involve some form of polynomial fitting [30]. An easily implemented method uses an asymmetrically reweighted penalized least squares smoothing algorithm (arPLS) developed by Baek et al. [31]. This method employs an iterative process to estimate a baseline. The calculated baseline is then subtracted from the intensity values of the raw spectrum to remove the continuum.
The final pre-processing step, normalization, attempts to minimize the impact of variables in the data collection process that are independent and extraneous to the hypothesis driving the LRS investigation [32]. Common confounding variables include changes in sample temperature, ambient lighting, laser power drift, and CCD/CMOS chip temperature. The two most common normalization procedures are peak normalization and vector normalization. In peak normalization a single peak, one predicted to be unchanging in the experimental conditions, is chosen as a gold standard. All peaks, including the normalizing peak, are then divided by the intensity of that normalizing peak. For a given set of experiments, evaluation of the entire data set using principal component analysis (PCA, defined below) can provide confirmation that the normalizing peak does not contribute to the information content of the LRS spectra. But that confirmation does not generalize beyond the bounds of the original experiment. In vector normalization, the square root of the sum of the squared intensities of the spectrum is calculated. Then, each of the Raman spectral intensities is simply divided by this ‘norm’ to obtain a normalized spectrum. Vector normalization is becoming increasingly popular and may be more useful when trying to interpret the results of disparate LRS measurements performed under a variety of experimental conditions.
2.2. Data Optimization and Dimension Reduction
At present it has become common practice for data analysis to begin with optimization of the raw input data using principle component analysis (PCA). PCA, also known as the Karhunen-Loeve or hotelling transform, is a classical unsupervised multivariate analysis technique. Often incorrectly thought of as a classification algorithm, PCA is actually the premier method for reducing the dimensionality of the raw data. In the case of LRS, the raw spectral data may contain ~2000 bands. PCA will often be able to reduce that enormous input vector to as few as 3–10 principal components or factors. PCA identifies linear combinations of raw parameters that account for the maximum variance. It is important to note that in machine learning and artificial intelligence, variance is often characterized as the information content in a data set. Analysis of variance (ANOVA) can be used to confirm PCA detection of high information content in specific regions of LRS spectra. The data dimensionality reduction significantly increases the computational efficiency of classification algorithms and makes it more likely that sophisticated, complex algorithms such as neural networks will not “memorize” the training set data, but will instead extract more robust correlations that can be applied to classify previously unseen data sets. Finally, PCA is unaffected by modest amounts of noise in the data since the covariance matrix is an average over many data points while the noise is uncorrelated from point to point [33].
Partial least squares (PLS) bears considerable resemblance to PCA. However, while PCA concentrates only on modeling the y-axis of a data set, PLS simultaneously models the structure of both the x and y axes. PLS in a form known as PLS-regression (PLSR) is used extensively in chemometrics [34]. PLSR usefulness is its ability to analyze data containing noisy, collinear, and even incomplete variables in both x and y
2.3. Unsupervised, Autonomous Data Exploration
Machine learning algorithms generally fall into one of two categories: unsupervised and supervised. Unsupervised algorithms identify patterns in a data set without prior knowledge of independent data that might provide classification criteria easily interpreted by a human expert. Supervised algorithms are provided with the predicted classification of either a human expert or the results of an unsupervised algorithm. The supervised algorithm then must predict the likelihood the clustering or classification model proposed by either the unsupervised or human expert is correct.
When initially exploring any unknown environment, it is certainly desirable to identify self-organizing patterns in the raw data. The exercise can quickly point out the existence of anomalies in the data such as outliers, measurement results unexpected by the experiment and distant from the spectral patterns generated by all other samples. The human or algorithmic analysis of these readings is critical for proceeding with data processing since there are only two primary reasons for the existence of an outlier. The common assumption is that this is a measurement error and the offending data should be thrown out. The other possibility, of course, is that this is a serendipitous detection of an unexpected phenomenon and may be the most important finding in the experiment. Both unsupervised artificial neural networks and factor analysis techniques have been employed successfully for such an initial qualitative exploration. In the data flow illustrated in Figure 3, PCA factors extracted from raw data are often used as inputs for two unsupervised clustering algorithms: hierarchical cluster analysis (HCA) and k-means. HCA is a completely autonomous cluster detection algorithm used extensively in molecular biology, medicine, and biochemistry to explore genome data sets [35].
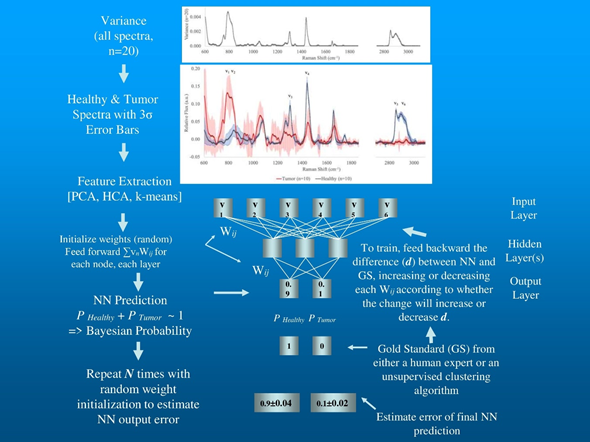
Figure 3. Flowchart example of data processing for LRS breast tissue signals.
Dendritic tree HCA initially considers each member of the data set as a separate cluster and then combines the clusters by merging nearest neighbors. Repeated with the resulting combined data points the binary combination continues, reducing the number of clusters at each step, until only one cluster remains. The HCA data partitioning is then represented by a dendrogram, or a tree where each step in the clustering process is illustrated by a node or branching of the tree. The distance between each level is calculated, and significance levels can be set deciding if the data best described by 1, 2, 3,., N clusters. HCA can be used as the very first data exploration algorithm since it does not require any help from a human expert, not even a priori selection of the probable number of classes. The algorithm can also generate a corresponding tree diagram showing contribution of each member of the input vector to the final clustering partitions. Such a dendritic tree produced the canonical genomic classification system devised by Woese et al. [36], a central tool for understanding the diversity and evolution of life.
The second unsupervised algorithm, k-means, has been shown to be able to generate the optimal clustering model for any input data [37]. However, it is not quite as autonomous as HCA. K-means requires an initial estimate of the likely number of clusters if it is going to solve the clustering task in a reasonable amount of time. The estimate of the likely number of clusters can be provided automatically as one of the outputs for HCA, or it can be provided by a human expert. After choosing the initial data points as temporary cluster centers, k-means assigns data points to a cluster and moves the center of the cluster such that the sum of the squared distance between the data points and the arithmetic mean of all the cluster’s data points is minimized. The algorithm does not generate a probabilistic estimate of the accuracy of cluster assignment.
2.4. Supervised Data Classification
Linear discriminant analysis (LDA) and support vector machines (SVM) are supervised machine learning classifiers. Often referred to as Fisher’s linear discriminant, LDA, like PCA, searches for a linear combination of variables that optimally characterizes a data set [38]. Unlike PCA, LDA has access to not only the uncontrolled variables (in the case of LRS the spectral bands), but also to the predicted classification of, usually, a human expert. Given that a priori classification, LDA attempts to model the differences between the predicted classes.
SVM is a robust, easily implemented and reliable linear binary classifier. SVM can rapidly identify class boundaries between two linearly separable clusters [39]. Vectors of the input data are non-linearly mapped to a high-dimensional feature space where a linear decision surface is formed to create two clusters [40]. Kernel trick is often employed when using SVM so that one can operate in input space instead of a highly dimensional one [41]. SVM boundary decisions are relatively easy to understand. However, the final classification is purely binary. Neither LDA or SVM produce a probability that a classification is correct and do not inherently estimate the error in their prediction for each target.
2.5. Bayesian Probabilities of Correct Classification—Stochastic Neural Networks
Once unsupervised algorithms assign cluster memberships to each data point for all samples, the correctness of each assignment must be estimated. Bayesian probability theory is a powerful formalized method to generate the probability that each data point should be included in each of the data clusters proposed by either a human expert or an unsupervised algorithm [42]. Stochastic backpropagation neural networks (NNs) are simple optimization algorithms modeled on the neuronal signal processing characteristics of the brain [43][44][45][46][47]. These stochastic algorithms have been shown to be robust estimators of the Bayesian a posteriori probability of correct classification and easily generate an error analysis for each probability [48][49]. Unlike LDA and SVM, NNs can model non-linear boundaries, have been shown to be universal approximation machines, and can generate a Bayesian probability that each target has been correctly classified [50]. NNs are not confined to binary classification tasks, but can easily assign a Bayesian probability that a target is a member of each class under consideration. Breast cancer tissue is often heterogenous [51], and at a given time the Raman laser spot light might be incident on a boundary region and thus capturing signal from a mixture of malignant and healthy cells. Hence a probabilistic classification model can more accurately depict the heterogenous nature of cancer and leave the final decision making to the surgeon.
Backpropagation networks consist of two or more “layers of nodes”. A node (i) is just one of the numbers in a vector describing a data point. In NN terminology, a complete vector is called a layer (j). Each NN will have at least one input layer of nodes, an output layer, and a set of weights (wij) that fully connect the nodes of the two layers. The output nodes for the NN are the Bayesian probability that a target has been correctly classified either by HCA, k-means, or a human expert. If the classes are linearly separable, only the input and output layers and their connecting weights are required. If a nonlinear separation is expected, one or more layers are inserted between the input and output layers to extract higher order terms.
Figure 3 illustrates a simple data flow we have used in previous work beginning with the initial analysis of variance and choice of spectral regions of interest used as qualitative input exploration with PCA, HCA, and k-means, through to a stochastic backpropagation NN using a single intermediary layer between the input and output layers (known as the hidden layer) [52].
For this strawman example Figure 3 depicts the variance in 20 LRS spectra acquired while evaluating ex vivo tissue excised during breast conserving lumpectomy, 10 from sites identified by subsequent histopathology as tumor sites and 10 from sites identified as healthy tissue. The spectra have been corrected for cosmic rays, smoothed using Savitsky-Golay algorithm, continuum removed by arPLS, and vector normalized. The first frame depicts the variance present in all 20 spectra without attention to probable classification. Multiple spectral regions appear to contain significant information. The second frame depicting the 3-sigma error for spectra from each of the two putative classes, tumor and healthy, show considerable overlap for several of the possible bands of interest for classification. Such a qualitative assessment can then be verified using PCA to look for spectral regions that can contribute to classification. HCA and k-means unsupervised classifications using multiple combinations of possible bands of interest can also be used to explore for the optimal data dimension reduction and clustering partitions. In the mock-up depicted in Figure 3, six regions of interest show high variance and are free from overlap at the 3-sigma level. The Raman shift values and the molecular targets exhibiting Raman shifts at these wavelengths appear in Table 1.
Table 1. Biomolecular assignments of six regions of interest in spectra displayed in Figure 3.
|
Table 1 |
Raman Shift (cm−1) |
Biomolecular Assignment* [53] |
|
v1 |
780–810 |
O—P—O stretching DNA, ring breathing mode U, T, C bases of RNA and DNA |
|
v2 |
815–825 |
C—C stretch of proline and hydroxyproline, out of plane ring breathing of tyrosine |
|
v3 |
1302 |
assigned to CH2 twisting of lipids in healthy; in tumor assigned to CH2 twisting in proteins or amide III (protein) |
|
v4 |
1441 |
CH2 bending mode in lipids |
|
v4 |
2853 |
CH2 symmetric stretch of lipids |
|
v4 |
2903 |
CH2 asymmetric stretch of lipids and proteins |
* See Movasaghi et al. [53], and references therein.
The intensities of each of the bands representing the spectral regions of interest enter the NN at the input layer. Each node in the hidden layer is connected to each node in both the input and output layers by a weight that is initialized at the start of training with a random number between 1 and 0. Training is a simple matter of iteratively adjusting each of these weights to generate values at the output layer that match values presented as the predicted classification. For example, a node at layer j initiates a calculation of the sum of the inputs from the previous layer each multiplied by the specific wij for that connection. The node constrains its output by transforming the sum using a nonlinear threshold function of sigmoid form across the interval. The weights are modified by minimizing least squares (see Storrie-Lombardi et al. [49] for a detailed description of NN training). The novel aspect of stochastic backpropagation NNs is the manner in which the optimization is performed using the chain rule (also known as gradient descent), which was independently discovered by several investigators [54][55]. During training, the algorithm measures the differences between its output and the putative class assignment and then propagates error backward by modifying the weights in each layer according to their contribution to the total error. Note that the NNs represented in Figure 3 are non-linear, unlike the two unsupervised clustering algorithms. These NNs are capable of drawing more complex class boundaries than can be accomplished by the two clustering algorithms. Interestingly, if a target has been incorrectly assigned by one of the linear unsupervised algorithms or a human expert, these stochastic non-linear NNs will “refuse” the putative assignment of the target and generate a low probability that the assignment is accurate. In analyzing the output of these NNs, if the model has been correctly configured, the probabilistic predictions for all classes considered will sum to ~1, the required hallmark of a Bayesian analytical engine.
For data sets of limited size, training and testing of all samples can be easily accomplished by two different techniques: leave-one-out cross-validation and jackknife training/testing sequence. Both have their advantages and disadvantages. Leave-one-out cross-validation removes one target before training begins, trains an NN on the full data set less one, tests the hold out target, and then repeats the entire process for the next datum until all targets have been tested. The process is excellent for optimal utilization of small data sets, for the proper training of the NN, and for the precise evaluation of each target. But for large data sets the technique is computationally resource-intensive. A variety of jackknife procedures have been developed that generally involveselection of random subsets of the data for training, testing, and validation. It is the stochastic reset of the NN’s weights for multiple runs that makes it possible to implement a Monte Carlo test-retest sequence and produce statistics that the NNs use to generate a true error estimate to assess their own performance. It should be noted that larger data sets (about an order of magnitude more spectra than the number of weights in the NN) are preferred since their size inhibits the NNs from “memorizing” the “correct” answers given by the unsupervised algorithms or the human expert. Instead the algorithms will learn the more robust patterns in the correlations and anti-correlations driving the unsupervised clustering algorithms.
Finally, it cannot be overemphasized that since these are stochastic NNs, the entire training and testing process can be automatically run as many times as necessary with a complete random reset of the starting weights occurring at the beginning of each run. The output from these runs, that each begin at unique initial states, provides clear statistics characterizing the inherent error in the Bayesian probability generated by the algorithm. This capability separates stochastic backpropagation algorithms from all other classifiers discussed here.
References
- DeSantis, C.E.; Ma, J.; Gaudet, M.M.; Newman, L.A.; Miller, K.D.; Goding Sauer, A.; Jemal, A.; Siegel, R.L. Breast cancer statistics, 2019. Ca A Cancer, J. Clin. 2019, 69, 438–451.
- Apantaku, L.M. Breast-conserving surgery for breast cancer. Am. Fam Physician 2002, 66, 2271–2278.
- Fisher, B.; Anderson, S.; Bryant, J.; Margolese, R.G.; Deutsch, M.; Fisher, E.R.; Jeong, J.H.; Wolmark, N. Twenty-year follow-up of a randomized trial comparing total mastectomy, lumpectomy, and lumpectomy plus irradiation for the treatment of invasive breast cancer. N. Engl. J. Med. 2002, 347, 1233–1241.
- Maloney, B.W.; McClatchy, D.M.; Pogue, B.W.; Paulsen, K.D.; Wells, W.A.; Barth, R.J. Review of methods for intraoperative margin detection for breast conserving surgery. J. Biomed. Opt. 2018, 23, 1–19.
- Pleijhuis, R.G.; Graafland, M.; de Vries, J.; Bart, J.; de Jong, J.S.; van Dam, G.M. Obtaining Adequate Surgical Margins in Breast-Conserving Therapy for Patients with Early-Stage Breast Cancer: Current Modalities and Future Directions. Ann. Surg. Oncol. 2009, 16, 2717–2730.
- Thill, M. MarginProbe: Intraoperative margin assessment during breast conserving surgery by using radiofrequency spectroscopy. Expert Rev. Med. Devices 2013, 10, 301–315.
- Dixon, J.M.; Renshaw, L.; Young, O.; Kulkarni, D.; Saleem, T.; Sarfaty, M.; Sreenivasan, R.; Kusnick, C.; Thomas, J.; Williams, L.J. Intra-operative assessment of excised breast tumour margins using ClearEdge imaging device. Eur. J. Surg. Oncol. 2016, 42, 1834–1840.
- Piras, D.; Xia, W.; Steenbergen, W.; Leeuwen, T.G.V.; Manohar, S. Photoacoustic Imaging of the Breast Using the Twente Photoacoustic Mammoscope: Present Status and Future Perspectives. IEEE J. Sel. Top. Quantum. Electron. 2010, 16, 730–739.
- Laughney, A.M.; Krishnaswamy, V.; Rizzo, E.J.; Schwab, M.C.; Barth, R.J., Jr.; Cuccia, D.J.; Tromberg, B.J.; Paulsen, K.D.; Pogue, B.W.; Wells, W.A. Spectral discrimination of breast pathologies in situ using spatial frequency domain imaging. Breast Cancer Res. 2013, 15, R61.
- Tummers, Q.R.; Verbeek, F.P.; Schaafsma, B.E.; Boonstra, M.C.; van der Vorst, J.R.; Liefers, G.J.; van de Velde, C.J.; Frangioni, J.V.; Vahrmeijer, A.L. Real-time intraoperative detection of breast cancer using near-infrared fluorescence imaging and Methylene Blue. Eur. J. Surg Oncol. 2014, 40, 850–858.
- Troyan, S.L.; Kianzad, V.; Gibbs-Strauss, S.L.; Gioux, S.; Matsui, A.; Oketokoun, R.; Ngo, L.; Khamene, A.; Azar, F.; Frangioni, J.V. The FLARE intraoperative near-infrared fluorescence imaging system: A first-in-human clinical trial in breast cancer sentinel lymph node mapping. Ann. Surg. Oncol. 2009, 16, 2943–2952.
- Johnson, K.S.; Chicken, D.W.; Pickard, D.C.; Lee, A.C.; Briggs, G.; Falzon, M.; Bigio, I.J.; Keshtgar, M.R.; Bown, S.G. Elastic scattering spectroscopy for intraoperative determination of sentinel lymph node status in the breast. J. Biomed. Opt. 2004, 9, 1122–1128.
- Fereidouni, F.; Harmany, Z.T.; Tian, M.; Todd, A.; Kintner, J.A.; McPherson, J.D.; Borowsky, A.D.; Bishop, J.; Lechpammer, M.; Demos, S.G.; et al. Microscopy with ultraviolet surface excitation for rapid slide-free histology. Nat. Biomed. Eng. 2017, 1, 957–966.
- Glaser, A.K.; Reder, N.P.; Chen, Y.; McCarty, E.F.; Yin, C.; Wei, L.; Wang, Y.; True, L.D.; Liu, J.T.C. Light-sheet microscopy for slide-free non-destructive pathology of large clinical specimens. Nat. Biomed. Eng. 2017, 1, 1–10.
- Tao, Y.K.; Shen, D.; Sheikine, Y.; Ahsen, O.O.; Wang, H.H.; Schmolze, D.B.; Johnson, N.B.; Brooker, J.S.; Cable, A.E.; Connolly, J.L.; et al. Assessment of breast pathologies using nonlinear microscopy. Proc. Natl. Acad. Sci. USA 2014, 111, 15304–15309.
- Nguyen, F.T.; Zysk, A.M.; Chaney, E.J.; Kotynek, J.G.; Oliphant, U.J.; Bellafiore, F.J.; Rowland, K.M.; Johnson, P.A.; Boppart, S.A. Intraoperative evaluation of breast tumor margins with optical coherence tomography. Cancer Res. 2009, 69, 8790–8796.
- Haka, A.S.; Volynskaya, Z.; Gardecki, J.A.; Nazemi, J.; Lyons, J.; Hicks, D.; Fitzmaurice, M.; Dasari, R.R.; Crowe, J.P.; Feld, M.S. In vivo margin assessment during partial mastectomy breast surgery using raman spectroscopy. Cancer Res. 2006, 66, 3317–3322.
- Haka, A.S.; Shafer-Peltier, K.E.; Fitzmaurice, M.; Crowe, J.; Dasari, R.R.; Feld, M.S. Diagnosing breast cancer by using Raman spectroscopy. Proc. Natl. Acad. Sci. USA 2005, 102, 12371–12376.
- Haka, A.S.; Shafer-Peltier, K.E.; Fitzmaurice, M.; Crowe, J.; Dasari, R.R.; Feld, M.S. Identifying microcalcifications in benign and malignant breast lesions by probing differences in their chemical composition using Raman spectroscopy. Cancer Res. 2002, 62, 5375–5380.
- Haka, A.S.; Volynskaya, Z.; Gardecki, J.A.; Nazemi, J.; Shenk, R.; Wang, N.; Dasari, R.R.; Fitzmaurice, M.; Feld, M.S. Diagnosing breast cancer using Raman spectroscopy: Prospective analysis. J. Biomed. Opt. 2009, 14, 054023.
- Shafer-Peltier, K.E.; Haka, A.S.; Fitzmaurice, M.; Crowe, J.; Myles, J.; Dasari, R.R.; Feld, M.S. Raman microspectroscopic model of human breast tissue: Implications for breast cancer diagnosis in vivo. J. Raman. Spectrosc. 2002, 33, 552–563.
- Hanlon, E.B.; Manoharan, R.; Koo, T.-W.; Shafer, K.E.; Motz, J.T.; Fitzmaurice, M.; Kramer, J.R.; Itzkan, I.; Dasari, R.R.; Feld, M.S. Procpets for in vivo Raman spectroscopy. Phys. Eng. Med. Biol. 1999, 45, R1–R59.
- Stokes, G.G. XXX. On the change of refrangibility of light. Philos. Trans. R. Soc. Lond. 1852, 142, 463–562.
- Gautam, R.; Vanga, S.; Ariese, F.; Umapathy, S. Review of multidimensional data processing approaches for Raman and infrared spectroscopy. EPJ Tech. Instrum. 2015, 2, 1–38.
- Savitzky, A.; Golay, M.J.F. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639.
- Camerlingo, C.; Zenone, F.; Gaeta, G.M.; Riccio, R.; Lepore, M. Wavelet data processing of micro-Raman spectra of biological samples. Meas. Sci. Technol. 2006, 17, 298–303.
- Mosier-Boss, P.A.; Lieberman, S.H.; Newbery, R. Fluorescence rejection in Raman-spectroscopy by shifted-Spectra, edge-detection, and FFT filtering techniques. Appl. Spectrosc. 1995, 49, 630–638.
- Liu, Y.; Lin, J. A general-purpose signal processing algorithm for biological profiles using only first-order derivative information. BMC Bioinform. 2019, 20, 611.
- Cadusch, P.J.; Hlaing, M.M.; Wade, S.A.; McArthur, S.L.; Stoddart, P.R. Improved methods for fluorescence background subtraction from Raman spectra†. J. Raman Spectrosc. 2013, 44, doi:10.1002/jrs.4371.
- Mendes, T.d.O.; Pinto, L.P.; Santos, L.D.; Tippavajhala, V.K.; Soto, C.A.T.L.; Martin, A.A.O. Statistical strategies to reveal potential vibrational markers for in vivo analysis by confocal Raman spectroscopy. J. Biomed. Opt. 2016, 21, 075010.
- Baek, S.-J.; Park, A.; Ahn, Y.-J.; Choo, J. Baseline correction using asymmetrically reweighted penalized least squares smoothing. Analyst 2015, 140, 250–257.
- Beattie, J.R.; Glenn, J.V.; Boulton, M.E.; Stitt, A.W.; McGarvey, J.J. Effect of signal intensity normalization on the multivariate analysis of spectral data in complex ‘real-world’ datasets. J. Raman Spectrosc. 2008, 40, doi:10.1002/jrs.2146.
- Murtagh, F.; Heck, A. Multivariate Data Analysis; Springer Science & Business Media: Dordrecht, Netherlands, 1986.
- Wold, S.; Sjöströma, M.; Erikssonb, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130.
- Revelle, W. Hierarchical cluster analysis and the internal structure of tests. Multivar. Behav. Res. 1979, 14, 57–74.
- Woese, C.R.; Kandler, O.; Wheelis, M.L. Towards a natural system of organisms: Proposal for the domains Archaea, Bacteria, and Eucarya. Proc. Natl. Acad. Sci. 1990, 87, 4576–4579.
- MacQueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Symposium on Mathematical Statistics and Probability, Berkeley, CA, University of California Press: Berkeley, CA, USA, 21 June–18 July 1965; pp 281–297.
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188.
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory–COLT ‘92, Pittsburgh, Pennsylvania, USA, July 1992; Association for Computing Machinery: New York, NY, USA, 1992; p 144.
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297.
- Murty, M.N.; Raghava, R. Kernel-Based SVM. In Support Vector Machines and Perceptrons; SpringerBriefs in Computer Science; Springer: Cham, Germany, 2016.
- Bayes, T. An Essay towards Solving a Problem in the Doctrine of Chances. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418.
- Kohonen, T. Self-Organization and Associative Memory; Springer-Verlag: New York, NY, USA, 1977.
- Hopfield, J.J.; Tank, D.W. Computing with neural circuits: A model. Science 1986, 233, 625–633.
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536.
- Adorf, H.M. Connectionism in neural networks. In Knowledge-Based Systems in Astronomy, edited by A. Heck and F.; Murtagh, Springer-Verlag: New York, NY, USA, 1989; pp 215–245.
- Hinton, G.E. Connectionist Symbol Processing; MIT Press: Cambridge, MA, USA, 1991.
- Richard, M.D.; Lippmann, R.P. Neural network classifiers estimate Bayesian a-posteriori probabilities. Neural Comput. 1991, 3, 461–483.
- Storrie-Lombardi, M.C.; Lahav, O.; Sodre, L.; Storrie-Lombardi, L.J. Morphological classification of galaxies by artificial neural networks. Mon. Not. R. Astron. Soc. 1992, 259, 8–12.
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554.
- Polyak, K. Heterogeneity in breast cancer. J. Clin. Investig. 2011, 121, 3786–3788.
- Kothari, R.; Jones, V.; Mena, D.; Bermúdez Reyes, V.; Shon, Y.; Smith, J.P.; Schmolze, D.; Cha, P.D.; Lai, L.; Fong, Y.; et al. Raman Spectroscopy and Artificial Intelligence to Predict the Bayesian Probability of Breast Cancer. Sci. Rep. 2020, under review.
- Movasaghi, Z.; Rehman, S.; Rehman, I.U. Raman Spectroscopy of Biological Tissues. Appl. Spectrosc. Rev. 2007, 42, 493–541
- Werbos, P.J. An overview of neural networks for control. IEEE Control. Syst. Mag. 1991, 11, 40–41.
- Parker, D.B. Learning-Logic: Casting the Cortex of the Human Brain in Silicon. Technical Report No.47; Center for Computational Research in Economics and Management Science. MIT: Cambridge, MA, USA, 1985; pp.1–47.


