 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Jason Zhu | -- | 5415 | 2022-10-19 01:35:57 |
Video Upload Options
In chemistry, a hypercycle is an abstract model of organization of self-replicating molecules connected in a cyclic, autocatalytic manner. It was introduced in an ordinary differential equation (ODE) form by the Nobel Prize winner Manfred Eigen in 1971 and subsequently further extended in collaboration with Peter Schuster. It was proposed as a solution to the error threshold problem encountered during modelling of replicative molecules that hypothetically existed on the primordial Earth (see: abiogenesis). As such, it explained how life on Earth could have begun using only relatively short genetic sequences, which in theory were too short to store all essential information. The hypercycle is a special case of the replicator equation. The most important properties of hypercycles are autocatalytic growth competition between cycles, once-for-ever selective behaviour, utilization of small selective advantage, rapid evolvability, increased information capacity, and selection against parasitic branches.
1. Central Ideas
The hypercycle is a cycle of connected, self-replicating macromolecules. In the hypercycle, all molecules are linked such that each of them catalyses the creation of its successor, with the last molecule catalysing the first one. In such a manner, the cycle reinforces itself. Furthermore, each molecule is additionally a subject for self-replication. The resultant system is a new level of self-organization that incorporates both cooperation and selfishness. The coexistence of many genetically non-identical molecules makes it possible to maintain a high genetic diversity of the population. This can be a solution to the error threshold problem, which states that, in a system without ideal replication, an excess of mutation events would destroy the ability to carry information and prevent the creation of larger and fitter macromolecules. Moreover, it has been shown that hypercycles could originate naturally and that incorporating new molecules can extend them. Hypercycles are also subject to evolution and, as such, can undergo a selection process. As a result, not only does the system gain information, but its information content can be improved. From an evolutionary point of view, the hypercycle is an intermediate state of self-organization, but not the final solution.[1]
Over the years, the hypercycle theory has experienced many reformulations and methodological approaches. Among them, the most notable are applications of partial differential equations,[2] cellular automata,[3][4][5][6] and stochastic formulations of Eigen's problem.[7][8] Despite many advantages that the concept of hypercycles presents, there were also some problems regarding the traditional model formulation using ODEs: a vulnerability to parasites and a limited size of stable hypercycles.[3][4][5][6][7][9][10] In 2012, the first experimental proof for the emergence of a cooperative network among fragments of self-assembling ribozymes was published, demonstrating their advantages over self-replicating cycles.[11] However, even though this experiment proves the existence of cooperation among the recombinase ribozyme subnetworks, this cooperative network does not form a hypercycle per se, so we still lack the experimental demonstration of hypercycles.[12]
2. Model Formulation
2.1. Model Evolution
- 1971 (1971): Eigen introduces the hypercycle concept[1]
- 1977 (1977): Eigen and Schuster extend the hypercycle concept, propose a hypercycle theory and introduce the concept of quasispecies[13]
- 1982 (1982): Discovery of ribozyme catalytic properties[14][15]
- 2001 (2001): Partial RNA polymerase ribozyme is designed via directed evolution[16]
- 2012 (2012): Experimental demonstration that ribozymes can form collectively autocatalytic sets[12]
2.2. Error Threshold Problem
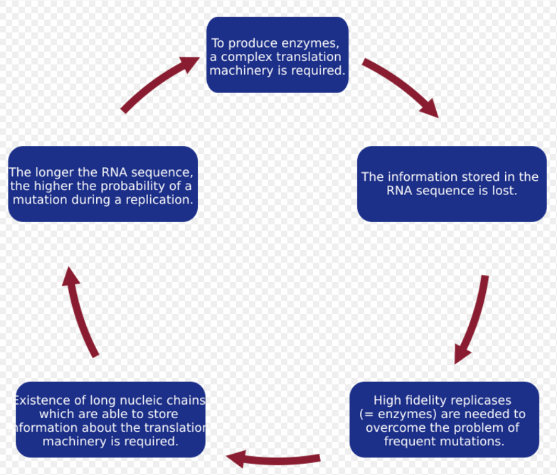
When a model of replicating molecules was created,[1][13] it was found that, for effective storage of information, macromolecules on prebiotic Earth could not exceed a certain threshold length. This problem is known as the error threshold problem. It arises because replication is an imperfect process, and during each replication event, there is a risk of incorporating errors into a new sequence, leading to the creation of a quasispecies. In a system that is deprived of high-fidelity replicases and error-correction mechanisms, mutations occur with a high probability. As a consequence, the information stored in a sequence can be lost due to the rapid accumulation of errors, a so-called error catastrophe. Moreover, it was shown that the genome size of any organism is roughly equal to the inverse of mutation rate per site per replication.[17][18][19] Therefore, a high mutation rate imposes a serious limitation on the length of the genome. To overcome this problem, a more specialized replication machinery that is able to copy genetic information with higher fidelity is needed. Manfred Eigen suggested that proteins are necessary to accomplish this task.[1] However, to encode a system as complex as a protein, longer nucleotide sequences are needed, which increases the probability of a mutation even more and requires even more complex replication machinery. John Maynard Smith and Eörs Szathmáry named this vicious circle Eigen's Paradox.[20]
According to current estimations, the maximum length of a replicated chain that can be correctly reproduced and maintained in enzyme-free systems is about 100 bases, which is assumed to be insufficient to encode replication machinery. This observation was the motivation for the formulation of the hypercycle theory.[21]
2.3. Models
It was suggested that the problem with building and maintaining larger, more complex, and more accurately replicated molecules can be circumvented if several information carriers, each of them storing a small piece of information, are connected such that they only control their own concentration.[1][13] Studies of the mathematical model describing replicating molecules revealed that to observe a cooperative behaviour among self-replicating molecules, they have to be connected by a positive feedback loop of catalytic actions.[22][23][24] This kind of closed network consisting of self-replicating entities connected by a catalytic positive-feedback loop was named an elementary hypercycle. Such a concept, apart from an increased information capacity, has another advantage. Linking self-replication with mutual catalysis can produce nonlinear growth of the system. This, first, makes the system resistant to so-called parasitic branches. Parasitic branches are species coupled to a cycle that do not provide any advantage to the reproduction of a cycle, which, in turn, makes them useless and decreases the selective value of the system. Secondly, it reinforces the self-organization of molecules into the hypercycle, allowing the system to evolve without losing information, which solves the error threshold problem.[13]
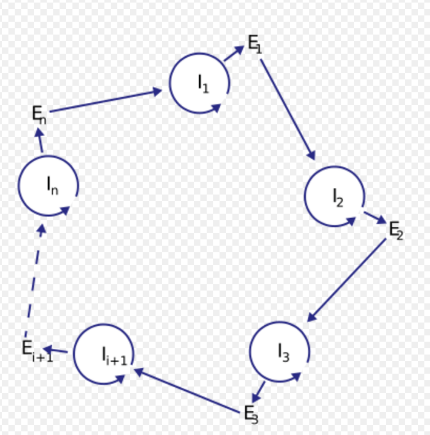
Analysis of potential molecules that could form the first hypercycles in nature prompted the idea of coupling an information carrier function with enzymatic properties. At the time of the hypercycle theory formulation, enzymatic properties were attributed only to proteins, while nucleic acids were recognized only as carriers of information. This led to the formulation of a more complex model of a hypercycle with translation. The proposed model consists of a number of nucleotide sequences I (I stands for intermediate) and the same number of polypeptide chains E (E stands for enzyme). Sequences I have a limited chain length and carry the information necessary to build catalytic chains E. The sequence Ii provides the matrix to reproduce itself and a matrix to build the protein Ei. The protein Ei gives the catalytic support to build the next sequence in the cycle, Ii+1. The self-replicating sequences I form a cycle consisting of positive and negative strands that periodically reproduce themselves. Therefore, many cycles of the +/− nucleotide collectives are linked together by the second-order cycle of enzymatic properties of E, forming a catalytic hypercycle. Without the secondary loop provided by catalysis, I chains would compete and select against each other instead of cooperating. The reproduction is possible thanks to translation and polymerization functions encoded in I chains. In his principal work, Manfred Eigen stated that the E coded by the I chain can be a specific polymerase or an enhancer (or a silencer) of a more general polymerase acting in favour of formation of the successor of nucleotide chain I. Later, he indicated that a general polymerase leads to the death of the system.[13] Moreover, the whole cycle must be closed, so that En must catalyse I1 formation for some integer n > 1.[1][13]
2.4. Alternative Concepts
During their research, Eigen and Schuster also considered types of protein and nucleotide coupling other than hypercycles. One such alternative was a model with one replicase that performed polymerase functionality and that was a translational product of one of the RNA matrices existing among the quasispecies. This RNA-dependent RNA polymerase catalysed the replication of sequences that had specific motifs recognized by this replicase. The other RNA matrices, or just one of their strands, provided translational products which had specific anticodons and were responsible for unique assignment and transportation of amino acids.[13]
Another concept devised by Eigen and Schuster was a model in which each RNA template's replication was catalysed by its own translational product; at the same time, this RNA template performed a transport function for one amino acid type. Existence of more than one such RNA template could make translation possible.[13]
Nevertheless, in both alternative concepts, the system will not survive due to the internal competition among its constituents. Even if none of the constituents of such a system is selectively favoured, which potentially allows coexistence of all of the coupled molecules, they are not able to coevolve and optimize their properties. In consequence, the system loses its internal stability and cannot live on. The reason for inability to survive is the lack of mutual control of constituent abundances.[13]
3. Mathematical Model
3.1. Elementary Hypercycle
The dynamics of the elementary hypercycle can be modelled using the following differential equation:[25]
- [math]\displaystyle{ \dot{x_i}=x_i \left(k_i+\sum_j k_{i,j} x_j - \frac{1}{x} \phi \right) }[/math]
where
- [math]\displaystyle{ \begin{align} x &= \sum_i x_i,\\ k_i &= f_i-d_i. \end{align} }[/math]
In the equation above, xi is the concentration of template Ii; x is the total concentration of all templates; ki is the excess production rate of template Ii, which is a difference between formation fi by self-replication of the template and its degradation di, usually by hydrolysis; ki,j is the production rate of template Ii catalysed by Ij; and φ is a dilution flux; which guarantees that the total concentration is constant. Production and degradation rates are expressed in numbers of molecules per time unit at unit concentration (xi = 1). Assuming that at high concentration x the term ki can be neglected, and, moreover, in the hypercycle, a template can be replicated only by itself and the previous member of the cycle, the equation can be simplified to:[25]
- [math]\displaystyle{ \dot{x_i} = x_i \left(k_{i,i-1} x_{i-1}-\frac{1}{x}\phi\right) }[/math]
where according to the cyclic properties, it can be assumed that
- [math]\displaystyle{ \begin{align} k_{i,0} &= k_{i,n}, \\ x_0 &= x_n. \end{align} }[/math]
3.2. Hypercycle with Translation
A hypercycle with translation consists of polynucleotides Ii (with concentration xi) and polypeptides Ei (with concentration yi). It is assumed that the kinetics of nucleotide synthesis follows a Michaelis–Menten-type reaction scheme in which the concentration of complexes cannot be neglected. During replication, molecules form complexes IiEi-1 (occurring with concentration zi). Thus, the total concentration of molecules (xi0 and yi0) will be the sum of free molecules and molecules involved in a complex:
- [math]\displaystyle{ \begin{align} x_i^0 &= x_i+z_{i}, \\ y_i^0 &= y_i+z_{i+1}. \end{align} }[/math]
The dynamics of the hypercycle with translation can be described using a system of differential equations modelling the total number of molecules:
- [math]\displaystyle{ \begin{align} \dot{x}_i^0 &= f_i z_i-\frac{x_i^0}{c_I} \phi_x, \\ \dot{y}_i^0 &= k_i x_i-\frac{y_i^0}{c_E} \phi_y \end{align} }[/math]
where
- [math]\displaystyle{ \begin{align} c_I &= \sum_i x_i^0, \\ c_E &= \sum_i y_i^0. \end{align} }[/math]
In the above equations, cE and cI are total concentrations of all polypeptides and all polynucleotides, φx and φy are dilution fluxes, ki is the production rate of polypeptide Ei translated from the polynucleotide Ii, and fi is the production rate of polynucleotide Ii synthesised by the complex IiEi-1 (through replication and polymerization).[25]
Coupling nucleic acids with proteins in such a model of hypercycle with translation demanded the proper model for the origin of translation code as a necessary condition for the origin of hypercycle organization. At the time of hypercycle theory formulation, two models for the origin of translation code were proposed by Crick and his collaborators. These were models stating that the first codons were constructed according to either an RRY or an RNY scheme, in which R stands for the purine base, Y for pyrimidine, and N for any base, with the latter assumed to be more reliable. Nowadays, it is assumed that the hypercycle model could be realized by utilization of ribozymes without the need for a hypercycle with translation, and there are many more theories about the origin of the genetic code.[26]
4. Evolution
4.1. Formation of the First Hypercycles
Eigen made several assumptions about conditions that led to the formation of the first hypercycles.[13] Some of them were the consequence of the lack of knowledge about ribozymes, which were discovered a few years after the introduction of the hypercycle concept[14][15] and negated Eigen's assumptions in the strict sense. The primary of them was that the formation of hypercycles had required the availability of both types of chains: nucleic acids forming a quasispecies population and proteins with enzymatic functions. Nowadays, taking into account the knowledge about ribozymes, it may be possible that a hypercycle's members were selected from the quasispecies population and the enzymatic function was performed by RNA. According to the hypercycle theory, the first primitive polymerase emerged precisely from this population. As a consequence, the catalysed replication could exceed the uncatalysed reactions, and the system could grow faster. However, this rapid growth was a threat to the emerging system, as the whole system could lose control over the relative amount of the RNAs with enzymatic function. The system required more reliable control of its constituents—for example, by incorporating the coupling of essential RNAs into a positive feedback loop. Without this feedback loop, the replicating system would be lost. These positive feedback loops formed the first hypercycles.[13]
In the process described above, the fact that the first hypercycles originated from the quasispecies population (a population of similar sequences) created a significant advantage. One possibility of linking different chains I—which is relatively easy to achieve taking into account the quasispecies properties—is that the one chain I improves the synthesis of the similar chain I’. In this way, the existence of similar sequences I originating from the same quasispecies population promotes the creation of the linkage between molecules I and I’.[13]
4.2. Evolutionary Dynamics
After formation, a hypercycle reaches either an internal equilibrium or a state with oscillating concentrations of each type of chain I, but with the total concentration of all chains remaining constant. In this way, the system consisting of all chains can be expressed as a single, integrated entity. During the formation of hypercycles, several of them could be present in comparable concentrations, but very soon, a selection of the hypercycle with the highest fitness value will take place.[1] Here, the fitness value expresses the adaptation of the hypercycle to the environment, and the selection based on it is very sharp. After one hypercycle wins the competition, it is very unlikely that another one could take its place, even if the new hypercycle would be more efficient than the winner. Usually, even large fluctuations in the numbers of internal species cannot weaken the hypercycle enough to destroy it. In the case of a hypercycle, we can speak of one-for-ever selection, which is responsible for the existence of a unique translation code and a particular chirality.[13]
The above-described idea of a hypercycle's robustness results from an exponential growth of its constituents caused by the catalytic support. However, Eörs Szathmáry and Irina Gladkih showed that an unconditional coexistence can be obtained even in the case of a non-enzymatic template replication that leads to a subexponential or a parabolic growth. This could be observed during the stages preceding a catalytic replication that are necessary for the formation of hypercycles. The coexistence of various non-enzymatically replicating sequences could help to maintain a sufficient diversity of RNA modules used later to build molecules with catalytic functions.[27]
From the mathematical point of view, it is possible to find conditions required for cooperation of several hypercycles. However, in reality, the cooperation of hypercycles would be extremely difficult, because it requires the existence of a complicated multi-step biochemical mechanism or an incorporation of more than two types of molecules. Both conditions seem very improbable; therefore, the existence of coupled hypercycles is assumed impossible in practice.[13]
Evolution of a hypercycle ensues from the creation of new components by the mutation of its internal species. Mutations can be incorporated into the hypercycle, enlarging it if, and only if, two requirements are satisfied. First, a new information carrier Inew created by the mutation must be better recognized by one of the hypercycle's members Ii than the chain Ii+1 that was previously recognized by it. Secondly, the new member Inew of the cycle has to better catalyse the formation of the polynucleotide Ii+1 that was previously catalysed by the product of its predecessor Ii. In theory, it is possible to incorporate into the hypercycle mutations that do not satisfy the second condition. They would form parasitic branches that use the system for their own replication but do not contribute to the system as a whole. However, it was noticed that such mutants do not pose a threat to the hypercycle, because other constituents of the hypercycle grow nonlinearly, which prevents the parasitic branches from growing.[13]
4.3. Evolutionary Dynamics: a Mathematical Model
According to the definition of a hypercycle, it is a nonlinear, dynamic system, and, in the simplest case, it can be assumed that it grows at a rate determined by a system of quadratic differential equations. Then, the competition between evolving hypercycles can be modelled using the differential equation:[25]
- [math]\displaystyle{ \dot{C_l}=q_l C_l^2-C_l \frac{\phi}{C} }[/math]
where
- [math]\displaystyle{ C = \sum_l C_l. }[/math]
Here, Cl is the total concentration of all polynucleotide chains belonging to a hypercycle Hl, C is the total concentration of polynucleotide chains belonging to all hypercycles, ql is the rate of growth, and φ is a dilution flux that guarantees that the total concentration is constant. According to the above model, in the initial phase, when several hypercycles exist, the selection of the hypercycle with the largest ql value takes place. When one hypercycle wins the selection and dominates the population, it is very difficult to replace it, even with a hypercycle with a much higher growth rate q.[25]
5. Compartmentalization and Genome Integration
Hypercycle theory proposed that hypercycles are not the final state of organization, and further development of more complicated systems is possible by enveloping the hypercycle in some kind of membrane.[13] After evolution of compartments, a genome integration of the hypercycle can proceed by linking its members into a single chain, which forms a precursor of a genome. After that, the whole individualized and compartmentalized hypercycle can behave like a simple self-replicating entity. Compartmentalization provides some advantages for a system that has already established a linkage between units. Without compartments, genome integration would boost competition by limiting space and resources. Moreover, adaptive evolution requires the package of transmissible information for advantageous mutations in order not to aid less-efficient copies of the gene. The first advantage is that it maintains a high local concentration of molecules, which helps to locally increase the rate of synthesis. Secondly, it keeps the effect of mutations local, while at the same time affecting the whole compartment. This favours preservation of beneficial mutations, because it prevents them from spreading away. At the same time, harmful mutations cannot pollute the entire system if they are enclosed by the membrane. Instead, only the contaminated compartment is destroyed, without affecting other compartments. In that way, compartmentalization allows for selection for genotypic mutations. Thirdly, membranes protect against environmental factors because they constitute a barrier for high-weight molecules or UV irradiation. Finally, the membrane surface can work as a catalyst.[25]
Despite the above-mentioned advantages, there are also potential problems connected to compartmentalized hypercycles. These problems include difficulty in the transport of ingredients in and out, synchronizing the synthesis of new copies of the hypercycle constituents, and division of the growing compartment linked to a packing problem.[13]
In the initial works, the compartmentalization was stated as an evolutionary consequence of the hypercyclic organization. Carsten Bresch and coworkers raised an objection that hypercyclic organization is not necessary if compartments are taken into account.[28] They proposed the so-called package model in which one type of a polymerase is sufficient and copies all polynucleotide chains that contain a special recognition motif. However, as pointed out by the authors, such packages are—contrary to hypercycles—vulnerable to deleterious mutations as well as a fluctuation abyss, resulting in packages that lack one of the essential RNA molecules. Eigen and colleagues argued that simple package of genes cannot solve the information integration problem and hypercycles cannot be simply replaced by compartments, but compartments may assist hypercycles.[29] This problem, however, raised more objections, and Eörs Szathmáry and László Demeter reconsidered whether packing hypercycles into compartments is a necessary intermediate stage of the evolution. They invented a stochastic corrector model[7] that assumed that replicative templates compete within compartments, and selective values of these compartments depend on the internal composition of templates. Numerical simulations showed that when stochastic effects are taken into account, compartmentalization is sufficient to integrate information dispersed in competitive replicators without the need for hypercycle organization. Moreover, it was shown that compartmentalized hypercycles are more sensitive to the input of deleterious mutations than a simple package of competing genes. Nevertheless, package models do not solve the error threshold problem that originally motivated the hypercycle.[30]
6. Ribozymes
At the time of the hypercycle theory formulation, ribozymes were not known. After the breakthrough of discovering RNA's catalytic properties in 1982,[14][15] it was realized that RNA had the ability to integrate protein and nucleotide-chain properties into one entity. Ribozymes potentially serving as templates and catalysers of replication can be considered components of quasispecies that can self-organize into a hypercycle without the need to invent a translation process. In 2001, a partial RNA polymerase ribozyme was designed via directed evolution.[16] Nevertheless, it was able to catalyse only a polymerization of a chain having the size of about 14 nucleotides, even though it was 200 nucleotides long. The most up-to-date version of this polymerase was shown in 2013.[31] While it has an ability to catalyse polymerization of longer sequences, even of its own length, it cannot replicate itself due to a lack of sequence generality and its inability to transverse secondary structures of long RNA templates. However, it was recently shown that those limitations could in principle be overcome by the assembly of active polymerase ribozymes from several short RNA strands.[32] In 2014, a cross-chiral RNA polymerase ribozyme was demonstrated.[33] It was hypothesized that it offers a new mode of recognition between an enzyme and substrates, which is based on the shape of the substrate, and allows avoiding the Watson-Crick pairing and, therefore, may provide greater sequence generality. Various other experiments have shown that, besides bearing polymerase properties, ribozymes could have developed other kinds of evolutionarily useful catalytic activity such as synthase, ligase, or aminoacylase activities.[16] Ribozymal aminoacylators and ribozymes with the ability to form peptide bonds might have been crucial to inventing translation. An RNA ligase, in turn, could link various components of quasispecies into one chain, beginning the process of a genome integration. An RNA with a synthase or a synthetase activity could be critical for building compartments and providing building blocks for growing RNA and protein chains as well as other types of molecules. Many examples of this kind of ribozyme are currently known, including a peptidyl transferase ribozyme,[34] a ligase,[35][36] and a nucleotide synthetase.[37] A transaminoacylator described in 2013 has five nucleotides,[38] which is sufficient for a trans-amino acylation reaction and makes it the smallest ribozyme that has been discovered. It supports a peptidyl-RNA synthesis that could be a precursor for the contemporary process of linking amino acids to tRNA molecules. An RNA ligase's catalytic domain, consisting of 93 nucleotides, proved to be sufficient to catalyse a linking reaction between two RNA chains.[39] Similarly, an acyltransferase ribozyme 82 nucleotides long was sufficient to perform an acyltransfer reaction.[40] Altogether, the results concerning the RNA ligase's catalytic domain and the acyltransferase ribozyme are in agreement with the estimated upper limit of 100 nucleotides set by the error threshold problem. However, it was hypothesized that even if the putative first RNA-dependent RNA-polymerases are estimated to be longer—the smallest reported up-to-date RNA-dependent polymerase ribozyme is 165 nucleotides long[16]—they did not have to arise in one step. It is more plausible that ligation of smaller RNA chains performed by the first RNA ligases resulted in a longer chain with the desired catalytically active polymerase domain.[41]
Forty years after the publication of Manfred Eigen's primary work dedicated to hypercycles,[1] Nilesh Vaidya and colleagues showed experimentally that ribozymes can form catalytic cycles and networks capable of expanding their sizes by incorporating new members.[11] However, this is not a demonstration of a hypercycle in accordance with its definition, but an example of a collectively autocatalytic set.[12] Earlier computer simulations showed that molecular networks can arise, evolve and be resistant to parasitic RNA branches.[42] In their experiments, Vaidya et al. used an Azoarcus group I intron ribozyme that, when fragmented, has an ability to self-assemble by catalysing recombination reactions in an autocatalytic manner. They mutated the three-nucleotide-long sequences responsible for recognition of target sequences on the opposite end of the ribozyme (namely, Internal Guide Sequences or IGSs) as well as these target sequences. Some genotypes could introduce cooperation by recognizing target sequences of the other ribozymes, promoting their covalent binding, while other selfish genotypes were only able to self-assemble. In separation, the selfish subsystem grew faster than the cooperative one. After mixing selfish ribozymes with cooperative ones, the emergence of cooperative behaviour in a merged population was observed, outperforming the self-assembling subsystems. Moreover, the selfish ribozymes were integrated into the network of reactions, supporting its growth. These results were also explained analytically by the ODE model and its analysis. They differ substantially from results obtained in evolutionary dynamics.[43] According to evolutionary dynamics theory, selfish molecules should dominate the system even if the growth rate of the selfish subsystem in isolation is lower than the growth rate of the cooperative system. Moreover, Vaidya et al. proved that, when fragmented into more pieces, ribozymes that are capable of self-assembly can not only still form catalytic cycles but, indeed, favour them. Results obtained from experiments by Vaidya et al. gave a glimpse on how inefficient prebiotic polymerases, capable of synthesizing only short oligomers, could be sufficient at the pre-life stage to spark off life. This could happen because coupling the synthesis of short RNA fragments by the first ribozymal polymerases to a system capable of self-assembly not only enables building longer sequences but also allows exploiting the fitness space more efficiently with the use of the recombination process. Another experiment performed by Hannes Mutschler et al.[32] showed that the RNA polymerase ribozyme, which they described, can be synthesized in situ from the ligation of four smaller fragments, akin to a recombination of Azoarcus ribozyme from four inactive oligonucleotide fragments described earlier. Apart from a substantial contribution of the above experiments to the research on the origin of life, they have not proven the existence of hypercycles experimentally.[44]
7. Related Problems and Reformulations
The hypercycle concept has been continuously studied since its origin. Shortly after Eigen and Schuster published their main work regarding hypercycles,[13] John Maynard Smith raised an objection that the catalytic support for the replication given to other molecules is altruistic.[45] Therefore, it cannot be selected and maintained in a system. He also underlined hypercycle vulnerability to parasites, as they are favoured by selection. Later on, Josef Hofbauer and Karl Sigmund[46] indicated that in reality, a hypercycle can maintain only fewer than five members. In agreement with Eigen and Schuster's principal analysis, they argued that systems with five or more species exhibit limited and unstable cyclic behaviour, because some species can die out due to stochastic events and break the positive feedback loop that sustains the hypercycle. The extinction of the hypercycle then follows. It was also emphasized that a hypercycle size of up to four is too small to maintain the amount of information sufficient to cross the information threshold.[13]
Several researchers proposed a solution to these problems by introducing space into the initial model either explicitly[3][10][47][48] or in the form of a spatial segregation within compartments.[7][28] Bresch et al.[28] proposed a package model as a solution for the parasite problem. Later on, Szathmáry and Demeter[7] proposed a stochastic corrector machine model. Both compartmentalized systems proved to be robust against parasites. However, package models do not solve the error threshold problem that originally motivated the idea of the hypercycle. A few years later, Maarten Boerlijst and Paulien Hogeweg, and later Nobuto Takeuchi, studied the replicator equations with the use of partial differential equations[2] and cellular automata models,[3][4][6] methods that already proved to be successful in other applications.[49][50] They demonstrated that spatial self-structuring of the system completely solves the problem of global extinction for large systems and, partially, the problem of parasites.[10] The latter was also analysed by Robert May,[9] who noticed that an emergent rotating spiral wave pattern, which was observed during computational simulations performed on cellular automata, proved to be stable and able to survive the invasion of parasites if they appear at some distance from the wave core. Unfortunately, in this case, rotation decelerates as the number of hypercycle members increases, meaning that selection tends toward decreasing the amount of information stored in the hypercycle. Moreover, there is also a problem with adding new information into the system. In order to be preserved, the new information has to appear near to the core of the spiral wave. However, this would make the system vulnerable to parasites, and, as a consequence, the hypercycle would not be stable. Therefore, stable spiral waves are characterized by once-for-ever selection, which creates the restrictions that, on the one hand, once the information is added to the system, it cannot be easily abandoned; and on the other hand, new information cannot be added.[9]
Another model based on cellular automata, taking into account a simpler replicating network of continuously mutating parasites and their interactions with one replicase species, was proposed by Takeuchi and Hogeweg[4] and exhibited an emergent travelling wave pattern. Surprisingly, travelling waves not only proved to be stable against moderately strong parasites, if the parasites' mutation rate is not too high, but the emergent pattern itself was generated as a result of interactions between parasites and replicase species. The same technique was used to model systems that include formation of complexes.[51] Finally, hypercycle simulation extending to three dimensions showed the emergence of the three-dimensional analogue of a spiral wave, namely, the scroll wave.[52]
8. Comparison with Other Theories of Life
The hypercycle is just one of several current theories of life, including the chemoton[53] of Tibor Gánti, the (M,R) systems[54][55] of Robert Rosen, autopoiesis (or self-building)[56] of Humberto Maturana and Francisco Varela, and the autocatalytic sets[57] of Stuart Kauffman, similar to an earlier proposal by Freeman Dyson.[58] All of these (including the hypercycle) found their original inspiration in Erwin Schrödinger's book What is Life?[59] but at first they appear to have little in common with one another, largely because the authors did not communicate with one another, and none of them made any reference in their principal publications to any of the other theories. Nonetheless, there are more similarities than may be obvious at first sight, for example between Gánti and Rosen.[60] Until recently[61][62][63] there have been almost no attempts to compare the different theories and discuss them together.
9. Last Universal Common Ancestor (LUCA)
Some authors equate models of the origin of life with LUCA, the Last Universal Common Ancestor of all extant life.[64] This is a serious error resulting from failure to recognize that L refers to the last common ancestor, not to the first ancestor, which is much older: a large amount of evolution occurred before the appearance of LUCA.[65]
Gill and Forterre expressed the essential point as follows:[66]
LUCA should not be confused with the first cell, but was the product of a long period of evolution. Being the "last" means that LUCA was preceded by a long succession of older "ancestors."
References
- Eigen, Manfred (October 1971). "Selforganization of matter and the evolution of biological macromolecules". Die Naturwissenschaften 58 (10): 465–523. doi:10.1007/BF00623322. PMID 4942363. Bibcode: 1971NW.....58..465E. https://dx.doi.org/10.1007%2FBF00623322
- Boerlijst, Maarten C.; Hogeweg, Pauline (November 1995). "Spatial gradients enhance persistence of hypercycles". Physica D: Nonlinear Phenomena 88 (1): 29–39. doi:10.1016/0167-2789(95)00178-7. Bibcode: 1995PhyD...88...29B. https://dx.doi.org/10.1016%2F0167-2789%2895%2900178-7
- Boerlijst, M.C.; Hogeweg, P. (February 1991). "Spiral wave structure in pre-biotic evolution: Hypercycles stable against parasites". Physica D: Nonlinear Phenomena 48 (1): 17–28. doi:10.1016/0167-2789(91)90049-F. Bibcode: 1991PhyD...48...17B. https://dx.doi.org/10.1016%2F0167-2789%2891%2990049-F
- Hogeweg, Paulien; Takeuchi, Nobuto (2003). "Multilevel Selection in Models of Prebiotic Evolution: Compartments and Spatial Self-organization". Origins of Life and Evolution of the Biosphere 33 (4/5): 375–403. doi:10.1023/A:1025754907141. PMID 14604183. Bibcode: 2003OLEB...33..375H. https://dx.doi.org/10.1023%2FA%3A1025754907141
- Takeuchi, Nobuto; Hogeweg, Paulien; Stormo, Gary D. (16 October 2009). "Multilevel Selection in Models of Prebiotic Evolution II: A Direct Comparison of Compartmentalization and Spatial Self-Organization". PLOS Computational Biology 5 (10): e1000542. doi:10.1371/journal.pcbi.1000542. PMID 19834556. Bibcode: 2009PLSCB...5E0542T. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2757730
- Takeuchi, Nobuto; Hogeweg, Paulien (September 2012). "Evolutionary dynamics of RNA-like replicator systems: A bioinformatic approach to the origin of life". Physics of Life Reviews 9 (3): 219–263. doi:10.1016/j.plrev.2012.06.001. PMID 22727399. Bibcode: 2012PhLRv...9..219T. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3466355
- Szathmáry, Eörs; Demeter, László (1987). "Group selection of early replicators and the origin of life". Journal of Theoretical Biology 128 (4): 463–486. doi:10.1016/S0022-5193(87)80191-1. PMID 2451771. Bibcode: 1987JThBi.128..463S. https://dx.doi.org/10.1016%2FS0022-5193%2887%2980191-1
- Musso, Fabio (16 March 2010). "A Stochastic Version of the Eigen Model". Bulletin of Mathematical Biology 73 (1): 151–180. doi:10.1007/s11538-010-9525-4. PMID 20232170. https://dx.doi.org/10.1007%2Fs11538-010-9525-4
- May, Robert M. (17 October 1991). "Hypercycles spring to life". Nature 353 (6345): 607–608. doi:10.1038/353607a0. Bibcode: 1991Natur.353..607M. https://dx.doi.org/10.1038%2F353607a0
- MC Boerlijst, P Hogeweg (1991) "Self-structuring and selection: Spiral Waves as a Substrate for Prebiotic Evolution". Conference Paper Artificial Life II
- Vaidya, Nilesh; Manapat, Michael L.; Chen, Irene A.; Xulvi-Brunet, Ramon; Hayden, Eric J.; Lehman, Niles (17 October 2012). "Spontaneous network formation among cooperative RNA replicators". Nature 491 (7422): 72–77. doi:10.1038/nature11549. PMID 23075853. Bibcode: 2012Natur.491...72V. https://dx.doi.org/10.1038%2Fnature11549
- Szathmáry, Eörs (2013). "On the propagation of a conceptual error concerning hypercycles and cooperation". Journal of Systems Chemistry 4 (1): 1. doi:10.1186/1759-2208-4-1. https://dx.doi.org/10.1186%2F1759-2208-4-1
- Schuster, M. Eigen ; P. (1979). The Hypercycle : a principle of natural self-organization (Reprint. ed.). Berlin [West] [u.a.]: Springer. ISBN 9783540092933.
- Kruger, Kelly; Grabowski, Paula J.; Zaug, Arthur J.; Sands, Julie; Gottschling, Daniel E.; Cech, Thomas R. (1982). "Self-splicing RNA: Autoexcision and autocyclization of the ribosomal RNA intervening sequence of tetrahymena". Cell 31 (1): 147–157. doi:10.1016/0092-8674(82)90414-7. ISSN 0092-8674. PMID 6297745. https://dx.doi.org/10.1016%2F0092-8674%2882%2990414-7
- Guerrier-Takada, Cecilia; Gardiner, Katheleen; Marsh, Terry; Pace, Norman; Altman, Sidney (1983). "The RNA moiety of ribonuclease P is the catalytic subunit of the enzyme". Cell 35 (3): 849–857. doi:10.1016/0092-8674(83)90117-4. ISSN 0092-8674. PMID 6197186. https://dx.doi.org/10.1016%2F0092-8674%2883%2990117-4
- Johnston, W. K. (18 May 2001). "RNA-Catalyzed RNA Polymerization: Accurate and General RNA-Templated Primer Extension". Science 292 (5520): 1319–1325. doi:10.1126/science.1060786. PMID 11358999. Bibcode: 2001Sci...292.1319J. https://dx.doi.org/10.1126%2Fscience.1060786
- Drake, J. W. (1 May 1993). "Rates of spontaneous mutation among RNA viruses.". Proceedings of the National Academy of Sciences 90 (9): 4171–4175. doi:10.1073/pnas.90.9.4171. PMID 8387212. Bibcode: 1993PNAS...90.4171D. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=46468
- Drake, JW; Charlesworth, B; Charlesworth, D; Crow, JF (April 1998). "Rates of spontaneous mutation.". Genetics 148 (4): 1667–86. doi:10.1093/genetics/148.4.1667. PMID 9560386. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1460098
- STADLER, BÄRBEL M. R.; STADLER, PETER F. (March 2003). "Molecular Replicator Dynamics". Advances in Complex Systems 06 (1): 47–77. doi:10.1142/S0219525903000724. https://dx.doi.org/10.1142%2FS0219525903000724
- Maynard Smith, J.; Szathmáry, E. (1995). The Major Transitions in Evolution. Oxford University Press. ISBN 978-0198502944.
- Eigen, Manfred; Schuster, Peter (1977). "The hypercycle. A principle of natural self-organization. Part A: Emergence of the hypercycle.". Naturwissenschaften 64 (11): 541–565. doi:10.1007/BF00450633. PMID 593400. Bibcode: 1977NW.....64..541E. https://dx.doi.org/10.1007%2FBF00450633
- Hofbauer, J.; Schuster, P.; Sigmund, K.; Wolff, R. (April 1980). "Dynamical Systems Under Constant Organization II: Homogeneous Growth Functions of Degree $p = 2$". SIAM Journal on Applied Mathematics 38 (2): 282–304. doi:10.1137/0138025. https://dx.doi.org/10.1137%2F0138025
- Hofbauer, J.; Schuster, P.; Sigmund, K. (February 1981). "Competition and cooperation in catalytic selfreplication". Journal of Mathematical Biology 11 (2): 155–168. doi:10.1007/BF00275439. https://dx.doi.org/10.1007%2FBF00275439
- Schuster, P; Sigmund, K; Wolff, R (June 1979). "Dynamical systems under constant organization. III. Cooperative and competitive behavior of hypercycles". Journal of Differential Equations 32 (3): 357–368. doi:10.1016/0022-0396(79)90039-1. Bibcode: 1979JDE....32..357S. https://dx.doi.org/10.1016%2F0022-0396%2879%2990039-1
- Eigen, M.; Schuster, P. (1982). "Stages of emerging life — Five principles of early organization". Journal of Molecular Evolution 19 (1): 47–61. doi:10.1007/BF02100223. PMID 7161810. Bibcode: 1982JMolE..19...47E. https://dx.doi.org/10.1007%2FBF02100223
- Crick, F. H. C.; Brenner, S.; Klug, A.; Pieczenik, G. (December 1976). "A speculation on the origin of protein synthesis". Origins of Life 7 (4): 389–397. doi:10.1007/BF00927934. PMID 1023138. Bibcode: 1976OrLi....7..389C. https://dx.doi.org/10.1007%2FBF00927934
- Szathmáry, Eörs; Gladkih, Irina (May 1989). "Sub-exponential growth and coexistence of non-enzymatically replicating templates". Journal of Theoretical Biology 138 (1): 55–58. doi:10.1016/S0022-5193(89)80177-8. PMID 2483243. Bibcode: 1989JThBi.138...55S. https://dx.doi.org/10.1016%2FS0022-5193%2889%2980177-8
- Bresch, C.; Niesert, U.; Harnasch, D. (1980). "Hypercycles, parasites and packages". Journal of Theoretical Biology 85 (3): 399–405. doi:10.1016/0022-5193(80)90314-8. ISSN 0022-5193. PMID 6893729. Bibcode: 1980JThBi..85..399B. https://dx.doi.org/10.1016%2F0022-5193%2880%2990314-8
- Eigen, M.; Gardiner, W.C.; Schuster, P. (August 1980). "Hypercycles and compartments". Journal of Theoretical Biology 85 (3): 407–411. doi:10.1016/0022-5193(80)90315-X. PMID 6160360. https://dx.doi.org/10.1016%2F0022-5193%2880%2990315-X
- ZINTZARAS, ELIAS; SANTOS, MAURO; SZATHMÁRY, EÖRS (July 2002). ""Living" Under the Challenge of Information Decay: The Stochastic Corrector Model vs. Hypercycles". Journal of Theoretical Biology 217 (2): 167–181. doi:10.1006/jtbi.2002.3026. PMID 12202111. Bibcode: 2002JThBi.217..167Z. https://dx.doi.org/10.1006%2Fjtbi.2002.3026
- Attwater, James; Wochner, Aniela; Holliger, Philipp (20 October 2013). "In-ice evolution of RNA polymerase ribozyme activity". Nature Chemistry 5 (12): 1011–1018. doi:10.1038/nchem.1781. PMID 24256864. Bibcode: 2013NatCh...5.1011A. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3920166
- Mutschler, Hannes; Wochner, Aniela; Holliger, Philipp (4 May 2015). "Freeze–thaw cycles as drivers of complex ribozyme assembly". Nature Chemistry 7 (6): 502–508. doi:10.1038/nchem.2251. PMID 25991529. Bibcode: 2015NatCh...7..502M. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4495579
- Sczepanski, Jonathan T.; Joyce, Gerald F. (29 October 2014). "A cross-chiral RNA polymerase ribozyme". Nature 515 (7527): 440–442. doi:10.1038/nature13900. PMID 25363769. Bibcode: 2014Natur.515..440S. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4239201
- Cech, Thomas R.; Zhang, Biliang (6 November 1997). "Peptide bond formation by in vitro selected ribozymes". Nature 390 (6655): 96–100. doi:10.1038/36375. PMID 9363898. Bibcode: 1997Natur.390...96Z. https://dx.doi.org/10.1038%2F36375
- Robertson, MP; Hesselberth, JR; Ellington, AD (April 2001). "Optimization and optimality of a short ribozyme ligase that joins non-Watson-Crick base pairings.". RNA 7 (4): 513–23. doi:10.1017/s1355838201002199. PMID 11345430. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1370105
- Paul, N.; Joyce, G. F. (18 September 2002). "A self-replicating ligase ribozyme". Proceedings of the National Academy of Sciences 99 (20): 12733–12740. doi:10.1073/pnas.202471099. PMID 12239349. Bibcode: 2002PNAS...9912733P. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=130529
- Bartel, David P.; Unrau, Peter J. (17 September 1998). "RNA-catalysed nucleotide synthesis". Nature 395 (6699): 260–263. doi:10.1038/26193. PMID 9751052. Bibcode: 1998Natur.395..260U. https://dx.doi.org/10.1038%2F26193
- Bianconi, Ginestra; Zhao, Kun; Chen, Irene A.; Nowak, Martin A.; Doebeli, Michael (9 May 2013). "Selection for Replicases in Protocells". PLOS Computational Biology 9 (5): e1003051. doi:10.1371/journal.pcbi.1003051. PMID 23671413. Bibcode: 2013PLSCB...9E3051B. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3649988
- Ekland, E.; Szostak, J.; Bartel, D. (21 July 1995). "Structurally complex and highly active RNA ligases derived from random RNA sequences". Science 269 (5222): 364–370. doi:10.1126/science.7618102. PMID 7618102. Bibcode: 1995Sci...269..364E. https://dx.doi.org/10.1126%2Fscience.7618102
- Suga, Hiroaki; Lee, Nick; Bessho, Yoshitaka; Wei, Kenneth; Szostak, Jack W. (1 January 2000). "Ribozyme-catalyzed tRNA aminoacylation". Nature Structural Biology 7 (1): 28–33. doi:10.1038/71225. PMID 10625423. https://dx.doi.org/10.1038%2F71225
- Costanzo, G.; Pino, S.; Ciciriello, F.; Di Mauro, E. (2 October 2009). "Generation of Long RNA Chains in Water". Journal of Biological Chemistry 284 (48): 33206–33216. doi:10.1074/jbc.M109.041905. PMID 19801553. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2785163
- Szathmary, E. (29 October 2006). "The origin of replicators and reproducers". Philosophical Transactions of the Royal Society B: Biological Sciences 361 (1474): 1761–1776. doi:10.1098/rstb.2006.1912. PMID 17008217. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1664675
- Nowak, Martin A. (2006). Evolutionary dynamics : exploring the equations of life. Cambridge, Mass. [u.a.]: Belknap Press of Harvard Univ. Press. ISBN 9780674023383.
- Hayden, Eric J.; Lehman, Niles (August 2006). "Self-Assembly of a Group I Intron from Inactive Oligonucleotide Fragments". Chemistry & Biology 13 (8): 909–918. doi:10.1016/j.chembiol.2006.06.014. PMID 16931340. https://dx.doi.org/10.1016%2Fj.chembiol.2006.06.014
- Smith, John Maynard (9 August 1979). "Hypercycles and the origin of life". Nature 280 (5722): 445–446. doi:10.1038/280445a0. PMID 460422. Bibcode: 1979Natur.280..445S. https://dx.doi.org/10.1038%2F280445a0
- Sigmund, Josef Hofbauer; Karl (1992). The theory of evolution and dynamical systems : mathematical aspects of selection (Repr. ed.). Cambridge [u.a.]: Cambridge Univ. Press. ISBN 978-0-521-35838-5.
- McCaskill, J.S.; Füchslin, R.M.; Altmeyer, S. (30 January 2001). "The Stochastic Evolution of Catalysts in Spatially Resolved Molecular Systems". Biological Chemistry 382 (9): 1343–63. doi:10.1515/BC.2001.167. PMID 11688718. https://dx.doi.org/10.1515%2FBC.2001.167
- Szabó, Péter; Scheuring, István; Czárán, Tamás; Szathmáry, Eörs (21 November 2002). "In silico simulations reveal that replicators with limited dispersal evolve towards higher efficiency and fidelity". Nature 420 (6913): 340–343. doi:10.1038/nature01187. PMID 12447445. Bibcode: 2002Natur.420..340S. https://dx.doi.org/10.1038%2Fnature01187
- Wasik, Szymon; Jackowiak, Paulina; Krawczyk, Jacek B.; Kedziora, Paweł; Formanowicz, Piotr; Figlerowicz, Marek; Błażewicz, Jacek (2010). "Towards Prediction of HCV Therapy Efficiency". Computational and Mathematical Methods in Medicine 11 (2): 185–199. doi:10.1080/17486700903170712. PMID 20461597. https://dx.doi.org/10.1080%2F17486700903170712
- Wasik, Szymon; Jackowiak, Paulina; Figlerowicz, Marek; Blazewicz, Jacek (February 2014). "Multi-agent model of hepatitis C virus infection". Artificial Intelligence in Medicine 60 (2): 123–131. doi:10.1016/j.artmed.2013.11.001. PMID 24309221. https://zenodo.org/record/846783.
- Takeuchi, Nobuto; Hogeweg, Paulien (23 October 2007). "The Role of Complex Formation and Deleterious Mutations for the Stability of RNA-Like Replicator Systems". Journal of Molecular Evolution 65 (6): 668–686. doi:10.1007/s00239-007-9044-6. PMID 17955153. Bibcode: 2007JMolE..65..668T. https://dx.doi.org/10.1007%2Fs00239-007-9044-6
- S Altmeyer, C Wilke, T Martinetz (2008) "How fast do structures emerge in hypercycle-systems?" in Third German Workshop on Artificial Life
- Gánti, Tibor (2003). The Principles of Life. Oxford University Press. ISBN 9780198507260.
- Rosen, R. (1958). "The representation of biological systems from the standpoint of the theory of categories". Bull. Math. Biophys. 20 (4): 317–341. doi:10.1007/BF02477890. https://dx.doi.org/10.1007%2FBF02477890
- Rosen, R. (1991). Life Itself: a comprehensive inquiry into the nature, origin, and fabrication of life. New York: Columbia University Press.
- Maturana, H. R.; Varela, F. (1980). Autopoiesis and cognition: the realisation of the living. Dordrecht: D. Reidel Publishing Company.
- Kauffman, S. A. (1969). "Metabolic stability and epigenesis in randomly constructed genetic nets". J. Theor. Biol. 22 (3): 437–467. doi:10.1016/0022-5193(69)90015-0. PMID 5803332. https://dx.doi.org/10.1016%2F0022-5193%2869%2990015-0
- Dyson, F. J. (1982). "A model for the origin of life". J. Mol. Evol. 18 (5): 344–350. doi:10.1007/bf01733901. https://dx.doi.org/10.1007%2Fbf01733901
- Schrödinger, Erwin (1944). What is Life?. Cambridge University Press.
- Cornish-Bowden, A. (2015). "Tibor Gánti and Robert Rosen: contrasting approaches to the same problem". J. Theor. Biol. 381: 6–10. doi:10.1016/j.jtbi.2015.05.015. PMID 25988381. https://dx.doi.org/10.1016%2Fj.jtbi.2015.05.015
- Letelier, J C; Cárdenas, M L; Cornish-Bowden, A (2011). "From L'Homme Machine to metabolic closure: steps towards understanding life". J. Theor. Biol. 286 (1): 100–113. doi:10.1016/j.jtbi.2011.06.033. PMID 21763318. https://dx.doi.org/10.1016%2Fj.jtbi.2011.06.033
- Igamberdiev, A.U. (2014). "Time rescaling and pattern formation in biological evolution". BioSystems 123: 19–26. doi:10.1016/j.biosystems.2014.03.002. PMID 24690545. https://dx.doi.org/10.1016%2Fj.biosystems.2014.03.002
- Cornish-Bowden, A; Cárdenas, M L (2020). "Contrasting theories of life: historical context, current theories. In search of an ideal theory". BioSystems 188: 104063. doi:10.1016/j.biosystems.2019.104063. PMID 31715221. https://dx.doi.org/10.1016%2Fj.biosystems.2019.104063
- Jheeta, S.; Chatzitheodoridis, E.; Devine, Kevin; Block, J. (2021). "The Way forward for the Origin of Life: Prions and Prion-Like Molecules First Hypothesis". Life 11 (9): 872. doi:10.3390/life11090872. PMID 34575021. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=8467930
- Cornish-Bowden, A; Cárdenas, M L (2017). "Life before LUCA". J. Theor. Biol. 434: 68–74. doi:10.1016/j.jtbi.2017.05.023. PMID 28536033. https://dx.doi.org/10.1016%2Fj.jtbi.2017.05.023
- Gill, S.; Forterre, P. (2016). "Origin of life: LUCA and extracellular membrane vesicles (EMVs)". Int. J. Astrobiol. 15 (1): 7–15. doi:10.1017/S1473550415000282. https://dx.doi.org/10.1017%2FS1473550415000282

