Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Tin Lai | -- | 1873 | 2022-10-10 13:34:49 | | | |
| 2 | Conner Chen | + 7 word(s) | 1880 | 2022-10-11 05:05:40 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Lai, T. Visual-Simultaneous Localisation and Mapping. Encyclopedia. Available online: https://encyclopedia.pub/entry/28741 (accessed on 24 June 2026).
Lai T. Visual-Simultaneous Localisation and Mapping. Encyclopedia. Available at: https://encyclopedia.pub/entry/28741. Accessed June 24, 2026.
Lai, Tin. "Visual-Simultaneous Localisation and Mapping" Encyclopedia, https://encyclopedia.pub/entry/28741 (accessed June 24, 2026).
Lai, T. (2022, October 10). Visual-Simultaneous Localisation and Mapping. In Encyclopedia. https://encyclopedia.pub/entry/28741
Lai, Tin. "Visual-Simultaneous Localisation and Mapping." Encyclopedia. Web. 10 October, 2022.
Copy Citation
Simultaneous Localisation and Mapping (SLAM) is one of the fundamental problems in autonomous mobile robots where a robot needs to reconstruct a previously unseen environment while simultaneously localising itself with respect to the map. In particular, Visual-SLAM uses various sensors from the mobile robot for collecting and sensing a representation of the map.
Visual SLAM
Simultaneous Localisation and Mapping
deep-learning SLAM
1. Visual-SLAM
Visual-Simultaneous Localisation and Mapping (SLAM) and sensors have been the main research direction for SLAM solutions due to their capability of collecting a large amount of information and measurement range for mapping. The principle of Visual-SLAM lies in a sequential estimation of the camera motions depending on the perceived movements of pixels in the image sequence. Besides robotics, Visual-SLAM is also essential for many enormous vision-based applications such as virtual and augmented reality. Many existing Visual-SLAM methods explicitly model camera projections, motions, and environments based on visual geometry. Recently, many methods have assigned and incorporated semantic meaning to the observed objects to provide a more successful localisation that is robust against observation noise and dynamic objects. The following sections will introduce the different families of algorithms within the branch of Visual-SLAM.
2. Feature-Based and Direct SLAM
Feature-based SLAM can be divided into filter-based and Bundle Adjustment based methods. Earlier SLAM approaches utilised extended Kalman filters (EKFs) for estimating the robot pose while updating the landmarks observed by the robots simultaneously [1][2][3]. However, the computational complexity of these methods increased with the number of landmarks, and they did not efficiently handle non-linearities in the measurements [4]. FastSLAM was proposed to improve the EKF-SLAM by combining particle filters with EKFs for landmark estimation [5]. However, it also suffered from the limitations of sample degeneracy when sampling the proposal distribution. Parallel Tracking and Mapping [6] was proposed to address the issue by splitting the pose and map estimation into separate threads, which enhance their real-time performance [7][8].
A place recognition system with ORB features was first proposed in [9], which is developed based on Bag-of-Words (BoW). The ORB is a rotational invariant and scale-aware feature [10], which can be used to extract features at a high frequency. Place recognition algorithms can often be highly efficient and run in real time. The algorithm is helpful in relocalisation and loop-closure for Visual-SLAM, and it is further developed with monocular cameras for operating in a large-scale environment [11].
RGB-D SLAM [11] is another feature-based SLAM that uses feature points for generating dense and accurate 3D maps. Several models are proposed to utilise the active camera sensor to develop a 6-DOF motion tracking model capable of 3D reconstruction and achieve impressive performance even under challenging scenarios [12][13]. In contrast to low-level point features, high-level objects often provide a more accurate tracking performance. For example, using a planar SLAM system, people can detect the planar in the environment for yielding a planar map while detecting objects such as desks and chairs for localisatino [14]. The recognition of the objects, however, requires an offline supervised-learning procedure before executing the SLAM procedure.
Direct SLAM refers to methods that directly use the input images without any feature detector and descriptors. In contrast to feature-based methods, these feature-less approaches are generally used in photometric consistency to register two successive images. Using deep-learning models for extracting the environment’s feature representation is promising in numerous robotic domains [15][16]. For example, DTAM [17], Large-Scale Direct (LSD)-SLAM [18] and SVO [19] are some of the models that had gain lots of successes. DSO models [20][21] are also shown to be capable of using bundle adjustment pipeline of temporal multi-view stereo for achieving high accuracy in a real-time system. In additions, models such as CodeSLAM [22] and CNN-SLAM [23] use deep-learning approach for extracting a dense representations of the environment for performing direct SLAM. However, direct SLAM is often more time-consuming when compared to feature-based SLAM since they operate directly on the image space.
3. Localisation with Scene Modelling
Deep learning plays an essential role in scene understanding by utilising a range of information in techniques such as CNN classifications. CNN can be utilised over RGB images for extracting semantic information such as detecting scene or pedestrians within the images [24][25][26]. CNN can also directly operates on captured point cloud information from range-based sensors such as Light Detection and Ranging (LiDAR). Models such as PointNet [27] in Figure 1 can understand classifying the class of the objects based purely on point clouds. For example, PointNet++ [27], TangentConvolutions [28], DOPS [29], and RandLA-Net [30] are some of the recent deep learning models that can perform semantic understanding using a large scale of point clouds. Most models are trained on some point cloud dataset that enables the model to infer objects and scene information based purely on the geometric orientations of the input points.
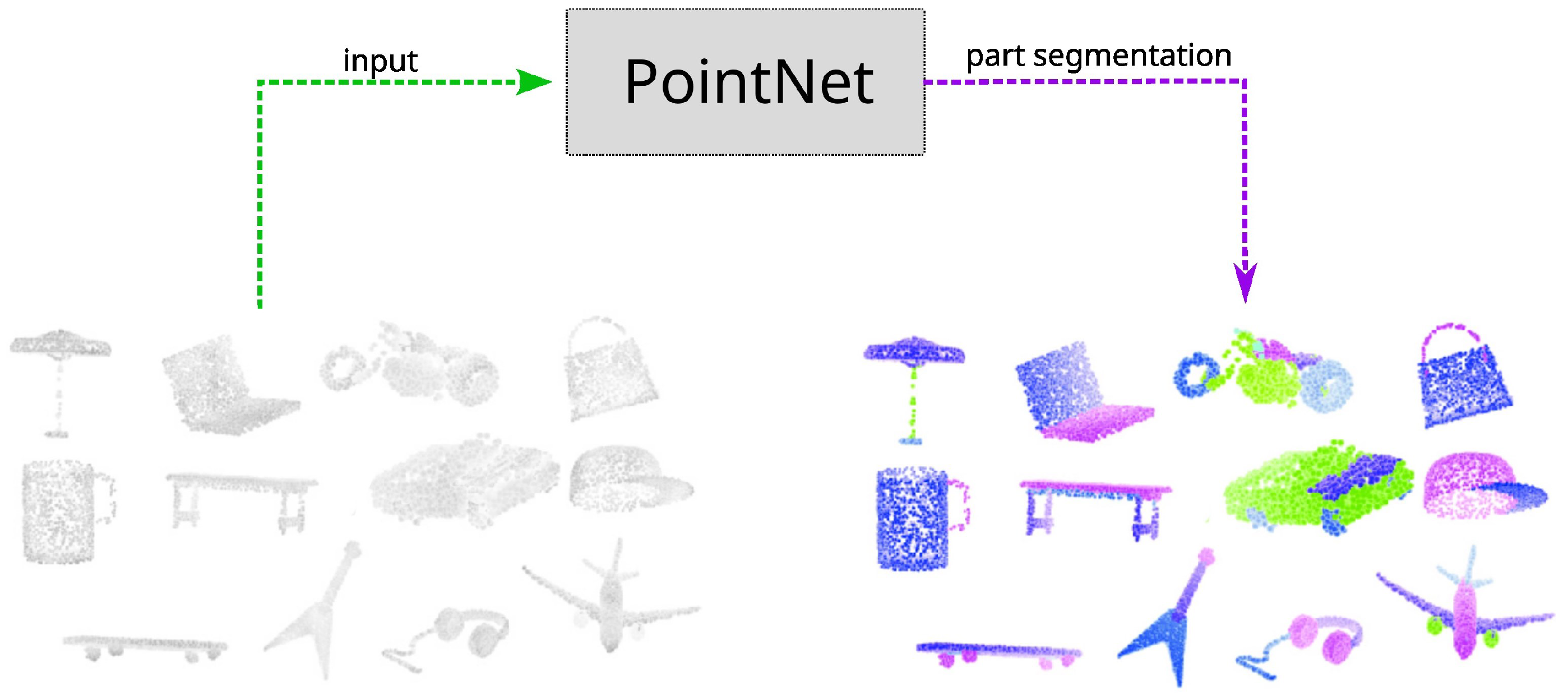
Figure 1. Example of using PointNet [27] for performing part segmentation directly on input point clouds.
Dynamic objects can introduce difficulties in SLAM during loop-closure due to the moving objects. SLAM can tackle this difficulty by utilising semantics information to filter dynamic objects from the input images [31]. Using the scene understanding module, people can filter out moving objects from the images to prevent the SLAM algorithm conditioning on dynamic objects. For example, the SUMA++ model illustrated on the right of Figure 2 can obtain a semantic understanding of each detected object to filter out dynamic objects such as pedestrians and other moving vehicles. However, the increased SLAM accuracy comes with the cost of lowering the accuracy of the estimated robot pose due to the method neglecting parts of the perceived information.
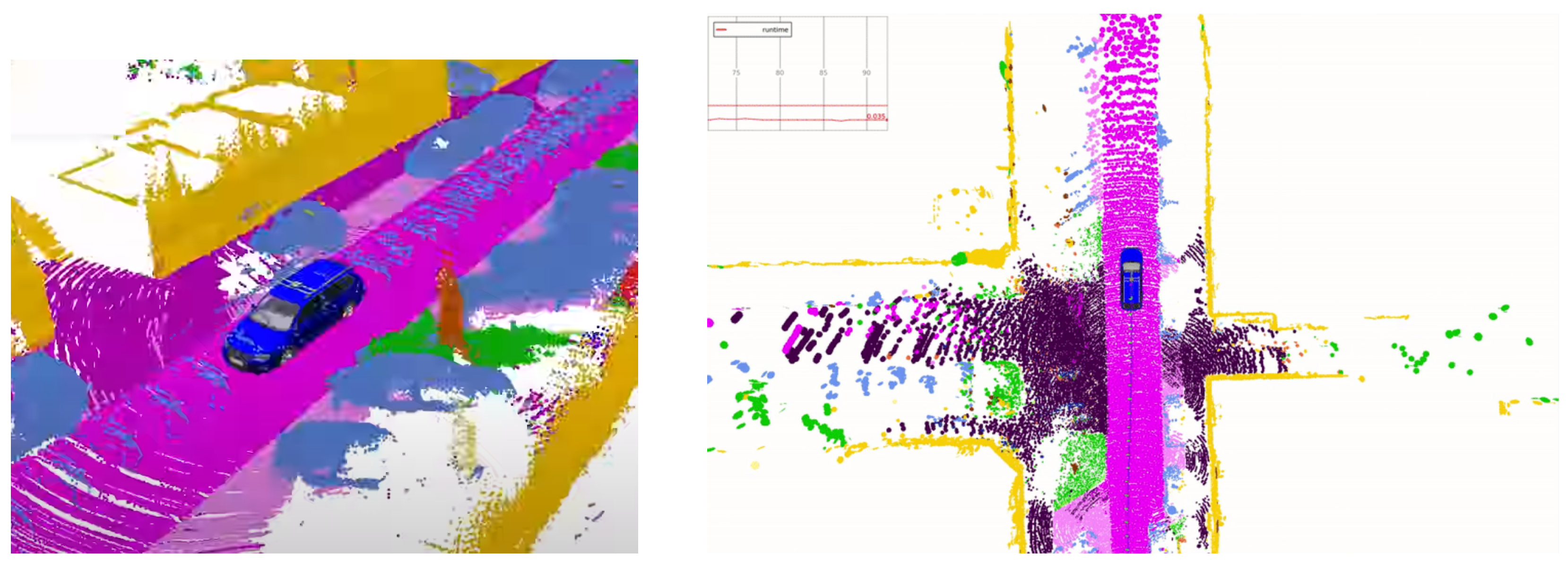
Figure 2. Using environment features to create a semantic map. SUMA++ [32] operating under an environment using LiDAR sensors, which provides rich information to understand the environment around the vehicle.
4. Scene Modelling with Typological Relationship and Dynamic Models
Scene graphs is a different approach to building a model of the environment that includes both the metric, semantic, and primary topological relationship between the scene objects and the overall environment [33]. Scene graphs can construct an environmental graph that spans an entire building, including objects, materials and rooms within the building [34]. The main disadvantage of scene graphs is the need to compute offline, requiring a known 3D mesh of the building with the registered RGB images to generate the 3D scene graphs. Previous approaches rely on registering RGB images with the 3D mesh of the buildings for generating the 3D scene graphs, which limits their applicability to static environments. Figure 3 illustrates one of the approaches, Dynamic scene graphs (DSG) [35], that can also include dynamic elements within the environment. For example, DSG can model humans that are navigating within the building. The original DSG approach needs to be built offline, but an extension has been proposed [35] which is capable of building a 3D dynamic DSG from visual-inertial data in a fully automatic manner. The approach first builds a 3D mesh-based semantic map fed to the dynamic scene generator.

Figure 3. Using Dynamic Scene Graph (DSG) [35] for generating multi-layer abstraction of an indoor environment.
In addition, people can perform reasoning on the current situation by projecting what will likely happen based on previous events [36]. This class of methods relies on predicting the possible future state of the robot by conditioning on the current belief of robot state and the robot’s dynamic model [37]. In addition, dynamic models can be incorporated into the objects in the surrounding environment, such as pedestrians and vehicles, for the model to recognise the predicted future pose of the nearby objects with some amount of uncertainty [38].
5. Semantic Understanding with Segmentation
Pixel-wise semantic segmentation is another promising direction in SLAM semantic understanding. FCN [24] is a fully convolutional neural network that uses pixel-wise segmentation in the computer vision community for SLAM. ParseNet derived a similar CNN architecture [39] and injected the global context information into the global pooling layers in FCN. The global context information allows the model to achieve better scene segmentation with a more feature-rich representation of the network. SegNet is another novel netowkr [40] that uses an encoder-decoder architecture for segmentation. The decoder architecture helps upsample the captured low-resolution features from the images. Bayesian approaches are helpful in many learning-based robotics application [41][42]. Bayesian SegNet [41] took a probabilistic approach by using dropout layers in the original SegNet for sampling. The Bayesian approach estimates the probability for pixel-level segmentation, which often outperforms the original approach. Conditional Random Fields had been combined with CNN architecture [43] for deriving a mean-field approximate inference as Recurrent neural Networks.
Semantic information is particularly valued in an environment where a robot needs to interact with human [44]. The progress in computer vision semantic segmentation using deep learning is constructive for pushing the research progress in semantic SLAM. By combining model-based SLAM methods with spatio-temporal CNN-based semantic segmentation [45], people can often provide the SLAM model with a more informative feature representation for localisation. The proposed system can simultaneously perform 3D semantic scene mapping and 6-DOF localisation even in a large indoor environment. Pixel-voxel netowk [46] is another similar approach that uses CNN-like architecture for semantic mapping. SemanticFusion [47] integrates the CNN-based semantic segmentation with the dense SLAM technology ElasticFusion [48], resulting in a model that produces a dense semantic map and performs well in an indoor environment.
6. Sensors Fusions for Semantic Scene Understanding
With the recent advancements in Deep Learning, numerous Visual-SLAM have also gained treatment success in using the learned models for semantic understanding using data fusion. Models such as Frustrum PointNets [49] utilise both RGB camera and LiDAR sensors to improve the accuracy of understanding the semantics of the scene. Figure 4 illustrates how Frustrum PointNet utilises information from both sensors for data fusion, where a PointNet is first applied for object instance segmentation and amodal bounding box regression. Sensor fusion provides a more rich feature representation for performing data association. For example, VINet is a sensor fusion network [50] that can use the estimated pose from DeepVO [51] along with the inertial sensor readings with an LSTM. During the model training procedure, the prediction and the fusion network are trained jointly to allow the gradient to pass through the entire network. Therefore, both networks can compensate each other, and the fusion system has high performance compared to traditional sensor fusion methods. The same methodology can also be used as a fusion system [52] which is capable of fusing the 6-DOF pose data from the cameras and the magnetic sensors [53].
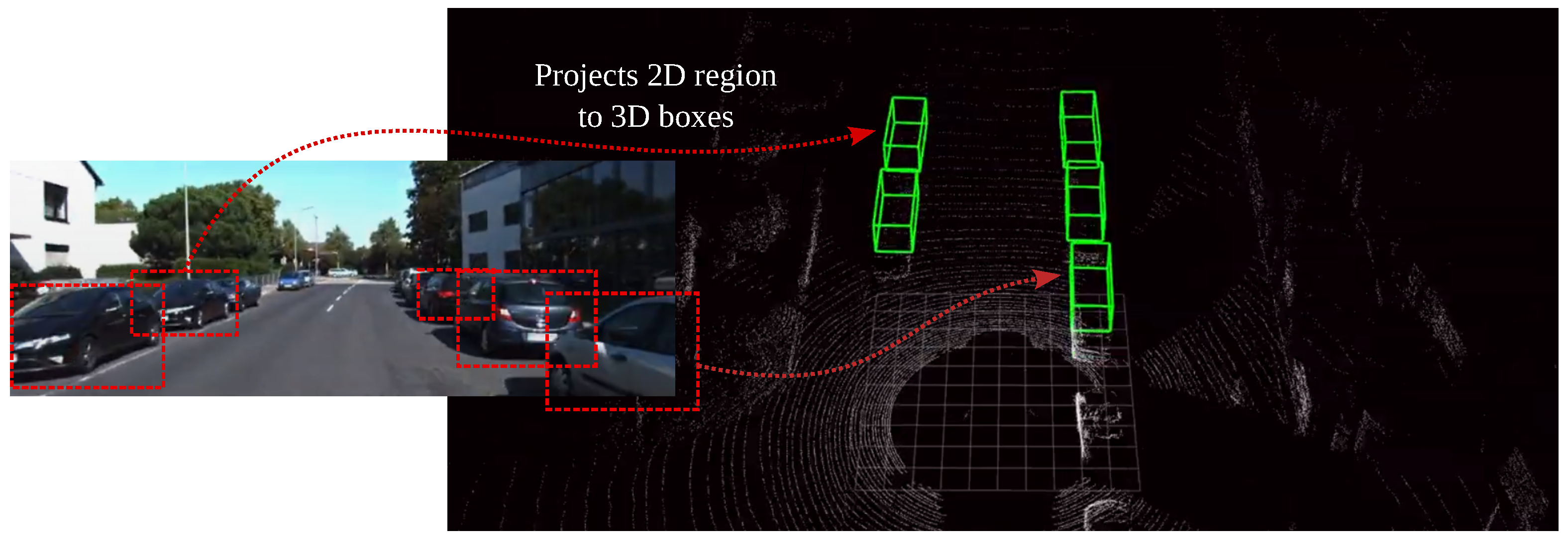
Figure 4. Multi-modal model Frustrum PointNets [49] which uses CNN model to projects detected objects from RGB images into 3D space, thus improving the accuracy on semantic understanding.
The information obtained from a camera can also be fused with GPS, INS, and wheel odometry readings as an ego-motion estimation system [54]. The model essentially uses deep learning to capture the temporal motion dynamics. The motion from the camera is utilised in a mixture density network to construct an optical flow vector for better estimation. Direct methods for visual odometry (VO) can often exploit information from the intensity level gathered from the input images. However, these methods cannot guarantee optimality compared to feature-based methods. Semi-direct VO (SVO2) [55] is a hybrid method that uses direct methods to track pixels while relying on feature-based methods for joint optimisation of structure and motions. The hybrid methods take advantage of both approaches to improve the robustness of VO. Similar approaches such as VINS-Fusion [56] are capable of using IMU fused with monocular visual input for estimating odometry with high reliability. Deep neural networks can further learn the rigid-body motion in a CNN architecture [57] using raw point cloud data as input for predicting the SE3 rigid transformation of the robot.
References
- Guivant, J.E.; Nebot, E.M. Optimization of the Simultaneous Localization and Map-Building Algorithm for Real-Time Implementation. IEEE Trans. Robot. Autom. 2001, 17, 242–257.
- Leonard, J.J.; Feder, H.J.S. A Computationally Efficient Method for Large-Scale Concurrent Mapping and Localization. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2000; pp. 169–176.
- Lu, F.; Milios, E. Globally Consistent Range Scan Alignment for Environment Mapping. Auton. Robot. 1997, 4, 333–349.
- Bailey, T.; Nieto, J.; Guivant, J.; Stevens, M.; Nebot, E. Consistency of the EKF-SLAM Algorithm. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 3562–3568.
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem. In Proceedings of the AAAI/IAAI, Edmonton, AB, Canada, 28 July–1 August 2002; pp. 593–598. Available online: https://www.aaai.org/Papers/AAAI/2002/AAAI02-089.pdf (accessed on 18 September 2022).
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234.
- Castle, R.; Klein, G.; Murray, D.W. Video-Rate Localization in Multiple Maps for Wearable Augmented Reality. In Proceedings of the 2008 12th IEEE International Symposium on Wearable Computers, Pittsburgh, PA, USA, 28 September–1 October 2008; pp. 15–22.
- Pradeep, V.; Rhemann, C.; Izadi, S.; Zach, C.; Bleyer, M.; Bathiche, S. MonoFusion: Real-time 3D Reconstruction of Small Scenes with a Single Web Camera. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, SA, Australia, 1–4 October 2013; pp. 83–88.
- Mur-Artal, R.; Tardós, J.D. Fast Relocalisation and Loop Closing in Keyframe-Based SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 846–853.
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571.
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D Mapping with an RGB-D Camera. IEEE Trans. Robot. 2013, 30, 177–187.
- Kueng, B.; Mueggler, E.; Gallego, G.; Scaramuzza, D. Low-Latency Visual Odometry Using Event-Based Feature Tracks. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 16–23.
- Kim, H.; Leutenegger, S.; Davison, A.J. Real-Time 3D Reconstruction and 6-DoF Tracking with an Event Camera. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 349–364.
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. Slam++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359.
- Hewing, L.; Wabersich, K.P.; Menner, M.; Zeilinger, M.N. Learning-Based Model Predictive Control: Toward Safe Learning in Control. Annu. Rev. Control. Robot. Auton. Syst. 2020, 3, 269–296.
- Lai, T.; Ramos, F. Plannerflows: Learning Motion Samplers with Normalising Flows. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems, Prague, Czech Republic, 27 September–1 October 2021; pp. 2542–2548.
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense Tracking and Mapping in Real-Time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327.
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale Direct Monocular SLAM. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 834–849.
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast Semi-Direct Monocular Visual Odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22.
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625.
- Wang, R.; Schworer, M.; Cremers, D. Stereo DSO: Large-scale Direct Sparse Visual Odometry with Stereo Cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3903–3911.
- Bloesch, M.; Czarnowski, J.; Clark, R.; Leutenegger, S.; Davison, A.J. CodeSLAM—Learning a Compact, Optimisable Representation for Dense Visual SLAM. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2560–2568.
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. Cnn-Slam: Real-time Dense Monocular Slam with Learned Depth Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6243–6252.
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Geraldes, R.; Gonçalves, A.; Lai, T.; Villerabel, M.; Deng, W.; Salta, A.; Nakayama, K.; Matsuo, Y.; Prendinger, H. UAV-based Situational Awareness System Using Deep Learning. IEEE Access 2019, 7, 122583–122594.
- Peng, C.; Zhang, K.; Ma, Y.; Ma, J. Cross Fusion Net: A Fast Semantic Segmentation Network for Small-Scale Semantic Information Capturing in Aerial Scenes. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13.
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660.
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q.Y. Tangent Convolutions for Dense Prediction in 3d. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3887–3896.
- Najibi, M.; Lai, G.; Kundu, A.; Lu, Z.; Rathod, V.; Funkhouser, T.; Pantofaru, C.; Ross, D.; Davis, L.S.; Fathi, A. Dops: Learning to Detect 3d Objects and Predict Their 3d Shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11913–11922.
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117.
- Wang, Z.; Zhang, Q.; Li, J.; Zhang, S.; Liu, J. A Computationally Efficient Semantic Slam Solution for Dynamic Scenes. Remote Sens. 2019, 11, 1363.
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguere, P.; Behley, J.; Stachniss, C. Suma++: Efficient Lidar-Based Semantic Slam. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4530–4537.
- Armeni, I.; He, Z.Y.; Gwak, J.; Zamir, A.R.; Fischer, M.; Malik, J.; Savarese, S. 3d Scene Graph: A Structure for Unified Semantics, 3d Space, and Camera. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5664–5673.
- Wald, J.; Dhamo, H.; Navab, N.; Tombari, F. Learning 3d Semantic Scene Graphs from 3d Indoor Reconstructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3961–3970.
- Rosinol, A.; Violette, A.; Abate, M.; Hughes, N.; Chang, Y.; Shi, J.; Gupta, A.; Carlone, L. Kimera: From SLAM to Spatial Perception with 3D Dynamic Scene Graphs. Int. J. Robot. Res. 2021, 40, 1510–1546.
- Castillo-Lopez, M.; Ludivig, P.; Sajadi-Alamdari, S.A.; Sanchez-Lopez, J.L.; Olivares-Mendez, M.A.; Voos, H. A Real-Time Approach for Chance-Constrained Motion Planning with Dynamic Obstacles. IEEE Robot. Autom. Lett. 2020, 5, 3620–3625.
- Sanchez-Lopez, J.L.; Arellano-Quintana, V.; Tognon, M.; Campoy, P.; Franchi, A. Visual Marker Based Multi-Sensor Fusion State Estimation. IFAC-PapersOnLine 2017, 50, 16003–16008.
- Lefkopoulos, V.; Menner, M.; Domahidi, A.; Zeilinger, M.N. Interaction-Aware Motion Prediction for Autonomous Driving: A Multiple Model Kalman Filtering Scheme. IEEE Robot. Autom. Lett. 2020, 6, 80–87.
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking Wider to See Better. arXiv 2015, arXiv:1506.04579.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495.
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian Segnet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. arXiv 2015, arXiv:1511.02680.
- Lai, T.; Morere, P.; Ramos, F.; Francis, G. Bayesian Local Sampling-Based Planning. IEEE Robot. Autom. Lett. 2020, 5, 1954–1961.
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional Random Fields as Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1529–1537.
- Hülse, M.; McBride, S.; Lee, M. Fast Learning Mapping Schemes for Robotic Hand–Eye Coordination. Cogn. Comput. 2010, 2, 1–16.
- Li, R.; Gu, D.; Liu, Q.; Long, Z.; Hu, H. Semantic Scene Mapping with Spatio-Temporal Deep Neural Network for Robotic Applications. Cogn. Comput. 2018, 10, 260–271.
- Zhao, C.; Sun, L.; Purkait, P.; Duckett, T.; Stolkin, R. Dense Rgb-d Semantic Mapping with Pixel-Voxel Neural Network. Sensors 2018, 18, 3099.
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. Semanticfusion: Dense 3d Semantic Mapping with Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635.
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.; Glocker, B.; Davison, A. ElasticFusion: Dense SLAM without a pose graph. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015; Available online: https://spiral.imperial.ac.uk/bitstream/10044/1/23438/2/whelan2015rss.pdf (accessed on 18 September 2022).
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum Pointnets for 3d Object Detection from Rgb-d Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927.
- Clark, R.; Wang, S.; Wen, H.; Markham, A.; Trigoni, N. Vinet: Visual-inertial Odometry as a Sequence-to-Sequence Learning Problem. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31.
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. Deepvo: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2043–2050.
- Turan, M.; Almalioglu, Y.; Gilbert, H.; Sari, A.E.; Soylu, U.; Sitti, M. Endo-VMFuseNet: Deep Visual-Magnetic Sensor Fusion Approach for Uncalibrated, Unsynchronized and Asymmetric Endoscopic Capsule Robot Localization Data. arXiv 2017, arXiv:1709.06041.
- Turan, M.; Almalioglu, Y.; Gilbert, H.; Araujo, H.; Cemgil, T.; Sitti, M. Endosensorfusion: Particle Filtering-Based Multi-Sensory Data Fusion with Switching State-Space Model for Endoscopic Capsule Robots. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5393–5400.
- Pillai, S.; Leonard, J.J. Towards Visual Ego-Motion Learning in Robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5533–5540.
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2017, 33, 249–265.
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020.
- Byravan, A.; Fox, D. Se3-Nets: Learning Rigid Body Motion Using Deep Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 173–180.
More
Information
Subjects:
Robotics
Contributor
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
810
Revisions:
2 times
(View History)
Update Date:
11 Oct 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No