 +1 credit
+1 credit
Video Upload Options
Temporal envelope (ENV) and temporal fine structure (TFS) are changes in the amplitude and frequency of sound perceived by humans over time. These temporal changes are responsible for several aspects of auditory perception, including loudness, pitch and timbre perception and spatial hearing. Complex sounds such as speech or music are decomposed by the peripheral auditory system of humans into narrow frequency bands. The resulting narrow-band signals convey information at different time scales ranging from less than one millisecond to hundreds of milliseconds. A dichotomy between slow "temporal envelope" cues and faster "temporal fine structure" cues has been proposed to study several aspects of auditory perception (e.g., loudness, pitch and timbre perception, auditory scene analysis, sound localization) at two distinct time scales in each frequency band. Over the last decades, a wealth of psychophysical, electrophysiological and computational studies based on this envelope/fine-structure dichotomy have examined the role of these temporal cues in sound identification and communication, how these temporal cues are processed by the peripheral and central auditory system, and the effects of aging and cochlear damage on temporal auditory processing. Although the envelope/fine-structure dichotomy has been debated and questions remain as to how temporal fine structure cues are actually encoded in the auditory system, these studies have led to a range of applications in various fields including speech and audio processing, clinical audiology and rehabilitation of sensorineural hearing loss via hearing aids or cochlear implants.
1. Definition
Notions of temporal envelope and temporal fine structure may have different meanings in many studies. An important distinction to make is between the physical (i.e., acoustical) and the biological (or perceptual) description of these ENV and TFS cues.
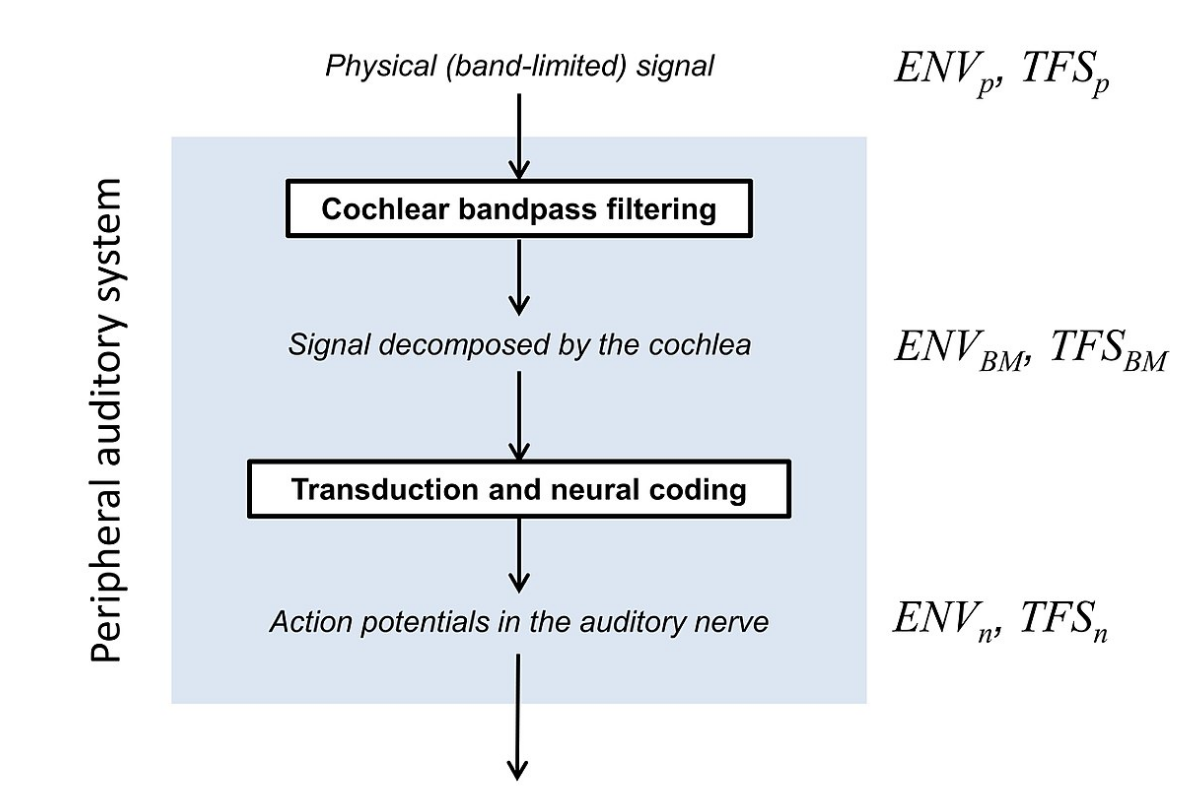
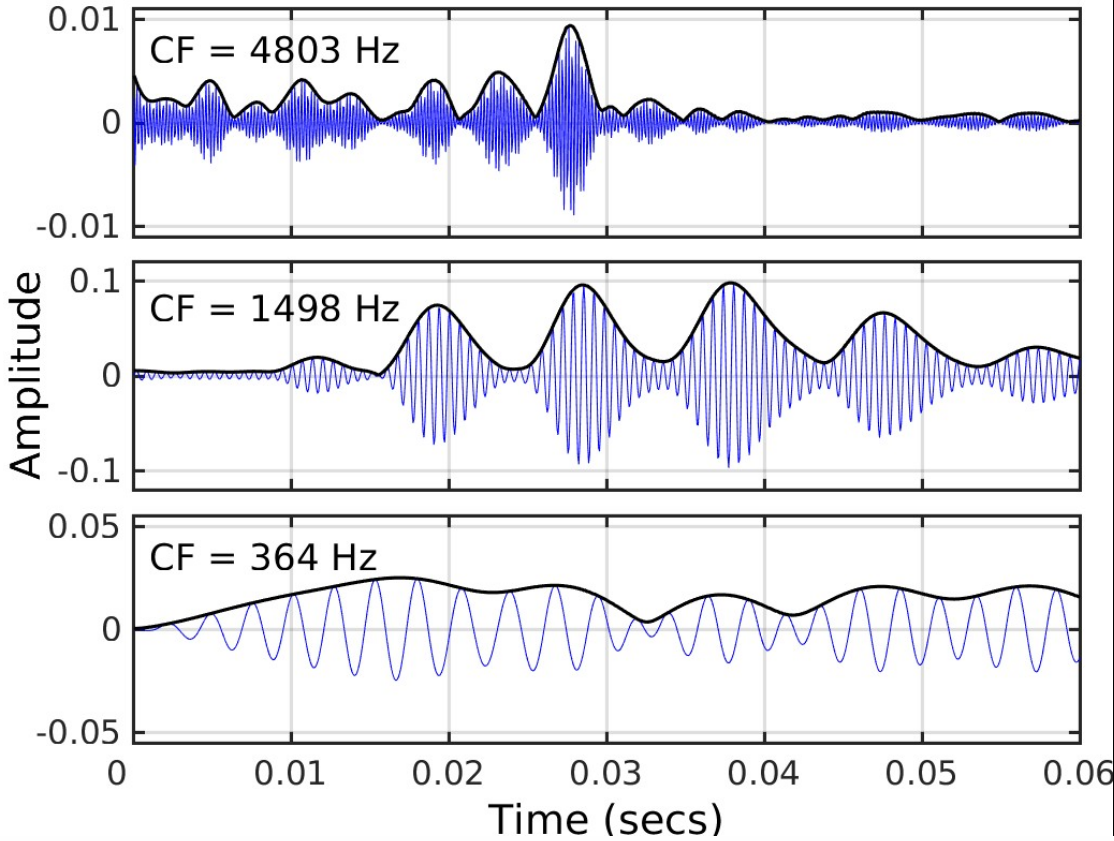
Any sound whose frequency components cover a narrow range (called a narrowband signal) can be considered as an envelope (ENVp, where p denotes the physical signal) superimposed on a more rapidly oscillating carrier, the temporal fine structure (TFSp).[1]
Many sounds in everyday life, including speech and music, are broadband; the frequency components spread over a wide range and there is no well-defined way to represent the signal in terms of ENVp and TFSp. However, in a normally functioning cochlea, complex broadband signals are decomposed by the filtering on the basilar membrane (BM) within the cochlea into a series of narrowband signals.[2] Therefore, the waveform at each place on the BM can be considered as an envelope (ENVBM) superimposed on a more rapidly oscillating carrier, the temporal fine structure (TFSBM).[3] The ENVBM and TFSBM depend on the place along the BM. At the apical end, which is tuned to low (audio) frequencies, ENVBM and TFSBM vary relatively slowly with time, while at the basal end, which is tuned to high frequencies, both ENVBM and TFSBM vary more rapidly with time.[3]
Both ENVBM and TFSBM are represented in the time patterns of action potentials in the auditory nerve[4] these are denoted ENVn and TFSn. TFSn is represented most prominently in neurons tuned to low frequencies, while ENVn is represented most prominently in neurons tuned to high (audio) frequencies.[4][5] For a broadband signal, it is not possible to manipulate TFSp without affecting ENVBM and ENVn, and it is not possible to manipulate ENVp without affecting TFSBM and TFSn.[6][7]
2. Temporal Envelope (ENV) Processing
2.1. Neurophysiological Aspects
The neural representation of stimulus envelope, ENVn, has typically been studied using well-controlled ENVp modulations, that is sinusoidally amplitude-modulated (AM) sounds. Cochlear filtering limits the range of AM rates encoded in individual auditory-nerve fibers. In the auditory nerve, the strength of the neural representation of AM decreases with increasing modulation rate. At the level of the cochlear nucleus, several cell types show an enhancement of ENVn information. Multipolar cells can show band-pass tuning to AM tones with AM rates between 50 and 1000 Hz.[8][9] Some of these cells show an excellent response to the ENVn and provide inhibitory sideband inputs to other cells in the cochlear nucleus giving a physiological correlate of comodulation masking release, a phenomenon whereby the detection of a signal in a masker is improved when the masker has correlated envelope fluctuations across frequency (see section below).[10][11]
Responses to the temporal-envelope cues of speech or other complex sounds persist up the auditory pathway, eventually to the various fields of the auditory cortex in many animals. In the Primary Auditory Cortex, responses can encode AM rates by phase-locking up to about 20–30 Hz,[12][13][14][15] while faster rates induce sustained and often tuned responses.[16][17] A topographical representation of AM rate has been demonstrated in the primary auditory cortex of awake macaques.[18] This representation is approximately perpendicular to the axis of the tonotopic gradient, consistent with an orthogonal organization of spectral and temporal features in the auditory cortex. Combining these temporal responses with the spectral selectivity of A1 neurons gives rise to the spectro-temporal receptive fields that often capture well cortical responses to complex modulated sounds.[19][20] In secondary auditory cortical fields, responses become temporally more sluggish and spectrally broader, but are still able to phase-lock to the salient features of speech and musical sounds.[21][22][23][24] Tuning to AM rates below about 64 Hz is also found in the human auditory cortex [25][26][27][28] as revealed by brain-imaging techniques (fMRI) and cortical recordings in epileptic patients (electrocorticography). This is consistent with neuropsychological studies of brain-damaged patients[29] and with the notion that the central auditory system performs some form of spectral decomposition of the ENVp of incoming sounds. The ranges over which cortical responses encode well the temporal-envelope cues of speech have been shown to be predictive of the human ability to understand speech. In the human superior temporal gyrus (STG), an anterior-posterior spatial organization of spectro-temporal modulation tuning has been found in response to speech sounds, the posterior STG being tuned for temporally fast varying speech sounds with low spectral modulations and the anterior STG being tuned for temporally slow varying speech sounds with high spectral modulations.[30]
One unexpected aspect of phase locking in the auditory cortex has been observed in the responses elicited by complex acoustic stimuli with spectrograms that exhibit relatively slow envelopes (< 20 Hz), but that are carried by fast modulations that are as high as hundreds of Hertz. Speech and music, as well as various modulated noise stimuli have such temporal structure.[31] For these stimuli, cortical responses phase-lock to both the envelope and fine-structure induced by interactions between unresolved harmonics of the sound, thus reflecting the pitch of the sound, and exceeding the typical lower limits of cortical phase-locking to the envelopes of a few 10’s of Hertz. This paradoxical relation[31][32] between the slow and fast cortical phase-locking to the carrier “fine structure” has been demonstrated both in the auditory[31] and visual[33] cortices. It has also been shown to be amply manifested in measurements of the spectro-temporal receptive fields of the primary auditory cortex giving them unexpectedly fine temporal accuracy and selectivity bordering on a 5-10 ms resolution.[31][33] The underlying causes of this phenomenon have been attributed to several possible origins, including nonlinear synaptic depression and facilitation, and/or a cortical network of thalamic excitation and cortical inhibition.[31][34][35][36] There are many functionally significant and perceptually relevant reasons for the coexistence of these two complementary dynamic response modes. They include the ability to accurately encode onsets and other rapid ‘events’ in the ENVp of complex acoustic and other sensory signals, features that are critical for the perception of consonants (speech) and percussive sounds (music), as well as the texture of complex sounds.[31][37]
2.2. Psychoacoustical Aspects
The perception of ENVp depends on which AM rates are contained in the signal. Low rates of AM, in the 1–8 Hz range, are perceived as changes in perceived intensity, that is loudness fluctuations (a percept that can also be evoked by frequency modulation, FM); at higher rates, AM is perceived as roughness, with the greatest roughness sensation occurring at around 70 Hz;[38] at even higher rates, AM can evoke a weak pitch percept corresponding to the modulation rate.[39] Rainstorms, crackling fire, chirping crickets or galloping horses produce "sound textures" - the collective result of many similar acoustic events - which perception is mediated by ENVn statistics.[40][41]
The auditory detection threshold for AM as a function of AM rate, referred to as the temporal modulation transfer function (TMTF),[42] is best for AM rates in the range from 4 – 150 Hz and worsens outside that range[42][43][44] The cutoff frequency of the TMTF gives an estimate of temporal acuity (temporal resolution) for the auditory system. This cutoff frequency corresponds to a time constant of about 1 - 3 ms for the auditory system of normal-hearing humans.
Correlated envelope fluctuations across frequency in a masker can aid detection of a pure tone signal, an effect known as comodulation masking release.[11]
AM applied to a given carrier can perceptually interfere with the detection of a target AM imposed on the same carrier, an effect termed modulation masking.[45][46] Modulation-masking patterns are tuned (greater masking occurs for masking and target AMs close in modulation rate), suggesting that the human auditory system is equipped with frequency-selective channels for AM. Moreover, AM applied to spectrally remote carriers can perceptually interfere with the detection of AM on a target sound, an effect termed modulation detection interference.[47] The notion of modulation channels is also supported by the demonstration of selective adaptation effects in the modulation domain.[48][49][50] These studies show that AM detection thresholds are selectively elevated above pre-exposure thresholds when the carrier frequency and the AM rate of the adaptor are similar to those of the test tone.
Human listeners are sensitive to relatively slow "second-order" AMs cues correspond to fluctuations in the strength of AM. These cues arise from the interaction of different modulation rates, previously described as "beating" in the envelope-frequency domain. Perception of second-order AM has been interpreted as resulting from nonlinear mechanisms in the auditory pathway that produce an audible distortion component at the envelope beat frequency in the internal modulation spectrum of the sounds.[51][52][53]
Interaural time differences in the envelope provide binaural cues even at high frequencies where TFSn cannot be used.[54]
2.3. Models of Normal Envelope Processing
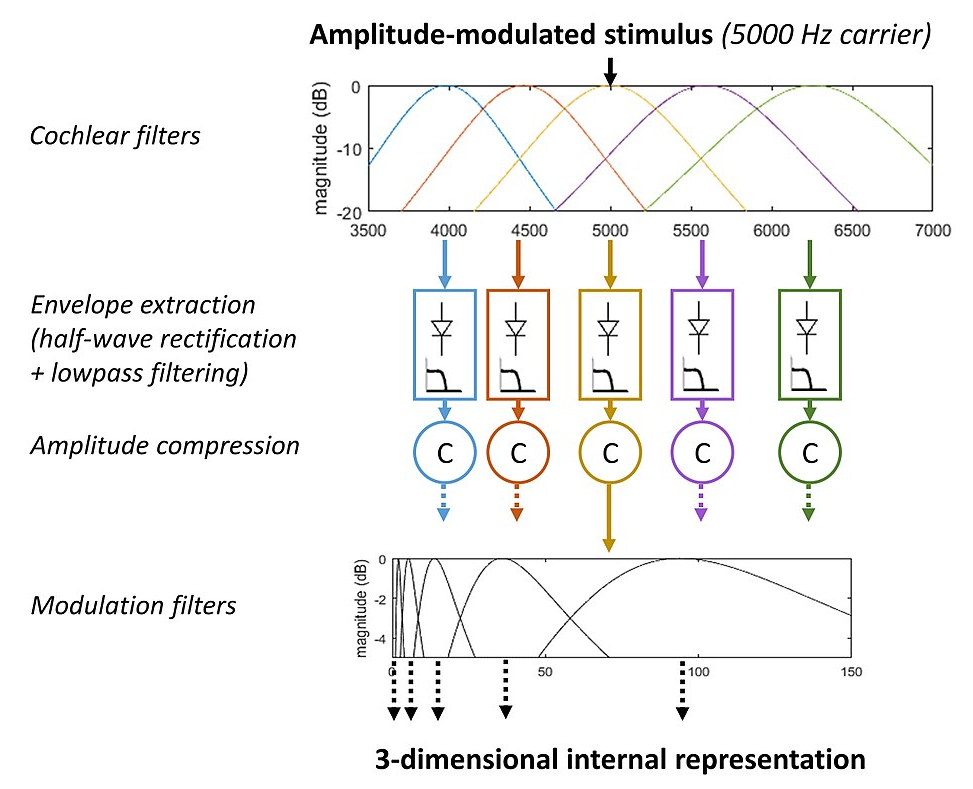
The most basic computer model of ENV processing is the leaky integrator model.[42][55] This model extracts the temporal envelope of the sound (ENVp) via bandpass filtering, half-wave rectification (which may be followed by fast-acting amplitude compression), and lowpass filtering with a cutoff frequency between about 60 and 150 Hz. The leaky integrator is often used with a decision statistic based on either the resulting envelope power, the max/min ratio, or the crest factor. This model accounts for the loss of auditory sensitivity for AM rates higher than about 60–150 Hz for broadband noise carriers.[42] Based on the concept of frequency selectivity for AM,[46] the perception model of Torsten Dau[56] incorporates broadly tuned bandpass modulation filters (with a Q value around 1) to account for data from a broad variety of psychoacoustic tasks and particularly AM detection for noise carriers with different bandwidths, taking into account their intrinsic envelope fluctuations. This model of has been extended to account for comodulation masking release (see sections above).[57] The shapes of the modulation filters have been estimated[58] and an “envelope power spectrum model” (EPSM) based on these filters can account for AM masking patterns and AM depth discrimination.[59] The EPSM has been extended to the prediction of speech intelligibility[60] and to account for data from a broad variety of psychoacoustic tasks.[61] A physiologically-based processing model simulating brainstem responses has also been developed to account for AM detection and AM masking patterns.[62]
3. Temporal Fine Structure (TFS) Processing
31. Neurophysiological Aspects
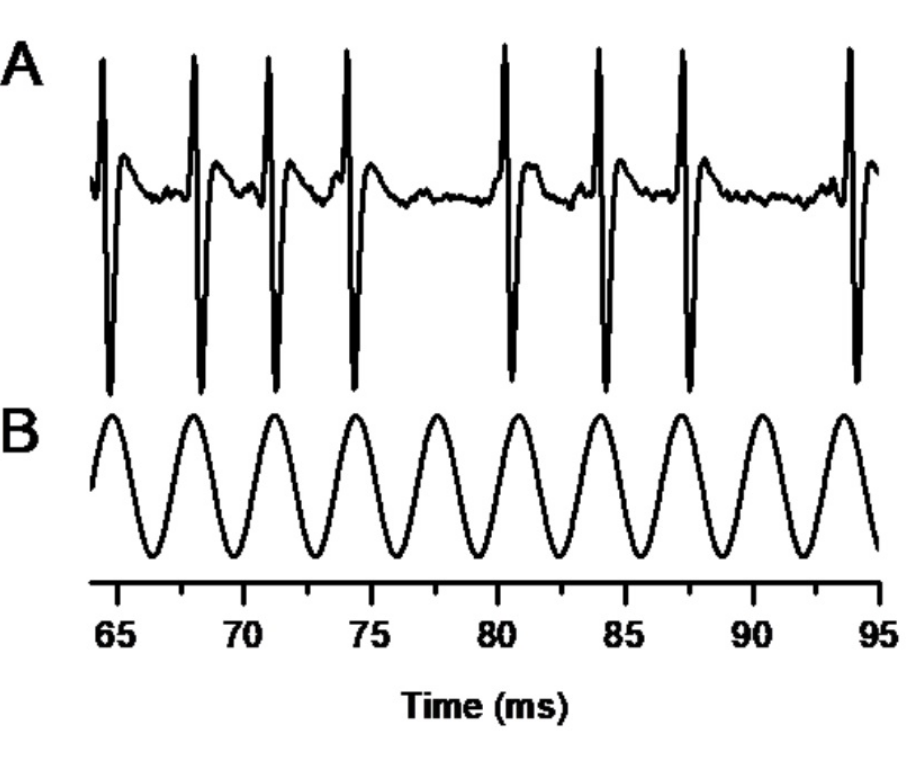
The neural representation of temporal fine structure, TFSn, has been studied using stimuli with well-controlled TFSp: pure tones, harmonic complex tones, and frequency-modulated (FM) tones.
Auditory-nerve fibres are able to represent low-frequency sounds via their phase-locked discharges (i.e., TFSn information). The upper frequency limit for phase locking is species dependent. It is about 5 kHz in the cat, 9 kHz in the barn owl and just 4 kHz in the guinea pig. We do not know the upper limit of phase locking in humans but current, indirect, estimates suggest it is about 4–5 kHz.[63] Phase locking is a direct consequence of the transduction process with an increase in probability of transduction channel opening occurring with a stretching of the stereocilia and decrease in channel opening occurring when pushed in the opposite direction. This has led some to suggest that phase locking is an epiphenomenon. The upper limit appears to be determined by a cascade of low pass filters at the level of the inner hair cell and auditory-nerve synapse.[64][65]
TFSn information in the auditory nerve may be used to encode the (audio) frequency of low-frequency sounds, including single tones and more complex stimuli such as frequency-modulated tones or steady-state vowels (see role and applications to speech and music).
The auditory system goes to some length to preserve this TFSn information with the presence of giant synapses (End bulbs of Held) in the ventral cochlear nucleus. These synapses contact bushy cells (Spherical and globular) and faithfully transmit (or enhance) the temporal information present in the auditory nerve fibers to higher structures in the brainstem.[66] The bushy cells project to the medial superior olive and the globular cells project to the medial nucleus of the trapezoid body (MNTB). The MNTB is also characterized by giant synapses (calyces of Held) and provides precisely timed inhibition to the lateral superior olive. The medial and lateral superior olive and MNTB are involved in the encoding of interaural time and intensity differences. There is general acceptance that the temporal information is crucial in sound localization but it is still contentious as to whether the same temporal information is used to encode the frequency of complex sounds.
Several problems remain with the idea that the TFSn is important in the representation of the frequency components of complex sounds. The first problem is that the temporal information deteriorates as it passes through successive stages of the auditory pathway (presumably due to the low pass dendritic filtering). Therefore, the second problem is that the temporal information must be extracted at an early stage of the auditory pathway. No such stage has currently been identified although there are theories about how temporal information can be converted into rate information (see section Models of normal processing: Limitations).
3.2. Psychoacoustical Aspects
It is often assumed that many perceptual capacities rely on the ability of the monaural and binaural auditory system to encode and use TFSn cues evoked by components in sounds with frequencies below about 1–4 kHz. These capacities include discrimination of frequency,[67][68][69][70] discrimination of the fundamental frequency of harmonic sounds,[68][69][70] detection of FM at rates below 5 Hz,[71] melody recognition for sequences of pure tones and complex tones,[67][68] lateralization and localization of pure tones and complex tones,[72] and segregation of concurrent harmonic sounds (such as speech sounds).[73] It appears that TFSn cues require correct tonotopic (place) representation to be processed optimally by the auditory system.[74] Moreover, musical pitch perception has been demonstrated for complex tones with all harmonics above 6 kHz, demonstrating that it is not entirely dependent on neural phase locking to TFSBM (i.e., TFSn) cues.[75]
As for FM detection, the current view assumes that in the normal auditory system, FM is encoded via TFSn cues when the FM rate is low (<5 Hz) and when the carrier frequency is below about 4 kHz,[71][76][77][78] and via ENVn cues when the FM is fast or when the carrier frequency is higher than 4 kHz.[71][78][79][80][81] This is supported by single-unit recordings in the low brainstem.[66] According to this view, TFSn cues are not used to detect FM with rates above about 10 Hz because the mechanism decoding the TFSn information is “sluggish” and cannot track rapid changes in frequency.[71] Several studies have shown that auditory sensitivity to slow FM at low carrier frequency is associated with speech identification for both normal-hearing and hearing-impaired individuals when speech reception is limited by acoustic degradations (e.g., filtering) or concurrent speech sounds.[82][83][84][85][86] This suggests that robust speech intelligibility is determined by accurate processing of TFSn cues.
3.3. Models of Normal Processing: Limitations
The separation of a sound into ENVp and TFSp appears inspired partly by how sounds are synthesized and by the availability of a convenient way to separate an existing sound into ENV and TFS, namely the Hilbert transform. There is a risk that this view of auditory processing[87] is dominated by these physical/technical concepts, similarly to how cochlear frequency-to-place mapping was for a long time conceptualized in terms of the Fourier transform. Physiologically, there is no indication of a separation of ENV and TFS in the auditory system for stages up to the cochlear nucleus. Only at that stage does it appear that parallel pathways, potentially enhancing ENVn or TFSn information (or something akin to it), may be implemented through the temporal response characteristics of different cochlear nucleus cell types.[66] It may therefore be useful to better simulate cochlear nucleus cell types to understand the true concepts for parallel processing created at the level of the cochlear nucleus. These concepts may be related to separating ENV and TFS but are unlikely realized like the Hilbert transform.
A computational model of the peripheral auditory system[88][89] may be used to simulate auditory-nerve fiber responses to complex sounds such as speech, and quantify the transmission (i.e., internal representation) of ENVn and TFSn cues. In two simulation studies,[90][91] the mean-rate and spike-timing information was quantified at the output of such a model to characterize, respectively, the short-term rate of neural firing (ENVn) and the level of synchronization due to phase locking (TFSn) in response to speech sounds degraded by vocoders.[92][93] The best model predictions of vocoded-speech intelligibility were found when both ENVn and TFSn cues were included, providing evidence that TFSn cues are important for intelligibility when the speech ENVp cues are degraded.
At a more fundamental level, similar computational modeling was used to demonstrate that the functional dependence of human just-noticeable-frequency-differences on pure-tone frequency were not accounted for unless temporal information was included (notably most so for mid-high frequencies, even above the nominal cutoff in physiological phase locking).[94][95] However, a caveat of most TFS models is that optimal model performance with temporal information typically over-estimates human performance.
An alternative view is to assume that TFSn information at the level of the auditory nerve is converted into rate-place (ENVn) information at a later stage of the auditory system (e.g., the low brainstem). Several modelling studies proposed that the neural mechanisms for decoding TFSn are based on correlation of the outputs of adjacent places.[96][97][98][99][100]
4. Role in Speech and Music Perception
4.1. Role of Temporal Envelope in Speech and Music Perception
The ENVp plays a critical role in many aspects of auditory perception, including in the perception of speech and music.[102][103][104][105] Speech recognition is possible using cues related to the ENVp, even in situations where the original spectral information and TFSp are highly degraded.[106] Indeed, when the spectrally local TFSp from one sentence is combined with the ENVp from a second sentence, only the words of the second sentence are heard.[107] The ENVp rates most important for speech are those below about 16 Hz, corresponding to fluctuations at the rate of syllables.[101][108][109] On the other hand, the fundamental frequency (“pitch”) contour of speech sounds is primarily conveyed via TFSp cues,[101] although some information on the contour can be perceived via rapid envelope fluctuations corresponding to the fundamental frequency.[102] For music, slow ENVp rates convey rhythm and tempo information, whereas more rapid rates convey the onset and offset properties of sound (attack and decay, respectively) that are important for timbre perception.[110]
4.2. Role of TFS in Speech and Music Perception
The ability to accurately process TFSp information is thought to play a role in our perception of pitch (i.e., the perceived height of sounds), an important sensation for music perception, as well as our ability to understand speech, especially in the presence of background noise.[68]
Role of TFS in pitch perception
Although pitch retrieval mechanisms in the auditory system are still a matter of debate,[70][111] TFSn information may be used to retrieve the pitch of low-frequency pure tones[69] and estimate the individual frequencies of the low-numbered (ca. 1st-8th) harmonics of a complex sound,[112] frequencies from which the fundamental frequency of the sound can be retrieved according to, e.g., pattern-matching models of pitch perception.[113] A role of TFSn information in pitch perception of complex sounds containing intermediate harmonics (ca. 7th-16th) has also been suggested[114] and may be accounted for by temporal or spectrotemporal[115] models of pitch perception. The degraded TFSn cues conveyed by cochlear implant devices may also be partly responsible for impaired music perception of cochlear implant recipients.[116]
Role of TFS cues in speech perception
TFSp cues are thought to be important for the identification of speakers and for tone identification in tonal languages.[117] In addition, several vocoder studies have suggested that TFSp cues contribute to the intelligibility of speech in quiet and noise.[92] Although it is difficult to isolate TFSp from ENVp cues,[105][118] there is evidence from studies in hearing-impaired listeners that speech perception in the presence of background noise can be partly accounted for by the ability to accurately process TFSp,[86][93] although the ability to “listen in the dips” of fluctuating maskers does not seem to depend on periodic TFSp cues.[119]
5. Role in Auditory Scene Analysis
Auditory scene analysis refers to the ability to perceive separately sounds coming from different sources. Any acoustical difference can potentially lead to auditory segregation,[120] and so any cues based either on ENVp or TFSp are likely to assist in segregating competing sound sources.[121] Such cues involve percepts such as pitch.[122][123][124][125] Binaural TFSp cues producing interaural time differences have not always resulted in clear source segregation, particularly with simultaneously presented sources, although successful segregation of sequential sounds, such as noise or speech, have been reported.[126]
6. Effects of Age and Hearing Loss on Temporal Envelope Processing
6.1. Developmental Aspects
In infancy, behavioral AM detection thresholds[127] and forward or backward masking thresholds[127][128][129] observed in 3-month olds are similar to those observed in adults. Electrophysiological studies conducted in 1-month-old infants using 2000 Hz AM pure tones indicate some immaturity in envelope following response (EFR). Although sleeping infants and sedated adults show the same effect of modulation rate on EFR, infants’ estimates were generally poorer than adults’.[130][131] This is consistent with behavioral studies conducted with school-age children showing differences in AM detection thresholds compared to adults. Children systematically show worse AM detection thresholds than adults until 10–11 years. However, the shape of the TMTF (the cutoff) is similar to adults’ for younger children of 5 years.[132][133] Sensory versus non-sensory factors for this long maturation are still debated,[134] but the results generally appear to be more dependent on the task or on sound complexity for infants and children than for adults.[135] Regarding the development of speech ENVp processing, vocoder studies suggest that infants as young as 3 months are able to discriminate a change in consonants when the faster ENVp information of the syllables is preserved (< 256 Hz) but less so when only the slowest ENVp is available (< 8 Hz).[136] Older children of 5 years show similar abilities than adults to discriminate consonant changes based on ENVp cues (< 64 Hz).[137]
6.2. Neurophysiological Aspects
The effects of hearing loss and age on neural coding are generally believed to be smaller for slowly varying envelope responses (i.e., ENVn) than for rapidly varying temporal fine structure (i.e., TFSn).[138][139] Enhanced ENVn coding following noise-induced hearing loss has been observed in peripheral auditory responses from single neurons[140] and in central evoked responses from the auditory midbrain.[141] The enhancement in ENVn coding of narrowband sounds occurs across the full range of modulation frequencies encoded by single neurons.[142] For broadband sounds, the range of modulation frequencies encoded in impaired responses is broader than normal (extending to higher frequencies), as expected from reduced frequency selectivity associated with outer-hair-cell dysfunction.[143] The enhancement observed in neural envelope responses is consistent with enhanced auditory perception of modulations following cochlear damage, which is commonly believed to result from loss of cochlear compression that occurs with outer-hair-cell dysfunction due to age or noise overexposure.[144] However, the influence of inner-hair-cell dysfunction (e.g., shallower response growth for mild-moderate damage and steeper growth for severe damage) can confound the effects of outer-hair-cell dysfunction on overall response growth and thus ENVn coding.[140][145] Thus, not surprisingly the relative effects of outer-hair-cell and inner-hair-cell dysfunction have been predicted with modeling to create individual differences in speech intelligibility based on the strength of envelope coding of speech relative to noise.
6.3. Psychoacoustical Aspects
For sinusoidal carriers, which have no intrinsic envelope (ENVp) fluctuations, the TMTF is roughly flat for AM rates from 10 to 120 Hz, but increases (i.e. threshold worsens) for higher AM rates,[44][146] provided that spectral sidebands are not audible. The shape of the TMTF for sinusoidal carriers is similar for young and older people with normal audiometric thresholds, but older people tend to have higher detection thresholds overall, suggesting poorer “detection efficiency” for ENVn cues in older people.[147][148] Provided that the carrier is fully audible, the ability to detect AM is usually not adversely affected by cochlear hearing loss and may sometimes be better than normal, for both noise carriers [149][150] and sinusoidal carriers,[146][151] perhaps because loudness recruitment (an abnormally rapid growth of loudness with increasing sound level) “magnifies” the perceived amount of AM (i.e., ENVn cues). Consistent with this, when the AM is clearly audible, a sound with a fixed AM depth appears to fluctuate more for an impaired ear than for a normal ear. However, the ability to detect changes in AM depth can be impaired by cochlear hearing loss.[151] Speech that is processed with noise vocoder such that mainly envelope information is delivered in multiple spectral channels was also used in investigating envelope processing in hearing impairment. Here, hearing-impaired individuals could not make use of such envelope information as well as normal-hearing individuals, even after audibility factors were taken into account.[152] Additional experiments suggest that age negatively affects the binaural processing of ENVp at least at low audio-frequencies.[153]
6.4. Models of Impaired Temporal Envelope Processing
The perception model of ENV processing[56] that incorporates selective (bandpass) AM filters accounts for many perceptual consequences of cochlear dysfunction including enhanced sensitivity to AM for sinusoidal and noise carriers,[154][155] abnormal forward masking (the rate of recovery from forward masking being generally slower than normal for impaired listeners),[156] stronger interference effects between AM and FM [76] and enhanced temporal integration of AM.[155] The model of Torsten Dau[56] has been extended to account for the discrimination of complex AM patterns by hearing-impaired individuals and the effects of noise-reduction systems.[157] The performance of the hearing-impaired individuals was best captured when the model combined the loss of peripheral amplitude compression resulting from the loss of the active mechanism in the cochlea[154][155][156] with an increase in internal noise in the ENVn domain.[76][154][155] Phenomenological models simulating the response of the peripheral auditory system showed that impaired AM sensitivity in individuals experiencing chronic tinnitus with clinically normal audiograms could be predicted by substantial loss of auditory-nerve fibers with low spontaneous rates and some loss of auditory-nerve fibers with high-spontaneous rates.[158]
7. Effects of Age and Hearing Loss on TFS Processing
7.1. Developmental Aspects
Very few studies have systematically assessed TFS processing in infants and children. Frequency-following response (FFR), thought to reflect phase-locked neural activity, appears to be adult-like in 1-month-old infants when using a pure tone (centered at 500, 1000 or 2000 Hz) modulated at 80 Hz with a 100% of modulation depth.[130]
As for behavioral data, six-month-old infants require larger frequency transitions to detect a FM change in a 1-kHz tone compared to adults.[159] However, 4-month-old infants are able to discriminate two different FM sweeps,[160] and they are more sensitive to FM cues swept from 150 Hz to 550 Hz than at lower frequencies.[161] In school-age children, performance in detecting FM change improves between 6 and 10 years and sensitivity to low modulation rate (2 Hz) is poor until 9 years.[162]
For speech sounds, only one vocoder study has explored the ability of school age children to rely on TFSp cues to detect consonant changes, showing the same abilities for 5-years-olds than adults.[137]
7.2. Neurophysiological Aspects
Psychophysical studies have suggested that degraded TFS processing due to age and hearing loss may underlie some suprathreshold deficits, such as speech perception;[3] however, debate remains about the underlying neural correlates.[138][139] The strength of phase locking to the temporal fine structure of signals (TFSn) in quiet listening conditions remains normal in peripheral single-neuron responses following cochlear hearing loss.[140] Although these data suggest that the fundamental ability of auditory-nerve fibers to follow the rapid fluctuations of sound remains intact following cochlear hearing loss, deficits in phase locking strength do emerge in background noise.[163] This finding, which is consistent with the common observation that listeners with cochlear hearing loss have more difficulty in noisy conditions, results from reduced cochlear frequency selectivity associated with outer-hair-cell dysfunction.[144] Although only limited effects of age and hearing loss have been observed in terms of TFSn coding strength of narrowband sounds, more dramatic deficits have been observed in TFSn coding quality in response to broadband sounds, which are more relevant for everyday listening. A dramatic loss of tonotopicity can occur following noise induced hearing loss, where auditory-nerve fibers that should be responding to mid frequencies (e.g., 2–4 kHz) have dominant TFS responses to lower frequencies (e.g., 700 Hz).[164] Notably, the loss of tonotopicity generally occurs only for TFSn coding but not for ENVn coding, which is consistent with greater perceptual deficits in TFS processing.[3] This tonotopic degradation is likely to have important implications for speech perception, and can account for degraded coding of vowels following noise-induced hearing loss in which most of the cochlea responds to only the first formant, eliminating the normal tonotopic representation of the second and third formants.
7.3. Psychoacoustical Aspects
Several psychophysical studies have shown that older people with normal hearing and people with sensorineural hearing loss often show impaired performance for auditory tasks that are assumed to rely on the ability of the monaural and binaural auditory system to encode and use TFSn cues, such as: discrimination of sound frequency,[70][165][166] discrimination of the fundamental frequency of harmonic sounds,[70][165][166][167] detection of FM at rates below 5 Hz,[85][168][169] melody recognition for sequences of pure tones and complex sounds,[170] lateralization and localization of pure tones and complex tones,[72][153][171] and segregation of concurrent harmonic sounds (such as speech sounds).[73] However, it remains unclear to which extent deficits associated with hearing loss reflect poorer TFSn processing or reduced cochlear frequency selectivity.[170]
7.4. Models of Impaired Processing
The quality of the representation of a sound in the auditory nerve is limited by refractoriness, adaptation, saturation, and reduced synchronization (phase locking) at high frequencies, as well as by the stochastic nature of actions potentials.[172] However, the auditory nerve contains thousands of fibers. Hence, despite these limiting factors, the properties of sounds are reasonably well represented in the population nerve response over a wide range of levels[173] and audio frequencies (see Volley Theory).
The coding of temporal information in the auditory nerve can be disrupted by two main mechanisms: reduced synchrony and loss of synapses and/or auditory nerve fibers.[174] The impact of disrupted temporal coding on human auditory perception has been explored using physiologically inspired signal-processing tools. The reduction in neural synchrony has been simulated by jittering the phases of the multiple frequency components in speech,[175] although this has undesired effects in the spectral domain. The loss of auditory nerve fibers or synapses has been simulated by assuming (i) that each afferent fiber operates as a stochastic sampler of the sound waveform, with greater probability of firing for higher-intensity and sustained sound features than for lower-intensity or transient features, and (ii) that deafferentation can be modeled by reducing the number of samplers.[172] However, this also has undesired effects in the spectral domain. Both jittering and stochastic undersampling degrade the representation of the TFSn more than the representation of the ENVn. Both jittering and stochastic undersampling impair the recognition of speech in noisy backgrounds without degrading recognition in silence, support the argument that TFSn is important for recognizing speech in noise.[176] Both jittering and stochastic undersampling mimic the effects of aging on speech perception.[177]
8. Transmission by Hearing Aids and Cochlear Implants
8.1. Temporal Envelope Transmission
Individuals with cochlear hearing loss usually have a smaller than normal dynamic range between the level of the weakest detectable sound and the level at which sounds become uncomfortably loud.[178][179] To compress the large range of sound levels encountered in everyday life into the small dynamic range of the hearing-impaired person, hearing aids apply amplitude compression, which is also called automatic gain control (AGC). The basic principle of such compression is that the amount of amplification applied to the incoming sound progressively decreases as the input level increases. Usually, the sound is split into several frequency “channels”, and AGC is applied independently in each channel. As a result of compressing the level, AGC reduces the amount of envelope fluctuation in the input signal (ENVp) by an amount that depends on the rate of fluctuation and the speed with which the amplification changes in response to changes in input sound level.[180][181] AGC can also change the shape of the envelope of the signal.[182] Cochlear implants are devices that electrically stimulate the auditory nerve, thereby creating the sensation of sound in a person who would otherwise be profoundly or totally deaf. The electrical dynamic range is very small,[183] so cochlear implants usually incorporate AGC prior to the signal being filtered into multiple frequency channels.[184] The channel signals are then subjected to instantaneous compression to map them into the limited dynamic range for each channel.[185]
Cochlear implants differ than hearing aids in that the entire acoustic hearing is replaced with direct electric stimulation of the auditory nerve, achieved via an electrode array placed inside the cochlea. Hence, here, other factors than device signal processing also strongly contribute to overall hearing, such as etiology, nerve health, electrode configuration and proximity to the nerve, and overall adaptation process to an entirely new mode of hearing.[186][187][188][189] Almost all information in cochlear implants is conveyed by the envelope fluctuations in the different channels. This is sufficient to give reasonable perception of speech in quiet, but not in noisy or reverberant conditions.[106][117][190][191][192][193][194][195][196][197] The processing in cochlear implants is such that the TFSp is discarded in favor of fixed-rate pulse trains amplitude-modulated by the ENVp within each frequency band. Implant users are sensitive to these ENVp modulations, but performance varies across stimulation site, stimulation level, and across individuals.[198][199] The TMTF shows a low-pass filter shape similar to that observed in normal-hearing listeners.[199][200][201] Voice pitch or musical pitch information, conveyed primarily via weak periodicity cues in the ENVp, results in a pitch sensation that is not salient enough to support music perception,[202][203] talker sex identification,[204][205] lexical tones,[206][207] or prosodic cues.[208][209][210] Listeners with cochlear implants are susceptible to interference in the modulation domain[211][212] which likely contributes to difficulties listening in noise.
8.2. Temporal Fine Structure Transmission
Hearing aids usually process sounds by filtering them into multiple frequency channels and applying AGC in each channel. Other signal processing in hearing aids, such as noise reduction, also involves filtering the input into multiple channels.[213] The filtering into channels can affect the TFSp of sounds depending on characteristics such as the phase response and group delay of the filters. However, such effects are usually small. Cochlear implants also filter the input signal into frequency channels. Usually, the ENVp of the signal in each channel is transmitted to the implanted electrodes in the form an electrical pulses of fixed rate that are modulated in amplitude or duration. Information about TFSp is discarded. This is justified by the observation that people with cochlear implants have a very limited ability to process TFSp information, even if it is transmitted to the electrodes,[214] perhaps because of a mismatch between the temporal information and the place in the cochlea to which it is delivered[70] Reducing this mismatch may improve the ability to use TFSp information and hence lead to better pitch perception.[215] Some cochlear implant systems transmit information about TFSp in the channels of the cochlear implants that are tuned to low audio frequencies, and this may improve the pitch perception of low-frequency sounds.[216]
9. Training Effects and Plasticity of Temporal-Envelope Processing
Perceptual learning resulting from training has been reported for various auditory AM detection or discrimination tasks,[217][218][219] suggesting that the responses of central auditory neurons to ENVp cues are plastic and that practice may modify the circuitry of ENVn processing.[219][220]
The plasticity of ENVn processing has been demonstrated in several ways. For instance, the ability of auditory-cortex neurons to discriminate voice-onset time cues for phonemes is degraded following moderate hearing loss (20-40 dB HL) induced by acoustic trauma.[221] Interestingly, developmental hearing loss reduces cortical responses to slow, but not fast (100 Hz) AM stimuli, in parallel with behavioral performance.[222] As a matter of fact, a transient hearing loss (15 days) occurring during the "critical period" is sufficient to elevate AM thresholds in adult gerbils.[223] Even non-traumatic noise exposure reduces the phase-locking ability of cortical neurons as well as the animals' behavioral capacity to discriminate between different AM sounds.[224] Behavioral training or pairing protocols involving neuromodulators also alter the ability of cortical neurons to phase lock to AM sounds.[225][226] In humans, hearing loss may result in an unbalanced representation of speech cues: ENVn cues are enhanced at the cost of TFSn cues (see: Effects of age and hearing loss on temporal envelope processing). Auditory training may reduce the representation of speech ENVn cues for elderly listeners with hearing loss, who may then reach levels comparable to those observed for normal-hearing elderly listeners.[227] Last, intensive musical training induces both behavioral effects such as higher sensitivity to pitch variations (for Mandarin linguistic pitch) and a better synchronization of brainstem responses to the f0-contour of lexical tones for musicians compared with non-musicians.[228]
10. Clinical Evaluation of TFS Sensitivity
Fast and easy to administer psychophysical tests have been developed to assist clinicians in the screening of TFS-processing abilities and diagnosis of suprathreshold temporal auditory processing deficits associated with cochlear damage and ageing. These tests may also be useful for audiologists and hearing-aid manufacturers to explain and/or predict the outcome of hearing-aid fitting in terms of perceived quality, speech intelligibility or spatial hearing.[229][230] These tests may eventually be used to recommend the most appropriate compression speed in hearing aids [231] or the use of directional microphones. The need for such tests is corroborated by strong correlations between slow-FM or spectro-temporal modulation detection thresholds and aided speech intelligibility in competing backgrounds for hearing-impaired persons.[84][232] Clinical tests can be divided into two groups: those assessing monaural TFS processing capacities (TFS1 test) and those assessing binaural capacities (binaural pitch, TFS-LF, TFS-AF).
TFS1: this test assesses the ability to discriminate between an harmonic complex tone and its frequency-transposed (and thus, inharmonic) version.[147][233][234][235] Binaural pitch: these tests evaluate the ability to detect and discriminate binaural pitch, and melody recognition using different types of binaural pitch.[170][236] TFS-LF: this test assesses the ability to discriminate low-frequency pure tones that are identical at the two ears from the same tones differing in interaural phase.[237][238] TFS AF: this test assesses the highest audio frequency of a pure tone up to which a change in interaural phase can be discriminated.[239]
11. Objective Measures Using Envelope and TFS Cues
Signal distortion, additive noise, reverberation, and audio processing strategies such as noise suppression and dynamic-range compression can all impact speech intelligibility and speech and music quality.[240][241][242][243][244] These changes in the perception of the signal can often be predicted by measuring the associated changes in the signal envelope and/or temporal fine structure (TFS). Objective measures of the signal changes, when combined with procedures that associate the signal changes with differences in auditory perception, give rise to auditory performance metrics for predicting speech intelligibility and speech quality.
Changes in the TFS can be estimated by passing the signals through a filterbank and computing the coherence [245] between the system input and output in each band. Intelligibility predicted from the coherence is accurate for some forms of additive noise and nonlinear distortion,[240][244] but works poorly for ideal binary mask (IBM) noise suppression.[242] Speech and music quality for signals subjected to noise and clipping distortion have also been modeled using the coherence [246] or using the coherence averaged across short signal segments.[247]
Changes in the signal envelope can be measured using several different procedures. The presence of noise or reverberation will reduce the modulation depth of a signal, and multiband measurement of the envelope modulation depth of the system output is used in the speech transmission index (STI) to estimate intelligibility.[248] While accurate for noise and reverberation applications, the STI works poorly for nonlinear processing such as dynamic-range compression.[249] An extension to the STI estimates the change in modulation by cross-correlating the envelopes of the speech input and output signals.[250][251] A related procedure, also using envelope cross-correlations, is the short-time objective intelligibility (STOI) measure,[242] which works well for its intended application in evaluating noise suppression, but which is less accurate for nonlinear distortion.[252] Envelope-based intelligibility metrics have also been derived using modulation filterbanks [60] and using envelope time-frequency modulation patterns.[253] Envelope cross-correlation is also used for estimating speech and music quality.[254][255]
Envelope and TFS measurements can also be combined to form intelligibility and quality metrics. A family of metrics for speech intelligibility,[252] speech quality,[256] and music quality [257] has been derived using a shared model of the auditory periphery [258] that can represent hearing loss. Using a model of the impaired periphery leads to more accurate predictions for hearing-impaired listeners than using a normal-hearing model, and the combined envelope/TFS metric is generally more accurate than a metric that uses envelope modulation alone.[252][256]
References
- Hilbert, David (1912). Grundzüge einer allgemeinen theorie der linearen integralgleichungen. University of California Libraries. Leipzig, B. G. Teubner. https://archive.org/details/grundzugeallg00hilbrich.
- "Response to noise of auditory nerve fibers in the squirrel monkey" (in English). Journal of Neurophysiology 36 (4): 569–87. July 1973. doi:10.1152/jn.1973.36.4.569. PMID 4197339. https://www.scholars.northwestern.edu/en/publications/response-to-noise-of-auditory-nerve-fibers-in-the-squirrel-monkey.
- Moore, Brian C. J. (2014-05-04). Auditory Processing of Temporal Fine Structure: Effects of Age and Hearing Loss. New Jersey: World Scientific Publishing Company. ISBN 9789814579650.
- "Correlation index: a new metric to quantify temporal coding". Hearing Research 216-217: 19–30. June 2006. doi:10.1016/j.heares.2006.03.010. PMID 16644160. https://dx.doi.org/10.1016%2Fj.heares.2006.03.010
- "Quantifying envelope and fine-structure coding in auditory nerve responses to chimaeric speech". Journal of the Association for Research in Otolaryngology 10 (3): 407–23. September 2009. doi:10.1007/s10162-009-0169-8. PMID 19365691. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3084379
- Søndergaard, Peter L.; Decorsière, Rémi; Dau, Torsten (2011-12-15). "On the relationship between multi-channel envelope and temporal fine structure". Proceedings of the International Symposium on Auditory and Audiological Research 3: 363–370. https://proceedings.isaar.eu/index.php/isaarproc/article/view/2011-42.
- "On the balance of envelope and temporal fine structure in the encoding of speech in the early auditory system". The Journal of the Acoustical Society of America 133 (5): 2818–33. May 2013. doi:10.1121/1.4795783. PMID 23654388. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3663870
- "Neural processing of amplitude-modulated sounds". Physiological Reviews 84 (2): 541–77. April 2004. doi:10.1152/physrev.00029.2003. PMID 15044682. https://dx.doi.org/10.1152%2Fphysrev.00029.2003
- "Subcortical neural coding mechanisms for auditory temporal processing". Hearing Research 158 (1–2): 1–27. August 2001. PMID 11506933. http://www.ncbi.nlm.nih.gov/pubmed/11506933
- "Physiological correlates of comodulation masking release in the mammalian ventral cochlear nucleus". The Journal of Neuroscience 21 (16): 6377–86. August 2001. PMID 11487661. http://www.ncbi.nlm.nih.gov/pubmed/11487661
- "Detection in noise by spectro-temporal pattern analysis". The Journal of the Acoustical Society of America 76 (1): 50–6. July 1984. PMID 6747111. http://www.ncbi.nlm.nih.gov/pubmed/6747111
- "Temporal modulation transfer functions for AM and FM stimuli in cat auditory cortex. Effects of carrier type, modulating waveform and intensity". Hearing Research 74 (1–2): 51–66. April 1994. doi:10.1016/0378-5955(94)90175-9. PMID 8040099. https://www.sciencedirect.com/science/article/pii/0378595594901759.
- "Temporal modulation transfer functions for AM and FM stimuli in cat auditory cortex. Effects of carrier type, modulating waveform and intensity". Hearing Research 74 (1–2): 51–66. April 1994. doi:10.1007/BF00228100. PMID 8040099. https://dx.doi.org/10.1007%2FBF00228100
- "Neural representations of sinusoidal amplitude and frequency modulations in the primary auditory cortex of awake primates". Journal of Neurophysiology 87 (5): 2237–61. May 2002. doi:10.1152/jn.2002.87.5.2237. PMID 11976364. https://dx.doi.org/10.1152%2Fjn.2002.87.5.2237
- "Representation of amplitude modulation in the auditory cortex of the cat. II. Comparison between cortical fields". Hearing Research 32 (1): 49–63. January 1988. doi:10.1016/0378-5955(88)90146-3. PMID 3350774. https://www.sciencedirect.com/science/article/pii/0378595588901463.
- "Temporal and rate representations of time-varying signals in the auditory cortex of awake primates" (in En). Nature Neuroscience 4 (11): 1131–8. November 2001. doi:10.1038/nn737. PMID 11593234. http://www.nature.com/articles/nn737.
- "Rate and synchronization measures of periodicity coding in cat primary auditory cortex". Hearing Research 56 (1–2): 153–67. November 1991. doi:10.1016/0378-5955(91)90165-6. PMID 1769910. https://dx.doi.org/10.1016%2F0378-5955%2891%2990165-6
- "The topography of frequency and time representation in primate auditory cortices". eLife 4. January 2015. doi:10.7554/eLife.03256. PMID 25590651. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4398946
- Depireux, Didier A.; Elhilali, Mounya, eds (2014-01-15). Handbook of Modern Techniques in Auditory Cortex (first ed.). Nova Science Pub Inc. ISBN 9781628088946.
- "Analysis of dynamic spectra in ferret primary auditory cortex. I. Characteristics of single-unit responses to moving ripple spectra". Journal of Neurophysiology 76 (5): 3503–23. November 1996. doi:10.1152/jn.1996.76.5.3503. PMID 8930289. http://drum.lib.umd.edu/bitstream/1903/5688/1/TR_95-108.pdf.
- "Selective cortical representation of attended speaker in multi-talker speech perception". Nature 485 (7397): 233–6. May 2012. doi:10.1038/nature11020. PMID 22522927. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3870007
- "Human auditory steady-state responses to amplitude-modulated tones: phase and latency measurements". Hearing Research 141 (1–2): 57–79. March 2000. doi:10.1016/S0378-5955(99)00209-9. PMID 10713496. https://dx.doi.org/10.1016%2FS0378-5955%2899%2900209-9
- "Emergent selectivity for task-relevant stimuli in higher-order auditory cortex" (in English). Neuron 82 (2): 486–99. April 2014. doi:10.1016/j.neuron.2014.02.029. PMID 24742467. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4048815
- "Representation of amplitude modulation in the auditory cortex of the cat. I. The anterior auditory field (AAF)". Hearing Research 21 (3): 227–41. 1986. doi:10.1016/0378-5955(86)90221-2. PMID 3013823. https://dx.doi.org/10.1016%2F0378-5955%2886%2990221-2
- "Representation of the temporal envelope of sounds in the human brain". Journal of Neurophysiology 84 (3): 1588–98. September 2000. doi:10.1152/jn.2000.84.3.1588. PMID 10980029. https://dx.doi.org/10.1152%2Fjn.2000.84.3.1588
- "Temporal envelope processing in the human left and right auditory cortices". Cerebral Cortex 14 (7): 731–40. July 2004. doi:10.1093/cercor/bhh033. PMID 15054052. https://dx.doi.org/10.1093%2Fcercor%2Fbhh033
- "Spatial representations of temporal and spectral sound cues in human auditory cortex". Cortex; A Journal Devoted to the Study of the Nervous System and Behavior 49 (10): 2822–33. November 2013. doi:10.1016/j.cortex.2013.04.003. PMID 23706955. https://dx.doi.org/10.1016%2Fj.cortex.2013.04.003
- "Spectro-temporal modulation transfer function of single voxels in the human auditory cortex measured with high-resolution fMRI". Proceedings of the National Academy of Sciences of the United States of America 106 (34): 14611–6. August 2009. doi:10.1073/pnas.0907682106. PMID 19667199. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2732853
- "Frontal processing and auditory perception". NeuroReport 11 (5): 919–22. April 2000. PMID 10790855. http://www.ncbi.nlm.nih.gov/pubmed/10790855
- "Human Superior Temporal Gyrus Organization of Spectrotemporal Modulation Tuning Derived from Speech Stimuli". The Journal of Neuroscience 36 (6): 2014–26. February 2016. doi:10.1523/JNEUROSCI.1779-15.2016. PMID 26865624. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4748082
- "Dynamics of precise spike timing in primary auditory cortex". The Journal of Neuroscience 24 (5): 1159–72. February 2004. doi:10.1523/JNEUROSCI.3825-03.2004. PMID 14762134. https://dx.doi.org/10.1523%2FJNEUROSCI.3825-03.2004
- Boer, E. de (1985). "Auditory Time Constants: A Paradox?". Time Resolution in Auditory Systems. Proceedings in Life Sciences. Springer, Berlin, Heidelberg. pp. 141–158. doi:10.1007/978-3-642-70622-6_9. ISBN 9783642706240. https://dx.doi.org/10.1007%2F978-3-642-70622-6_9
- "Temporal precision of spike trains in extrastriate cortex of the behaving macaque monkey". Neural Computation 8 (6): 1185–202. August 1996. PMID 8768391. http://www.ncbi.nlm.nih.gov/pubmed/8768391
- "Temporal symmetry in primary auditory cortex: implications for cortical connectivity". Neural Computation 19 (3): 583–638. March 2007. doi:10.1162/neco.2007.19.3.583. PMID 17298227. https://dx.doi.org/10.1162%2Fneco.2007.19.3.583
- "Spectral-temporal receptive fields of nonlinear auditory neurons obtained using natural sounds". The Journal of Neuroscience 20 (6): 2315–31. March 2000. PMID 10704507. http://www.jneurosci.org/content/20/6/2315.
- "Rapid synaptic depression explains nonlinear modulation of spectro-temporal tuning in primary auditory cortex by natural stimuli". The Journal of Neuroscience 29 (11): 3374–86. March 2009. doi:10.1523/JNEUROSCI.5249-08.2009. PMID 19295144. PMC 2774136. http://www.jneurosci.org/content/29/11/3374.
- "Auditory responsive cortex in the squirrel monkey: neural responses to amplitude-modulated sounds". Experimental Brain Research 108 (2): 273–84. March 1996. PMID 8815035. http://www.ncbi.nlm.nih.gov/pubmed/8815035
- Fast, Hugo. Psychoacoustics - Facts and Models. Springer. https://www.springer.com/la/book/9783540231592.
- Burns, E. M.; Viemeister, Neal F. (1981). "Played-again SAM: Further observations on the pitch of amplitude-modulated noise". Journal of the Acoustical Society of America 70. ISSN 0001-4966. https://experts.umn.edu/en/publications/played-again-sam-further-observations-on-the-pitch-of-amplitude-m.
- "Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis". Neuron 71 (5): 926–40. September 2011. doi:10.1016/j.neuron.2011.06.032. PMID 21903084. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4143345
- "Cascaded Amplitude Modulations in Sound Texture Perception". Frontiers in Neuroscience 11: 485. 2017-09-11. doi:10.3389/fnins.2017.00485. PMID 28955191. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5601004
- "Temporal modulation transfer functions based upon modulation thresholds". The Journal of the Acoustical Society of America 66 (5): 1364–80. November 1979. PMID 500975. http://www.ncbi.nlm.nih.gov/pubmed/500975
- "Temporal integration in amplitude modulation detection". The Journal of the Acoustical Society of America 88 (2): 796–805. August 1990. PMID 2212305. http://www.ncbi.nlm.nih.gov/pubmed/2212305
- "The influence of carrier level and frequency on modulation and beat-detection thresholds for sinusoidal carriers". The Journal of the Acoustical Society of America 108 (2): 723–34. August 2000. PMID 10955639. http://www.ncbi.nlm.nih.gov/pubmed/10955639
- "Modulation masking: effects of modulation frequency, depth, and phase". The Journal of the Acoustical Society of America 85 (6): 2575–80. June 1989. PMID 2745880. http://www.ncbi.nlm.nih.gov/pubmed/2745880
- "Frequency selectivity in amplitude-modulation detection". The Journal of the Acoustical Society of America 85 (4): 1676–80. April 1989. PMID 2708683. http://www.ncbi.nlm.nih.gov/pubmed/2708683
- "Across-critical-band processing of amplitude-modulated tones". The Journal of the Acoustical Society of America 85 (2): 848–57. February 1989. PMID 2925999. http://www.ncbi.nlm.nih.gov/pubmed/2925999
- "On the existence in human auditory pathways of channels selectively tuned to the modulation present in frequency-modulated tones". The Journal of Physiology 225 (3): 657–77. September 1972. PMID 5076392. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1331136
- "Time course of adaptation and recovery of channels selectively sensitive to frequency and amplitude modulation". The Journal of the Acoustical Society of America 74 (3): 765–75. September 1983. PMID 6630734. http://www.ncbi.nlm.nih.gov/pubmed/6630734
- "Suprathreshold effects of adaptation produced by amplitude modulation". The Journal of the Acoustical Society of America 114 (2): 991–7. August 2003. PMID 12942978. http://www.ncbi.nlm.nih.gov/pubmed/12942978
- "Second-order modulation detection thresholds for pure-tone and narrow-band noise carriers". The Journal of the Acoustical Society of America 110 (5 Pt 1): 2470–8. November 2001. PMID 11757936. http://www.ncbi.nlm.nih.gov/pubmed/11757936
- "Spectro-temporal processing in the envelope-frequency domain". The Journal of the Acoustical Society of America 112 (6): 2921–31. December 2002. PMID 12509013. http://www.ncbi.nlm.nih.gov/pubmed/12509013
- "Modulation masking produced by second-order modulators". The Journal of the Acoustical Society of America 117 (4 Pt 1): 2158–68. April 2005. PMID 15898657. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2708918
- "The influence of different segments of the ongoing envelope on sensitivity to interaural time delays". The Journal of the Acoustical Society of America 129 (6): 3856–72. June 2011. doi:10.1121/1.3585847. PMID 21682409. https://dx.doi.org/10.1121%2F1.3585847
- "Cues for discrimination of envelopes". The Journal of the Acoustical Society of America 99 (6): 3638–46. June 1996. PMID 8655796. http://www.ncbi.nlm.nih.gov/pubmed/8655796
- "Modeling auditory processing of amplitude modulation. I. Detection and masking with narrow-band carriers". The Journal of the Acoustical Society of America 102 (5 Pt 1): 2892–905. November 1997. PMID 9373976. http://www.ncbi.nlm.nih.gov/pubmed/9373976
- "Modeling comodulation masking release using an equalization-cancellation mechanism". The Journal of the Acoustical Society of America 121 (4): 2111–26. April 2007. PMID 17471726. http://www.ncbi.nlm.nih.gov/pubmed/17471726
- "Characterizing frequency selectivity for envelope fluctuations". The Journal of the Acoustical Society of America 108 (3 Pt 1): 1181–96. September 2000. PMID 11008819. http://www.ncbi.nlm.nih.gov/pubmed/11008819
- "Discrimination of modulation depth of sinusoidal amplitude modulation (SAM) noise". The Journal of the Acoustical Society of America 88 (3): 1367–73. September 1990. PMID 2229672. http://www.ncbi.nlm.nih.gov/pubmed/2229672
- "A multi-resolution envelope-power based model for speech intelligibility". The Journal of the Acoustical Society of America 134 (1): 436–46. July 2013. doi:10.1121/1.4807563. PMID 23862819. http://orbit.dtu.dk/en/publications/a-multiresolution-envelopepower-based-model-for-speech-intelligibility(7a54661a-7bdd-4f21-962e-208f2edfd0d4).html.
- "Envelope and intensity based prediction of psychoacoustic masking and speech intelligibility". The Journal of the Acoustical Society of America 140 (2): 1023–1038. August 2016. doi:10.1121/1.4960574. PMID 27586734. https://dx.doi.org/10.1121%2F1.4960574
- "Cues for masked amplitude-modulation detection". The Journal of the Acoustical Society of America 120 (2): 978–90. August 2006. PMID 16938985. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2572864
- "Assessment of the limits of neural phase-locking using mass potentials". The Journal of Neuroscience 35 (5): 2255–68. February 2015. doi:10.1523/JNEUROSCI.2979-14.2015. PMID 25653380. https://dx.doi.org/10.1523%2FJNEUROSCI.2979-14.2015
- "Phase-locking in the cochlear nerve of the guinea-pig and its relation to the receptor potential of inner hair-cells". Hearing Research 24 (1): 1–15. 1986. PMID 3759671. http://www.ncbi.nlm.nih.gov/pubmed/3759671
- "A comparison of synchronization filters in different auditory receptor organs" (in en). Hearing Research 33 (2): 175–9. May 1988. doi:10.1016/0378-5955(88)90030-5. PMID 3397327. https://dx.doi.org/10.1016%2F0378-5955%2888%2990030-5
- "Dual Coding of Frequency Modulation in the Ventral Cochlear Nucleus". The Journal of Neuroscience 38 (17): 4123–4137. April 2018. doi:10.1523/JNEUROSCI.2107-17.2018. PMID 29599389. https://dx.doi.org/10.1523%2FJNEUROSCI.2107-17.2018
- "Frequency difference limens for short-duration tones". The Journal of the Acoustical Society of America 54 (3): 610–9. September 1973. PMID 4754385. http://www.ncbi.nlm.nih.gov/pubmed/4754385
- "The role of temporal fine structure processing in pitch perception, masking, and speech perception for normal-hearing and hearing-impaired people". Journal of the Association for Research in Otolaryngology 9 (4): 399–406. December 2008. doi:10.1007/s10162-008-0143-x. PMID 18855069. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2580810
- Moore, Brian (2013-04-05). An Introduction to the Psychology of Hearing: Sixth Edition (6th ed.). Leiden: BRILL. ISBN 9789004252424.
- Plack, Christopher J. (2005). Pitch - Neural Coding and Perception. Springer. https://www.springer.com/la/book/9780387234724.
- "Detection of frequency modulation at low modulation rates: evidence for a mechanism based on phase locking". The Journal of the Acoustical Society of America 100 (4 Pt 1): 2320–31. October 1996. PMID 8865639. http://www.ncbi.nlm.nih.gov/pubmed/8865639
- "Consequences of cochlear damage for the detection of interaural phase differences". The Journal of the Acoustical Society of America 118 (4): 2519–26. October 2005. PMID 16266172. http://www.ncbi.nlm.nih.gov/pubmed/16266172
- "Effects of moderate cochlear hearing loss on the ability to benefit from temporal fine structure information in speech". The Journal of the Acoustical Society of America 123 (2): 1140–53. February 2008. doi:10.1121/1.2824018. PMID 18247914. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2688774
- "Correct tonotopic representation is necessary for complex pitch perception". Proceedings of the National Academy of Sciences of the United States of America 101 (5): 1421–5. February 2004. doi:10.1073/pnas.0306958101. PMID 14718671. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=337068
- "Pitch perception beyond the traditional existence region of pitch". Proceedings of the National Academy of Sciences of the United States of America 108 (18): 7629–34. May 2011. doi:10.1073/pnas.1015291108. PMID 21502495. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3088642
- "Interactions between amplitude modulation and frequency modulation processing: Effects of age and hearing loss". The Journal of the Acoustical Society of America 140 (1): 121–131. July 2016. doi:10.1121/1.4955078. PMID 27475138. https://dx.doi.org/10.1121%2F1.4955078
- "Detection thresholds for sinusoidal frequency modulation". The Journal of the Acoustical Society of America 85 (3): 1295–301. March 1989. PMID 2708671. http://www.ncbi.nlm.nih.gov/pubmed/2708671
- "Mechanisms underlying the detection of frequency modulation". The Journal of the Acoustical Society of America 128 (6): 3642–8. December 2010. doi:10.1121/1.3506350. PMID 21218896. https://dx.doi.org/10.1121%2F1.3506350
- Zwicker, E (1956-01-01). "Die elementaren Grundlagen zur Bestimmung der Informationskapazität des Gehörs". Acta Acustica United with Acustica 6 (4): 365–381. http://www.ingentaconnect.com/contentone/dav/aaua/1956/00000006/00000004/art00008.
- Maiwald, D (1967). "Ein Funktionsschema des Gehors zur Beschreibung der Erkennbarkeit kleiner Frequenz und Amplitudenanderungen". Acustica 18: 81–92. https://ci.nii.ac.jp/naid/10006767154/.
- "A common neural code for frequency- and amplitude-modulated sounds". Nature 374 (6522): 537–9. April 1995. doi:10.1038/374537a0. PMID 7700378. https://dx.doi.org/10.1038%2F374537a0
- "Normal hearing is not enough to guarantee robust encoding of suprathreshold features important in everyday communication". Proceedings of the National Academy of Sciences of the United States of America 108 (37): 15516–21. September 2011. doi:10.1073/pnas.1108912108. PMID 21844339. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3174666
- "The Influence of Cochlear Mechanical Dysfunction, Temporal Processing Deficits, and Age on the Intelligibility of Audible Speech in Noise for Hearing-Impaired Listeners". Trends in Hearing 20: 233121651664105. September 2016. doi:10.1177/2331216516641055. PMID 27604779. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5017567
- "Predictors of Hearing-Aid Outcomes". Trends in Hearing 21: 2331216517730526. January 2017. doi:10.1177/2331216517730526. PMID 28929903. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5613846
- "Temporal fine-structure cues to speech and pure tone modulation in observers with sensorineural hearing loss". Ear and Hearing 25 (3): 242–50. June 2004. PMID 15179115. http://www.ncbi.nlm.nih.gov/pubmed/15179115
- "Relations between frequency selectivity, temporal fine-structure processing, and speech reception in impaired hearing". The Journal of the Acoustical Society of America 125 (5): 3328–45. May 2009. doi:10.1121/1.3097469. PMID 19425674. http://orbit.dtu.dk/files/4294492/Strelcyk.pdf.
- "A two-path model of auditory modulation detection using temporal fine structure and envelope cues". The European Journal of Neuroscience. January 2018. doi:10.1111/ejn.13846. PMID 29368797. https://dx.doi.org/10.1111%2Fejn.13846
- "A phenomenological model of the synapse between the inner hair cell and auditory nerve: long-term adaptation with power-law dynamics". The Journal of the Acoustical Society of America 126 (5): 2390–412. November 2009. doi:10.1121/1.3238250. PMID 19894822. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2787068
- "Updated parameters and expanded simulation options for a model of the auditory periphery". The Journal of the Acoustical Society of America 135 (1): 283–6. January 2014. doi:10.1121/1.4837815. PMID 24437768. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3985897
- "Predictions of Speech Chimaera Intelligibility Using Auditory Nerve Mean-Rate and Spike-Timing Neural Cues". Journal of the Association for Research in Otolaryngology 18 (5): 687–710. October 2017. doi:10.1007/s10162-017-0627-7. PMID 28748487. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5612921
- "Optimal combination of neural temporal envelope and fine structure cues to explain speech identification in background noise". The Journal of Neuroscience 34 (36): 12145–54. September 2014. doi:10.1523/JNEUROSCI.1025-14.2014. PMID 25186758. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4152611
- "Speech perception problems of the hearing impaired reflect inability to use temporal fine structure". Proceedings of the National Academy of Sciences of the United States of America 103 (49): 18866–9. December 2006. doi:10.1073/pnas.0607364103. PMID 17116863. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1693753
- "The effects of age and cochlear hearing loss on temporal fine structure sensitivity, frequency selectivity, and speech reception in noise". The Journal of the Acoustical Society of America 130 (1): 334–49. July 2011. doi:10.1121/1.3585848. PMID 21786903. https://dx.doi.org/10.1121%2F1.3585848
- "Evaluating auditory performance limits: i. one-parameter discrimination using a computational model for the auditory nerve". Neural Computation 13 (10): 2273–316. October 2001. doi:10.1162/089976601750541804. PMID 11570999. https://dx.doi.org/10.1162%2F089976601750541804
- "Evaluating auditory performance limits: II. One-parameter discrimination with random-level variation". Neural Computation 13 (10): 2317–38. October 2001. doi:10.1162/089976601750541813. PMID 11571000. https://dx.doi.org/10.1162%2F089976601750541813
- Carney, Laurel; G. Heinzy, Michael; E. Evilsizer, Mary; H. Gilkeyz, Robert; Colburn, H. Steven (2002-05-01). Auditory Phase Opponency: A Temporal Model for Masked Detection at Low Frequencies. 88. https://www.researchgate.net/publication/233562295.
- "A composite auditory model for processing speech sounds". The Journal of the Acoustical Society of America 82 (6): 2001–12. December 1987. PMID 3429735. http://www.ncbi.nlm.nih.gov/pubmed/3429735
- "Spatial cross-correlation. A proposed mechanism for acoustic pitch perception". Biological Cybernetics 47 (3): 149–63. 1983. PMID 6615914. https://www.ncbi.nlm.nih.gov/pubmed/?term=Spatial+cross+correlation:+A+proposed+mechanism+for+acoustic+pitch+perception.
- "The case of the missing pitch templates: how harmonic templates emerge in the early auditory system". The Journal of the Acoustical Society of America 107 (5 Pt 1): 2631–44. May 2000. PMID 10830385. http://www.ncbi.nlm.nih.gov/pubmed/10830385
- "Speech processing in the auditory system. II: Lateral inhibition and the central processing of speech evoked activity in the auditory nerve". The Journal of the Acoustical Society of America 78 (5): 1622–32. November 1985. PMID 3840813. https://www.ncbi.nlm.nih.gov/pubmed/?term=Speech+processing+in+the+auditory+system+II:+Lateral+inhibition+and+the+central+processing+of+speech+evoked+activity+in+the+auditory+nerve.
- "A cross-linguistic study of speech modulation spectra". The Journal of the Acoustical Society of America 142 (4): 1976–1989. October 2017. doi:10.1121/1.5006179. PMID 29092595. https://dx.doi.org/10.1121%2F1.5006179
- "Temporal information in speech: acoustic, auditory and linguistic aspects". Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences 336 (1278): 367–73. June 1992. doi:10.1098/rstb.1992.0070. PMID 1354376. https://dx.doi.org/10.1098%2Frstb.1992.0070
- Plomp, Reinier (1983). "Perception of speech as a modulated signal". Proceedings of the 10th International Congress of Phonetic Sciences, Utrecht: 19–40.
- "Speech waveform envelope cues for consonant recognition". The Journal of the Acoustical Society of America 82 (4): 1152–61. October 1987. PMID 3680774. http://www.ncbi.nlm.nih.gov/pubmed/3680774
- "On the upper cutoff frequency of the auditory critical-band envelope detectors in the context of speech perception". The Journal of the Acoustical Society of America 110 (3 Pt 1): 1628–40. September 2001. PMID 11572372. http://www.ncbi.nlm.nih.gov/pubmed/11572372
- "Speech recognition with primarily temporal cues". Science 270 (5234): 303–4. October 1995. PMID 7569981. http://www.ncbi.nlm.nih.gov/pubmed/7569981
- "Chimaeric sounds reveal dichotomies in auditory perception". Nature 416 (6876): 87–90. March 2002. doi:10.1038/416087a. PMID 11882898. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2268248
- "Effect of temporal envelope smearing on speech reception". The Journal of the Acoustical Society of America 95 (2): 1053–64. February 1994. PMID 8132899. http://www.ncbi.nlm.nih.gov/pubmed/8132899
- "Modulation spectra of natural sounds and ethological theories of auditory processing". The Journal of the Acoustical Society of America 114 (6 Pt 1): 3394–411. December 2003. PMID 14714819. http://www.ncbi.nlm.nih.gov/pubmed/14714819
- "Isolating the dynamic attributes of musical timbre". The Journal of the Acoustical Society of America 94 (5): 2595–603. November 1993. PMID 8270737. http://www.ncbi.nlm.nih.gov/pubmed/8270737
- Cheveigné, Alain de (2005). "Pitch Perception Models" (in en). Pitch. Springer Handbook of Auditory Research. 24. Springer, New York, NY. pp. 169–233. doi:10.1007/0-387-28958-5_6. ISBN 9780387234724. https://dx.doi.org/10.1007%2F0-387-28958-5_6
- "Effects of level and frequency on the audibility of partials in inharmonic complex tones". The Journal of the Acoustical Society of America 120 (2): 934–44. August 2006. PMID 16938981. http://www.ncbi.nlm.nih.gov/pubmed/16938981
- "Pitch, consonance, and harmony". The Journal of the Acoustical Society of America 55 (5): 1061–9. May 1974. PMID 4833699. http://www.ncbi.nlm.nih.gov/pubmed/4833699
- "The role of temporal fine structure information for the low pitch of high-frequency complex tones". The Journal of the Acoustical Society of America 129 (1): 282–92. January 2011. doi:10.1121/1.3518718. PMID 21303009. https://dx.doi.org/10.1121%2F1.3518718
- "On the possibility of a place code for the low pitch of high-frequency complex tones". The Journal of the Acoustical Society of America 132 (6): 3883–95. December 2012. doi:10.1121/1.4764897. PMID 23231119. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3528728
- "Accuracy of cochlear implant recipients on pitch perception, melody recognition, and speech reception in noise". Ear and Hearing 28 (3): 412–23. June 2007. doi:10.1097/AUD.0b013e3180479318. PMID 17485990. https://dx.doi.org/10.1097%2FAUD.0b013e3180479318
- "Speech recognition with amplitude and frequency modulations". Proceedings of the National Academy of Sciences of the United States of America 102 (7): 2293–8. February 2005. doi:10.1073/pnas.0406460102. PMID 15677723. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=546014
- "Role and relative contribution of temporal envelope and fine structure cues in sentence recognition by normal-hearing listeners". The Journal of the Acoustical Society of America 134 (3): 2205–12. September 2013. doi:10.1121/1.4816413. PMID 23967950. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3765279
- "Intelligibility of whispered speech in stationary and modulated noise maskers". The Journal of the Acoustical Society of America 132 (4): 2514–23. October 2012. doi:10.1121/1.4747614. PMID 23039445. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3477190
- "Properties of auditory stream formation". Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences 367 (1591): 919–31. April 2012. doi:10.1098/rstb.2011.0355. PMID 22371614. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3282308
- "Effects of differences in the pattern of amplitude envelopes across harmonics on auditory stream segregation". Hearing Research 193 (1–2): 95–104. July 2004. doi:10.1016/j.heares.2004.03.009. PMID 15219324. https://dx.doi.org/10.1016%2Fj.heares.2004.03.009
- "Sequential stream segregation in the absence of spectral cues". The Journal of the Acoustical Society of America 105 (1): 339–46. January 1999. PMID 9921660. http://www.ncbi.nlm.nih.gov/pubmed/9921660
- "Influence of peripheral resolvability on the perceptual segregation of harmonic complex tones differing in fundamental frequency". The Journal of the Acoustical Society of America 108 (1): 263–71. July 2000. PMID 10923890. http://www.ncbi.nlm.nih.gov/pubmed/10923890
- "Auditory stream segregation on the basis of amplitude-modulation rate". The Journal of the Acoustical Society of America 111 (3): 1340–8. March 2002. PMID 11931311. http://www.ncbi.nlm.nih.gov/pubmed/11931311
- "Comparison of perceptual properties of auditory streaming between spectral and amplitude modulation domains". Hearing Research 350: 244–250. July 2017. doi:10.1016/j.heares.2017.03.006. PMID 28323019. https://dx.doi.org/10.1016%2Fj.heares.2017.03.006
- "Discrimination and streaming of speech sounds based on differences in interaural and spectral cues". The Journal of the Acoustical Society of America 142 (3): 1674–1685. September 2017. doi:10.1121/1.5003809. PMID 28964066. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5617732
- Levi, E. C. & Werner, L. A. Amplitude modulation detection in infancy: Update on 3-month-olds. Assoc. Res. Otolaryngol. 19, 142 (1996).
- "The development of auditory behavior (or what the anatomists and physiologists have to explain)". Ear and Hearing 17 (5): 438–46. October 1996. PMID 8909892. http://www.ncbi.nlm.nih.gov/pubmed/8909892
- "Forward masking among infant and adult listeners". The Journal of the Acoustical Society of America 105 (4): 2445–53. April 1999. PMID 10212425. http://www.ncbi.nlm.nih.gov/pubmed/10212425
- "Coherence analysis of envelope-following responses (EFRs) and frequency-following responses (FFRs) in infants and adults". Hearing Research 89 (1–2): 21–7. September 1995. PMID 8600128. http://www.ncbi.nlm.nih.gov/pubmed/8600128
- "Amplitude-modulation following response (AMFR): effects of modulation rate, carrier frequency, age, and state". Hearing Research 68 (1): 42–52. June 1993. PMID 8376214. http://www.ncbi.nlm.nih.gov/pubmed/8376214
- "Development of temporal resolution in children as measured by the temporal modulation transfer function". The Journal of the Acoustical Society of America 96 (1): 150–4. July 1994. PMID 7598757. http://www.ncbi.nlm.nih.gov/pubmed/7598757
- "Assessing spectral and temporal processing in children and adults using temporal modulation transfer function (TMTF), Iterated Ripple Noise (IRN) perception, and spectral ripple discrimination (SRD)". Journal of the American Academy of Audiology 25 (2): 210–8. February 2014. doi:10.3766/jaaa.25.2.9. PMID 24828221. https://dx.doi.org/10.3766%2Fjaaa.25.2.9
- "Issues in human auditory development". Journal of Communication Disorders 40 (4): 275–83. 2007. doi:10.1016/j.jcomdis.2007.03.004. PMID 17420028. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=1975821
- "Development of adult-like performance in backward, simultaneous, and forward masking". Journal of Speech, Language, and Hearing Research 42 (4): 844–9. August 1999. PMID 10450905. http://www.ncbi.nlm.nih.gov/pubmed/10450905
- "Infants' and Adults' Use of Temporal Cues in Consonant Discrimination". Ear and Hearing 38 (4): 497–506. July 2017. doi:10.1097/AUD.0000000000000422. PMID 28338496. PMC 5482774. http://discovery.ucl.ac.uk/1547466/1/Cabrera_26Werner_2017_preprint.pdf.
- "Discrimination of speech sounds based upon temporal envelope versus fine structure cues in 5- to 7-year-old children". Journal of Speech, Language, and Hearing Research 52 (3): 682–95. June 2009. doi:10.1044/1092-4388(2008/07-0273). PMID 18952853. https://dx.doi.org/10.1044%2F1092-4388%282008%2F07-0273%29
- Le Prell, Colleen G. (2012). Noise-Induced Hearing Loss - Scientific Advances. Springer. https://www.springer.com/la/book/9781441995223.
- Manley, Geoffrey A. (2017). Understanding the Cochlea. Springer. https://www.springer.com/us/book/9783319520711.
- "Envelope coding in auditory nerve fibers following noise-induced hearing loss". Journal of the Association for Research in Otolaryngology 11 (4): 657–73. December 2010. doi:10.1007/s10162-010-0223-6. PMID 20556628. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2975881
- "Sensorineural hearing loss amplifies neural coding of envelope information in the central auditory system of chinchillas". Hearing Research 309: 55–62. March 2014. doi:10.1016/j.heares.2013.11.006. PMID 24315815. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3922929
- "Temporal modulation transfer functions measured from auditory-nerve responses following sensorineural hearing loss". Hearing Research 286 (1–2): 64–75. April 2012. doi:10.1016/j.heares.2012.02.004. PMID 22366500. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3326227
- "Noise-induced hearing loss increases the temporal precision of complex envelope coding by auditory-nerve fibers". Frontiers in Systems Neuroscience 8: 20. 2014-02-17. doi:10.3389/fnsys.2014.00020. PMID 24596545. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3925834
- "Furosemide alters organ of corti mechanics: evidence for feedback of outer hair cells upon the basilar membrane". The Journal of Neuroscience 11 (4): 1057–67. April 1991. PMID 2010805. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3580957
- "Response growth with sound level in auditory-nerve fibers after noise-induced hearing loss". Journal of Neurophysiology 91 (2): 784–95. February 2004. doi:10.1152/jn.00776.2003. PMID 14534289. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2921373
- "Temporal modulation transfer functions obtained using sinusoidal carriers with normally hearing and hearing-impaired listeners". The Journal of the Acoustical Society of America 110 (2): 1067–73. August 2001. PMID 11519575. http://www.ncbi.nlm.nih.gov/pubmed/11519575
- "Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition". Frontiers in Aging Neuroscience 6: 347. 2014. doi:10.3389/fnagi.2014.00347. PMID 25628563. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4292733
- "Comparing the effects of age on amplitude modulation and frequency modulation detection". The Journal of the Acoustical Society of America 139 (6): 3088–3096. June 2016. doi:10.1121/1.4953019. PMID 27369130. https://dx.doi.org/10.1121%2F1.4953019
- "Modulation detection in subjects with relatively flat hearing losses". Journal of Speech and Hearing Research 35 (3): 642–53. June 1992. PMID 1608256. http://www.ncbi.nlm.nih.gov/pubmed/1608256
- "Temporal modulation transfer functions for band-limited noise in subjects with cochlear hearing loss". British Journal of Audiology 26 (4): 229–37. August 1992. PMID 1446186. http://www.ncbi.nlm.nih.gov/pubmed/1446186
- "Discrimination of amplitude-modulation depth by subjects with normal and impaired hearing". The Journal of the Acoustical Society of America 140 (5): 3487–3495. November 2016. doi:10.1121/1.4966117. PMID 27908066. https://dx.doi.org/10.1121%2F1.4966117
- "Speech recognition in normal hearing and sensorineural hearing loss as a function of the number of spectral channels". The Journal of the Acoustical Society of America 120 (5): 2908–2925. November 2006. doi:10.1121/1.2354017. https://dx.doi.org/10.1121%2F1.2354017
- "The effects of age and hearing loss on interaural phase difference discrimination". The Journal of the Acoustical Society of America 135 (1): 342–51. January 2014. doi:10.1121/1.4838995. PMID 24437774. https://dx.doi.org/10.1121%2F1.4838995
- "Modeling temporal and compressive properties of the normal and impaired auditory system". Hearing Research 159 (1–2): 132–49. September 2001. PMID 11520641. http://www.ncbi.nlm.nih.gov/pubmed/11520641
- "Sensorineural hearing loss enhances auditory sensitivity and temporal integration for amplitude modulation". The Journal of the Acoustical Society of America 141 (2): 971–980. February 2017. doi:10.1121/1.4976080. PMID 28253641. https://dx.doi.org/10.1121%2F1.4976080
- "Characterizing auditory processing and perception in individual listeners with sensorineural hearing loss". The Journal of the Acoustical Society of America 129 (1): 262–81. January 2011. doi:10.1121/1.3518768. PMID 21303008. https://dx.doi.org/10.1121%2F1.3518768
- "Effects of noise reduction on AM perception for hearing-impaired listeners". Journal of the Association for Research in Otolaryngology 15 (5): 839–48. October 2014. doi:10.1007/s10162-014-0466-8. PMID 24899379. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4164688
- "Evidence that hidden hearing loss underlies amplitude modulation encoding deficits in individuals with and without tinnitus". Hearing Research 344: 170–182. February 2017. doi:10.1016/j.heares.2016.11.010. PMID 27888040. https://dx.doi.org/10.1016%2Fj.heares.2016.11.010
- "Discrimination of frequency transitions by human infants". The Journal of the Acoustical Society of America 86 (2): 582–90. August 1989. PMID 2768673. http://www.ncbi.nlm.nih.gov/pubmed/2768673
- "Infants' attentional responses to frequency modulated sweeps". Child Development 57 (2): 287–91. April 1986. doi:10.2307/1130583. PMID 3956313. https://dx.doi.org/10.2307%2F1130583
- Leibold, Lori J.; Werner, Lynne A. (2007-09-01). "Infant Auditory Sensitivity to Pure Tones and Frequency-Modulated Tones". Infancy 12 (2): 225–233. doi:10.1111/j.1532-7078.2007.tb00241.x. https://dx.doi.org/10.1111%2Fj.1532-7078.2007.tb00241.x
- "Maturation of visual and auditory temporal processing in school-aged children". Journal of Speech, Language, and Hearing Research 51 (4): 1002–15. August 2008. doi:10.1044/1092-4388(2008/073). PMID 18658067. https://dx.doi.org/10.1044%2F1092-4388%282008%2F073%29
- "Diminished temporal coding with sensorineural hearing loss emerges in background noise". Nature Neuroscience 15 (10): 1362–4. October 2012. doi:10.1038/nn.3216. PMID 22960931. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3458164
- "Distorted Tonotopic Coding of Temporal Envelope and Fine Structure with Noise-Induced Hearing Loss". The Journal of Neuroscience 36 (7): 2227–37. February 2016. doi:10.1523/JNEUROSCI.3944-15.2016. PMID 26888932. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4756156
- "Pitch discrimination and phase sensitivity in young and elderly subjects and its relationship to frequency selectivity". The Journal of the Acoustical Society of America 91 (5): 2881–93. May 1992. PMID 1629481. http://www.ncbi.nlm.nih.gov/pubmed/1629481
- Moore, Brian C.J. (2008). Cochlear Hearing Loss: Physiological, Psychological and Technical Issues (Second ed.). Wiley Online Library. doi:10.1002/9780470987889. ISBN 9780470987889. https://dx.doi.org/10.1002%2F9780470987889
- "Moderate cochlear hearing loss leads to a reduced ability to use temporal fine structure information". The Journal of the Acoustical Society of America 122 (2): 1055–68. August 2007. doi:10.1121/1.2749457. PMID 17672653. https://dx.doi.org/10.1121%2F1.2749457
- "Detection of frequency modulation by hearing-impaired listeners: effects of carrier frequency, modulation rate, and added amplitude modulation". The Journal of the Acoustical Society of America 111 (1 Pt 1): 327−35. January 2002. PMID 11833538. https://www.academia.edu/11982576.
- "Frequency modulation detection as a measure of temporal processing: age-related monaural and binaural effects". Hearing Research 294 (1–2): 49–54. December 2012. doi:10.1016/j.heares.2012.09.007. PMID 23041187. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3505233
- "Binaural pitch perception in normal-hearing and hearing-impaired listeners". Hearing Research 223 (1–2): 29–47. January 2007. doi:10.1016/j.heares.2006.09.013. PMID 17107767. http://orbit.dtu.dk/en/publications/binaural-pitch-perception-in-normalhearing-and-hearingimpaired-listeners(0f7af462-8989-4ce9-a040-9108999702fd).html.
- "Processing of temporal fine structure as a function of age". Ear and Hearing 31 (6): 755–60. December 2010. doi:10.1097/AUD.0b013e3181e627e7. PMID 20592614. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2966515
- "Perception of stochastically undersampled sound waveforms: a model of auditory deafferentation". Frontiers in Neuroscience 7: 124. 2013-07-16. doi:10.3389/fnins.2013.00124. PMID 23882176. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3712141
- "Representation of steady-state vowels in the temporal aspects of the discharge patterns of populations of auditory-nerve fibers". The Journal of the Acoustical Society of America 66 (5): 1381–1403. November 1979. PMID 500976. http://www.ncbi.nlm.nih.gov/pubmed/500976
- "Perceptual consequences of disrupted auditory nerve activity". Journal of Neurophysiology 93 (6): 3050–63. June 2005. doi:10.1152/jn.00985.2004. PMID 15615831. https://dx.doi.org/10.1152%2Fjn.00985.2004
- "Temporal jitter disrupts speech intelligibility: a simulation of auditory aging". Hearing Research 223 (1–2): 114–21. January 2007. doi:10.1016/j.heares.2006.10.009. PMID 17157462. https://dx.doi.org/10.1016%2Fj.heares.2006.10.009
- "Temporal envelope and fine structure cues for speech intelligibility". The Journal of the Acoustical Society of America 97 (1): 585–92. January 1995. PMID 7860835. http://www.ncbi.nlm.nih.gov/pubmed/7860835
- "Why do I hear but not understand? Stochastic undersampling as a model of degraded neural encoding of speech". Frontiers in Neuroscience 8: 348. 2014-10-30. doi:10.3389/fnins.2014.00348. PMID 25400543. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4214224
- "A method for the early detection of otosclerosis: a study of sounds well above threshold". Archives of Otolaryngology–Head and Neck Surgery 24 (6): 731–741. 1936-12-01. doi:10.1001/archotol.1936.00640050746005. https://jamanetwork.com/journals/jamaotolaryngology/article-abstract/559453?redirect=true.
- "Testing the concept of softness imperception: loudness near threshold for hearing-impaired ears". The Journal of the Acoustical Society of America 115 (6): 3103–11. June 2004. PMID 15237835. http://www.ncbi.nlm.nih.gov/pubmed/15237835
- "Syllabic compression: effective compression ratios for signals modulated at different rates". British Journal of Audiology 26 (6): 351–61. December 1992. PMID 1292819. http://www.ncbi.nlm.nih.gov/pubmed/1292819
- "The negative effect of amplitude compression in multichannel hearing aids in the light of the modulation-transfer function". The Journal of the Acoustical Society of America 83 (6): 2322–7. June 1988. PMID 3411024. http://www.ncbi.nlm.nih.gov/pubmed/3411024
- "Quantifying the effects of fast-acting compression on the envelope of speech". The Journal of the Acoustical Society of America 121 (3): 1654–64. March 2007. PMID 17407902. http://www.ncbi.nlm.nih.gov/pubmed/17407902
- Bacon, Sid. Compression: From Cochlea to Cochlear Implants. Springer. https://www.springer.com/us/book/9780387004969.
- "Comparison of dual-time-constant and fast-acting automatic gain control (AGC) systems in cochlear implants". International Journal of Audiology 48 (4): 211–21. April 2009. doi:10.1080/14992020802581982. PMID 19363722. https://dx.doi.org/10.1080%2F14992020802581982
- "The University of Melbourne--nucleus multi-electrode cochlear implant". Advances in Oto-Rhino-Laryngology 38: V–IX, 1–181. 1987. PMID 3318305. http://www.ncbi.nlm.nih.gov/pubmed/3318305
- "Chapter 12: Perception and Psychoacoustics of Speech in Cochlear Implant Users". Scientific foundations of Audiology: Perspectives from Physics, Biology, Modeling, and Medicine. San Diego, CA: Plural Publishing, Inc. 2016. pp. 285–319. ISBN 978-1-59756-652-0. https://www.pluralpublishing.com/publication_sfa.htm.
- "Identifying cochlear implant channels with poor electrode-neuron interface: partial tripolar, single-channel thresholds and psychophysical tuning curves". Ear and Hearing 31 (2): 247–58. April 2010. doi:10.1097/AUD.0b013e3181c7daf4. PMID 20090533. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2836401
- "Pre-, per- and postoperative factors affecting performance of postlinguistically deaf adults using cochlear implants: a new conceptual model over time". PLOS One 7 (11): e48739. November 2012. doi:10.1371/journal.pone.0048739. PMID 23152797. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3494723
- "Factors Affecting Outcomes in Cochlear Implant Recipients Implanted With a Perimodiolar Electrode Array Located in Scala Tympani". Otology & Neurotology 37 (10): 1662–1668. December 2016. doi:10.1097/MAO.0000000000001241. PMID 27755365. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5113723
- "STARR: a speech test for evaluation of the effectiveness of auditory prostheses under realistic conditions". Ear and Hearing 34 (2): 203–12. March 2013. doi:10.1097/AUD.0b013e31826a8e82. PMID 23135616. https://dx.doi.org/10.1097%2FAUD.0b013e31826a8e82
- "Acoustic temporal modulation detection and speech perception in cochlear implant listeners". The Journal of the Acoustical Society of America 130 (1): 376–88. July 2011. doi:10.1121/1.3592521. PMID 21786906. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3155593
- "Temporal processing and speech recognition in cochlear implant users". NeuroReport 13 (13): 1635–9. September 2002. PMID 12352617. http://www.ncbi.nlm.nih.gov/pubmed/12352617
- "Speech recognition in noise as a function of the number of spectral channels: comparison of acoustic hearing and cochlear implants". The Journal of the Acoustical Society of America 110 (2): 1150–63. August 2001. PMID 11519582. http://www.ncbi.nlm.nih.gov/pubmed/11519582
- "Beyond cochlear implants: awakening the deafened brain". Nature Neuroscience 12 (6): 686–91. June 2009. doi:10.1038/nn.2326. PMID 19471266. https://dx.doi.org/10.1038%2Fnn.2326
- "Cochlear implant speech recognition with speech maskers". The Journal of the Acoustical Society of America 116 (2): 1081–91. August 2004. doi:10.1121/1.1772399. PMID 15376674. https://dx.doi.org/10.1121%2F1.1772399
- "Factors affecting auditory performance of postlinguistically deaf adults using cochlear implants: an update with 2251 patients". Audiology & Neuro-Otology 18 (1): 36–47. 2013. doi:10.1159/000343189. PMID 23095305. http://www.zora.uzh.ch/id/eprint/69118/1/Dillier_HuberA_etal_AudiolNeurotol_2012.pdf.
- "Cognitive compensation of speech perception with hearing impairment, cochlear implants, and aging". Trends in Hearing 20: 233121651667027. October 2016. doi:10.1177/2331216516670279. https://dx.doi.org/10.1177%2F2331216516670279
- "Across-site patterns of modulation detection in listeners with cochlear implants". The Journal of the Acoustical Society of America 123 (2): 1054–62. February 2008. doi:10.1121/1.2828051. PMID 18247907. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2431465
- "Detection and rate discrimination of amplitude modulation in electrical hearing". The Journal of the Acoustical Society of America 130 (3): 1567–80. September 2011. doi:10.1121/1.3621445. PMID 21895095. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3188971
- "Temporal modulation transfer functions in patients with cochlear implants". The Journal of the Acoustical Society of America 91 (4 Pt 1): 2156–64. April 1992. PMID 1597606. http://www.ncbi.nlm.nih.gov/pubmed/1597606
- "Low-pass filtering in amplitude modulation detection associated with vowel and consonant identification in subjects with cochlear implants". The Journal of the Acoustical Society of America 96 (4): 2048–54. October 1994. PMID 7963020. http://www.ncbi.nlm.nih.gov/pubmed/7963020
- "Music perception by cochlear implant and normal hearing listeners as measured by the Montreal Battery for Evaluation of Amusia". Ear and Hearing 29 (4): 618–26. August 2008. doi:10.1097/AUD.0b013e318174e787. PMID 18469714. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2676841
- "Melodic contour identification by cochlear implant listeners". Ear and Hearing 28 (3): 302–19. June 2007. doi:10.1097/01.aud.0000261689.35445.20. PMID 17485980. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3627492
- "Voice gender identification by cochlear implant users: the role of spectral and temporal resolution". The Journal of the Acoustical Society of America 118 (3 Pt 1): 1711–8. September 2005. PMID 16240829. http://www.ncbi.nlm.nih.gov/pubmed/16240829
- "Gender categorization is abnormal in cochlear implant users". Journal of the Association for Research in Otolaryngology 15 (6): 1037–48. December 2014. doi:10.1007/s10162-014-0483-7. PMID 25172111. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4389960
- "Processing of Acoustic Cues in Lexical-Tone Identification by Pediatric Cochlear-Implant Recipients". Journal of Speech, Language, and Hearing Research 60 (5): 1223–1235. May 2017. doi:10.1044/2016_JSLHR-S-16-0048. PMID 28388709. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5755546
- "Musical pitch and lexical tone perception with cochlear implants". International Journal of Audiology 50 (4): 270–8. April 2011. doi:10.3109/14992027.2010.542490. PMID 21190394. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5662112
- "Processing F0 with cochlear implants: Modulation frequency discrimination and speech intonation recognition". Hearing Research 235 (1–2): 143–56. January 2008. doi:10.1016/j.heares.2007.11.004. PMID 18093766. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2237883
- "Vocal emotion recognition by normal-hearing listeners and cochlear implant users". Trends in Amplification 11 (4): 301–15. December 2007. doi:10.1177/1084713807305301. PMID 18003871. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4111530
- "Voice emotion recognition by cochlear-implanted children and their normally-hearing peers". Hearing Research 322: 151–62. April 2015. doi:10.1016/j.heares.2014.10.003. PMID 25448167. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4615700
- "Across- and within-channel envelope interactions in cochlear implant listeners". Journal of the Association for Research in Otolaryngology 5 (4): 360–75. December 2004. PMID 15675001. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2504569
- "Modulation detection interference in cochlear implant listeners under forward masking conditions". The Journal of the Acoustical Society of America 143 (2): 1117–1127. February 2018. doi:10.1121/1.5025059. PMID 29495705. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5821512
- "Evaluation of the noise reduction system in a commercial digital hearing aid". International Journal of Audiology 42 (1): 34–42. January 2003. PMID 12564514. http://www.ncbi.nlm.nih.gov/pubmed/12564514
- "Coding of sounds in the auditory system and its relevance to signal processing and coding in cochlear implants". Otology & Neurotology 24 (2): 243–54. March 2003. PMID 12621339. http://www.ncbi.nlm.nih.gov/pubmed/12621339
- "Place dependent stimulation rates improve pitch perception in cochlear implantees with single-sided deafness". Hearing Research 339: 94–103. September 2016. doi:10.1016/j.heares.2016.06.013. PMID 27374479. https://dx.doi.org/10.1016%2Fj.heares.2016.06.013
- "Musical Sound Quality in Cochlear Implant Users: A Comparison in Bass Frequency Perception Between Fine Structure Processing and High-Definition Continuous Interleaved Sampling Strategies". Ear and Hearing 36 (5): 582–90. October 2015. doi:10.1097/AUD.0000000000000170. PMID 25906173. https://dx.doi.org/10.1097%2FAUD.0000000000000170
- "Perceptual learning and generalization resulting from training on an auditory amplitude-modulation detection task". The Journal of the Acoustical Society of America 129 (2): 898–906. February 2011. doi:10.1121/1.3531841. PMID 21361447. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3070992
- "A perceptual learning investigation of the pitch elicited by amplitude-modulated noise". The Journal of the Acoustical Society of America 118 (6): 3794–803. December 2005. PMID 16419824. http://www.ncbi.nlm.nih.gov/pubmed/16419824
- "Perceptual learning evidence for tuning to spectrotemporal modulation in the human auditory system". The Journal of Neuroscience 32 (19): 6542–9. May 2012. doi:10.1523/JNEUROSCI.5732-11.2012. PMID 22573676. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3519395
- "Dynamic Reweighting of Auditory Modulation Filters". PLoS Computational Biology 12 (7): e1005019. July 2016. doi:10.1371/journal.pcbi.1005019. PMID 27398600. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4939963
- "Effects of noise-induced hearing loss at young age on voice onset time and gap-in-noise representations in adult cat primary auditory cortex". Journal of the Association for Research in Otolaryngology 7 (1): 71–81. March 2006. doi:10.1007/s10162-005-0026-3. PMID 16408166. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2504589
- "Diminished behavioral and neural sensitivity to sound modulation is associated with moderate developmental hearing loss". PLOS One 7 (7): e41514. 2012-07-26. doi:10.1371/journal.pone.0041514. PMID 22848517. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3406049
- "Sustained Perceptual Deficits from Transient Sensory Deprivation". The Journal of Neuroscience 35 (30): 10831–42. July 2015. doi:10.1523/JNEUROSCI.0837-15.2015. PMID 26224865. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4518056
- "Environmental noise exposure degrades normal listening processes". Nature Communications 3: 843. May 2012. doi:10.1038/ncomms1849. PMID 22588305. https://dx.doi.org/10.1038%2Fncomms1849
- "Temporal plasticity in the primary auditory cortex induced by operant perceptual learning". Nature Neuroscience 7 (9): 974–81. September 2004. doi:10.1038/nn1293. PMID 15286790. https://dx.doi.org/10.1038%2Fnn1293
- "Plasticity of temporal information processing in the primary auditory cortex". Nature Neuroscience 1 (8): 727–31. December 1998. doi:10.1038/3729. PMID 10196590. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=2948964
- "Training changes processing of speech cues in older adults with hearing loss". Frontiers in Systems Neuroscience 7: 97. 2013. doi:10.3389/fnsys.2013.00097. PMID 24348347. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3842592
- "Musical experience shapes human brainstem encoding of linguistic pitch patterns". Nature Neuroscience 10 (4): 420–2. April 2007. doi:10.1038/nn1872. PMID 17351633. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4508274
- "Sensitivity to temporal fine structure and hearing-aid outcomes in older adults". Frontiers in Neuroscience 8: 7. 2014. doi:10.3389/fnins.2014.00007. PMID 24550769. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=3914396
- "Hearing impairment, cognition and speech understanding: exploratory factor analyses of a comprehensive test battery for a group of hearing aid users, the n200 study". International Journal of Audiology 55 (11): 623–42. November 2016. doi:10.1080/14992027.2016.1219775. PMID 27589015. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5044772
- "Preferred Compression Speed for Speech and Music and Its Relationship to Sensitivity to Temporal Fine Structure". Trends in Hearing 20: 233121651664048. September 2016. doi:10.1177/2331216516640486. PMID 27604778. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5017572
- "Spectrotemporal Modulation Sensitivity as a Predictor of Speech-Reception Performance in Noise With Hearing Aids". Trends in Hearing 20: 233121651667038. November 2016. doi:10.1177/2331216516670387. PMID 27815546. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5098798
- "Implementation of two tests for measuring sensitivity to temporal fine structure". International Journal of Audiology 51 (1): 58–63. January 2012. doi:10.3109/14992027.2011.605808. PMID 22050366. https://dx.doi.org/10.3109%2F14992027.2011.605808
- "The effects of age on temporal fine structure sensitivity in monaural and binaural conditions". International Journal of Audiology 51 (10): 715–21. October 2012. doi:10.3109/14992027.2012.690079. PMID 22998412. https://dx.doi.org/10.3109%2F14992027.2012.690079
- "Age-dependent changes in temporal-fine-structure processing in the absence of peripheral hearing loss". American Journal of Audiology 22 (2): 313–5. December 2013. doi:10.1044/1059-0889(2013/12-0070). PMID 23975124. https://dx.doi.org/10.1044%2F1059-0889%282013%2F12-0070%29
- "Relating binaural pitch perception to the individual listener's auditory profile". The Journal of the Acoustical Society of America 131 (4): 2968–86. April 2012. doi:10.1121/1.3689554. PMID 22501074. http://orbit.dtu.dk/files/12854679/Santurette2012.pdf.
- "Development of a fast method for measuring sensitivity to temporal fine structure information at low frequencies". International Journal of Audiology 49 (12): 940–6. December 2010. doi:10.3109/14992027.2010.512613. PMID 20874427. https://dx.doi.org/10.3109%2F14992027.2010.512613
- "Development of a method for determining binaural sensitivity to temporal fine structure". International Journal of Audiology 56 (12): 926–935. December 2017. doi:10.1080/14992027.2017.1366078. PMID 28859494. http://eprints.nottingham.ac.uk/45398/8/Temporal%20_12___09___2017_Developmen.pdf.
- "Evaluation of a Method for Determining Binaural Sensitivity to Temporal Fine Structure (TFS-AF Test) for Older Listeners With Normal and Impaired Low-Frequency Hearing". Trends in Hearing 21: 2331216517737230. January 2017. doi:10.1177/2331216517737230. PMID 29090641. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=5669320
- "Coherence and the speech intelligibility index". The Journal of the Acoustical Society of America 117 (4 Pt 1): 2224–37. April 2005. PMID 15898663. http://www.ncbi.nlm.nih.gov/pubmed/15898663
- "Effects of noise, nonlinear processing, and linear filtering on perceived speech quality". Ear and Hearing 31 (3): 420–36. June 2010. doi:10.1097/AUD.0b013e3181d3d4f3. PMID 20440116. https://dx.doi.org/10.1097%2FAUD.0b013e3181d3d4f3
- Taal, Cees H.; Hendriks, Richard C.; Heusdens, Richard; Jensen, Jesper (September 2011). "An Algorithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech". IEEE Transactions on Audio, Speech, and Language Processing 19 (7): 2125–2136. doi:10.1109/tasl.2011.2114881. http://ieeexplore.ieee.org/document/5713237/.
- "Music preferences with hearing aids: effects of signal properties, compression settings, and listener characteristics". Ear and Hearing 35 (5): e170–84. September 2014. doi:10.1097/AUD.0000000000000056. PMID 25010635. https://dx.doi.org/10.1097%2FAUD.0000000000000056
- "Relationship Among Signal Fidelity, Hearing Loss, and Working Memory for Digital Noise Suppression". Ear and Hearing 36 (5): 505–16. 2015. doi:10.1097/aud.0000000000000173. PMID 25985016. PMC 4549215. https://insights.ovid.com/crossref?an=00003446-201509000-00002.
- "Estimation of the magnitude-squared coherence function via overlapped fast Fourier transform processing - IEEE Journals & Magazine" (in en-US). https://ieeexplore.ieee.org/document/1162496/.
- "Effects of noise and distortion on speech quality judgments in normal-hearing and hearing-impaired listeners". The Journal of the Acoustical Society of America 122 (2): 1150–64. August 2007. doi:10.1121/1.2754061. PMID 17672661. https://dx.doi.org/10.1121%2F1.2754061
- "Perception of nonlinear distortion by hearing-impaired people". International Journal of Audiology 47 (5): 246–56. May 2008. doi:10.1080/14992020801945493. PMID 18465409. https://dx.doi.org/10.1080%2F14992020801945493
- Houtgast, T; Steeneken, Herman (1985-03-01). "A review of the MTF concept in room acoustics and its use for estimating speech intelligibility in auditoria". The Journal of the Acoustical Society of America 77 (3): 1069–1077. doi:10.1121/1.392224. https://www.researchgate.net/publication/200045201.
- "The effect of multichannel dynamic compression on speech intelligibility". The Journal of the Acoustical Society of America 97 (2): 1191–5. February 1995. PMID 7876441. http://www.ncbi.nlm.nih.gov/pubmed/7876441
- "Analysis of speech-based Speech Transmission Index methods with implications for nonlinear operations". The Journal of the Acoustical Society of America 116 (6): 3679–89. December 2004. PMID 15658718. http://www.ncbi.nlm.nih.gov/pubmed/15658718
- "Prediction of intelligibility of non-linearly processed speech". Acta Oto-Laryngologica. Supplementum 469: 190–5. 1990. PMID 2356726. http://www.ncbi.nlm.nih.gov/pubmed/2356726
- Kates, James M; Arehart, Kathryn H (2014-11-01). "The Hearing-Aid Speech Perception Index (HASPI)". Speech Communication 65: 75–93. doi:10.1016/j.specom.2014.06.002. ISSN 0167-6393. https://www.sciencedirect.com/science/article/pii/S0167639314000545.
- "Spectro-temporal modulation transfer functions and speech intelligibility". The Journal of the Acoustical Society of America 106 (5): 2719–32. November 1999. PMID 10573888. http://www.ncbi.nlm.nih.gov/pubmed/10573888
- Huber, Rainer; Kollmeier, Birger (2006-01-01). "PEMO-Q - A New Method for Objective Audio Quality Assessment Using a Model of Auditory Perception". IEEE Transactions on Audio, Speech & Language Processing 14: 1902–1911. https://www.researchgate.net/publication/220655956.
- "Predicting the perceived sound quality of frequency-compressed speech". PLOS One 9 (11): e110260. 2014-11-17. doi:10.1371/journal.pone.0110260. PMID 25402456. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4234248
- Kates, James; Arehart, Kathryn (2014-03-20). "The Hearing-Aid Speech Quality Index (HASQI) Version 2". Journal of the Audio Engineering Society 62 (3): 99–117. doi:10.17743/jaes.2014.0006. ISSN 1549-4950. https://dx.doi.org/10.17743%2Fjaes.2014.0006
- "The Hearing-Aid Audio Quality Index (HAAQI)". IEEE/ACM Transactions on Audio, Speech, and Language Processing 24 (2): 354–365. February 2016. doi:10.1109/taslp.2015.2507858. PMID 27135042. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=4849486
- Kates, James (2013). An auditory model for intelligibility and quality predictions. Proceedings of Meetings on Acoustics. ASA. pp. 050184. doi:10.1121/1.4799223. https://dx.doi.org/10.1121%2F1.4799223

