 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Amir Mosavi | + 6108 word(s) | 6108 | 2020-10-20 05:56:37 | | | |
| 2 | Bruce Ren | Meta information modification | 6108 | 2020-10-21 04:13:54 | | |
Video Upload Options
This entry provides a comprehensive state-of-the-art investigation of the recent advances in data science in emerging economic applications. The analysis is performed on the novel data science methods in four individual classes of deep learning models, hybrid deep learning models, hybrid machine learning, and ensemble models. Application domains include a broad and diverse range of economics research from the stock market, marketing, and e-commerce to corporate banking and cryptocurrency. Prisma method, a systematic literature review methodology, is used to ensure the quality of the survey. The findings reveal that the trends follow the advancement of hybrid models, which outperform other learning algorithms. It is further expected that the trends will converge toward the evolution of sophisticated hybrid deep learning models.
1. Introduction
Due to the rapid advancement of databases and information technologies, and the remarkable progress in data analysis methods, the use of data science (DS) in various disciplines, including economics, has been increasing exponentially [1]. Advancements in data science technologies for economics applications have been progressive with promising results [2][3]. Several studies suggest that data science applications in economics can be categorized and studied in various popular technologies, such as deep learning, hybrid learning models, and ensemble algorithms [4]. Machine learning (ML) algorithms provide the ability to learn from data and deliver in-depth insight into problems [5]. Researchers use machine learning models to solve various problems associated with economics. Notable applications of data science in economics are presented in Table 1. Deep learning (DL), as an emerging field of machine learning, is currently applied in many aspects of today’s society, from self-driving cars to image recognition, hazard prediction, health informatics, and bioinformatics [5][6]. Several comparative studies have evaluated the performance of DL models with standard ML models, e.g., support vector machine (SVM), K-nearest neighbors (KNN), and generalized regression neural networks (GRNN) in economic applications. The evolution of DS methods has progressed at a fast pace, and every day, many new sectors and disciplines are added to the number of users and beneficiaries of DS algorithms. On the other hand, hybrid machine learning models consist of two or more single algorithms and are used to increase the accuracy of the other models [7]. Hybrid models can be formed by combining two predictive machine learning algorithms or a machine learning algorithm and an optimization method to maximize the prediction function [8]. It has been demonstrated that the hybrid machine learning models outperform the single algorithms, and such an approach has improved the prediction accuracy [9]. Ensemble machine learning algorithms are one of the supervised learning algorithms that use multiple learning algorithms to improve learning processes and increase predictive accuracy [10]. Ensemble models apply different training algorithms to enhance training and learning from data [11].
Table 1. Examples of notable classic machine learning methods applied in economics-related fields.
|
Sources |
Machine Learning Models |
Objectives |
|
Lee et al. [12] |
Support Vector Regression (SVR) |
Anomaly Detection |
|
Husejinović [13] |
Naive Bayesian And C4.5 Decision Tree Classifiers |
Credit Card Fraud Detection |
|
Zhang [14] |
Improved BP Neural Network |
Aquatic Product Export Volume Prediction |
|
Sundar and Satyanarayana [15] |
Multilayer Feed Forward Neural Network |
Stock Price Prediction |
|
Hew et al. [16] |
Artificial Neural Network (ANN) |
Mobile Social Commerce |
|
Abdillah and Suharjito [17] |
Adaptive Neuro-Fuzzy Inference System (ANFIS) |
E-Banking Failure |
|
Sabaitytė et al. [18] |
Decision Tree (DT) |
Customer Behavior |
|
Zatevakhina, Dedyukhina, and Klioutchnikov [19] |
Deep Neural Network (ANN) |
Recommender Systems |
|
Benlahbib and Nfaoui [20] |
Naïve Bayes and Linear Support Vector Machine (LSVM) |
Sentiment Analysis |
Various works exist on the state-of-the-art of DS methods in different disciplines, such as image recognition [21], animal behavior [22], renewable energy forecasting [23]. Hybrid methods have also been investigated in various fields, including financial time series [24], solar radiation forecasting [25], and FOREX rate prediction [26], while ensemble methods have been mostly in the fields, ranging from breast cancer [27], image categorization[28], electric vehicle user behavior prediction [29], and solar power generation forecasting [30]. Exploring the scientific databases such as Thomson Reuters Web-of-Science (WoS) shows an exponential rise in using both DL and ML in economics. The results of an inquiry of essential ML and DL in the emerging applications to economics over the past decade is illustrated in Figure 1. Even though many researchers have applied DS methods to address different problems in the field of economics, these studies are scattered. At the same time, no single study provides a comprehensive overview of the contributions of DS in economic-related fields. Therefore, the current study is conducted to bridge this literature gap. In other words, the main objective of this study is to investigate the advancement of DS in three parts: deep learning methods, hybrid deep learning methods, and ensemble machine learning techniques in economics-related fields. The present work aims to answer the following research questions. (1) what are the emerging economics domains with the involvement of data science technologies? (2) what are the popular data science models and applications in these domains?
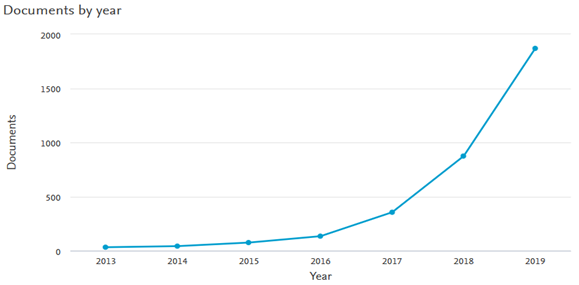
Figure 1. Rapid rise in the applications of data science in economics.
2. Findings and Discussion
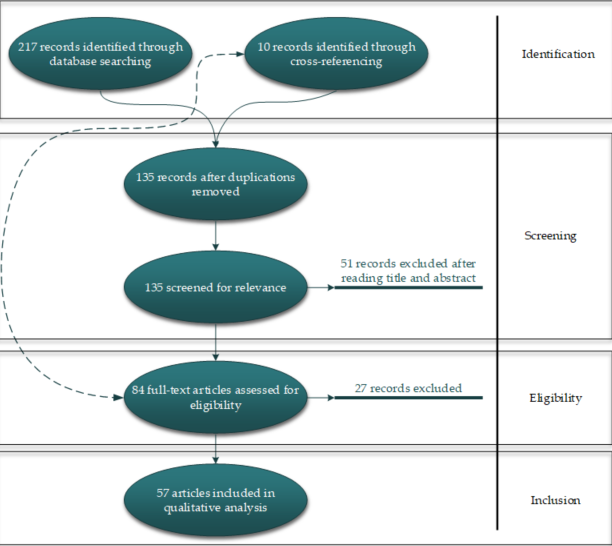
Figure 2 shows that this study's database consists of 57 articles that were analyzed and categorized according to two criteria: (1) research/application area, and (2) the method type. Based on the review of articles by application, it was found that these articles were designed to address the issues of five different applications, namely the Stock Market (37 articles), Marketing (6 articles), E-commerce (8 articles), Corporate Bankruptcy (3 articles), and Cryptocurrency (3 articles) (Tables 2–7). In addition, the articles were analyzed by the type of method, revealing that 42 unique algorithms were employed among the 57 reviewed articles (see Figure 3). It was further found that 9 articles used 9 single DL models (Table 8), 18 hybrid deep learning (HDL) models (Table 9), 7 hybrid machine learning models (Table 10), and 8 ensemble models (Table 11). In the following section, the identified applications and each of these methods are described in detail.
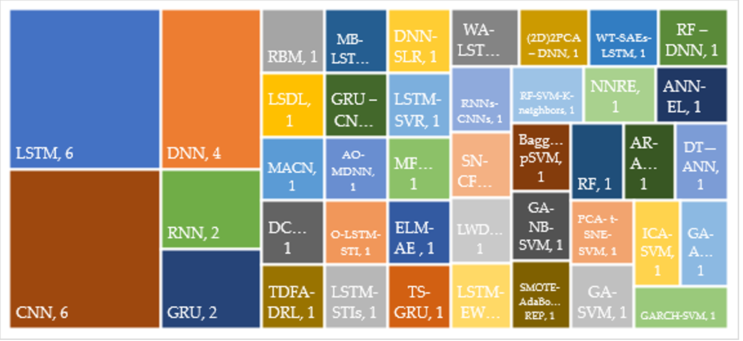
Figure 3. Notable methods of deep learning and hybrid deep learning models applied in economics-related fields; the size of the rectangle is proportional to the number of publications (source: WoS).
2.1. Applications of Data Science in Economics
3.1.1. Stock Market
Applying deep learning in the stock market has become more common than in other economics areas, considering that most of the research articles reviewed in the present study are classified in this category (37 out of 57). Table 2 summarizes the articles that employed predictive models in stock market studies, including research objectives, data sources, and applied models of each article. Investment in the stock market is profitable, while the higher the profit, the higher the risk. Therefore, investors always try to determine and estimate the stock value before any action. The stock value is often influenced by uncontrollable economical and political factors that make it notoriously difficult to identify the future stock market trends. Not only is the nature of the stock market so volatile and complex, but the financial time series data are also noisy and nonstationary. Thus, the traditional forecasting models are not reliable enough to predict the stock value. Researchers are continuously seeking new methodologies based on DS algorithms to enhance the accuracy of such predictions. Forecasting stock price was found to be the objective of 29 out of 37 articles. Other studies aimed at applying DS in sentiment analysis, or the analysis of the context of texts to extracts subjective information, to identify future trends in the stock market. In addition, portfolio management, algorithmic trading (i.e., using a pre-programmed automated system for trading), automated stock trading, socially responsible investment portfolios, the S&P 500 index trend prediction, and exchange-trade-fund (EFT) options prices prediction were the objectives of other articles that projected to employ DS methods. Financial time series served as the data source of all these studies, except for the studies aimed at sentiment analysis, which used different data sources, such as social media and financial news.
LSTM
Long short-term memory (LSTM) networks are a special kind of recurrent neural network (RNN) that can overcome the main issue of RNN, i.e., vanishing gradients using the gates to retain relevant information and discard unrelated details selectively. The structure of an LSTM neural network is shown in Figure 4, which is composed of a memory unit , a hidden state and three types of gates, where indexes the time step. Specifically, for each step , LSTM receives an input and the previous hidden state then calculates the activation of the gates. Finally, the memory unit and the hidden state are updated. The computations involved are described below:
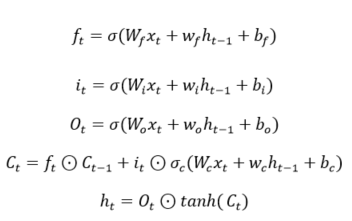
where , , and denote the weights of inputs; and and indicate weights of recurrent output and biases, respectively. The subscripts , , and represent the forget, input, and output gate vectors, respectively; , , and denote the biases; and is the element-wise multiplication.
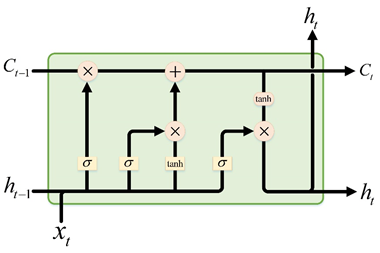
Figure 4. The structure of the long short-term memory (LSTM) network
Many researchers have strived to forecast the stock value relying on the LSTM algorithm, either a single long short-term memory (LSTM) or a hybrid model of LSTM. Adapting the LSTM algorithm, Moon and Kim [31][32] proposed an algorithm to predict the stock market index and volatility. Fischer and Krauss [33] expand the LSTM networks to forecast out-of-sample directional movements in the stock market. The comparison between the performance of their model with the random forest (RF), deep neural network (DNN), and logistic regression classifier (LOG) illustrates the remarkable outperformance of the LSTM model. Tamura et al. [34] introduced a two-dimensional approach to predict the stock values in which the technical financial indices of the Japanese stock market were entered as input data to the LSTM for the prediction, then the data on financial statements of the related companies were retrieved and added to the database. Wang et al. [35] tried to find the best model to predict portfolio management's financial time-series to optimize portfolio formation. They compared the results of LSTM against SVM, RF, DNN, and the autoregressive integrated moving average model (ARIMA) and realized that LSTM is more suitable for financial time-series forecasting. Using LSTM, Fister et al. [36] designed a model for automated stock trading. They argue that the performance of LSTM is remarkably higher than the traditional trading strategies, such as passive and rule-based trading strategies. In their case studies, the German blue-chip stock and BMW in the period between 2010 and 2018 formed the data sources.
In addition, there is much evidence in the literature that hybrid LSTM methods outperform the other single DL methods [37]. In the application of the stock market, LSTM has been combined with different methods to develop a hybrid model. For instance, Tamura et al. [34] used LSTM to predict stock price and reported that the accuracy-test results outperform other literature models. Employing optimal long short-term memory (O-LSTM), Agrawal et al. [38] proposed a model for the stock price prediction using correlation-tensor, which is formed by stock technical indicators (STIs) to optimize the deep learning function. As a result, two predictive models were developed, namely one for price trend prediction and the other for making the buy-sell decision at the end of the day.
Integrating wavelet transforms (WT), stacked autoencoders (SAEs), and LSTM, Bao, Yue, and Rao [39] established a new method to predict the stock price. In the first stage, WT first eliminates noises to decompose the stock price time series, then predictive features for the stock price are created by SAEs in the next stage. Finally, the LSTM is applied to predict the next day's closing price based on the previous stage's features. Bao et al. [39] claim that their model outperforms state-of-the-art literature models in terms of predictive accuracy and profitability performance. To cope with non-linearity and non-stationary characteristics of financial time series, Yan and Ouyang [40] integrate wavelet analysis-LSTM (WA-LSTM) to forecast the daily closing price of the Shanghai Composite Index. Results show that their proposed model outperformed multiple layer perceptron (MLP), SVM, and KNN in finding the patterns in the financial time series. Vo et al. [41] used a multivariate bidirectional-LSTM (MB-LSTM) to develop a deep responsible investment portfolio (DRIP) model for the prediction of stock returns for socially responsible investment portfolios. They applied the deep reinforcement learning (DRL) model to retrain neural networks. Fang, Chen, and Xue [42] developed a methodology to predict the exchange-trade-fund (EFT) options prices. Through integrating LSTM and support vector regression (SVR), they produce two models of LSTM-SVR for modeling the final transaction price, buy price, highest price, lowest price, volume, historical volatility, and the implied volatility of the time segment. They predicted the price with promising results. In the second generation of LSTM-SVR, the hidden state vectors of LSTM and the seven factors affecting the option price are considered the SVR’s inputs. They also compare the results with the LSTM and RF models, where the proposed model outperforms other methods.
Table 2. Notable machine learning and deep learning methods in stock market.
|
Source |
Modeling Methods |
Data Source |
Research Objective |
|
Wang et al. [35] |
LSTM Comparing with SVM, RF, DNN, and ARIMAs |
Financial Time Series |
Portfolio management |
|
Lei et al. [43] |
time-driven feature-aware and DRL |
Financial Time Series |
Algorithmic trading |
|
Vo et al. [41] |
Multivariate Bidirectional LSTM Comparing with DRL |
Financial Time Series |
Socially Responsible Investment Portfolios |
|
Sabeena and Venkata Subba Reddy [44] |
GRU–CNN |
Financial Time Series |
Stock Price Prediction |
|
Das and Mishra [45] |
Adam optimizer-MDNN |
Financial Time Series |
Stock Price Prediction |
|
Go and Hong [46] |
DNN |
Financial Time Series |
Stock Price Prediction |
|
Agrawal et al. [38] |
O-LSTM-STI |
Financial Time Series |
Stock Price Prediction |
|
Gonçalves et al. [47] |
CNN comparing with DNNC and LSTM |
Financial Time Series |
Stock Price Prediction |
|
Moews et al. [48] |
DNN-SLR |
Financial Time Series |
Stock Price Prediction |
|
Song et al. [49] |
DNN |
Financial Time Series |
Stock Price Prediction |
|
Fang et al. [42] |
LSTM-SVR comparing with RF and LSTM |
Financial Time Series |
Exchange-trade-fund (EFT) Options Prices Prediction |
|
Long et al. [50] |
MFNN (CNN and RNN) |
Financial Time Series |
Stock Price Prediction |
|
Fister et al. [36] |
LSTM |
Financial Time Series |
Automated Stock Trading |
|
Rajesh [51] |
RF, SVM, and KNN |
Financial Time Series |
Stock Price Prediction |
|
Moon and Kim [32] |
LSTM |
Financial Time Series |
Stock Price Prediction |
|
Sim Kim, and Ahn [52] |
CNN comparing with ANN and SVM |
Financial Time Series |
Stock Price Prediction |
|
Agrawal et al. [53] |
LSTM-STIs |
Financial Time Series |
Stock Price Prediction |
|
Tashiro et al. [54] |
CNN |
Financial Time Series |
Stock Price Prediction |
|
Sirignano and Cont [55] |
LSDL |
Financial Time Series |
Stock Price Prediction |
|
Weng et al. [56] |
BRT comparing with NNRE, SVRE, and RFR |
Financial Time Series |
Stock Price Prediction |
|
Preeti et al. [57] |
ELM-AE comparing with GARCH, GRNN, MLP, RF, and GRDH |
Financial Time Series |
Stock Price Prediction |
|
Sohangir et al. [58] |
CNN comparing with doc2vec and LSTM |
Social media |
Sentiment Analysis |
|
Fischer and Krauss [33] |
LSTM comparing with RF, DNN, and LOG |
Financial Time Series |
Stock Price Prediction |
|
Lien Minh et al. [59] |
two-stream GRU |
Financial news |
Sentiment Analysis |
|
Das et al. [60] |
DNN |
Financial Time Series |
The S&P 500 Index Trend Prediction |
|
Yan and Ouyang [40] |
wavelet analysis with LSTM, comparing with SVM, KNN, and MLP |
Financial Time Series |
Stock Price Prediction |
|
Kim et al. [61] |
MACN |
Financial Time Series |
Stock Price Prediction |
|
Faghihi-Nezhad and Minaei-Bidgoli [62] |
EL-ANN |
Financial Time Series |
Stock Price Prediction |
|
Tamura et al. [34] |
LSTM |
Financial Time Series |
Stock Price Prediction |
|
Chong et al. [63] |
DNN comparing with PCA, Autoencoder, and RBM |
Financial Time Series |
Stock Price Prediction |
|
Dingli and Fournier [64] |
CNN |
Financial Time Series |
Stock Price Prediction |
|
Singh and Srivastava [65] |
(2D)2PCA–DNN comparing with RBFNN |
Financial Time Series |
Stock Price Prediction |
|
Bao et al. [39] |
WT-SAEs-LSTM |
Financial Time Series |
Stock Price Prediction |
|
Shekhar and Varshney [66] |
GA-SVM |
Financial Time Series |
Stock Price Prediction |
|
Ahmadi et al. [67] |
ICA- SVM |
Financial Time Series |
Stock Price Prediction |
|
Ebadati and Mortazavi [68] |
GA-ANN |
Financial Time Series |
Stock Price Prediction |
|
Johari et al. [69] |
GARCH-SVM |
Financial Time Series |
Stock Price Prediction |
DNN
Deep neural network (DNN), which is composed of multiple nonlinear operations levels, and each layer only receives the connections from its previous training layer as shown in Figure 5, adapted from [49]. Suppose be the input data, and be a filter bank, where is the number of layers. The multi-layer features of the DNN can be represented as
|
|
|
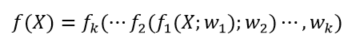
Currently, DNN has been widely applied in the stock market to identify the trends and patterns among the financial time series data. Go and Hong [46] used the DNN method to predict the stock value. They first trained the method by the time series data and then tested and confirmed their model's predictability. Song et al. [49] developed DNN using 715 novel input-features to forecast the stock price fluctuation. They also compared the performance of their model with the other models that include simple price-based input-features. For predicting the stock market behavior, Chong, Han, and Park [63] examined the performance of DNN. They consider high-frequency intraday stock returns as the input in their model. They analyzed the predictability of principal component analysis (PCA), autoencoder, and RBM. According to their results, DNN has good predictability with the information they receive from the autoregressive mode residuals. Although applying the autoregressive model to the network's residuals may not contribute to the model's predictability. , Chong et al. [63] found out applying covariance-based market structure analysis to the predictive network remarkably increases the covariance estimation. Das et al. [60] used DNN to predict the future trends of the S&P 500 Index. Their results show that their model can poorly forecast the underlying stocks' behavior in the S&P 500 index. They believe that randomness and non-stationarity are the reasons that make hard the predictability of this index.
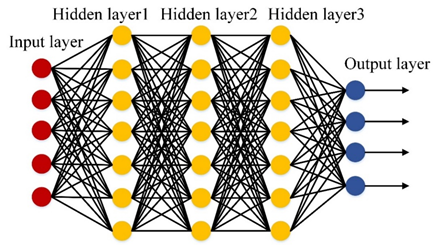
Figure 5. Structure of the deep neural network.
In addition, hybrid methods that are constructed based on DNN have been reported to be very accurate in the financial time series data. For example, Das and Mishra proposed an advanced model to plan, analyze, and predict the stock value, using a multilayer deep neural network (MDNN) optimized by Adam optimizer (AO) to find the patterns among the stock values. Moews et al. proposed a method to predict the stock market's behavior, as a complex system with a massive number of noisy time series. Their model integrates DNN and stepwise linear regressions (SLR). Moews et al. considered regression slopes as trend strength indicators for a given time interval. To predict the Google stock price, Singh and Srivastava compared two integrated models, i.e., 2-directional 2-dimensional principal component analysis-DNN ((2D)2PCA-DNN) and (2D)2PCA-radial basis function neural network (RBFNN). According to their results, the (2D) 2PCA-DNN model has higher accuracy in predicting the stock price. They also compared their results with the RNN model and reported that the predictability of (2D)2PCA-DNN outperforms RNN as well.
CNN
Convolutional neural network (CNN) is one of the most popular methods in deep learning and is widely applied in various fields [70][71][72], such as classification, language processing, and object detection. A classical CNN structure is presented in Figure 6, adapted from [73], which mainly consists of three components, i.e., convolution layers, pooling layers, and fully connected layers. Different layers have different roles in the training process and are discussed in more detail below:
Convolutional layer: This layer is composed of a set of trainable filters, which are used to perform feature extraction. Suppose is the input data and there are filters in convolutional layers, then the output of the convolutional layer can be determined as follows:
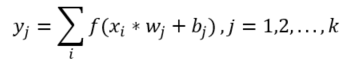
where and are the weight and bias, respectively; and denotes an activation function. represents the convolution operation.
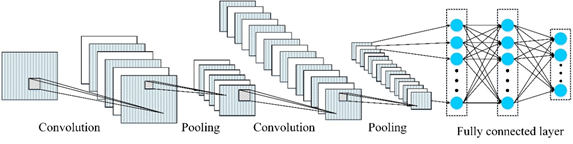
Figure 6. Structure of the convolutional neural network (CNN).
Pooling layer: In general, this layer is used to decrease the obtained feature data and network parameters' dimensions. Currently, max pooling and average pooling are the most widely used methods. Let be a window size, then the average pooling operation can be expressed as follows:
|
|
|
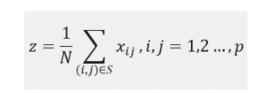
where indicates the activation value at ; and is the total number of elements in .
Fully connected layer: Following the last pooling layer, the fully connected layer is utilized to reshape the feature maps into a 1-D feature vector, which can be expressed as
|
|
|
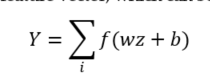
where and denote the output vector and input features; and and represent the weight and bias of the fully connected layer, respectively.
Recently, many researchers have extensively applied CNN for predicting stock values using financial time series data. Sim et al. developed a model to predict the stock price by adapting CNN. Their results reveal that CNN's predictive performance demonstrated a better performance in forecasting stock price than ANN and SVM. Tashiro et al. first criticized the current models for the price prediction in the stock markets in that the properties of market orders are ignored. Therefore, they constructed a CNN architecture integrating order-based features to predict the stock markets' mid-price trends. Their results prove that adding the features of orders to the model increased its accuracy. Dingli and Fournier applied CNN to predict the future movement of stock prices and found that the predictive accuracy of their model was 65% in predicting the following month’s price and was 60% for the following week’s price. Gonçalves et al. compared the results of the prediction of CNN, LSTM, and deep neural network classifier (DNNC) for finding the best model to predict the price trends in the exchange markets. Their findings reveal that CNN, on average, has the best predictive power. Sohangir et al. compared the performance of several neural network models, including CNN, LSTM, and doc2vec, for sentiment analysis among the experts' posts and opinions in StockTwits to predict the movements in the stock markets. Their results disclose that CNN has the highest accuracy in predicting the sentiment of experts.
To increase CNN's accuracy, some researchers integrated CNN with other models and proposed new hybrid models. For example, by integrating gated recurrent unit (GRU) and CNN, Sabeena et al. introduced a hybrid DL model to predict financial fluctuations in the real-time stock market that is able to process the real-time data from online financial sites. GRUs are developed based on the RNN architectures. They represent a simpler implementation for LSTMs to address gradient functions and learn long-range dependencies. To predict the price movement from financial time series samples, Long et al. introduced an end-to-end model called multi-filters neural network (MFNN) that incorporates CNN and recurrent neural network (RNN).
Other Algorithms
In addition to LSTM, DNN, and CNN, other DS methods have been employed for predicting stock value using time series data. For example, Sirignano and Cont developed an LSDL model to study the USA market quotes and transactions. Their results disclose that there is a universal and stationary relationship between order flow history and price trends. Kim et al. proposed a multi-agent collaborated network (MACN) model to optimize financial time series data, claiming that their model can share and generalize agents' experience in stock trading.
In addition, various other hybrid methods have been applied by the researchers for financial time series data. For instance, to predict the stock price trends, Lien Minh et al. developed and trained a two-stream GRU (TS-GRU) network and Stock2Vec model to analyze the sentiments in the financial news and their relationship with the financial prices, based on their belief that financial news and sentiment dictionaries affect the stock prices. Their findings support the outperformance of their model in comparison with the current models. Lien Minh et al. also claim that Stock2Vec is highly efficient in financial datasets. Lei et al. combined deep learning models and reinforcement learning models to develop a time-driven feature-aware (TDFA) jointly deep reinforcement learning model (TFJ-DRL) for financial time-series forecasting in algorithmic trading. Preeti et al. introduced an extreme learning machine (ELM)-auto-encoder (AE) model to identify patterns in the financial time series. They tested the accuracy of their model in the time series data of gold price and crude oil price and compared their results with those of generalized autoregressive conditional heteroskedasticity (GARCH), GRNN, MLP, RF, and group method of data handling (GRDH). The result of the mean square error (MSE) test proved that the performance of their model was higher than the existing methods.
In addition to the hybrid deep learning models, four articles applied hybrid machine learning models to financial time series data. Shekhar and Varshney integrated a hybrid model of genetic algorithm-SVM (GV-SVM) with sentiment analysis to predict the future of the stock market. Using quantitative empirical analysis, they proved that the combination of sentiment analysis with GV-SVM increased the model's accuracy by 18.6% and reported the final model’s accuracy of about 89.93%. Ahmadi et al. compared the performance of two hybrid machine learning models in predicting the timing of the stock markets, using imperialist competition algorithm-SVM (ICA- SVM), and SVM-GA. Their results exposed that SVM-ICA has a higher performance compared with SVM-GA in the prediction of stock market trends for periods of 1–6 days. To predict stock prices using financial time series data, Ebadati and Mortazavi applied a hybrid model by integrating GA-ANN, where GA was employed to select ANN features and optimize parameters. Their study suggests that this hybrid machine learning model has an improved sum square error (SSE) (i.e., performance accuracy) by 99.99% and improved time (i.e., speed accuracy) by 90.66%. Johari et al. compared the accuracy and performance of GARCH-SVM and GARCH-ANN models in the financial time series data for stock price forecasting. They found that GARCH-SVM outperformed GARCH-ANN, SVM, ANN, and GARCH based on MSE and RMSE accuracy metrics.
Rajesh et al. used ensemble learning to predict future stock trends by applying heat maps and ensemble learning to the top 500 companies' financial data in the S&P stock exchange. Their results show that the combination of RF, SVM, and K-neighbors classifiers had the most accurate results, and the accuracy of the proposed model was 23% higher than a single classifier labeling prediction model. Weng et al. aimed to design a financial expert system to forecast short-term stock prices. For data analysis and predicting stock prices, they employed four machine learning ensemble methods, namely neural network regression ensemble (NNRE), support vector regression ensemble (SVRE), boosted regression tree, and random forest regression (RFR). Using Citi Group stock ($C) data, they were able to forecast the one-day ahead price of 19 stocks from different industries. Weng et al. claim that the boosted regression tree (BRT) outperformed other ensemble models with a considerably better mean absolute percent error (MAPE) than those reported in the literature. Faghihi-Nezhad and Minaei-Bidgoli employed ensemble learning and ANN to develop a two-stage model to predict the stock price. They first predicted the next price movement's direction and then created a new training dataset to forecast the stock price. They used a genetic algorithm (GA) optimization and particle swarm optimization (PSO) to optimize the results of each stage. The results ultimately reveal that the accuracy of their model in prediction of stock price outperformed other models in the literature.
Reviewing the articles categorized in the stock market category reveals that, although the articles' research objectives are different, most utilized financial time-series data (35 out of 37 articles). Only two articles used financial news and social media as the data source to determine future trends in the stock market (see Table 3).
Table 3. Classification of articles using data science by research purpose and data source in the stock market section.
|
Research Objective |
Data Source |
Number of Documents |
|
Stock Price Prediction |
Financial Time Series |
29 |
|
Sentiment Analysis |
Financial News, Social Media |
2 |
|
Portfolio management |
Financial Time Series |
1 |
|
Algorithmic trading |
Financial Time Series |
1 |
|
Socially Responsible Investment Portfolios |
Financial Time Series |
1 |
|
Automated Stock Trading |
Financial Time Series |
1 |
|
The S&P 500 Index Trend Prediction |
Financial Time Series |
1 |
|
Exchange-trade-fund (EFT) Options Prices Prediction |
Financial Time Series |
1 |
2.1.2. Marketing
Studying the purpose of the articles discloses that DS algorithms were mostly used for the purpose of studying customer behavior and promotional activities, which is why these articles are classified in group labeled marketing. As seen in Table 4, two studies applied a single DL method, and three used hybrid DL methods. In addition, these studies used various data sources, such as customer time series data, case studies, and social media. For example, Paolanti et al. [74] employed deep convolutional neural network (DCNN) to develop a mobile robot, so-called ROCKy, to analyze real-time store heat maps of retail store shelves for detection of the shelf-out-of-stock (SOOS) and promotional activities during working hours. Dingli, Marmara, and Fournier [75] investigated solutions to identify the patterns and features among transactional data to predict customer churn within the retail industry. To do so, they compared the performance of CNN and restricted Boltzmann machine (RBM), realizing the RBM outperformed in customer churn prediction.
Table 4. Notable machine learning and deep learning methods in Marketing.
|
Source |
Modeling Methods |
Data Source |
Research Objective |
|
Ładyżyński et al. [76] |
RF–DNN |
Time Series data of Customers |
Customer Behavior |
|
Ullah et al. [77] |
RF |
Time Series data of Customers |
Customer Behavior |
|
Paolanti et al. [74] |
DCNN |
Primary Data |
Detection of Shelf Out of Stock (SOOS) and Promotional Activities |
|
Agarwal [78] |
RNNs-CNNs |
Social media |
Sentiment Analysis |
|
Shamshirband et al. [79] |
SN-CFM |
Social media |
Customer behavior |
|
Dingli et al. [75] |
RBM |
Primary Data |
Customer behavior |
On the other hand, RF-DNN, RNN-CNN, and similarity, neighborhood-based collaborative filtering model (SN-CFM) are hybrid models that researchers used to study customer behavior. Ładyżyński et al. [76], for instance, employed Random Forest (RF) and DNN methods and customers’ historical transactional data to propose a hybrid model that can predict the customers’ willingness to purchase credit products from the banks. Ullah et al. [77] used the RF algorithm to predict churn customers and to formulate strategies for customer relationship management to prevent churners. Ullah et al. [77] explained that a combination of churn classification, utilizing the RF algorithm and customer profiling using k-means clustering, increased their model’s performance. Agarwal [78] integrated RNN and CNN to develop a model for sentiment analysis. According to Agarwal [78], sentiment analysis is the best approach to receive the customers’ feedback. He tested his proposed model using social media data and believes that the result of the sentiment analysis provides guidance to the business to improve the quality of their service and presents evidence for the startups to improve customer experience. Shamshirband et al. [79] proposed SN-CFM to predict consumer preferences according to the similarity of features of users and products that are acquired from the Internet of Things and social networks.
3.1.3. E-Commerce
Another category that emerged after reviewing the articles is labeled e-commerce, where the authors employed data science models to address problems in the e-commerce sector. A summary of these studies is presented in Table 5. Based on the GRU model, Lei [80] designed a neural network investment quality evaluation model to support the decision-making related to investment in e-commerce. Their proposed model is able to evaluate different index data that provides a better picture to investors. Leung et al. [81] argue that the ability to handle orders and logistics management is one of the major challenges in e-commerce. Therefore, using a hybrid autoregressive-adaptive neuro-fuzzy inference system (AR-ANFIS), they developed a prediction model for B2C e-commerce order arrival. According to their results, their proposed hybrid model can successfully forecast e-order arrivals. Cai et al. [82] used deep reinforcement learning to develop an algorithm to address allocating impression problems on e-commerce websites, such as www.taobao.com, www.ebay.com, and www.amazon.com. In this algorithm, the buyers are allocated to the sellers based on the buyer’s impressions and the seller’s strategies in a way that maximizes the income of the platform. To do so, they applied GRU, and their findings show that GRU outperforms the deep deterministic policy gradient (DDPG). Ha, Pyo, and Kim [83] applied RNN to develop a deep categorization network (Deep CN) for item categorization in e-commerce, which refers to classifying the leaf category of items from their metadata. They used RNN to generate features from text metadata and categorize the items accordingly. Xu et al. [84] designed an advanced credit risk evaluation system for e-commerce platforms to minimize the transaction risk associated with buyers and sellers. To this end, they employed a hybrid machine learning model combined with decision tree-ANN (DT-ANN) and found that this model has high accuracy and outperforms other hybrid machine learning models, such as DT-Logistic Regression and DR-dynamic Bayesian network.
Selling products online has unique challenges, for which data science has been able to provide solutions. To increase the buyer's trust in the quality of the products and to buy online, Saravanan and Charanya [85] designed an algorithm where the products are categorized according to several criteria, including reviews and ratings of other users. By integrating a hybrid feature extraction method principle component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) with SVM using lexicon-based method, Saravanan and Charanya [85] also proposed a model that separates the products from the large collection of different products based on characteristics, best product ratings, and positive reviews. Wang, Mo, and Tseng [86] used RNN to develop a personalized product recommendation system on e-commerce websites. The result of their model disclosed the outperformance of RNN to K-nearest neighbors (KNN). Wu and Yan [87] claim that the main assumption of the current production recommender models for e-commerce websites is that all historical data of users are recorded, while in practice, many platforms fail to record such dada. Therefore, they devised a list-wise DNN (LWDNN) to model the temporal online behaviors of users and provide recommendations for anonymous users.
Table 5. Notable machine learning and deep learning methods in e-commerce.
|
Source |
Modeling Methods |
Data Source |
Research Objective |
|
Lei [80] |
GRU |
Financial Time Series |
Investment Quality Evaluation Model |
|
Leung et al. [81] |
AR-ANFIS |
Primary Data |
Order Arrival Prediction |
|
Cai et al. [82] |
GRU |
Customers Time Series |
Impression Allocation Problem |
|
Ha et al. [83] |
RNN |
Primary Data |
Item Categorization |
|
Xu et al. [84] |
DT—ANN |
Credit Data |
Dynamic Credit Risk Evaluation |
|
Saravanan and Charanya [85] |
PCA- t-SNE-SVM |
Primary Data |
Product Recommendation |
|
Wang et al. [86] |
RNN |
Primary Data |
Product Recommendation |
|
Wu and Yan [87] |
LWDNN |
Customers Time Series |
Product Recommendation |
3.1.4. Cryptocurrency
The decision-making process related to investing in the cryptocurrencies is similar to investing in the stock market, where the prediction of future value is very determinant and effective on the investment decisions. Applying machine learning and DL models to predict the trends of cryptocurrency prices is an attractive research problem that is emerging in the literature (see Table 6). For example, Lahmiri and Bekiros [88]applied deep learning methods for the prediction of the price of cryptocurrencies, including Bitcoin, Digital Cash, and Ripple, and compared the predictive performance of LSTM and GRNN. Their findings disclose that the LSTM model has a better performance in comparison with GRNN. Altan, Karasu, and Bekiros [89] claim that integrating LSTM and empirical wavelet transform (EWT) improves the performance of LSTM in forecasting the digital currency price by testing their proposed model using Bitcoin, Ripple, Digital Cash, and Litecoin time series data. Jiang and Liang [90] developed a CNN model to predict the price of Bitcoin as a cryptocurrency example. They train their proposed model using historical data of financial assets prices and used portfolio weights of the set as the output of their model.
Table 6. Notable machine learning and deep learning methods in Cryptocurrency.
|
Source |
Modeling Methods |
Data Source |
Research Objective |
|
Lahmiri and Bekiros [88] |
LSTM comparing with GRNN |
Financial Time Series |
Cryptocurrencies Price prediction |
|
Altana et al. [89] |
LSTM-EWT |
Financial Time Series |
Cryptocurrencies Price prediction |
|
Jiang and Liang [90] |
CNN |
Financial Time Series |
Cryptocurrencies Price prediction |
3.1.5. Corporate Bankruptcy Prediction
Corporate bankruptcy prediction has become an important tool to evaluate the future financial situation of a company. Utilizing machine learning-based methods is widely recommended to address bankruptcy prediction problems. Such as done by Chen, Chen, and Shi [91] , who utilized bagging and boosting ensemble strategies and develop two models of Bagged-proportion support vector machines (pSVM) and boosted-pSVM. Using datasets of UCI and LibSVM, they test their models and explain that ensemble learning strategies increased the performance of the models in bankruptcy prediction. Lin, Lu, and Tsai [92] believe that finding the best match of feature selection and classification techniques improves the prediction performance of bankruptcy prediction models. Their results reveal that the genetic algorithm as the wrapper‐based feature selection method and the combination of the genetic algorithm with the naïve Bayes and support vector machine classifiers had a remarkable predictive performance. Lahmiri et al. [93], to develop an accurate model for forecasting corporate bankruptcy, compare the performance of different ensemble systems of AdaBoost, LogitBoost, RUSBoost, subspace, and bagging. Their finding reveals that the AdaBoost model has been effective in terms of short-time data processing and low classification error, and limited complexity. Faris et al. [94] investigate the combination of re-sampling (oversampling) techniques and multiple features of election methods to improve the accuracy of bankruptcy prediction methods. According to their results, employing SMOTE oversampling technique and AdaBoost ensemble method using reduced error pruning (REP) tree provides reliable promising results to bankruptcy prediction. A summary of these research articles is presented in Table 7.
Table 7. Notable machine learning and deep learning methods in corporate bankruptcy prediction.
|
Source |
Modeling Methods |
Data Source |
Research Objective |
|
Chen et al. [91] |
Bagged-pSVM and Boosted-pSVM |
UCI and LibSVM datasets |
bankruptcy prediction |
|
Lin et al. [92] |
Genetic Algorithm with the Naïve Bayes and SVM classifiers |
Australian credit, German credit, and Taiwan bankruptcy datasets |
bankruptcy prediction |
|
Lahmiri et al. [93] |
AdaBoost |
University of California Irvine (UCI) Machine Learning Repository |
bankruptcy prediction |
|
Faris et al. [94] |
SMOTE-AdaBoost-REP Tree |
Infotel database |
bankruptcy prediction |
References
- Nosratabadi, S.; Mosavi, A.; Keivani, R.; Ardabili, S.; Aram, F. State of the art survey of deep learning and machine learning models for smart cities and urban sustainability. In Proceedings of the International Conference on Global Research and Education; Springer: Cham, Switzerland, 2019; pp. 228–238.
- Mittal, S.; Stoean, C.; Kajdacsy-Balla, A.; Bhargava, R. Digital Assessment of Stained Breast Tissue Images for Comprehensive Tumor and Microenvironment Analysis. Front. Bioeng. Biotechnol. 2019, 7, 246.
- Stoean, R.; Iliescu, D.; Stoean, C. Segmentation of points of interest during fetal cardiac assesment in the first trimester from color Doppler ultrasound. arXiv 2019, arXiv:1909.11903.
- Stoean, R.; Stoean, C.; Samide, A.; Joya, G. Convolutional Neural Network Learning Versus Traditional Segmentation for the Approximation of the Degree of Defective Surface in Titanium for Implantable Medical Devices. In Proceedings of the International Work-Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2019; pp. 871–882.
- Casalino, G.; Castellano, G.; Consiglio, A.; Liguori, M.; Nuzziello, N.; Primiceri, D. A Predictive Model for MicroRNA Expressions in Pediatric Multiple Sclerosis Detection. In Proceedings of the International Conference on Modeling Decisions for Artificial Intelligence; Springer: Cham, Switzerland, 2017; pp. 177–188.
- Ardabili, S.; Mosavi, A.; Várkonyi-Kóczy, A.R. Advances in machine learning modeling reviewing hybrid and ensemble methods. In Proceedings of the International Conference on Global Research and Education; Springer: Cham, Switzerland, 2019; pp. 215–227.
- Nosratabadi, S.; Karoly, S.; Beszedes, B.; Felde, I.; Ardabili, S.; Mosavi, A. Comparative Analysis of ANN-ICA and ANN-GWO for Crop Yield Prediction. 2020 RIVF International Conference on Computing and Communication Technologies (RIVF), Ho Chi Minh, Vietnam 14–15 October 2020, doi: 10.1109/RIVF48685.2020.9140786.
- Torabi, M.; Hashemi, S.; Saybani, M.R.; Shamshirband, S.; Mosavi, A. A Hybrid clustering and classification technique for forecasting short‐term energy consumption. Environ. Prog. Sustain. Energy 2019, 38, 66–76.
- Mosavi, A.; Edalatifar, M. A hybrid neuro-fuzzy algorithm for prediction of reference evapotranspiration. In Proceedings of the International Conference on Global Research and Education; Springer: Cham, Switzerland, 2018; pp. 235–243.
- Mosavi, A.; Shamshirband, S.; Salwana, E.; Chau, K.-w.; Tah, J.H. Prediction of multi-inputs bubble column reactor using a novel hybrid model of computational fluid dynamics and machine learning. Eng. Appl. Comput. Fluid Mech. 2019, 13, 482–492.
- Torabi, M.; Mosavi, A.; Ozturk, P.; Varkonyi-Koczy, A.; Istvan, V. A hybrid machine learning approach for daily prediction of solar radiation. In Proceedings of International Conference on Global Research and Education; Springer: Cham, Switzerland, 2018; pp. 266–274.
- Lee, H.; Li, G.; Rai, A.; Chattopadhyay, A. Real-time anomaly detection framework using a support vector regression for the safety monitoring of commercial aircraft. Adv. Eng. Inf. 2020, 44, doi:10.1016/j.aei.2020.101071.
- Husejinović, A. Credit card fraud detection using naive Bayesian and c4.5 decision tree classifiers. Period. Eng. Nat. Sci. 2020, 8, 1–5.
- Zhang, Y. Application of improved BP neural network based on e-commerce supply chain network data in the forecast of aquatic product export volume. Cogn. Sys. Res. 2019, 57, 228–235, doi:10.1016/j.cogsys.2018.10.025.
- Sundar, G.; Satyanarayana, K. Multi layer feed forward neural network knowledge base to future stock market prediction. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 1061–1075, doi:10.35940/ijitee.K1218.09811S19.
- Hew, J.J.; Leong, L.Y.; Tan, G.W.H.; Ooi, K.B.; Lee, V.H. The age of mobile social commerce: An Artificial Neural Network analysis on its resistances. Technol. Soc. Chang. 2019, 144, 311–324, doi:10.1016/j.techfore.2017.10.007.
- Abdillah, Y.; Suharjito. Failure prediction of e-banking application system using Adaptive Neuro Fuzzy Inference System (ANFIS). Int. J. Electr. Comput. Eng. 2019, 9, 667–675, doi:10.11591/ijece.v9i1.pp.667-675.
- Sabaitytė, J.; Davidavičienė, V.; Straková, J.; Raudeliūnienė, J. Decision tree modelling of E-consumers’ preferences for internet marketing communication tools during browsing. E M Ekon. Manag. 2019, 22, 206–224, doi:10.15240/tul/001/2019-1-014.
- Zatevakhina, A.; Dedyukhina, N.; Klioutchnikov, O. Recommender Systems-The Foundation of an Intelligent Financial Platform: Prospects of Development. In Proceedings of 2019 International Conference on Artificial Intelligence: Applications and Innovations (IC-AIAI), Belgrade, Serbia, 30 September–4 October 2019; pp. 104–1046.
- Benlahbib, A.; Nfaoui, E.H. A hybrid approach for generating reputation based on opinions fusion and sentiment analysis. J. Organ. Comput. Electron. Commer. 2020, 30, 9–27.
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. Iatss Res. 2019.
- Mathis, M.W.; Mathis, A. Deep learning tools for the measurement of animal behavior in neuroscience. Curr. Opin. Neurobiol. 2020, 60, 1–11.
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 2019, 198, 111799.
- Durairaj, M.; Krishna Mohan, B.H. A review of two decades of deep learning hybrids for financial time series prediction. Int. J. Emerg. Technol. 2019, 10, 324–331.
- Guermoui, M.; Melgani, F.; Gairaa, K.; Mekhalfi, M.L. A comprehensive review of hybrid models for solar radiation forecasting. J. Clean. Prod. 2020, 258, 120357.
- Pradeepkumar, D.; Ravi, V. Soft computing hybrids for FOREX rate prediction: A comprehensive review. Comput. Oper. Res. 2018, 99, 262–284.
- Hosni, M.; Abnane, I.; Idri, A.; de Gea, J.M.C.; Alemán, J.L.F. Reviewing ensemble classification methods in breast cancer. Comput. Methods Programs Biomed. 2019, 177, 89–112.
- Song, X.; Jiao, L.; Yang, S.; Zhang, X.; Shang, F. Sparse coding and classifier ensemble based multi-instance learning for image categorization. Signal Process. 2013, 93, 1–11.
- Chung, Y.-W.; Khaki, B.; Li, T.; Chu, C.; Gadh, R. Ensemble machine learning-based algorithm for electric vehicle user behavior prediction. Appl. Energy 2019, 254, 113732.
- AlKandari, M.; Ahmad, I. Solar Power Generation Forecasting Using Ensemble Approach Based on Deep Learning and Statistical Methods. Appl. Comput. Inform. 2020, doi:10.1016/j.aci.2019.11.002
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gøtzsche, P.C.; Ioannidis, J.P.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. J. Clin. Epidemiol. 2009, 62, e1–e34.
- Moon, K.S.; Kim, H. Performance of deep learning in prediction of stock market volatility. Econ. Comput. Econ. Cybern. Stud. Res. 2019, 53, 77–92, doi:10.24818/18423264/53.2.19.05.
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669, doi:10.1016/j.ejor.2017.11.054.
- Tamura, K.; Uenoyama, K.; Iitsuka, S.; Matsuo, Y. Model for evaluation of stock values by ensemble model using deep learning. Trans. Jpn. Soc. Artif. Intell. 2018, 33, doi:10.1527/tjsai.A-H51.
- Wang, W.; Li, W.; Zhang, N.; Liu, K. Portfolio formation with preselection using deep learning from long-term financial data. Expert Syst. Appl. 2020, 143, 113042.
- Fister, D.; Mun, J.C.; Jagric, V.; Jagric, T. Deep learning for stock market trading: A superior trading strategy? Neural Netw. World 2019, 29, 151–171, doi:10.14311/NNW.2019.29.011.
- Stoean, C.; Paja, W.; Stoean, R.; Sandita, A. Deep architectures for long-term stock price prediction with a heuristic-based strategy for trading simulations. PLoS ONE 2019, 14, e0223593.
- Agrawal, M.; Khan, A.U.; Shukla, P.K. Stock price prediction using technical indicators: A predictive model using optimal deep learning. Int. J. Recent Technol. Eng. 2019, 8, 2297–2305, doi:10.35940/ijrteB3048.078219.
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, doi:10.1371/journal.pone.0180944.
- Yan, H.; Ouyang, H. Financial Time Series Prediction Based on Deep Learning. Wirel. Pers. Commun. 2018, 102, 683–700, doi:10.1007/s11277-017-5086-2.
- Vo, N.N.; He, X.; Liu, S.; Xu, G. Deep learning for decision making and the optimization of socially responsible investments and portfolio. Decis. Support Syst. 2019, 124, 113097.
- Fang, Y.; Chen, J.; Xue, Z. Research on quantitative investment strategies based on deep learning. Algorithms 2019, 12, doi:10.3390/a12020035.
- Lei, K.; Zhang, B.; Li, Y.; Yang, M.; Shen, Y. Time-driven feature-aware jointly deep reinforcement learning for financial signal representation and algorithmic trading. Expert Syst. Appl. 2020, 140, doi:10.1016/j.eswa.2019.112872.
- Sabeena, J.; Venkata Subba Reddy, P. A modified deep learning enthused adversarial network model to predict financial fluctuations in stock market. Int. J. Eng. Adv. Technol. 2019, 8, 2996–3000, doi:10.35940/ijeat.F9011.088619.
- Das, S.; Mishra, S. Advanced deep learning framework for stock value prediction. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 2358–2367, doi:10.35940/ijitee.B2453.0881019.
- Go, Y.H.; Hong, J.K. Prediction of stock value using pattern matching algorithm based on deep learning. Int. J. Recent Technol. Eng. 2019, 8, 31–35, doi:10.35940/ijrte.B1007.0782S619.
- Gonçalves, R.; Ribeiro, V.M.; Pereira, F.L.; Rocha, A.P. Deep learning in exchange markets. Inf. Econ. Policy 2019, 47, 38–51, doi:10.1016/j.infoecopol.2019.05.002.
- Moews, B.; Herrmann, J.M.; Ibikunle, G. Lagged correlation-based deep learning for directional trend change prediction in financial time series. Expert Syst. Appl. 2019, 120, 197–206, doi:10.1016/j.eswa.2018.11.027.
- Song, Y.; Lee, J.W.; Lee, J. A study on novel filtering and relationship between input-features and target-vectors in a deep learning model for stock price prediction. Appl. Intell. 2019, 49, 897–911, doi:10.1007/s10489-018-1308-x.
- Long, W.; Lu, Z.; Cui, L. Deep learning-based feature engineering for stock price movement prediction. Knowl. -Based Syst. 2019, 164, 163–173, doi:10.1016/j.knosys.2018.10.034.
- Rajesh, P.; Srinivas, N.; Vamshikrishna Reddy, K.; VamsiPriya, G.; Vakula Dwija, M.; Himaja, D. Stock trend prediction using Ensemble learning techniques in python. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 150–155.
- Sim, H.S.; Kim, H.I.; Ahn, J.J. Is Deep Learning for Image Recognition Applicable to Stock Market Prediction? Complexity 2019, 2019, doi:10.1155/2019/4324878.
- Agrawal, M.; Khan, A.U.; Shukla, P.K. Stock indices price prediction based on technical indicators using deep learning model. Int. J. Emerg. Technol. 2019, 10, 186–194.
- Tashiro, D.; Matsushima, H.; Izumi, K.; Sakaji, H. Encoding of high-frequency order information and prediction of short-term stock price by deep learning. Quant. Financ. 2019, 19, 1499–1506, doi:10.1080/14697688.2019.1622314.
- Sirignano, J.; Cont, R. Universal features of price formation in financial markets: perspectives from deep learning. Quant. Financ. 2019, 19, 1449–1459, doi:10.1080/14697688.2019.1622295.
- Weng, B.; Lu, L.; Wang, X.; Megahed, F.M.; Martinez, W. Predicting short-term stock prices using ensemble methods and online data sources. Expert Syst. Appl. 2018, 112, 258–273.
- Preeti; Dagar, A.; Bala, R.; Singh, R.P. Financial time series forecasting using deep learning network. In Communications in Computer and Information Science; Springer Verlag: Heidelberg, Germany, 2019; Volume 899, pp. 23–33.
- Sohangir, S.; Wang, D.; Pomeranets, A.; Khoshgoftaar, T.M. Big Data: Deep Learning for financial sentiment analysis. J. Big Data 2018, 5, doi:10.1186/s40537-017-0111-6.
- Lien Minh, D.; Sadeghi-Niaraki, A.; Huy, H.D.; Min, K.; Moon, H. Deep learning approach for short-term stock trends prediction based on two-stream gated recurrent unit network. IEEE Access 2018, 6, 55392–55404, doi:10.1109/ACCESS.2018.2868970.
- Das, S.R.; Mokashi, K.; Culkin, R. Are markets truly efficient? Experiments using deep learning algorithms for market movement prediction. Algorithms 2018, 11, doi:10.3390/a11090138.
- Kim, J.J.; Cha, S.H.; Cho, K.H.; Ryu, M. Deep reinforcement learning based multi-agent collaborated network for distributed stock trading. Int. J. Grid Distrib. Comput. 2018, 11, 11–20, doi:10.14257/ijgdc.2018.11.2.02.
- Faghihi-Nezhad, M.-T.; Minaei-Bidgoli, B. Prediction of Stock Market Using an Ensemble Learning-based Intelligent Model. Ind. Eng. Manag. Syst. 2018, 17, 479–496.
- Chong, E.; Han, C.; Park, F.C. Deep learning networks for stock market analysis and prediction: Methodology, data representations, and case studies. Expert Syst. Appl. 2017, 83, 187–205, doi:10.1016/j.eswa.2017.04.030.
- Dingli, A.; Fournier, K.S. Financial time series forecasting—a deep learning approach. Int. J. Mach. Learn. Comput. 2017, 7, 118–122, doi:10.18178/ijmlc.2017.7.5.632.
- Singh, R.; Srivastava, S. Stock prediction using deep learning. Multimed. Tools Appl. 2017, 76, 18569–18584, doi:10.1007/s11042-016-4159-7.
- Shekhar, S.; Varshney, N. A hybrid GA-SVM and sentiment analysis for forecasting stock market movement direction. Test Eng. Manag. 2020, 82, 64–72.
- Ahmadi, E.; Jasemi, M.; Monplaisir, L.; Nabavi, M.A.; Mahmoodi, A.; Amini Jam, P. New efficient hybrid candlestick technical analysis model for stock market timing on the basis of the Support Vector Machine and Heuristic Algorithms of Imperialist Competition and Genetic. Expert Syst. Appl. 2018, 94, 21–31, doi:10.1016/j.eswa.2017.10.023.
- Ebadati, O.M.E.; Mortazavi, M.T. An efficient hybrid machine learning method for time series stock market forecasting. Neural Netw. World 2018, 28, 41–55, doi:10.14311/NNW.2018.28.003.
- Johari, S.N.M.; Farid, F.H.M.; Nasrudin, N.A.E.B.; Bistamam, N.S.L.; Shuhaili, N.S.S.M. Predicting stock market index using hybrid intelligence model. Int. J. Eng. Technol. (UAE) 2018, 7, 36–39, doi:10.14419/ijet.v7i3.15.17403.
- Ghamisi, P.; Höfle, B.; Zhu, X.X. Hyperspectral and LiDAR data fusion using extinction profiles and deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 3011–3024.
- Duan, P.; Kang, X.; Li, S.; Ghamisi, P. Multichannel Pulse-Coupled Neural Network-Based Hyperspectral Image Visualization. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2444–2456.
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709.
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251.
- Paolanti, M.; Romeo, L.; Martini, M.; Mancini, A.; Frontoni, E.; Zingaretti, P. Robotic retail surveying by deep learning visual and textual data. Robot. Auton. Syst. 2019, 118, 179–188, doi:10.1016/j.robot.2019.01.021.
- Dingli, A.; Marmara, V.; Fournier, N.S. Comparison of deep learning algorithms to predict customer churn within a local retail industry. Int. J. Mach. Learn. Comput. 2017, 7, 128–132, doi:10.18178/ijmlc.2017.7.5.634.
- Ładyżyński, P.; Żbikowski, K.; Gawrysiak, P. Direct marketing campaigns in retail banking with the use of deep learning and random forests. Expert Syst. Appl. 2019, 134, 28–35, doi:10.1016/j.eswa.2019.05.020.
- Ullah, I.; Raza, B.; Malik, A.K.; Imran, M.; Islam, S.U.; Kim, S.W. A churn prediction model using random forest: analysis of machine learning techniques for churn prediction and factor identification in telecom sector. IEEE Access 2019, 7, 60134–60149.
- Agarwal, S. Deep Learning-based Sentiment Analysis: Establishing Customer Dimension as the Lifeblood of Business Management. Glob. Bus. Rev. 2019, doi:10.1177/0972150919845160.
- Shamshirband, S.; Khader, J.; Gani, S. Predicting consumer preferences in electronic market based on IoT and Social Networks using deep learning based collaborative filtering techniques. Electron. Commer. Res. 2019, doi:10.1007/s10660-019-09377-0.
- Lei, Z. Research and analysis of deep learning algorithms for investment decision support model in electronic commerce. Electron. Commer. Res. 2019, doi:10.1007/s10660-019-09389-w.
- Leung, K.H.; Choy, K.L.; Ho, G.T.S.; Lee, C.K.M.; Lam, H.Y.; Luk, C.C. Prediction of B2C e-commerce order arrival using hybrid autoregressive-adaptive neuro-fuzzy inference system (AR-ANFIS) for managing fluctuation of throughput in e-fulfilment centres. Expert Syst. Appl. 2019, 134, 304–324, doi:10.1016/j.eswa.2019.05.027.
- Cai, Q.; Filos-Ratsikas, A.; Tang, P.; Zhang, Y. Reinforcement Mechanism Design for e-commerce. In Proceedings of the 2018 World Wide Web Conference, 23–27 April 2018; pp. 1339–1348.
- Ha, J.-W.; Pyo, H.; Kim, J. Large-scale item categorization in e-commerce using multiple recurrent neural networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 13 August 2016; pp. 107–115.
- Xu, Y.Z.; Zhang, J.L.; Hua, Y.; Wang, L.Y. Dynamic credit risk evaluation method for e-commerce sellers based on a hybrid artificial intelligence model. Sustainability (Switz.) 2019, 11, doi:10.3390/su11195521.
- Saravanan, V.; Sathya Charanya, C. E-commerce product classification using lexical based hybrid feature extraction and SVM. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 1885–1891, doi:10.35940/ijitee.L3608.119119.
- Wang, Y.; Mo, D.Y.; Tseng, M.M. Mapping customer needs to design parameters in the front end of product design by applying deep learning. CIRP Ann. 2018, 67, 145–148.
- Wu, C.; Yan, M. Session-aware information embedding for e-commerce product recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, Singapore, 19 Jul 2017; pp. 2379–2382.
- Lahmiri, S.; Bekiros, S. Cryptocurrency forecasting with deep learning chaotic neural networks. Chaos Solitons Fractals 2019, 118, 35–40, doi:10.1016/j.chaos.2018.11.014.
- Altan, A.; Karasu, S.; Bekiros, S. Digital currency forecasting with chaotic meta-heuristic bio-inspired signal processing techniques. Chaos Solitons Fractals 2019, 126, 325–336.
- Jiang, Z.; Liang, J. Cryptocurrency portfolio management with deep reinforcement learning. In Proceedings of 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 905–913.
- Chen, Z.; Chen, W.; Shi, Y. Ensemble learning with label proportions for bankruptcy prediction. Expert Syst. Appl. 2020, 146, 113155.
- Lin, W.C.; Lu, Y.H.; Tsai, C.F. Feature selection in single and ensemble learning‐based bankruptcy prediction models. Expert Syst. 2019, 36, e12335.
- Lahmiri, S.; Bekiros, S.; Giakoumelou, A.; Bezzina, F. Performance assessment of ensemble learning systems in financial data classification. Intell. Syst. Account. Financ. Manag. 2020, 1–7, doi:10.1002/isaf.1460.
- Faris, H.; Abukhurma, R.; Almanaseer, W.; Saadeh, M.; Mora, A.M.; Castillo, P.A.; Aljarah, I. Improving financial bankruptcy prediction in a highly imbalanced class distribution using oversampling and ensemble learning: a case from the Spanish market. Prog. Artif. Intell. 2019, 9, 1–23.

