Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Tharangani Rukmali Wimalarathne Perera | -- | 9104 | 2022-09-01 06:14:43 | | | |
| 2 | Vivi Li | + 58 word(s) | 9162 | 2022-09-02 03:16:19 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Perera, T.R.; Skerrett-Byrne, D.A.; Gibb, Z.; Nixon, B.; Swegen, A. Biomarkers in Veterinary Medicine. Encyclopedia. Available online: https://encyclopedia.pub/entry/26771 (accessed on 15 July 2026).
Perera TR, Skerrett-Byrne DA, Gibb Z, Nixon B, Swegen A. Biomarkers in Veterinary Medicine. Encyclopedia. Available at: https://encyclopedia.pub/entry/26771. Accessed July 15, 2026.
Perera, Tharangani R.w, David A. Skerrett-Byrne, Zamira Gibb, Brett Nixon, Aleona Swegen. "Biomarkers in Veterinary Medicine" Encyclopedia, https://encyclopedia.pub/entry/26771 (accessed July 15, 2026).
Perera, T.R., Skerrett-Byrne, D.A., Gibb, Z., Nixon, B., & Swegen, A. (2022, September 01). Biomarkers in Veterinary Medicine. In Encyclopedia. https://encyclopedia.pub/entry/26771
Perera, Tharangani R.w, et al. "Biomarkers in Veterinary Medicine." Encyclopedia. Web. 01 September, 2022.
Copy Citation
New biomarkers promise to transform veterinary practice through rapid diagnosis of diseases, effective monitoring of animal health and improved welfare and production efficiency. However, the road from biomarker discovery to translation is not always straightforward. The use of biomarkers has been identified as an increasing trend in the animal health industry and has been applied to the evaluation of a variety of health parameters. In particular, it is useful in clinical applications such as diagnosing illness, predicting and/or tracking the response to treatment, and determining the toxicity or failure of an organ.
biomarkers
veterinary
proteomics
lipidomics
metabolomics
genomics
transcriptomics
1. Introduction
Veterinary medicine is a fast-growing field and arguably has effectively embraced cutting edge developments arising in other health fields, such as biomedicine. Veterinary professionals hold considerable responsibility for the quick diagnosis, treatment, disease prevention, and nutrition of animals, working towards both enhanced animal welfare and human public health outcomes [1][2]. Only a few decades ago, veterinary disease diagnosis mainly relied on clinical signs, with confirmation via a limited repertoire of laboratory tests and microbiological cultures, with imaging via radiography and ultrasound incorporated more recently. Such confirmatory diagnoses often take several days and may require outsourcing or referral and specialist expertise. This not only delays treatment but in the case of infectious diseases, time to diagnosis is critical as spread of a disease can result in mass culls and huge economic losses, with widespread implications for industry and public health [3]. To address those welfare and economic issues, routine, robust and early diagnostic tests are increasingly being developed and incorporated into practice. Thus, biotechnology is now playing a major role in the veterinary field, with potential applications extending to animal reproduction and the diagnosis and treatment of animal diseases [4]. While the utility of new biotechnologies for veterinary diagnostics is now recognised and there are several examples of successful incorporation into routine practice, there persist numerous challenges in biomarker identification and translation to clinical use.
The origins of the biotechnology field stem from the discovery of microbiology and cellular biology in the twentieth century, including the development of vaccines, sera and antibiotics, as well as selective breeding and cross-breeding of plants and animals. At this time, the detection of pathogens also became possible, mainly based on microbial culture methods, biochemical tests, and microscopy. These methods can be time consuming and require specific equipment and expertise, driving a need for rapid, accurate and sensitive diagnostic tests to detect disease pathogens [1][4]. More recently, with the development of molecular biology, the realm of biotechnology has expanded greatly to include DNA manipulation, gene engineering [5] and a host of research, agricultural and medical applications. A major milestone was the sequencing of the human genome. Along with ongoing characterisation of genomes of other species, this has facilitated an era of biotechnology where mass spectrometry (MS)-driven “omics” platforms—proteomics, lipidomics, metabolomics, transcriptomics, epigenomics and genomics—allow the generation of extensive datasets in almost any tissue, cell or species [6]. These new technologies are continuously improving in capability and becoming more accessible, revealing vast amounts of information about the molecular properties of biological systems [4][6].
The use of biomarkers has been identified as an increasing trend in the animal health industry and has been applied to the evaluation of a variety of health parameters. In particular, it is useful in clinical applications such as diagnosing illness, predicting and/or tracking the response to treatment, and determining the toxicity or failure of an organ. The term biological marker first appeared in the literature in the late 1960s [7]; the term “biomarker” is a shortened version that became more commonly used by the 1990s, albeit in various and often inconsistent ways [8]. Though there are several definitions for the term “biomarker” in human medicine [7][9][10][11], the most relevant and applicable to veterinary medicine is the BEST glossary broadened definition of biomarkers and related terms by the animal health industry [8]. The definition is “A defining characteristic that is measured as an indicator of normal biological processes, pathogenic processes, or biological responses to an exposure or intervention, including therapeutic interventions”. This definition classifies biomarkers into types as “molecular, histologic, radiographic, or physiologic characteristics”. Further, seven categories of biomarkers are proposed: susceptibility/risk biomarker, diagnostic biomarker, monitoring biomarker, prognostic biomarker, predictive biomarker, pharmacodynamic/response biomarker, and safety biomarker [12]. In this entry, researchers focus on molecular biomarkers, and in particular, the role of emerging technological platforms in biomarker discovery and translation.
Opportunities to develop new biomarkers can arise in different ways; for example, a planned search for a biomarker for a specific disease, a chance finding of a marker (protein, lipid, metabolite, etc.) that could be used as the target for a new biomarker test, or a comparison to existing biomarkers in human medicine [13][14]. Many of the biomarkers typically included in standard haematology and biochemistry profiles have been known for many years and were adapted from human medicine [15][16][17]; the same applies for many of the more recent additions to molecular diagnostics, as discussed later in this entry. With the advent of new technologies, it is now possible to conduct large-scale studies directed specifically at identifying novel biomarkers capable of predicting or diagnosing a given condition. Currently, biomarker discovery in the veterinary field is increasing, in tune with a new era of precision and high-quality practice in veterinary care. While older biomarkers tend to focus mostly on diagnosing disease processes and organ dysfunction, more recently there is an increasing trend in identifying markers for survival and response to treatment [8]. This is critical in cases where a disease or outcome is relatively uncommon but poses a significant medical challenge because there is currently no method for early detection of those diseases, and they are typically not diagnosed until patients have progressed to the symptomatic stage, which reduces the chances of survival and reduces treatment efficacy [18]. Beyond pathological conditions, this also applies to other biological processes of importance in animal management, reproduction, and husbandry, all of which contribute to good animal welfare and public health. Therefore, researchers consider it is important to examine the process of biomarker invention.
According to the review of Myers et al. [8], the most successful biomarker research process involves first clearly identifying the clinical utility and target population, then working backward and again forward in sequential steps to select and validate the putative biomarker(s) along with the related analytical procedure(s). The flowchart given in Figure 1, illustrates the steps involved in this process. Specifically in the veterinary field, new diagnostic biomarkers are being developed for the early detection of disease, when it may be reversible or more easily managed, and susceptibility/risk biomarkers are being developed to identify animals with increased resistance or susceptibility to disease [8]. To develop these tests, blood, and body fluids such as urine, saliva, endometrial fluids are utilised most often. As technological capabilities expand, molecular markers within individual cells are also becoming feasible. When challenged with a particular biological change or disease, somatic cells secrete specific substances to the extracellular tissue or body fluids. As such, changes in the concentration of the substance of interest can be measured from those samples. Blood plasma tends to contain transudates from almost all kinds of tissue as it circulates the entire organism and can be easily collected from the patient. For these reasons, easily and routinely obtained samples from the patients such as blood plasma and serum are most commonly used for diagnostic purposes [19][20][21].
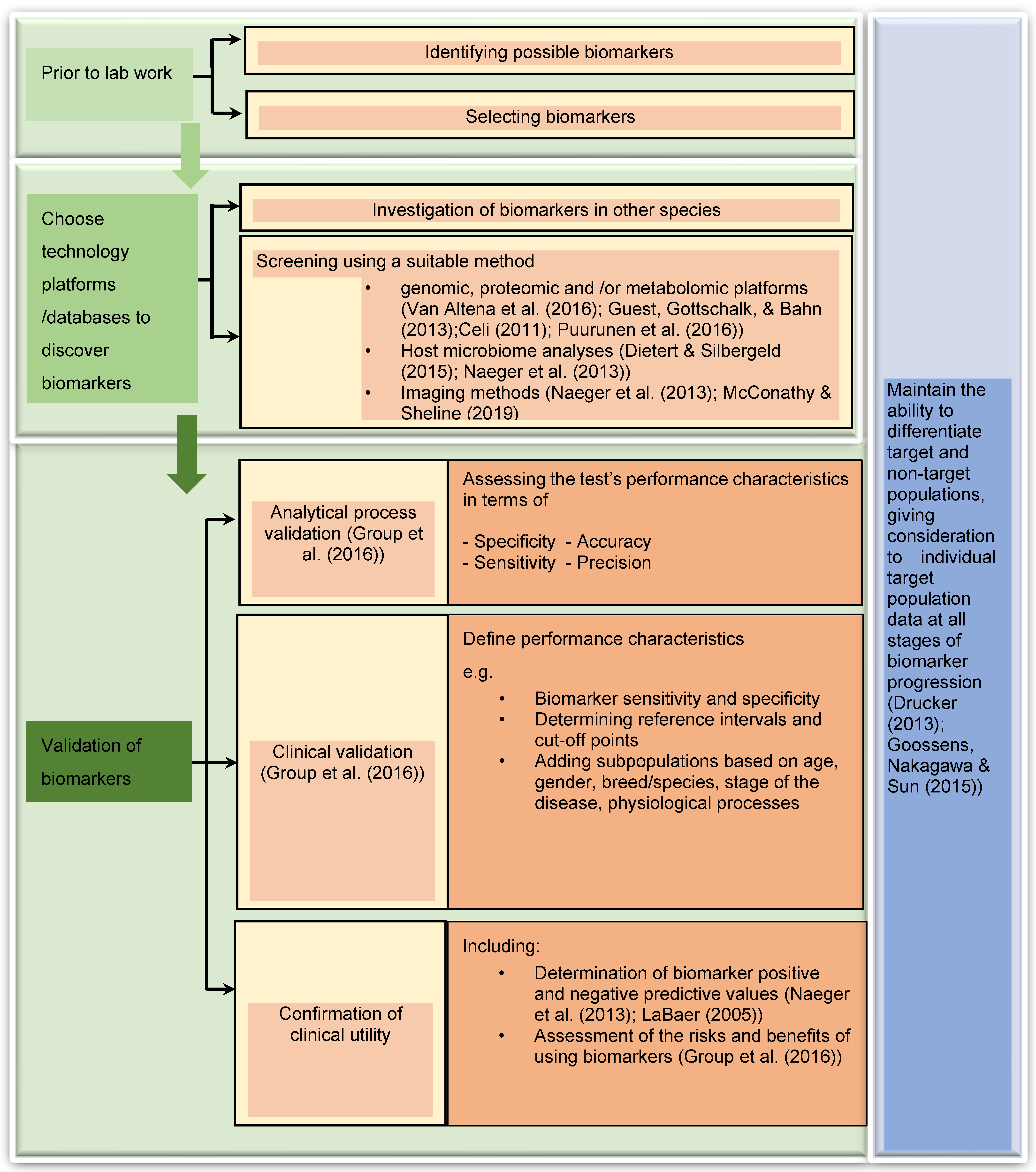
Figure 1. Visual summary of proposed workflow for effective biomarker discovery and validation as discussed in this entry [10][22][23][24][25][26][27][28][29][30][31][32].
2. The Omics Platforms and Their Role in Biomarker Discovery
2.1. Genomics
Although many factors influence one’s health and sickness, it is apparent that genetic heritage is a significant contributor. Examining this genetic background is crucial for discovering particular mutations and/or variations that underpin pathways that differentiate between health and sickness [6][33]. Further, both illness risk and treatment response are influenced by genetic variation. Genome-wide association studies have enabled the identification of genetic variants that contribute to the pathophysiology of complex genetic diseases [34], as well as the detection of several pharmacogenetic markers [35][36]. A genome-wide association study (GWA study, or GWAS), also known as whole genome association study (WGA study, or WGAS), is an observational study of a genome-wide set of genetic variants in different individuals to detect if any variant is associated with a trait of interest.
DNA biomarker tests, for example, can be used to decide if treatment can be safely postponed for a time of watchful waiting in the case of prostate cancer. If the tumour is found to be devoid of genes that cause an aggressive form of cancer, it may remain stable for decades, obviating the need for major surgical removal followed by radiotherapy or chemotherapy. Genetic profiles, on the other hand, may also be utilised to determine preventive treatments [37]. Individual genetic testing is used to decide on specific, sometimes extremely radical interventions such as prophylactic surgery in some cases of hereditary cancer [37]. Biomarker based on DNA Single Nucleotide Polymorphism (SNPs), Short Tandem Repeats (STRs), deletions, insertions, and other DNA sequence variations are examples of germline biomarkers. Compared to expression-based indicators, DNA methylation biomarkers have numerous important advantages. For example, even if changes are present in a small number of cells, they are easily amplifiable and detectable using polymerase chain reaction (PCR)-based techniques [38]. DNA methylation is a highly stable marker that may be identified in a wide range of minimally invasive materials, including saliva, plasma, serum, urine, sperm, and faeces [39]. Many DNA biomarkers for cancer in human medicine are now commonly used in commercial test kits, highlighting their successful application after initial identification as biomarkers [40][41]; e.g., VIM gene (vimentin) is used for diagnosis of colorectal cancer in a commercially available kit known as “Cologuard” and marketed by Exact Sciences [42].
According to a review of the literature by Myers, Smith and Turfle [8], the most recent significant advances in disease susceptibility/risk, diagnostic, and prognostic biomarkers for veterinary clinical medicine have occurred in the areas of genomic markers of disease resistance or susceptibility, as well as diagnostic, prognostic, and monitoring biomarkers for kidney disease, cardiovascular disease, stem cell biology [43], and cancer. The genome sequencing of domestic animals, such as the horse, cow, dog, and cat has aided rapid progress in the identification of the genetic basis for disease susceptibility and resistance [8]. Disease genetic markers are fast being identified, and genetic testing for determining disease risk in both companion and livestock species is becoming available. The discovery of genetic markers linked to the development of mast cell malignancies in golden retrievers [44], dilated cardiomyopathy in Doberman pinschers [45], lavender foal syndrome in Arabian foals [46], and cholesterol insufficiency in Holstein cattle serve as a few recent examples [47].
The availability of tests to discover genetic biomarkers of disease has the potential to improve the health of companion and livestock animals and influence breeding decisions, as well as contribute to a better knowledge of diseases that affect humans [48]. For livestock species, genetic indicators of immune system function and infectious disease susceptibility are being created, which should improve animal health and potentially reduce dependency on some therapeutic medications, such as antimicrobials [49]. In the United States, progress has been made in identifying genetic biomarkers of vulnerability to bovine respiratory illness, one of the most frequent (and possibly fatal) infectious diseases in cattle [50].
DNA sequencing technologies are well-established meaning that genetic biomarkers benefit from a straight-forward validation process and relatively low costs of assay development once a suitable biomarker has been identified. Requirements for sample drawing, handling, and storage are minimal, and equipment for testing tends to be widely available. On the other hand, genetic biomarkers are mostly limited to screening tests and general predictions about disease susceptibility rather than more specific clinical endpoints and cannot be used in more dynamic situations since they are limited to examining the animal’s static genetic code. Thus, biomarkers emanating from the newer ‘omics platforms have greater scope for generating an accurate and specific profile of health or disease. Nevertheless, continued evolution in the sensitivity and depth of sequencing technologies and ongoing investment into GWAS will undoubtedly continue to generate efficient genetic tests to improve animal welfare, particularly at the population level.
2.2. Transcriptomics
The transcriptome lies immediately downstream of the genetic code and captures a more responsive state than does DNA sequencing, by providing a profile of genes being actively transcribed and regulated at a given timepoint. The transcriptome consists of all the total complements of ribonucleic acid (RNA) transcripts in a cell, tissue or body fluid [6], comprising both coding and non-coding RNAs. Of total RNAs, coding transcripts (messenger RNA; mRNA) comprise 1–4% while non-coding transcripts make up the remaining >95% and include ribosomal RNA, transfer RNA, small nuclear RNA, small interfering RNA, microRNA and long-non-coding RNA [14][32][33]. RNA reflects cellular states by delivering genetic information and regulatory information by transcriptional and post-transcriptional regulation [51][52]. Rapid advances in RNA biomarker research have led to creation of a significant variety of high-performance RNA-detection technologies in recent years [53]. Molecular biology techniques such as quantitative reverse transcription polymerase chain reaction (RT-qPCR) [54][55], microarrays [56], and RNA sequencing [57] are the methods used in these technologies. Next-generation sequencing technology has recently made it possible to quantify RNA expression levels at the full genome level. Increasing the depth of RNA sequencing now facilitates the detection of novel transcripts, such as lowly expressed noncoding RNAs, and their modest expression fluctuations, with high accuracy [58][59]. RNA biosensors, micro- and nanofabrication technologies, and diverse readout techniques, such as electrochemical and optical transducers, have all received a lot of interest in recent years [53].
The first well-studied type of RNA as biomarker is mRNA [60]. The study of mRNAs provides direct insight into the gene expression characteristics of individual cells and tissues. It allows the measurement of the presence/absence and quantification of a transcript, assessment or prediction of protein isoforms and quantitative assessment of genotype influence on gene expression using expression quantitative trait loci analyses (eQTL) or allele-specific expression [6]. Accumulating data based on high-throughput sequencing technology shows that diverse RNA molecules can serve as biomarkers for the diagnosis and prognosis of various diseases, such as cancer [53]. Many cancer studies have explored multi-gene expression patterns as a biomarker for clinical outcome [61]. PAM50, for example, is a 50-gene panel that has been successfully used to classify breast cancer [62]. Another expression panel of 31 mRNAs linked to cell cycle progression was employed as a prognostic marker to predict prostate cancer metastasis, recurrence, and risk [63].
In addition to mRNA, certain miRNAs play critical roles in cell proliferation, differentiation, and death, and hence act as tumour suppressors or oncogenes [64]. It has been observed that miRNA expression profiles can successfully distinguish poorly differentiated tumour types [65]. Furthermore, reduced miR-21 expression was linked to a lower hazard risk in individuals with pancreatic ductal adenocarcinoma after adjuvant therapy. Moreover, miR-21 has been identified as a possible therapeutic target. Extracellular RNAs (exRNAs) are emerging as non-invasive biomarkers for earlier cancer diagnosis, tumour progression monitoring, and therapeutic response prediction, as they are detectable in diverse bio-fluids such as serum, saliva, and urine [66].
RNA biomarkers are also valuable in distinguishing various diseases in veterinary medicine. Dirksen, et al. [67] showed the ability to distinguish between parenchymal, biliary, and neoplastic hepatobiliary diseases using a panel of microRNA consisting of miR-21, miR-122, miR-126, miR-200c, and miR-222. Lecchi, et al. [68] have identified miRNAs can serve as potential biomarkers for Brucella infection in water buffaloes (Bubalus bubalis). The identified miRNAs were involved in regulating the transcription of genes related to the molecular pathogenesis of brucellosis. Further, they have identified miR-let-7f, miR-151, miR-30e, miR-191, miR-150 and miR-339b extracted from vaginal fluids, which are potentially useful biomarkers of Brucella infection. miRNAs also appear to be a very useful tool in identifying different disease conditions such as osteochondrosis, rhabdomyolysis, insulin resistance and osteoarthritis [69][70][71] according to the functional role of the identified miRNAs in corresponding healthy tissues in horses [72][73].
In contrast to genome sequencing technology, accurate determination of RNA levels often requires some form of amplification, a time-consuming sample pre-treatment procedure, and the associated expense of appropriate equipment. Working with RNA is more demanding due to its chemical instability, with the geometry of the molecule as a single stranded polynucleotide being very susceptible to degradation reactions. Therefore, RNA can easily be affected by oxidation and spontaneous changes of phosphodiester linkage through transesterification. Special precautions must be taken when working with RNA to address the high risk of contamination such as the ubiquitous presence of RNases [74]. Furthermore, because oligo(dT) primers are used for amplification, they frequently cannot amplify RNA sequences without a poly(A) tail [75]. Moreover, to prevent sample heterogeneity caused by physiological and systemic changes in clinical samples, very high sample volumes are required for sensing RNA biomarkers in body fluids [76]. The storage of the samples is generally done at −20 °C, −80 °C or under liquid nitrogen, thus requiring more sophisticated facilities for storage, transport and processing of samples [74]. Several nanotechnology-based RNA sensing systems linked with optical and electrochemical readouts have been developed as a result of extensive study to uncover relatively robust, accurate, and effective methodologies. These methods provide simple sampling processes, quick and cost-effective analysis, portability, label-free and amplification-free choices, and portability [77][78][79]. Electrochemical approaches, for example, have demonstrated ultra-high sensitivity and selectivity, as well as a high potential for multiplexed analysis in a point-of-care platform [80][81]. However, the functioning of electrochemical RNA sensors is still limited to proof-of-concept research, and various obstacles must be overcome before these technologies may be used in typical clinical settings [53][75].
Although serum circulating RNAs are considered some of the most promising clinical diagnostic or therapeutic biomarkers in both humans and animals, their diagnostic potential in veterinary medicine remains to be fully explored [68]. Many of these studies provided new and important insights into disease pathogenesis and further experiments involving more animals are required to validate the potential use of RNAs in clinical diagnostics.
2.3. Proteomics
Proteins are the ultimate endpoint of transcription and translation of the genetic code and are the workhorses of cells and tissues as they are responsible for carrying out the biochemical and metabolic functions required for survival and homeostasis. This includes the response to disease and various physiological states. A remarkably useful feature of this biological cascade is that each protein is directly encoded by a corresponding gene and can thus be unambiguously traced to a unique identifier based on its amino acid sequence. Proteomic technologies, i.e., mass spectrometry (MS) and its adjuncts, take advantage of this feature to generate profiles of hundreds to thousands of proteins reflective of specific cells, tissues, fluids or biological states, known as proteomes. Many animal researchers [82][83][84][85] are now exploiting the advances in proteomics [86][87] and directing its use to biomarker discovery in the future. Being the phenotypic endpoint of any given biological process, proteomes not only reveal mechanistic information about how biological responses operate but also reveal high resolution, detectable differences that can be used as specific biomarkers or treatment targets [88].
In proteomics, quadrupole mass spectrometry is most commonly used in conjunction with time-of-flight (TOF) or Orbitrap analysers. Proteome identification and quantification, protein–protein interactions (interactomics), organellar proteomics, post-translational modification detection, and many more applications have now become possible with advances in MS. Accordingly, this field is now well positioned to contribute significantly to translational medicine, notably in the identification and routine use of biomarkers. Although MS-based proteomics is more sophisticated than antibody-based techniques, it exhibits exceptional specificity of detection, and allows large scale screening and hypothesis-free exploration to identify novel biomarkers. Meanwhile, antibody techniques remain most accessible when seeking to detect a specific protein already identified as a biomarker or protein of interest. The sensitivity of MS processes has improved dramatically, allowing single-cell proteomics to become a reality. Proteomics has the extra benefit of allowing researchers to study single cells while keeping the full spatial information of the cellular environment. Furthermore, when compared to their equivalent mRNAs, there are far more protein copies, making single-cell proteomics intrinsically more robust. Intercellular dynamics such as receptor–ligand interactions between cells and their surroundings will be immediately revealed by MS-based single-cell proteomics [88]. These techniques of single cell proteomics will lead to identify pathways that are activated in therapy-resistant cells and can provide biomarkers for cancer diagnosis and for determining patient prognosis.
Liquid chromatography and MS- based proteomics approaches are driving the development of novel veterinary biomarkers [89]. Biomarkers linked with canine babesiosis, such as apolipoproteins and vitamin D metabolism-related proteins, have been detected in dogs [90]. These same biomarkers alongside several new possible proteins for treatment monitoring of canine leishmaniosis have been reported in another investigation [91]. These biomarkers would be advantageous in a clinical setting because they are expected to be quicker than the conventional diagnostic methods such as identifying organisms in blood smears; it may also be possible that testing could be conducted in general practice without the need for an expert to identify the organism in the blood smear. Treatment monitoring biomarkers will help the owners to manage animals at home and inform the vet rather than having the animal stay in hospital for monitoring, reducing stress and costs of aftercare. Proteomic studies on feline biomarkers have also been conducted in research on congestive heart failure due to primary cardiomyopathy [92]. The application of proteomics in farm animal health has sparked considerable interest in biomarker research, notably for subclinical but economically important diseases such as bovine mastitis, where an on-farm biomarker test could be quite useful [93]. Tandem Mass Tag (TMT) technology was applied for the first time for protein quantification using saliva to uncover new biomarkers for stress in sheep, revealing six proteins as potential markers, including those associated with hyperglycaemia—an immediate physiological response to stress [94]. In another application of proteomics, the cause of mortality in manatees following two separate mortality episodes was explored using a combination of 2D-DIGE (two-dimensional difference gel electrophoresis) and shot gun proteomics in which isobaric tags for relative and absolute quantification (iTRAQ) LC–MS/MS were used; with both techniques yielding similar results including an increased quantity of complement C4 protein, which was subsequently validated by immunoblotting [95]. To find biomarkers for early and late-stage oral melanoma, benign oral tumours, oral squamous cell carcinoma and periodontitis in dog using saliva, Ploypetch, et al. [96] used MALDI-TOF MS and LC-MS/MS and validated the markers using immunoblot analysis. One of the identified proteins was sentrin-specific protease 7 (SENP7), the expression of which significantly increased in oral squamous cell carcinoma. Expression of TLR4, was also increased in late oral melanoma and oral squamous cell carcinoma, compared with the control group. These studies represent but a few examples of active proteomic research directed toward development of biomarkers with significant welfare and economic impacts in the veterinary field. While the identified protein markers show potential for rapid diagnosis of the respective conditions, they are yet to be developed into clinically useful and commercially available diagnostic assays.
While proteomic platforms such as MS provide unparalleled capacity for discovery and screening, validation still largely relies on antigen detection (immunoassay) techniques. The latter also tend to be most practical in clinical scenarios. As such, numerous immunoassay driven biomarkers have been developed or adapted from human medicine, including for renal disease, cardiovascular disease, and cancer. In veterinary cardiology, for example, for the detection of primary heart disease or myocardial damage secondary to other diseases, N-terminal pro-b-type (or brain) natriuretic peptides, and cardiac troponins have shown diagnostic and prognostic clinical utility across a broad range of animal species [97][98][99][100][101]. Acute phase proteins (APPs) are also becoming more popular as indicators in canine medicine, with Soler, et al. [102] demonstrating this principle with the development and validation of two enzyme linked immunosorbent assay (ELISA) techniques for assessing ITIH4 and haptoglobin (Hp) in dogs.
The most simple and common antigen detection technique is the ELISA [103][104]. One prominent example is the recently developed bovine Pregnancy Associated Glycoproteins (PAG) ELISA to detect pregnancy in cattle. Since the ELISA is more efficient than previously existing Radioimmunoassay (RIA), the practicability of the PAG test was greatly enhanced. Friedrich and Holtz [105] have discovered a competitive double antibody ELISA using a polyclonal anti-PAG-IgG and an anti-rabbit-IgG raised in sheep for coating and application of newly established ELISA to test its suitability for pregnancy detection by measuring PAG in serum or milk. In their study, the ELISA proved to be an adequate and efficient way of measuring PAG in maternal serum or milk and was a useful means of pregnancy detection in cows.
Proteomics is currently at the forefront of biomarker development in both medical and veterinary fields, and benefits from many well-established protein detection methods that can be used downstream of discovery in clinical settings. While many proteins already serve as useful clinical biomarkers, the path from discovery to application is not always straightforward and some of the relevant challenges are discussed in subsequent sections of this entry.
2.4. Metabolomics
The term metabolomics became popular at the end of the 1990s to describe approaches that aim to measure all the low molecular weight metabolites present within a cell, tissue or organism during a genetic modification or physiological stimulus [106][107]. Proton nuclear magnetic resonance (1H NMR) spectroscopy, gas chromatography–mass spectrometry (GC–MS), and liquid chromatography–mass spectrometry (LC–MS) have all been employed in conjunction with pattern recognition algorithms in this process [108]. In less than two decades, proteomics and metabolomics have emerged as the functional continuation of transcriptomics and have progressed swiftly thanks to advances in technology and bioinformatics tools. While the proteome describes the set of enzymes, receptors and other machinery responsible for carrying out biochemical processes, the metabolome depicts the endpoint of those biochemical processes. Importantly, the metabolome may be a more accurate molecular depiction of phenotype and current state of health or function than any genome, transcriptome, or proteome-based biomarker because of its close relationship with phenotype and its real time reflection of the state of health of a patient [109]. Metabolites change faster and more dramatically than do genes or proteins, and those changes may be quantified in absolute terms, but genes and proteins show activity changes in a different way than concentration changes. Further, as metabolites can be assigned to metabolic pathways, their changes can usually be explained physiologically, enhancing their value.
In dairy cattles, biomarkers are being sought for dysfunction in key metabolic phases, for example the ‘transition period’ [110]. This is the period three weeks prior to calving and the three weeks following calving and is associated with major metabolic changes that transition from pregnancy to lactation. A compromised transition period can have significant detrimental impact on both welfare and productivity, while the molecular basis of effective versus compromised adaptation to the metabolic strain of early lactation remains unknown. Several dairy cow investigations have used targeted metabolomics to evaluate the respective changes in blood throughout the transition phase [111][112] in order to understand the pathophysiology and to identify promising biomarkers. Carnitines have been identified as possible biomarkers for metabolic illnesses associated with the transition period [111][113]. Hailemariam, Mandal, Saleem, Dunn, Wishart and Ametaj [111] suggest that the biomarker profiles they found (carnitine (C0), propionyl carnitine (C3), and lysophosphatidylcholine acyl C14:0 (lysoPC a C14:0)), such as any other set of candidate biomarkers, need to be further verified using a much larger cohort of animals to confirm their reliability.
Using non-targeted metabolomics Wu, et al. [114], found leukotriene C4 (LTC4), leukotriene D4 (LTD4), chenodeoxycholate, linoleate, and other metabolites to be significantly different in a Mycoplasma gallisepticum (MG) and Escherichia coli (E.coli) co-infection model in serum. LTC4 in serum has been found as a potential biomarker for identifying poultry respiratory illness. Furthermore, to identify the consequences of co-infection, an arachidonic acid (AA) metabolic network pathway with metabolic products and enzyme genes were created and showed a similar dramatic increase in LTC4 expression, which was linked to varied degrees of infection.
As discussed above, metabolomics is expected to enhance the accuracy of diagnosing the health status of patients by offering up reliable biomarkers. The expansion of the dynamic range of detection of low-abundance metabolites, in conjunction with the advent of artificial intelligence, will eventually pave the way for the detection of metabolic signatures as biomarkers; however, in the near future it is expected that such diagnostics will remain the domain of centralised facilities rather than point-of-care testing.
2.5. Lipidomics
Lipidomics is a discipline concerned with the study of lipids, not only in terms of their structures and transformations, but also in terms of their diversity and activities in relation to cellular, metabolic, and environmental factors that influence living organisms [115]. Lipids represent major components of the cell membrane and are involved in a range of biological processes (organ function, metabolism, inflammation, endocrine signalling, etc.). Therefore, ratios of certain lipid species or classes are likely to be altered in response to pathological conditions and various physiological states, potentially serving as sensitive biomarkers. Indeed, lipids already form a useful component of clinical veterinary pathology, with cholesterol and triglycerides a mainstay of routine biochemistry analyses and extensively characterised for their association with a range of pathological and physiological processes. These lipids are readily measured in serum, plasma or cells using enzymatic reaction kits coupled with spectrophotometric detection. Newer analytical approaches are now allowing much higher resolution detection of lipid species, down to the lipid ion level, thus opening up potential for lipidomic signatures to serve as specific biomarkers.
Traditionally, three defined analytical approaches have been identified in lipidomics: direct infusion shotgun approaches, chromatography-based separation approaches, and imaging mass spectrometry. Within these approaches, the terms “untargeted” and “targeted” also describe how the decided analytical output influences the sample preparation, methodological technique, and data processing. There are also newer categories such as ‘macrolipidome’ and ‘microlipidome’ that refer to the particular lipid classes’ abundance and activity [116].
While the proteomes and transcriptomes of many pathologies and physiological states, tissues, and organs have already been mapped, the field of lipidomics is younger and fundamental descriptive studies to characterise normal lipidomes are currently underway. These will be crucial for providing the foundations and data repositories needed before biomarkers can be sought to differentiate disease states from normal physiology. Nonetheless, altered lipid levels have been identified in numerous diseases in both model animals and humans, e.g., differential fatty acid levels were identified in kidney [117] and liver [118] diseases, with such changes associated with other biochemical indicators. Lipid biomarkers are being sought for a range of veterinary applications, including predictors of wildlife mortality events [119], livestock production efficiency markers [120], early detection of subclinical disease and monitoring of drug toxicities [121].
MRM-profiling has been used to detect changes in the lipid composition of the epidermis in atopic dogs even when the skin seems clinically healthy, and sex is a modifying factor in the lipid profile of canine atopic dermatitis [122]. This entry contributes to a better understanding of epidermal lipid alterations with the development of atopic dermatitis and as the chronic inflammatory process progresses. The high prediction rate for disease development provided by the lipid biomarkers found here by the machine learning technique suggests that they could be used as a molecular evaluation tool for atopic dermatitis diagnosis and monitoring, as well as patient response to treatment.
In milk obtained from cows with subclinical mastitis, untargeted lipidomics analyses revealed 597 lipids to be altered in abundance more than 10-fold versus non-infected samples [123]. Principal component analysis demonstrated distinct clustering based on both lipid class and lipid species between infected and healthy samples, although data are considered preliminary due to small sample size. It is also yet to be determined whether lipidome changes precede infection or are a consequence; nonetheless once identified, such markers could serve to indicate at-risk animals or those requiring further investigation.
Additionally, in cattle, several studies have revealed the potential of specific lipid classes for the identification of peripartal metabolic dysfunction [124][125]. Certain phosphatidylcholines appear to distinguish between healthy cows or those manifesting clinical metabolic disease during the periparturient period [124]. LC-TOF MS lipidomic profiling of plasma from cows affected by hepatic lipidosis (fatty liver disease), which also commonly affects dairy cows in transition from pregnancy to lactation, revealed a distinct plasma lipidomic profile with reduced phosphatidylcholines [126]. Diagnosis of fatty liver disease currently requires confirmation through biopsies to determine the hepatic lipid content, so a plasma biomarker could be extremely useful. Further investigation is needed to identify and validate specific phosphatidylcholines that could serve as a practical diagnostic tool for this disease.
Lipidomic profiling has been applied in the investigation of wildlife mass mortality events; remarkably, adipose tissue collected from Mozambique tilapia (Oreochromis mossambicus) affected by pansteatisis (an environmentally derived inflammatory disease) showed up to a 1000-fold increase in ceramides and correlated with disease severity [119]. This highlights the potential utility of lipidomic biomarkers within biopsy or post-mortem-collected tissue samples in addition to fluids such as plasma.
Untargeted lipidomics has also been successful in profiling the lipids in plasma and urine of cats treated repeatedly with meloxicam, a non-steroidal anti-inflammatory (NSAID), thus identifying putative biomarkers for monitoring the effect of NSAIDs [120]. Here, 6 lipids in plasma and 5 in urine could discriminate meloxicam-treated from saline treated-cats. This work may ultimately lead to feline-specific pre-clinical biomarkers of NSAID-induced toxicity and would assist clinicians make therapeutic decisions according to individual needs, including selecting optimal dose intervals, thus minimizing the risk of adverse effects.
Another preliminary study identified lipidomic signatures that could potentially be used as a proxy for digestive efficiency in chickens, with important potential consequences for livestock production efficiency and economic output in the poultry industry [121]. However, as with many lipidomics studies, the exact chemical nature of the markers remains unconfirmed, and they are yet to be validated in an independent population. Notably, the authors report that the lipidomic investigation was triggered by an observation of differences in serum colouration between the two lines of broilers representing different digestion efficiencies. Indeed, a spectrophotometric analysis showed difference in absorption between 430 nm and 516 nm, corresponding to the signature of orange–red lipophilic pigments. Such observations tentatively promise innovative yet simple downstream applications of lipidomic biomarkers where incidental properties of certain lipid classes may facilitate means of detection that do not rely on the complex analytical methods used to identify the biomarkers in the first place.
In the horse, elevated cyclic phosphatidic acid and diacylglycerol have been detected in surfactant from severely asthmatic horses using shot-gun lipidomics and suggested as useful biomarkers of this important inflammatory condition [127]. Yet again, these data can only be considered preliminary, and it is currently unknown whether the plasma lipidome is similarly altered in affected horses.
Lipid biomarkers have long been a routine component of clinical diagnostics in veterinary medicine, and discovery of new markers via innovative lipidomics platforms is on the horizon. There is clear evidence for the association of specific lipid profiles with disease and physiological states; at present these are yet to be translated into practical and widely used diagnostic biomarkers. The putative lipid biomarkers described here are a long way away from widespread application, limited by the preliminary nature of most datasets, lack of standardisation in the metabolites and diseases studied, and few studies characterising the normal lipid profile in different physiological states and across species. Maturation of the lipidomic platforms, particularly with regard to standardised methods of analysis and interpretation of data, as well as expansion of publicly accessible data repositories, will facilitate efficient translation, as discussed further in this entry.
2.6. Multiomics
A rapidly developing new approach for biomarker discovery is that of using multi modal integration. Omics technologies, as previously described, measure all or nearly all incidences of the targeted molecular environment in the assay, offering comprehensive perspectives of the biological system because they are high-throughput biochemical assays that evaluate molecules of the same type from a biological sample comprehensively and simultaneously. Initially, omics research focused on a single type of assay and produced single-omics results. However, more recently, researchers have designed multi-omics datasets by combining different assays from the same set of samples [128]. Because multi-omics data obtained for the same set of samples can reveal valuable information about the flow of biological information across many levels, it can aid in the understanding of the mechanisms behind the biological state of concern [129]. The advent of numerous new multi-omics projects has been fuelled by the constrained findings of early single-omics studies, such as the Human Genome Project, and the expansion of facilities that offer omics tests as a service. Identifiers from several timepoints in one or more omic types, phenotypic details such as treatment/control labelling, and pertinent clinical characteristics such as age and sex may all be included in multi-omics data. These findings give a comprehensive picture of disease-driven biological pathway dysregulation, as well as early proof for the establishment of new targets or intervention techniques [130].
Multi-omics’ increased potential has been evident for some time, but the challenge of maintaining and integrating such multi-dimensional data remains problematic. For big datasets, data storage, quality control, and statistical analysis are all more difficult, therefore adhering to the FAIR principles is naturally incredibly hard. Furthermore, creating full multi-omics datasets with the same set of omics tests for all research samples is an extensive undertaking. As a result, researchers who want to make use of these datasets’ multiplatform nature frequently have difficulty getting entire data records or finding appropriate multi-omics datasets for their research topics. Additional quality control metrics that analyse the link across datasets should be explored in the case of multi-omics data. These extra quality indicators are important since omics technologies differ in terms of accuracy, technical noise, and signal dynamic range, thus reliable integrative analytic results can only be drawn when quality is similar across platforms [128].
Omics data can be integrated in a variety of ways after pre-processing. Broadly there are two main approaches. One is post integration where each ‘omic’ approach can be analysed or modelled independently and then the findings integrated; the other is prior integration where data for all omic modalities can be integrated before any statistical or computational modelling takes place. Data may need to be prepared differently depending on which integration strategy is used. When using a prior integration, scaling analyte measurements suitably within each omic approach is especially important. In addition, the multi-omics datasets’ sample origin influences which integrative strategy can be employed. A prior integration necessitates the collection of data in the same biospecimens such as tissue, blood, etc., or individuals in order to match measurements to the same sample, whereas a post-integration does not. It is not possible to examine direct links between genes and metabolites and how they may relate to phenotype when the study is performed on the same individual but distinct biospecimens, such as genomic data from blood and metabolomic data from urine. Despite this limitation, it is possible to determine if data fit one biological paradigm; in this example; metabolites may serve as biomarkers for what is occurring at another level (i.e., genome) or alternatively, one omic modality can be used to orthogonally confirm biological pathways discovered by another omic modality [130].
Many human-focused studies have increasingly turned to the use of multiomics techniques (e.g., integration of genomic, transcriptomic, proteomic, and metabolomic platforms) to find relevant and accurate biomarkers. For example, in the past decade, multiomics studies of atrial fibrillation have identified a number of potential biomarkers of this condition [131]. Another study investigating the results of a metabolome and transcriptome-wide association study to identify genes influencing the human metabolome, found that this integration can support the causal role of ALMS1 (Alstrom syndrome 1) gene expression levels on N-acetylated compound concentration, whereas for HPS1 (Hermansky-Pudlak syndrome), a negative feedback loop between its expression levels and TMA (Trimethylamine) using an untargeted approach in nuclear magnetic resonance spectroscopy (NMR) and methylation quantitative trait loci (mQTLs) analysis. Multi-omics integrative analyses have also found use in investigateions of nutrition and functional food components [132], as well as in deciphering regulatory networks for complex disease traits [133]. Previous research has shown that a systems-level multi-omics investigation can provide more robust and valuable insights into biological mechanisms than a single platform analysis, especially where the condition under study can arise from a range of different underlying pathological mechanisms. Li, et al. [134] used advanced metabolomics and transcriptomics approaches to identify molecular and metabolic pathway abnormalities that could contribute to canine degenerative mitral valve disease (DMVD) development and progression. The goal of their study was to find pathways that could be altered with nutritional or pharmaceutical interventions to prevent, reverse, or control DMVD. While there are few studies of this depth in the veterinary field at present, researchers expect that integrative approaches showcasing multi-omics research in veterinary sciences will become increasingly important and prevalent over coming years, facilitating efficient biomarker discovery and development.
3. Challenges to Successful Biomarker Development
The example biomarker studies described in this entry have been performed in different species and focus on diagnostics and monitoring of a wide range of conditions. While many are considered promising, the bulk of the biomarkers identified have yet to be developed into commercial products or diagnostic tests in practice. In many cases, the full suite of necessary validation steps required for a biomarker to enter clinical use has not been conducted or has not been published. Further, it appears that the rate of successful completion of biomarker studies to clinical use is higher for human medical applications than for the veterinary field. Although many of the same challenges persist in both human and veterinary medicine, some issues are more pronounced in the veterinary field and may help explain the deficits in this translational pipeline. Understanding and subsequently addressing these challenges is key to the future success of biomarker science in this field and realisation of the associated improvements in animal production efficiency and welfare they promise.
3.1. Time and Finance towards the Biomarker Discovery
One of the foremost challenges is the time and expense required for establishing a biomarker. Research funding remains a major constraint in biomarker development, as extensive studies with a large sample size are required to ensure that any given biomarker is not only associated with, but truly able to predict, the clinical outcome [135]. Additionally, translating those identified markers into clinical practice requires further time and investment. Importantly, continuity of funding is essential as the path from discovery to clinical application is likely to take many years and interruptions in this process can compromise the ultimate success of even the most promising biomarkers. One example is the use of urinary estrogens to diagnose pregnancy in giant pandas, where researchers have been analysing estrogen metabolites as markers of pregnancy and viable cub development [136]; studies working towards this biomarker began a decade ago, characterising the biological and technical aspects and demonstrating the value of estrogen as a biomarker [136][137][138]. However, estrogen metabolites are yet to be validated and to undergo the clinical trials needed to confirm their utility as a robust test in zoo medicine practice and such studies are expected to take several additional years.
Furthermore, there are unique challenges to the development of biomarkers for veterinary medicine. A given biomarker may need to be qualified multiple times, once for each applicable species. Other limitations relate to sample handling requirements, and difficulties in establishing cut-off values owing to breed differences. Historically, many animal biomarkers have relied on previous experiences from human medicine to reduce the time taken for many studies, exploiting already established methodologies and making modifications according to species-specific requirements. This application is very limited but useful if implemented with care and sufficient knowledge of species variation of the particular biomarkers. Examples of such scenarios include N-terminal pro b-type natriuretic peptide (NT-proBNP) and cardiac troponin T (cTnT): cardiac biomarkers used in human medicine that have been adapted to evaluate systemic inflammatory response syndrome (SIRS) in dogs. These biomarkers are well established markers in diagnosing cardiac dysfunction and evaluating prognosis in human medicine. Since cardiac dysfunction secondary to systemic inflammation has been reported in human medicine known as myocardial hibernation, increased concentration of these markers reported in SIRS in humans has been associated with myocardial hibernation [16][17]. Cardiac hibernation has been reported in dogs with experimentally induced sepsis, and more recent data suggest that plasma concentrations of cardiac biomarkers are increased in dogs with SIRS [139][140]. Thus, it has been hypothesised that these cardiac biomarkers may help in the diagnosis of cardiac dysfunction and the evaluation of prognosis in people with SIRS, and may also be useful to evaluate dogs with SIRS [141]. Indeed, NT-pro BNP and cTnT were found to be significantly increased in dogs with SIRS regardless of underlying diseases. Additionally, this entry confirmed that the cTnT concentration was associated with survival in dogs with SIRS. Studies investigating the correlation of cardiac biomarkers with echocardiographic findings and inflammatory cytokines in canine patients with SIRS are warranted. Evidently, the background of research performed for human applications provides a huge advantage for the development of this biomarker in animal applications and its translation to clinical veterinary practice, reducing both time and funding required.
A similar approach is to directly use commercially available kits of identified biomarkers to validate their use in veterinary medicine. Cardiac troponin I (cTnI) is also a peripheral blood biomarker for myocardial diseases in humans and veterinary medicine [81][83][126]. There are commercially available kits to monitor the cTnI levels in humans. It has been suggested that commercial human cTnI assays could be used in horses, cattle, and sheep and some assays have been evaluated and validated for use in camelids [100], cattle [98][142], horses [143] and goats [144]. Another example is biomarker identification for treatment monitoring in leishmaniosis in dogs. This research identified apolipoprotein A1 (APO-A1) as a potential biomarker using 2-dimensional electrophoresis followed by mass spectrometry analysis, observing that concentration of APO-A1 was low in dogs with leishmaniosis and increased with good response to treatment. From a panel of 8 differentially expressed proteins in leishmaniosis, selection of the APO-A1 biomarker was mainly based on its ability to be easily measured by an established automated immunoturbidimetric method and on previous work indicating its value as a possible diagnostic/prognostic biomarker of visceral leishmaniasis in humans [145]. Whilst incorporating expertise from other species, in particular from human medicine, can be advantageous in terms of time and finance, care must be taken to ensure that such biomarkers are truly the most appropriate and useful option for clinical decision making. Furthermore, in many situations human markers cannot be directly applied to veterinary medicine, not only because of differences in physiology, but also pragmatic aspects such as ease of collection of sample type (e.g., in many species collecting urine is more difficult than taking a blood sample), and clinical priorities (e.g., where patient comfort is prioritised over remission of neoplastic conditions or herd health is more critical than individual prognosis). Another example is the not-yet-elucidated maternal recognition of pregnancy (MRP) signal of horses, a factor that remains elusive despite being a fundamental component of reproductive biology. The review of Swegen [146] clearly shows how the biological and physiological differences between horses and other species pose challenges leading to lagging diagnostics in the early pregnancy of horses. The review also elaborates how the time and technological advances are accumulating knowledge towards pregnancy biomarker identification. Recent omics approaches including the proteomic analysis of early equine embryo secretome, blastocele fluid and capsule [147], uterine fluid of pregnant mares [148] together with transcriptomics studies [149][150] have provided more positive insight for the biomarker discovery to address the gap. Truly novel markers will require the full suite of discovery and validation studies in a given species and relevant clinical setting. Researchers, clinicians and funding bodies must work closely together to ensure clear goals, realistic expectations and thorough planning for all phases of biomarker development.
3.2. Requirement of Standardised Methodologies
Evidently, the scale and screening capacity of ‘omics platforms provide unparalleled appeal for biomarker discovery. However, sophisticated equipment and rapidly evolving technology mean that developing appropriate protocols for sample collection, processing and analysis is not always straightforward, nor consistent between studies. A thorough understanding of multiple components is required, e.g., biochemistry for sample preparation, analytical chemistry for instruments, and computational biology for data analysis. Thus, it is an essential requirement to have well-established standard methodology for each of these steps. Across all the omics platforms, collection and preparation of samples must be treated as a delicate process that necessitates close care to avoid sample handling bias [88]. In case–control studies any variation in sample selection and processing can result in systematic bias [20][151][152][153][154]. As an example, variation in sampling times between different studies can yield different results and it is important to take this into account when interpreting omics results or planning further studies.
As a more established platform, proteomics has engaged in some interdisciplinary collaboration to standardise methods [155][156][157], while the lipidomics community is now initiating international standardisation [157]. The following steps have been suggested to minimise systematic bias [155].
- 1.
-
Sample selection
-
Avoiding the pooling of samples
-
Not using a combination of blood plasma and serum, but instead consolidating around the exclusive use of a single substrate
-
- 2.
-
Collection of Samples
-
Blood collection and pre analytical procedures should be standardised
-
Blood collection-to be conducted by the same person,
-
Pre-analytical procedures–use of identical conditions for centrifuging, containers, storage temperatures and times
-
Immediately centrifuging blood to generate plasma
-
Immediately harvesting plasma after centrifugation
-
Not withdrawing the last 500 μL of plasma at every possible stage to avoid contamination with platelets. If not, incorporating a second centrifugation clean-up step
-
Immediately freezing samples after harvesting
-
Furthermore, apart from these guidelines there are some standard analytical and statistical methods in use with a level of understanding in the international proteomics community [70][141][142]. Though some of these can apply to other omics approaches such as sampling standards, each field will need to agree on and publish clear standards in line with the relevant platforms’ requirements [157].
Likewise, metabolomics platforms are yet to develop universal standards for methods in biomarker discovery. As in other fields, those operating at the highly specialised end of the spectrum may be not fully aware of the clinical setting and requirements, while clinicians are unfamiliar with the technical aspects of metabolomic tests as well as the biochemical interdependencies of metabolites. Effective collaboration across the full spectrum of translation is clearly essential for successful development of truly useful assays. With increasingly complex datasets and a clear role for pattern recognition and machine learning, new statistical methodologies must be investigated for some study designs [109]. Towards this goal, there is ongoing improvement of the livestock metabolome database (LMBDB, available at http://www.lmdb.ca accessed on 27 July 2022), however further refinement of this dataset and its annotation promises to facilitate future untargeted metabolomics studies by increasing the number of identified metabolites. Nevertheless, for NMR-based approaches there remains considerable variability in the reference methods used for calibration. In brief, metabolite identification relies heavily on the mass spectrometry expertise of the operator and is further constrained by the availability of standards and as such, many of the inventories of promising markers contain only putative identifications. Thus, standardising the methods used within and across countries and laboratories remains a major challenge [158].
In addition to technical aspects and sample preparation, the standardisation and detailed reporting of experimental circumstances and animal traits are essential, and individual species should have their own guidelines [159]. Due to the snapshot nature of the results provided from most omics approaches, there remains a general problem of extrapolating findings to other scenarios, species, etc. Although it is nearly impossible to standardise experimental conditions and replicates across the entire range of veterinary species spanning from large to small animals, important information such as age, lactation number and stage, body condition, diet composition and feeding regimen, as well as a detailed description of sampling procedures and timing relative to physiological state, can be reported. Computer based algorithms can then be harnessed to model/integrate data from papers reporting on the proteome and other omics of animal diseases and facilitate the assembly of an atlas of all proteins and other biological agents present, regardless of their abundance or statistical analysis. Most proteomics and lipidomics investigations do not provide absolute quantitative data; they instead report patterns, such as an increase or reduction in comparison to internal standards. Although such studies have contributed substantially to researchers' understanding of the pathophysiology of diseases, using proteomic techniques to study metabolic diseases has not yielded a comprehensive and consistent list of biomarkers. In the context of metabolic diseases, it could be argued that metabolomics has greater potential to identify suitable biomarkers. Thus, producing a cohesive atlas that includes all previously detected biological markers across independent studies, along with methods and animal data, will be very useful for accurate identification of markers in future studies.
The multivariate outcomes from omics techniques, in accordance with computational and data requirements, necessitate significant bioinformatics resources, which are generally available online [112]. The identification of a limited number of potential candidates from thousands of proteins quantified by untargeted MS proteomics for downstream verification and validation using targeted assays is one of the rate-limiting phases in protein biomarker development [159]. Despite the fact that MS-based discovery platforms may measure a huge number of proteins they are frequently performed with a small number of samples, resulting in the “big p, small n” dilemma [160]. Thus, protein markers identified from discovery data may not be generalisable to independent datasets due to the limited sample size of typical discovery research. This issue arises frequently in omics-based association research, and it is frequently addressed using dimension reduction techniques such as principal component (PC) analysis and its supervised equivalents [161]. Because each PC is a linear combination of all original properties, predictive models based on PCs require genome-wide measurements as inputs and hence cannot be used as tailored clinical diagnostics but can be used to identify proteins serving as the main contributors to the predictive model and flag these for further investigation. As researchers can see from the summary details several novel cluster selection approaches and statistical methodologies are being developed to assist in these processes. Algorithms developed by Shi, Wen, Gao and Zhang [159] allowed for functional interpretation of the detected markers and should facilitate a smooth transition to the verification and validation platforms. Additional bioinformatics tools to assist modelling and validation are expected to emerge in the near future and will contribute significantly to the efficiency of the biomarker discovery process.
4. Conclusions and Future Directions
Biomarker discovery is clearly a rapidly expanding research area in the veterinary field. Successful biomarker discovery, development and translation is being facilitated by emerging technologies but remains challenging due to several factors such as financial support, species variations, a smaller number of samples in some species, difficulty in sample collection, and lack of method standardisation or bioinformatics resources with which to analyse the output of some platforms. Identifying such challenges early in the research and development planning process can help to overcome many obstacles and maximise the chance of success of such projects. Here, Researchers also emphasise the critical need for close collaboration between clinicians, researchers and funding bodies and the need to set clear goals for biomarker requirements and realistic application in the clinical setting, ensuring that biomarker type, method of detection and clinical utility are compatible, and adequate funding, time and sample size are available for all phases of development. Researchers contend that embracing these approaches will assist in many of the promising preliminary biomarkers attaining their full potential in clinical application, ultimately reducing workload in veterinary practice, enhancing animal welfare outcomes, and improving economic viability of livestock industries.
References
- Blancou, J. Utilisation and control of biotechnological procedures in veterinary science. Rev. Sci. Tech. (Int. Off. Epizoot.) 1990, 9, 621–680.
- National Research Council (US) Committee on the National Needs for Research in Veterinary Science. Critical Needs for Research in Veterinary Science; National Academies Press: Washington, DC, USA, 2005. Available online: https://www.ncbi.nlm.nih.gov/books/NBK22917/ (accessed on 27 July 2022).
- Scott, N.R. Nanoscience in Veterinary Medicine. Vet. Res. Commun. 2007, 31, 139–144.
- Dahlhausen, B. Future Veterinary Diagnostics. J. Exot. Pet Med. 2010, 19, 117–132.
- Soetan, K.; Abatan, M. Biotechnology a key tool to breakthrough in medical and veterinary research. Biotechnol. Mol. Biol. Rev. 2008, 3, 88–94.
- Manzoni, C.; Kia, D.A.; Vandrovcova, J.; Hardy, J.; Wood, N.W.; Lewis, P.A.; Ferrari, R. Genome, transcriptome and proteome: The rise of omics data and their integration in biomedical sciences. Brief. Bioinform. 2018, 19, 286–302.
- Figueroa, M.; Rawls, W. Biological markers for differentiation of herpes-virus strains of oral and genital origin. J. Gen. Virol. 1969, 4, 259–267.
- Myers, M.J.; Smith, E.R.; Turfle, P.G. Biomarkers in Veterinary Medicine. Annu. Rev. Anim. Biosci. 2017, 5, 65–87.
- Micheel, C.; Ball, J. Evaluation of Biomarkers and Surrogate Endpoints in Chronic Disease; National Academies Press: Washington, DC, USA, 2010.
- FDA-NIH Biomarker Working Group. BEST (Biomarkers, EndpointS, and Other Tools) Resource; Food and Drug Administration: Bethesda, MD, USA, 2016.
- Institute of Medicine. Surrogate Endpoints in Chronic Disease. In Evaluation of Biomarkers and Surrogate Endpoints in Chronic Disease; Micheel, C.M., Ball, J.R., Eds.; National Academy of Sciences: Washington, DC, USA, 2010.
- FDA-NIH Biomarker Working Group. Safety Biomarker. In BEST (Biomarkers, EndpointS, and Other Tools) Resource—Safety Biomarker; Food and Drug Administration: Bethesda, MD, USA, 2016.
- Yamamoto, S.; Shida, T.; Okimura, T.; Otabe, K.; Honda, M.; Ashida, Y.; Furukawa, E.; Sarikaputi, M.; Naiki, M. Determination of C-reactive protein in serum and plasma from healthy dogs and dogs with pneumonia by ELISA and slide reversed passive latex agglutination test. Vet. Q. 1994, 16, 74–77.
- Eckersall, P.D. Calibration of Novel Protein Biomarkers for Veterinary Clinical Pathology: A Call for International Action. Front. Vet. Sci. 2019, 6, 210.
- Sarko, J.; Pollack, C.V., Jr. Cardiac troponins. J. Emerg. Med. 2002, 23, 57–65.
- Babuin, L.; Vasile, V.C.; Perez, J.A.R.; Alegria, J.R.; Chai, H.-S.; Afessa, B.; Jaffe, A.S. Elevated cardiac troponin is an independent risk factor for short-and long-term mortality in medical intensive care unit patients. Crit. Care Med. 2008, 36, 759–765.
- Chen, Y.; Li, C. Prognostic significance of brain natriuretic peptide obtained in the ED in patients with SIRS or sepsis. Am. J. Emerg. Med. 2009, 27, 701–706.
- Osei, E.; Walters, P.; Masella, O.; Tennant, Q.; Fishwick, A.; Dadzie, E.; Bhangu, A.; Darko, J. A review of predictive, prognostic and diagnostic biomarkers for brain tumours: Towards personalised and targeted cancer therapy. J. Radiother. Pract. 2021, 20, 83–98.
- Omenn, G.S.; States, D.J.; Adamski, M.; Blackwell, T.W.; Menon, R.; Hermjakob, H.; Apweiler, R.; Haab, B.B.; Simpson, R.J.; Eddes, J.S. Overview of the HUPO Plasma Proteome Project: Results from the pilot phase with 35 collaborating laboratories and multiple analytical groups, generating a core dataset of 3020 proteins and a publicly-available database. Proteomics 2005, 5, 3226–3245.
- Rai, A.J.; Gelfand, C.A.; Haywood, B.C.; Warunek, D.J.; Yi, J.; Schuchard, M.D.; Mehigh, R.J.; Cockrill, S.L.; Scott, G.B.; Tammen, H. HUPO Plasma Proteome Project specimen collection and handling: Towards the standardization of parameters for plasma proteome samples. Proteomics 2005, 5, 3262–3277.
- Millioni, R.; Tolin, S.; Puricelli, L.; Sbrignadello, S.; Fadini, G.P.; Tessari, P.; Arrigoni, G. High Abundance Proteins Depletion vs Low Abundance Proteins Enrichment: Comparison of Methods to Reduce the Plasma Proteome Complexity. PLoS ONE 2011, 6, e19603.
- Van Altena, S.; De Klerk, B.; Hettinga, K.; Van Neerven, R.; Boeren, S.; Savelkoul, H.; Tijhaar, E. A proteomics-based identification of putative biomarkers for disease in bovine milk. Vet. Immunol. Immunopathol. 2016, 174, 11–18.
- Guest, P.C.; Gottschalk, M.G.; Bahn, S. Proteomics: Improving biomarker translation to modern medicine? Genome Med. 2013, 5, 17.
- Celi, P. Biomarkers of oxidative stress in ruminant medicine. Immunopharmacol. Immunotoxicol. 2011, 33, 233–240.
- Puurunen, J.; Tiira, K.; Lehtonen, M.; Hanhineva, K.; Lohi, H. Non-targeted metabolite profiling reveals changes in oxidative stress, tryptophan and lipid metabolisms in fearful dogs. Behav. Brain Funct. 2016, 12, 7.
- Dietert, R.R.; Silbergeld, E.K. Biomarkers for the 21st century: Listening to the microbiome. Toxicol. Sci. 2015, 144, 208–216.
- Naeger, D.M.; Kohi, M.P.; Webb, E.M.; Phelps, A.; Ordovas, K.G.; Newman, T.B. Correctly using sensitivity, specificity, and predictive values in clinical practice: How to avoid three common pitfalls. Am. J. Roentgenol. 2013, 200, W566–W570.
- McConathy, J.; Sheline, Y.I. Imaging biomarkers associated with cognitive decline: A review. Biol. Psychiatry 2015, 77, 685–692.
- Drucker, E.; Krapfenbauer, K. Pitfalls and limitations in translation from biomarker discovery to clinical utility in predictive and personalised medicine. EPMA J. 2013, 4, 7.
- Goossens, N.; Nakagawa, S.; Sun, X.; Hoshida, Y. Cancer biomarker discovery and validation. Transl. Cancer Res. 2015, 4, 256.
- LaBaer, J. So, you want to look for biomarkers (introduction to the special biomarkers issue). J. Proteome Res. 2005, 4, 1053–1059.
- Parikh, N.I.; Vasan, R.S. Assessing the clinical utility of biomarkers in medicine. Biomark. Med. 2007, 3, 419–436.
- Chaisson, M.J.; Huddleston, J.; Dennis, M.Y.; Sudmant, P.H.; Malig, M.; Hormozdiari, F.; Antonacci, F.; Surti, U.; Sandstrom, R.; Boitano, M. Resolving the complexity of the human genome using single-molecule sequencing. Nature 2015, 517, 608–611.
- Pandey, J.P. Genomewide association studies and assessment of risk of disease. New Engl. J. Med. 2010, 363, 2076–2077.
- Williams, J.; Link, E.; Parish, S.; Armitage, J.; Bowman, L.; Heath, S.; Matsuda, F.; Emberson, J.; Tomlinson, L.; Halliday, A.; et al. SLCO1B1 variants and statin-induced myopathy—A genomewide study. N. Engl. J. Med. 2008, 359, 789–799.
- Verschuren, J.J.; Trompet, S.; Wessels, J.A.; Guchelaar, H.-J.; de Maat, M.P.; Simoons, M.L.; Jukema, J.W. A systematic review on pharmacogenetics in cardiovascular disease: Is it ready for clinical application? Eur. Heart J. 2012, 33, 165–175.
- Kroll, W. Biomarkers–Predictors, Surrogate Parameters–A concept definition; Biomarker Schattauer: Stuttgart, Germany, 2008; pp. 1–4.
- Herman, J.G.; Graff, J.R.; Myöhänen, S.; Nelkin, B.D.; Baylin, S.B. Methylation-specific PCR: A novel PCR assay for methylation status of CpG islands. Proc. Natl. Acad. Sci. USA 1996, 93, 9821–9826.
- Paluszczak, J.; Baer-Dubowska, W. Epigenetic diagnostics of cancer—The application of DNA methylation markers. J. Appl. Genet. 2006, 47, 365–375.
- Payne, S.R. From discovery to the clinic: The novel DNA methylation biomarker m SEPT9 for the detection of colorectal cancer in blood. Epigenomics 2010, 2, 575–585.
- Darwiche, K.; Zarogoulidis, P.; Baehner, K.; Welter, S.; Tetzner, R.; Wohlschlaeger, J.; Theegarten, D.; Nakajima, T.; Freitag, L. Assessment of SHOX2 methylation in EBUS-TBNA specimen improves accuracy in lung cancer staging. Ann. Oncol. 2013, 24, 2866–2870.
- Li, Y.-W.; Kong, F.-M.; Zhou, J.-P.; Dong, M. Aberrant promoter methylation of the vimentin gene may contribute to colorectal carcinogenesis: A meta-analysis. Tumor Biol. 2014, 35, 6783–6790.
- Screven, R.; Kenyon, E.; Myers, M.J.; Yancy, H.F.; Skasko, M.; Boxer, L.; Bigley III, E.C.; Borjesson, D.L.; Zhu, M. Immunophenotype and gene expression profile of mesenchymal stem cells derived from canine adipose tissue and bone marrow. Vet. Immunol. Immunopathol. 2014, 161, 21–31.
- Arendt, M.L.; Melin, M.; Tonomura, N.; Koltookian, M.; Courtay-Cahen, C.; Flindall, N.; Bass, J.; Boerkamp, K.; Megquir, K.; Youell, L. Genome-wide association study of golden retrievers identifies germ-line risk factors predisposing to mast cell tumours. PLoS Genet. 2015, 11, e1005647.
- Meurs, K.M.; Fox, P.R.; Norgard, M.; Spier, A.W.; Lamb, A.; Koplitz, S.L.; Baumwart, R.D. A prospective genetic evaluation of familial dilated cardiomyopathy in the Doberman pinscher. J. Vet. Intern. Med. 2007, 21, 1016–1020.
- Brooks, S.A.; Gabreski, N.; Miller, D.; Brisbin, A.; Brown, H.E.; Streeter, C.; Mezey, J.; Cook, D.; Antczak, D.F. Whole-genome SNP association in the horse: Identification of a deletion in myosin Va responsible for Lavender Foal Syndrome. PLoS Genet. 2010, 6, e1000909.
- Menzi, F.; Besuchet-Schmutz, N.; Fragnière, M.; Hofstetter, S.; Jagannathan, V.; Mock, T.; Raemy, A.; Studer, E.; Mehinagic, K.; Regenscheit, N. A transposable element insertion in APOB causes cholesterol deficiency in Holstein cattle. Anim. Genet. 2016, 47, 253–257.
- Irizarry, R.A.; Ladd-Acosta, C.; Wen, B.; Wu, Z.; Montano, C.; Onyango, P.; Cui, H.; Gabo, K.; Rongione, M.; Webster, M. The human colon cancer methylome shows similar hypo-and hypermethylation at conserved tissue-specific CpG island shores. Nat. Genet. 2009, 41, 178–186.
- Raszek, M.M.; Guan, L.L.; Plastow, G.S. Use of genomic tools to improve cattle health in the context of infectious diseases. Front. Genet. 2016, 7, 30.
- Neibergs, H.L.; Seabury, C.M.; Wojtowicz, A.J.; Wang, Z.; Scraggs, E.; Kiser, J.N.; Neupane, M.; Womack, J.E.; Van Eenennaam, A.; Hagevoort, G.R. Susceptibility loci revealed for bovine respiratory disease complex in pre-weaned holstein calves. BMC Genom. 2014, 15, 1164.
- Yang, Y.-C.T.; Di, C.; Hu, B.; Zhou, M.; Liu, Y.; Song, N.; Li, Y.; Umetsu, J.; Lu, Z.J. CLIPdb: A CLIP-seq database for protein-RNA interactions. BMC Genom. 2015, 16, 51.
- Hu, B.; Yang, Y.-C.T.; Huang, Y.; Zhu, Y.; Lu, Z.J. POSTAR: A platform for exploring post-transcriptional regulation coordinated by RNA-binding proteins. Nucleic Acids Res. 2017, 45, D104–D114.
- Islam, M.N.; Masud, M.K.; Haque, M.H.; Hossain, M.S.A.; Yamauchi, Y.; Nguyen, N.-T.; Shiddiky, M.J.A. RNA Biomarkers: Diagnostic and Prognostic Potentials and Recent Developments of Electrochemical Biosensors. Small Methods 2017, 1, 1700131.
- del Mar Lleò, M.; Pierobon, S.; Tafi, M.C.; Signoretto, C.; Canepari, P. mRNA detection by reverse transcription-PCR for monitoring viability over time in an Enterococcus faecalis viable but nonculturable population maintained in a laboratory microcosm. Appl. Environ. Microbiol. 2000, 66, 4564–4567.
- Vandenbroucke, I.I.; Vandesompele, J.; De Paepe, A.; Messiaen, L. Quantification of splice variants using real-time PCR. Nucleic Acids Res. 2001, 29, E68.
- Lund, S.H.; Gudbjartsson, D.F.; Rafnar, T.; Sigurdsson, A.; Gudjonsson, S.A.; Gudmundsson, J.; Stefansson, K.; Stefansson, G. A method for detecting long non-coding RNAs with tiled RNA expression microarrays. PLoS ONE 2014, 9, e99899.
- Ayturk, U.M.; Jacobsen, C.M.; Christodoulou, D.C.; Gorham, J.; Seidman, J.G.; Seidman, C.E.; Robling, A.G.; Warman, M.L. An RNA-seq protocol to identify mRNA expression changes in mouse diaphyseal bone: Applications in mice with bone property altering Lrp5 mutations. J. Bone Miner. Res. 2013, 28, 2081–2093.
- Hu, L.; Di, C.; Kai, M.; Yang, Y.-C.T.; Li, Y.; Qiu, Y.; Hu, X.; Yip, K.Y.; Zhang, M.Q.; Lu, Z.J. A common set of distinct features that characterize noncoding RNAs across multiple species. Nucleic Acids Res. 2015, 43, 104–114.
- Hu, L.; Xu, Z.; Hu, B.; Lu, Z.J. COME: A robust coding potential calculation tool for lncRNA identification and characterization based on multiple features. Nucleic Acids Res. 2017, 45, e2.
- Xi, X.; Li, T.; Huang, Y.; Sun, J.; Zhu, Y.; Yang, Y.; Lu, Z.J. RNA biomarkers: Frontier of precision medicine for cancer. Noncoding RNA 2017, 3, 9.
- Martinez-Ledesma, E.; Verhaak, R.G.; Treviño, V. Identification of a multi-cancer gene expression biomarker for cancer clinical outcomes using a network-based algorithm. Sci. Rep. 2015, 5, 11966.
- Parker, J.S.; Mullins, M.; Cheang, M.C.; Leung, S.; Voduc, D.; Vickery, T.; Davies, S.; Fauron, C.; He, X.; Hu, Z. Supervised risk predictor of breast cancer based on intrinsic subtypes. J. Clin. Oncol. 2009, 27, 1160.
- Cuzick, J.; Swanson, G.P.; Fisher, G.; Brothman, A.R.; Berney, D.M.; Reid, J.E.; Mesher, D.; Speights, V.; Stankiewicz, E.; Foster, C.S. Prognostic value of an RNA expression signature derived from cell cycle proliferation genes in patients with prostate cancer: A retrospective study. Lancet Oncol. 2011, 12, 245–255.
- Glavac, D.; Hrasovec, S. MicroRNAs as novel biomarkers in colorectal cancer. Front. Genet. 2012, 3, 180.
- Lu, J.; Getz, G.; Miska, E.A.; Alvarez-Saavedra, E.; Lamb, J.; Peck, D.; Sweet-Cordero, A.; Ebert, B.L.; Mak, R.H.; Ferrando, A.A. MicroRNA expression profiles classify human cancers. Nature 2005, 435, 834–838.
- Hwang, J.-H.; Voortman, J.; Giovannetti, E.; Steinberg, S.M.; Leon, L.G.; Kim, Y.-T.; Funel, N.; Park, J.K.; Kim, M.A.; Kang, G.H. Identification of microRNA-21 as a biomarker for chemoresistance and clinical outcome following adjuvant therapy in resectable pancreatic cancer. PLoS ONE 2010, 5, e10630.
- Dirksen, K.; Verzijl, T.; Grinwis, G.C.; Favier, R.P.; Penning, L.C.; Burgener, I.A.; van der Laan, L.J.; Fieten, H.; Spee, B. Use of Serum MicroRNAs as Biomarker for Hepatobiliary Diseases in Dogs. J. Vet. Intern. Med. 2016, 30, 1816–1823.
- Lecchi, C.; Catozzi, C.; Zamarian, V.; Poggi, G.; Borriello, G.; Martucciello, A.; Vecchio, D.; DeCarlo, E.; Galiero, G.; Ceciliani, F. Characterization of circulating miRNA signature in water buffaloes (Bubalus bubalis) during Brucella abortus infection and evaluation as potential biomarkers for non-invasive diagnosis in vaginal fluid. Sci. Rep. 2019, 9, 1945.
- Barrey, E.; Bonnamy, B.; Barrey, E.; Mata, X.; Chaffaux, S.; Guerin, G. Muscular microRNA expressions in healthy and myopathic horses suffering from polysaccharide storage myopathy or recurrent exertional rhabdomyolysis. Equine Vet. J. 2010, 42, 303–310.
- Desjardin, C.; Vaiman, A.; Mata, X.; Legendre, R.; Laubier, J.; Kennedy, S.P.; Laloe, D.; Barrey, E.; Jacques, C.; Cribiu, E.P. Next-generation sequencing identifies equine cartilage and subchondral bone miRNAs and suggests their involvement in osteochondrosis physiopathology. BMC Genom. 2014, 15, 798.
- da Costa Santos, H.; Hess, T.; Bruemmer, J.; Splan, R. Possible role of MicroRNA in equine insulin resistance: A pilot study. J. Equine Vet. Sci. 2018, 63, 74–79.
- Pacholewska, A.; Mach, N.; Mata, X.; Vaiman, A.; Schibler, L.; Barrey, E.; Gerber, V. Novel equine tissue miRNAs and breed-related miRNA expressed in serum. BMC Genom. 2016, 17, 831.
- Xiao, X.; Wu, Z.-C.; Chou, K.-C. A multi-label classifier for predicting the subcellular localization of gram-negative bacterial proteins with both single and multiple sites. PLoS ONE 2011, 6, e20592.
- Fabre, A.-L.; Colotte, M.; Luis, A.; Tuffet, S.; Bonnet, J. An efficient method for long-term room temperature storage of RNA. Eur. J. Hum. Genet. 2014, 22, 379–385.
- Haider, M.; Haselgrübler, T.; Sonnleitner, A.; Aberger, F.; Hesse, J. A Double-Hybridization Approach for the Transcription-and Amplification-Free Detection of Specific mRNA on a Microarray. Microarrays 2016, 5, 5.
- Tavallaie, R.; De Almeida, S.R.; Gooding, J.J. Toward biosensors for the detection of circulating microRNA as a cancer biomarker: An overview of the challenges and successes. Wiley Interdiscip. Rev. Nanomed. Nanobiotechnol. 2015, 7, 580–592.
- Carrascosa, L.; Gómez-Montes, S.A.; Avi nó, A.; Nadal, M.; Pla, R.; Eritja, L.M. Lechuga. Nucleic Acids Res. 2012, 40, e56.
- Carrascosa, L.G.; Huertas, C.S.; Lechuga, L.M. Prospects of optical biosensors for emerging label-free RNA analysis. Trac Trends Anal. Chem. 2016, 80, 177–189.
- Koo, K.M.; Carrascosa, L.G.; Shiddiky, M.J.; Trau, M. Amplification-free detection of gene fusions in prostate cancer urinary samples using mrna–gold affinity interactions. Anal. Chem. 2016, 88, 6781–6788.
- Labib, M.; Khan, N.; Ghobadloo, S.M.; Cheng, J.; Pezacki, J.P.; Berezovski, M.V. Three-mode electrochemical sensing of ultralow microRNA levels. J. Am. Chem. Soc. 2013, 135, 3027–3038.
- Labib, M.; Sargent, E.H.; Kelley, S.O. Electrochemical methods for the analysis of clinically relevant biomolecules. Chem. Rev. 2016, 116, 9001–9090.
- Griffin, R.A.; Swegen, A.; Baker, M.; Aitken, R.J.; Skerrett-Byrne, D.A.; Silva Rodriguez, A.; Martín-Cano, F.E.; Nixon, B.; Peña, F.J.; Delehedde, M.; et al. Mass spectrometry reveals distinct proteomic profiles in high- and low-quality stallion spermatozoa. Reproduction 2020, 160, 695–707.
- Zhang, M.; Chiozzi, R.Z.; Skerrett-Byrne, D.A.; Veenendaal, T.; Klumperman, J.; Heck, A.J.R.; Nixon, B.; Helms, J.B.; Gadella, B.M.; Bromfield, E.G. High Resolution Proteomic Analysis of Subcellular Fractionated Boar Spermatozoa Provides Comprehensive Insights Into Perinuclear Theca-Residing Proteins. Front. Cell. Dev. Biol. 2022, 10, 836208.
- Nixon, B.; Johnston, S.D.; Skerrett-Byrne, D.A.; Anderson, A.L.; Stanger, S.J.; Bromfield, E.G.; Martin, J.H.; Hansbro, P.M.; Dun, M.D. Modification of Crocodile Spermatozoa Refutes the Tenet That Post-testicular Sperm Maturation Is Restricted To Mammals. Mol. Cell. Proteom. 2019, 18, S58–S76.
- Skerrett-Byrne, D.A.; Anderson, A.L.; Hulse, L.; Wass, C.; Dun, M.D.; Bromfield, E.G.; De Iuliis, G.N.; Pyne, M.; Nicolson, V.; Johnston, S.D.; et al. Proteomic analysis of koala (phascolarctos cinereus) spermatozoa and prostatic bodies. Proteomics 2021, 21, e2100067.
- Nixon, B.; De Iuliis, G.N.; Hart, H.M.; Zhou, W.; Mathe, A.; Bernstein, I.R.; Anderson, A.L.; Stanger, S.J.; Skerrett-Byrne, D.A.; Jamaluddin, M.F.B.; et al. Proteomic Profiling of Mouse Epididymosomes Reveals their Contributions to Post-testicular Sperm Maturation. Mol. Cell. Proteom. 2019, 18, S91–S108.
- Smyth, S.P.; Nixon, B.; Anderson, A.L.; Murray, H.C.; Martin, J.H.; MacDougall, L.A.; Robertson, S.A.; Skerrett-Byrne, D.A.; Schjenken, J.E. Elucidation of the protein composition of mouse seminal vesicle fluid. Proteomics 2022, 22, e2100227.
- Sinha, A.; Mann, M. A beginner’s guide to mass spectrometry–based proteomics. Biochemist 2020, 42, 64–69.
- Bilić, P.; Kuleš, J.; Galan, A.; Gomes de Pontes, L.; Guillemin, N.; Horvatić, A.; Festa Sabes, A.; Mrljak, V.; Eckersall, P.D. Proteomics in veterinary medicine and animal science: Neglected scientific opportunities with immediate impact. Proteomics 2018, 18, 1800047.
- Kuleš, J.; Mrljak, V.; Rafaj, R.B.; Selanec, J.; Burchmore, R.; Eckersall, P.D. Identification of serum biomarkers in dogs naturally infected with Babesia canis canis using a proteomic approach. BMC Vet. Res. 2014, 10, 111.
- Martinez-Subiela, S.; Horvatic, A.; Escribano, D.; Pardo-Marin, L.; Kocaturk, M.; Mrljak, V.; Burchmore, R.; Ceron, J.J.; Yilmaz, Z. Identification of novel biomarkers for treatment monitoring in canine leishmaniosis by high-resolution quantitative proteomic analysis. Vet. Immunol. Immunopathol. 2017, 191, 60–67.
- Liu, M.; Eckersall, P.D.; Mrljak, V.; Horvatić, A.; Guillemin, N.; Galan, A.; Köster, L.; French, A. Novel biomarkers in cats with congestive heart failure due to primary cardiomyopathy. J. Proteom. 2020, 226, 103896.
- Mudaliar, M.; Tassi, R.; Thomas, F.C.; McNeilly, T.N.; Weidt, S.K.; McLaughlin, M.; Wilson, D.; Burchmore, R.; Herzyk, P.; Eckersall, P.D.; et al. Mastitomics, the integrated omics of bovine milk in an experimental model of Streptococcus uberis mastitis: 2. Label-free relative quantitative proteomics. Mol. BioSystems 2016, 12, 2748–2761.
- Escribano, D.; Horvatic, A.; Contreras-Aguilar, M.D.; Guillemin, N.; Ceron, J.J.; Lopez-Arjona, M.; Hevia, M.L.; Eckersall, P.D.; Manteca, X.; Mrljak, V. Identification of possible new salivary biomarkers of stress in sheep using a high-resolution quantitative proteomic technique. Res. Vet. Sci. 2019, 124, 338–345.
- Lazensky, R.; Silva-Sanchez, C.; Kroll, K.J.; Chow, M.; Chen, S.; Tripp, K.; Walsh, M.T.; Denslow, N.D. Investigating an increase in Florida manatee mortalities using a proteomic approach. Sci. Rep. 2021, 11, 4282.
- Ploypetch, S.; Roytrakul, S.; Jaresitthikunchai, J.; Phaonakrop, N.; Krobthong, S.; Suriyaphol, G. Salivary proteomics of canine oral tumors using MALDI-TOF mass spectrometry and LC-tandem mass spectrometry. PLoS ONE 2019, 14, e0219390.
- Borgeat, K.; Connolly, D.; Fuentes, V.L. Cardiac biomarkers in cats. J. Vet. Cardiol. 2015, 17, S74–S86.
- Varga, A.; Schober, K.; Walker, W.; Lakritz, J.; Michael Rings, D. Validation of a commercially available immunoassay for the measurement of bovine cardiac troponin I. J. Vet. Intern. Med. 2009, 23, 359–365.
- Van Der Vekens, N.; Decloedt, A.; Sys, S.; Ven, S.; De Clercq, D.; van Loon, G. Evaluation of assays for troponin I in healthy horses and horses with cardiac disease. Vet. J. 2015, 203, 97–102.
- Blass, K.A.; Kraus, M.S.; Rishniw, M.; Mann, S.; Mitchell, L.M.; Divers, T.J. Measurement of cardiac troponin I utilizing a point of care analyzer in healthy alpacas. J. Vet. Cardiol. 2011, 13, 261–266.
- Langhorn, R.; Willesen, J. Cardiac troponins in dogs and cats. J. Vet. Intern. Med. 2016, 30, 36–50.
- Soler, L.; Szczubiał, M.; Dąbrowski, R.; Płusa, A.; Bochniarz, M.; Brodzki, P.; Lampreave, F.; Piñeiro, M. Measurement of ITIH4 and Hp levels in bitches with pyometra using newly developed ELISA methods. Vet. Immunol. Immunopathol. 2021, 235, 110221.
- Zhan, L.; Wu, W.B.; Yang, X.X.; Huang, C.Z. Gold nanoparticle-based enhanced ELISA for respiratory syncytial virus. New J. Chem. 2014, 38, 2935–2940.
- Ambrosi, A.; Airo, F.; Merkoçi, A. Enhanced gold nanoparticle based ELISA for a breast cancer biomarker. Anal. Chem. 2010, 82, 1151–1156.
- Friedrich, M.; Holtz, W. Establishment of an ELISA for measuring bovine pregnancy-associated glycoprotein in serum or milk and its application for early pregnancy detection. Reprod. Domest. Anim. 2010, 45, 142–146.
- Oliver, S.; Winson, M.K.; Kell, D.B.; Baganz, F. Systematic functional analysis of the yeast genome. TIPTeCH 1998, 16, 373–378.
- Nicholson, J.K.; Higham, D.P.; Timbrell, J.A.; Sadler, P.J. Quantitative high resolution 1H NMR urinalysis studies on the biochemical effects of cadmium in the rat. Mol. Pharmacol. 1989, 36, 398–404.
- Griffin, J.L. The Cinderella story of metabolic profiling: Does metabolomics get to go to the functional genomics ball? Philos. Trans. R. Soc. B Biol. Sci. 2006, 361, 147–161.
- Marchand, C.R.; Farshidfar, F.; Rattner, J.; Bathe, O.F. A framework for development of useful metabolomic biomarkers and their effective knowledge translation. Metabolites 2018, 8, 59.
- Couperus, A.M.; Schroeder, F.; Hettegger, P.; Huber, J.; Wittek, T.; Peham, J.R. Longitudinal Metabolic Biomarker Profile of Hyperketonemic Cows from Dry-Off to Peak Lactation and Identification of Prognostic Classifiers. Animals 2021, 11, 1353.
- Hailemariam, D.; Mandal, R.; Saleem, F.; Dunn, S.; Wishart, D.; Ametaj, B. Identification of predictive biomarkers of disease state in transition dairy cows. J. Dairy Sci. 2014, 97, 2680–2693.
- Ceciliani, F.; Lecchi, C.; Urh, C.; Sauerwein, H. Proteomics and metabolomics characterizing the pathophysiology of adaptive reactions to the metabolic challenges during the transition from late pregnancy to early lactation in dairy cows. J. Proteom. 2018, 178, 92–106.
- Li, Y.; Xu, C.; Xia, C.; Zhang, H.; Sun, L.; Gao, Y. Plasma metabolic profiling of dairy cows affected with clinical ketosis using LC/MS technology. Vet. Q. 2014, 34, 152–158.
- Wu, Z.; Chen, C.; Zhang, Q.; Bao, J.; Fan, Q.; Li, R.; Ishfaq, M.; Li, J. Arachidonic acid metabolism is elevated in Mycoplasma gallisepticum and Escherichia coli co-infection and induces LTC4 in serum as the biomarker for detecting poultry respiratory disease. Virulence 2020, 11, 730–738.
- Prasinou, P.; Crisi, P.E.; Chatgilialoglu, C.; Di Tommaso, M.; Sansone, A.; Gramenzi, A.; Belà, B.; De Santis, F.; Boari, A.; Ferreri, C. The Erythrocyte Membrane Lipidome of Healthy Dogs: Creating a Benchmark of Fatty Acid Distribution and Interval Values. Front. Vet. Sci. 2020, 7, 502.
- Aristizabal Henao, J.J.; Bradley, R.M.; Duncan, R.E.; Stark, K.D. Categorizing and qualifying nutritional lipidomic data: Defining brutto, medio, genio, and infinio lipid species within macrolipidomics and microlipidomics. Curr. Opin. Clin. Nutr. Metab. Care 2018, 21, 352–359.
- Zhao, Y.-Y.; Cheng, X.-L.; Wei, F.; Bai, X.; Tan, X.-J.; Lin, R.-C.; Mei, Q. Intrarenal metabolomic investigation of chronic kidney disease and its TGF-β1 mechanism in induced-adenine rats using UPLC Q-TOF/HSMS/MSE. J. Proteome Res. 2013, 12, 692–703.
- Svegliati-Baroni, G.; Pierantonelli, I.; Torquato, P.; Marinelli, R.; Ferreri, C.; Chatgilialoglu, C.; Bartolini, D.; Galli, F. Lipidomic biomarkers and mechanisms of lipotoxicity in non-alcoholic fatty liver disease. Free. Radic. Biol. Med. 2019, 144, 293–309.
- Koelmel, J.P.; Ulmer, C.Z.; Fogelson, S.; Jones, C.M.; Botha, H.; Bangma, J.T.; Guillette, T.C.; Luus-Powell, W.J.; Sara, J.R.; Smit, W.J. Lipidomics for wildlife disease etiology and biomarker discovery: A case study of pansteatitis outbreak in South Africa. Metabolomics 2019, 15, 38.
- Rivera-Velez, S.M.; Broughton-Neiswanger, L.E.; Suarez, M.; Piñeyro, P.; Navas, J.; Chen, S.; Hwang, J.; Villarino, N.F. Repeated administration of the NSAID meloxicam alters the plasma and urine lipidome. Sci. Rep. 2019, 9, 4303.
- Beauclercq, S.; Lefèvre, A.; Nadal-Desbarats, L.; Germain, K.; Praud, C.; Emond, P.; Bihan-Duval, E.L.; Mignon-Grasteau, S. Does lipidomic serum analysis support the assessment of digestive efficiency in chickens? Poult. Sci. 2019, 98, 1425–1431.
- Franco, J.; Rajwa, B.; Gomes, P.; HogenEsch, H. Local and Systemic Changes in Lipid Profile as Potential Biomarkers for Canine Atopic Dermatitis. Metabolites 2021, 11, 670.
- Ceciliani, F.; Audano, M.; Addis, M.F.; Lecchi, C.; Ghaffari, M.H.; Albertini, M.; Tangorra, F.; Piccinini, R.; Caruso, D.; Mitro, N.; et al. The untargeted lipidomic profile of quarter milk from dairy cows with subclinical intramammary infection by non-aureus staphylococci. J. Dairy Sci. 2021, 104, 10268–10281.
- Imhasly, S.; Bieli, C.; Naegeli, H.; Nyström, L.; Ruetten, M.; Gerspach, C. Blood plasma lipidome profile of dairy cows during the transition period. BMC Vet. Res. 2015, 11, 252.
- Rico, J.E.; Saed Samii, S.; Zang, Y.; Deme, P.; Haughey, N.J.; Grilli, E.; McFadden, J.W. Characterization of the Plasma Lipidome in Dairy Cattle Transitioning from Gestation to Lactation: Identifying Novel Biomarkers of Metabolic Impairment. Metabolites 2021, 11, 290.
- Gerspach, C.; Imhasly, S.; Gubler, M.; Naegeli, H.; Ruetten, M.; Laczko, E. Altered plasma lipidome profile of dairy cows with fatty liver disease. Res. Vet. Sci. 2017, 110, 47–59.
- Christmann, U.; Hite, R.D.; Witonsky, S.G.; Buechner-Maxwell, V.A.; Wood, P.L. Evaluation of lipid markers in surfactant obtained from asthmatic horses exposed to hay. Am. J. Vet. Res. 2019, 80, 300–305.
- Conesa, A.; Beck, S. Making multi-omics data accessible to researchers. Sci. Data 2019, 6, 251.
- Subramanian, I.; Verma, S.; Kumar, S.; Jere, A.; Anamika, K. Multi-omics Data Integration, Interpretation, and Its Application. Bioinform. Biol. Insights 2020, 14, 1177932219899051.
- Eicher, T.; Kinnebrew, G.; Patt, A.; Spencer, K.; Ying, K.; Ma, Q.; Machiraju, R.; Mathé, E.A. Metabolomics and Multi-Omics Integration: A Survey of Computational Methods and Resources. Metabolites 2020, 10, 202.
- Kornej, J.; Hanger, V.A.; Trinquart, L.; Ko, D.; Preis, S.R.; Benjamin, E.J.; Lin, H. New biomarkers from multiomics approaches: Improving risk prediction of atrial fibrillation. Cardiovasc. Res. 2021, 117, 1632–1644.
- Kato, H.; Takahashi, S.; Saito, K. Omics and Integrated Omics for the Promotion of Food and Nutrition Science. J. Tradit. Complementary Med. 2011, 1, 25–30.
- Civelek, M.; Lusis, A.J. Systems genetics approaches to understand complex traits. Nat. Rev. Genet. 2014, 15, 34–48.
- Li, Q.; Freeman, L.M.; Rush, J.E.; Huggins, G.S.; Kennedy, A.D.; Labuda, J.A.; Laflamme, D.P.; Hannah, S.S. Veterinary Medicine and Multi-Omics Research for Future Nutrition Targets: Metabolomics and Transcriptomics of the Common Degenerative Mitral Valve Disease in Dogs. OMICS A J. Integr. Biol. 2015, 19, 461–470.
- Giuffrida, M.; Brown, D. Association between article citation rate and level of evidence in the companion animal literature. J. Vet. Intern. Med. 2012, 26, 252–258.
- Wilson, K.S.; Wauters, J.; Valentine, I.; McNeilly, A.; Girling, S.; Li, R.; Li, D.; Zhang, H.; Rae, M.T.; Howie, F.; et al. Urinary estrogens as a non-invasive biomarker of viable pregnancy in the giant panda (Ailuropoda melanoleuca). Sci. Rep. 2019, 9, 12772.
- Kinoshita, K.; Miyazaki, M.; Morita, H.; Vassileva, M.; Tang, C.; Li, D.; Ishikawa, O.; Kusunoki, H.; Tsenkova, R. Spectral pattern of urinary water as a biomarker of estrus in the giant panda. Sci. Rep. 2012, 2, 856.
- Cai, K.; Yie, S.; Zhang, Z.; Wang, J.; Cai, Z.; Luo, L.; Liu, Y.; Wang, H.; Huang, H.; Wang, C. Urinary profiles of luteinizing hormone, estrogen and progestagen during the estrous and gestational periods in giant pandas (Ailuropda melanoleuca). Sci. Rep. 2017, 7, 40749.
- Langhorn, R.; Persson, F.; Åblad, B.; Goddard, A.; Schoeman, J.P.; Willesen, J.L.; Tarnow, I.; Kjelgaard-Hansen, M. Myocardial injury in dogs with snake envenomation and its relation to systemic inflammation. J. Vet. Emerg. Crit. Care 2014, 24, 174–181.
- Hamacher, L.; Dörfelt, R.; Müller, M.; Wess, G. Serum cardiac troponin I concentrations in dogs with systemic inflammatory response syndrome. J. Vet. Intern. Med. 2015, 29, 164–170.
- Gommeren, K.; Desmas, I.; Garcia, A.; Clercx, C.; Mc Entee, K.; Merveille, A.C.; Peeters, D. Cardiovascular biomarkers in dogs with systemic inflammatory response syndrome. J. Vet. Emerg. Crit. Care 2019, 29, 256–263.
- Fraser, B.C.; Anderson, D.E.; White, B.J.; Miesner, M.D.; Wheeler, C.; Amrine, D.; Lakritz, J.; Overbay, T. Assessment of a commercially available point-of-care assay for the measurement of bovine cardiac troponin I concentration. Am. J. Vet. Res. 2013, 74, 870–873.
- Kraus, M.S.; Jesty, S.A.; Gelzer, A.R.; Ducharme, N.G.; Mohammed, H.O.; Mitchell, L.M.; Soderholm, L.V.; Divers, T.J. Measurement of plasma cardiac troponin I concentration by use of a point-of-care analyzer in clinically normal horses and horses with experimentally induced cardiac disease. Am. J. Vet. Res. 2010, 71, 55–59.
- Karapinar, T.; Eroksuz, Y.; Hayirli, A.; Beytut, E.; Kaynar, O.; Baydar, E.; Sozdutmaz, I.; Isidan, H. The diagnostic value of two commercially available human cTnI assays in goat kids with myocarditis. Vet. Clin. Pathol. 2016, 45, 164–171.
- Escribano, D.; Tvarijonaviciute, A.; Kocaturk, M.; Cerón, J.J.; Pardo-Marín, L.; Torrecillas, A.; Yilmaz, Z.; Martínez-Subiela, S. Serum apolipoprotein-A1 as a possible biomarker for monitoring treatment of canine leishmaniosis. Comp. Immunol. Microbiol. Infect. Dis. 2016, 49, 82–87.
- Swegen, A. Maternal recognition of pregnancy in the mare: Does it exist and why do we care? Reproduction 2021, 161, R139–R155.
- Swegen, A.; Grupen, C.G.; Gibb, Z.; Baker, M.A.; de Ruijter-Villani, M.; Smith, N.D.; Stout, T.A.E.; Aitken, R.J. From Peptide Masses to Pregnancy Maintenance: A Comprehensive Proteomic Analysis of The Early Equine Embryo Secretome, Blastocoel Fluid, and Capsule. Proteomics 2017, 17, 17–18.
- Smits, K.; Willems, S.; Van Steendam, K.; Van De Velde, M.; De Lange, V.; Ververs, C.; Roels, K.; Govaere, J.; Van Nieuwerburgh, F.; Peelman, L.; et al. Proteins involved in embryo-maternal interaction around the signalling of maternal recognition of pregnancy in the horse. Sci. Rep. 2018, 8, 5249.
- Klein, C. Novel equine conceptus?endometrial interactions on Day 16 of pregnancy based on RNA sequencing. Reprod. Fertil. Dev. 2015, 28, 1712–1720.
- Klein, C.; Troedsson, M.H. Transcriptional profiling of equine conceptuses reveals new aspects of embryo-maternal communication in the horse. Biol. Reprod. 2011, 84, 872–885.
- Timms, J.F.; Arslan-Low, E.; Gentry-Maharaj, A.; Luo, Z.; T’Jampens, D.; Podust, V.N.; Ford, J.; Fung, E.T.; Gammerman, A.; Jacobs, I. Preanalytic influence of sample handling on SELDI-TOF serum protein profiles. Clin. Chem. 2007, 53, 645–656.
- Schrohl, A.-S.; Würtz, S.; Kohn, E.; Banks, R.E.; Nielsen, H.J.; Sweep, F.C.; Brünner, N. Banking of biological fluids for studies of disease-associated protein biomarkers. Mol. Cell. Proteom. 2008, 7, 2061–2066.
- Qundos, U.; Hong, M.-G.; Tybring, G.; Divers, M.; Odeberg, J.; Uhlen, M.; Nilsson, P.; Schwenk, J.M. Profiling post-centrifugation delay of serum and plasma with antibody bead arrays. J. Proteom. 2013, 95, 46–54.
- Hassis, M.E.; Niles, R.K.; Braten, M.N.; Albertolle, M.E.; Witkowska, H.E.; Hubel, C.A.; Fisher, S.J.; Williams, K.E. Evaluating the effects of preanalytical variables on the stability of the human plasma proteome. Anal. Biochem. 2015, 478, 14–22.
- Geyer, P.E.; Voytik, E.; Treit, P.V.; Doll, S.; Kleinhempel, A.; Niu, L.; Muller, J.B.; Buchholtz, M.L.; Bader, J.M.; Teupser, D.; et al. Plasma Proteome Profiling to detect and avoid sample-related biases in biomarker studies. EMBO Mol. Med. 2019, 11, e10427.
- Geyer, P.E.; Holdt, L.M.; Teupser, D.; Mann, M. Revisiting biomarker discovery by plasma proteomics. Mol. Syst. Biol. 2017, 13, 942.
- Burla, B.; Arita, M.; Arita, M.; Bendt, A.K.; Cazenave-Gassiot, A.; Dennis, E.A.; Ekroos, K.; Han, X.; Ikeda, K.; Liebisch, G.; et al. MS-based lipidomics of human blood plasma: A community-initiated position paper to develop accepted guidelines. J. Lipid Res. 2018, 59, 2001–2017.
- De Marchi, M.; Toffanin, V.; Cassandro, M.; Penasa, M. Invited review: Mid-infrared spectroscopy as phenotyping tool for milk traits. J. Dairy Sci. 2014, 97, 1171–1186.
- Shi, Z.; Wen, B.; Gao, Q.; Zhang, B. Feature Selection Methods for Protein Biomarker Discovery from Proteomics or Multiomics Data. Mol. Cell. Proteom. 2021, 20, 100083.
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning. In Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009.
- Bair, E.; Hastie, T.; Paul, D.; Tibshirani, R. Prediction by supervised principal components. J. Am. Stat. Assoc. 2006, 101, 119–137.
More
Information
Subjects:
Veterinary Sciences
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
1.5K
Revisions:
2 times
(View History)
Update Date:
02 Sep 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No