Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Joao Manuel R.S. Tavares | -- | 2870 | 2022-07-20 17:24:56 | | | |
| 2 | Vivi Li | -1 word(s) | 2869 | 2022-07-21 07:54:52 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Hassen, K.B.A.; Machado, J.J.M.; Tavares, J.M.R.S. Methods for Crowd Counting. Encyclopedia. Available online: https://encyclopedia.pub/entry/25356 (accessed on 23 July 2026).
Hassen KBA, Machado JJM, Tavares JMRS. Methods for Crowd Counting. Encyclopedia. Available at: https://encyclopedia.pub/entry/25356. Accessed July 23, 2026.
Hassen, Khouloud Ben Ali, José J. M. Machado, João Manuel R. S. Tavares. "Methods for Crowd Counting" Encyclopedia, https://encyclopedia.pub/entry/25356 (accessed July 23, 2026).
Hassen, K.B.A., Machado, J.J.M., & Tavares, J.M.R.S. (2022, July 20). Methods for Crowd Counting. In Encyclopedia. https://encyclopedia.pub/entry/25356
Hassen, Khouloud Ben Ali, et al. "Methods for Crowd Counting." Encyclopedia. Web. 20 July, 2022.
Copy Citation
The crowd counting task has become a pillar for crowd control as it provides information concerning the number of people in a scene. It is helpful in many scenarios such as video surveillance, public safety, and future event planning. To solve such tasks, researchers have proposed different solutions. In the beginning, researchers went with more traditional solutions, then the focus is on deep learning methods and, more specifically, on Convolutional Neural Networks (CNNs), because of their efficiency.
computer vision
deep learning
people counting
sparse datasets
crowded datasets
1. Background
Because of the fast growth of the world’s population, and situations where crowds occur, such as concerts, political speeches, rallies, marathons, and stadiums, crowd counting is becoming an active research topic in computer vision [1]. The task of crowd counting, defined as determining the number of people in a crowd, would help in many fields, such as in video surveillance for safety reasons, human behavior analysis, and urban planning [2][3][4][5]. Many approaches have been proposed in the literature to solve this problem, which generally can be split into four categories: detection, regression, density estimation, and approaches based on convolutional neural networks (CNNs).
2. Introduction
As mentioned previously, this entry divides the crowd counting models into four categories. Starting with the detection-based method, the principle behind it to use a moving window as a detector to identify and count how many persons are in an input image [6]. Although these methods work well for detecting faces, they do not perform sufficiently well on crowded images as most target objects are not clearly visible. Counting by detection is categorized into five types: monolithic detection [7][8][9], part-based detection [10][11], shape matching [12][13], multi-sensor detection [14], and transfer learning [15][16].
Since counting by detection is not very precise when factors such as dense crowds and high background clutter appear, researchers proposed a regression method [17] to overcome these problems, where neither segmentation nor tracking individuals are involved. First, it extracts the low-level features such as edge details and foreground pixels and then applies regression modelling to them by mapping the features and the count.
Clustering models are about selecting and gathering feature points or trajectories of feature points. These methods use unsupervised learning to identify each moving entity by an independent motion [18].
Among existing approaches, CNN based methods [19][20] have proved their efficiency and exhibit the best results for the crowd counting task. The general concept behind using deep convolutional networks is to scan the input image to understand its different features and then to combine the different scanned local features to classify it. According to the used network architecture, crowd counting models can be classified into: basic CNN [21][22], multi-column [23][24][25], and single column-based methods [26][27][28][29][30].
3. Heuristic Models
Early methods of this category estimate the pedestrian number via heuristic methods [31], for instance detection-based, regression-based, and density-estimation-based methods. This section explains in more detail these models and how they work.
3.1. Detection Based Methods
Earlier works on crowd counting were focused on detection-based methods to determine the number of people in the crowd [32][33][34]. They mainly detect each target person in a given image using specific detectors. In the following paragraphs, an explanation of these methods with some examples is given.
Monolithic detection: it is considered a typical pedestrian detection approach that trains the classifier, utilizing the entire body of a set of pedestrian training images [7][8][9][31]. In order to represent the entire body’s appearance, common features are used: Haar wavelets, gradient-based features, edgelet, and shapelets. As to the classification, several classifiers were used:
-
Non-Linear: Similarly to RBF, Support Vector Machines (SVMs) present good quality while suffering from low detection speed.
-
Linear: more commonly used classifiers such as boosting, linear SVMs, or Random Forests [35].
A trained classifier is applied in a sliding window fashion across the image space to catch pedestrian candidates. A monolithic detector can generate good detection in sparse scenes. However, it suffers in congested locations where it is impossible to avoid occlusion and scene clutter.
Part based detection: consists in constructing boosted classifiers for precise body parts, for instance the head and the shoulder, to count the people in the monitored region [10][11][36]. The idea is to include the shoulder region with the head to account for the real-world scenario better. Another method relies on a head detector to count people [37], which is based on finding interest points using gradient information from the greyscale image located at the top of the head region in order to reduce the search space.
Compared to monolithic detection, part-based detection relaxes the stringent hypothesis regarding the visibility of the whole body. As a result, it is more robust in crowds but it always suffers from the occlusion problem.
Shape matching: the idea is to detect the body shapes of the peoples in the crowd to count them. Zhao et al. [12] presented a set of parameterized body shapes formed of ellipses and zeros to estimate the number and shape configuration that best presents a given foreground mask in a scene, employing a stochastic process. Ge and Collins [13] developed the idea by permitting more flexible and realistic shape prototypes than only the simple geometric forms presented in [12]. The learned shape prototypes are more accurate than simple geometric shapes. The method proposed by Ge and Collins [13] can detect varying numbers of pedestrians under different crowd densities with reasonable occlusion.
Multi-sensor detection: When numerous cameras are available, one can also include multi-view information to handle visual ambiguities generated by inter-object occlusion. For instance, ref. [14] worked on extracting the foreground human silhouettes from the images under analysis in order to set bounds on the number and potential areas where people exist. The issue with these methods is that a multi-camera configuration with overlapping views is not always available in many possible applications.
Transfer learning: it is about transferring the generic pedestrian detectors to a new scene without human supervision. This solution faces the problems of the variations of viewpoints, resolutions, illuminations, and backgrounds in the new environment. A key to overcome these challenges is proposed in [15][16], by using multiple parameters such as scene structures, spatial-temporal occurrences, and object sizes to determine positive and negative examples from the target scene in order to iteratively adjust a generic detector.
3.2. Regression Methods
Because of the difficulty of detection-based models in dealing with highly dense crowds and high background clutter, researchers introduced regression-based approaches, which are inspired by the capacity of humans to determine the density at first sight without the need to enumerate how many pedestrians are in the scene under analysis [17]. Such a method counts people in crowded scenes by discovering a direct mapping from low-level imagery features to crowd density. First, it extracts global features [38]: texture [39], gradient or edge, or local features [40], such as Scale-invariant Feature Transform (SIFT), Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG), and Gray Level Co-occurrence Matrix (GLCM). After the feature extraction step, it trains a regression model to indicate the count given the normalized features. Among the regression techniques, one can mention: linear regression [41], piecewise linear regression [17], and Gaussian mixture regression [42].
Another approach from Idrees et al. [43] considered that, in highly crowded scenes, there is no feature or detection approach reliable enough to deliver sufficient information for a precise counting because of the low resolution, severe occlusion, foreshortening, and perspective problems. Furthermore, the presence of a spatial relationship is used in constraining the count estimates in neighboring local regions, and it is suggested that the extraction of features be performed using different methods to catch the different information. Table 1 summarizes some of the regression-based methods.
Table 1. Summary of regression-based methods.
| Method | Global Features | Regression Model | Dataset(s) |
|---|---|---|---|
| [44] | Segment, internal edge, texture | Gaussian | Peds1, Peds2 |
| [45] | Segment, motion | Linear regression | PETS2009 |
| [46] | Segment, edge, gradient | Gaussian | UCSD pedestrian, Pets 2009 |
| [38] | Segment, edge, texture | Kernel ridge regression | UCSD, Mall |
| [47] | Edge | Linear regression | Internal data (2000 images, number of people per image: from 3 to 27 people) |
3.3. Clustering Based Methods
Another alternative technique is counting by clustering. The idea is to decompose the crowd into individual entities. Each entity has unique patterns that can be clustered to determine the number of individuals [31].
Rabaud et al. [48], used a simple yet effective tracker, the Kanade–Lucas–Tomasi (KLT), to extract a large set of low-level features in pedestrian videos. It is proposed as a conditioning technique for feature trajectories to identify the number of objects in a scene. A complementary trajectory set clustering method was also introduced. The method can only be applied to crowd-counting videos. Three different real-world datasets were used to validate and determine the method’s robustness: USC, Library, and Cells datasets [49].
Brostow et al. [50], proposed a simple unsupervised Bayesian clustering framework to capture people in moving gatherings, the principal idea being to track local features and group them into clusters. The algorithm tracks simple image features and groups them into clusters defining independently-moving entities in a probabilistic way. The method uses space-time proximity and trajectory coherence via image space as the only probabilistic criteria for clustering. This solution came instead of determining the number of clusters and setting constituent features with supervised learning or a subject-specific model. The results were encouraging from crowded videos of bees, ants, penguins, and most humans.
Rao et al. [51], explained the importance of crowd density estimation in a video scene to understand crowd behavior by implementing a crowd density estimation method based on clustering motion cues and hierarchical clustering. For motion estimation, the approach integrates optical flow. It employs contour analysis to detect crowd silhouettes and clustering to calculate crowd density. It starts by applying a lens correction profile to each image frame, followed by pre-processing the frames to remove noise. A Gaussian filter is applied to suppress high amplitude edges. Finally, the foreground pixels are mapped to crowd density by clustering the motion cues hierarchically. For evaluation, three datasets were used: MCG, PETS, and UCSD.
Antonini et al. [52], worked on video sequences to improve the automatic counting of pedestrians. A generative probabilistic approach was applied to better represent the data. The main goal was to analyze the computed trajectories, find a better representation in the Independent Component Analysis (ICA) transformed domain, and apply clustering techniques to improve the estimation of the actual count of pedestrians in the scene. The advantage of using the ICA generative statistical model is in reducing the influence of outliers.
4. Deep Learning Methods
Because of the CNN architecture’s efficiency in many tasks, including crowd counting, recent researchers used CNN as the base framework of their work. The general concept is to understand the various features of the image under analysis by browsing its content from left to right or top to bottom, and then combining the different scanned local features in order to classify it. A CNN includes three layers: convolutional layer, pooling layer, and fully connected layer [53][54][55].
-
Convolutional layer: the primary role of this layer is to apply filters to detect features in the input image and build numerous feature maps to help identify or classify it. After every convolution operation, a linear function, the ReLU activation, is applied to replace the negative pixel values with zero values in the feature map.
-
Pooling layer: this step takes the output feature map generated by the convolution. The goal is to reduce the complexity for further layers by applying a specific function such as the max pooling.
-
Fully connected layer: every neuron from the previous layer is connected to every neuron on the next layer to generate the final classification result.
Figure 1 shows the basic architecture of a CNN.
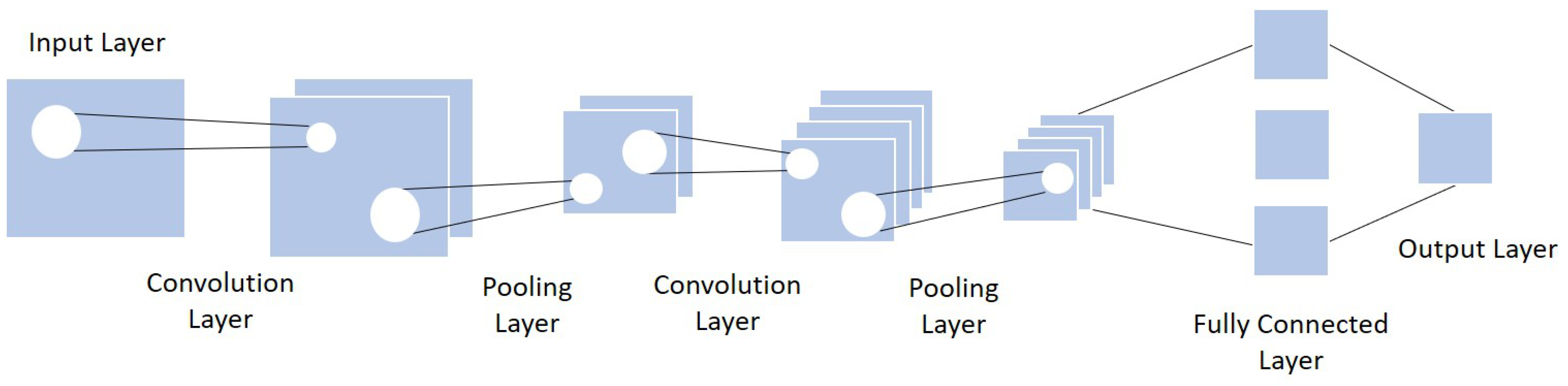
Figure 1. Usual CNN architecture (adapted from [56]).
Table 2 details each usual CNN layer with its actions, parameters, inputs and outputs.
Table 2. Details of the three CNN layers.
| Actions | Parameters | Input | Output | |
|---|---|---|---|---|
| Convolutional layer |
|
|
|
|
| Pooling layer |
|
|
|
|
| Fully connected layer |
|
|
|
|
According to the architecture of the used CNN, crowd counting methods can be divided into basic CNN, multi column, and single column networks.
4.1. Basic CNN
Among the CNN architectures, one has the basic CNN with its light network. It adopts the primary CNN layers: the convolutional layer, the pooling layer, and the fully connected layer. Figure 2 presents a simplified structure of the fundamental CNN.

Figure 2. General structure of the Basic CNN architecture.
Wang et al. [21] proposed a solution that can provide good results in high-density crowds, unlike the traditional methods that would fail in these scenarios, consisting of a deep regression network in crowded scenes using deep convolutional networks. The basic CNN architecture allows for efficient feature extraction. Since other objects can exist in dense crowd images, such as buildings and trees, influencing performance, the goal was to feed the CNN with negative samples to reduce false alarms. Few collected images without people were considered, and their regression score was set as 0 (zero), making the method more robust. The UCFCC dataset was used to evaluate the approach’s efficacy. A comparison between the CNN network with and without negative samples was performed. The method achieves almost 50% improvement.
Fu et al. [22] improved the speed and precision of the original approach by firstly removing some redundant network connections in the feature maps and, secondly, designing a cascade of two ConvNet classifiers:
-
Optimizing the connections: the multi-stage ConvNet increases the number of features in the final classifier, and the connections seriously increase the calculation time during the training and detection phases. Some redundant connections among two similar feature maps were observed, so these extra connections were removed based on a similarity matrix to accelerate the speed.
-
Cascade classifier: samples with complicated backgrounds are always hard to classify. The idea is to pick out those complex samples and train them individually and, after that, send them to a second ConvNet classifier to obtain the final classification result.
The three datasets used to evaluate this method were the PETS 2009, Subway, and Chunxi Road datasets, and the experiments confirm its excellent performance.
4.2. Multi column CNN
To solve the variation problem, researchers have resorted to a multi-column architecture. Despite being harder to train, it proved its efficiency in specific situations. It consists of using more than one column to catch multi-scale information. Figure 3 represents the overall architecture of the multi-column CNN.
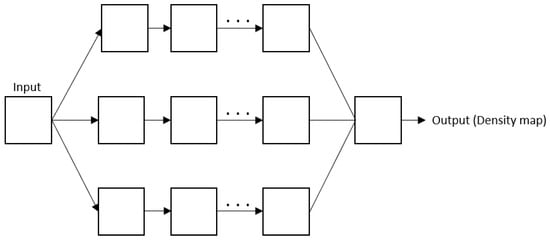
Figure 3. Overall architecture of the multi-column CNN.
MCNN: Development of a multi-column CNN method to count the crowd in a single image from any perspective [23]. The application of an MCNN architecture with three columns occurs since each one corresponds to a filter with different sizes of receptive fields: large, medium and small, so that the features could adapt to significant variations in people. Moreover, to avoid distortion, a convolution layer with a filter size of 1 × 1 replaces a fully connected layer. It is flexible to inputs of different sizes. To test this method, a new large-scale dataset named Shanghaitech was introduced, containing two parts: part A and part B. In addition to Shanghaitech, the UCF CC 50, WorldExpo’10, and UCSD datasets were used to evaluate the proposed method. Compared to the existing methods at that time for crowd counting, their solution outperforms all the results.
CrowdNet: to forecast the density map for a provided crowd image, this method combines deep and shallow fully convolutional networks [24]. The shallow is to capture the low-level features with a large-scale variation: head blob patterns appearing from individuals far from the camera, and the deep one captures the high-level semantic details: faces/body detectors.
Because most datasets used for crowd counting have restricted training samples while deep learning-based approaches need extensive training data, the researchers opt for data augmentation by sampling patches from the multi-scale image representation to make the built models more potent to crowd variations. Therefore, the CNN is guided to learn scale-invariant representations. One of the most challenging datasets was used, the UCF CC 50, allowing the CNN to obtain competitive evaluation results.
RANet: starts from the problem that density estimation methods for crowd counting serve pixel-wise regression without accounting for the interdependence of pixels explicitly, which leads to noisy and inconsistent independent pixel-wise predictions [25]. To solve this issue, it was suggested to capture the interdependence of pixels thanks to a Relational Attention Network (RANet) with a self-attention mechanism by accounting for short-range and long-range interdependence of pixels. These implementations are Local Self-attention (LSA) and Global Self-attention (GSA).
In addition, features from LSA and GSA have different information for each part. The researchers introduced a relation module to link those features and reach better instructive aggregated feature representations using intra-relation and inter-relation. The datasets used to evaluate their model were the ShanghaiTech A and B, UCF-CC-50, and UCF-QNRF datasets.
References
- Tang, S.; Pan, Z.; Zhou, X. Low-Rank and Sparse Based Deep-Fusion Convolutional Neural Network for Crowd Counting. Math. Probl. Eng. 2017, 2017, 5046727.
- Gao, J.; Yuan, Y.; Wang, Q. Feature-aware adaptation and density alignment for crowd counting in video surveillance. IEEE Trans. Cybern. 2020, 51, 4822–4833.
- Marsden, M.; McGuinness, K.; Little, S.; O’Connor, N.E. Fully convolutional crowd counting on highly congested scenes. arXiv 2016, arXiv:1612.00220.
- Ding, X.; Lin, Z.; He, F.; Wang, Y.; Huang, Y. A deeply-recursive convolutional network for crowd counting. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1942–1946.
- Marsden, M.; McGuinness, K.; Little, S.; O’Connor, N.E. Resnetcrowd: A residual deep learning architecture for crowd counting, violent behavior detection and crowd density level classification. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–7.
- Pan, X.; Mo, H.; Zhou, Z.; Wu, W. Attention guided region division for crowd counting. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2568–2572.
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893.
- Leibe, B.; Seemann, E.; Schiele, B. Pedestrian detection in crowded scenes. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 878–885.
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian detection via classification on riemannian manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727.
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645.
- Lin, S.F.; Chen, J.Y.; Chao, H.X. Estimation of number of people in crowded scenes using perspective transformation. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2001, 31, 645–654.
- Zhao, T.; Nevatia, R.; Wu, B. Segmentation and tracking of multiple humans in crowded environments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1198–1211.
- Ge, W.; Collins, R.T. Marked point processes for crowd counting. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 2913–2920.
- Yang, D.B.; González-Banos, H.H.; Guibas, L.J. Counting People in Crowds with a Real-Time Network of Simple Image Sensors. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 3, p. 122.
- Wang, M.; Li, W.; Wang, X. Transferring a generic pedestrian detector towards specific scenes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3274–3281.
- Wang, M.; Wang, X. Automatic adaptation of a generic pedestrian detector to a specific traffic scene. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3401–3408.
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–7.
- Shehzed, A.; Jalal, A.; Kim, K. Multi-person tracking in smart surveillance system for crowd counting and normal/abnormal events detection. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 27–29 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 163–168.
- Iqbal, M.S.; Ahmad, I.; Bin, L.; Khan, S.; Rodrigues, J.J. Deep learning recognition of diseased and normal cell representation. Trans. Emerg. Telecommun. Technol. 2021, 32, e4017.
- Iqbal, M.S.; El-Ashram, S.; Hussain, S.; Khan, T.; Huang, S.; Mehmood, R.; Luo, B. Efficient cell classification of mitochondrial images by using deep learning. J. Opt. 2019, 48, 113–122.
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep people counting in extremely dense crowds. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1299–1302.
- Fu, M.; Xu, P.; Li, X.; Liu, Q.; Ye, M.; Zhu, C. Fast crowd density estimation with convolutional neural networks. Eng. Appl. Artif. Intell. 2015, 43, 81–88.
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597.
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644.
- Zhang, A.; Shen, J.; Xiao, Z.; Zhu, F.; Zhen, X.; Cao, X.; Shao, L. Relational attention network for crowd counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6788–6797.
- Zhang, L.; Shi, M.; Chen, Q. Crowd counting via scale-adaptive convolutional neural network. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1113–1121.
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100.
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd counting and density estimation by trellis encoder-decoder networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6133–6142.
- Shi, Z.; Zhang, L.; Liu, Y.; Cao, X.; Ye, Y.; Cheng, M.M.; Zheng, G. Crowd counting with deep negative correlation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5382–5390.
- Wang, B.; Cao, G.; Shang, Y.; Zhou, L.; Zhang, Y.; Li, X. Single-column CNN for crowd counting with pixel-wise attention mechanism. Neural Comput. Appl. 2020, 32, 2897–2908.
- Loy, C.C.; Chen, K.; Gong, S.; Xiang, T. Crowd counting and profiling: Methodology and evaluation. In Modeling, Simulation and Visual Analysis of Crowds; Springer: Berlin/Heidelberg, Germany, 2013; pp. 347–382.
- Kong, D.; Gray, D.; Tao, H. A viewpoint invariant approach for crowd counting. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 3, pp. 1187–1190.
- Song, X.; Long, M.; Fang, Y.; Chen, L.; Shang, M. Switching Detection and Density Regression Network for Crowd Counting. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 5, pp. 703–709.
- Menon, A.; Omman, B.; Asha, S. Pedestrian Counting Using Yolo V3. In Proceedings of the 2021 International Conference on Innovative Trends in Information Technology (ICITIIT), Kottayam, India, 11–12 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–9.
- Gall, J.; Yao, A.; Razavi, N.; Van Gool, L.; Lempitsky, V. Hough forests for object detection, tracking, and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202.
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–4.
- Subburaman, V.B.; Descamps, A.; Carincotte, C. Counting people in the crowd using a generic head detector. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, Beijing, China, 18–21 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 470–475.
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. Bmvc 2012, 1, 3.
- Marana, A.; Costa, L.d.F.; Lotufo, R.; Velastin, S. On the efficacy of texture analysis for crowd monitoring. In Proceedings of the SIBGRAPI’98. International Symposium on Computer Graphics, Image Processing, and Vision (Cat. No. 98EX237), Rio de Janeiro, Brazil, 20–23 October 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 354–361.
- Ryan, D.; Denman, S.; Fookes, C.; Sridharan, S. Crowd counting using multiple local features. In Proceedings of the 2009 Digital Image Computing: Techniques and Applications, Melbourne, Australia, 1–3 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 81–88.
- Paragios, N.; Ramesh, V. A MRF-based approach for real-time subway monitoring. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1, p. I.
- Tian, Y.; Sigal, L.; Badino, H.; Torre, F.D.l.; Liu, Y. Latent gaussian mixture regression for human pose estimation. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 679–690.
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554.
- Chan, A.B.; Vasconcelos, N. Counting people with low-level features and Bayesian regression. IEEE Trans. Image Process. 2011, 21, 2160–2177.
- Benabbas, Y.; Ihaddadene, N.; Yahiaoui, T.; Urruty, T.; Djeraba, C. Spatio-temporal optical flow analysis for people counting. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 212–217.
- Lin, T.Y.; Lin, Y.Y.; Weng, M.F.; Wang, Y.C.; Hsu, Y.F.; Liao, H.Y.M. Cross camera people counting with perspective estimation and occlusion handling. In Proceedings of the 2011 IEEE International Workshop on Information Forensics and Security, Iguacu Falls, Brazil, 29 November–2 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6.
- Regazzoni, C.S.; Tesei, A. Distributed data fusion for real-time crowding estimation. Signal Process. 1996, 53, 47–63.
- Rabaud, V.; Belongie, S. Counting crowded moving objects. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 1, pp. 705–711.
- Saleh, S.A.M.; Suandi, S.A.; Ibrahim, H. Recent survey on crowd density estimation and counting for visual surveillance. Eng. Appl. Artif. Intell. 2015, 41, 103–114.
- Brostow, G.J.; Cipolla, R. Unsupervised bayesian detection of independent motion in crowds. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 1, pp. 594–601.
- Rao, A.S.; Gubbi, J.; Marusic, S.; Palaniswami, M. Estimation of crowd density by clustering motion cues. Vis. Comput. 2015, 31, 1533–1552.
- Antonini, G.; Thiran, J. Trajectories Clustering in ICA Space: An Application to Automatic Counting of Pedestrians in Video Sequences; Technical Report; IEEE: Piscataway, NJ, USA, 2004.
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458.
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6.
- Hossain, M.A.; Sajib, M.S.A. Classification of image using convolutional neural network (CNN). Glob. J. Comput. Sci. Technol. 2019, 19, 2-D.
- Gu, H.; Wang, Y.; Hong, S.; Gui, G. Blind channel identification aided generalized automatic modulation recognition based on deep learning. IEEE Access 2019, 7, 110722–110729.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
2.7K
Revisions:
2 times
(View History)
Update Date:
21 Jul 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No