Your browser does not fully support modern features. Please upgrade for a smoother experience.
Submitted Successfully!
 +1 credit
+1 credit
Thank you for your contribution! You can also upload a video entry or images related to this topic.
For video creation, please contact our Academic Video Service.
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Yi Zhou | -- | 3014 | 2022-06-06 16:54:57 | | | |
| 2 | Sirius Huang | + 22 word(s) | 3036 | 2022-06-07 04:13:50 | | |
Video Upload Options
We provide professional Academic Video Service to translate complex research into visually appealing presentations. Would you like to try it?
Cite
If you have any further questions, please contact Encyclopedia Editorial Office.
Zhou, Y.; , .; López-Benítez, M.; Yu, L.; Yue, Y. Radar Object Detection. Encyclopedia. Available online: https://encyclopedia.pub/entry/23751 (accessed on 23 July 2026).
Zhou Y, , López-Benítez M, Yu L, Yue Y. Radar Object Detection. Encyclopedia. Available at: https://encyclopedia.pub/entry/23751. Accessed July 23, 2026.
Zhou, Yi, , Miguel López-Benítez, Limin Yu, Yutao Yue. "Radar Object Detection" Encyclopedia, https://encyclopedia.pub/entry/23751 (accessed July 23, 2026).
Zhou, Y., , ., López-Benítez, M., Yu, L., & Yue, Y. (2022, June 06). Radar Object Detection. In Encyclopedia. https://encyclopedia.pub/entry/23751
Zhou, Yi, et al. "Radar Object Detection." Encyclopedia. Web. 06 June, 2022.
Copy Citation
With the improvement of automotive radar resolution, radar target classification has become a hot research topic. Deep radar detection can be classified into point-cloud-based and pre-CFAR-based. Radar point cloud and pre-CFAR data are similar to the LiDAR point cloud and visual image, respectively. Accordingly, the architectures for LiDAR and vision tasks can be adapted for radar detection.
automotive radars
radar signal processing
object detection
deep learning
1. Introduction
Due to low resolution, the classical radar detection algorithm has limited classification capability. In recent years, the performance of automotive radar has greatly improved. At the hardware level, next-generation imaging radars can output high-resolution point clouds. At the algorithmic level, neural networks show their potential to learn better features from the dataset. A broader definition of radar detection is considered here, including pointwise detection, 2D/3D bounding box detection, and instance segmentation. As shown in Figure 1, neural networks can be applied to different stages in the classical pipeline. According to the input data structure, the deep radar detection can be classified into point-cloud-based and pre-CFAR-based. Radar point cloud and pre-CFAR data are similar to the LiDAR point cloud and visual image, respectively. Accordingly, the architectures for LiDAR and vision tasks can be adapted for radar detection.
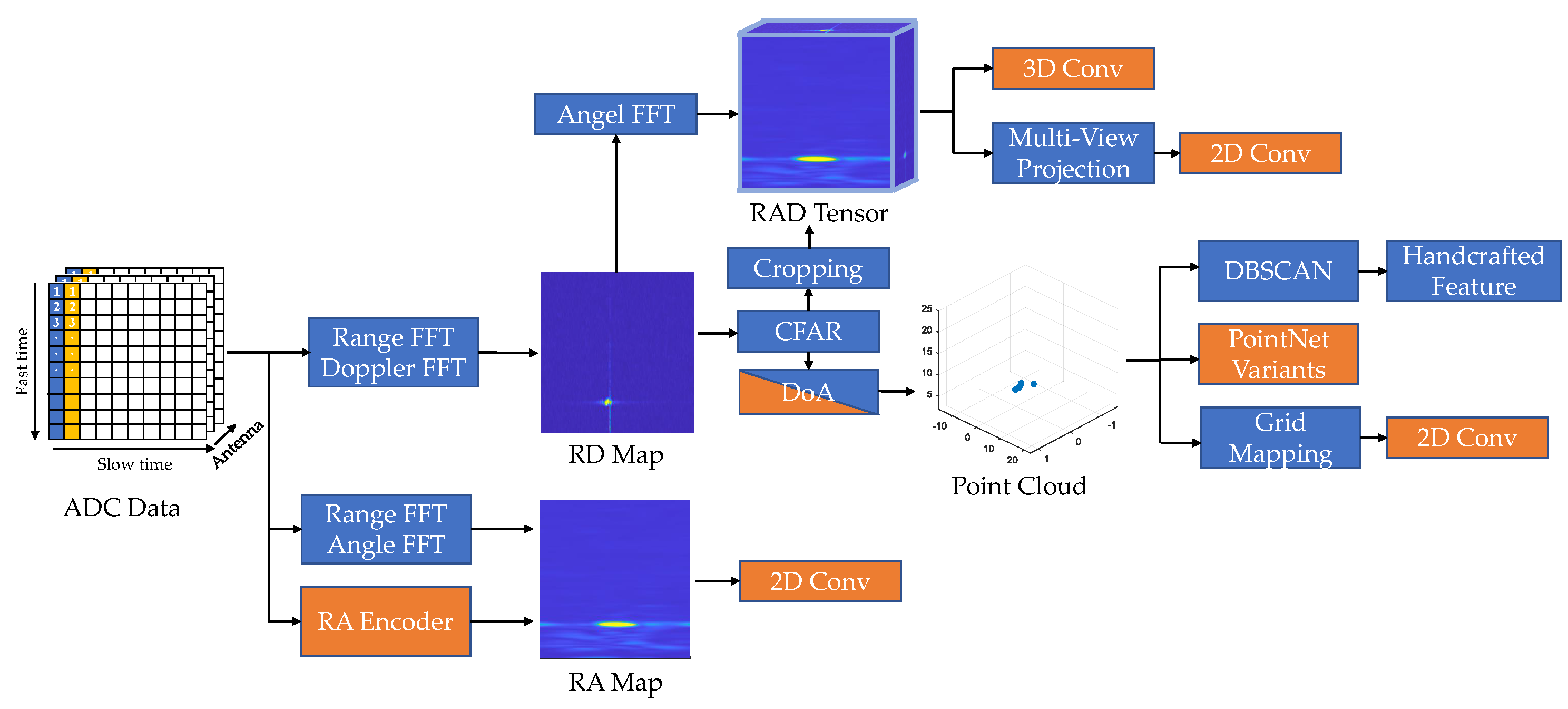
Figure 1. Overview of radar detection frameworks: Blue boxes indicate classical radar detection modules. Orange boxes represent AI-based substitutions.
2. Classical Detection Pipeline
As shown in Figure 1, the conventional radar detection pipeline consists of four steps: constant false alarm rate (CFAR) detection, clustering, feature extraction, and classification. Firstly, a CFAR detector is applied to detect peaks in the Range–Doppler (RD) heat map as a list of targets. Then, the moving targets are projected to Cartesian coordinates and clustered by DBSCAN [1]. Static targets are usually filtered out before clustering because they are indistinguishable from environmental clutter. Within each cluster, hand-crafted features, such as the statistics of measurements and shape descriptors, are extracted and sent to a machine learning classifier. Improvements can be made upon each of these four steps. CFAR is usually executed in an on-chip digital signal processor (DSP), so the choice of method is restricted by hardware support. Cell-averaging (CA) CFAR [2] is widely used due to its efficiency. It estimates the noise as the average power of neighbouring cells around the cell under test (CUT) within a CFAR window. A threshold is set to achieve a constant false alarm rate for Rayleigh-distributed noise. The next-generation high-resolution radar chips also support order-statistics (OS) CFAR [2]. It sorts neighbouring cells around the CUT according to the received power and selects the k-th cell to represent the noise value. OS-CFAR has advantages in distinguishing close targets, but introduces a slightly increased false alarm rate and additional computational costs. More sophisticated CFAR variants are summarised in [3], but are rarely used in automotive applications. Deep learning methods can be used to improve noise estimation [4] and peak classification [3] in CFAR. Clustering is the most important stage in the radar detection pipeline, especially for the next-generation high-resolution radar [5]. DBSCAN is favoured for several reasons: it does not require a pre-specified number of clusters; it fits arbitrary shapes; it runs fast [6]. Some works improved DBSCAN by explicitly considering the characteristics of radar point clouds. Grid-based DBSCAN [7] suggests clustering radar points in a Range–azimuth (RA) grid map to avoid the range-dependent resolution variations in Cartesian coordinates. Multi-stage clustering [8] proposes a coarse-to-fine two-stage framework to alleviate the negative impact of clutter. It applies a second cluster merging based on the velocity and spatial trajectory of clusters estimated from the first stage.
With the improvement of automotive radar resolution, radar target classification has become a hot research topic. For moving objects, the micro-Doppler velocity of moving components such as wheels and arms can be useful for classification. To better observe these micro-motions, short-time Fourier transform (STFT) is applied to extract Doppler spectrograms. Different types of vulnerable road users (VRUs) can be classified according to their micro-Doppler signatures [9][10]. For static objects, Cai et al. [11] suggest the use of statistical Radar cross-section (RCS) and time-domain RCS as useful features for classification of vehicles and pedestrians. Some researchers work on exploiting a large number of features for better classification. Scheiner et al. [12] considered a large set of 98 features and used the heuristic-guided backward elimination for feature selection. They found that range and Doppler features are most important for classification, while angle and shape features are usually discarded, probably because of the low angular resolution. Schumann et al. [13] compared the performance of random forest and long short-term memory (LSTM) for radar classification. Experiments showed that LSTM with an input of eight-frame sequences performs slightly better than random forests, especially in the classification of classes with a similar shape, such as pedestrians and pedestrian groups, and for false alarms. However, LSTM is more sensitive to the amount of training examples. To cope with class imbalance in radar datasets, Scheiner et al. [14] suggest using classifier binarisation techniques, which can be divided into two variants: one-vs.-all (OVA) and one-vs.-one (OVO). OVA trains N classifiers to separate one class from the other N−1 classes, and OVO trains classifiers for every class pair. During inference, the results are decided by max-voting.
3. Point Cloud Detector
End-to-end object detectors are expected to replace the conventional pipelines based on hand-crafted features. However, the convolutional neural network is not well designed for sparse data structure [15]. It is necessary to increase the input density of the radar point cloud for better performance. Dreher et al. [16] accumulated radar points into an occupancy grid mapping (OGM), then applied YOLOv3 [17] for object detection. Some works [18][19][20] utilise point cloud segmentation networks, such as PointNet [21] and PointNet++ [22], followed by a bounding box regression module for 2D radar detection. The original 3D point cloud input is replaced by a 4D radar point cloud with two spatial coordinates in the x-y plane, Doppler velocity, and RCS. Scheiner et al. [20] compared the performances of the two-stage clustering method, OGM-based method, and PointNet-based method with respect to 2D detection. Experiments showed that the OGM-based method performs best, while the PointNet-based method performs far worse than others probably due to sparsity. Liu et al. [23] suggest that incorporating global information can help with the sparsity issue of the radar point cloud. Therefore, they added a gMLP [24] block to each set abstraction layer in PointNet++. The gMLP block is expected to extract global features at an affordable computational cost.
Most radar detection methods only apply to moving targets, since static objects are difficult to classify due to low angular resolution. Schumann et al. [25] propose a scene understanding framework to detect both static and dynamic objects simultaneously. For static objects, they first built an RCS histogram grid map through the temporal integration of multiple frames and send it to a fully convolutional network (FCN) [26] for semantics segmentation. For dynamic objects, they adopted a two-branch recurrent architecture: One is the point feature generation module, which uses PointNet++ to extract features from the input point cloud. The other is the memory abstraction module, which learns temporal features from the temporal neighbours in the memorised point cloud. The resulting features are concatenated together and sent to an instance segmentation head. In addition, a memory update module is proposed to integrate targets into the memorised point cloud. Finally, static and dynamic points are combined into a single semantic point cloud. The proposed framework can successfully detect moving targets such as cars and pedestrians, as well as static targets such as parked cars, infrastructures, poles, and vegetation.
As 4D radars have gradually come to the market, radar point cloud density has increased considerably. A major advantage of 4D radar is that static objects can be classified based on elevation measurements without the need to build an occupancy grid map. Therefore, it is possible to train a single detector for both static and dynamic objects. Plaffy et al. [27] applied PointPillars [28] to 4D radar point clouds for 3D detection of multi-class road users. They found the performance can be improved by temporal integration and by introducing additional features, such as elevation, Doppler velocity, and RCS. Among them, the Doppler velocity is essential for detecting pedestrians and bicyclists. However, the performance of the proposed 4D radar detector (mAP 47.0) is still far inferior to their LiDAR detector on 64-beam LiDAR (mAP 62.1). They argue this performance gap comes from radar’s poor ability in determining the exact 3D position of objects. RPFA-Net [29] improves PointPillars by introducing a radar pillar features attention (PFA) module. It leverages self-attention to extract the global context feature from pillars. The global features are then residually connected to the original feature map and sent to a CNN-based detection network. The idea behind this is to explore the global relationship between objects for a better heading angle estimation. In fact, self-attention is basically a set operator, so it is well suited for sparse point clouds. Radar transformer et al. [30] is a classification network constructed entirely of self-attention modules. The 4D radar point cloud is first sent to an MLP network for input embedding. The following feature extraction network consists of two branches. In the local feature branch, it uses three stacked set abstraction modules [22] and vector attention modules [31] to extract hierarchical local features. In the global feature branch, the extracted local features at each hierarchy are concatenated with the global feature map at the previous hierarchy and fed into a vector attention module for feature extraction. In the last hierarchy, a scalar-attention, i.e., the conventional self-attention, is used for feature integration. Finally, the feature map is sent to a classification head. Experiments showed the proposed radar transformer outperforms other point cloud networks in terms of classification. The above two attention-based approaches show their potential in modelling the global context and extracting semantic information. Further works should focus on combining these two advantages into a fully attention-based detection network.
4. Pre-CFAR Detector
There are some attempts to explore the potential of pre-CFAR data for detection. Radar pre-CFAR data encode rich information of both targets and backgrounds, but this is hard to interpret by humans. Neural networks are expected to better utilise this information. One option is to use neural networks to replace CFAR [32] or direction of arrival (DOA) estimation [33][34]. Readers can refer to [35] for a detailed survey of learning-based DOA estimation. Alternatively, there are also some efforts to perform end-to-end detection through neural networks. The deep radar detector [36] jointly trains two cascaded networks for CFAR and DOA estimation, respectively. Zhang et al. [37] used stacked complex RD maps as the input to an FCN for 3D detection. In order to remove the DC component in phase, they performed a phase normalisation by using RD cells in the first receiver as normalisers. They argued that phase normalisation is crucial for successful training. Rebut et al. [38] designed a DDM-MIMO encoder with a complex RD map as the input. In the DDM configuration, all Tx antennas transmit signals at the same time. Instead of performing waveform separation, they directly applied range FFT and Doppler FFT to ADC signals received by Rx antennas. In this way, targets detected from different Tx antennas should be located separately with fixed Doppler shifts in the RA map. To extract these features, they designed a two-layer MIMO encoder, consisting of a dilated convolutional layer to separate Tx channels, followed by a convolutional layer to mix the information. This MIMO encoder was jointly trained with the following RA encoder, detection head, and segmentation head.
In close-field applications that require large bandwidth and high resolution, RD maps are not suitable because the extended Doppler profile can lead to false alarms. The RA map, on the other hand, does not suffer from the same problem. For each detection point on the RA map, the micro-Doppler information in slow time can be utilised for better classification. RODNet [39] uses complex RA maps as input for object detection. It performs range FFT followed by angle FFT to obtain a complex RA map for each sampled chirp. It is difficult to separate static clutter and moving objects using the RA map alone without Doppler dimension. To utilise the motion information, it samples a few chirps within a frame. Then, the sequences of RA maps corresponding to these chirps are sent to a temporal convolution layer. Specifically, it first uses 1 × 1 convolutions along the chirp dimension to aggregate temporal information. Then, a 3D convolution layer is used to extract temporal features. Finally, the features are merged along the chirp dimension by max-pooling. Experiments indicate sampling 8 chirps out of 255 can achieve a comparable performance with using the full chirp sequences.
Training neural network to utilise phase information in complex RA or RD maps is a difficult task. Alternatively, some works attempt to use the real-valued RAD tensor as the input. A key issue in using the 3D RAD tensor as the input is the curse of dimensionality. Therefore, many techniques are proposed to reduce the computational cost of 3D tensor processing. RADDet [40] normalises and reshapes the RAD tensor to an image-like data structure. The Doppler dimension is treated as the channel of 2D RA maps. Then, YOLO is applied to the RA map for object detection. One disadvantage is that this method fails to utilise the spatial distribution of Doppler velocities. Alternatively, 3D convolution can be used to extract features from all three dimensions in a 3D tensor, but requires huge computation and memory overheads [41]. RODNet [39] samples chirp sequences, as described above, to reduce input dimensionality. RTCNet [42] reduces tensor size by cropping a small cube around each point detected by CFAR and then uses 3D CNN to classify these small cubes. However, its detection performance is limited by the CFAR detector. To fully exploit the information encoded in RAD tensors, some works [43][44][45] adopt the multi-view encoder–decoder architecture. Major et al. [44] and Ouaknine et al. [45] both utilised a similar multi-view structure. The RAD tensor is projected into three 2D views. Then, three decoders extract features from these views, respectively. To fuse these features, Ouaknine et al.directly concatenated three feature maps. Major et al.recovered the tensor shape by duplicating these 2D feature maps along the missing dimension, then used a 3D convolution layer to fuse them. Next, the Doppler dimension is suppressed by pooling to recover the shape of the RA feature map. Finally, the fused feature maps are sent to a decoder for downstream segmentation tasks. Another difference is Major et al.used a skip-connection, while Ouaknine et al.adopted an ASPP [46] pathway to encode information from different resolutions. RAMP-CNN et al. [43] is also built in a multi-view architecture, but it uses three encoder–decoders for feature map extraction. Their fusion method is similar to Major’s, but in 2D.
Radar pre-CFAR data are captured in polar coordinates. For object detection, polar-to-Cartesian transformation is necessary to obtain the correct bounding box. Major et al. [44] compared three configurations for coordinate transformation: preprocessed input transformation, learning from neural networks, and transformation on a middle-layer feature map. Experiments showed applying explicit polar-to-Cartesian transformation to the last-layer feature map achieves the best performance, the implicit learning-based transformation is slightly worse, and the preprocessed transformation is far inferior to the other two. They attributed this poor performance to distorted azimuth sidelobes in the input. In fact, conventional 2D convolution is not the best choice for radar pre-CFAR data, since the range, Doppler, and azimuth dimension vary in their dynamic ranges and resolutions. Instead of 2D convolution, PolarNet [47] uses a cascade of two 1D convolutions, including a columnwise convolution to extract range-dependent features, followed by a row-wise convolution to mix information from spatial neighbours. A similar idea is used in Google’s RadarNet [48] for gesture recognition. They first extracted rangewise features, then summarised them together in the later stage. Meyer et al. [49] used an isotropic graph convolution network (GCN) [50] to encode the RAD tensor and achieved more than a 10% improvement in AP for 3D detection. They argued that the performance gain comes from the ability of GCN to aggregate information from neighbouring nodes.
Incorporating temporal information is an effective way to improve the performance of pre-CFAR detectors. There are multiple ways to add temporal information to the network. Major et al. [44] used a convolutional LSTM layer to process a sequence of feature maps from the encoder network. Experiments indicated the temporal layer enables more accurate detection and significantly better velocity estimation. Ouaknine et al. [45] compared the performance between the static model with accumulated inputs and the temporal model with stacked inputs. For the static model, RAD tensors within three frames are accumulated into one single tensor and fed to a multi-view encoder–decoder for segmentation. For the temporal model, RAD tensors within five frames are stacked to form a 4D tensor and then sent to a multi-view encoder–decoder. In each branch, multiple 3D convolution layers are used to leverage spatial–temporal information. The results show that the introduction of the temporal dimension can significantly improve detection performance. Pervsic et al. [51] discussed the effect of the number of stacked radar frames. They found too long frames will introduce many background clutter, which in turn makes it difficult for the model to learn target correspondences. According to their experiments, stacking of five frames is the most suitable choice. RODNet [39] investigates stacking multiple frames at the feature level. It concatenates the extracted per-frame features and sends them to a 3D CNN layer. For motion compensation, they applied deformable convolution [52] on the chirp dimension in the first few layers. In addition, an inception module with different temporal lengths was used in the later layers. Despite the introduction of additional computational costs, these two temporal modules significantly improve the average precision. Li et al. [53] explicitly modelled the temporal relationship between features extracted from two consecutive frames using an attention module. Firstly, they stacked RA maps in two orders, i.e., current frame on top and previous frame on top. Then, they used two encoders to extract features from these two inputs and concatenated the features together. A positional encoding was further added to compensate the positional imprecision. Next, the features were sent to a masked attention module. The mask was used to disable cross-object attention in the same frame. Finally, the temporally enhanced features were sent to an encoder for object detection. This attention-based approach is more semantically interpretable and avoids the locality constraint induced by convolution.
References
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21.
- Richards, M.A. Fundamentals of Radar Signal Processing; Tata McGraw-Hill Education: New York, NY, USA, 2005.
- Cao, Z.; Fang, W.; Song, Y.; He, L.; Song, C.; Xu, Z. DNN-Based Peak Sequence Classification CFAR Detection Algorithm for High-Resolution FMCW Radar. IEEE Trans. Geosci. Remote Sens. 2021, 60.
- Lin, C.H.; Lin, Y.C.; Bai, Y.; Chung, W.H.; Lee, T.S.; Huttunen, H. DL-CFAR: A Novel CFAR target detection method based on deep learning. In Proceedings of the 2019 IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–6.
- Scheiner, N.; Schumann, O.; Kraus, F.; Appenrodt, N.; Dickmann, J.; Sick, B. Off-the-shelf sensor vs. experimental radar-How much resolution is necessary in automotive radar classification? In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8.
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Comparing Different Clustering Algorithms on Toy Datasets. Available online: https://scikit-learn.org/0.15/auto_examples/cluster/plot_cluster_comparison.html#example-cluster-plot-cluster-comparison-py (accessed on 1 May 2022).
- Kellner, D.; Klappstein, J.; Dietmayer, K. Grid-based DBSCAN for clustering extended objects in radar data. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium (IV), Alcala de Henares, Spain, 3–7 June 2012; pp. 365–370.
- Scheiner, N.; Appenrodt, N.; Dickmann, J.; Sick, B. A multi-stage clustering framework for automotive radar data. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2060–2067.
- Angelov, A.; Robertson, A.; Murray-Smith, R.; Fioranelli, F. Practical classification of different moving targets using automotive radar and deep neural networks. IET Radar Sonar Navig. 2018, 12, 1082–1089.
- Gao, X.; Xing, G.; Roy, S.; Liu, H. Experiments with mmwave automotive radar test-bed. In Proceedings of the 2019 53rd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 3–6 November 2019; pp. 1–6.
- Cai, X.; Giallorenzo, M.; Sarabandi, K. Machine Learning-Based Target Classification for MMW Radar in Autonomous Driving. IEEE Trans. Intell. Veh. 2021, 6, 678–689.
- Scheiner, N.; Appenrodt, N.; Dickmann, J.; Sick, B. Radar-based road user classification and novelty detection with recurrent neural network ensembles. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 722–729.
- Schumann, O.; Wöhler, C.; Hahn, M.; Dickmann, J. Comparison of random forest and long short-term memory network performances in classification tasks using radar. In Proceedings of the 2017 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 10–12 October 2017; pp. 1–6.
- Scheiner, N.; Appenrodt, N.; Dickmann, J.; Sick, B. Radar-based feature design and multiclass classification for road user recognition. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, Suzhou, China, 26–30 June 2018; pp. 779–786.
- Graham, B.; van der Maaten, L. Submanifold sparse convolutional networks. arXiv 2017, arXiv:1706.01307.
- Dreher, M.; Erçelik, E.; Bänziger, T.; Knol, A. Radar-based 2D Car Detection Using Deep Neural Networks. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8.
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767.
- Schumann, O.; Hahn, M.; Dickmann, J.; Wöhler, C. Semantic segmentation on radar point clouds. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 2179–2186.
- Danzer, A.; Griebel, T.; Bach, M.; Dietmayer, K. 2d car detection in radar data with pointnets. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 61–66.
- Scheiner, N.; Kraus, F.; Appenrodt, N.; Dickmann, J.; Sick, B. Object detection for automotive radar point clouds—A comparison. AI Perspect. 2021, 3, 1–23.
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660.
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–7 December 2017; Volume 30.
- Liu, J.; Xiong, W.; Bai, L.; Xia, Y.; Huang, T.; Ouyang, W.; Zhu, B. Deep Instance Segmentation with Automotive Radar Detection Points. IEEE Trans. Intell. Transp. Syst. 2022.
- Liu, H.; Dai, Z.; So, D.; Le, Q. Pay attention to MLPs. In Proceedings of the Advances in Neural Information Processing Systems 2021, Virtual, 6–14 December 2021; Volume 34.
- Schumann, O.; Lombacher, J.; Hahn, M.; Wöhler, C.; Dickmann, J. Scene understanding with automotive radar. IEEE Trans. Intell. Veh. 2019, 5, 188–203.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Palffy, A.; Pool, E.; Baratam, S.; Kooij, J.; Gavrila, D. Multi-class Road User Detection with 3+ 1D Radar in the View-of-Delft Dataset. IEEE Robot. Autom. Lett. 2022, 7, 4961–4968.
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705.
- Xu, B.; Zhang, X.; Wang, L.; Hu, X.; Li, Z.; Pan, S.; Li, J.; Deng, Y. RPFA-Net: A 4D RaDAR Pillar Feature Attention Network for 3D Object Detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3061–3066.
- Bai, J.; Zheng, L.; Li, S.; Tan, B.; Chen, S.; Huang, L. Radar transformer: An object classification network based on 4d mmw imaging radar. Sensors 2021, 21, 3854.
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 10076–10085.
- Cheng, Y.; Su, J.; Chen, H.; Liu, Y. A New Automotive Radar 4D Point Clouds Detector by Using Deep Learning. In Proceedings of the 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 6–11 June 2021; pp. 8398–8402.
- Grimm, C.; Fei, T.; Warsitz, E.; Farhoud, R.; Breddermann, T.; Haeb-Umbach, R. Warping of Radar Data into Camera Image for Cross-Modal Supervision in Automotive Applications. arXiv 2020, arXiv:2012.12809.
- Gall, M.; Gardill, M.; Horn, T.; Fuchs, J. Spectrum-based single-snapshot super-resolution direction-of-arrival estimation using deep learning. In Proceedings of the 2020 German Microwave Conference (GeMiC), Cottbus, Germany, 9–11 March 2020; pp. 184–187.
- Fuchs, J.; Gardill, M.; Lübke, M.; Dubey, A.; Lurz, F. A Machine Learning Perspective on Automotive Radar Direction of Arrival Estimation. IEEE Access 2022, 10, 6775–6797.
- Brodeski, D.; Bilik, I.; Giryes, R. Deep radar detector. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6.
- Zhang, G.; Li, H.; Wenger, F. Object detection and 3d estimation via an FMCW radar using a fully convolutional network. In Proceedings of the 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 4487–4491.
- Rebut, J.; Ouaknine, A.; Malik, W.; Pérez, P. Raw High-Definition Radar for Multi-Task Learning. arXiv 2021, arXiv:2112.10646.
- Wang, Y.; Jiang, Z.; Li, Y.; Hwang, J.N.; Xing, G.; Liu, H. RODNet: A Real-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization. IEEE J. Sel. Top. Signal Process. 2021, 15, 954–967.
- Zhang, A.; Nowruzi, F.E.; Laganiere, R. RADDet: Range-Azimuth-Doppler based radar object detection for dynamic road users. In Proceedings of the 2021 18th Conference on Robots and Vision (CRV), Burnaby, BC, Canada, 26–28 May 2021; pp. 95–102.
- Mittal, S.; Vibhu. A survey of accelerator architectures for 3D convolution neural networks. J. Syst. Archit. 2021, 115, 102041.
- Palffy, A.; Dong, J.; Kooij, J.F.; Gavrila, D.M. CNN based road user detection using the 3D radar cube. IEEE Robot. Autom. Lett. 2020, 5, 1263–1270.
- Gao, X.; Xing, G.; Roy, S.; Liu, H. Ramp-cnn: A novel neural network for enhanced automotive radar object recognition. IEEE Sens. J. 2020, 21, 5119–5132.
- Major, B.; Fontijne, D.; Ansari, A.; Teja Sukhavasi, R.; Gowaikar, R.; Hamilton, M.; Lee, S.; Grzechnik, S.; Subramanian, S. Vehicle detection with automotive radar using deep learning on range-azimuth-Doppler tensors. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCV Workshop), Seoul, Korea, 27 October–2 November 2019.
- Ouaknine, A.; Newson, A.; Pérez, P.; Tupin, F.; Rebut, J. Multi-View Radar Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 15671–15680.
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587.
- Nowruzi, F.E.; Kolhatkar, D.; Kapoor, P.; Heravi, E.J.; Hassanat, F.A.; Laganiere, R.; Rebut, J.; Malik, W. PolarNet: Accelerated Deep Open Space Segmentation Using Automotive Radar in Polar Domain. arXiv 2021, arXiv:2103.03387.
- Hayashi, E.; Lien, J.; Gillian, N.; Giusti, L.; Weber, D.; Yamanaka, J.; Bedal, L.; Poupyrev, I. Radarnet: Efficient gesture recognition technique utilizing a miniature radar sensor. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI), Yokohama, Japan, 8–13 May 2021; pp. 1–14.
- Meyer, M.; Kuschk, G.; Tomforde, S. Graph convolutional networks for 3d object detection on radar data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 3060–3069.
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907.
- Peršić, J.; Petrović, L.; Marković, I.; Petrović, I. Spatio-temporal multisensor calibration based on gaussian processes moving object tracking. arXiv 2019, arXiv:1904.04187.
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773.
- Li, P.; Wang, P.; Berntorp, K.; Liu, H. Exploiting Temporal Relations on Radar Perception for Autonomous Driving. arXiv 2022, arXiv:2204.01184.
More
Information
Contributors
MDPI registered users' name will be linked to their SciProfiles pages. To register with us, please refer to https://encyclopedia.pub/register
:
View Times:
3.4K
Revisions:
2 times
(View History)
Update Date:
07 Jun 2022
Table of Contents


Notice
You are not a member of the advisory board for this topic. If you want to update advisory board member profile, please contact office@encyclopedia.pub.
OK
Confirm
Only members of the Encyclopedia advisory board for this topic are allowed to note entries. Would you like to become an advisory board member of the Encyclopedia?
Yes
No
${ textCharacter }/${ maxCharacter }
Submit
Cancel
Back
Comments
${ item }
|
${ item.createdUser.fullName }
${ item.createdAt }
${ item.vote }
${ item.reply }
Delete
${ reply.createdUser.fullName }
${ reply.createdAt }
${ reply.vote }
Delete
There is no reply to this comment~
${ item.replyTextCharacter }/${ item.replyMaxCharacter }
Submit
Cancel
More
No more~
There is no comment~
${ textCharacter }/${ maxCharacter }
Submit
Cancel
${ selectedItem.replyTextCharacter }/${ selectedItem.replyMaxCharacter }
Submit
Cancel
Confirm
Are you sure to Delete?
Yes
No