 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Ilias Kalouptsoglou | -- | 2028 | 2022-06-01 13:11:56 | | | |
| 2 | Ilias Kalouptsoglou | + 2 word(s) | 2030 | 2022-06-01 13:48:36 | | | | |
| 3 | Dean Liu | -9 word(s) | 2021 | 2022-06-02 04:19:43 | | |
Video Upload Options
Vulnerability prediction is a mechanism that facilitates the identification (and, in turn, the mitigation) of vulnerabilities early enough during the software development cycle. The scientific community has recently focused a lot of attention on developing Deep Learning models using text mining techniques and software metrics for predicting the existence of vulnerabilities in software components. However, limited attention has been given on the comparison and the combination of text mining- based and software metrics- based vulnerability prediction models.
1. Introduction
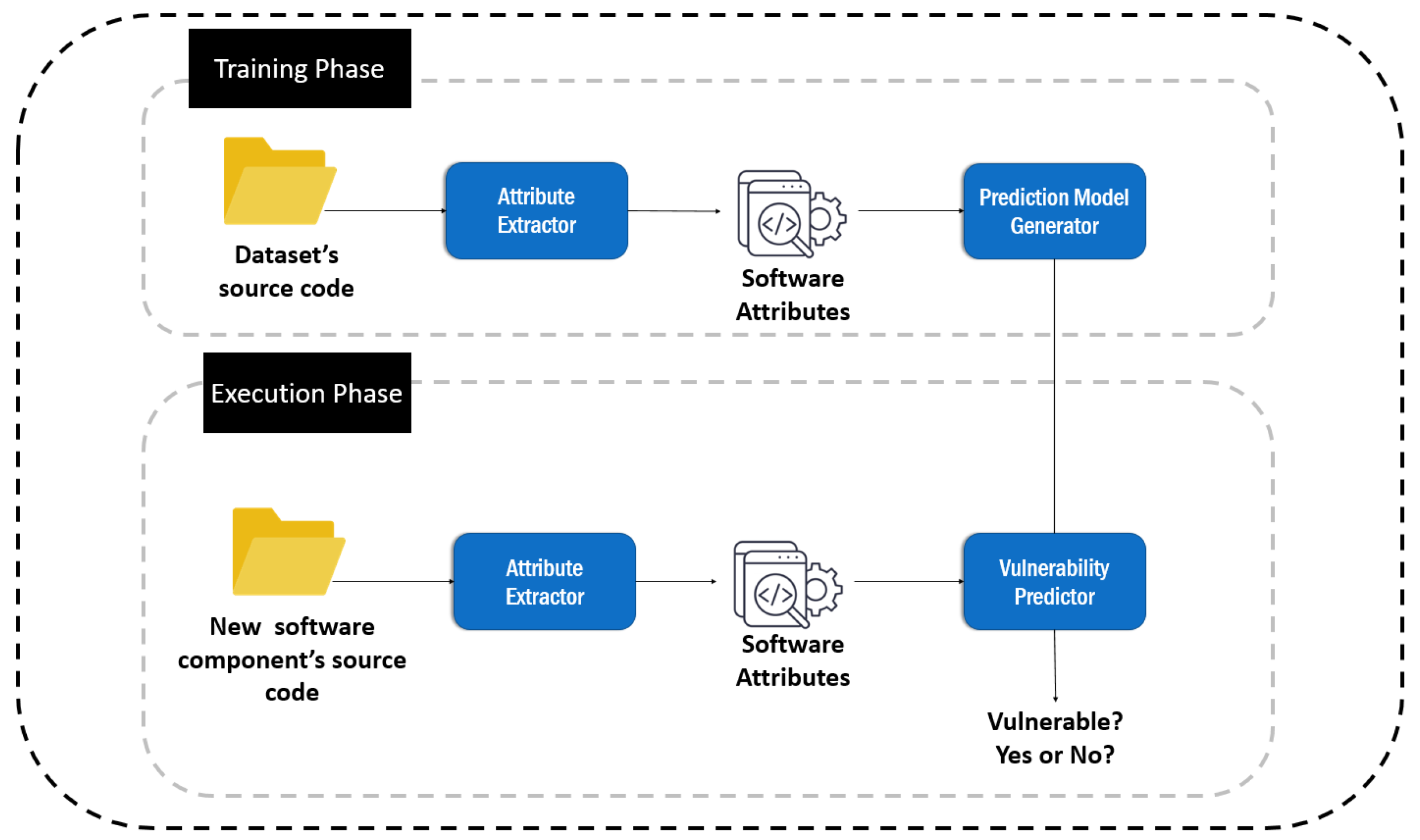
2. Vulnerability Prediction
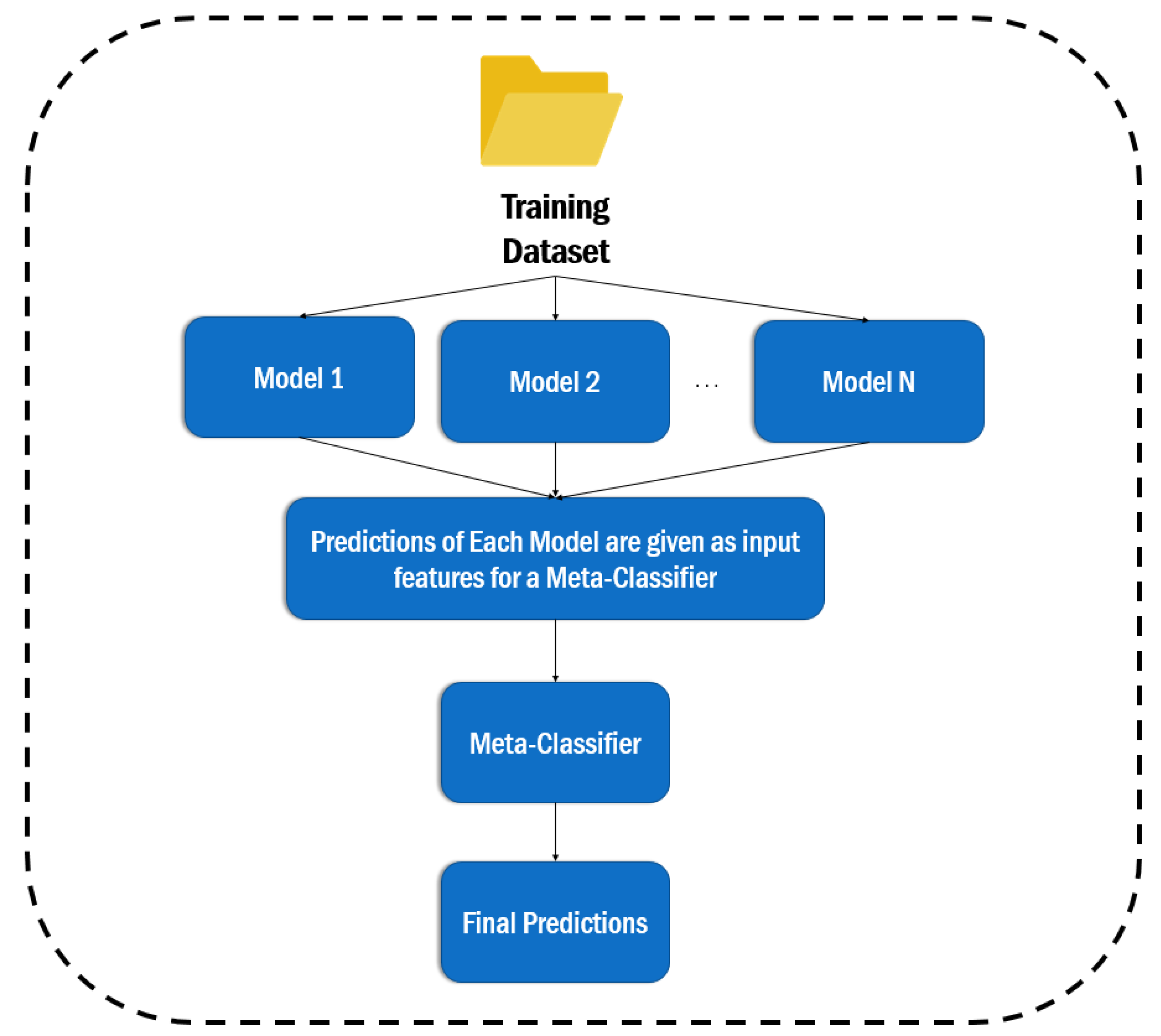
3. Ensemble Learning
4. Comparison between software metrics- based and text mining- based models
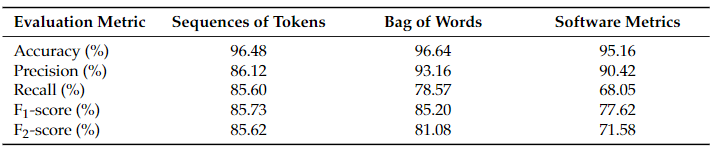
In comparison with the software metrics approach, it can be seen (Table 1) that the sequence-based CNN models outperform the software metrics-based models. In particular, the best CNN model achieves an F1-score of 85.73% and an F2-score of 85.62%, which is 8% and 14% higher than the F1-score and F2-score respectively of the best software metrics-based model. In comparison with the Bag of Words (BoW) approach, the sequence-based models still demonstrate better predictive performance; however, the difference in the performance is much smaller compared to the metrics-based models, at least with respect to their F1-score and F2-score. This could be expected by the fact that those approaches are similar in nature (i.e., they are both text mining approaches), and their difference lies in the way how the text tokens are represented. In fact, the improvement that the sequence-based models introduce is that instead of taking as input the occurrences of the tokens in the code, they take as input their sequence inside the source code, potentially allowing them to detect more complex code patterns, and, thus, this improvement in the predictive performance could be attributed to those complex patterns. In general, from the above analysis one can notice that text mining-based models (either based on BoW or on the sequences of tokens) provide better results in vulnerability prediction than the software metrics-based models.
Table 1. A table with the evaluation scores of both text mining–based and software metrics–based models.
5. Hybrid model combining software metrics- based and text mining- based models
Four classifiers were repeatedly trained in nine folds of the dataset, two of them are based on software metrics (Support Vector Machine, Random Forest), and two are based on text mining (i.e., BoW, sequences of tokens). Then predictions were made with each classifier, and the predicted probabilities were saved. These probabilities constituted the input of the Random Forest meta-classifier. This meta-classifier was trained on the output of the first ones, and it was evaluated in a second Cross Validation loop. Figure 3 illustrates the overview of this approach.
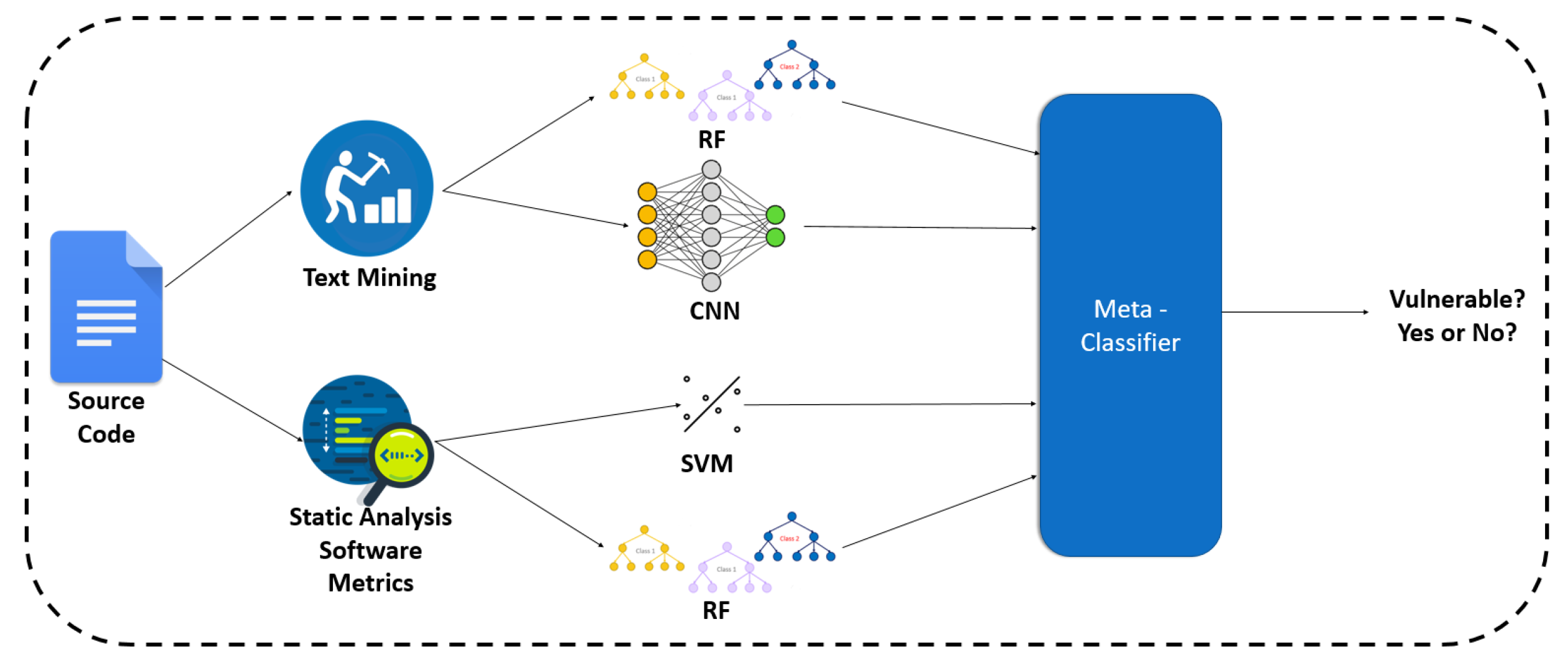
Figure 3. The overview of the stacking approach between text mining and software metrics.
Table 2 presents the produced results.
Table 2. Stacking classifier evaluation.
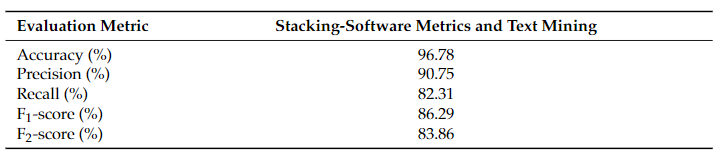
Based on Table 1 and Table 2, the combination of statically extracted code metrics and text features (either BoW or sequences of tokens) did not manage to surpass the text mining approach, at least on this specific dataset. The fact that the ensemble learning classifiers did not produce better results leads to the conclusion that almost all the right predictions of the software metrics-based models are included in the right decisions of the text mining-based model and so, there are no errors to be compensated.
6. Conclusion
This analysis led to the conclusion that text mining is an effective solution for vulnerability prediction, while it is superior to software metrics utilization. More specifically, both Bag of Words and token sequences approaches provided better results than the software metrics-based models. Another interesting observation that was made by this analysis is that the combination of software metrics with text features did not lead to more accurate vulnerability prediction models. Although their predictive performance was found to be sufficient, it did not manage to surpass the predictive performance of the already strong text mining-based vulnerability prediction models.
References
- Shin, Y.; Williams, L. Is complexity really the enemy of software security? In Proceedings of the 4th ACM Workshop on Qualityof Protection, Alexandria, VA, USA, 27 October 2008; pp. 47–50.
- Shin, Y.; Williams, L. An empirical model to predict security vulnerabilities using code complexity metrics. In Proceedings of theSecond ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, Kaiserslautern, Germany,9 October 2008; pp. 315–317.
- Chowdhury, I.; Zulkernine, M.; Using complexity, coupling, and cohesion metrics as early indicators of vulnerabilities. J. Syst.Archit. 2011, 57, 294–313.
- Pang, Y.; Xue, X.; Wang, H. Predicting vulnerable software components through deep neural network. In Proceedings of the 2017International Conference on Deep Learning Technologies, Chengdu, China, 2 June 2017; pp. 6–10.
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerabilitydetection.arXiv2018, arXiv:1801.01681.
- Zheng, J.; Williams, L.; Nagappan, N.; Snipes, W.; Hudepohl, J.P.; Vouk, M.A; On the value of static analysis for fault detection insoftware. IEEE Trans. Softw. Eng. 2006, 32, 240–253.
- Gegick, M.; Williams, L. Toward the use of automated static analysis alerts for early identification of vulnerability-and attack-prone components. In Proceedings of the Second International Conference on Internet Monitoring and Protection (ICIMP 2007),San Jose, CA, USA, 1–5 July 2007; pp. 18–18.
- Neuhaus, S.; Zimmermann, T.; Holler, C.; Zeller, A. Predicting vulnerable software components. In Proceedings of the 14th ACMConference on Computer and Communications Security, Alexandria, VA, USA, 2 November 2007; pp. 529–540.
- Hovsepyan, A.; Scandariato, R.; Joosen, W.; Walden, J. Software vulnerability prediction using text analysis techniques.In Proceedings of the 4th International Workshop on Security Measurements and Metrics, Lund, Sweden, 21 September 2012;pp. 7–10.
- Walden, J.; Stuckman, J.; Scandariato, R. Predicting vulnerable components: Software metrics vs text mining. In Proceedings ofthe 2014 IEEE 25th International Symposium on Software Reliability Engineering, Naples, Italy, 3–6 November 2014; pp. 23–33.
- Zhang, Y.; Lo, D.; Xia, X.; Xu, B.; Sun, J.; Li, S. Combining software metrics and text features for vulnerable file prediction. InProceedings of the 2015 20th International Conference on Engineering of Complex Computer Systems (ICECCS), Gold Coast,Australia, 9–12 December 2015; pp. 40–49.
- Ferenc, R.; Heged ̋us, P.; Gyimesi, P.; Antal, G.; Bán, D.; Gyimóthy, T. Challenging machine learning algorithms in predictingvulnerable javascript functions. In Proceedings of the 2019 IEEE/ACM 7th International Workshop on Realizing ArtificialIntelligence Synergies in Software Engineering (RAISE), Montreal, QC, Canada, 28–28 May 2019; pp. 8–14.
- Sagi, O.; Rokach, L; Ensemble learning: A survey.. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249.
- Subramanyam, R.; Krishnan, M.S; Empirical analysis of ck metrics for object-oriented design complexity: Implications forsoftware defects.. IEEE Trans. Softw. Eng. 2003, 29, 297–310.
- Goyal, P.K.; Joshi, G. QMOOD metric sets to assess quality of Java program. In Proceedings of the 2014 International Conferenceon Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 7–8 February 2014; pp. 520–533.
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space.arXiv2013,arXiv:1301.3781
- Breiman, L. Bagging predictors.Mach. Learn.1996,24, 123–140.

