Protein solubility is an important thermodynamic parameter that is critical for the characterization of a protein’s function, and a key determinant for the production yield of a protein in both the research setting and within industrial (e.g., pharmaceutical) applications. Experimental approaches to predict protein solubility are costly, time-consuming, and frequently offer only low success rates. To reduce cost and expedite the development of therapeutic and industrially relevant proteins, a highly accurate computational tool for predicting protein solubility from protein sequence is sought. While a number of in silico prediction tools exist, they suffer from relatively low prediction accuracy, bias toward the soluble proteins, and limited applicability for various classes of proteins. In this study, researchers developed a novel deep learning sequence-based solubility predictor, DSResSol, that takes advantage of the integration of squeeze excitation residual networks with dilated convolutional neural networks and outperforms all existing protein solubility prediction models. This model captures the frequently occurring amino acid k-mers and their local and global interactions and highlights the importance of identifying long-range interaction information between amino acid k-mers to achieve improved accuracy, using only protein sequence as input. DSResSol outperforms all available sequence-based solubility predictors by at least 5% in terms of accuracy when evaluated by two different independent test sets. Compared to existing predictors, DSResSol not only reduces prediction bias for insoluble proteins but also predicts soluble proteins within the test sets with an accuracy that is at least 13% higher than existing models. Researchers derive the key amino acids, dipeptides, and tripeptides contributing to protein solubility, identifying glutamic acid and serine as critical amino acids for protein solubility prediction. Overall, DSResSol can be used for the fast, reliable, and inexpensive prediction of a protein’s solubility to guide experimental design.
1. Introduction
Solubility is a fundamental protein property, that can give useful insights into the protein’s function or potential usability, for example, in foams, emulsions, and gels
[1], and therapeutics applications such as drug delivery
[2][3]. In practice, the analysis of protein solubility is the most important determinant of success (i.e., high yields) in therapeutic protein and protein-based drug production
[4][5]. In the research setting, producing a soluble recombinant protein is essential for investigating the functional and structural properties of the molecule
[6]. To improve yields experimentally, there exist certain refolding methods that utilize weak promoters and fusion proteins or optimize expression conditions, e.g., by using low temperatures
[4][5]. However, these methods cannot ensure the production of soluble proteins from a relatively small trial batch size as they are limited by production cost and time. Given these concerns, reliable computational approaches for discovering potentially soluble protein targets for experimental testing can help to avoid expensive experimental trial and error approaches.
A protein’s structure and sequence features such as the isoelectric point, polarity, hydrophobicity, turn-forming amino acids, etc., are crucial intrinsic factors in protein solubility determination
[7][8][9]. On this basis, several in silico approaches have been developed to predict protein solubility by using the protein sequence and its features. The majority of these tools use traditional machine learning models such as support vector machines (SVM)
[10] and gradient boosting machines
[11], employing pre-extracted features (i.e., features that are extracted from the protein sequences via other bioinformatics tools before being fed into machine learning models) as input for these models. For example, SOLpro employs two-stage SVM models for training 23 extracted features from the protein sequences
[5]. PROSO II utilizes a two-layered structure, including the Parzen window
[12] and first level logistic regression models as the first layer and a second-level logistic regression model as the second layer
[13]. In more recent models such as PaRSnIP
[14], gradient boosting machine models are used. This predictor utilizes the frequency of mono-, di-, and tripeptides from the protein sequence in addition to other biological features such as secondary structure, and the fraction of exposed residues in different solvent accessibility cutoffs as training features. SoluProt is the newest solubility predictor using a gradient boosting machine for training
[15]. To evaluate the performance of this tool, a new independent test set was utilized. Notably, the frequency of important dimers extracted from the protein sequences was used as an input feature of the SoluProt model
[15]. All the aforementioned models are two-stage models, with a first stage set up for extracting and selecting features and a second stage employed for classification. Deep learning (DL) models circumvent the need for a two-stage model. DeepSol is the first deep learning-based solubility predictor proposed by Khurana and coworkers
[16] built as a single stage predictor through the use of parallel convolutional neural network layers
[17] with different filter sizes to extract high dimensional structures encoding frequent amino acid k-mers and their non-linear local interactions from the protein sequence as distinguishable features for protein solubility classification
[16].
In this study, a novel deep learning architecture and framework is proposed to create a sequence-based solubility predictor that outperforms all currently available state-of-the-art predictors: Dilated Squeeze excitation Residual network Solubility predictor (DSResSol). Specifically, researchers employ parallel Squeeze-and-Excitation residual network blocks that include dilated convolutional neural network layers (D-CNNs)
[18], residual networks blocks (ResNet)
[19], and Squeeze-and-Excitation (SE) neural network blocks
[20] to capture not only extracted high dimensional amino acid k-mers from the input protein sequence but also both local and long-range interactions between amino acid k-mers, thereby increasing the information extracted by the model from the protein sequence. This framework can capture independent, non-linear interactions between amino acid residues without increasing the training parameters and run time and offers a significant improvement in performance compared to other models. Our work is inspired by recent studies using dilated convolutional neural networks and SE-ResNet for protein sequence and text classification
[21][22].
The traditional method to capture long-range interactions in data and to solve vanishing gradient problems is to use Bidirectional Long Short-Term (BLSTM) memory networks
[23][24]. However, BLSTM implementation significantly increases the number of parameters in the model. Thus, researchers use D-CNNs instead of BLSTM because D-CNNs perform simple CNN operations, but over every
nth element in the protein sequence, resulting in captured long-range interactions between amino acid k-mers. ResNet is a recent advance in neural networks that utilizes skip connections to jump over network layers to avoid the vanishing gradient problem and gradually learns the feature vectors with many fewer parameters
[19]. The Squeeze-and-Excitation (SE) neural network explicitly blocks model interdependencies between channels, thereby directing higher importance to specific channels within the feature maps over others. Thus, by designing a novel architecture that combines these three neural networks in a specific manner together with parallel CNNs layers, a highly accurate solubility predictor is built. In the first model instance, DSResSol (1), researchers use only protein sequence as input and protein solubility as output. The second model instance, DSResSol (2), includes pre-extracted biological features added to the model as a hidden layer to improve the model’s performance. DSResSol is evaluated on two different independent test sets and is the first protein solubility predictor outperforming all existing tools on two distinct test sets, confirming its useability for different classes of proteins expressed in various host cells. By contrast, all existing tools have been built to work on a single test set for a specific class of proteins. DSResSol shows an improvement in accuracy of up to 13% compared with existing tools. Additionally, DSResSol reduces bias within the insoluble protein class compared to existing tools. researchers further investigate the most important single amino acids, dipeptides, and tripeptides contributing to protein solubility, which are directly extracted from feature maps in layers of the DSResSol architecture, with close alignment to experimental findings. Researchers find that DSResSol is a reliable predictive tool that can be used for possible soluble and insoluble protein targets, achieving high accuracy, with improved relevance for guiding experimental studies.
2. Model Performance
A 10-fold cross-validation is performed for the training process. In each cross-validation step, the training set is divided into ten parts where nine parts are used for training and one part is used for validation. The performance of the DSResSol model is reported by using the ten models. To evaluate the stability in performance results, researchers use four different metrics: accuracy, precision, recall, and F1-score.
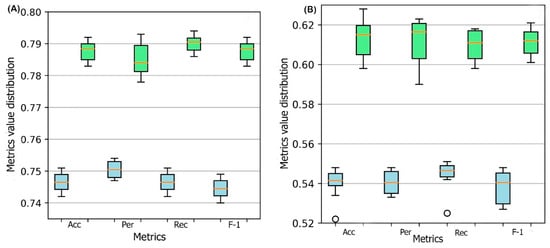
Figure 1 represents the box plots of these metrics for all ten models obtained through 10-fold cross-validation for both DSResSol (1) and DSResSol (2) on both independent test sets. Notably, the variance in box plots corresponding to each metric for both DSResSol (1) and DSResSol (2) is very small, highlighting the outstanding stability in the performance of the DSResSol predictor. For example, for DSResSol (2), among 10 models, the best model has an accuracy of 79.2% and the weakest model has an accuracy of 78.4%, with a variance of 0.8% (
Tables S1 and S2).
Figure 1. Box plot for 10 models obtained from 10-fold cross-validation for both DSResSol (1) and DSResSol (2) considering four metrics: ACC (accuracy), Per (precision), Rec (recall), and F-1 (f-1 score) for (
A) Chang et al. test set
[25], (
B) NESG test set. Note: blue and green box plots represent the score distribution for DSResSol (1) and DSResSol (2), respectively.
It is worth noting that the reason for significant differences between the performance of the model on the first and second test sets is not due to overfitting or overtraining. The difference between accuracy in training and validation for both DSResSol 1 and DSResSol (2) is less than 1.5% (
Tables S1 and S2), suggesting that neither model has an overfitting problem. Therefore, researchers conclude that the difference between the performance in different test sets originates from the nature of the test sets. Specifically, the protein sequences within the second test set are expressed in
E. coli. while, for the training process, researchers used a training set that includes mixed proteins (expressed in
E. coli or other host cells) to achieve a more comprehensive model (
Table 1).
Table 1. Performance of DSResSol in comparison with known existing models on first independent test set
[25]. Note: Best performing method is in bold.
| Model |
ACC |
MMC |
Selectivity
(Soluble) |
Selectivity
(Insoluble) |
Sensitivity
(Soluble) |
Sensitivity
(Insoluble) |
Gain
(Soluble) |
Gain
(Insoluble) |
| DSResSol (2) |
0.796 |
0.589 |
0.817 |
0.782 |
0.769 |
0.823 |
1.634 |
1.564 |
| DSResSol (1) |
0.751 |
0.508 |
0.786 |
0.722 |
0.691 |
0.813 |
1.572 |
1.445 |
| SoluProt |
0.682 |
0.382 |
0.701 |
0.670 |
0.722 |
0.643 |
1.403 |
1.342 |
| DeepSol S2 |
0.762 |
0.546 |
0.821 |
0.721 |
0.681 |
0.843 |
1.642 |
1.442 |
| DeepSol S3 |
0.760 |
0.543 |
0.801 |
0.725 |
0.707 |
0.822 |
1.602 |
1.451 |
| PaRSnIP |
0.720 |
0.472 |
0.761 |
0.723 |
0.698 |
0.743 |
1.522 |
1.446 |
| DeepSol S1 |
0.720 |
0.471 |
0.752 |
0.706 |
0.691 |
0.749 |
1.504 |
1.412 |
| PROSSO II |
0.638 |
0.345 |
0.671 |
0.682 |
0.693 |
0.662 |
1.342 |
1.365 |
| SCM |
0.600 |
0.214 |
0.650 |
0.572 |
0.422 |
0.773 |
1.301 |
1.145 |
| PROSO |
0.581 |
0.161 |
0.582 |
0.575 |
0.541 |
0.622 |
1.164 |
1.151 |
| CCSOL |
0.543 |
0.083 |
0.543 |
0.539 |
0.514 |
0.572 |
1.087 |
1.081 |
| RPSP |
0.520 |
0.032 |
0.522 |
0.517 |
0.447 |
0.588 |
1.044 |
1.035 |
To compare the performance of DSResSol with the best existing prediction tools, two different testing sets are employed, the first one proposed by Chang et al.
[25] and the second one, NESG dataset, proposed by Price et al.
[26] and refined by Hon et al.
[15].
Table 1 and
Table 2 display the performance of eight solubility predictors on both test sets. DSResSol (2) outperforms all available sequence-based predictor tools when the performance is assessed by accuracy, MCC, sensitivity for soluble proteins, selectivity for insoluble proteins, and gain for insoluble proteins.
Table 2. Performance of DSResSol in comparison with known existing models on NESG test set
[15]. Note: Best performing method is in bold.
| Method |
ACC |
MCC |
Selectivity (Soluble) |
Selectivity (Insoluble) |
Sensitivity (Soluble) |
Sensitivity (Insoluble) |
Gain (Soluble) |
Gain (Insoluble) |
| DSResSol (2) |
0.629 |
0.273 |
0.606 |
0.663 |
0.73 |
0.53 |
1.212 |
1.326 |
| DSResSol (1) |
0.557 |
0.169 |
0.558 |
0.555 |
0.54 |
0.58 |
1.117 |
1.11 |
| SoluProt |
0.578 |
0.189 |
0.575 |
0.581 |
0.6 |
0.56 |
1.15 |
1.162 |
| PROSSO II |
0.565 |
0.143 |
0.578 |
0.555 |
0.48 |
0.66 |
1.157 |
1.11 |
| SWI |
0.558 |
0.142 |
0.545 |
0.58 |
0.7 |
0.42 |
1.09 |
1.16 |
| CamSol |
0.535 |
0.115 |
0.548 |
0.527 |
0.39 |
0.68 |
1.097 |
1.054 |
| ESPRESSO |
0.493 |
0.093 |
0.493 |
0.492 |
0.55 |
0.44 |
0.987 |
0.984 |
| rWH |
0.519 |
0.133 |
0.532 |
0.513 |
0.31 |
0.73 |
1.065 |
1.026 |
| DeepSol S2 |
0.546 |
0.132 |
0.894 |
0.56 |
0.22 |
0.88 |
1.788 |
1.12 |
| SOLpro |
0.5 |
0.089 |
0.5 |
0.5 |
0.48 |
0.52 |
1 |
1 |
For the first test set, researchers find that only the sensitivity value for the insoluble class, and the selectivity value for the soluble class were slightly inferior to the close competitor, DeepSol S2
[16]. The accuracy and MCC of DSResSol (2) are higher compared to DeepSol by at least 4% and 7%, respectively (
Table 1). In addition, the sensitivity of DSResSol (2) for both soluble and insoluble proteins is close in value, suggesting that the DSResSol (2) model can predict both soluble and insoluble protein sequences with high accuracy and minimal bias. This consistency is missing in DeepSol S2 and DeepSol S3, the most accurate predictors to date. The sensitivity of DSResSol (2) for insoluble protein is about 83% which is comparable to the current best predictor (DeepSol S2 = 85%). On the other hand, DSResSol (2) can identify soluble proteins with higher predictive accuracy (77%) than all existing models, including DeepSol S2 (68%), DeepSol S3 (70%), and PaRSnIP (70%). There is a 16.2% and 12.7% difference in sensitivity between soluble and insoluble classes, for DeepSol S2 and DeepSol S3, respectively, where the insoluble class is predicted with higher accuracy. By contrast, the difference for the DSResSol (2) model is less than 6%, representing the outstanding capability of DSResSol (2) for identifying both soluble and insoluble classes and thereby reducing prediction bias.
The DSResSol (1) model performs comparably to DeepSol S2 and DeepSol S3 models and outperforms other models such as PaRSnIP and DeepSol S1. The performance of DSResSol (1) is competitive with DeepSol S2 and DeepSol S3; notably, however, in contrast to DeepSol S2 and DeepSol S3, DSResSol (1) obtains a similar performance without additional biological features as complimentary information in the training process. The accuracy of DSResSol (1) is only 1% lower than DeepSol S2, and higher by at least 4% in accuracy and 7% in MCC than DeepSol S1, suggesting that our proposed model architecture can capture more meaningful information from the protein sequence than DeepSol S1 by using only protein sequence as input for the training process.
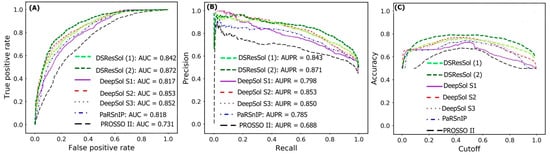
Figure 2A,B show the Receiver Operating Characteristic (ROC) curve and the recall vs. precision curve for seven different solubility predictors, using the first independent test set
[25]. The area under curve (AUC) and area under precision recall curve (AUPR) for DSResSol (2) are 0.871 and 0.872, respectively, which is at least 2% higher than other models confirming that the DSResSol (2) model outperforms other state-of-the-art available predictors.
Figure 2C shows the accuracy of models in different probability threshold cutoffs. The highest accuracy for DSResSol (2) and DSResSol (1) is achieved at the probability thresholds equal to 0.5. This achieved result is due to using a balanced training and testing set.
Figure 2. Comparison of the performance of DSResSol models with DeepSol
[16] and PaRSnIP
[14] models. (
A) Receiver operating curve (ROC), (
B) recall-precision curve, (
C) accuracy-threshold cutoffs curve. The cutoff threshold discriminates between the soluble and the insoluble proteins. The curve for PROSSO II is obtained with permission from Bioinformatics
[16].
For the second test set, (the newest test set to date), the performances of both models are evaluated and compared with eight different available sequence-based tools.
Table 2 represents the performance of the DSResSol models on the NESG test set. Evaluation metrics include both threshold-dependent metrics such as accuracy and MCC as well as threshold-independent metrics such as area under ROC curve value. The results represent that the accuracy and MCC of DSResSol (2) is at least 5% and 50% more than SoluProt tools, respectively. Furthermore, DSResSol (2) achieves the highest AUC value (0.68) among other tested solubility predictors on the second independent test set. The DSResSol (1) model, using only protein sequences for training, achieves comparable results with other tools such as SoluProt
[15] and PROSSO II
[13]. The accuracy value for DSResSol (1) only is 2% lower than the best competitor (SoluProt). This demonstrates an outstanding performance of the DSResSol (1) model which does not take advantage of using additional biological features for training, confirming that DSResSol (1) indeed captures the most meaningful features from the protein sequence to distinguish soluble proteins from insoluble ones. Furthermore, the sensitivity of DSResSol (2) for soluble proteins is 73% which is significantly higher than SoluProt (at 13%).
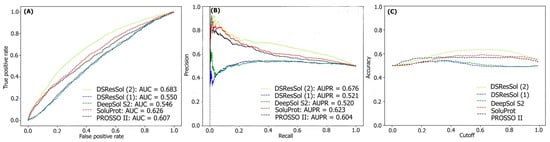
Figure 3A, B displays the threshold-independent evaluation metrics to show the performance of our models in comparison to three different existing models for the second independent test set (NESG)
[26]. The area under ROC curve (AUC) and area under precision-accuracy curve (AUPR) are 0.683 and 0.678, respectively, which is at least 8% higher than the best existing competitor, SoluProt.
Figure 3C shows the accuracy of the tested models at different solubility thresholds. The highest accuracy (62%) for DSResSol models is obtained at the solubility threshold equal to 0.5.
Figure 3. Comparison of the performance of DSResSol models with DeepSol
[16], PROSSO II
[13], and SoluProt
[15] models. (
A) Receiver operating curve (ROC), (
B) recall-precision curve, (
C) accuracy-threshold cutoffs curve. The cutoff threshold discriminates between the soluble and the insoluble proteins.
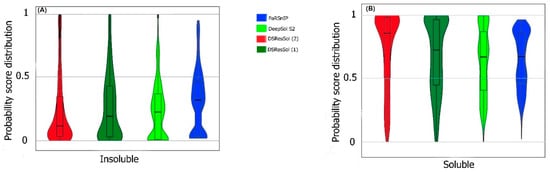
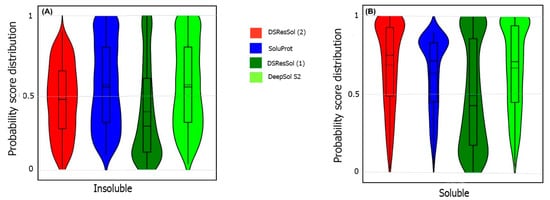
Researchers also use the probability score distribution to evaluate DSResSol on both test sets. For the first test set, researchers consider the probability score distribution of DSResSol and close competitors (PaRSnIP
[14] and DeepSol
[16]) in violin plots (
Figure 4) for both soluble and insoluble proteins. The distribution of scores for the four models shown in
Figure 4 does not follow a normal distribution. For soluble and insoluble proteins, the score distribution plot shows that although DeepSol S2 like DSResSol (1) and DSResSol (2) gives more than a 99% level of confidence for the solubility prediction, the density of scores for DSResSol (2) in soluble proteins (values near score = 1) and for insoluble proteins (values near score = 0) is much higher than for DeepSol S2, confirming the better performance of DSResSol over DeepSol S2. In contrast to DSResSol and DeepSol S2, the score distribution for the PaRSnIP model does not reach a score = 1 for soluble and 0 for insoluble proteins, suggesting poor performance for PaRSnIP. To compare the score distribution of DSResSol (1) and DeepSol S2, researchers can see that near the probability score cutoff = 0.5, DSResSol (1) has greater density scores than DeepSol S2, suggesting lower accuracy in comparison to DeepSol S2. The mean score for each model is also computed. For the insoluble class, the mean score of DSResSol (2) (0.12) is significantly lower than DeepSol S2 (0.26) and PaRSnIP (0.37). For the soluble class, the mean score for DSResSol (2) (0.81) is much higher than DeepSol S2 (0.62) and PaRSnIP (0.61), suggesting the improved performance of DSResSol (2) over close competitors. In other words, a lower mean score value for the insoluble class and a higher mean score value for the soluble class represent higher confidence in the model. Finally, researchers note that the density of scores in the DSResSol (1) model beyond a score of 0.5 is higher and lower for the insoluble and soluble classes, respectively, than DSResSol (2), suggesting lower accuracy (
Figure 4). This result suggests that DSResSol (1) wrongly predicts more solubility values than DSResSol (2). This result can be understood considering that DSResSol (2) takes advantage of 85 additional biological features to establish a more accurate predictive model. For the second test set, a similar analysis is performed.
Figure 4. Violin plots represent the probability score distribution of DSResSol (1) and (2), DeepSol S2
[16], and PaRSnIP
[14] for (
A) insoluble and (
B) soluble classes in the first test set
[25].
For the second test set, the probability score distribution with two competitors, SoluProt
[15] and DeepSol
[16], is compared.
Figure 5 shows this analysis for the second test set in two violin plots. The density score distribution near the probability value 0 for the DeepSol S2 model is higher than DSResSol (2) and DSResSol (1), indicating that DeepSol S2 works better than DSResSol (2) for insoluble protein prediction. Furthermore, the density of score distribution near the value = 0.5 for DSResSol is higher than DeepSol S2, confirming the slightly better performance of DeepSol S2 on insoluble protein prediction in comparison to DSResSol (2). Furthermore, the mean score distribution of the SoluProt model is 0.63 for insoluble proteins, representing its relatively poor performance on insoluble proteins. However, based on
Figure 5B, DSResSol (2) outperforms DeepSol S2 and SoluProt for the soluble class. The mean of scores distribution on soluble proteins is 0.72 for DSResSol (2) while this value for DeepSol S2 and SoluProt is 0.42 and 0.66, respectively, confirming DSResSol (2) is the best candidate tool for soluble proteins prediction. Furthermore, the density of scores distribution for the soluble class in DSResSol (2) is higher than both DeepSol S2 and SoluProt (e.g., close to value = 1 in the violin plot), which further validates the outstanding performance of DSResSol (2) on the soluble class.
Figure 5. Violin plots representing the probability score distribution of DSResSol (1) and (2), DeepSol S2
[16], and SoluProt
[15] for (
A) insoluble and (
B) soluble classes in NESG test set.
3. Effect of Sequence Length on Solubility Prediction
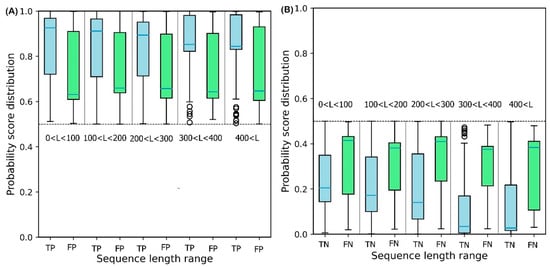
To illustrate the effect of protein sequence length on protein solubility prediction, researchers divide both test sets into five separate sets of different sequence length, in the range: {[0, 100], [100, 200], [200, 300], [300, 400], [400,
∞]}. To evaluate how sequence length affects the solubility score, the score distribution is shown for proteins predicted to be soluble and insoluble in five different sequence length ranges (
Figure 6). True Positive (TP) and True Negative (TN) predictions correspond to the soluble and insoluble classes predicted correctly. False Positive (FP) and False Negative (FN) predictions correspond to the insoluble and soluble classes predicted incorrectly.
Figure 6A shows that the median decreases monotonically as sequence length increases, suggesting that longer sequence length results in reduced solubility. In other words, the shorter protein sequences are more soluble as proposed by Kramer et al.
[27]. The median scores for TP sets for five sequence length ranges are 0.93, 0.92, 0.90, 0.86, and 0.83, respectively. These values highlight the outstanding performance of DSResSol on the soluble class (a value of 1 corresponds to soluble protein). From
Figure 6B, researchers observe that an increase in sequence length in the TN sets yields a decrease in the score distribution for insoluble proteins, suggesting that DSResSol can more easily predict insoluble proteins having longer than shorter sequences. The median of TN sets for five sequence length ranges is 0.21, 0.18, 0.16, 0.08, and 0.05, respectively, showing good performance of the DSResSol predictor (a value of 0 corresponds to insoluble protein). Furthermore, the difference between median TN and FN (Median (FN) -Median (TN)) for the insoluble class as well as the difference between the median of TP and FP (Median (TP)—Median (FP)) is calculated for the soluble class (
Table 3). Proteins in the soluble class in the sequence length range (0, 100) and proteins in the insoluble class in the sequence length range (400 < L <
∞) have maximum values (0.29 for soluble and 0.34 for insoluble), confirming that the DSResSol model can predict proteins in these sequence length ranges with higher relative confidence than proteins with other sequence length ranges.
Figure 6. Probability score distributions for proteins predicted in both test sets to be (A) soluble and (B) insoluble for 5 different sequence length ranges: 0 < L < 100, 100 < L < 200, 200 < L < 300, 300 < L< 400, and 400 < L < ∞. TP = True Positive, FP = False Positive, TN = True Negative, and FN = False Negative. Blue horizontal line in box plot of each set shows the median of the score distribution for that set.
Table 3. Difference between the median of True Positive and False Positive (TP, FP) soluble proteins as well as False Negative and True Negative (FN, TN) for insoluble proteins for different sequence length ranges. M = Median. Median of each category showed as horizontal blue line in box plots in Figure 6.
| Sequence Length Range |
M(TP)—M(FP) |
M(FN)—M(TN) |
| (0, 100) |
0.29 |
0.23 |
| (100, 200) |
0.24 |
0.22 |
| (200, 300) |
0.24 |
0.26 |
| (300, 400) |
0.22 |
0.31 |
| (400, ∞) |
0.22 |
0.34 |
4. Key Amino Acids, Dipeptides, and Tripeptides for Protein Solubility
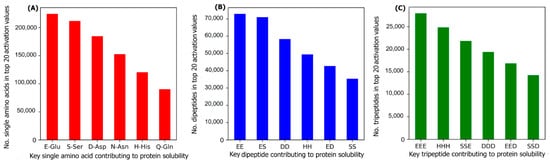
To investigate the most important amino acids and di- and tripeptides contributing to protein solubility, these are directly extracted from the DSResSol model. As discussed, nine initial CNNs in DSResSol are responsible for capturing amino acid k-mers from k = 1 to 9. The feature maps obtained from each initial CNN, having dimensions 1200 × 32, are associated with amino acid k-mers for the corresponding protein sequence. To extract key amino acids associated with protein solubility, the feature vector, called activation vector, is needed for each protein sequence. These feature vectors for each protein sequence in our training set are extracted as follows. First, researchers pass the feature maps, which researchers receive from the CNN layer having a filter size of 1, through a reshape layer to assign features maps with dimension 32 × 1200. Then, these feature vectors are fed to a Global Average Pooling layer to obtain the feature vectors of length 1200 for each protein sequence, which represents the activation vector for that protein sequence. Each value in the activation vector, called activation value, is associated with a corresponding amino acid within the original protein sequence. Hence, higher activation values suggest a larger contribution to the classification results and protein solubility. The amino acids corresponding to the top 20 activation values for each protein sequence in the training dataset are counted. The total number of each amino acid corresponding to the top 20 activation values for all protein sequences in the training dataset represents the importance of that amino acid in protein solubility classification. The same process is applied for feature maps obtained from initial CNN layers with a filter size of 2 and 3 and the total number of pairs and triplets are counted, corresponding to the top 20 activation values across all protein sequences, to gain insight into the contribution of di- and tripeptides in protein solubility prediction.
Figure 7 depicts the most important amino acids, dipeptides, and tripeptides contributing to protein solubility. Researchers found that glutamic acid, serine, aspartic acid, asparagine, histidine, and glutamine are key amino acids contributing to protein solubility. Glutamic acid, aspartic acid, and histidine are amino acids with electrically charged side chains, while serine, asparagine, and glutamine have polar uncharged side chains. Interestingly, in one experimental study reported by Trevino et al., glutamine, glutamic acid, serine, and aspartic acid contribute most favorably to protein solubility
[28].
Figure 7B,C shows that two and three consecutive glutamine amino acids (EE and EEE) are the most important dipeptides and tripeptides contributing to protein solubility. These results are consistent with experimental data proposed by Islam et al.
[29]. Additionally, polar residues and residues that have negatively charged side chains such as glutamic acid and aspartic acid are, in general, more likely to be solvent-exposed than other residues
[28] and can bind water better than other residues
[30]. These observations are well-correlated with protein solubility and consistent with our analysis that identifies these as key amino acids for protein solubility prediction. In another investigation, Chan et al. demonstrated that positively charged amino acids are correlated with protein insolubility
[31], consistent with our findings that histidine in the single, dipeptide, and tripeptide state strongly impacts protein solubility prediction. Moreover, Nguyen et al. found negatively charged fusion tags as another way to improve protein solubility
[32][33], consistent with our findings.
Figure 7. The number of (A) amino acids, (B) dipeptides, and (C) tripeptides corresponding to the top 20 activation values, obtained from the initial CNNs in DSResSol model, across all protein sequences within the training dataset.
5. Effect of Additional Biological Features on DSResSol Performance
To evaluate the effect of each additional biological feature group on DSResSol performance, researchers consider each feature group independently in the DSResSol (1) model (
Table 4 and
Table 5). When only solvent accessibility-related features are added to DSResSol (1), the accuracy of the model on the first test set increases from 0.751 to 0.782, and the accuracy of the model on the second test improves from 0.557 to 0.618. Adding secondary structure-related features to DSResSol (1) improves the accuracy for the first test set from 0.751 to 0.763 and for the second test set from 0.557 to 0.582. Researchers also consider the fraction of exposed residues and secondary structure content for soluble and insoluble proteins in the training data. Researchers identify that the soluble protein class has 61.2% helix and beta strand content. In total, 68.7% of the residues are exposed residues with relative solvent accessibility cutoff higher than 65%. On the other hand, for the insoluble proteins in the training set, 81% of the secondary structure content is random coils. Further, 78% of residues are buried with relative solvent accessibility less than 35%, suggesting that the proteins having highly ordered structure and solvent-exposed residues with larger relative solvent accessibility cutoffs have a greater tendency to be soluble. By contrast, proteins with a higher degree of disordered secondary structure, such as random coil, and buried residues are predominantly insoluble. These results represent the influence on protein solubility propensity by solvent accessibility and secondary structure and are supported by experimental data. Kramer et al. have previously demonstrated the correlation between solvent accessibility and secondary structure content with protein solubility. They proposed that soluble proteins have larger negatively-charged surface area and are thus amenable to bind water
[27]. Furthermore, Tan et al. identified the significant relationship between protein solubility and ordered secondary structure content such as helix and beta sheets
[34]. They found large helix and beta sheet content within the most soluble proteins
[34]. Thus, our results, which suggest that ordered secondary structures such as helix and beta sheets, as well as a larger fraction of solvent-exposed residues with higher relative solvent accessibility cutoffs, contribute to protein solubility, correlate well with experimental findings.
Table 4. Performance of the DSResSol model after adding each biological feature group to the DSResSol (1) model for the first test set. The accuracy of DSResSol (1) without biological features is 0.751.
| Model |
ACC DSResSol (1) after Adding the Additional Biological Features |
ACC Improvement |
| DSResSol (1) + Solvent accessibility related features |
0.787 |
3.7% |
| DSResSol (1) + Secondary structure related features |
0.762 |
1.1% |
| DSResSol (1) + order/disorder related features |
0.757 |
0.6% |
| DSResSol (1) + global sequence features |
0.756 |
0.5% |
Table 5. Performance of the DSResSol model after adding each biological feature group to the DSResSol (1) model for the second test set. The accuracy of DSResSol (1) without biological features is 0.557.
| Model |
ACC DSResSol (1) after Adding the Additional Biological Features |
ACC Improvement |
| DSResSol (1) + Solvent accessibility related features |
0.618 |
6.1% |
| DSResSol (1) + Secondary structure related features |
0.582 |
2.5% |
| DSResSol (1) + order/disorder related features |
0.564 |
0.7% |
| DSResSol (1) + global sequence features |
0.561 |
0.4% |
6. Effect of Sequence Identity Cutoff on DSResSol Performance
To develop input datasets, researchers removed the redundant protein sequences in the training set with sequence identity over 25%. Moreover, the protein sequences having more than 15% sequence similarity with both test sets have been eliminated in the training set. To analyze the impact of identity cutoff on DSResSol performance, researchers considered different cutoffs to train DSResSol (
Table 6 and
Table 7). The results indicate that by changing the sequence identity cutoffs, the performance of the DSResSol predictor improves to 75.1% for the first test set and to 55.7% for the second test set, suggesting that the optimal identity cutoff is 25%
[16]. In fact, these results show that the existence of similar sequences within the training set leads to overfitting or overtraining of the model, which results in a decrease in model performance on the test sets.
Table 6. Performance comparison for DSResSol (1) on the first independent test set for different cutoff sequence identity. Note: Best performing method is in bold.
| Model |
ACC |
MMC |
Sensitivity (Soluble) |
Sensitivity (Insoluble) |
| DSResSol (1) Cutoff 25% |
0.751 |
0.508 |
0.691 |
0.813 |
| DSResSol (1) Cutoff 15% |
0.744 |
0.491 |
0.686 |
0.805 |
| DSResSol (1) Cutoff 20% |
0.743 |
0.488 |
0.701 |
0.795 |
| DSResSol (1) Cutoff 30% |
0.744 |
0.492 |
0.688 |
0.801 |
Table 7. Performance comparison for DSResSol (1) on the second independent test set for different cutoff sequence identity. Note: Best performing method in bold.
| Model |
ACC |
MCC |
Sensitivity (Soluble) |
Sensitivity (Insoluble) |
| DSResSol (1) Cutoff 25% |
0.557 |
0.166 |
0.545 |
0.568 |
| DSResSol (1) Cutoff 15% |
0.553 |
0.157 |
0.542 |
0.567 |
| DSResSol (1) Cutoff 20% |
0.555 |
0.164 |
0.547 |
0.563 |
| DSResSol (1) Cutoff 30% |
0.552 |
0.159 |
0.541 |
0.567 |
 +1 credit
+1 credit