1. Neural Networks and Deep Learning
In the era of information processing tasks, machine learning (ML) has been merged in many disciplines, including information mining, relations classification, image processing, video classifications, recommendation, and analysis of different social networks. Including all ML algorithms, Neural Network (NN) and DL are identified as representation learning
[1] extensively used. NN computes a result/predication/output, which generally states forward propagation (FF). During FF, the NN receives inputs vector X and result in a prediction vector Y. More generally, NN is based on interconnected layers (input, hidden, and output layer). Each layer is linked via a so-called weight matrix (W) to the next layer. Further, each layer consists of different combinations of neurons/nodes, where each node gets a particular number of inputs and computes a prediction/output. Every node in the output layers makes weighted addition based on received values from the input neurons. Further, the weighted addition is passed to some nonlinear activation functions (Sigmoid, Tan Hyperbolic (Tanh), Rectified Linear Unit (ReLU), Leaky ReLU, and Softmax Activation Function) to compute outputs.
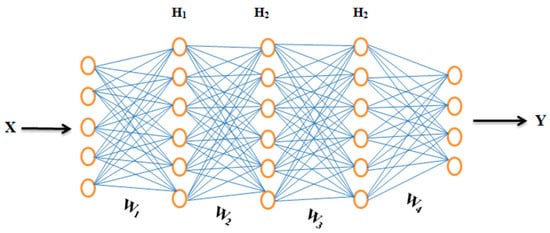
Figure 1 represents a simple NN with one input layer, three hidden layers (H
1, H
2, and H
3), one output layer, and four weight matrices (W
1, W
2, W
3, and W
4).
Figure 1. Represents a simple NN of one input layer, three hidden layers, and one output layer.
We set an input vector X to calculate dot-product by the first weight matrix (W
1) and used the nonlinear activation function to the result of this dot-product, which output a new vector h
1 that denotes values of the nodes in the first layer. Further, h
1 is used as a new input vector to the next layer, where similar operations are executed again. This process is repeated until the final output vector Y is produced, known as the NN prediction. While Equations (1)–(4) represent the whole set of operations in NN, where “σ” denotes an arbitrary activation function.
More generally, we consider NN as a function instead of using a combination of interconnected neurons. With this function, we combine all operations in a chained format in Equation (5) that we have seen in the above four equations.
2. Loss Functions and Optimization Algorithms
The selection of loss function and optimization algorithms for DL networks can significantly generate optimal and quicker results. Every input in the feature vector is allocated its particular weight, which chooses the impact that the specific input desires in the summation function (Y). In simple words, certain inputs are made more significant than others by assigning them more weight, which has a superior effect in Y. Furthermore, a bias (b) is added to summation shown in Equation (6).
The outcome Y is a weighted sum is converted to performed output using a non-linear activation function (fNL). In this case, the preferred result is the probability of an event, which is represented by Equation (7).
In many learning models, error (e) is calculated as the gap between the actual and predicted results in Equation (8).−pˆ
The function for error calculation is called Loss Function J (.), which significantly affects the model prediction. Distinct J (.) will provide diverse errors for a similar prediction. Different J (.) deals with various problems, including classification, detection, extraction, and regression. Furthermore, error J (w) is a function of the network/model’s inner parameters (weights and bias). Precise likelihoods require minimizing the calculated error. In NN, this is achieved by Back Propagation (BP)
[2], in which the existing error is commonly propagated backward toward the preceding layer, where optimization function (OF), including Stochastic Gradient Decent (SGD), Adagrad, and Adam is used to modify the parameters in an efficient way to the minimize error.
The OF calculates the gradient (partial derivative) of J (.) concerning parameter (weights), and weights are improved in the reverse direction of the calculated gradient. This process is repetitive until it reaches the minimum J (.). Equation (9) represents the optimization process.
The basic differences between different models are based on the number of layers and the architecture of the interconnected nodes. In those models, neurons are structured into sequential layers, where each neuron receives inputs only from previous layers neurons, called Feedforward Neural Networks (FFNNs). Though, there is no clear consensus on precisely what explains a Deep Neural Network (DNN), networks with several hidden layers are known as deep and those with several layers are known as very deep
[3]. Contrary to traditional and ML techniques, DL techniques have enhanced performance in computer vision (Image Processing, Video Processing, Audio Processing, and Speech Processing)
[4][5][6], and NLP tasks (Text Classification, Information Retrieval, Event Prediction, Sentiment Analysis, and Language Translation)
[7][8][9][10][11].
Usually, the effectiveness of shallow ML algorithms is based on the goodness of input data representation. Compared to precise data representation, the performance of depraved data representation is usually lower. Hence, for shallow ML tasks, feature engineering is an effective research direction in raw datasets and will lead to various research studies. Usually, most of the features are domain-dependent which need much human effort e.g., in computer vision tasks, diverse features are compared and proposed including Bag of Words (BoW), Scale Invariant Feature Transform (SIFT)
[12], and Histogram of Oriented Gradients (HOG)
[13]. Similarly, in NLP tasks, diverse features sets are used including BoW, Linguistics Patterns (LP), and Clue Terms (CT), Syntactic, and Semantic context. Contrary, DL techniques work on automatic feature engineering, which lets researchers get more discriminative features with minimal human effort and domain knowledge
[14]. As discussed above that DL techniques are based on a low-level, middle-level, and high-level layered structure for data representation, where the low-level layers are used for low-level features, the middle-level/hidden layers are used to extract hidden/middle-level features. Finally, the high-level features are extracted by high-level layers.
3. Motivation for Causality Mining
DL applications are resulted based on feature representation and algorithms together with the design. These are related to data illustration/representation and learning structure. For data illustration, there is typically a disjunction among what information is said to be essential for the task, against what illustration produces good outcomes. For instance, Syntactic Structure, Sentiment Analysis, Lexicon Semantics, and Context are supposed by some linguists to be of fundamental importance. However, prior works are based on bag-of-words (BoW) system proven satisfactory performance
[15]. The BoW
[16], frequently seen as vector space models, includes an illustration that accounts only for the words/tokens and their frequency of existence. BoW overlooks the order and relations of words and treats every token as a distinctive feature. BoW neglects syntactic format, still delivers effective results for what some could consider syntax-oriented applications. This judgment recommends that simple illustrations, when combined with a big data set, may work superior to difficult representations. These outcomes verify the argument courtesy of the significance of DL architectures and algorithms. Often the effective language modeling guarantees the advancement of NLP. The aim of statistical language designing is the probabilistic illustration of word sequences, which is a complex job because of the dimensionality curse. In
[17], a breakthrough for language designing with NN aimed to overcome the dimensionality cures by learning a distributed illustration of tokens and giving a likelihood function for structures.
A significant challenge in NLP study, related to other areas including computer vision, looks complicated to reach an in-depth illustration of language using statistical/ML networks. A core task in NLP is to illustrate texts (documents), which comprises feature learning, i.e., mining expressive information to allow additional analysis and processing of raw data. Non-statistical approaches are based on handcrafted features engineering, which is time-consuming. Through, the development of algorithms needs careful human analysis to mine and exploit instances of such features. While, deep supervised approaches are more data-driven and can be used in extra general efforts, which directed a robust data illustration. In the presence of huge amounts of unlabeled datasets, unsupervised learning techniques are known to be critical tasks. With the beginning of DL and the sufficiency of unlabeled datasets, unsupervised techniques become a critical job for representation learning. At present, many NLP tasks depend on annotated data, while most unannotated data encourages study in employing deep data-driven unsupervised techniques. Given the possible power of DL techniques in NLP tasks, it looks critical to analyses numerous DL techniques extensively.
DL models have a hierarchical structure of layers that learn from data representation by input layer, then pass them through multiple intermediate layers (hidden layers) for further processing
[18]. Finally, the last layer computes the output predation. ANN is a representative network using FP and backward propagation (BP). FP is used for processing weighted sum (WX) of input from the prior layer along with bias (b) term and further passes it to a sequence of Convolutional, Non-linear, Pooling, and Fully connected layers to produce the required output (final prediction). Equation (10) represents the fundamental matrices of the neural networks.
where ‘W’ represents the weight (number matrix), also known as parameters, X represents the input feature vector, ‘b’ represents the bias term, ‘A’ represents the activation function, and Z represents the final prediction. Similarly, the BP computes the derivative/slope/gradient of an objective function by chain rule of the gradient to the weights of a multilayer stack of modules via the chain rule of derivatives. DL plays a role by deeply analyzing input and capturing all related features from low to high levels. The semantic configuration and representation learning are strengthened by neural processing and vector representation, making machines capable of feeding raw data to automatically determine hidden illustrations for final prediction
[18] automatically. DL techniques have some fundamental strengths for CM, including, (1) By DL techniques, CM takes advantage of non-linear processing, which creates non-linear conversion from source to target output. They have the power to learn all related features from input data by a layered structure with different parameters and hyperparameters. (2) Compared to traditional and shallow ML techniques, DL can automatically capture important features without much human effort. (3) In the DL network, the optimization function plays an important role for the end-to-end paradigm to train a more complex task for CM. (4) With DL techniques, both data-driven and program-driven techniques are easily structured for CM tasks.
4. Deep Learning Frameworks
Currently, some well-known DL frameworks are available at hand for diverse model designing. Such frameworks are either the library or interface tools that help ML developers and research scientists to develop and design DL networks more efficiently.
Table 1 represent some well-known frameworks including Torch
[19], TensorFlow
[20], DeepLearning4j (DL4j)
[21], Caffe
[22], MXNet
[23], Theano
[24], Microsoft Cognitive Toolkit (CNTK)
[25], Neon
[26], Keras
[27], and Gluon
[28]. They all play a very significant role in DL architectures. Due to space limitations, it is advised for readers to visit
[29] for detailed information about the mentioned Frameworks.
Table 1. Summary of Deep Learning Framework.
| Frameworks |
References |
Primary Language |
Interface Provision |
RNN and CNN Provision |
Key Note to Know About |
| Torch |
[19] |
C and Lua |
Python, C/C++, and Lua |
Yes |
- ✓
-
Allow standard IDE for debugging, such as PyCharm or PDA
- ✓
-
It works with dynamically updated graph
- ✓
-
It is mostly used for DL applications, such as NLP and Computer Vision.
|
| TensorFlow (TF) |
[20] |
Python and C++ |
Python, Java, JavaScript, C/C++, Julia, C#, and Go |
Yes |
- ✓
-
TF is the best choice for DL networks deployments
- ✓
-
Used for Data Integration (DI), such as SQL tables, input graphs, and images
- ✓
-
Along with deploying networks on influential computing clusters, TF can run networks on mobile systems (Android and iOS) as well.
|
| DL4j |
[21] |
Java, JVM |
Python, Java, and Scala |
Yes |
- ✓
-
It integrates the employment of the GloVe, Deep Autoencoder, Recursive Neural Tensor Network, Word2Vec, and Doc2Vec.
- ✓
-
It uses both Hadoop and Spark, this helps to accelerate network training.
- ✓
-
It trains neural networks in parallel through repeated reduction through clusters.
|
| Caffe |
[22] |
C++ |
MATLAB and Python |
Yes |
- ✓
-
It is an open-source DL framework
- ✓
-
Works fine in computer vision
- ✓
-
It supports industrial and researchers applications
|
| MXNet |
[23] |
// |
Python, C++, Perl, R, Go, Matlab, Scala, and Julia. |
Yes |
- ✓
-
It can support several GPUs with optimized calculation and fast context switching.
- ✓
-
It is a scalable and lean DL framework with the provision of previous networks including, CNNs, GRU, and LSTM.
- ✓
-
It supports symbolic and imperative programming.
|
| Theano |
[24] |
Python |
Python |
Yes |
- ✓
-
It lets to process mathematical operations such as multi-dimensional arrays
- ✓
-
It is used to handle computation for large algorithms used in DL
- ✓
-
It works well with GPU as compared to CPU
|
| CNTK |
[25] |
C++/C# |
C++, Python, and BrainScript |
Yes |
- ✓
-
It is an open-source app for commercial DL.
- ✓
-
It easily combines feed-forward deep neural networks, CNN, RNN, and LSTM.
- ✓
-
It describes the NN as a chain of computational stages through a directed graph
|
| Neon |
[26] |
Python |
Python |
Yes |
- ✓
-
It is an open-source DL framework
- ✓
-
It uses its own GPU and CPU backend
- ✓
-
It performs well on large batches
|
| Keras |
[27] |
Python |
Python |
Yes |
- ✓
-
User friendly, easy, and modular
- ✓
-
It offers the advantages of comprehensive adoption, provision for a wide range of incorporation with at least five back-end engines including, Theano, TensorFlow, PlaidML, CNTK, and MXNet
- ✓
-
Support several GPUs and distributed training
|
| Gluon |
[28] |
Python |
Python |
Yes |
- ✓
-
Gluon provides a friendly API, for defining easy, clear, simple, and brief code
- ✓
-
It is easier for developers to understand and learn
- ✓
-
The model’s definition is dynamic, it is easier to maintain because of its flexible structure.
|
5. Deep Learning Techniques for Causality Mining (CM)
Recently several works have been published, and most of the attention has been given to supervised systems such as shallow ML and DL approaches. The basic distinction among these systems is that advanced features engineering is essential for ML techniques, wherein DL techniques; features are learned automatically by training. However, previous approaches were largely automated, only focused on extracting explicit and simple implicit causality, and did not address complex implicit and ambiguous causalities. Furthermore, most of the early works have focused on identifying whether a relation or sentence is causal or not, and little attention is given to determine the direction of causality that which entity is the effect, and which one is the cause. The challenges mentioned above are critical for NLP researchers. Recently, DL techniques have been applied to various NLP tasks such as sentiment analysis, sentence classification, topic categorization
[30], POS tagging, named entity recognition (NER), semantic role labeling (SRL), relation classification, and causality mining.
The two most widely used classifiers among various deep neural classifiers for relation classification are CNNs and RNN. In NLP, those classifiers are based on a discrete representation of words in vector space, known as word embedding that captures syntactic and semantic information of words
[31][32]. The two most widely used classifiers among various deep neural classifiers for relation classification are CNNs and RNN. To the best of our knowledge, very few DL techniques are used for CM; some are discussed in this section. Similarly,
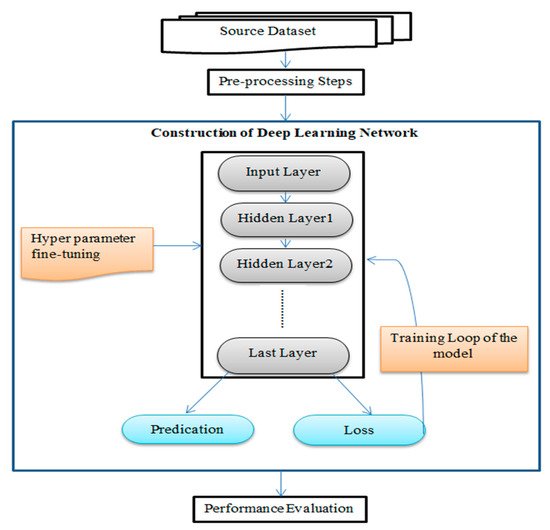
Figure 2 represents the processing levels of DL techniques, which consist of different phases of processing till to the final prediction. In this figure, the model is provided the raw input data, passed it to pre-processing steps for cleaning it for further processing. Further, the pre-processed data is passed to the input layer of the model and followed by multiple hidden layers for deep analysis of hidden features by using different hyperparameter settings. Finally, the output prediction is achieved at the output layer. If the prediction is correct, then the model is finalized. Otherwise, the model is trained repeatedly by applying the loss function to reduce the error until the final prediction is based on the model’s performance evaluation metrics (precision, accuracy, and recall score).
Figure 2. Processing level of DL techniques.
In
[33], two networks are presented, a Knowledge-based features mining network and Deep CNN, to train a model for implicit and explicit causalities and their direction. They used sentence context for designing the problem into a three-class classification of entity pairs, including class-1 that specifies the annotated pair with causal direction e1 -> e2 (cause, effect), class-2 entity pairs with causal direction e2 -> e1 (effect, cause), and class-3 entity pairs are non-causal. A list of hypernyms in WordNet is prepared for each of the two annotated entities in a source sentence They used two labeled datasets including, SemEval-2007 Task-4 (
http://docs.google.com/View?docID=w.df735kg3_8gt4b4c) and SemEval- 2010 Task-8” dataset (
http://docs.google.com/View?docid=dfvxd49s_36c28v9pmw), in which total of 479 samples are used for class-1, 927 for class-2, and 982 for class-3. The SemEval-2007 dataset has seven labeled relations and the SemEval-2010 has nine relations, including cause-effect relation. They extract causality from each dataset as positive labeled data and extract a random mix of other relations as negative data.
Ref.
[34] propose a novel technique using multi-column convolutional neural networks (MCNNs) and source background knowledge (BK) for CM. It is a variant of CNN
[35] with several independent columns. The inspiration for this work was
[36]. They used short binary patterns to connect pairs of nouns like “A causes B” and “A prevents B” to increase the performance of event causality recognition. They focused on such event causalities, “smoke cigarettes” → “die of lung cancer” by taking an original sentence from which the candidate of causalities is extracted with the addition of related BK taken from the web texts. Three distinct methods are used to get related texts for a given causality candidate from 4 billion web pages as a source of BK, including (1) Why-question answering, (2) Using Binary Pattern (BP), and (3) Clues Terms. These techniques identify useful BK scattered in the web archives and feed into MCNNs for CM. MCNNs consists of 8 columns, where five columns are used to process event causality candidates and their nearby contexts in the original sentence. The other three columns deal with web archives. Then the output of all columns based on their layers combination is combined into the last layer for final prediction. Using all types of BK (Base + BP + WH + CL), the top achieved average precision is 55.13%, which is 7.6% higher than the best of
[36] methods (47.52%). Note that by extending single CNN’s to multi-column CNN’s (CNN-SENT vs. Base), the proposed work obtained a 5.6% improvement, and further gave 5.8% improvement by adding with external BK.
[37] enhanced MCNN by adding causality attention (CA), which results in the CA-MCNN model. This model is based on two notions that enhanced why-QA, which includes expressing implicitly expressed causality in one text by explicit cues from other text and describing the causes of similar events by using a set of similar words.
In
[38], a novel set of event semantics and position features are used to train a Feed-Forward Network (FFN) for implicit causality. This work aims to improve ANN with features that take assistance from linguistic and associated works. It captures knowledge about the position and content of events contained in the relation. They used Penn Discourse Treebank (PDTB) and CST News (CST-NC) corpus. The whole objective function of the proposed algorithm is shown in Equation (11).
where the set of parameters is θΘ= {E, W1, b1, W2, b2}, cross-entropy function is used for the loss function, which is regularized by the squared norm of parameters and scaled by hyperparameter (ℓ), positional features (Xp), input indices array (Xi), the true class label (y), and event-related features (Xe). Table 1 lists the most popular DL approaches for CM based on their targets, architecture, datasets, and references. A neural encoder-decoder approach predicts causally related events in stories through standard evaluation framework choice of plausible alternatives (COPA) [39]. This was the first approach to evaluate a neural-based model for such kinds of tasks, which learns to predict relations between adjacent sequences in stories as a means of modeling causality.
The bi-LSTM
[40] is a linguistically informed architecture for automatic CM using word linguistics features and word-level embedding. It contains three modules: linguistic preprocessor and feature extractor, resource creation, and prediction background for cause/effect. A causal graph is created after grouping and proper generalization of the extracted events and their relations. They used the BBC News Article dataset, a portion of SemEval2010 task-8 related to “Cause-Effect”, and adverse drug effect (ADE) dataset for training. In
[41], a Temporal Causal Discovery Framework (TCDF), a DL model that learns temporal causal graph design by mining causality in continuous observational time series data. It applied multiple attention-based CNN along with a causal support step. It can also mine time interruption among cause and the existence of its effect. They used two benchmarks with multiple datasets including, simulated financial market and simulated functional magnetic resonance imaging (FMRI) data. Both contain a ground truth comprising the underlying causal graph. The experimental analysis shows that this mechanism is precise in mining time-series data.
Ref.
[42] proposes a novel deep CNN using grammar tags for cause-effect pair identification from nominal words in natural language corpus knowledge reasoning. Though, the prior works mainly were based on predefined syntactic and linguistic rules. The modern approaches use shallow ML primarily Deep NN on top of linguistic and semantic knowledge to classify nominal word relations in a corpus. They used the SemEval-2010 Task 8 corpus for enhancing the performance of CM. In
[43], a novel idea of Knowledge-Oriented CNN (K-CNN) for causality identification is presented. This model combined two channels: Data-Oriented Channel (DOC), which acquires important features of causality from the target data, and Knowledge-Oriented Channel (KOC), which integrates former human knowledge to capture the linguistic clues of causality. In KOC, the convolutional filters are automatically created from available knowledge bases (FrameNet and WordNet) without training the classifier by a huge amount of data. Such filters are the embedding of causation words. Additionally, it uses clustering, filters selection, and additional semantic features to increase the performance of K-CNN. They used three datasets including Causal-Time Bank4 (CTB), SemEval-2010 task-86, and Event StoryLine datasets7. More specifically, the KOC is used to integrate existing linguistic information from knowledge bases. Where DOC is used to learn important features from data by using a pre-defined convolutional filter. These two channels complement each other and extract valuable features of CM.
In the same year, a novel feed-forward neural network (FFNN) was used with a context word extension mechanism for CM in tweets
[44]. For event context word extension, they used BK, extracted from news articles in the form of a causal network to identify event causality. They have used 2018 commonwealth game-related tweets held in Australia. This was a challenging job because tweets are mostly composed of unstructured nature, highly informal, and lack contextual information. This approach is closely related to
[38] for detecting causality between events using FFNN by enhancing the feature set by computing distances among events trigger word and related words in the phrase. Though, such positional knowledge for tweets might not show the causal direction more easily because tweets are mostly composed of noisy words and characters e.g., # (hashtags), @ sign, question marks (?), URLs, and emojis. Hence, such data is not appropriate for the detection of causality in tweets. Inspired by
[44], the automatic mining of causality in a short corpus is a useful and challenging task
[45], because it contains many informal characters, emojis, and questions marks. This technique was applied a deep causal event detection and context word extension approach for CM in tweets. They used more than 207k tweets using Twitter API (
https://developer.twitter.com/en/docs/tweets/search/overview). They prepare to collect those tweets that were associated with the “Commonwealth Games-2018 held in Australia”. This study
[46] presents a BERT-based approach using multiple classifiers for CM inside a web corpus, which used independent labels given by multiple annotators in the corpus. By training multiple classifiers, hold all annotators procedure, where every classifier predicts the labels provided by a particular annotator, and integrate the result of all classifiers to predict the final labels found by the majority vote. BERT is a pre-trained network with a huge amount of corpus that learned some sort of BK for event-causal relations during pre-training. They used (Hashimoto et al., 2014) in the construction of source datasets. The experimentations prove that the performance is improved when BERT is pre-trained with a web corpus that covers a huge amount of event causalities instead of using Wikipedia texts. Though this effect was inadequate, hence, they further enhanced the performance by simply adding corpus associated with an input causality candidate as a BK to the input of the BERTs, which significantly beat the state-of-the-art approach
[34] by around 0.5 in average precision.
Ref.
[47] explored the causality effect of search queries associated with bars and restaurants on every day new cases in the United State (US) areas with low and high everyday cases. GT searches for bars and restaurants presented a major effect on every day new cases for areas with higher numbers of every day new cases in the US. They used the deep LSTM model for training, which is a typical problem in ML tasks. In
[48], the Event Causality identification (ECI) model are proposed by targeting the limitations of past approaches by leveraging outside knowledge for reasoning, which can significantly improve the illustration of events and also mine event-agnostic, context-specific patterns, by a mechanism named “event mention masking generalization”, which can significantly improve the capability of the model to handle new and previous unnoticed cases. Significantly, the important element of this model is “Knowledge-aware causal reasoned”, which can exploit BK in external CONCEPTNET knowledge bases
[49] to improve the cognitive process. They used 3 benchmark datasets including, Causal-TimeBank, Event Story Line, and Event Causality for experimentations, which show the model achieves state-of-the-art performance. In
[50], the problem of causal impact is considered for numerous ‘COVID-19’ associated policies on the outbreak dynamics in diverse US states at different time intervals in 2020. The core issue in this work is the presence of time-varying and overlooked confounders. To address this issue, they integrated data from several COVID-19 related databases comprising diverse types of information, which help as substitutions for confounders. They used a neural network-based approach, which learns the illustrations of the confounders using time-varying observational and relational data and then guesses the causal effect of such policies on the outbreak dynamics with the learned confounder representations. The outcomes of this study confirm the proficiency of the model in controlling confounders for causal valuation of COVID-19 associated policies.
In
[51], a self-attentive Bi-LSTM-CRF based approach is presented, named Self-attentive BiLSTM-CRF wIth Transferred Embedding (SCITE). This technique formulates CM as a sequence tagging problem. This is useful for directly mining cause and effect events without considering cause-effect pairs and their relationship separately. Moreover, to progress the performance of CM, a multi-head self-attention procedure is presented into the model to acquire the dependencies among causal words. To solve two issues, first, they included Flair embedding due to prior information deficiency in the
[52]. Second, in terms of positions in the text, cause and effect are rarely far from each other. For this, a multi-head self-attention
[53] is applied. The SemEval 2010 task 8 is used with extended annotation, in which Flair-BiLSTM-CRF achieved progress of about 6.32% over the Bi-LSTM-CRF compared with BERT and ELMo (rises of 4.55% and 6.28%). Moreover, the causality tagging approach produced enhanced results compared to the general tagging approach under the SCITE model. This study
[54] developed three network-architectures (Masked Event C-BERT, Event aware C-BERT, C-BERT) on the top of language models (pre-trained BERT) that influence the complete sentence context, events context, and events masked context for CM among expressed events in natural language text (NLT). They simply focus to recognize possible causality among marked events in a given sequence of text, but it doesn’t find the validity of such relations.
This approach achieved state-of-the-art performance in the proposed data distributions and can be used for mining causal diagrams and/or constructing a chain of events from an unstructured corpus. For experimentation, they generated their dataset from three benchmarks including, Semeval 2010 task 8
[55], Semeval 2007 task 4
[56], and ADE
[57] corpus. This approach achieved state-of-the-art performance in the proposed data distributions and can be used for mining causal diagrams and/or constructing a chain of events from an unstructured corpus.
 +1 credit
+1 credit