 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Max Marian | + 1769 word(s) | 1769 | 2021-09-06 08:51:25 | | | |
| 2 | Dean Liu | Meta information modification | 1769 | 2021-10-21 07:32:59 | | |
Video Upload Options
Tribology has been and continuous to be one of the most relevant fields in today’s society, being present in almost aspects of our lives. The importance of friction, lubrication and wear is also reflected by the significant share of today’s world energy consumption. The understanding of tribology can pave the way for novel solutions for future technical challenges.
1. Introduction
Tribology has been and continuous to be one of the most relevant fields in today’s society, being present in almost aspects of our lives. The importance of friction, lubrication and wear is also reflected by the significant share of today’s world energy consumption [1]. The understanding of tribology can pave the way for novel solutions for future technical challenges. At the root of all advances are multitudes of precise experiments and advanced computer simulations across different scales and multiple physical disciplines [2]. In the context of tribology 4.0 [3] or triboinformatics [4], advanced data handling, analysis, and learning methods can be developed based upon this sound and data-rich foundation and employed to expand existing knowledge. Moreover, tribology is characterized by the fact that it is not yet possible to fully describe underlying processes with mathematical terms, e.g., by differential equations. Therefore, modern Machine Learning (ML) or Artificial Intelligence (AI) methods provide opportunities to explore the complex processes in tribological systems and to classify or quantify their behavior in an efficient or even real-time way [5]. Thus, their potential also goes beyond purely academic aspects into actual industrial applications. The advantages and the potential of ML and AI techniques are seen especially in their ability to handle high dimensional problems and data sets as well as to adapt to changing conditions with reasonable effort and cost [6]. They allow for the identification of relevant relations and/or causality, thus expand the existing knowledge with already available data. Ultimately, through analyses, predictions, and optimizations, transparent and precise recommendations for action could be derived for the engineer, practitioner, or even the potentially smart and adaptive tribological system itself. Nevertheless, compared to other disciplines or domains, e. g. economics and finances [7], health care [8], or manufacturing processes [6], the applicability of ML and AI techniques for tribological issues is still surprisingly underexplored. This is certainly also due to the interdisciplinarity and the quantity of heterogenous data from simulations on different scales or manyfold measurement devices with individual uncertainties. Furthermore, friction and wear characteristics do not represent hard data, but irreversible loss quantities with a dependence on time and test conditions [9].
To help pave the way, a more detailed analysis of the available ML/AI techniques as well as their applicability, strengths and limitations with regard to the requirements of the respective tribological application scenario with its specific, theoretical foundations is essential. Therefore, this contribution aims to introduce the trends and applications of ML algorithms with relevance to the domain of tribology. While other reviews were more generic [10], had a more concise scope [5], or focused on a specific technique (i.e., artificial neural networks [11]), this review article is also intended to cover a wider range of techniques and in particular to shed light on the broad applicability to various fields with tribological issues. Thus, the interested reader shall be provided with a high-level understanding of the capabilities of certain methods with respect to the tribological applications ranging from composite materials over drive technology or manufacturing to surface engineering and lubricant formulations.
2. Background and a Quantitative Survey on Machine Learning in Tribology
ML is part of AI [12] and thus originally a sub-domain of computer science. AI and ML are formed by logic, probability theory, algorithm theory, and computing [13]. In a first step, ML involves designing computing systems for a special task that can learn from training data over time and develop and refine experience-based models that predict outcomes. The system can thus be used to answer questions in the given field [12]. There are a number of different algorithms that can be used for ML, whereby the suitability is strongly task-dependent. Generally, algorithms can be categorized as “supervised learning” or “unsupervised learning” [12]. For the former, algorithms learn a relation from a given set of input and output data vectors. During learning, a “teacher” (e.g., an expert) provides the correct inputs and outputs. In unsupervised learning, the algorithm generates a statistical model that describes a given data set without the model being evaluated by a “teacher”. Furthermore, reinforcement learning features different characteristics, although it is sometimes classified as supervised learning. Instead of induction from pre-classified examples, an “agent” “experiments” with the system and the system responds to the experiments with reward or punishment. The agent thus optimizes the behavior with the goal of maximizing reward and minimizing punishment. While the classification of the three learning types mentioned above is common and widely accepted, there is no consensus on which algorithms should be assigned to which category. One possible allocation following [6] is illustrated in Figure 1.
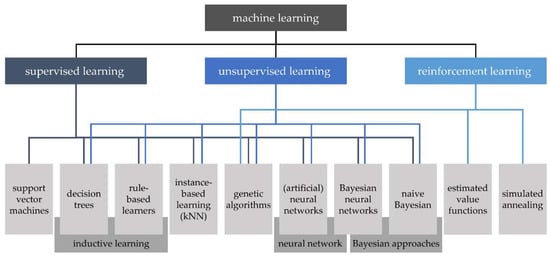
The basic idea of support vector machines (SVM) is that a known set of objects is represented by a vector in a vector space. Hyperplanes are introduced into this space to separate the data points. In most cases, only the subset of the training data that lies on the boundaries of two planes is relevant. These vectors are the name-giving support vectors [14]. To account for nonlinear boundaries, kernel functions are an essential part of SVM. By using the kernel trick, the vector space is transformed into an arbitrarily higher-dimensional space, so that arbitrarily nested vector sets are linearly separable [15]. Decision trees (DT) are ordered, directed trees that illustrate hierarchically successive decisions [12]. A decision tree always consists of a root node and any number of inner nodes as well as at least two leaves. Each node represents a logical rule, and each leaf represents an answer to the decision problem. The complexity and semantics of the rules are not restricted, although all decision trees can be reduced to binary decision trees. In this case, each rule expression can take only one of two values [16]. A possibility to increase the classification quality of decision trees is the use of sets of decision trees instead of single trees, this is called decision forests [17]. If decision trees are uncorrelated, they are called random forest (RF) [18]. The idea behind decision forests is that while a single, weak decision tree may not provide optimal classification, a large number of such decision trees are able to do so. A widely used method for generating decision forests is boosting [19]. In rule-based learners , the output results from composing individual rules, which are typically expressed in the form “If–Then”. Rule-based ML methods typically comprise a set of rules, that collectively make up the prediction model. K-Nearest-Neighbor algorithms (kNN) are classification methods in which class assignment is performed considering k nearest neighbors, which were classified before. The choice of k is crucial for the quality of the classification [16]. In addition, different distance measures can be considered [20]. Artificial neural networks (ANN) are essentially modeled on the architecture of natural brains [21]. They are ‘a computing system made up of a number of quite simple but highly interconnected processing elements (neurons), which process information by their dynamic state response to external inputs’ [12]. The so-called transfer function calculates the neuron’s network input based on the weighting of the inputs [22]. Calculating the output value is done by the so-called activation function considering a threshold value [12][22]. Weightings and thresholds for each neuron can be modified in a training process [16]. The overall structure of neurons and interconnections, in particular how many neurons are arranged in a layer and how many neurons are arranged in parallel per layer, is called topology or architecture. The last layer is called the output layer and there can be several hidden layers between the input and the output layer (multilayer ANN) [21]. While single-layer networks can only be used to solve linear problems, multi-layer networks also allow the solution of nonlinear problems [12]. Feedforward means, that neuron outputs are routed in processing direction only. Recurrent networks, in contrast, also have feedback loops. Commonly, ANNs are represented in graph theory notation, with nodes representing neurons and edges representing their interconnections.
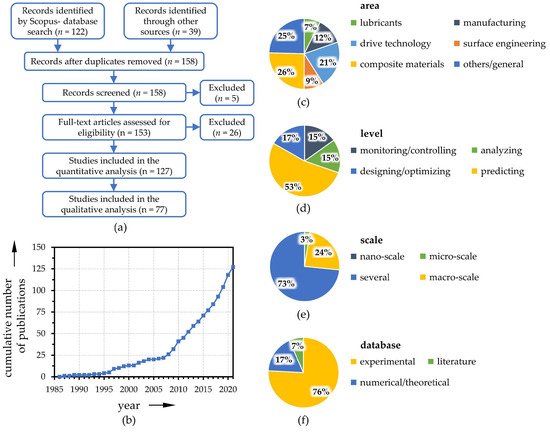
Already rather early works in the field of tribology from the 1980s can be assigned to the current understanding of ML. For example, Tallian [23][24] introduced computerized databases and expert systems to support tribological design decisions or failure diagnosis. Other initial studies were concerned, for example, with the prediction of tribological properties [25][26][27] or classification of wear particles [28][29]. Between 1985 and today, almost 130 publications related to ML in tribology were identified within a systematic literature review (see Prisma flow chart in Figure 2 a), whereas the number of papers initially increased slowly and more rapidly within the last decade ( Figure 2 b). During the latter period, the number of publications has more than tripled, which represents a faster growth than the general increase in the number of publications in the field of tribology (the numbers of Scopus-listed publications related to tribology grew by a factor of 2.3 between 2010 and today). It can therefore be highly expected that this trend will continue and that ML techniques will also become increasingly prominent in the field of tribology due to technological advances and decreasing barriers and preconceptions. Therefore, the analysis of the publications with respect to the fields of application is of particular interest, which is illustrated in Figure 2 c. Especially in the areas of composite materials, drive technology, and manufacturing, numerous successful implementations of ML algorithms can already be found. Yet, some studies can also be found for surface engineering, lubricant formulation or manufacturing. As depicted in Figure 2 d, ML techniques are applied for monitoring tribo-systems or for pure analytical/diagnostic purposes, but especially for predicting and optimizing the tribological behavior with respect to the friction and wear behavior. The scales under consideration are mainly on the macro and/or micro level, see Figure 2 e. However, a few works also show the applicability down to the nano scale. Finally, it could be observed that the database for training the ML algorithms can also be generated based on numerical or theoretical fundamentals from simulation models or on information from the literature. However, the vast majority (roughly three quarters) of the published work is based upon experimentally generated data sets ( Figure 2 f).
References
- Holmberg, K.; Erdemir, A. Influence of tribology on global energy consumption, costs and emissions. Friction 2017, 5, 263–284.
- Vakis, A.; Yastrebov, V.; Scheibert, J.; Nicola, L.; Dini, D.; Minfray, C.; Almqvist, A.; Paggi, M.; Lee, S.; Limbert, G.; et al. Modeling and simulation in tribology across scales: An overview. Tribol. Int. 2018, 125, 169–199.
- Ciulli, E. Tribology and industry: From the origins to 4.0. Front. Mech. Eng. 2019, 5, 103.
- Zhang, Z.; Yin, N.; Chen, S.; Liu, C. Tribo-informatics: Concept, architecture, and case study. Friction 2021, 9, 642–655.
- Rosenkranz, A.; Marian, M.; Profito, F.J.; Aragon, N.; Shah, R. The use of artificial intelligence in tribology—A perspective. Lubricants 2021, 9, 2.
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.-D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45.
- Ghoddusi, H.; Creamer, G.G.; Rafizadeh, N. Machine learning in energy economics and finance: A review. Energy Econ. 2019, 81, 709–727.
- Kaieski, N.; da Costa, C.A.; Righi, R.D.R.; Lora, P.S.; Eskofier, B. Application of artificial intelligence methods in vital signs analysis of hospitalized patients: A systematic literature review. Appl. Soft Comput. 2020, 96, 106612.
- Kügler, P.; Marian, M.; Schleich, B.; Tremmel, S.; Wartzack, S. tribAIn—Towards an explicit specification of shared tribological understanding. Appl. Sci. 2020, 10, 4421.
- Ji, Y.; Bao, J.; Yin, Y.; Ma, C. Applications of artificial intelligence in tribology. Recent Patents Mech. Eng. 2016, 9, 193–205.
- Argatov, I. Artificial Neural Networks (ANNs) as a novel modeling technique in tribology. Front. Mech. Eng. 2019, 5, 1074.
- Bell, J. Machine Learning: Hands-On for Developers and Technical Professionals; Wiley: Hoboken, NJ, USA, 2014; ISBN 978-1-118-88906-0.
- Wittpahl, V. Künstliche Intelligenz; Springer: Berlin, Germany, 2019; ISBN 978-3-662-58041-7.
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientist, 1st ed.; O’Reilly: Beijing, China, 2016; ISBN 978-1-4493-6941-5.
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002; ISBN 978-0-262-19475-4.
- Bishop, C.M. Pattern recognition and machine learning. In Information Science and Statistics; Springer: New York, NY, USA, 2006; pp. 21–24. ISBN 9780387310732.
- Freund, Y. Boosting a weak learning algorithm by majority. Inf. Comput. 1995, 121, 256–285.
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32.
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227.
- Forsyth, D. Applied Machine Learning; Springer: Cham, Switzerland, 2019; ISBN 978-3-030-18113-0.
- Sarkar, D.; Bali, R.; Sharma, T. Practical Machine Learning with Python: A Problem-Solver’s Guide to Building Real-World Intelligent Systems; Apress L.P.: Berkeley, CA, USA, 2017; ISBN 978-1-4842-3206-4.
- Kinnebrock, W. Neuronale Netze: Grundlagen, Anwendungen, Beispiele; 2., verb. Aufl.; Oldenbourg: München, Germany, 1994; ISBN 3-486-22947-8.
- Tallian, T.E. A computerized expert system for tribological failure diagnosis. J. Tribol. 1989, 111, 238–244.
- Tallian, T.E. Tribological design decisions using computerized databases. J. Tribol. 1987, 109, 381–386.
- Jones, S.P.; Jansen, R.; Fusaro, R.L. Preliminary investigation of neural network techniques to predict tribological properties. Tribol. Trans. 1997, 40, 312–320.
- Karkoub, M.; Elkamel, A. Modelling pressure distribution in a rectangular gas bearing using neural networks. Tribol. Int. 1997, 30, 139–150.
- Santner, E. Computer support in tribology—Experiments and database. Tribotest 1996, 2, 267–280.
- Myshkin, N.; Kwon, O.; Grigoriev, A.; Ahn, H.-S.; Kong, H. Classification of wear debris using a neural network. Wear 1997, 203–204, 658–662.
- Umeda, A.; Sugimura, J.; Yamamoto, Y. Characterization of wear particles and their relations with sliding conditions. Wear 1998, 216, 220–228.

