 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Xuanchen Xiang | + 6266 word(s) | 6266 | 2021-07-20 03:28:40 |
Video Upload Options
Deep Reinforcement Learning (DRL) combines Reinforcement Learning and Deep Learning. It is more capable of learning from raw sensors or images as input, enabling end-to-end learning, which opens up more applications in robotics, video games, NLP, computer vision, healthcare, and more. A milestone in value-based DRL is employing Deep Q-Networks (DQN) to play Atari games by Google DeepMindin 2013.
1. Introduction
Where V(st) is the estimated state value, initialized using a certain strategy; α is a rate that influences the convergence; Gt is the return from the time that the actor first visited the state-action pair (or sum of returns from each time it visited the pair), can be calculated as below:(12)Gt=rt+1+γrt+2+…+γT−1rT
Q-learning:(14)Q(s,a)←Q(s,a)+α[r+γmaxαQ(s′,a′)−Q(s,a)](s←s′)
SARSA:(15)Q(s,a)←Q(s,a)+α[r+γQ(s′,a′)−Q(s,a)](s←s′,a←a′)
A table of representative DRL techniques is shown inTable 1.
Table 1. Representative DRL Techniques.
| DRL Algorithms | Main Techniques | |
|---|---|---|
| Value-based | DQN [1] | Experience Replay, Target Network, Clipping Rewards, Clipping Rewards, and Skipping Frames |
| Double DQN [2] | Double Q-learning | |
| Dueling DQN [3] | Dueling Neural Network architecture | |
| Prioritized DQN [4] | Prioritized experience replay | |
| Bootstrapped DQN [5] | Deep exploration with DNNs | |
| Distributional DQN [6] | Distributional Bellman equation | |
| Noisy DQN [7] | Parametric noise added to weights | |
| Rainbow DQN [8] | Combine 6 extensions to the DQN | |
| Hierarchical DQN [9] | Hierarchical value functions | |
| Gorila [10] | Asynchronous training for multi agents | |
| Policy-based | TRPO [11] | KL divergence constraint |
| PPO [12] | Specialized clipping in the objective function | |
| Actor-Critic | Deep DPG [13] | DNN and DPG |
| TD3 [14] | Twin Delayed DDPG | |
| PGQ [15] | Policy gradient and Q-learning | |
| Soft Actor Critic (SAC) [16] | Maximum entropy RL framework | |
| A3C [17] | Asynchronous Gradient Descent |
2. Applications
| Domains | Applications |
|---|---|
| Healthcare | DTRs, HER/EMR, diagnosis |
| Education | Educational games, recommendation, proficiency estimation |
| Transportation | Traffic control |
| Energy | Decision control |
| Finance | Trading, risk management |
| Science, Engineering, Art | Math, Physics, music, animation |
| Business management | Recommendation, customer management |
| Computer systems | Resources management, security |
| Games | Board games, card games, video games |
| Robotics | Sim-to-real, control |
| Computer vision | Recognition, detection, perception |
| NLP | Sequence generation, translation, dialogue |
2.1. Games
2.1.1. Board Games
RL in Board Games
AlphaGo
2.1.2. Card Games
Texas Hold’em Poker
Hearts and Wizard
RLCard
2.1.3. Video Games

Atari
ViZDoom
TORCS
Minecraft
DeepMind Lab
Real-Time Strategy Games
| StarCraft Algorithms | Main Techniques |
|---|---|
| GMEZO [91] | Micromanagement; greedy MDP; episodic zero-order exploration |
| BiCNet [92] | Multiagent bidirectionally coordinated network |
| Stabilising Experience Replay [93] | Importance sampling; fingerprints |
| PS-MAGDS [94] | Parameter sharing multi-agent gradient descent SARSA(λ |
| ) | |
| MS-MARL [95] | Master-slave architecture; multi-agent |
| QMIX [96] | Decentralised policies in a centralised end-to-end training |
| NNFQ CNNFQ [97] | Neural network fitted Q-Learning |
| SC2LE [98] | FullyConv-A2C; baseline results |
| Relational DRL [99] | Self-attention to iteratively reason about the relations |
| TStarBots [100] | Flat action structure; hierarchical action structure |
| Modular architecture [101] | Splits responsibilities between multiple modules |
| Two-level hierarchical RL [102] | Macro-actions; a two-layer hierarchical architecture |
2.2. Robotics
2.2.1. Manipulation
Multi-Fingered Hands
Grasping
Opening a Door
Cloth Manipulation
Magnetic Manipulation
2.2.2. Locomotion
Walking/Running
Hopping
Swimming
Tensegrity
2.2.3. Robotics Simulators
2.3. Natural Language Processing
2.3.1. Neural Machine Translation
2.3.2. Dialogue
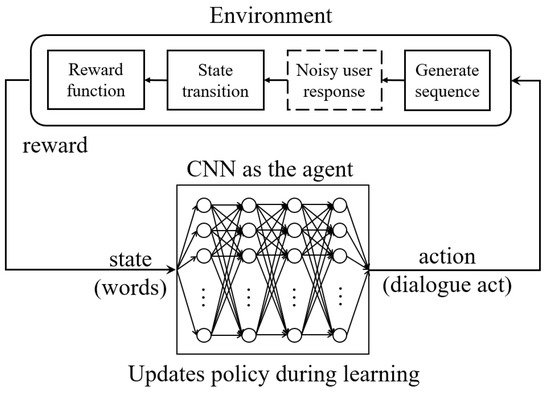
Text Generation
Sentence Simplification
Coherent Dialogues
Goal-Oriented Dialogues
2.3.3. Visual Dialogue
Visual Captioning
Visual Relationship and Attribute Detection
3. Conclusions
In this paper, we have presented the fundamental concepts of Markov Decision Processes(MDP), Partially Observable Markov Decision Processes (POMDPs), Reinforcement Learning (RL), and Deep Reinforcement Learning (DRL). Generally, we have discussed the representative DRL techniques and algorithms. The core elements of an RL algorithm are value function, policy, reward, model and planning, exploration, and knowledge. In DRL applications that were discussed, most of the algorithms applied are extensions of the representative algorithms, for example, DQN, DPG, A3C, etc., with some optimizations, respectively. We then discussed the applications of DRL in some popular domains. As DRL provides optimal policies and strategies, it has been widely utilized in gaming, including almost all kinds of games. As the leading entertainment among people, a better gaming experience is always desired. Another popular application of DRL is in Robotics. We discussed manipulation, locomotion, and other aspects of robotics where DRL can be applied. Robotics simulators are also discussed, where DRL is used to select the appropriate simulator when needed. Finally, the application of DRL in natural language processing (NLP) is presented.
As we witnessed, DRL has been developing fast and on enormous scales. Some groups pushed forward the development of DRL, like OpenAI, DeepMind, AI research office in Alberta, and research center led by Rich Sutton, and more. From the research, we have acknowledged the algorithms; variations, and the development of all the optimizations. Based on the review, we are more familiar with the usability of each method. For example, model-free methods work better in scaled-up tasks. The value function is key to RL, in DQN and its many extensions; policy gradient approaches have also been utilized in lots of applications, such as robotics, dialogue systems, machine translation, etc. New learning techniques have also been applied, such as transfer, curriculum learning, adversarial networks, etc. When we select a method or combinations of methods to apply in our models, the characteristics we need to consider are stability, convergence, generalizing power, accuracy, efficiency, scalability, robustness, safety, cost, speed, simplicity, etc. For example, in healthcare, we focus more on stability and security rather than simplicity or cost. This topic, along with applications in transportation, communications and networking, and industries, will be discussed in a Part 2 follow-up paper.
References
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602.
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. arXiv 2015, arXiv:1509.06461.
- Wang, Z.; Schaul, T.; Hessel, M.; can Hasselt, H.; Lanctot, M.; de Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016.
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2016, arXiv:1511.05952.
- Osband, I.; Blundell, C.; Pritzel, A.; Van Roy, B. Deep Exploration via Bootstrapped DQN. arXiv 2016, arXiv:1602.04621.
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017.
- Fortunato, M.; Azar, M.G.; Piot, B. Noisy Networks for Exploration. arXiv 2018, arXiv:1706.10295.
- Hessel, M.; Modayil, J.; van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining Improvements in Deep Reinforcement Learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018.
- Kulkarni, T.D.; Narasimhan, K.R.; Saeedi, A.; Tenenbaum, J.B. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation. arXiv 2016, arXiv:1604.06057.
- Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; Maria, A.D.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; et al. Massively Parallel Methods for Deep Reinforcement Learning. arXiv 2015, arXiv:1507.04296.
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.; Abbeel, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015.
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347.
- Lillicrap, T.P.; Hunt, J.J.; Alexander Pritzel, N.H.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. arXiv 2016, arXiv:1509.02971.
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. arXiv 2018, arXiv:1802.09477.
- O’Donoghue, B.; Munos, R.; Kavukcuoglu, K.; Mnih, V. Combining policy gradient and Q-learning. arXiv 2017, arXiv:1611.01626.
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018.
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016.
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2018, arXiv:1701.07274.
- Tesauro, G. TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play. Neural Comput. 1994, 6, 215–219.
- Buro, M. How Machines have Learned to Play Othello. IEEE Intell. Syst. 1999, 14, 12–14.
- Schaeffer, J.; Burch, N.; Bjornsson, Y.; Kishimoto, A.; Muller, M.; Lake, R.; Lu, P.; Sutphen, S. Checkers Is Solved. Science 2007, 317, 1518–1522.
- Ginsberg, M.L. GIB: Imperfect Information in a Computationally Challenging Game. J. Artif. Intell. Res. 2001, 14, 303–358.
- Huang, S.C.; Arneson, B.; Hayward, R.B.; Müller, M.; Pawlewicz, J. MoHex 2.0: A Pattern-Based MCTS Hex Player. In Computers and Games; van den Herik, H.J., Iida, H., Plaat, A., Eds.; Series Title: Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8427, pp. 60–71.
- Gao, C.; Hayward, R.; Muller, M. Move Prediction Using Deep Convolutional Neural Networks in Hex. IEEE Trans. Games 2018, 10, 336–343.
- Mannen, H.; Wiering, M. Learning To Play Chess Using Reinforcement Learning with Database Games. Master’s Thesis, Cognitive Artificial Intelligence Utrecht University, Utrecht, The Netherlands, October 2003.
- Block, M.; Bader, M.; Tapia, E.; Ramírez, M.; Gunnarsson, K.; Cuevas, E.; Zaldivar, D.; Rojas, R. Using Reinforcement Learning in Chess Engines. Res. Comput. Sci. 2008, 35, 31–40.
- Baxter, J.; Tridgell, A.; Weaver, L. KnightCap: A chess program that learns by combining TD(lambda) with game-tree search. arXiv 1999, arXiv:cs/9901002.
- Lai, M. Giraffe: Using Deep Reinforcement Learning to Play Chess. arXiv 2008, arXiv:1509.01549.
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489.
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359.
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144.
- Kimura, T.; Sakamoto, K.; Sogabe, T. Development of AlphaZero-based Reinforcment Learning Algorithm for Solving Partially Observable Markov Decision Process (POMDP) Problem. Bull. Netw. Comput. Syst. Softw. 2020, 9, 69–73.
- Davidson, A. Using Artifical Neural Networks to Model Opponents in Texas Hold’em. Department of Computing Science, University of Alberta, Edmonton, Alberta, Canada, November 1999. Available online: http://www.spaz.ca/aaron/poker/nnpoker.pdf (accessed on 1 July 2021).
- Davidson, A.; Billings, D.; Schaeffer, J.; Szafron, D. Improved Opponent Modeling in Poker. Department of Computing Science, University of Alberta, Edmonton, Alberta, Canada, January 2002. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.480.8603&rep=rep1&type=pdf (accessed on 1 July 2021).
- Felixa, D.; Reis, L.P. An Experimental Approach to Online Opponent Modeling in Texas Hold’em Poker. In Advances in Artificial Intelligence—SBIA 2008; Zaverucha, G., da Costa, A.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 83–92.
- Southey, F.; Bowling, M.; Larson, B.; Piccione, C.; Burch, N.; Billings, D.; Rayner, D.C. Bayes’ Bluff: Opponent Modelling in Poker. arXiv 2012, arXiv:1207.1411.
- Zinkevich, M.; Johanson, M.; Bowling, M.; Piccione, C. Regret Minimization in Games with Incomplete Information. In Advances in Neural Information Processing Systems 20; Platt, J.C., Koller, D., Singer, Y., Roweis, S.T., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2008; pp. 1729–1736.
- Bowling, M.; Burch, N.; Johanson, M.; Tammelin, O. Heads-up limit hold’em poker is solved. Science 2015, 347, 145–149.
- Brown, N.; Lerer, A.; Gross, S.; Sandholm, T. Deep Counterfactual Regret Minimization. arXiv 2018, arXiv:1811.00164.
- Moravčík, M.; Schmid, M.; Burch, N.; Lisý, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. DeepStack: Expert-level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513.
- Brown, N.; Sandholm, T. Superhuman AI for multiplayer poker. Science 2019, 365, 885–890.
- Ishii, S.; Fujita, H.; Mitsutake, M.; Yamazaki, T.; Matsuda, J.; Matsuno, Y. A Reinforcement Learning Scheme for a Partially-Observable Multi-Agent Game. Mach. Learn. 2005, 59, 31–54.
- Fujita, H.; Ishii, S. Model-based Reinforcement Learning for Partially Observable Games with Sampling-based State Estimation. Neural Comput. 2007, 19, 3051–3087.
- Sturtevant, N.R.; White, A.M. Feature Construction for Reinforcement Learning in Hearts. In International Conference on Computers and Games; Springer: Berlin/Heidelberg, Germany, 2006; pp. 122–134.
- Wagenaar, M.; Wiering, D.M. Learning to Play the Game of Hearts Using Reinforcement Learning and a Multi-Layer Perceptron. Bachelor’s Thesis, University of Groningen, Groningen, The Netherlands, 2017. Available online: http://fse.studenttheses.ub.rug.nl/id/eprint/15440 (accessed on 11 July 2021).
- Backhus, J.C.; Nonaka, H.; Yoshikawa, T.; Sugimoto, M. Application of reinforcement learning to the card game Wizard. In Proceedings of the 2013 IEEE 2nd Global Conference on Consumer Electronics (GCCE), Tokyo, Japan, 1–4 October 2013; pp. 329–333.
- Heinrich, J.; Lanctot, M. Fictitious Self-Play in Extensive-Form Games. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 805–813.
- Heinrich, J.; Silver, D. Deep Reinforcement Learning from Self-Play in Imperfect-Information Games. arXiv 2016, arXiv:1603.01121.
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Perolat, J.; Silver, D.; Graepel, T. A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4190–4203.
- Zha, D.; Lai, K.H.; Cao, Y.; Huang, S.; Wei, R.; Guo, J.; Hu, X. RLCard: A Toolkit for Reinforcement Learning in Card Games. arXiv 2019, arXiv:1910.04376.
- Shao, K.; Tang, Z.; Zhu, Y.; Li, N.; Zhao, D. A Survey of Deep Reinforcement Learning in Video Games. arXiv 2019, arXiv:1912.10944.
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res. 2013, 47, 253–279.
- Hausknecht, M.; Stone, P. Deep Recurrent Q-Learning for Partially Observable MDPs. arXiv 2017, arXiv:1507.06527.
- Zhu, P.; Li, X.; Poupart, P.; Miao, G. On Improving Deep Reinforcement Learning for POMDPs. arXiv 2018, arXiv:1704.07978.
- Aytar, Y.; Pfaff, T.; Budden, D.; Paine, T.; Wang, Z.; de Freitas, N. Playing hard exploration games by watching YouTube. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 2930–2941.
- Kempka, M.; Wydmuch, M.; Runc, G.; Toczek, J.; Jaskowski, W. ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning. In Proceedings of the 2016 IEEE Conference on Computational Intelligence and Games (CIG), Santorini, Greece, 20–23 September 2016.
- Lample, G.; Chaplot, D.S. Playing FPS Games with Deep Reinforcement Learning. arXiv 2016, arXiv:1609.05521.
- Papoudakis, G.; Chatzidimitriou, K.C.; Mitkas, P.A. Deep Reinforcement Learning for Doom using Unsupervised Auxiliary Tasks. arXiv 2018, arXiv:1807.01960.
- Akimov, D.; Makarov, I. Deep Reinforcement Learning with VizDoom First-Person Shooter. CEUR Workshop Proc. 2019, 2479, 3–17.
- Wu, Y.; Tian, Y. Training Agent for First-Person Shooter Game with Actor-Critic Curriculum Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017.
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum Learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 41–48.
- Parisotto, E.; Salakhutdinov, R. Neural Map: Structured Memory for Deep Reinforcement Learning. arXiv 2017, arXiv:1702.08360.
- Shao, K.; Zhao, D.; Li, N.; Zhu, Y. Learning Battles in ViZDoom via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; pp. 1–4.
- Koutník, J.; Schmidhuber, J.; Gomez, F. Online Evolution of Deep Convolutional Network for Vision-Based Reinforcement Learning. In Proceedings of the International Conference on Simulation of Adaptive Behavior, Aberystwyth, UK, 23–26 August 2014; pp. 260–269.
- Koutník, J.; Schmidhuber, J.; Gomez, F. Evolving deep unsupervised convolutional networks for vision-based reinforcement learning. In Proceedings of the 2014 Conference on Genetic and Evolutionary Computation—GECCO ’14, Vancouver, BC, Canada, 12–16 July 2014; ACM Press: Vancouver, BC, Canada, 2014; pp. 541–548.
- Wang, S.; Jia, D.; Weng, X. Deep Reinforcement Learning for Autonomous Driving. arXiv 2019, arXiv:1811.11329.
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. End-to-End Deep Reinforcement Learning for Lane Keeping Assist. arXiv 2016, arXiv:1612.04340.
- Liu, K.; Wan, Q.; Li, Y. A Deep Reinforcement Learning Algorithm with Expert Demonstrations and Supervised Loss and its application in Autonomous Driving. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 2944–2949.
- Verma, A.; Murali, V.; Singh, R.; Kohli, P.; Chaudhuri, S. Programmatically Interpretable Reinforcement Learning. arXiv 2019, arXiv:1804.02477.
- Sharma, S.; Lakshminarayanan, A.S.; Ravindran, B. Fine grained action repetition for deep reinforcement learning. arXiv 2017, arXiv:1702.06054.
- Gao, Y.; Xu, H.; Lin, J.; Yu, F.; Levine, S.; Darrell, T. Reinforcement Learning from Imperfect Demonstrations. arXiv 2018, arXiv:1802.05313.
- Mazumder, S.; Liu, B.; Wang, S.; Zhu, Y.; Liu, L.; Li, J. Action Permissibility in Deep Reinforcement Learning and Application to Autonomous Driving. In KDD’18 Deep Learning Day; ACM: London, UK, 2018.
- Li, D.; Zhao, D.; Zhang, Q.; Chen, Y. Reinforcement Learning and Deep Learning based Lateral Control for Autonomous Driving. arXiv 2018, arXiv:1810.12778.
- Zhu, Y.; Zhao, D. Driving Control with Deep and Reinforcement Learning in The Open Racing Car Simulator. In Neural Information Processing; Cheng, L., Leung, A.C.S., Ozawa, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 326–334.
- Johnson, M.; Hofmann, K.; Hutton, T.; Bignell, D. The Malmo Platform for Artificial Intelligence Experimentation. IJCAI. 2016. pp. 4246–4247. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.1045.1281&rep=rep1&type=pdf (accessed on 1 July 2021).
- Guss, W.H.; Houghton, B.; Topin, N.; Wang, P.; Codel, C.; Veloso, M.; Salakhutdinov, R. MineRL: A Large-Scale Dataset of Minecraft Demonstrations. arXiv 2019, arXiv:1907.13440.
- Liu, L.T.; Dogan, U.; Hofmann, K. Decoding multitask DQN in the world of Minecraft. In Proceedings of the 13th European Workshop on Reinforcement Learning (EWRL), Barcelona, Spain, 3–4 December 2016; p. 11.
- Oh, J.; Chockalingam, V.; Singh, S.P.; Lee, H. Control of Memory, Active Perception, and Action in Minecraft. arXiv 2016, arXiv:1605.09128.
- Frazier, S. Improving Deep Reinforcement Learning in Minecraft with Action Advice. arXiv 2019, arXiv:1908.01007.
- Xiong, Y.; Chen, H.; Zhao, M.; An, B. HogRider: Champion Agent of Microsoft Malmo Collaborative AI Challenge. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018.
- Tessler, C.; Givony, S.; Zahavy, T.; Mankowitz, D.J.; Mannor, S. A Deep Hierarchical Approach to Lifelong Learning in Minecraft. arXiv 2016, arXiv:1604.07255.
- Jin, P.H.; Levine, S.; Keutzer, K. Regret Minimization for Partially Observable Deep Reinforcement Learning. arXiv 2017, arXiv:1710.11424.
- Beattie, C.; Leibo, J.Z.; Teplyashin, D.; Ward, T.; Wainwright, M.; Küttler, H.; Lefrancq, A.; Green, S.; Valdés, V.; Sadik, A.; et al. DeepMind Lab. arXiv 2016, arXiv:1612.03801.
- Johnston, L. Surprise Pursuit Auxiliary Task for Deepmind Lab Maze. n.d. p. 7. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/610.pdf (accessed on 1 July 2021).
- Mankowitz, D.J.; Zídek, A.; Barreto, A.; Horgan, D.; Hessel, M.; Quan, J.; Oh, J.; van Hasselt, H.; Silver, D.; Schaul, T. Unicorn: Continual Learning with a Universal, Off-policy Agent. arXiv 2018, arXiv:1802.08294.
- Schmitt, S.; Hudson, J.J.; Zídek, A.; Osindero, S.; Doersch, C.; Czarnecki, W.M.; Leibo, J.Z.; Küttler, H.; Zisserman, A.; Simonyan, K.; et al. Kickstarting Deep Reinforcement Learning. arXiv 2018, arXiv:1803.03835.
- Jaderberg, M.; Czarnecki, W.M.; Dunning, I.; Marris, L.; Lever, G.; Castañeda, A.G.; Beattie, C.; Rabinowitz, N.C.; Morcos, A.S.; Ruderman, A.; et al. Human-level performance in first-person multiplayer games with population-based deep reinforcement learning. arXiv 2018, arXiv:1807.01281.
- Leibo, J.Z.; de Masson d’Autume, C.; Zoran, D.; Amos, D.; Beattie, C.; Anderson, K.; Castañeda, A.G.; Sanchez, M.; Green, S.; Gruslys, A.; et al. Psychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents. arXiv 2018, arXiv:1801.08116.
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354.
- Open, A.I.; Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680.
- Usunier, N.; Synnaeve, G.; Lin, Z.; Chintala, S. Episodic Exploration for Deep Deterministic Policies: An Application to StarCraft Micromanagement Tasks. arXiv 2016, arXiv:1609.02993.
- Peng, P.; Yuan, Q.; Wen, Y.; Yang, Y.; Tang, Z.; Long, H.; Wang, J. Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games. arXiv 2017, arXiv:1703.10069.
- Foerster, J.N.; Nardelli, N.; Farquhar, G.; Torr, P.H.S.; Kohli, P.; Whiteson, S. Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning. arXiv 2017, arXiv:1702.08887.
- Shao, K.; Zhu, Y.; Zhao, D. StarCraft Micromanagement With Reinforcement Learning and Curriculum Transfer Learning. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 73–84.
- Kong, X.; Xin, B.; Liu, F.; Wang, Y. Revisiting the Master-Slave Architecture in Multi-Agent Deep Reinforcement Learning. arXiv 2017, arXiv:1712.07305.
- Rashid, T.; Samvelyan, M.; de Witt, C.S.; Farquhar, G.; Foerster, J.N.; Whiteson, S. QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. arXiv 2018, arXiv:1803.11485.
- Tang, Z.; Zhao, D.; Zhu, Y.; Guo, P. Reinforcement Learning for Build-Order Production in StarCraft II. In Proceedings of the 2018 Eighth International Conference on Information Science and Technology (ICIST), Cordoba/Granada/Seville, Spain, 30 June–6 July 2018; pp. 153–158.
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.P.; Schrittwieser, J.; et al. StarCraft II: A New Challenge for Reinforcement Learning. arXiv 2017, arXiv:1708.04782.
- Zambaldi, V.F.; Raposo, D.; Santoro, A.; Bapst, V.; Li, Y.; Babuschkin, I.; Tuyls, K.; Reichert, D.P.; Lillicrap, T.P.; Lockhart, E.; et al. Relational Deep Reinforcement Learning. arXiv 2018, arXiv:1806.01830.
- Sun, P.; Sun, X.; Han, L.; Xiong, J.; Wang, Q.; Li, B.; Zheng, Y.; Liu, J.; Liu, Y.; Liu, H.; et al. TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game. arXiv 2018, arXiv:1809.07193.
- Lee, D.; Tang, H.; Zhang, J.O.; Xu, H.; Darrell, T.; Abbeel, P. Modular Architecture for StarCraft II with Deep Reinforcement Learning. arXiv 2018, arXiv:1811.03555.
- Pang, Z.J.; Liu, R.Z.; Meng, Z.Y.; Zhang, Y.; Yu, Y.; Lu, T. On reinforcement learning for full-length game of starcraft. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4691–4698.
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483.
- Deisenroth, M.P. A Survey on Policy Search for Robotics. Found. Trends Robot. 2013, 2, 1–142.
- Kober, J.; Peters, J. Reinforcement Learning in Robotics: A Survey. In Learning Motor Skills: From Algorithms to Robot Experiments; Springer International Publishing: Cham, Switzerland, 2014; pp. 9–67.
- Tai, L.; Zhang, J.; Liu, M.; Boedecker, J.; Burgard, W. A Survey of Deep Network Solutions for Learning Control in Robotics: From Reinforcement to Imitation. arXiv 2015, arXiv:1612.07139.
- Todorov, E.; Erez, T.; Tassa, Y. Mujoco: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura/Algarve, Portugal, 7–12 October 2012; pp. 5026–5033.
- Nguyen, H.; La, H. Review of Deep Reinforcement Learning for Robot Manipulation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 590–595.
- Peters, J.; Schaal, S. Reinforcement learning of motor skills with policy gradients. Neural Netw. 2008, 21, 682–697.
- Peters, J.; Schaal, S. Natural actor-critic. Neurocomputing 2008, 71, 1180–1190.
- Theodorou, E.; Buchli, J.; Schaal, S. Reinforcement learning of motor skills in high dimensions: A path integral approach. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2397–2403.
- Peters, J.; Mülling, K.; Altun, Y. Relative entropy policy search. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; Volume 10, pp. 1607–1612.
- Kalakrishnan, M.; Righetti, L.; Pastor, P.; Schaal, S. Learning force control policies for compliant manipulation. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 4639–4644.
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming Exploration in Reinforcement Learning with Demonstrations. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6292–6299.
- Kumar, V.; Tassa, Y.; Erez, T.; Todorov, E. Real-time behaviour synthesis for dynamic hand-manipulation. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6808–6815.
- Kumar, V.; Todorov, E.; Levine, S. Optimal control with learned local models: Application to dexterous manipulation. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 378–383.
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Schulman, J.; Todorov, E.; Levine, S. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. arXiv 2017, arXiv:1709.10087.
- Haarnoja, T.; Pong, V.; Zhou, A.; Dalal, M.; Abbeel, P.; Levine, S. Composable Deep Reinforcement Learning for Robotic Manipulation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6244–6251.
- Zhu, H.; Gupta, A.; Rajeswaran, A.; Levine, S.; Kumar, V. Dexterous Manipulation with Deep Reinforcement Learning: Efficient, General, and Low-Cost. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3651–3657.
- Huang, S.H.; Zambelli, M.; Kay, J.; Martins, M.F.; Tassa, Y.; Pilarski, P.M.; Hadsell, R. Learning Gentle Object Manipulation with Curiosity-Driven Deep Reinforcement Learning. arXiv 2019, arXiv:1903.08542.
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-End Training of Deep Visuomotor Policies. arXiv 2015, arXiv:1504.00702.
- Pinto, L.; Gupta, A. Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours. arXiv 2015, arXiv:1509.06825.
- Levine, S.; Pastor, P.; Krizhevsky, A.; Quillen, D. Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection. arXiv 2016, arXiv:1603.02199.
- Popov, I.; Heess, N.; Lillicrap, T.P.; Hafner, R.; Barth-Maron, G.; Vecerík, M.; Lampe, T.; Tassa, Y.; Erez, T.; Riedmiller, M.A. Data-efficient Deep Reinforcement Learning for Dexterous Manipulation. arXiv 2017, arXiv:1704.03073.
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. arXiv 2018, arXiv:1806.10293.
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, Singapore, 29 May–3 June 2017; pp. 3389–3396.
- Tsurumine, Y.; Cui, Y.; Uchibe, E.; Matsubara, T. Deep reinforcement learning with smooth policy update: Application to robotic cloth manipulation. Robot. Auton. Syst. 2019, 112, 72–83.
- Jangir, R.; Alenya, G.; Torras, C. Dynamic Cloth Manipulation with Deep Reinforcement Learning. arXiv 2019, arXiv:1910.14475.
- de Bruin, T.; Kober, J.; Tuyls, K.; Babuška, R. Improved deep reinforcement learning for robotics through distribution-based experience retention. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 3947–3952.
- Özalp, R.; Kaymak, C.; Yildirum, Ö.; Ucar, A.; Demir, Y.; Güzeliş, C. An Implementation of Vision Based Deep Reinforcement Learning for Humanoid Robot Locomotion. In Proceedings of the 2019 IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), Sofia, Bulgaria, 3–5 July 2019; pp. 1–5.
- Danel, M. Reinforcement learning for humanoid robot control. POSTER May 2017.
- Haarnoja, T.; Zhou, A.; Ha, S.; Tan, J.; Tucker, G.; Levine, S. Learning to Walk via Deep Reinforcement Learning. arXiv 2018, arXiv:1812.11103.
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4299–4307.
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540.
- Peng, X.B.; Berseth, G.; Yin, K.; Van De Panne, M. DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning. ACM Trans. Graph. 2017, 36.
- Berseth, G.; Xie, C.; Cernek, P.; Van de Panne, M. Progressive reinforcement learning with distillation for multi-skilled motion control. arXiv 2018, arXiv:1802.04765.
- Nagabandi, A.; Kahn, G.; Fearing, R.S.; Levine, S. Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7559–7566.
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1329–1338.
- Xie, Z.; Berseth, G.; Clary, P.; Hurst, J.; van de Panne, M. Feedback Control For Cassie With Deep Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1241–1246.
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-Real: Learning Agile Locomotion For Quadruped Robots. arXiv 2018, arXiv:1804.10332.
- Huang, Y.; Wei, G.; Wang, Y. V-D D3QN: The Variant of Double Deep Q-Learning Network with Dueling Architecture. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9130–9135.
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533.
- Peng, X.B.; Berseth, G.; Van de Panne, M. Terrain-adaptive locomotion skills using deep reinforcement learning. ACM Trans. Graph. (TOG) 2016, 35, 1–12.
- Heess, N.; Wayne, G.; Tassa, Y.; Lillicrap, T.P.; Riedmiller, M.A.; Silver, D. Learning and Transfer of Modulated Locomotor Controllers. arXiv 2016, arXiv:1610.05182.
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. arXiv 2017, arXiv:1702.08165.
- Pinto, L.; Davidson, J.; Sukthankar, R.; Gupta, A. Robust Adversarial Reinforcement Learning. arXiv 2017, arXiv:1703.02702.
- Verma, S.; Novati, G.; Koumoutsakos, P. Efficient collective swimming by harnessing vortices through deep reinforcement learning. Proc. Natl. Acad. Sci. USA 2018, 115, 5849–5854.
- Zhang, M.; Geng, X.; Bruce, J.; Caluwaerts, K.; Vespignani, M.; SunSpiral, V.; Abbeel, P.; Levine, S. Deep reinforcement learning for tensegrity robot locomotion. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, Singapore, 29 May–3 June 2017; pp. 634–641.
- Luo, J.; Edmunds, R.; Rice, F.; Agogino, A.M. Tensegrity Robot Locomotion Under Limited Sensory Inputs via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6260–6267.
- Wikipedia. Robotics Simulator. Available online: https://en.wikipedia.org/wiki/Robotics_simulator (accessed on 1 July 2021).
- Wang, W.Y.; Li, J.; He, X. Deep reinforcement learning for NLP. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Melbourne, Australia, 15–20 July 2018; pp. 19–21.
- Sharma, A.R.; Kaushik, P. Literature survey of statistical, deep and reinforcement learning in natural language processing. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 350–354.
- Xiong, C. Recent Progress in Deep Reinforcement Learning for Computer Vision and NLP. In Proceedings of the 2017 Workshop on Recognizing Families in the Wild, RFIW ’17, New York, NY, USA, 27 October 2017; Association for Computing Machinery. p. 1.
- Lapan, M. Deep Reinforcement Learning Hands-On: Apply Modern RL Methods, with Deep Q-Networks, Value Iteration, Policy Gradients, TRPO, AlphaGo Zero and More; Packt Publishing Ltd.: Birmingham, UK, 2018.
- Gao, J.; Galley, M.; Li, L. Neural approaches to conversational AI. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1371–1374.
- Wu, L.; Tian, F.; Qin, T.; Lai, J.; Liu, T. A Study of Reinforcement Learning for Neural Machine Translation. arXiv 2018, arXiv:1808.08866.
- He, D.; Xia, Y.; Qin, T.; Wang, L.; Yu, N.; Liu, T.Y.; Ma, W.Y. Dual Learning for Machine Translation. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 820–828.
- Satija, H.; Pineau, J. Simultaneous machine translation using deep reinforcement learning. In Proceedings of the ICML 2016 Workshop on Abstraction in Reinforcement Learning, International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016.
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. OpenNMT: Open-Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:1701.02810.
- Zhang, J.; Ding, Y.; Shen, S.; Cheng, Y.; Sun, M.; Luan, H.; Liu, Y. THUMT: An Open Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:1706.06415.
- Yang, Z.; Chen, W.; Wang, F.; Xu, B. Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets. arXiv 2017, arXiv:1703.04887.
- Wu, L.; Xia, Y.; Tian, F.; Zhao, L.; Qin, T.; Lai, J.; Liu, T.Y. Adversarial neural machine translation. In Proceedings of the 10th Asian Conference on Machine Learning, PMLR, Beijing, China, 14–16 November 2018; pp. 534–549.
- Jurafsky, D.; Martin, J.H. Speech & Language Processing—Third Edition Draft; Pearson Education India: New Delhi, India, 2019.
- Cuayáhuitl, H.; Renals, S.; Lemon, O.; Shimodaira, H. Evaluation of a hierarchical reinforcement learning spoken dialogue system. Comput. Speech Lang. 2010, 24, 395–429.
- Cuayáhuitl, H.; Dethlefs, N. Spatially-aware dialogue control using hierarchical reinforcement learning. Acm Trans. Speech Lang. Process. (TSLP) 2011, 7, 1–26.
- Cuayáhuitl, H.; Kruijff-Korbayová, I.; Dethlefs, N. Nonstrict hierarchical reinforcement learning for interactive systems and robots. Acm Trans. Interact. Intell. Syst. (TiiS) 2014, 4, 1–30.
- Cuayáhuitl, H.; Keizer, S.; Lemon, O. Strategic Dialogue Management via Deep Reinforcement Learning. arXiv 2015, arXiv:1511.08099.
- Cuayáhuitl, H. SimpleDS: A Simple Deep Reinforcement Learning Dialogue System. In Dialogues with Social Robots: Enablements, Analyses, and Evaluation; Jokinen, K., Wilcock, G., Eds.; Springer Singapore: Singapore, 2017; pp. 109–118.
- Cuayáhuitl, H.; Yu, S. Deep reinforcement learning of dialogue policies with less weight updates. In Poceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017.
- Cuayáhuitl, H.; Lee, D.; Ryu, S.; Cho, Y.; Choi, S.; Indurthi, S.; Yu, S.; Choi, H.; Hwang, I.; Kim, J. Ensemble-based deep reinforcement learning for chatbots. Neurocomputing 2019, 366, 118–130.
- Jaques, N.; Ghandeharioun, A.; Shen, J.H.; Ferguson, C.; Lapedriza, À.; Jones, N.; Gu, S.; Picard, R.W. Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog. arXiv 2019, arXiv:1907.00456.
- Ranzato, M.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. arXiv 2015, arXiv:1511.06732.
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256.
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.; Bengio, Y. An actor-critic algorithm for sequence prediction. arXiv 2016, arXiv:1607.07086.
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017.
- Li, Z.; Jiang, X.; Shang, L.; Li, H. Paraphrase Generation with Deep Reinforcement Learning. arXiv 2017, arXiv:1711.00279.
- Zhang, X.; Lapata, M. Sentence simplification with deep reinforcement learning. arXiv 2017, arXiv:1703.10931.
- Li, J.; Monroe, W.; Ritter, A.; Jurafsky, D.; Galley, M.; Gao, J. Deep Reinforcement Learning for Dialogue Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016.
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215.
- Dhingra, B.; Li, L.; Li, X.; Gao, J.; Chen, Y.; Ahmed, F.; Deng, L. End-to-End Reinforcement Learning of Dialogue Agents for Information Access. arXiv 2016, arXiv:1609.00777.
- Keizer, S.; Guhe, M.; Cuayáhuitl, H.; Efstathiou, I.; Engelbrecht, K.P.; Dobre, M.; Lascarides, A.; Lemon, O. Evaluating Persuasion Strategies and Deep Reinforcement Learning Methods for Negotiation Dialogue Agents. ACL. In Proceedings of the 15th Conference of the European chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017.
- Ilievski, V.; Musat, C.; Hossmann, A.; Baeriswyl, M. Goal-Oriented Chatbot Dialog Management Bootstrapping with Transfer Learning. arXiv 2018, arXiv:1802.00500.
- Ciou, P.H.; Hsiao, Y.T.; Wu, Z.Z.; Tseng, S.H.; Fu, L.C. Composite reinforcement learning for social robot navigation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2553–2558.
- Das, A.; Kottur, S.; Moura, J.M.; Lee, S.; Batra, D. Learning cooperative visual dialog agents with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2951–2960.
- Strub, F.; De Vries, H.; Mary, J.; Piot, B.; Courville, A.; Pietquin, O. End-to-end optimization of goal-driven and visually grounded dialogue systems. arXiv 2017, arXiv:1703.05423.
- Liu, S.; Zhu, Z.; Ye, N.; Guadarrama, S.; Murphy, K. Improved Image Captioning via Policy Gradient Optimization of SPIDEr. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017.
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057.
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning. arXiv 2016, arXiv:1612.01887.
- Ren, Z.; Wang, X.; Zhang, N.; Lv, X.; Li, L.J. Deep Reinforcement Learning-Based Image Captioning With Embedding Reward. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017.
- Wang, X.; Chen, W.; Wang, Y.; Wang, W.Y. No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling. arXiv 2018, arXiv:1804.09160.
- Wang, X.; Chen, W.; Wu, J.; Wang, Y.F.; Wang, W.Y. Video Captioning via Hierarchical Reinforcement Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018.
- Pasunuru, R.; Bansal, M. Reinforced video captioning with entailment rewards. arXiv 2017, arXiv:1708.02300.
- Liang, X.; Lee, L.; Xing, E.P. Deep variation-structured reinforcement learning for visual relationship and attribute detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 848–857.

