 +1 credit
+1 credit
| Version | Summary | Created by | Modification | Content Size | Created at | Operation |
|---|---|---|---|---|---|---|
| 1 | Alla Marchenko | + 3162 word(s) | 3162 | 2020-06-29 06:04:43 | | | |
| 2 | Catherine Yang | -12 word(s) | 3150 | 2020-07-23 09:00:40 | | |
Video Upload Options
Since 1997, scientists have been trying to utilize new non-invasive approaches for thermal discomfort detection, which promise to be more effective for comparing frameworks that need direct responses from users. Due to rapid technological development in the bio-metrical field, a systematic literature review to investigate the possibility of thermal discomfort detection at the work place by non-invasive means using bio-sensing technology was performed. Firstly, the problem intervention comparison outcome context (PICOC) framework was introduced in the study to identify the main points for meta-analysis and, in turn, to provide relevant keywords for the literature search. In total, 2776 studies were found and processed using the preferred reporting items for systematic reviews and meta-analyses (PRISMA) methodology. After filtering by defined criterion, 35 articles were obtained for detailed investigation with respect to facility types used in the experiment, amount of people for data collection and algorithms used for prediction of the thermal discomfort event. The given study concludes that there is potential for the creation of non-invasive thermal discomfort detection models via utilization of bio-sensing technologies, which will provide a better user interaction with the built environment, potentially decrease energy use and enable better productivity. There is definitely room for improvement within the field of non-invasive thermal discomfort detection, especially with respect to data collection, algorithm implementation and sample size, in order to have opportunities for the deployment of developed solutions in real life. Based on the literature review, the potential of novel technology is seen to utilize a more intelligent approach for performing non-invasive thermal discomfort prediction. The architecture of deep neural networks should be studied more due to the specifics of its hidden layers and its ability of hierarchical data extraction. This machine learning algorithm can provide a better model for thermal discomfort detection based on a data set with different types of bio-metrical variables.
1. Introduction
Over the last 50 years, people have become increasingly bound to the indoor workplace. The regular worker spends around 35 hours per week in front of the computer, at brainstorming sessions and meetings. Due to this fact, there is a need to provide good indoor environment quality, not only because it will result in fewer sick leave periods but also because it will result in improved productivity.
A number of studies have been conducted to determine ways in which indoor comfort can bring an increase in quality and productivity among the employees [1] [2] [3][4][5][6][7], and even more studies have been conducted to find a way to reduce energy consumption while still providing comfortable indoor conditions [8][9][10][11][12][13]. In general, comfort can be divided into three groups: physical, functional and psychological. The given review is focused only on indoor thermal comfort which is a part of physical comfort within indoor environment quality (IEQ)[14]. It is an important topic due to current climate change conditions, abnormality in temperature peaks concerning different seasons and general overheating and over-cooling challenges.
Indoor thermal comfort is assured by the combination of different aspects such as clothing insulation, levels of activity, radiation exchange, air temperature, air movement and humidity[15]. A variety of these factors can be predefined by age, sex, diet or even clothing requirements at the workplace[16][17]. Therefore, a number of the studies have been performed in order to find a correlation between measurable parameters and actual comfort.
Thermal comfort is traditionally evaluated by using predicted mean vote (PMV) and predicted percentage of dissatisfied (PPD) models (indexes). The PMV model developed by Fanger [18] represents the mean thermal sensation vote on a standard 7-point scale: +3 Hot; +2 Warm; +1 Slightly warm; 0 Neutral; -1 Slightly cold; -2 Cool; -3 Cold.
It is also referred to as the seven-point ASHRAE thermal sensation scale. The PPD is a quantitative measure of the thermal comfort for a group of people within a given thermal environment[9]. Both PPD and PMV were adopted by several international standards and guidelines, such as ASHRAE Standard 55 [19] and ISO 7730[20]. The PMV model was widely used for different building types and within different climate zones around the world, which resulted in a deviation between predicted and actual thermal sensations. Such a deviation may be explained by the fact that the given model was developed in a laboratory setting, which means it contains constraints that are not typical for buildings in real life [21]. Due to given circumstances, the adaptive thermal comfort model was proposed in 1970 [22]. Nicol et al. [23] suggested a feedback approach for thermal comfort field surveys’ interpretation, which was based on the fact that unpleasant sensations would lead to physical reactions and cause a change in the comfort control system itself. Humphreys and Nicol [24] suggested a list of physiological, psychological, social and behavioral actions which can restore comfort conditions in response to cold or heat. Since people live in different climate zones, they can experience different perceptions of the indoor thermal environment, and as a result, have their levels of "usual" indoor temperature altered. The same can be applied for seasonal outdoor temperature change. If a person enters a room with indoor temperature 21 ºC, he/she would feel warmer if the outside temperature is −1ºC
but a totally different response will accrue if it is summer and the outside temperature is 30ºC.
That is why many studies have been conducted for thermal comfort evaluation on a personal level. Such studies are focused more on creating numerical thermal comfort models that take into account cultural identities, human body heat exchange, metabolic activities and other parameters which define each person individually[25]. Additionally, a number of studies have been done for HVAC control automation based on the usage of artificial neural networks (ANN) and other machine learning (ML) algorithms for personal thermal comfort evaluation[26].
In recent years, the field of non-invasive bio-sensing technology has made huge progress, creating good conditions for research aimed at studying ways for such technology introduction within the field of indoor thermal comfort. This combination has a potential to reduce bias in the HVAC system that has originated from the continuous request of personal feedback on thermal conditions or the need for manual user adjustment of the thermostat or opening of the windows. Such a personal bio-sensing system may provide a better user experience, while reducing energy consumption and prevention of the overheating/over-cooling period within the individual’s thermal environment.
The main research question for this study is: What are the options for determining thermal discomfort by non-invasive means using bio-sensing technology? Within the given paper, the approaches and (or) models which were developed in order to track comfort or to predict/prevent thermal discomfort events within office work space are evaluated. If proven that thermal discomfort can be tracked and prevented in advance, the deployment of such a system can revolutionize indoor environment quality and personal experience within office space.
2. Discussion
The discussion of processed studies within the systematic literature review is presented (see Figure 1) in following steps: definition of the data collection space, population sampling, data collection, pre-processing of the data, algorithms’ implementations, results and discussion and opportunities for further development.
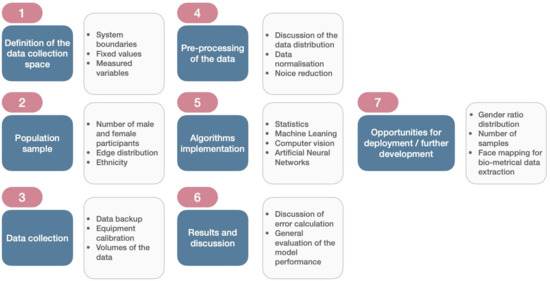
Figure 1. General steps sequence among processed studies.
The usage of diverse experimental space for data collection can be explained by different factors, such as the definition of the study scope and its budget. Environmental chambers and other types of laboratories which provide total control of the environment are quite expensive and should usually be booked in advance. Unfortunately, there is no explanation behind the selection of the variables among processed studies. The frequency of the variables used alters from study to study, which can be explained by the specific criteria behind their use in each study. Some studies were more focused on cheaper and less complicated solutions[27][28][29] which (if proven function properly) may be build quickly and have a good market value. Other studies[30][31][32] were focused on the collection of different types of data by different equipment, which in turn would allow the use of a variety of algorithms in order to detect thermal discomfort and evaluate which algorithms perform better under given conditions.
There is a lack of explanation behind the selection of the population samples in the processed studies. Additionally, some studies [33][34][35][36][37][38][28]discuss in detail the limitations posed by the number of participants and that the number of people should be increased in order to make their code/models perform better in real life applications. In addition, the sex of participants is not discussed in detail. In general, it is good to see that studies have more or less equal sex distribution during last few years in comparison to earlier studies from 1997–2014, where the number of males was several times larger than that of females[39].
General data utilization flow is shown at Figure 2. It illustrates the broad nature of variables and components used for predicting thermal discomfort via machine learning algorithms, artificial neural network and statistics. The section dedicated to the bio-metrical data covers all data related to participants’ biological parameters. This type of data should be handled in a strict way, since the combination of bio-metrical variables can destroy the anonymity of data sampling within a study. Due to given circumstances, the protocol for data collection should be developed with sections that have detailed descriptions of the data protection, encryption and sample ID generation. Such strict rules may be one of the reasons why “Skin Temperature” and “Pulse” were the most commonly used variables among processed studies. For example, “BMI” in combination with “height” can provide private information about a person’s lifestyle and general appearance which can compromise the results of the study. Given circumstances create additional milestones within bio-metric data collection, especially in cases where certain facial mapping data collection is involved.
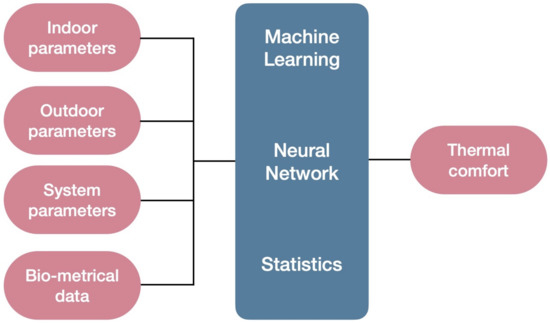
Figure 2. General scheme of data flow among case studies.
The algorithm implementation step also differs from study to study. There are only few algorithms which were used repeatedly. One of them was SVM, which is a supervised learning algorithm represented by a discriminative classifier formally defined by a separating hyper plane[40]. Kernel, regularization and gamma are tuning parameters for SVM. Those parameters can easily introduce non-linear data separation into the classes, which, if used correctly, can increase the accuracy of the prediction[41]. A decision tree is also a supervised learning algorithm; since it is based on queries, by building a specific set of questions and answers, the algorithm can gradually reach a specified level of confidence in order to provide the answer to the global question[40]. A decision tree algorithm has no prior knowledge with respect to the outside world, which is why each relationship must be taught/introduced into the system. Each node contains a piece of information gained for predicting the target value. During the implementation of the algorithm, there are two possible options at each step, “true” and “false”, in order to evaluate whether a specific criterion is met. By conducting queries, the algorithm will reach some prediction that is the best fit for the relation introduced in the system. The evolution of the decision tree algorithm is a random forest. It combines a number of decision trees into one so called “forest” [42][43]. Since each decision tree naturally has a random subset of features during the process of question formulation, and has access to a random set of training data points, a combination of several decision trees into the forest allows for the introduction of greater diversity, which results in a more robust prediction. For cases where we need to predict continuous variables (skin temperature for example), the random forest takes the average of all individual decision tree predictions. However, if there is a need to solve the classification problem (e.g., “comfortable”; “uncomfortable”) instead of regression, the random forest will follow the majority of the vote for a predicted class [44].
Linear regression is another type of algorithm that uses supervised learning. It was developed for statistical purposes but has evolved into other fields. It was originally used to evaluate, understand and study the relationship between input and output numerical variables. On its own, simple form linear regression is shown to perform poorly in some cases due to the complexity of the real world. That is why the given algorithm evolved into ordinary least squares and gradient descent [40]. The following assumptions are made for linear regression: the relationship between input and output data is linear; data are cleaned and all noise is removed; highly correlated data should be treated since overfitting may be a big problem in given case; transforming functions may be implemented in order to make data follow the Gaussian distribution; and standardization or normalization of the parameters should be performed in order to increase the accuracy of the prediction. The k-NN is yet another supervised learning algorithm. Also named the lazy learning algorithm[43], it uses the same data for training and testing. The k-NN does not introduce any assumptions about the provided data set, which makes it non-parametric[45]. It is usually helpful for classification problems such as decision support systems.
ANN can be both a supervised and an unsupervised learning algorithm, depending on the purpose of the neural network and its architecture. ANN is a group of nodes connected with each other in a way that mimics brain behavior and function [45][40]. The deep neural network, which was used in the study by Cheng et al. [36], represents a more complex architecture of neural network layers. Multiple layers were used to extract higher level features from the raw data.
All those algorithms were used to predict whether a person is comfortable or not within provided indoor conditions. In general, it is a good approach for the given task, but, as was mentioned before in the brief description of each algorithm, overfitting is a significant problem that may occur in each algorithm’s implementation[40][43]. Only a few articles described how they approached this problem [46][47][36][31][48][49]. For studies which had only few test subjects and a relatively small volume of data, the question of overfitting might not be a problem, but it is common practice to use a number of actions with respect to each algorithm.
The complexity of thermal comfort perception by each human will always raise the question of validity for predictors in a data set. The findings of SLR show different sets of variables in combination with a number of algorithms and potential models. The Achiles heel of this topic is the tenuous link (if any) established between the non-invasive bio marker and that nebulous state of mind. The basic biological theory behind a collection of the skin images, heart rate, blood pressure and other parameters, is that the body is predefined by nature to restore conditions, which are comfortable for the functioning of the organism. Such a biological feature gives the assumption that there is a link between a certain bio-metrical trait and the actual feeling of thermal comfort. Unfortunately, there is a need to perform more targeted research within the field before it will be possible to validate certain bio-metrical parameters as the ones suitable for thermal comfort prediction.
For better validation, it would be beneficial to utilize the link between the thermoregulation system and the subcortical level of the brain (or lower brain). Since the human body must to maintain core temperature within a normal range (e.g., 36.5–37.C),the thermoregulation system needs continuous information flow from temperature-sensitive nerves. The signals travel from temperature-sensitive nerves through the spinal cord to subcortical level of the brain, where they are evaluated and the body’s physiological features are adjusted respectively[50]. Based on such human body function, a new approach in non-invasive thermal comfort sensing is envisioned. For artificial intelligence algorithms, it is proposed to synthesize and use only those bio markers, which have direct interaction link to the lower brain that is directly responsible for the thermal comfort evaluation.
3. Conclusions
This study carried out a systematic literature review about the possibilities for determining indoor thermal discomfort by non-invasive means using bio-sensing technology. The review concludes that there is great potential for utilizing digital bio-sensing equipment within the given topic. Bio-metrical data can provide grounds for estimation of the thermal comfort at the workplace [46][35][51]. The facial skin temperature has proven to be a very useful parameter for the training of the machine learning algorithms. The facial skin temperature can be extracted without the placement of the sensors directly on a person’s skin, due to the fact that facial skin is always exposed to the indoor conditions without any layers of clothes. It is useful for deployment of the developed models, since the models can directly extract variables on which they were trained.
The majority of the reviewed studies used regular cameras and post-process pictures or thermal cameras which provided images directly [52][53][54]. This approach has a good potential to be used in everyday life, but there are some challenges for the given technology. There should be a large amount of data collected to train algorithms, since skin color is very different for each person; lighting in the office may change during working hours, which may introduce bias into comfort prediction; and people may have different levels of blood circulation within their fingers due to a variety of personal health factors. That is why many studies have been done for thermal comfort evaluation on a personal level. Other studies [55][56][57] tried to use fitness bands and other sensors which might be directly secured on a person’s hand or installed in glasses[53]. The given technology can provide good results, but more investigation should be done, since the deployment of such systems has not been fully discussed. It is a complicated task to install all sensors onto glasses that people are using. Additionally, people who are not wearing glasses will be pushed to wear fake ones so that there is a frame to mount sensors[53]. Another issue is a privacy concern with the usage of the fitness band. It is unlikely that people would want to synchronize their private devices with work servers, since such equipment contains personal information such as the hour of waking up and private messages. It is important to provide a user-friendly solution that is not violating personal data privacy while still providing personal comfort. Based on the literature review, it is possible to conclude that there is potential for the creation of non-invasive thermal discomfort detection models via utilization of bio-sensing technologies, which will provide better user interaction with the built environment, potentially decrease energy use and enable better productivity. A deep neural network with multiple hidden layers for learning characteristics of the data in a feature hierarchy way has shown potential for further development and use in future studies. By defining the architecture of the layers in the model, information from different data types can be extracted and processed more efficiently and potentially provide a more accurate prediction of future discomfort events.
References
- Shin-Ichi Tanabe; Masaoki Haneda; Naoe Nishihara; Workplace productivity and individual thermal satisfaction. Building and Environment 2015, 91, 42-50, 10.1016/j.buildenv.2015.02.032.
- Ana Chadburn; Judy Smith; Joshua Milan; Productivity drivers of knowledge workers in the central London office environment. Journal of Corporate Real Estate 2017, 19, 66-79, 10.1108/jcre-12-2015-0047.
- Mark Mulville; Nicola Callaghan; David Isaac; The impact of the ambient environment and building configuration on occupant productivity in open-plan commercial offices. Journal of Corporate Real Estate 2016, 18, 180-193, 10.1108/jcre-11-2015-0038.
- Haynes, B.P; Impact of workplace connectivity on office productivity. Journal of Corporate Real Estate 2008, 10, 286-302, 10.1108/14630010810925145.
- Takashi Akimoto; Shin-Ichi Tanabe; Takashi Yanai; Masato Sasaki; Thermal comfort and productivity - Evaluation of workplace environment in a task conditioned office. Building and Environment 2010, 45, 45-50, 10.1016/j.buildenv.2009.06.022.
- Baričič, Andrej, Temeljotov Salaj, Alenka.; The impact of office workspace on the satisfaction of employees and their overall health-research presentation. Zdravniški vestnik 2014, 83, 217-231.
- Alenka Temeljotov-Salaj; The synergetic effect of the observer on the built environment. Urbani izziv 2009, 16, 163-167, 10.5379/urbani-izziv-en-2005-16-02-005.
- António Figueiredo; Romeu Vicente; José Alberto Marques Lapa; Claudino Cardoso; M. Fernanda Rodrigues; Jérôme Kämpf; Indoor thermal comfort assessment using different constructive solutions incorporating PCM. Applied Energy 2017, 208, 1208-1221, 10.1016/j.apenergy.2017.09.032.
- Liu Yang; Haiyan Yan; Joseph C. Lam; Thermal comfort and building energy consumption implications – A review. Applied Energy 2014, 115, 164-173, 10.1016/j.apenergy.2013.10.062.
- Yacine Allab; Margot Pellegrino; Xiaofeng Guo; Elyes Nefzaoui; Andrea Kindinis; Energy and comfort assessment in educational building: Case study in a French university campus. Energy and Buildings 2017, 143, 202-219, 10.1016/j.enbuild.2016.11.028.
- António Figueiredo; José Figueira; Romeu Vicente; Rui Maio; Thermal comfort and energy performance: Sensitivity analysis to apply the Passive House concept to the Portuguese climate. Building and Environment 2016, 103, 276-288, 10.1016/j.buildenv.2016.03.031.
- Francesca Romana D'ambrosio Alfano; Bjarne W. Olesen; Boris Igor Palella; Giuseppe Riccio; Thermal comfort: Design and assessment for energy saving. Energy and Buildings 2014, 81, 326-336, 10.1016/j.enbuild.2014.06.033.
- Jowkar, Mina, Hom Bahadur Rijal, Azadeh Montazami, James Brusey, and Alenka Temeljotov-Salaj.; The influence of acclimatization, age and gender-related differences on thermal perception in university buildings: Case studies in Scotland and England. Building and Environment 2020, 179, 106933.
- Marchenko, A.; Carlucci, S.; Pagliano, L.; Pietrobon, M.; Karlessi, T.; Santamouris, M.; Delaere, N.;Assimakopoulos, M. The assessment of the environmental quality directly perceived and experienced by the employees of 69 European offices. In Proceedings of the 10th Windsor Conference: Rethinking Comfort, Windsor, UK, 12–15 April 2018; pp. 1017–1028.
- Michael A. Humphreys; J. Fergus Nicol; Iftikhar A. Raja; Field Studies of Indoor Thermal Comfort and the Progress of the Adaptive Approach. Advances in Building Energy Research 2007, 1, 55-88, 10.1080/17512549.2007.9687269.
- Cristiana Verona Croitoru; Ilinca Nastase; Florin Bode; Amina Meslem; Angel Dogeanu; Thermal comfort models for indoor spaces and vehicles—Current capabilities and future perspectives. Renewable and Sustainable Energy Reviews 2015, 44, 304-318, 10.1016/j.rser.2014.10.105.
- Attia, S.; Hensen, J.L. Investigating the impact of different thermal comfort models for zero energy buildings in hot climates. In Proceedings of the 1st International Conferenceon Energy and Indoor Environment for Hot Climates, Doha, Qatar, 24–26 February 2014.
- Fanger, P.O. Thermal Comfort. Analysis and Applications in Environmental Engineering; Danish Technical Press: Copenhagen, Denmark, 1970.
- Standard, A. Standard 55-2010, Thermal Environmental Conditions for Human Occupancy; American Society of Heating, Refrigerating, and Air-Conditioning Engineers: Atlanta, GA, USA, 2010.
- ISO. ISO 7730:2005 Ergonomics of the Thermal Environment—Analytical determination and Interpretation of Thermal Comfort Using Calculation of the PMV and PPD Indices and Local Thermal Comfort Criteria; ISO: Geneva, Switzerland, 2005; p. 10.
- Y.H. Yau; Bt Chew; A review on predicted mean vote and adaptive thermal comfort models. Building Services Engineering Research and Technology 2012, 35, 23-35, 10.1177/0143624412465200.
- Runming Yao; BaiZhan Li; Jing Liu; A theoretical adaptive model of thermal comfort – Adaptive Predicted Mean Vote (aPMV). Building and Environment 2009, 44, 2089-2096, 10.1016/j.buildenv.2009.02.014.
- Nicol, J.F.; Humphreys, M. Understanding the adaptive approach to thermal comfort. ASHRAE Trans. 1998, 104, 991–1004.
- Nicol, F.; Humphreys, M.; Roaf, S. Adaptive The rmal Comfort: Principles and Practice; Routledge: Abingdon, UK, 2012.
- Yuanda Cheng; Jianlei Niu; Naiping Gao; Thermal comfort models: A review and numerical investigation. Building and Environment 2012, 47, 13-22, 10.1016/j.buildenv.2011.05.011.
- Weiwei Liu; Zhiwei Lian; Bo Zhao; A neural network evaluation model for individual thermal comfort. Energy and Buildings 2007, 39, 1115-1122, 10.1016/j.enbuild.2006.12.005.
- Ueda, M.; Taniguchi, Y.; Aoki, H. A new method to predict the thermal sensation of an occupant using a neural network and its application to the automobile HVAC system. JSME Int. J. Ser. B Fluids Therm. Eng. 1997, 40, 166–174.
- Xiaogang Cheng; Bin Yang; Thomas Olofsson; Guoqing Liu; Haibo Li; A pilot study of online non-invasive measuring technology based on video magnification to determine skin temperature. Building and Environment 2017, 121, 1-10, 10.1016/j.buildenv.2017.05.021.
- B. Pavlin; G. Carabin; G. Pernigotto; A. Gasparella; Renato Vidoni; An Embedded Mechatronic Device for Real-Time Monitoring and Prediction of Occupants’ Thermal Comfort. Volume 8: Heat Transfer and Thermal Engineering 2018, -, -, 10.1115/imece2018-87632.
- Laftchiev, E.; Nikovski, D. An IoT system to estimate personal thermal comfort. In Proceedings of the 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 672–677.
- Tanaya Chaudhuri; Deqing Zhai; Yeng Chai Soh; Hua Li; Lihua Xie; Xianhua Ou; Convolutional Neural Network and Kernel Methods for Occupant Thermal State Detection using Wearable Technology. 2018 International Joint Conference on Neural Networks (IJCNN) 2018, -, 1-8, 10.1109/ijcnn.2018.8489069.
- Farrokh Jazizadeh; Geoffrey Kavulya; Laura Klein; Burcin Becerik-Gerber; Continuous Sensing of Occupant Perception of Indoor Ambient Factors. Computing in Civil Engineering (2011) 2011, -, 161-168, 10.1061/41182(416)20.
- Quan Jin; Lin Duanmu; Experimental study of thermal sensation and physiological response during step changes in non-uniform indoor environment. Science and Technology for the Built Environment 2016, 22, 237-247, 10.1080/23744731.2016.1124714.
- Joon-Ho Choi; Dongwoo Yeom; Study of data-driven thermal sensation prediction model as a function of local body skin temperatures in a built environment. Building and Environment 2017, 121, 130-147, 10.1016/j.buildenv.2017.05.004.
- Chaudhuri, T.; Zhai, D.; Soh, Y.C.; Li, H.; Xie, L. Random forest based thermal comfort prediction from gender-specificphysiologicalparametersusingwearablesensingtechnology. EnergyBuild.2018,166,391–406.
- Xiaogang Cheng; Bin Yang; Kaige Tan; Erik Isaksson; LiRen Li; Anders Hedman; Thomas Olofsson; Haibo Li; A Contactless Measuring Method of Skin Temperature based on the Skin Sensitivity Index and Deep Learning. Applied Sciences 2019, 9, 1375, 10.3390/app9071375.
- Berardo Matalucci; Kenton Phillips; Alicia A Walf; Anna Dyson; Joshua Draper; An experimental design framework for the personalization of indoor microclimates through feedback loops between responsive thermal systems and occupant biometrics. International Journal of Architectural Computing 2017, 15, 54-69, 10.1177/1478077117691601.
- Vesely, M.; Zeiler, W. Fingertip temperature as a control signal for personalized heating. In Proceedings of the 13th International Conference on Indoor Air Quality and Climate (Indoor Air 2014), Hong Kong, China, 7–12 June 2014; pp. 464–470.
- Matsuei Ueda; Yousuke Taniguchi; Hiroshi Aoki; A New Method to Predict the Thermal Sensation of an Occupant Using a Neural Network and Its Application to the Automobile HVAC System.. JSME International Journal Series B 1997, 40, 166-174, 10.1299/jsmeb.40.166.
- Mitchell, T.M. Machine Learning; McGraw Hill: New York, NY, USA, 1997.
- Bennett, K.P.; Campbell, C. Support vector machines: Hype or hallelujah? ACM SIGKDD Explor. Newsl.2000, 2, 1–13.
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42.
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020.
- Richter, M.M.; Weber, R.O. Case-Based Reasoning; Springer: Berlin, Germany, 2016.
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016.
- Jongseong Gwak; Motoki Shino; Kazutaka Ueda; Minoru Kamata; Effects of Changes in the Thermal Factor on Arousal Level and Thermal Comfort. 2015 IEEE International Conference on Systems, Man, and Cybernetics 2015, -, 923-928, 10.1109/smc.2015.169.
- Da Li; Carol C. Menassa; Vineet R. Kamat; Non-intrusive interpretation of human thermal comfort through analysis of facial infrared thermography. Energy and Buildings 2018, 176, 246-261, 10.1016/j.enbuild.2018.07.025.
- Siliang Lu; Weilong Wang; Shihan Wang; Erica Cochran Hameen; Thermal Comfort-Based Personalized Models with Non-Intrusive Sensing Technique in Office Buildings. Applied Sciences 2019, 9, 1768, 10.3390/app9091768.
- Katarina Katić; Rongling Li; Jacob Verhaart; Wim Zeiler; Neural network based predictive control of personalized heating systems. Energy and Buildings 2018, 174, 199-213, 10.1016/j.enbuild.2018.06.033.
- Ivana Špelić; Alka Mihelić-Bogdanić; Anica Hursa Šajatović; Standard Methods for Thermal Comfort Assessment of Clothing. Standard Methods for Thermal Comfort Assessment of Clothing 2019, -, -, 10.1201/9780429422997.
- Deqing Zhai; Tanaya Chaudhuri; Yeng Chai Soh; Energy efficiency improvement with k-means approach to thermal comfort for ACMV systems of smart buildings. 2017 Asian Conference on Energy, Power and Transportation Electrification (ACEPT) 2017, -, 1-6, 10.1109/acept.2017.8168568.
- Andrei Claudiu Cosma; Rahul Simha; Machine learning method for real-time non-invasive prediction of individual thermal preference in transient conditions. Building and Environment 2019, 148, 372-383, 10.1016/j.buildenv.2018.11.017.
- Ali Ghahramani; Guillermo Castro; Burcin Becerik-Gerber; Xinran Yu; Infrared thermography of human face for monitoring thermoregulation performance and estimating personal thermal comfort. Building and Environment 2016, 109, 1-11, 10.1016/j.buildenv.2016.09.005.
- Lu, S.; Cochran Hameen, E. Integrated IR Vision Sensor for Online Clothing Insulation Measurement. In Proceedings of the 23rd International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Beijing, China, 17–19 May 2018; Volume 1, pp. 565–573.
- Francesco Salamone; Lorenzo Belussi; Cristian Currò; Ludovico Danza; Matteo Ghellere; Giulia Guazzi; Bruno Lenzi; Valentino Megale; Italo Meroni; Integrated Method for Personal Thermal Comfort Assessment and Optimization through Users’ Feedback, IoT and Machine Learning: A Case Study †. Sensors 2018, 18, 1602, 10.3390/s18051602.
- Wei Li; Jili Zhang; Tianyi Zhao; Indoor thermal environment optimal control for thermal comfort and energy saving based on online monitoring of thermal sensation. Energy and Buildings 2019, 197, 57-67, 10.1016/j.enbuild.2019.05.050.
- Liliana Barrios; Wilhelm Kleiminger; The Comfstat - automatically sensing thermal comfort for smart thermostats. 2017 IEEE International Conference on Pervasive Computing and Communications (PerCom) 2017, -, 257-266, 10.1109/percom.2017.7917872.

