This entry offers policymakers and researchers pragmatic and sustainable approaches to identify and mitigate conflict threats by looking beyond p-values and plausible instruments. We argue that predicting conflict successfully depends on the choice of algorithms, which, if chosen accurately, can reduce economic and social instabilities caused by post-conflict reconstruction. After collating data with variables linked to conflict, we used a grid level dataset of 5928 observations spanning 48 countries across sub-Saharan Africa to predict civil conflict. The goals of the study were to assess the performance of supervised classification machine learning (ML) algorithms in comparison with logistic model, assess the implication of selecting a specific performance metric on policy initiatives, and evaluate the value of interpretability of the selected model. After comparing class imbalance resampling methods, the synthetic minority over-sampling technique (SMOTE) was employed to improve out-of-sample prediction for the trained model. The results indicate that if our selected performance metric is recall, gradient tree boosting is the best algorithm; however, if precision or F1 score is the selected metric, then the multilayer perceptron algorithm produces the best model.
1. Introduction
Machine learning approaches empirical analysis as algorithms that estimate and compare different alternate scenarios. This fundamentally differs from econometric analysis, where the researcher chooses a specification based on principles and estimates the best model. Instead, machine learning is based on improving and changing models dynamically, which is data-driven. It enables researchers and policymakers to improve their predictions and analysis over time with evolving technology and data points. While research on conflict and violence in economic and policy sciences has progressed substantially in recent times, most of this literature focuses on identifying the possible drivers of conflict while ensuring the underlying assumptions of the data-generating process are met
[1][2]. Model selection in such an econometric analysis of conflict is dominated by issues of identification, variable direction, as well as the magnitude of estimates, thereby imposing additional constraint on the response of policymakers. Most of the contemporary literature draws a causal connection to conflict with sociopolitical and geographic variables
[3][4][5][6], whereby researchers identify variables and their associated, unbiased coefficients that cause conflict. The general goal is to maximize the t-statistic, thereby increasing estimation confidence and averting a type II error. However, we ask if from a policy perspective, are these investigations effective in mitigating, and more importantly, preventing conflict? We argue that conflict prevention is better than incurring the costs of conflict. Accordingly, we reformulate the research question to whether a region is susceptible to imminent conflict through a comparison of different econometric and machine learning models.
To examine how binary choice algorithms used in traditional econometrics compares to supervised machine learning algorithms, we have carefully synthesized data on violent conflict, geographical, socioeconomic, political, and agricultural variables. We used data from the Armed Conflict Location and Event Data (ACLED) Project
[7], which records violence prevalence information, as opposed to the Uppsala Conflict Data Program (UCDP) database, which codes civil war onset and fatality information
[2][8]. Our rationale for this approach lies in our efforts to impact policy changes at a state or district level. Our approach of including a larger sphere of conflict events, especially less fatal ones, has the potential of generating effective policy pathways to prevent mass atrocities. Conflict prevention or mitigation goes beyond civil war deterrence and the promotion of peace. Often, smaller events are warning signs which, if detected, can prevent potential civil wars. Our combined variables are scaled to a 0.5 × 0.5-degree grid scale. The ACLED data provides information on the prevalence of conflict events including battles, violence against civilians, remote violence, rioting and protesting against a government, and non-violent conflict within the context of war. Next, we have identified and described a set of novel and standard prediction algorithms currently dominating the machine learning literature. Machine learning provides a set of algorithms that can be used to improve prediction accuracy over classic predictive techniques such as logistic algorithm. Supervised (classification) machine learning (ML) approaches have gained popularity due to their ability to outperform simple algorithms such as logistic algorithms, providing more accurate out-of-sample predictions
[9]. In as much as ML-supervised algorithms have gained popularity, their use in conflict prediction is still limited and class imbalance is not explicitly addressed
[10][11]. Imbalance occurs when the number of observations reporting conflict are not equally distributed, and this might bias the algorithm’s out-of-sample prediction towards the dominant class (observations or locations without conflict). In our study, we have explicitly addressed classification imbalance. We argue that policymakers can obtain good prediction on incidences of conflict using existing data and applying ML algorithms that can assist in developing the best model for identifying the onset of conflict, thus reducing socioeconomic costs. Finally, we have compared the performances of the logistic model (binary choice model) against four machine learning algorithms and subsequently discuss the best path forward for policymakers.
Contemporary studies on conflict prediction suffer from a few drawbacks, as discussed in detail in the following section. To begin with, most of these studies are limited in their geographical scope or use of high-resolution data. Furthermore, they often indicate low performance in accuracy. Finally, in cases where multiple models are compared, the studies neither explicitly illustrate how addressing imbalance increases model performance nor compare predictive performance between using a reduced set of indicators. In contrast, our initiative distinguishes and contributes to the novel yet emerging body of literature on conflict prediction in the following ways. First, in the realm of the machine learning and conflict mitigation literature, our synthesized datasets are exhaustive and fine-combed. Our study spans over 40 countries in sub-Saharan Africa and examines conflict at a finer grid resolution within each country to predict conflict incidences at a sub-national level. From a policy perspective, our model selection is data driven, whereby a large range of models are considered. However, we have carefully selected confidence intervals as well as document model selection processes. Second, while our intention is neither to carry out causal analysis nor impact evaluation, we have listed the top 25 predictors of conflict that may assist policymakers. We hope that our efforts can at least enable policymakers to focus on a few key drivers of conflict. Third, and most importantly, we have compared performances across five classification algorithms while addressing issues of class imbalance that are pervasive in conflict analysis and provide information on the best imbalance resampling methods that provides the most accurate prediction. Additionally, we compare the differences on the possible efficacy and precision of these models. While the philosophical and scientific needs to investigate the drivers of conflict are undeniable, policy prescription needs to be pragmatic. In our model comparisons, we examine the gains obtained from using different ML models in comparison to the logistic model and discuss how performance metrics of the models may be of different value to different policy markers given the context. The trade-off between the models depends on the objective that the policymaker wants to achieve. Traditional causal analysis of conflict puts emphasis on in-sample prediction power and extreme caution towards not accepting a false hypothesis. However, for successful policies to prevent random yet fatal conflict, out-of-sample predictions along with caution towards neglecting harbingers of catastrophic uprising, i.e., rejecting the true hypotheses, may be more important. ML classification prediction problems are focused on a lower classification error and thereby provide a much better approach. The performance metrics shed light on the important policy conundrum of deciding whether institutions should prioritize preventing conflict or preserving resources for post-conflict development.
2. Research on Conflict Prediction in Sub-Saharan Africa
This study compares the logistic regression algorithm to machine learning algorithms in order to predict civil conflict in sub-Saharan Africa. This analysis creates a useful debate on which measure of prediction policymakers should prioritize—precision or recall—and how and when this choice would differ. In addition, this paper raises important questions as to why and when scientists should use ML approaches in the field of conflict assessment. Is it worthwhile to try and predict civil conflict with the new machine learning algorithms, given the available data? As such, our effort improves on the existing literature by collating a higher resolution dataset, adding gradient boosting mechanisms to the analysis and comprehensively comparing across several classification models while addressing issues of class imbalance.
The problem of class imbalance is ubiquitous in predicting conflict, wherein we observe disproportionately lower cases of conflict compared to ones without conflict. Correcting for issues of imbalance improves the performance of the algorithms—in particular, the recall scores. Modeling conflict data that has an imbalanced class problem creates two issues: (i) accuracy is not a good performance measure, and (ii) training a model using an imbalanced class may not provide good out-of-sample predictions where recall is a key metric for model evaluation. Using the models trained on an imbalanced dataset, our results indicate a higher accuracy rate than those trained using techniques that adjust from imbalance, SMOTE and NearMiss, but lower recall rates. The models trained on an imbalanced dataset have a high accuracy rate that is higher than the no-information rate in three algorithms, except for the support vector machines and gradient boosting. In the latter two, we see minimal increases to the no-information rate. This indicates that the accuracy rate is lower than the rate of the largest class (no conflict) in three models. Therefore, accuracy might not be a good measure for imbalanced classes, since it will be expected to have a high accuracy rate biased towards the majority class.
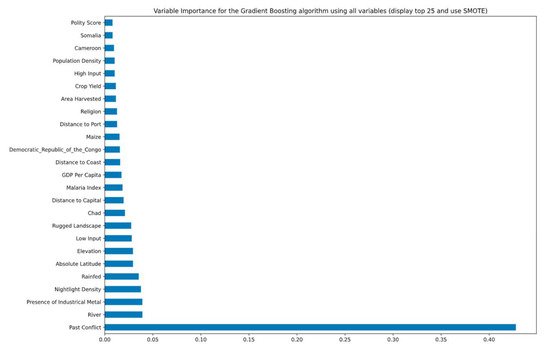
Our models are trained with future data to predict out-of-sample data. This approach mimics the real-world scenario of training current conflict to predict future data. Comparing performance across models, we found better predictions across all models for recall measures when imbalance was addressed compared to results where imbalance was not addressed. We have investigated two types of class imbalance learning methods—an over-sampling technique (SMOTE) and under-sampling technique (NearMiss). We found that although the results in terms of which algorithm performs best on precision, recall, and F1 score are similar, overall, the SMOTE technique provides better results on precision and recall on average. Focusing on the SMOTE technique results, we found that when the metric of interest is recall, gradient boosting outperforms all other algorithms; however, when the metric of interest is precision, multilayer perceptron provides the best results. Since recall is a critical metric in predicting and preventing conflict, where we are more interested in identifying all potential conflict areas, gradient boosting appears to be the best model for policymakers (a key drawback of the gradient boosting model is that it took three times as much time to train on a 16 GB RAM laptop than the other four algorithms. This implies that if time is an issue, random forest might be a second-best option). Another advantage of the gradient boosting model is that we can obtain a ranking of the most important variables (see Figure 1 for variable importance in predicting conflict). This not only improves our prediction of conflict but can also provide policymakers with guidance on which key predictors to collect data on in order to develop early warning systems. Not surprisingly, we have observed that past conflict is a critical predictor of future conflict. In addition, areas located near a developed city, which can be proxied with high night light density, is a good predictor of conflict. Another key predictor was the presence of industrial metals. The extant literature concerning sub-Saharan Africa has previously shown that the presence of minerals is a strong driver of conflict through extractive institutions.
Figure 1. List of 25 of the most important variables used to predict conflict using the gradient boosting algorithm.
From a policy perspective, our results emphasize the trade-offs between recall and precision in making appropriate decisions. On the one hand, a high recall measure is of importance since we prefer lower false negatives, i.e., identifying all areas with potential conflict. On the other hand, this implies that some areas that might be predicted as conflict zones will not observe conflict in reality, and any resources diverted to such areas will come at the cost of other, more fragile areas. The question then becomes whether it is important for the policymakers be informed of all potential areas that might experience conflict, even though the true outcome may be that conflict does not occur in some of the identified areas. Or would they rather ensure that most areas where conflict might occur are correctly predicted, with some areas being overlooked? This is the trade-off that policymakers need to assess depending on the existing infrastructure and available resources and on how much it might cost them to put in place preventative measures relative to the potential benefits.
Overall, we found that not all modern machine learning algorithms outperform the traditional logistic model. However, the ones that do so provide better performance across all metrics (recall and precision). When recall is the chosen measure, tree-based ML algorithms such as gradient boosting and random forest outperform the logistic regression algorithm; however, if we rank the balance using the F1 score, the logit model ranks among the top half of the five algorithms. If the policy goal is to minimize this trade-off, policymakers can consider selecting a balanced model with a high F1 score. However, if a modeler wants a balanced model with good precision and recall, then the multilayer perceptron algorithm provides the best model with a high F1 score. The trade-off with the multilayer perceptron that is similar with the SVM is that the model is like a black box. The model output provides predictions of performance metrics but does not indicate which variables are important in making that prediction. If understanding and examining the key predictor variables is of importance to the policymaker, then the best, most balanced model with SMOTE is the gradient boosting model, followed by the logit model. Therefore, given the discussed trade-offs in performance, we present all the recall and precision measures in our data that provide this information across all five models. This approach will enable the decision makers to choose the most appropriate model according to their goals and priorities.
 +1 credit
+1 credit