Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Arterial hypertension (AH) is a progressive issue that grows in importance with the increased average age of the world population. The potential role of artificial intelligence (AI) in its prevention and treatment is firmly recognized. Indeed, AI application allows personalized medicine and tailored treatment for each patient.
- hypertension
- artificial intelligence
- machine learning
1. The Principles of AI
AI is a wide-ranging branch of computer science concerned with building smart machines capable of increasing their knowledge through an automatic learning process that typically requires human intelligence [1][2][3]. Therefore, AI is an interdisciplinary science with multiple approaches that incorporate reasoning (making inferences using data), natural language processing (ability to read and understand human languages), planning (ability to act autonomously and flexibly to create a sequence of actions to achieve a final goal), and machine learning (ML) (algorithms that develop automatically through experience) [1]. Specifically, AI based on ML techniques [4] is used to perform predictive analyses by examining mechanisms and associations among given variables from training datasets, which may consist of a variety of data inputs, including wearable devices, multi-omics, and standardized EHRs [5][6]. Essentially, in ML, the rules would be learned by algorithms directly from a set of data rather than being encoded by hand [7]; consequently, by using specific algorithms, ML can establish complex relationships among data, rules governing a system, behavioral patterns, and classification schemes [4]. The classic ML process begins with data acquisition, continues with feature extraction, algorithm selection, and model development, and leads to model evaluation and application [8] (Figure 1). Supervised and unsupervised learning are the most popular approaches employed in ML. Supervised learning is used to predict unknown outputs from a known labeled dataset, hypotheses, and appropriate algorithms, such as an artificial neural network (ANN), support vector machine (SVM), and K-nearest neighbor. The choice of the technique depends on the dataset’s features, number of variables, learning curve, training, and computation time [9][10]. Specifically, supervised learning provides predictions from big data analytics but requires manually labeled datasets and biases that can arise from the dataset itself or the algorithms [6].
Figure 1. The typical ML workflow in healthcare research.
On the other hand, in unsupervised learning techniques, there is no information on the features to be predicted; consequently, these techniques must learn from the relationships among the elements of a dataset and classify them without basing them on categories or labels [2]. Therefore, they look for structures, patterns, or characteristics in the source data that can be reproduced in new datasets [4]. ML mainly mimics the nervous system’s structure by creating ANNs, which are networks of units called artificial neurons structured into layers [11]. The system learns to generate patterns from data entered in the training session [11]. A specific ANN, consisting of more layers that allow for improved predictions from data, is known as a deep neural network (DNN). Its performance could be enhanced as the dimension of the training dataset rises [7]. Still, it largely depends on the distribution gap between training and test datasets: a highly divergent test dataset would test an ML prediction model on a feature space that it was not trained on, resulting in poor testing and results; additionally, a highly overlapping test dataset would not test the model for its generalization ability [12]. Specifically, DL employs algorithms such as DNNs and convolutional neural networks (CNNs) [4]. Nevertheless, regardless of its capability of using unlabeled datasets, unsupervised learning still has some limitations, such as the generalizability of cluster patterns identified from a cohort of patients, which can lead to overfitting to the training dataset, and the need to be validated in different large datasets [6]. In the real world, AI can provide tools to improve and extend the effectiveness of clinical interventions [4]. For example, incorporating AI into hypertension management could improve every stage of patient care, from diagnosis to therapy; consequently, the clinical practice could become more efficient and effective.
2. AI in the Measurement of Blood Pressure
The commonly used methods for BP monitoring are either non-invasive inflatable cuff-based oscillometric or invasive arterial line manometric measurement. The former takes intermittent measures because a pause of at least 1–2 min between two BP measurements is necessary to avoid errors in the measurement [13][14]; moreover, the inflation of the cuff may disturb the patient, and the consequences of these disturbances are alterations in BP [15]. On the other hand, invasive arterial line manometric measurement has an elevated risk of complications; consequently, these unsolved issues drive the search for new non-invasive BP monitoring techniques.
In this scenario, AI algorithms could help improve precision, accuracy, and reproducibility in diagnosing and managing AH using emerging wearable technologies. Alternatives for monitoring BP are cuff-based devices (such as volume-clamp devices or wrist-worn inflatable cuffs) and cuffless devices that use mechanical and optical sensors to determine features of the blood pulse waveform shape (for example, tonometry [16], photoplethysmography [17], and capacitance [14]). In particular, cuffless blood pressure monitoring has been evaluated using a two-step algorithm with a single-channel photoplethysmograph (PPG). This system achieved an AAMI/ISO standard accuracy in all blood pressure categories except systolic hypotension [18]. Independently of the acquisition method, the received signals are preprocessed and sent for feature extraction and selection. Subsequently, the signals and the gathered data can be used to feed ML to obtain systolic BP (SBP) and diastolic BP (DBP) estimations from the raw signals [17] (Figure 2).
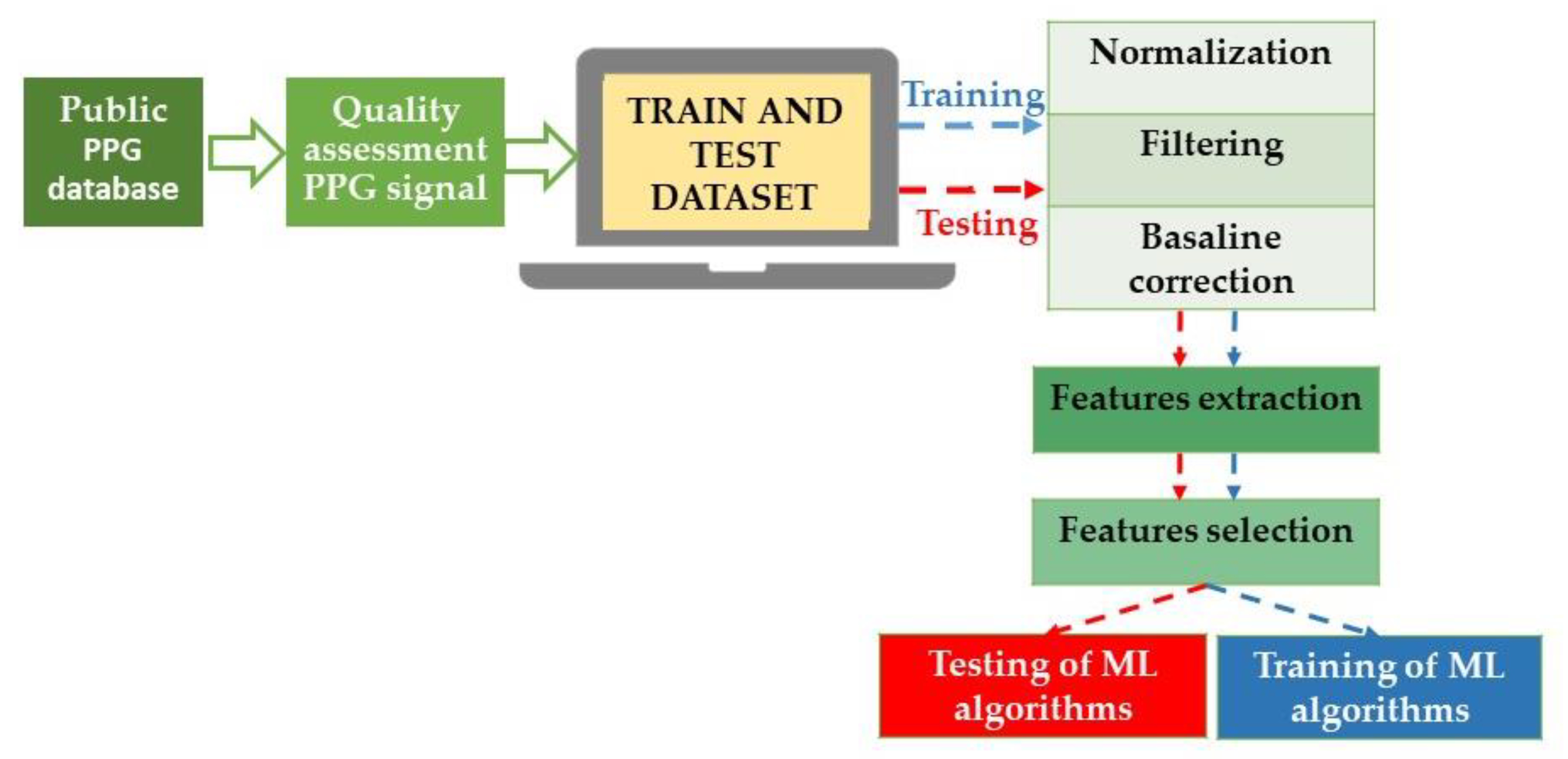
Figure 2. Block diagram of the blood pressure estimation process using ML techniques. In detail, the raw signals are prepared through normalization, the correction of baseline wandering due to respiration, and finally, signal filtration. Specifically, to construct a dataset for BP estimation models, it is necessary to accurately extract the features of the original waveform (and underlying demographic and statistical data) and select effective features, improving the generalization and reducing the risk of overfitting the algorithms. PPG: photoplethysmograph; ML: machine learning.
Since the volume and distension of arteries can be related to the pressure in the arteries, the PPG signal produces pulse waveforms that are similar to pressure waveforms created by tonometry. PPG offers the added advantage that it can be measured continuously using miniature, inexpensive, and wearable optical electronics [19]. However, PPG signal measurements are not without technical challenges; indeed, they require noise elimination, multisite measurement, multiphotodector development, event detection, event visualization, different models, the accurate positioning of sensors, and the calculation of propagation distances, without neglecting the impact of the variable PEP time on the pulse wave velocity timing [19]. Moreover, there are several PPG-based methods for estimating BP: the PPG signal alone and its derivate, ECG and PPG signals, BCG and PPG signals, and PCG and PPG signals; each has advantages and limitations [20][21][22][23][24], which, however, are beyond this discussion.
ML Algorithms in BP Estimation
To adapt to the nonlinearity of the dataset and to create a relationship between features and estimated BP, there are different ML approaches [25]:
-
Ensemble trees: The idea is to pull together a set of weak learners to create a strong learner [27].
After hyper-parameter optimization, it is necessary to evaluate the performance of ML algorithms through the correlation between the acquired predicted data and the ground-truth data. The difference between reference and estimated BP could be considered using the following criteria: the mean absolute error, mean squared error, and correlation coefficient [17]. The role of parameter optimization is to lower the value of the predicted error. The mean absolute and standard deviations are the model’s predictive performance indicators.
Specifically, these AI-based systems could help continuously monitor BP using wearable technologies and improve AH management and outcomes [15][32]. Starting from the input (raw signals), researchers can reach the output (estimated SBP and DBP) through the algorithms of ML [6]. In particular, BP can be estimated from a PPG signal obtained from a smartphone or a smartwatch by using DL [36][37].
Moreover, future studies on AI and wearable devices need to confirm the above results and provide conclusive clinical data to support using a combination of AI and wearable-device-obtained data to correctly perform BP measurements, which may offer an alternative to current oscillometric methods [6].
This entry is adapted from the peer-reviewed paper 10.3390/jcdd10020074
References
- Padmanabhan, S.; Tran, T.Q.B.; Dominiczak, A.F. Artificial Intelligence in Hypertension: Seeing Through a Glass Darkly. Circ. Res. 2021, 128, 1100–1118.
- Dorado-Diaz, P.I.; Sampedro-Gomez, J.; Vicente-Palacios, V.; Sanchez, P.L. Applications of Artificial Intelligence in Cardiology. The Future is Already Here. Rev. Esp. Cardiol. Engl. Ed. 2019, 72, 1065–1075.
- Bonderman, D. Artificial intelligence in cardiology. Wien. Klin. Wochenschr. 2017, 129, 866–868.
- Visco, V.; Ferruzzi, G.J.; Nicastro, F.; Virtuoso, N.; Carrizzo, A.; Galasso, G.; Vecchione, C.; Ciccarelli, M. Artificial Intelligence as a Business Partner in Cardiovascular Precision Medicine: An Emerging Approach for Disease Detection and Treatment Optimization. Curr. Med. Chem. 2020, 28, 6569–6590.
- Dzau, V.J.; Balatbat, C.A. Future of Hypertension. Hypertension 2019, 74, 450–457.
- Chaikijurajai, T.; Laffin, L.J.; Tang, W.H.W. Artificial Intelligence and Hypertension: Recent Advances and Future Outlook. Am. J. Hypertens. 2020, 33, 967–974.
- Schmidt-Erfurth, U.; Sadeghipour, A.; Gerendas, B.S.; Waldstein, S.M.; Bogunovic, H. Artificial intelligence in retina. Prog. Retin. Eye Res. 2018, 67, 1–29.
- Johnson, K.W.; Torres Soto, J.; Glicksberg, B.S.; Shameer, K.; Miotto, R.; Ali, M.; Ashley, E.; Dudley, J.T. Artificial Intelligence in Cardiology. J. Am. Coll. Cardiol. 2018, 71, 2668–2679.
- Bzdok, D.; Krzywinski, M.; Altman, N. Machine learning: Supervised methods. Nat. Methods 2018, 15, 5–6.
- Krittanawong, C.; Zhang, H.; Wang, Z.; Aydar, M.; Kitai, T. Artificial Intelligence in Precision Cardiovascular Medicine. J. Am. Coll. Cardiol. 2017, 69, 2657–2664.
- Ahuja, A.S. The impact of artificial intelligence in medicine on the future role of the physician. PeerJ 2019, 7, e7702.
- Turhan, B. On the dataset shift problem in software engineering prediction models. Empir. Softw. Eng. 2012, 17, 62–75.
- Campbell, N.R.; Chockalingam, A.; Fodor, J.G.; McKay, D.W. Accurate, reproducible measurement of blood pressure. CMAJ 1990, 143, 19–24.
- Quan, X.; Liu, J.; Roxlo, T.; Siddharth, S.; Leong, W.; Muir, A.; Cheong, S.M.; Rao, A. Advances in Non-Invasive Blood Pressure Monitoring. Sensors 2021, 21, 4273.
- Gesche, H.; Grosskurth, D.; Kuchler, G.; Patzak, A. Continuous blood pressure measurement by using the pulse transit time: Comparison to a cuff-based method. Eur. J. Appl. Physiol. 2012, 112, 309–315.
- Huang, K.H.; Tan, F.; Wang, T.D.; Yang, Y.J. A Highly Sensitive Pressure-Sensing Array for Blood Pressure Estimation Assisted by Machine-Learning Techniques. Sensors 2019, 19, 848.
- Chowdhury, M.H.; Shuzan, M.N.I.; Chowdhury, M.E.H.; Mahbub, Z.B.; Uddin, M.M.; Khandakar, A.; Reaz, M.B.I. Estimating Blood Pressure from the Photoplethysmogram Signal and Demographic Features Using Machine Learning Techniques. Sensors 2020, 20, 3127.
- Khalid, S.; Liu, H.; Zia, T.; Zhang, J.; Chen, F.; Zheng, D. Cuffless Blood Pressure Estimation Using Single Channel Photoplethysmography: A Two-Step Method. IEEE Access 2020, 8, 58146–58154.
- Elgendi, M.; Fletcher, R.; Liang, Y.; Howard, N.; Lovell, N.H.; Abbott, D.; Lim, K.; Ward, R. The use of photoplethysmography for assessing hypertension. NPJ Digit. Med. 2019, 2, 60.
- Zheng, Y.; Poon, C.C.; Yan, B.P.; Lau, J.Y. Pulse Arrival Time Based Cuff-Less and 24-H Wearable Blood Pressure Monitoring and its Diagnostic Value in Hypertension. J. Med. Syst. 2016, 40, 195.
- Pandian, P.S.; Mohanavelu, K.; Safeer, K.P.; Kotresh, T.M.; Shakunthala, D.T.; Gopal, P.; Padaki, V.C. Smart Vest: Wearable multi-parameter remote physiological monitoring system. Med. Eng. Phys. 2008, 30, 466–477.
- Plante, T.B.; Urrea, B.; MacFarlane, Z.T.; Blumenthal, R.S.; Miller, E.R., 3rd; Appel, L.J.; Martin, S.S. Validation of the Instant Blood Pressure Smartphone App. JAMA Intern. Med. 2016, 176, 700–702.
- Zhang, Q.; Zhou, D.; Zeng, X. Highly wearable cuff-less blood pressure and heart rate monitoring with single-arm electrocardiogram and photoplethysmogram signals. Biomed. Eng. Online 2017, 16, 23.
- Radha, M.; de Groot, K.; Rajani, N.; Wong, C.C.P.; Kobold, N.; Vos, V.; Fonseca, P.; Mastellos, N.; Wark, P.A.; Velthoven, N.; et al. Estimating blood pressure trends and the nocturnal dip from photoplethysmography. Physiol. Meas. 2019, 40, 025006.
- Hare, A.J.; Chokshi, N.; Adusumalli, S. Novel Digital Technologies for Blood Pressure Monitoring and Hypertension Management. Curr. Cardiovasc. Risk Rep. 2021, 15, 11.
- Nour, M.; Kandaz, D.; Ucar, M.K.; Polat, K.; Alhudhaif, A. Machine Learning and Electrocardiography Signal-Based Minimum Calculation Time Detection for Blood Pressure Detection. Comput. Math. Methods Med. 2022, 2022, 5714454.
- Kumar, P.S.; Rai, P.; Ramasamy, M.; Varadan, V.K.; Varadan, V.K. Multiparametric cloth-based wearable, SimpleSense, estimates blood pressure. Sci. Rep. 2022, 12, 13059.
- Mase, M.; Mattei, W.; Cucino, R.; Faes, L.; Nollo, G. Feasibility of cuff-free measurement of systolic and diastolic arterial blood pressure. J. Electrocardiol. 2011, 44, 201–207.
- Park, M.; Kang, H.; Huh, Y.; Kim, K.C. Cuffless and noninvasive measurement of systolic blood pressure, diastolic blood pressure, mean arterial pressure and pulse pressure using radial artery tonometry pressure sensor with concept of Korean traditional medicine. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2007, 2007, 3597–3600.
- Kachuee, M.; Kiani, M.M.; Mohammadzade, H.; Shabany, M. Cuffless Blood Pressure Estimation Algorithms for Continuous Health-Care Monitoring. IEEE Trans. Biomed. Eng. 2017, 64, 859–869.
- Monte-Moreno, E. Non-invasive estimate of blood glucose and blood pressure from a photoplethysmograph by means of machine learning techniques. Artif. Intell. Med. 2011, 53, 127–138.
- Peng, R.C.; Yan, W.R.; Zhang, N.L.; Lin, W.H.; Zhou, X.L.; Zhang, Y.T. Cuffless and Continuous Blood Pressure Estimation from the Heart Sound Signals. Sensors 2015, 15, 23653–23666.
- Khalid, S.G.; Zhang, J.; Chen, F.; Zheng, D. Blood Pressure Estimation Using Photoplethysmography Only: Comparison between Different Machine Learning Approaches. J. Healthc. Eng. 2018, 2018, 1548647.
- Yan, C.; Li, Z.; Zhao, W.; Hu, J.; Jia, D.; Wang, H.; You, T. Novel Deep Convolutional Neural Network for Cuff-less Blood Pressure Measurement Using ECG and PPG Signals. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2019, 2019, 1917–1920.
- Rastegar, S.; Gholamhosseini, H.; Lowe, A.; Mehdipour, F.; Linden, M. Estimating Systolic Blood Pressure Using Convolutional Neural Networks. Stud. Health Technol. Inform. 2019, 261, 143–149.
- Tison, G.H.; Singh, A.C.; Ohashi, D.A.; Hsieh, J.T.; Ballinger, B.M.; Olgin, J.E.; Marcus, G.M.; Pletcher, M.J. Abstract 21042: Cardiovascular Risk Stratification Using Off-the-Shelf Wearables and a Multi-Task Deep Learning Algorithm. Circulation 2017, 136, A21042.
- Banerjee, R.; Choudhury, A.D.; Sinha, A.; Visvanathan, A. HeartSense: Smart phones to estimate blood pressure from photoplethysmography. In Proceedings of the 12th ACM Conference on Embedded Network Sensor Systems, Memphis, TN, USA, 3–6 November 2014.
This entry is offline, you can click here to edit this entry!