Artificial Intelligence (Al) models are being produced and used to solve a variety of current and future business and technical problems. Therefore, AI model engineering processes, platforms, and products are acquiring special significance across industry verticals. For achieving deeper automation, the number of data features being used while generating highly promising and productive AI models is numerous, and hence the resulting AI models are bulky. Such heavyweight models consume a lot of computation, storage, networking, and energy resources. On the other side, increasingly, AI models are being deployed in IoT devices to ensure real-time knowledge discovery and dissemination.
1. Introduction
The Internet of Things (IoT) has grown rapidly and generates a huge amount of data. Depending upon the domain and application, say, for example, smart traffic application, smart home, smart city, smart transport, etc., the acquired data are required to be processed immediately to produce meaningful insights and actionable decisions. In these cases, sending data to a centralized server and analyzing the data at the server involves greater latency [
1] which even prohibits the real purpose of the application itself. Cloud computing is not adequate to meet the diverse needs of data analysis of today’s intelligent society, and so edge computing has evolved [
2,
3]. Edge computing has brought the processing of data to the point of acquisition by pushing applications, storage, and processing power away from the centralized data center and to the edge itself [
4].
Centralized processing requires a massive amount of need to be transferred to the cloud for analysis. This not only requires more network bandwidth but also consumes time. Thus, it seriously suffers from latency, bandwidth-related issues, and huge transmission energy, which cannot be tolerated in applications involving augmented reality, video conferences, streaming applications, etc. However, in reality, every network has limited bandwidth. In addition, when data are transmitted to the cloud, it inherently prohibits the real-time analysis of data. However, many applications are in need of real-time analysis. For example, in the case of the healthcare domain, consider the case of a vital parameter-monitoring system that monitors parameters related to, say, COVID-19. Despite sending the monitored data to a centralized cloud server to which the physician or hospital is connected, which upon receiving the data, will analyze the health conditions of the patient, the monitoring system itself should be equipped with processing capability so that it can produce actionable and meaningful insights without latency. In addition, it itself will direct the required action and prevents the transfer of data to a centralized infrastructure. In scenarios where the analysis in edge becomes necessary, it should be conducted at the edge itself without centralized analytics.
2. Motivating Use Cases of Edge AI
Real-time analysis and decision making without latency—In contrast to cloud Al, edge AI can provide many benefits to the healthcare domain. For example, consider an individual is taking up his routine exercising. His vital parameters, namely pulse rate, blood glucose level, and blood pressure, are being monitored by wearable sensors and got updated in the edge application running on his mobile. Here, the mobile is the edge device, and it analyses the monitored parameters with the help of an artificial intelligence-based model, and it immediately takes the decision according to the analysis done, without sending the data to any other central server such as a cloud. The emphasis is that without any latency, the data are analyzed locally, and the decision is taken immediately. This is more important in the case of the healthcare domain, as the vital parameters are out of the normal threshold ranges. In such instances, immediately, the edge application intimates the physician and books the ambulance to a hospital.
Edge AI in Remote robotics surgery—In medical exigency, robotics surgery would be carried out under the supervision of a surgeon from remote. In this situation, the robots are fully equipped with AI-based models, and it performs the concerned surgery with guidance and conversation with a remote physician. The key point to be noted here is that the evolving 5G communication makes surgery easy and safe.
Edge AI integrated into cameras in airport security systems—When the video cameras installed in airports are integrated with video analytics applications, say, for example, detection of terrorist attacks, the attacks can be detected without latency. In conventional security applications, a series of video cameras capture the video of what is happening in the airport to cloud servers where AI-based models would run to detect or predict terrorist attacks. When the video analytics models run in the camera itself, based on the seriousness of the analysis, the device (i.e., video camera) makes a call to the police immediately to avoid the escape of any detected terrorist.
Edge AI in predictive maintenance—In manufacturing and in similar other sectors, predictive maintenance is used to determine potential faults and abnormalities in processes. Conventionally, heartbeat signals which exhibit the healthiness of various sensors and machines are continuously collected and sent to a centralized cloud setup where AI-based analytics would be carried out to predict the faults. However, nowadays, the loT devices themselves are equipped with AI models to predict the possibility of faults, and immediately with no latency proper maintenance process will be carried which ultimately leads to increased production with reduced cost.
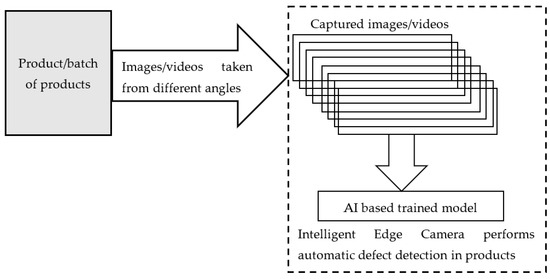
Edge AI in quality assurance—Existing cameras and devices are incorporated with intelligent state-of-art neural network-based video analytics models, which are capable of executing Trillions of Operations Per Second. These devices have higher computer vision and scan a single product or huge batches of products at a time and find out faulty products with accuracy exceeding human capability. In addition to product inspection, edge devices are also equipped with relevant models for continuous and detailed factory monitoring. In addition, the complete assembly line of factories is thoroughly inspected by the installed cameras towards production with zero defects as shown in Figure 1.
Figure 1. Block diagram of edge AI-based defect detection.
Edge AI and mobile augmented reality—Mobile augmented reality applications have to process huge amounts of data that arrive from various devices such as a camera, OPS, and other video and audio data within the stipulated latency of around 15 to 20 milliseconds in order to show the augmented reality to the user [
9]. The next generation IoT devices are equipped with reinforcement learning-based Al models implemented with the help of customized processors and 50 communication technologies. The combination of edge Al and the next-generation IoT enables practical implementation and brings in a more autonomous nature along with real-time analysis of the edge devices themselves. This combination will not only reduce the latency but also conserves energy.
Edge AI in drone applications—In contrast to traditional PID-based drone flights, which have limitations on the number of parameters and hence tend to break more often under situations that were not taken into the design, deep neural networks are trained with several example situations and simulated situations consisting of several disturbances, the AI-powered drone flight becomes easier. AT-powered drones are used for many applications such as (i) delivery of medicine to COVID-19 infected cases, (ii) delivery of food packets to affected people during natural disasters such as storms, (iii) tracking of vehicles, (iv) traffic monitoring, (v) air, noise, pollution monitoring, (vi) monitoring and exploring dangerous areas.
3. Learning-Related Strategies
3.1. Federated Learning
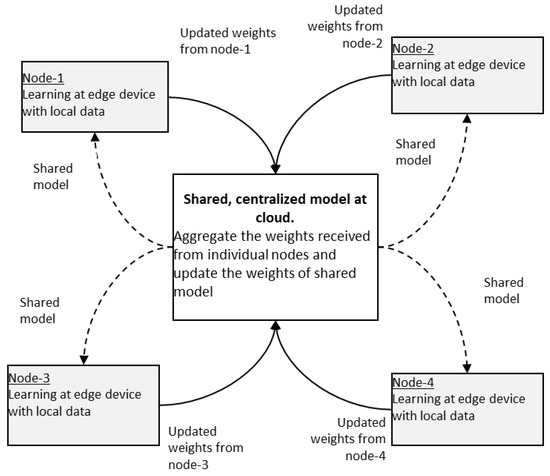
Federated learning is a distributed, and collaborative learning method that allows different edge devices with different datasets to work together to train a global model. In this learning, a single global model is stored in a centralized cloud infrastructure. At first, the global model is shared with devices with initial weights. Now the edge device collects the real-time data and trains the model locally with the new data for one or several iterations in order to update the weights so that the loss function is minimized [
19]. The updated weights are sent to a centralized server. Here the data are not sent to the centralized server. Only the weights are sent to the server with encryption [
4]. The centralized server receives the updated weights from several edge devices. It computes the average of updated weights, and then it updates the weights of the global model. Then the global model is again shared with edge devices. The concept of federated learning is shown in
Figure 7. Federated learning could cater to the needs of modern IoT-based applications and turns out to be the basis for next-generation artificial intelligence [
20].
Figure 7. Concept of federated learning in edge servers (shown with four nodes).
As discussed above, in centralized learning, the server sends a model, which initially gets trained in the server, to edge devices. In an edge device, the model gets training with local data, and the updated model parameters are sent to the server. In this way, the server aggregates all the parameters and resends the updated model to devices. In the case of decentralized, federated learning such as Peer-to-Peer [
22] or in a ring topology [
23], in addition to training the model with local data, each device performs the updating of parameter values with a Gossip algorithm [
24,
25]. As multiple devices are involved in training the model simultaneously, the training time is reduced [
26]. Moreover, in federated computing, privacy and security of data are maintained [
27]. Federated learning is more appropriate for utilizing low-costing machine learning models on devices and sensors [
28].
As far as the data in different clients are homogeneous in which the feature space of local data in participating clients is the same, updating the global model with updated weights of clients would be easy, and such data federated learning is called horizontal learning, and it leads to an effective global solution [
29]. However, updating the global models becomes a challenge when the data in devices are of the kind non-Independent and Identically Distributed (non-IID) which makes the convergence of the global model becomes difficult [
30]. This issue can be resolved by developing a personalized local model for each client [
31], and then the personalized local models can be merged into a shared global model with the help of the Bayesian fusion rule, as discussed in [
32,
33]. In another research work [
34], a branch-wise averaging-based aggregation method has been proposed, which guarantees convergence of the global model. In another work [
35], feature-oriented regulation method has been proposed to establish a firm structure information alignment across collaborative models.
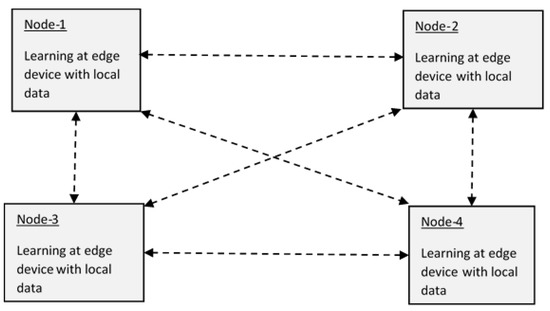
Federated learning is of two kinds, centralized [
21] and decentralized (
Figure 8).
Figure 8. Federated learning in a peer-to-peer model.
3.2. Deep Transfer Learning (DTL)
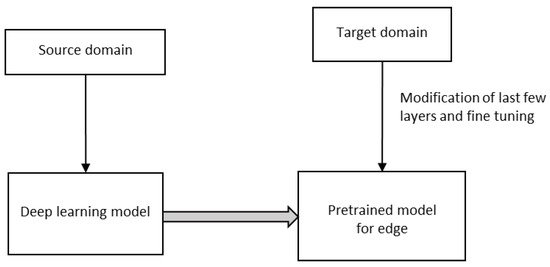
Edge devices such as IoT, webcam, robots, intelligent medical equipment, etc., are very useful for many healthcare applications during a pandemic, say, for example, COVID-19. Both shortages of reliable datasets, limited hardware, and power support of edge devices prohibit the usage of deep learning models in them. However, in Deep Transfer Learning (DTL), the knowledge of an already learned model is used to solve a new task, as in
Figure 9. DTL significantly reduces training time and the requirement of resources for a target domain-specific task for a fixed feature extraction or fine-tuning [
36,
37].
Figure 9. Deep transfer learning.
In contrast to conventional machine learning, where learning takes place in isolation, transfer learning uses knowledge learned from other existing domains while learning for a new task. Transfer learning is of two types, homogeneous and heterogeneous. In homogeneous transfer learning, the source and target domains are the same. It means that the feature space is the same, whereas, in heterogeneous transfer learning, the feature space is not the same. Different methods, namely, instance-based methods, feature-based methods, parameter-based methods, and relation-based methods, are being used for homogeneous transfer learning, whereas for heterogeneous domains, only feature-based methods are being used. There are two types of methods, namely asymmetric feature transformation and symmetric in heterogeneous transfer learning. In asymmetric transfer learning, one of the domains is transformed into the other, and this method is found to be effective when both domains share the same label space. In symmetric transfer leaning, both domains are transformed into a common feature space.
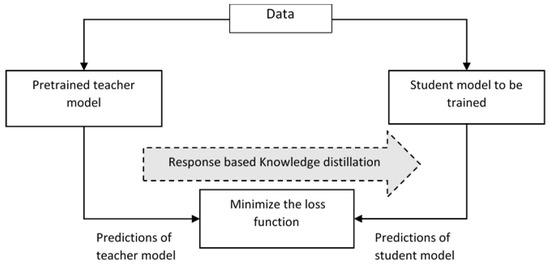
3.3. Knowledge Distillation
Large machine learning models have millions of parameters associated with them, which makes the deployment of the model in edge devices infeasible. So, the knowledge gained from large models is transferred to small models which run on edge devices. Here, the large models serve as the teacher model, and the small model is such as the student model. The teacher model refers to a larger model, and it alone gets pre-trained. The learned knowledge from the teacher model is transferred to the student model through knowledge distillation, as in
Figure 10. The knowledge distillation helps in improving the accuracy of the student model despite the constrained hardware [
38]. Different knowledge distillation techniques, namely response-based distillation, where the prediction performance of output layers of the teacher model and student model are compared using a loss function which shows the difference between the models and the loss function is minimized so that the accuracy of student model approaches that of the teacher model. In contrast to response-based distillation, in feature-based distillation teacher model distills the intermediate features of the student model. Here, the position of distillation is moved prior to the output layer [
39,
40]. Here the student mimics by minimizing the loss function that is computed according to the intermediate layers. Relation based distillation is one in which the difference between the relationship between different feature maps is captured as a gram matrix, and the corresponding loss function is minimized. The student model reduces the computation cost and memory usage [
41].
Figure 10. Knowledge distillation.
In addition, knowledge distillation is also used to tackle the problems, namely, heterogeneity in the local data of different devices and heterogeneity in the architecture of the models in edge devices. Federated learning can be implemented through knowledge distillation, as discussed in [
42,
43].
This entry is adapted from the peer-reviewed paper 10.3390/s23031279