Detection and localization of regions of images that attract immediate human visual
attention is currently an intensive area of research in computer vision. The capability of automatic
identification and segmentation of such salient image regions has immediate consequences for
applications in the field of computer vision, computer graphics, and multimedia. A large number
of salient object detection (SOD) methods have been devised to effectively mimic the capability of
the human visual system to detect the salient regions in images. These methods can be broadly
categorized into two categories based on their feature engineering mechanism: conventional or
deep learning-based. In this survey, most of the influential advances in image-based SOD from
both conventional as well as deep learning-based categories have been reviewed in detail. Relevant
saliency modeling trends with key issues, core techniques, and the scope for future research work
have been discussed in the context of difficulties often faced in salient object detection. Results
are presented for various challenging cases for some large-scale public datasets. Different metrics
considered for assessment of the performance of state-of-the-art salient object detection models are
also covered. Some future directions for SOD are presented towards end.
- salient object detection
- conventional salient object detection
- Deep learning-based salient object detection
Salient object detection (SOD) is an important computer vision task aimed at precise detection and segmentation of visually distinctive image regions from the perspective of the human visual system (HVS). (draft for definition)
Introduction
The behavior of SOD models is expected to mimic the pre-attentive stage of HVS which guides human attention to the highly interesting regions in the scene. The identified salient regions in images can facilitate subsequent high-level vision tasks for improved efficiency and optimal resource usage. As a preprocessing step, SOD has served many computer vision tasks such as, visual tracking [1,2], image captioning [3], image/video segmentation [4,5,6], and so forth.
The challenges and difficulties in SOD come from the very nature of the scenes captured in free viewing conditions. Several sample images from different SOD datasets can be seen in Figure 1. The accompanying pixel-wise annotations shown here are used for evaluation but clearly delineate the basic requirements for a salient object detector. A SOD method should keep the error metric values to their least by strictly attaining to the salient regions and missing the non-salient ones. It is further expected that the SOD method should be computationally inexpensive in producing a high resolution saliency map for accurate salient object localization [7]. Being an active research field over the past two decades, a large number of models have been attempted to satisfy the minimum requirements for image based SOD. Early efforts for saliency detection were focused at fixation prediction [8,9]. Fixation prediction aims to attend the spatial locations where an observer may fixate within few seconds of free-viewing. SOD is different from fixation prediction as models for the former should detect and segment the entire extent of salient regions/objects in the scene. A general approach adopted by conventional SOD models to accomplish this goal is to assign high probability values to salient elements in a scene while producing a saliency map. Once detected, techniques such as thresholding can be used to segment out the whole salient object. Conventional SOD models following Itti et al. [8] attempt to capture the notion of scene rarity or uniqueness mainly by devising center-surround contrast features. Regional contrast in terms of global and local schemes have been frequently used in conventional SOD. Various complementary heuristic saliency priors have also been deployed to effectively capture the most conspicuous object regions in images. These conventional models have been proven to be efficient and effective in relatively simple scenes with a single object and/or clean background.

Figure 1. Sample challenging images for salient object detection with corresponding pixel-wise annotations shown below. (a) Large object, (b) Reflection, (c) Multiple objects, (d) Small object, (e) Complex scene, and (f) Low contrast.
Many diverse datasets have surfaced in the past ten years to challenge these SOD models. The presence of multiple salient objects, heterogeneous salient objects with variations in shape, size and position, low-contrast objects, and much cluttered background in datasets are challenging issues to address while adhering to high prediction requirements of SOD. However, the recent rapid development of deep learning-based techniques in the field has been highly successful in tackling most of the aforementioned issues. Fully convolution neural networks (FCN) lies at the core of deep learning-based SOD [10]. The powerful hierarchical multi-scale feature representation of FCN has been utilized in various ways for a coarse saliency prediction and its refinement for boundary accurate saliency map in a data-driven manner. However, the conventional models for SOD have the advantage of providing real-time performance and can be applied in the wild. Meanwhile, several deep models have leveraged saliency priors to improve the representational ability of multi-layer features and to speed-up the training process. Wang et al. [11] combined saliency estimate of multiple conventional methods as the prior knowledge informative of salient regions to guide saliency detection. Chen et al. [12] utilize saliency priors as an initial prediction for saliency refinement. Zhang et. al. [13] devised a deep unsupervised saliency detection with noisy supervision from multiple conventional SODs. Simple heuristic operator such as contrast in Reference [14] has been adopted for contrast modelling of multi-scale features in References [15,16]. These adaptations suggest that despite tremendous progress and superior performance demonstrated by deep learning based SOD, the tools of conventional saliency detection can be useful for further raising the performance bar of deep models.
Overview of Salient Object Detection
Saliency detection has been an interdisciplinary field. The fundamental investigations on cognitive and psychological theories of HVS attention [51,52,53] were contributed by cognitive psychologists and neuroscientists. Such theories preliminarily formed the base for development of the early saliency models. A major milestone in visual saliency was achieved when the complete implementation of the computational attention architecture [53] was realized by Itti et al. [8]. The feed-forward model proposed in Reference [8] computes and combines multi-scale color contrast, intensity contrast, and orientation contrast to direct computational mechanism to highlight the salient locations in a low-resolution saliency map. Further, a winner-take-all (WTA) neural network is invoked multiple times to shift the focus of attention to the next most conspicuous location by employing inhibition of return mechanism after the first WTA invocation. This ability to shift from location to location in a fixation map is vital for tasks such as image understanding. Nevertheless, the computation of center-surround contrast using low-level features and their integration for attention guidance provided great insight for further research in the conventional SOD paradigm.
It is widely accepted that the seminal work of Liu et al. [54] and frequency tuned approach proposed in Reference [14] brought novel contributions to boost up research in SOD. Liu et al. [54] introduced the computational methods for extracting local, regional, and global features that capture different aspects of saliency information. A binary segmentation is achieved using conditional random fields (CRFs) with all extracted features. In addition to that, the first large-scale dataset was also presented in Reference [54] with bounding box annotations for training and evaluation of SOD models. Contributions by Reference [14] include in-depth frequency analysis of sub-sampled features used for contrast computation and generation of full-resolution saliency maps using a frequency-tuned approach.
Deep convolutional neural networks (CNNs) have demonstrated exceptional performance in many vision tasks such as image classification [55,56], semantic segmentation [57,58,59], object detection [60,61], and object tracking [62,63]. Deep CNNs have also benefited SOD and delivered a huge performance gain compared to the conventional SOD models. This data-driven approach generates a hierarchy of multi-scale feature representation automatically from the input image. The stacking of convolution and pooling operation in deep CNNs allows the receptive field of the network to grow gradually with depth. Due to the large receptive field, deep layers in the network could capture the global semantics and provide a holistic estimation of the salient regions. The shallow layers retain more spatial details useful for the localization of fine structures and salient object boundaries. Different deep learning-based SOD models utilize these complementary multi-layer features in various ways to learn robust saliency representations with a powerful end-to-end learning [57]. Figure 2 shows a sudden rise in the number of papers published in SOD from images since 2015 when the first few deep learning-based SOD models were proposed.
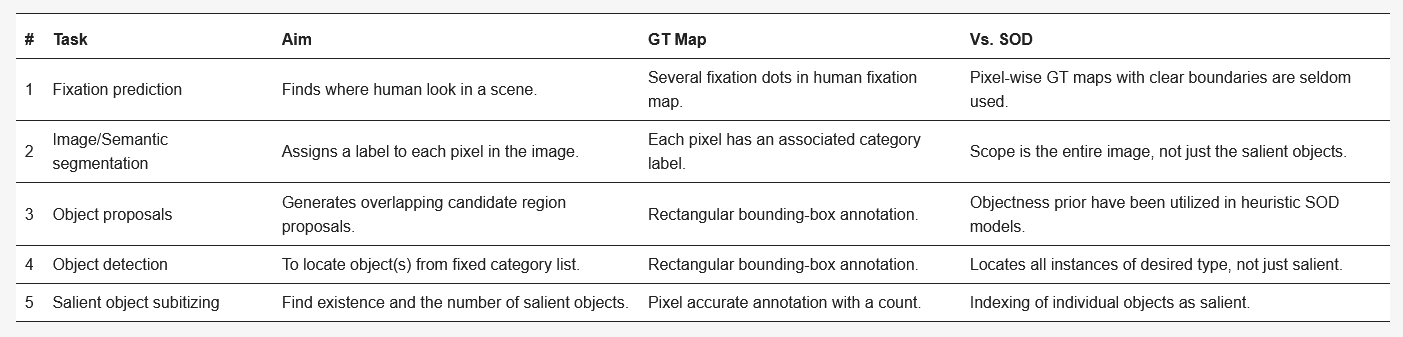
Recently, the most advanced models in SOD have been devised from the field of computer vision. Table 2 compares SOD with some related computer vision tasks such as fixation prediction [64,65], image segmentation [66,67], semantic segmentation [57,58,59], object proposals generation [68], object detection [60,61], and salient object subitizing [69]. Table 2 highlights various research tasks in the similar fields compare with SOD in terms of objective and approach taken. Although this survey focuses mainly on single RGB image based SOD models, closely related fields such as co-saliency detection(CoSOD), RGB-Depth (RGB-D) SOD, video SOD, and SOD on light field have also experienced a great deal of interest in the recent past. The CoSOD task aims at the automatic detection of the salient object(s) that are common among multiple related images. Given an image group, a co-salient object should be salient in each image along with a high chance of repeatability and appearance similarity among the related images [48]. Classical approaches to CoSOD resort to inter-image correspondence modelling strategies [70,71] to represent the common attributes among multiple images. Recent deep learning-based CoSOD models [72] learn co-salient object representations jointly, and have utilized deep-CNN models to achieve outstanding performance. Typical applications of CoSOD include collection-aware crops [73], co-segmentation [74] and video foreground detection [75]. The RGB-D based SOD models utilize important complementary information of depth along with color measurements for detecting salient objects on RGB-D images. Similar to SOD, traditional RGB-D models [76,77] rely heavily on hand-crafted features while combining RGB image with depth maps. Models [78,79] that exploit the implicit shape and contour information in depth maps to refine saliency results have shown promising performance. Deep learning-based, end-to-end RGB-D models [80,81] are becoming more and more popular as they can effectively exploit multi-modal correlations, and multi-layer information hierarchy for robust RGB-D saliency detection [82]. Video SOD models leverage the sequential, motion, and color appearance information contained in a video sequence to detect targets that are repeated, dynamic, and salient [48]. Video SOD has many applications viz., action recognition [83] and compression [84]. Very similar to other related fields, current state-of-the-art models in video SOD are deep learning-based which capture and focus on combining the spatial and temporal saliency information efficiently [74]. Efforts have also been made to deal with data insufficiency problem in the supervised video-SOD models through novel data augmentation techniques [74] or introducing new datasets [85]. The detection of saliency on 4-D light field (LF) is another interesting task related to the RGB-SOD task. A light field is an array of 2-D images which includes focal stacks, depth maps and all-focus images captured through handheld light field camera Lytro Illum [86]. In absence of a large-scale LF-SOD dataset, low-level cues have been utilized to tackle the task. Recently, Reference [87] proposed a new dataset and deep learning based model for the LF-SOD task. Interested readers may refer to References [48,82,85,87,88] for further information on these related tasks.
Table 2. Comparison of salient object detection with other computer vision tasks (GT - Ground truth).
This entry is adapted from the peer-reviewed paper 10.3390/e22101174