Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Engineering, Electrical & Electronic
随着分布式光伏系统(DPVS)的快速发展,数据监测设备的短缺和测量设备全面覆盖的难度变得更加突出,给DPVS的高效管理和维护带来了巨大的挑战。虚拟采集是一种新型的DPVS数据采集方案,具有成本效益和计算效率,满足分布式能源管理的需求,但缺乏关注和研究。为了填补当前研究领域的空白,本文对DPVS虚拟馆藏进行了全面系统的综述。
- distributed photovoltaic
- virtual collection
- similarity analysis
- artificial intelligence
1. 简介
在当前全球能源危机和环境污染日益严重的背景下,光伏(PV)发电因其高效率和清洁性而得到了世界各国的大力支持,迅速成为仅次于水电和风力发电的第三大可再生能源[1]。根据国际能源署(IEA)的报告,2021年全球新增光伏装机容量超过175吉瓦,占新增可再生能源装机容量的一半以上。截至2021年底,全球累计光伏装机容量已超过942吉瓦。图1说明了全球光伏市场的变化动态以及中国光伏市场的重大影响[1]。
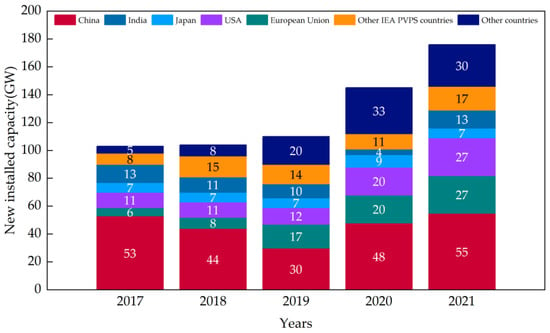
图1.2017-2021 年每个地区的增长。
光伏电站主要分为集中式系统和分布式系统两种。分布式光伏系统由于其安装灵活,环境效益突出以及发电和消费共存而迅速发展[2]。如图2所示,2021年分布式光伏新增装机容量超过集中式光伏[3]。因此,高效准确地访问DPVS操作数据变得越来越重要。高质量的运行数据可以帮助评估DPVS的输出性能指标,以提高光伏电站在运行和维护方面的可靠性以及DPVS输出预测的准确性。还可以为电力公司提供准确的电表计费审计指标,更好地监控市场,延长DPVS的使用寿命。然而,大多数DPVS是分散和无序的,点多,区域广。为了有效地管理它们,需要部署大量的传感器、收集器和集中器来监控DPVS的输出,以及专用的通信通道、服务器、数据库和数据监控软件[4]。然而,较高的实施成本和个人隐私要求使得很大一部分光伏用户不愿意购买这些数据监控服务,限制了光伏产业的进一步发展。此外,随着分布式光伏规模的不断扩大和运行环境变得更加复杂和多样化,其运行数据的收集往往遭受传输堵塞和设备故障的困扰。因此,为部署在战略位置的传感设备数量相对较少的大规模DPVS集群开发一种具有成本效益和计算效率的数据收集方法至关重要且有益。如果部署在具有适当冗余的战略位置,减少的传感网络仍然可以为各种电力操作提供低成本但足够准确的DPVS网络测量。
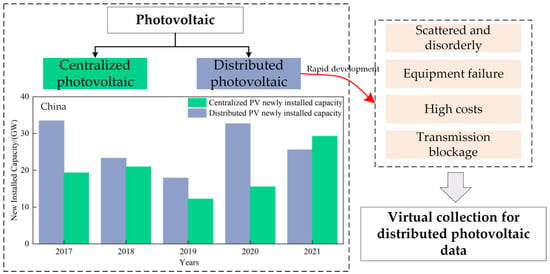
图2.虚拟采集技术的研究动机。
意识到这一需求,相关学者受到虚拟馆藏概念的启发[4],并研究了DPVS的虚拟馆藏。DPVS虚拟采集的核心思想是利用区域内选定参考电站(RPS)的电力数据作为输入,通过计算智能算法推断其他电站的电力数据。为了减少传感器的数量,参考文献[5]通过深度循环降噪自动编码器拟合选定区域内的所有DPVS台站运行数据,并引入仿生人工神经网络来动态选择候选RPS集中的最佳参考站子集。可以看出,结合人工智能算法进行DPVS数据虚拟采集的研究相对较少,这种方法仍处于早期探索阶段。而且,目前在虚拟馆藏研究中没有对知识进行全面介绍,导致业界对DPVS的虚拟馆藏缺乏重视。适合虚拟收藏的各种方法和虚拟收藏的应用场景尚未总结。
2. DPVS 虚拟馆藏概述
虚拟采集中的“虚拟”一词表示该技术不通过现场的传感器、集热器和聚光器等采集设备收集光伏数据。虚拟采集是一种新型的推理技术,用于无法实时采集或难以采集的数据。其本质是由多个子系统组成的大型系统的系统识别和状态估计[5]。
如图3所示,本文根据DPVS虚拟采集的实现条件,将虚拟采集过程分为三个步骤:
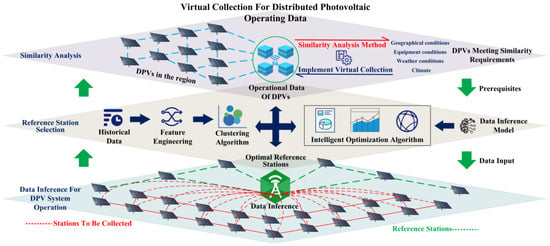
图3.DPVS 虚拟采集过程示意图。
-
DPVS在虚拟采集区域的相似性分析。
-
选择用于虚拟采集的参考电站 (RPS)。
-
DPVS的数据推断,即通过计算智能准确估计该地区所有电站的输出。
首先,所有电站的数据都需要通过5G、ZigBee等无线通信方式传输到公司的光伏智能运维云平台。然后,通过相似性分析方法分析各电站在地理、设备、气候等方面的相似性,得到满足虚拟采集前提的电站集。此外,通过聚类或智能优化算法选择整个光伏系统中最好的RPS来部署传感设备,从而准确估计整个光伏系统的运行数据。
3. DPVS虚拟采集的过程与挑战
3.1. 区域DPVS的相似性分析
光伏数据与外部条件以及安装地点的地理位置等因素密切相关。环境因素对虚拟馆藏模型的准确性有重大影响。因此,实现虚拟采集的前提之一是要采集的站点和RPS具有相似的外部因素。从数据的角度来看,我们希望数据集尽可能遵循相似的分布模式,从而为监督学习提供更高质量的输入数据。这种相似性可以使虚拟馆藏更加健壮,并确保虚拟馆藏数据即使在天气变化的情况下也能准确无误。
举例来说,中国湖北省西南部的巴东县和江苏省南京市的江宁区,由于地形、地形、气象和其他条件的不同,产生的电力数据差异很大。图4显示了典型夏日巴东县和江宁区光伏电站的功率输出。对于江宁区的DPVS来说,使用巴东区的DPVS运行数据进行数据推断,由于两者之间的相似度极低,会严重降低虚拟采集的准确性。因此,有必要通过相似性分析提前定义满足相似性要求的光伏电站集群。
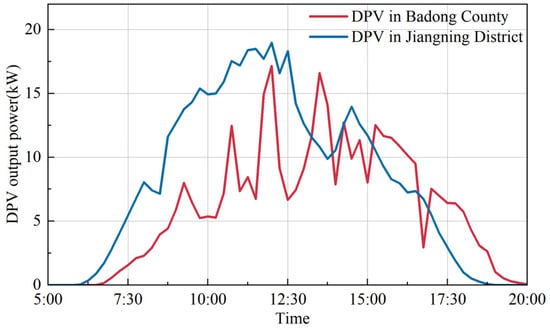
Figure 4. Badong county and Jiangning district DPVS output on a typical day.
Many factors affecting the PV output state are coupled with each other [6]. The main factors influencing the solar energy conversion process are shown in Figure 5. It can be seen that the degree of solar irradiance received by the PV module is significantly influenced by the geographical location and meteorological conditions. The climate is the comprehensive pattern in the general state of the atmosphere and weather processes in a certain area on a long timescale, which is an important factor affecting the level of light resources, and meteorology refers to the physical phenomena of the atmosphere on a short time scale, such as temperature, clouds, etc. Secondly, the link of solar irradiance to power for conversion is closely related to the selection of equipment, the design of the station, and electrical efficiency. After the series of the energy conversion process mentioned above, the final PV power output is obtained. Therefore, similarity analysis can be performed from two perspectives: influencing factors (causes) and power output trends (results). However, from the perspective of influencing factors, it is difficult to analyze the similarity due to the large number of factors affecting PV output, the significant difference between the dimensions, and the complex types of characteristics. From the perspective of the PV output trend, the trend changes are complicated, and the time scale is long, which makes it challenging to analyze the trend characteristics.
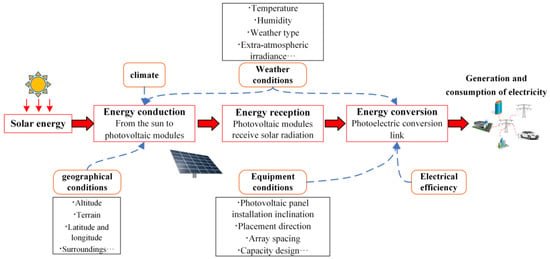
图5.影响DPVS功率输出的因素。
数据相似性的重要性也反映在许多研究领域。在参考文献[7]中,提出了一种基于BP神经网络曲线相似性分析的异常识别和重建模型,用于检测异常并补偿缺失的PV历史数据。与虚拟采集类似,该方法也需要相邻光伏电站的电源。考虑到光伏发电的周期性,参考文献[8]提出了一种基于近似周期时间序列的数据清洗方法,有效地提高了光伏数据的质量。考虑到由于天气条件的变化而导致光伏发电的不确定性,参考文献[9]提出了一个结合类似日期选择技术的预测框架。在此框架中,作者首先筛选出能够准确捕捉不同日期相似度的外部变量,并根据这些外部变量选择相似度较高的日期进行历史日期和待预测日期,从而提高预测精度。
3.2. 虚拟集合的 RPS 选择
选择 RPS 是虚拟收集过程中最关键的一步。RPS的实时功率数据将作为多维特征输入计算智能算法,以估计所有区域DPV的输出。我们的目标是在区域DPVS中选择DPVS的子集,这些DPVS可以更准确地估计其他台站的数据。此步骤的关键是确定收集最重要数据的选择性传感器位置,以监控所有DPV的状态。因此,我们将从输入数据和设备放置的角度分析RPS选择步骤与其他方法之间的差异和关联。
如图6所示,从输入数据的角度来看,RPS的选择可以近似为机器学习的特征选择问题。两者都旨在通过选择 RPS(特征)尽可能提高结果的准确性。因此,虽然关于参考电站选择的研究很少,但相对成熟的特征选择理论也可以为我们提供启示。对于数据挖掘技术,输入数据的特征质量严重影响模型的性能,因此许多学者都研究了特征选择问题。参考文献[10]从单个稀疏特征选择和组稀疏特征选择的角度系统地研究了现有的稀疏学习模型的特征选择。它分析了各种稀疏学习模型之间的差异和联系。参考文献[11]提出了一种新的增量特征选择,使该方法对动态排序的数据具有鲁棒性。参考文献[12]提出了一种蚱蜢优化算法,该算法可以通过从大量原始特征中选择可以更好地表征数据属性的特征子集来解决二元优化问题,从而提高分类精度。上述研究对特征选择问题提出了有效的处理方法,可为选择RPS提供一定的理论参考,例如将RPS选择转化为组合优化问题。但值得注意的是,如果选择某电站作为RPS,则将其用作输入要素,其余电站则用作要采集的电站。可以看出,虚拟集合的RPS选择问题类似于高维特征选择问题[13],但与传统回归和分类[14]问题中的特征选择不同。因此,选择合理的RPS比选择功能更具挑战性。
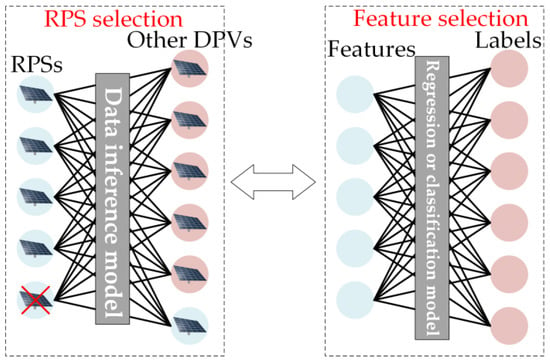
图6.RPS 选择和功能选择过程。
从传感器放置的角度来看,RPS的选择也可以受到智能电表中数据聚合点(DAP)选择问题的启发。如图7所示,DAP选择和RPS选择都可以看作是系统中传输节点的优化配置。选择DAP是为了降低数据冗余和带宽需求,将数据本地聚合在传感器或中间节点,形成高质量的信息,降低发送到基站的数据包质量,从而节省能源和带宽。参考文献 [15] 将 DAP 放置视为混合整数规划问题,并提出了一种新的启发式算法,以最小化安装、传输和延迟成本,以选择最佳 DAP 放置位置。参考文献[16]提出了一种改进的k均值聚类算法来分配DAP,从而大大减少了安装的DAP数量。
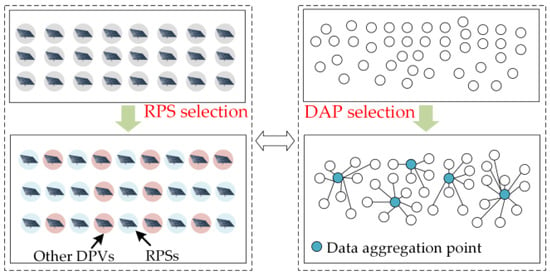
图7.RPS 选择和 DAP 选择过程。
尽管DAP和RPS的选择存在一定的共性,但仍有许多挑战需要研究。获取数据聚合点的目的是确定所有SM布局点中传输和延迟成本最低的,以实现整个系统数据的聚合和传输。通过在区域光伏系统中选择一个光伏子集来选择RPS,以实现整个系统的数据估计。因此,在选择RPS时考虑的要素更加多样化。除了通信和设备成本外,还需要考虑不同RPS集对整个系统的数据估计精度,以及当前研究所缺乏的时空耦合特性。
3.3. 区域 DPVS 的数据推断
虚拟采集技术的最后一步是通过人工智能算法推断整个DPVS的运行数据。此步骤通过在RPS和要在区域中收集的电站之间构建计算智能模型,使用第二步中选择的RPS数据作为输入,映射RPS与整个系统之间的关系。此步骤类似于PV预测技术中使用的方法,两者都需要一定的历史数据作为驱动因素来获得未知的PV输出功率。
业界对DPVS虚拟数据推断的研究相对较少,大多数研究仅关注光伏发电量预测,利用历史数据、实时天气等环境信息来预测光伏发电量。值得庆幸的是,目前的DPVS功率预测算法相对成熟,可以为虚拟DPVS数据采集提供一些理论参考。但值得注意的是,虚拟采集中的数据推断在模型构建和使用上与传统的PV预测存在差异。虚拟数据收集通过数据推理模型实时估计当前的光伏功率输出,而光伏预测器估计未来的功率输出。虚拟采集模型的输入是来自 RPS 的实时 PV 数据,PV 预测器的输入是历史运行数据和环境信息。这种实时性使得虚拟采集的数据推理模型必须比PV预测模型具有更好的鲁棒性和更高的精度要求。
4. DPVS虚拟采集方法
上一节介绍了虚拟采集的具体实施步骤及其目的,并指出了为上述步骤面临的挑战提供解决方案的迫切需要。因此,本节通过总结适用于DPVS相似性分析、RPS选择和DPVS数据推理的方法,为虚拟采集技术的发展提供理论支持。图 8 总结了 DPVS 虚拟采集的各种方法。
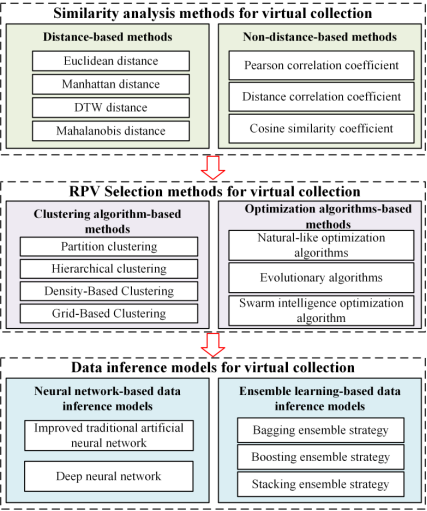
图8.虚拟收集方法摘要。
5. 虚拟采集技术的应用场景
随着DPVS的规模扩大,DPVS的应用场景越来越复杂多变。运维信息的获取往往存在数据采集不完整、传输堵塞、采集传输成本高等问题。因此,为引起更多学者对虚拟馆藏实际应用价值的关注,本文创新性地总结了基于多源信息的虚拟馆藏的多种应用场景,包括但不限于以下内容:
- DPVS操作数据异常检测。
- DPVS 故障诊断。
- DPV缺少数据恢复。
- DPVS实时操作数据收集。
图9总结了四种应用场景以及DPVS虚拟采集技术的意义。
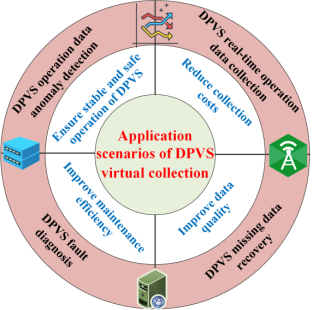
图9.DPVS虚拟采集技术的应用场景。
This entry is adapted from the peer-reviewed paper 10.3390/en15238783
This entry is offline, you can click here to edit this entry!