This article presents a comprehensive survey on the diagnosis of colon cancer. This covers many aspects related to colon cancer, such as its symptoms and grades as well as the available imaging modalities (particularly, histopathology images used for analysis) in addition to common diagnosis systems. Furthermore, the most widely used datasets and performance evaluation metrics are discussed. We provide a comprehensive review of the current studies on colon cancer, classified into deep-learning (DL) and machine-learning (ML) techniques, and we identify their main strengths and limitations. These techniques provide extensive support for identifying the early stages of cancer that lead to early treatment of the disease and produce a lower mortality rate compared with the rate produced after symptoms develop. In addition, these methods can help to prevent colorectal cancer from progressing through the removal of pre-malignant polyps, which can be achieved using screening tests to make the disease easier to diagnose. Finally, the existing challenges and future research directions that open the way for future work in this field are presented.
1. Introduction
Colon cancer is a specific kind of tumor that originates in the colon or the rectum, existing in the digestive system at the lower portion of [
1]. The colon forms the main part of the large intestine, and the rectum exists at the end of the colon [
2]. Colon cancer is considered to be one of the leading causes of death in the industrialized and Western world, and its incidence grown [
3]. In 2012, about 1.4 million people were diagnosed with this disease. In 2017, there were almost 50,260 deaths reported [
4]. The main reasons for incidence stem from unhealthy habits, including chain-smoking and eating high amounts of red meat and little fruit in addition to a family history of disease and increasing age [
5].
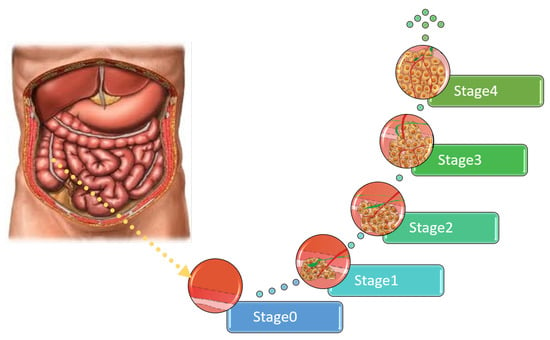
There are four main grades of colon cancer as shown in
Figure 1 [
6]. The first stage is defined as the mucosa or lining of the colon or rectum, while the organ wall has not yet developed tumors. In the second stage, the walls of the rectum or colon begin to develop tumors; however, nearby tissues or lymph nodes are not yet affected [
7].
Figure 1. The different stages of colon cancer.
The third stage is reached when the tumor has spread only to the lymph tissues but has not yet spread to any other body part. In the fourth stage, the tumor spreads to other organs, such as the lungs [
8]. The prevalence in stage four has different symptoms, depending on the organ to which the tumor has spread as shown in
Table 1 [
9].
Table 1. Comparison between symptoms of tumor spread across various organs at the fourth stage.
| No. |
Spread to Various Organs |
Symptoms |
| 1 |
Liver |
-
Pain on the right side of the abdomen.
-
Constant feeling of illness and fatigue.
-
Loss of weight and appetite.
-
Abdominal bulge due to fluid assembly.
-
Itching disorders of the skin.
|
| 2 |
Lung |
|
| 3 |
Bone |
|
| 4 |
Lymph nodes |
|
Although colorectal cancer does not have apparent symptoms, particularly in its early stages [
10], there are unusual symptoms, such as abdominal pain, constipation, excess gas, diarrhea, and changes in the color and shape of stool (e.g., narrow stool, abdominal cramps, and blood in the stool) [
11]. According to ACS, the most common reason for colon cancer stems from adenocarcinoma disorders, accounting for almost 96% of all stages of this type of cancer [
12].
Colorectal cancers can also arise from other tissues that have tumors, such as carcinomas that first arise in the hormone-producing polyps of the intestines [
13] and lymphomas that may first form in the colon; however, this is less common. These sarcomas start in small tissues, such as gastrointestinal stromal tumors that start as normal tumors and later become cancerous (these at a few times begin in the colon but almost start in the digestive tract) [
14].
Not all types of tumors are malignant. There is a non-spreadable or benign type that is not fatal or destructive as the spreadable type is. The difference of biological tumor structures presents great challenges for automatic and manual analysis of histopathological images (HIs) [
15]. A manual examination of the cancer level/grade relies on the pathologist’s visual assessment, which is subjective, time-consuming, and potentially error-prone [
16]. An incorrect or late diagnosis can cause anxiety for many patients. Therefore, Medical Image Analysis (MIA) is required to process and analyze HIs automatically. Such an MIA system can be used to classify colon cancer and present an objective, and accurate assessment of various grades of this cancer [
17].
A diagnosis of colon cancer can be implemented automatically with the power of AI, leading to more types of diagnosis with less cost and in less time. AI-based diagnosis methods can be categorized into ML techniques and DL techniques. Recent advances in digital image processing (DIP) techniques and DL play an essential role in the diagnostic process [
18]. In this paper, researchers show a comprehensive survey on different ML and DL techniques proposed for identifying the different stages of colon cancer. This can be accomplished using different imaging modalities. However, researchers focus on histopathological imaging, which is considered the best modality used to examine, classify, locate and provide a comprehensive view of the different cancer stages.
2. Colon Cancer Diagnosis
Before going in depth and reviewing the current work on colon cancer diagnosis, many aspects related to the diagnosis process should be taken into consideration, such as the image modality used, type of diagnosis system, the dataset used, and the metrics used for evaluation. Therefore, in the following subsections, researchers discuss these aspects.
2.1. Imaging Modalities
As mentioned before, our main goal is the automatic diagnosis of colon cancer with high detection accuracy and without manual intervention. In this section, researchers take an in-depth look at the different imaging modalities recently applied for MIA, including Computed Tomography (CT), Endorectal Ultrasound (ERUS), virtual Computed Tomography Colonoscopy (CTC), and Magnetic Resonance Imaging (MRI) [
22] in addition to other modalities, such as Histopathological Imaging (HI) and Positron Emission Tomography (PET) [
23].
2.2. Common Diagnosis Systems Based on HI Analysis
In this paper, our main focus is on colon cancer diagnosis based on HI analysis. In general, most of the stages of HI analysis depend mainly on the basic concepts of mathematics.
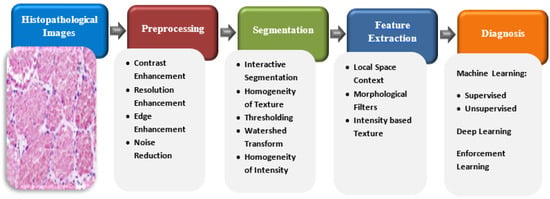
Figure 7 presents the main stages of a typical HI Analysis pipeline [
44].
Figure 7. HI analysis pipeline.
In the first stage, 2D/3D arrays of HIs are obtained and passed to a gray-scale or color imaging system. They are then fed to the preprocessing phase, where some operations in linear algebra are applied to array of the image for better image resolution to be able to distinguish structures from others. Then, the segmentation phase separates the background of the objects from the cells by applying mathematical algorithms, such as texture homogeneity, intensity, watershed transformation, and level set transformations.
The next stage is the extraction of features process. Instead of processing each pixel, this stage explores the most significant features from the sliced images for further processing. Therefore, it minimizes the computational complexity of the system. Finally, the diagnostic stage applies clustering or classification algorithms on the features extracted from the input images [
45]. To achieve an intensive analysis of HIs, mathematical functions and operations must be applied to all analysis phases, beginning with the prepossession phase and ending with the diagnostic phase [
46].
2.3. Datasets
Dramatically increasing the dataset size needed for testing training is a critical challenge [
54,
55]. There are public datasets in the electronic pathology course, including manual observations for HIs. These are helpful in the review process. Image artifacts (e.g., the zoom level and image resolution) and slide problems (e.g., smudges) have similarity ratios. However, all of these datasets are expected only in specific states of tumors, and there are several tasks that the existing databases do not handle.
-
CRC Grading Dataset
The CRC [
56] Grading Dataset contains 38 H&E stained histological WSIs with a resolution 4548 × 7548.
-
PanNuke Dataset
PanNuke [
57] includes 200,000 nuclei divided into five main classes to challenge the approaches of classifying and segmenting nuclei in WSIs with a resolution of 224 × 224.
-
The Warwick-QU Dataset
In this dataset [
58] are 16 slides of H&E stained histological WSIs of colon histology; this dataset is being created as category of the GlaS challenge with resolutions of 430 × 575 (14 images) and 520 × 775 (151 images).
-
CoNSeP Dataset
CoNSeP [
59] contains 41 H&E stained image slides with a resolution of 1000 × 1000 pixels at 40× magnification of objective: generally 24,319 annotated nuclei with labeled classes.
-
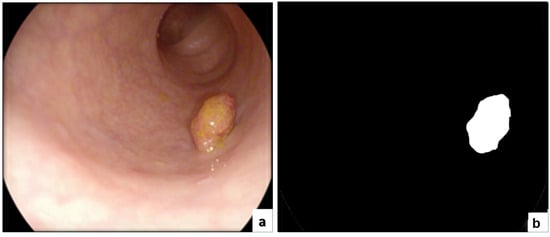
ETIS-LARIB
The ETIS-LARIB [
60] database contains frames taken from colonoscopy videos, including several examples of polyps. It produces the baseline reality for each frame while displaying a mask due to the polyp region in the image. A sample of this dataset is shown in
Figure 8.
-
CRCHistoPhenotypes–Labeled Cell Nuclei Dataset
This dataset [
61] has 100 H&E CRC. For the process of detection, there are 29,756 nuclei; for classification, 22,444 nuclei (miscellaneous, fibroblast, and epithelial); and 7312 unlabeled with a resolution of 500 × 500.
-
Kent Integrated Dataset (KID)
The KID [
62] is responsible for the health and welfare system for the entire population of Medway and Kent. This dataset is rich and unique for researchers seeking health and care on a large scale. This also provides an overview of the patient journey, care, and needs.
-
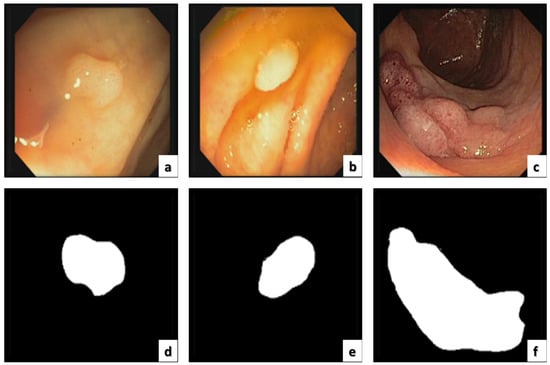
CVC-ColonDB and CVC-ClinicDB
Since 2012 [
60], this dataset has been the top research leader as it includes many databases that are public and available, and CVC-ColonDB is included, which specializes in colon cancer imaging containing the original images and the ground truth as shown in
Figure 9.
-
Colonoscopy Dataset
The dataset [
63] contains 76 videos, containing both WL and NBI. The database contains 40 adenomas with SD resolution of 768 × 576, 21 hyperplastic lesions, and 15 serrated adenomas.
-
Extended CRC Grading Dataset (KID) In this dataset [
64] are 300 images that are non-overlapping. These were labeled by expert pathologists as high grade (Grade 3) tumors, low grade (Grade 2) tumors, or normal tissue (Grade 1) with a resolution of 4548 × 7548.
-
ASU-Mayo Clinic
Currently, there are numerous research programs based on co-funded acceleration, seed research, and team science grants [
65]. This means that more than 20–30 cohorts of senior nursing students in their clinical training by Mayo Clinic nursing faculty on the Mayo campus are expected to be completed. Due to this effort and cooperation, the seed grant program has added joint, cutting-edge research collaborations, a host of dual degree opportunities, and others. In 2016 and in the summer of 2010, the relationships of the Mayo Clinic became enterprise-wide, and the ASU Alliance for Health Care was formed.
Figure 8. Original data and associated manual annotation from ETIS-Larib polyp DB. (a) the original image and (b) the annotation.
Figure 9. (a–c) The original images. (d–f) The corresponding ground truth.
3.4. Performance Evaluation Metrics
Metrics of evaluation are utilized to measure the quality of models of machine learning. One can evaluate whether the DL algorithm of training is effective on new data by using these metrics of evaluation. Many different evaluation metrics can be used for testing a model. More accurate results can be found using multiple metrics for evaluating the quality of a trained model because each model performing using a metric of evaluation differs from the same model using another evaluation metric.
The factors of correctly used evaluation metrics are critical as these describe whether the trained model is performing well or not. In the following section, researchers show some formulas and an explanation of the evaluation metrics utilized by academic papers.
True Positive (TP) is when a method classifies the correct category correctly, while False Positive (FP) is when a method classifies the correct category incorrectly. On the other hand, True Negative (TN) is when a method classifies the negative category correctly, while False Negative (FN) is when a method classifies the negative category incorrectly. researchers can customize these values in the medical field of cancer detection. An example is that, if the image includes cancerous cells, then the trained model predicts the malignant cells successfully, and thus this case is called TP, while if the trained model predicts that it is not a malignant cell, then this case is called FP.
On the other hand, if the image includes no malignant cells, and the model predicts that the image does not contain cancerous cells, then this case is called TN. If the image includes no malignant cells, and the trained model predicts it as a malignant cell, then this case is called FN. In the next section, researchers present an explanation and description for formulas that are related to the common evaluation metrics.
-
The Precision measures the true classified positive estimates of the total classified estimates in a correct category, which can be calculated as:
-
The Recall is employed for measuring the ratio of correct estimates that are correctly predicted. This can be calculated as:
-
The Specificity is presented for measuring the positive observations rate of false samples and can be calculated as:
-
The Sensitivity measures the number of correct samples that are classified as true and can be calculated as:
-
The ROC curve presents the ratio of false positives to the ratio of TPs by showing the performances of the possible threshold values used and can be calculated as:
This entry is adapted from the peer-reviewed paper 10.3390/s22239250