Coordinates: 37°46′56″N 122°28′18″W / 37.782321°N 122.47161137°W / 37.782321; -122.47161137 The Internet Archive is an American digital library with the stated mission of "universal access to all knowledge".[notes 2][notes 3] It provides free public access to collections of digitized materials, including websites, software applications/games, music, movies/videos, moving images, and millions of books. In addition to its archiving function, the Archive is an activist organization, advocating a free and open Internet. As of April 2021, the Internet Archive holds over 30 million books and texts, 8.9 million movies, videos and TV shows, 649,000 software programs, 13,225,000 audio files, 3.8 million images, and 580 billion web pages in the Wayback Machine. The Internet Archive allows the public to upload and download digital material to its data cluster, but the bulk of its data is collected automatically by its web crawlers, which work to preserve as much of the public web as possible. Its web archive, the Wayback Machine, contains hundreds of billions of web captures.[notes 4] The Archive also oversees one of the world's largest book digitization projects.
- digital material
- digital library
- digitization
1. History

Brewster Kahle founded the Archive in May 1996 around the same time that he began the for-profit web crawling company Alexa Internet.[1] In October 1996, the Internet Archive had begun to archive and preserve the World Wide Web in large quantities,[2] though it saved the earliest pages in May 1996.[3][4] The archived content first became available to the general public in 2001, when it developed the Wayback Machine.
In late 1999, the Archive expanded its collections beyond the Web archive, beginning with the Prelinger Archives. Now the Internet Archive includes texts, audio, moving images, and software. It hosts a number of other projects: the NASA Images Archive, the contract crawling service Archive-It, and the wiki-editable library catalog and book information site Open Library. Soon after that, the Archive began working to provide specialized services relating to the information access needs of the print-disabled; publicly accessible books were made available in a protected Digital Accessible Information System (DAISY) format.[5]
According to its website:[6]
Most societies place importance on preserving artifacts of their culture and heritage. Without such artifacts, civilization has no memory and no mechanism to learn from its successes and failures. Our culture now produces more and more artifacts in digital form. The Archive's mission is to help preserve those artifacts and create an Internet library for researchers, historians, and scholars.
In August 2012, the Archive announced[7] that it has added BitTorrent to its file download options for more than 1.3 million existing files, and all newly uploaded files.[8][9] This method is the fastest means of downloading media from the Archive, as files are served from two Archive data centers, in addition to other torrent clients which have downloaded and continue to serve the files.[8][10] On November 6, 2013, the Internet Archive's headquarters in San Francisco's Richmond District caught fire,[11] destroying equipment and damaging some nearby apartments.[12] According to the Archive, it lost a side-building housing one of 30 of its scanning centers; cameras, lights, and scanning equipment worth hundreds of thousands of dollars; and "maybe 20 boxes of books and film, some irreplaceable, most already digitized, and some replaceable".[13] The nonprofit Archive sought donations to cover the estimated $600,000 in damage.[14]
An overhaul of the site was launched as beta in November 2014, and the legacy layout was removed in March 2016.[15][16]
In November 2016, Kahle announced that the Internet Archive was building the Internet Archive of Canada, a copy of the Archive to be based somewhere in Canada . The announcement received widespread coverage due to the implication that the decision to build a backup archive in a foreign country was because of the upcoming presidency of Donald Trump.[17][18][19] Kahle was quoted as saying:
On November 9th in America, we woke up to a new administration promising radical change. It was a firm reminder that institutions like ours, built for the long-term, need to design for change. For us, it means keeping our cultural materials safe, private and perpetually accessible. It means preparing for a Web that may face greater restrictions. It means serving patrons in a world in which government surveillance is not going away; indeed it looks like it will increase. Throughout history, libraries have fought against terrible violations of privacy—where people have been rounded up simply for what they read. At the Internet Archive, we are fighting to protect our readers' privacy in the digital world.[17]
Beginning in 2017, OCLC and the Internet Archive have collaborated to make the Archive's records of digitized books available in WorldCat.[20]
Since 2018, the Internet Archive visual arts residency, which is organized by Amir Saber Esfahani and Andrew McClintock, helps connect artists with the Archive's over 48 petabytes[21] of digitized materials. Over the course of the yearlong residency, visual artists create a body of work which culminates in an exhibition. The hope is to connect digital history with the arts and create something for future generations to appreciate online or off.[22] Previous artists in residence include Taravat Talepasand, Whitney Lynn, and Jenny Odell.[23]
In 2019, its headquarters in San Francisco received a bomb threat which forced a temporary evacuation of the building.[24]
The Internet Archive acquires most materials from donations,[25] such as hundreds of thousands of 78 rpm discs from Boston Public Library in 2017,[26] a donation of 250,000 books from Trent University in 2018,[27] and the entire collection of Marygrove College's library in 2020 after it closed.[28] All material is then digitized and retained in digital storage, while a digital copy is returned to the original holder and the Internet Archive's copy, if not in the public domain, is lent to patrons worldwide one at a time under the controlled digital lending (CDL) theory of the first-sale doctrine.[29]
2. Operations

The Archive is a 501(c)(3) nonprofit operating in the United States. It has an annual budget of $10 million, derived from revenue from its Web crawling services, various partnerships, grants, donations, and the Kahle-Austin Foundation.[30] The Internet Archive also manages periodic funding campaigns. For instance, a December 2019 campaign had a goal of reaching $6 million in donations.
The Archive is headquartered in San Francisco, California . From 1996 to 2009, its headquarters were in the Presidio of San Francisco, a former U.S. military base. Since 2009, its headquarters have been at 300 Funston Avenue in San Francisco , a former Christian Science Church. At one time, most of its staff worked in its book-scanning centers; as of 2019, scanning is performed by 100 paid operators worldwide.[31] The Archive also has data centers in three Californian cities: San Francisco, Redwood City, and Richmond. To reduce the risk of data loss, the Archive creates copies of parts of its collection at more distant locations, including the Bibliotheca Alexandrina[32] in Egypt and a facility in Amsterdam.[33]
The Archive is a member of the International Internet Preservation Consortium[34] and was officially designated as a library by the state of California in 2007.[35][36]
3. Web Archiving
3.1. Wayback Machine
The Internet Archive capitalized on the popular use of the term "WABAC Machine" from a segment of The Adventures of Rocky and Bullwinkle cartoon (specifically, Peabody's Improbable History), and uses the name "Wayback Machine" for its service that allows archives of the World Wide Web to be searched and accessed.[37] This service allows users to view some of the archived web pages. The Wayback Machine was created as a joint effort between Alexa Internet (owned by Amazon.com) and the Internet Archive when a three-dimensional index was built to allow for the browsing of archived web content.[38] Millions of web sites and their associated data (images, source code, documents, etc.) are saved in a database. The service can be used to see what previous versions of web sites used to look like, to grab original source code from web sites that may no longer be directly available, or to visit web sites that no longer even exist. Not all web sites are available because many web site owners choose to exclude their sites. As with all sites based on data from web crawlers, the Internet Archive misses large areas of the web for a variety of other reasons. A 2004 paper found international biases in the coverage, but deemed them "not intentional".[39]


A "Save Page Now" archiving feature was made available in October 2013,[40] accessible on the lower right of the Wayback Machine's main page.[41] Once a target URL is entered and saved, the web page will become part of the Wayback Machine.[40] Through the Internet address web.archive.org,[42] users can upload to the Wayback Machine a large variety of contents, including PDF and data compression file formats. The Wayback Machine creates a permanent local URL of the upload content, that is accessible in the web, even if not listed while searching in the http://archive.org official website.
May 12, 1996, is the date of the oldest archived pages on the archive.org WayBack Machine, such as infoseek.com.[43]
In October 2016, it was announced that the way web pages are counted would be changed, resulting in the decrease of the archived pages counts shown.[44]
| Year | Archived pages (billions) |
|---|---|
| 2005 | 40[45] |
| 2006 | 85[46] |
| 2007 | 85[47] |
| 2008 | 85[48] |
| 2009 | 150[49] |
| 2010 | 150[50] |
| 2011 | 150[51] |
| 2012 | 150[52] |
| 2013 | 373[53] |
| 2014 | 430[54] |
| 2015 | 479[55] |
| 2016 | 510[A][56]
273[B][44] |
| 2017 | 286[57] |
| 2018 | 344[58] |
|
A Using the old counting system used before October 2016 |
|
In September 2020, the Internet Archive announced a partnership with Cloudflare to automatically index websites served via its "Always Online" services.[59]
3.2. Archive-It
Created in early 2006, Archive-It[60] is a web archiving subscription service that allows institutions and individuals to build and preserve collections of digital content and create digital archives. Archive-It allows the user to customize their capture or exclusion of web content they want to preserve for cultural heritage reasons. Through a web application, Archive-It partners can harvest, catalog, manage, browse, search, and view their archived collections.[61]
In terms of accessibility, the archived web sites are full text searchable within seven days of capture.[62] Content collected through Archive-It is captured and stored as a WARC file. A primary and back-up copy is stored at the Internet Archive data centers. A copy of the WARC file can be given to subscribing partner institutions for geo-redundant preservation and storage purposes to their best practice standards.[63] Periodically, the data captured through Archive-It is indexed into the Internet Archive's general archive.
(As of March 2014), Archive-It had more than 275 partner institutions in 46 U.S. states and 16 countries that have captured more than 7.4 billion URLs for more than 2,444 public collections. Archive-It partners are universities and college libraries, state archives, federal institutions, museums, law libraries, and cultural organizations, including the Electronic Literature Organization, North Carolina State Archives and Library, Stanford University, Columbia University, American University in Cairo, Georgetown Law Library, and many others.
3.3. Internet Archive Scholar
In September 2020 Internet Archive announced a new initiative to archive and preserve open access academic journals, called the "Internet Archive Scholar".[64][65] Its fulltext search index includes over 25 million research articles and other scholarly documents preserved in the Internet Archive. The collection spans from digitized copies of eighteenth century journals through the latest Open Access conference proceedings and pre-prints crawled from the World Wide Web.
4. Book Collections
4.1. Text Collection

The Internet Archive operates 33 scanning centers in five countries, digitizing about 1,000 books a day for a total of more than 2 million books,[66] financially supported by libraries and foundations.[67] (As of July 2013), the collection included 4.4 million books with more than 15 million downloads per month.[66] (As of November 2008), when there were approximately 1 million texts, the entire collection was greater than 0.5 petabytes, which includes raw camera images, cropped and skewed images, PDFs, and raw OCR data.[68] Between about 2006 and 2008, Microsoft had a special relationship with Internet Archive texts through its Live Search Books project, scanning more than 300,000 books that were contributed to the collection, as well as financial support and scanning equipment. On May 23, 2008, Microsoft announced it would be ending the Live Book Search project and no longer scanning books.[69] Microsoft made its scanned books available without contractual restriction and donated its scanning equipment to its former partners.[69]

Around October 2007, Archive users began uploading public domain books from Google Book Search.[70] (As of November 2013), there were more than 900,000 Google-digitized books in the Archive's collection;[71] the books are identical to the copies found on Google, except without the Google watermarks, and are available for unrestricted use and download.[72] Brewster Kahle revealed in 2013 that this archival effort was coordinated by Aaron Swartz, who with a "bunch of friends" downloaded the public domain books from Google slow enough and from enough computers to stay within Google's restrictions. They did this to ensure public access to the public domain. The Archive ensured the items were attributed and linked back to Google, which never complained, while libraries "grumbled". According to Kahle, this is an example of Swartz's "genius" to work on what could give the most to the public good for millions of people.[73] Besides books, the Archive offers free and anonymous public access to more than four million court opinions, legal briefs, or exhibits uploaded from the United States Federal Courts' PACER electronic document system via the RECAP web browser plugin. These documents had been kept behind a federal court paywall. On the Archive, they had been accessed by more than six million people by 2013.[73]
The Archive's BookReader web app,[74] built into its website, has features such as single-page, two-page, and thumbnail modes; fullscreen mode; page zooming of high-resolution images; and flip page animation.[74][75]
4.2. Number of Texts for Each Language
| Number of all texts (December 9, 2019) |
22,197,912[76] |
|---|
| Language | Number of texts (November 27, 2015) |
|---|---|
| English | 6,553,945[77] |
| French | 358,721[78] |
| German | 344,810[79] |
| Spanish | 134,170[80] |
| Chinese | 84,147[81] |
| Arabic | 66,786[82] |
| Dutch | 30,237[83] |
| Portuguese | 25,938[84] |
| Russian | 22,731[85] |
| Urdu | 14,978[86] |
| Japanese | 14,795[87] |
4.3. Number of Texts for Each Decade
|
|
|
4.4. Open Library
The Open Library is another project of the Internet Archive. The wiki seeks to include a web page for every book ever published: it holds 25 million catalog records of editions. It also seeks to be a web-accessible public library: it contains the full texts of approximately 1,600,000 public domain books (out of the more than five million from the main texts collection), as well as in-print and in-copyright books,[111] many of which are fully readable, downloadable[112][113] and full-text searchable;[114] it offers a two-week loan of e-books in its controlled digital lending program for over 647,784 books not in the public domain, in partnership with over 1,000 library partners from 6 countries[66][115] after a free registration on the web site. Open Library is a free and open-source software project, with its source code freely available on GitHub.
The Open Library faces objections from some authors and the Society of Authors, who hold that the project is distributing books without authorization and is thus in violation of copyright laws,[116] and four major publishers initiated a copyright infringement lawsuit against the Internet Archive in June 2020 to stop the Open Library project.[117]
4.5. Digitizing Sponsors for Books
Many large institutional sponsors have helped the Internet Archive provide millions of scanned publications (text items).[118] Some sponsors that have digitized large quantities of texts include the University of Toronto's Robarts Library, the University of Alberta Libraries, the University of Ottawa, the Library of Congress, Boston Library Consortium member libraries, the Boston Public Library, the Princeton Theological Seminary Library, and many others.[119]
In 2017, the MIT Press authorized the Internet Archive to digitize and lend books from the press's backlist,[120] with financial support from the Arcadia Fund.[121][122] A year later, the Internet Archive received further funding from the Arcadia Fund to invite some other university presses to partner with the Internet Archive to digitize books, a project called "Unlocking University Press Books".[123][124]
The Library of Congress has created numerous handle system identifiers that point to free digitized books in the Internet Archive.[125] The Internet Archive and Open Library are listed on the Library of Congress website as a source of e-books.[126]
5. Media Collections



In addition to web archives, the Internet Archive maintains extensive collections of digital media that are attested by the uploader to be in the public domain in the United States or licensed under a license that allows redistribution, such as Creative Commons licenses. Media are organized into collections by media type (moving images, audio, text, etc.), and into sub-collections by various criteria. Each of the main collections includes a "Community" sub-collection (formerly named "Open Source") where general contributions by the public are stored.
5.1. Audio
Audio Archive
The Audio Archive is an audio archive that includes music, audiobooks, news broadcasts, old time radio shows, and a wide variety of other audio files. There are more than 200,000 free digital recordings in the collection. The subcollections include audio books and poetry, podcasts, non-English audio, and many others.[127] The sound collections are curated by B. George, director of the ARChive of Contemporary Music.[128]
Next to the stock HTML5 audio player, Winamp-resembling Webamp is available.
Live Music Archive
The Live Music Archive sub-collection includes more than 170,000 concert recordings from independent musicians, as well as more established artists and musical ensembles with permissive rules about recording their concerts, such as the Grateful Dead, and more recently, The Smashing Pumpkins. Also, Jordan Zevon has allowed the Internet Archive to host a definitive collection of his father Warren Zevon's concert recordings. The Zevon collection ranges from 1976 to 2001 and contains 126 concerts including 1,137 songs.[129]
The Great 78 Project
The Great 78 Project aims to digitize 250,000 78 rpm singles (500,000 songs) from the period between 1880 and 1960, donated by various collectors and institutions. It has been developed in collaboration with the Archive of Contemporary Music and George Blood Audio, responsible for the audio digitization.[128]
Netlabels
The Archive has a collection of freely distributable music that is streamed and available for download via its Netlabels service. The music in this collection generally has Creative Commons-license catalogs of virtual record labels.[130][131]
Images collection
This collection contains more than 3.5 million items.[132] Cover Art Archive, Metropolitan Museum of Art - Gallery Images, NASA Images, Occupy Wall Street Flickr Archive, and USGS Maps and are some sub-collections of Image collection.
Cover Art Archive

The Cover Art Archive is a joint project between the Internet Archive and MusicBrainz, whose goal is to make cover art images on the Internet. (As of April 2021) this collection contains more than 1,400,000 items.[133]
Metropolitan Museum of Art images
The images of this collection are from the Metropolitan Museum of Art. This collection contains more than 140,000 items.[134]
NASA Images
The NASA Images archive was created through a Space Act Agreement between the Internet Archive and NASA to bring public access to NASA's image, video, and audio collections in a single, searchable resource. The IA NASA Images team worked closely with all of the NASA centers to keep adding to the ever-growing collection.[135] The nasaimages.org site launched in July 2008 and had more than 100,000 items online at the end of its hosting in 2012.
Occupy Wall Street Flickr archive
This collection contains creative commons licensed photographs from Flickr related to the Occupy Wall Street movement. This collection contains more than 15,000 items.[136]
USGS Maps
This collection contains more than 59,000 items from Libre Map Project.[137]
Mathematical images
This collection contains mathematical images created by mathematical artist Hamid Naderi Yeganeh.[138]
5.2. Machinima Archive
One of the sub-collections of the Internet Archive's Video Archive is the Machinima Archive. This small section hosts many Machinima videos. Machinima is a digital artform in which computer games, game engines, or software engines are used in a sandbox-like mode to create motion pictures, recreate plays, or even publish presentations or keynotes. The archive collects a range of Machinima films from internet publishers such as Rooster Teeth and Machinima.com as well as independent producers. The sub-collection is a collaborative effort among the Internet Archive, the How They Got Game research project at Stanford University, the Academy of Machinima Arts and Sciences, and Machinima.com.[139]
5.3. Microfilm collection
This collection contains approximately 160,000 microfilmed items from a variety of libraries including the University of Chicago Libraries, the University of Illinois at Urbana-Champaign, the University of Alberta, Allen County Public Library, and the National Technical Information Service.[140][141]
5.4. Moving Image Collection
The Internet Archive holds a collection of approximately 3,863 feature films.[142] Additionally, the Internet Archive's Moving Image collection includes: newsreels, classic cartoons, pro- and anti-war propaganda, The Video Cellar Collection, Skip Elsheimer's "A.V. Geeks" collection, early television, and ephemeral material from Prelinger Archives, such as advertising, educational, and industrial films, as well as amateur and home movie collections.
Subcategories of this collection include:
- IA's Brick Films collection, which contains stop-motion animation filmed with Lego bricks, some of which are "remakes" of feature films.
- IA's Election 2004 collection, a non-partisan public resource for sharing video materials related to the 2004 United States presidential election.
- IA's FedFlix collection, Joint Venture NTIS-1832 between the National Technical Information Service and Public.Resource.Org that features "the best movies of the United States Government, from training films to history, from our national parks to the U.S. Fire Academy and the Postal Inspectors"[143]
- IA's Independent News collection, which includes sub-collections such as the Internet Archive's World At War competition from 2001, in which contestants created short films demonstrating "why access to history matters". Among their most-downloaded video files are eyewitness recordings of the devastating 2004 Indian Ocean earthquake.
- IA's September 11 Television Archive, which contains archival footage from the world's major television networks of the terrorist attacks of September 11, 2001, as they unfolded on live television.[144]
5.5. Open Educational Resources
Open Educational Resources is a digital collection at archive.org. This collection contains hundreds of free courses, video lectures, and supplemental materials from universities in the United States and China . The contributors of this collection are ArsDigita University, Hewlett Foundation, MIT, Monterey Institute, and Naropa University.[145]
5.6. TV News Search & Borrow

In September 2012, the Internet Archive launched the TV News Search & Borrow service for searching U.S. national news programs.[146] The service is built on closed captioning transcripts and allows users to search and stream 30-second video clips. Upon launch, the service contained "350,000 news programs collected over 3 years from national U.S. networks and stations in San Francisco and Washington D.C."[147] According to Kahle, the service was inspired by the Vanderbilt Television News Archive, a similar library of televised network news programs.[148] In contrast to Vanderbilt, which limits access to streaming video to individuals associated with subscribing colleges and universities, the TV News Search & Borrow allows open access to its streaming video clips. In 2013, the Archive received an additional donation of "approximately 40,000 well-organized tapes" from the estate of a Philadelphia woman, Marion Stokes. Stokes "had recorded more than 35 years of TV news in Philadelphia and Boston with her VHS and Betamax machines."[149]
5.7. Miscellaneous Collections
Brooklyn Museum
This collection contains approximately 3,000 items from Brooklyn Museum.[150]
Michelson library
In December 2020, the film research library of Lillian Michelson was donated to the archive.[151]
6. Other Services and Endeavors
6.1. Physical Media

Voicing a strong reaction to the idea of books simply being thrown away, and inspired by the Svalbard Global Seed Vault, Kahle now envisions collecting one copy of every book ever published. "We're not going to get there, but that's our goal", he said. Alongside the books, Kahle plans to store the Internet Archive's old servers, which were replaced in 2010.[152]
6.2. Software
The Internet Archive has "the largest collection of historical software online in the world", spanning 50 years of computer history in terabytes of computer magazines and journals, books, shareware discs, FTP sites, video games, etc. The Internet Archive has created an archive of what it describes as "vintage software", as a way to preserve them.[153] The project advocated for an exemption from the United States Digital Millennium Copyright Act to permit them to bypass copy protection, which was approved in 2003 for a period of three years.[154] The Archive does not offer the software for download, as the exemption is solely "for the purpose of preservation or archival reproduction of published digital works by a library or archive."[155] The exemption was renewed in 2006, and in 2009 was indefinitely extended pending further rulemakings.[156] The Library reiterated the exemption as a "Final Rule" with no expiration date in 2010.[157] In 2013, the Internet Archive began to provide abandonware video games browser-playable via MESS, for instance the Atari 2600 game E.T. the Extra-Terrestrial.[158] Since December 23, 2014, the Internet Archive presents, via a browser-based DOSBox emulation, thousands of DOS/PC games[159][160][161][162] for "scholarship and research purposes only".[163][164][165] In November 2020, the Archive introduced a new emulator for Adobe Flash called Ruffle, and began archiving Flash animations and games ahead of the December 31, 2020 end-of-life for the Flash plugin across all computer systems.[166]
6.3. Table Top Scribe System
A combined hardware software system has been developed that performs a safe method of digitizing content.[167][168]
6.4. Credit Union
From 2012 to November 2015, the Internet Archive operated the Internet Archive Federal Credit Union, a federal credit union based in New Brunswick, New Jersey, with the goal of providing access to low- and middle-income people. Throughout its short existence, the IAFCU experienced significant conflicts with the National Credit Union Administration, which severely limited the IAFCU's loan portfolio and concerns over serving Bitcoin firms. At the time of its dissolution, it consisted of 395 members and was worth $2.5 million.[169][170]
7. Controversies and Legal Disputes

7.1. Grateful Dead
In November 2005, free downloads of Grateful Dead concerts were removed from the site. John Perry Barlow identified Bob Weir, Mickey Hart, and Bill Kreutzmann as the instigators of the change, according to an article in The New York Times .[171] Phil Lesh commented on the change in a November 30, 2005, posting to his personal web site:
It was brought to my attention that all of the Grateful Dead shows were taken down from Archive.org right before Thanksgiving. I was not part of this decision making process and was not notified that the shows were to be pulled. I do feel that the music is the Grateful Dead's legacy and I hope that one way or another all of it is available for those who want it.[172]
A November 30 forum post from Brewster Kahle summarized what appeared to be the compromise reached among the band members. Audience recordings could be downloaded or streamed, but soundboard recordings were to be available for streaming only. Concerts have since been re-added.[173]
7.2. National Security Letters
On May 8, 2008, it was revealed that the Internet Archive had successfully challenged an FBI national security letter asking for logs on an undisclosed user.[174][175]
On November 28, 2016, it was revealed that a second FBI national security letter had been successfully challenged that had been asking for logs on another undisclosed user.[176]
7.3. Opposition to SOPA and PIPA Bills
The Internet Archive blacked out its web site for 12 hours on January 18, 2012, in protest of the Stop Online Piracy Act and the PROTECT IP Act bills, two pieces of legislation in the United States Congress that they claimed would "negatively affect the ecosystem of web publishing that led to the emergence of the Internet Archive". This occurred in conjunction with the English Wikipedia blackout, as well as numerous other protests across the Internet.[177]
7.4. Opposition to Google Books Settlement
The Internet Archive is a member of the Open Book Alliance, which has been among the most outspoken critics of the Google Book Settlement. The Archive advocates an alternative digital library project.[178]
7.5. Nintendo Power Magazine
In February 2016, Internet Archive users had begun archiving digital copies of Nintendo Power, Nintendo's official magazine for their games and products, which ran from 1988 to 2012. The first 140 issues had been collected, before Nintendo had the archive removed on August 8, 2016. In response to the take-down, Nintendo told gaming website Polygon, "[Nintendo] must protect our own characters, trademarks and other content. The unapproved use of Nintendo's intellectual property can weaken our ability to protect and preserve it, or to possibly use it for new projects".[179]
7.6. Government of India
In August 2017, the Department of Telecommunications of the Government of India blocked the Internet Archive along with other file-sharing websites, in accordance with two court orders issued by the Madras High Court,[180] citing piracy concerns after copies of two Bollywood films were allegedly shared via the service.[181] The HTTP version of the Archive was blocked but it remained accessible using the HTTPS protocol.[180]
7.7. Turkey
On October 9, 2016, the Internet Archive was temporarily blocked in Turkey after it was used (amongst other file hosters) by hackers to host 17 GB of leaked government emails.[182][183]
7.8. National Emergency Library
In the midst of the COVID-19 pandemic which closed many schools, universities, and libraries, the Archive announced on March 24, 2020 that it was creating the National Emergency Library by removing the lending restrictions it had in place for 1.4 million digitized books in its Open Library but otherwise limiting users to the number of books they could check out and enforcing their return; normally, the site would only allow one digital lending for each physical copy of the book they had, by use of an encrypted file that would become unusable after the lending period was completed. This Library would remain as such until at least June 30, 2020 or until the US national emergency was over, whichever came later.[184] At launch, the Internet Archive allowed authors and rightholders to submit opt-out requests for their works to be omitted from the National Emergency Library.[185][186][187]
The Internet Archive said the National Emergency Library addressed an "unprecedented global and immediate need for access to reading and research material" due to the closures of physical libraries worldwide.[188] They justified the move in a number of ways. Legally, they said they were promoting access to those inaccessible resources, which they claimed was an exercise in Fair Use principles. The Archive continued implementing their controlled digital lending policy that predated the National Emergency Library, meaning they still encrypted the lent copies and it was no easier for users to create new copies of the books than before. An ultimate determination of whether or not the National Emergency Library constituted Fair Use could only be made by a court. Morally, they also pointed out that the Internet Archive was a registered library like any other, that they either paid for the books themselves or received them as donations, and that lending through libraries predated copyright restrictions.[185][189]
However, the Archive had already been criticized by authors and publishers for its prior lending approach, and upon announcement of the National Emergency Library, authors (like Neil Gaiman and Chuck Wendig), publishers, and groups representing both took further issue, equating the move to copyright infringement and digital piracy, and using the COVID-19 pandemic as a reason to push the boundaries of copyright (see also: Open Library § Copyright violation accusations).[190][191][192][193] After the works of some of these authors were ridiculed in responses, the Internet Archive's Jason Scott requested that supporters of the National Emergency Library not denigrate anyone's books: "I realize there's strong debate and disagreement here, but books are life-giving and life-changing and these writers made them."[194]
7.9. Publishers' Lawsuit
The operation of the National Emergency Library is part of a lawsuit filed against the Internet Archive by four major book publishers in June 2020, challenging the copyright validity of the controlled digital lending program.[117] In response, the Internet Archive closed the National Emergency Library on June 16, 2020, rather than the planned June 30, 2020, due to the lawsuit.[195][196] The plaintiffs, supported by the Copyright Alliance,[197] claimed in their lawsuit that the Internet Archive's actions constituted a "willful mass copyright infringement". Additionally, Senator Thom Tillis (R-North Carolina), chairman of the intellectual property subcommittee on the Senate Judiciary Committee, said in a letter to the Internet Archive that he was "concerned that the Internet Archive thinks that it – not Congress – gets to determine the scope of copyright law".[198] In August 2020 the lawsuit trial was tentatively scheduled to begin in November 2021.[199]
As part of its response to the publishers' lawsuit, in late 2020 the Archive launched a campaign called Empowering Libraries (hashtag #EmpoweringLibraries) that portrayed the lawsuit as a threat to all libraries.[200]
In December 2020, Publishers Weekly included the lawsuit among its "Top 10 Library Stories of 2020".[201]
In a 2021 preprint article, Argyri Panezi argued that the case "presents two important, but separate questions related to the electronic access to library works; first, it raises questions around the legal practice of digital lending, and second, it asks whether emergency use of copyrighted material might be fair use" and argued that libraries have a public service role to enable "future generations to keep having equal access—or opportunities to access—a plurality of original sources".[202]
7.10. Wayforward Machine
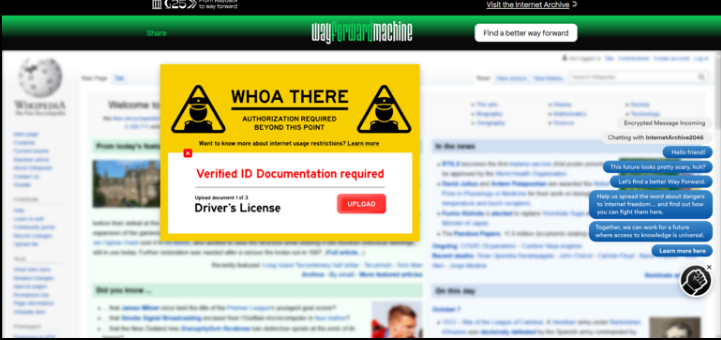
In October 2021, as part of its 25th anniversary, the Internet Archive launched the "Wayforward Machine", a pseudo-satirical or fictional website covered with pop-ups asking for personal information. The site was intended to depict a potential timeline of events leading to such a future, such as the repeal of Section 230 of the United States Code.[203][204] The Wayforward Machine will be removed after the Archive's 25th anniversary.[needs update]
8. Ceramic Archivists Collection

The Great Room of the Internet Archive features a collection of more than 100 ceramic figures representing employees of the Internet Archive. This collection, inspired by the statues of the Xian warriors in China, was commissioned by Brewster Kahle, sculpted by Nuala Creed, and is ongoing.[205]
9. Artists in Residence
The Internet Archive visual arts residency,[206] organized by Amir Saber Esfahani, is designed to connect emerging and mid-career artists with the Archive's millions of collections and to show what is possible when open access to information intersects with the arts. During this one-year residency, selected artists develop a body of work that responds to and utilizes the Archive's collections in their own practice.[207]
2019 Residency Artists: Caleb Duarte, Whitney Lynn, and Jeffrey Alan Scudder.
2018 Residency Artists: Mieke Marple, Chris Sollars, and Taravat Talepasand.
2017 Residency Artists: Laura Kim, Jeremiah Jenkins, and Jenny Odell
The content is sourced from: https://handwiki.org/wiki/Internet_Archive
References
- "Brewster Kahle . In Scientific American". Internet Archive. November 4, 1997. https://archive.org/sciam_article.html.
- "Internet Archive: In the Collections". Wayback Machine. June 6, 2000. https://archive.org/collections/index.html.
- "MTV Online: Main Page – Wayback Machine". Wayback Machine. May 12, 1996. http://www.mtv.com.
- "Infoseek Guide – Wayback Machine". Wayback Machine. May 12, 1996. http://www.infoseek.com/.
- "Daisy Books for the Print Disabled" , February 25, 2013. Internet Archive. https://archive.org/details/printdisabled
- "Internet Archive Frequently Asked Questions". https://archive.org/about/faqs.php#21.
- Kahle, Brewster (August 7, 2012). "Over 1,000,000 Torrents of Downloadable Books, Music, and Movies" . Internet Archive Blogs. https://blog.archive.org/2012/08/07/over-1000000-torrents-of-downloadable-books-music-and-movies/
- Ernesto (August 7, 2012). "Internet Archive Starts Seeding 1,398,875 Torrents". TorrentFreak. https://torrentfreak.com/internet-archive-starts-seeding-1398635-torrents-120807/.
- "Hot List for bt1.us.archive.org (Updated August 7 2012, 7:31 pm PDT)" . US Cluster. Internet Archive. http://bt1.archive.org/hotlist.php
- "Welcome to Archive torrents" . Internet Archive. https://archive.org/details/bittorrent
- B, Sarah (November 6, 2013). "Part of Internet Archive building badly burned in early morning fire". http://richmondsfblog.com/2013/11/06/part-of-internet-archive-building-badly-burned-in-early-morning-fire/.
- Alexander, Kurtis (November 16, 2013). "Internet Archive's S.F. office damaged in fire". San Francisco Chronicle. http://www.sfgate.com/bayarea/article/Internet-Archive-s-S-F-office-damaged-in-fire-4960703.php.
- "Fire Update: Lost Many Cameras, 20 Boxes. No One Hurt". Internet Archive Blogs. November 6, 2013. https://blog.archive.org/2013/11/06/scanning-center-fire-please-help-rebuild/.
- Shu, Catherine (November 6, 2013). "Internet Archive Seeking Donations To Rebuild Its Fire-Damaged Scanning Center". TechCrunch. https://techcrunch.com/2013/11/06/internet-archive-seeking-donations-to-rebuild-its-fire-damaged-scanning-center/.
- Rossi, Alexis (2014-11-05). "Redesigning Archive.org" (in en-US). https://blog.archive.org/2014/11/05/redesign/.
- "Internet Archive: Digital Library of Free Books, Movies, Music & Wayb…". 2016-03-25. http://archive.today/2nuds.
- Kahle, Brewster (November 29, 2016). "Help Us Keep the Archive Free, Accessible, and Reader Private". https://blog.archive.org/2016/11/29/help-us-keep-the-archive-free-accessible-and-private/.
- Johnson, Tim (December 1, 2016). "Donald Trump scares Internet Archive into moving to Canada". http://www.mcclatchydc.com/news/nation-world/national/article118256733.html.
- Rothschild, Mike (December 2, 2016). "The Internet Archive Is Moving to Canada to Protect Itself from Trump". http://www.attn.com/stories/13238/the-internet-archive-is-moving-to-canada-due-to-trump-presidency.
- Michalko, Jim (October 12, 2017). "Syncing Catalogs with thousands of Libraries in 120 Countries through OCLC". Internet Archive. https://blog.archive.org/2017/10/12/syncing-catalogs-with-thousands-of-libraries-in-120-countries-through-oclc/.
- "Used Paired Space". March 8, 2019. https://archive.org/~tracey/mrtg/du.html.
- Locker, Melissa (July 3, 2018). "The Internet Archive is helping these artists get inspired by digital history" (in en-US). https://www.fastcompany.com/90179133/the-internet-archive-is-helping-these-artists-get-inspired-by-digital-history.
- "Jenny Odell - Neo-Surreal". May 30, 2018. https://thephotographersgallery.org.uk/whats-on/display/jenny-odell-neo-surreal.
- "Internet Archive evacuated due to bomb threat". https://www.msn.com/en-us/news/us/internet-archive-evacuated-due-to-bomb-threat/ar-BBUbgZC.
- "How do I make a physical donation to the Internet Archive?". https://help.archive.org/hc/en-us/articles/360017876312-How-do-I-make-a-physical-donation-to-the-Internet-Archive-. See also: "Tag Archives: donations". https://blog.archive.org/tag/donations/.
- "Boston Public Library transfers sound archives collection to Internet Archive for digitization, preservation, and public access". October 11, 2017. https://www.bpl.org/news/boston-public-library-transfers-sound-archives-collection-to-internet-archive-for-digitization-preservation-and-public-access/.
- "Trent University donates 250,000 books to be digitized by Internet Archive as part of Bata Library transformation". September 13, 2018. https://www.trentu.ca/news/story/22235.
- Seltzer, Rick (October 21, 2020). "A new home online for closed college libraries?". https://www.insidehighered.com/news/2020/10/21/marygrove-college-library-materials-have-been-digitized-and-placed-online-will.
- Matt Enis (May 2, 2019). "Internet Archive Expands Partnerships for Open Libraries Project". https://www.libraryjournal.com/?detailStory=internet-archive-expands-partnerships-for-open-library-project.
- Womack, David (Spring 2003). "Who Owns History?". Cabinet Magazine (10). http://www.cabinetmagazine.org/issues/10/womack.php.
- Whitney Kimball. "The Internet Archive Fights Wiki Citation Wars With Books". https://gizmodo.com/the-internet-archive-fights-wiki-citation-wars-with-boo-1839609540.
- "Donation to the new Library of Alexandria in Egypt" ; Alexandria, Egypt; April 20, 2002. Bibliotheca Alexandrina . Internet Archive. https://archive.org/about/bibalex.php
- "Brewster Kahle: Universal Access to All Knowledge – The Long Now". 45'47". http://longnow.org/seminars/02011/nov/30/universal-access-all-knowledge/.
- "Members". http://netpreserve.org/about/memberList.php. International Internet Preservation Consortium. Netpreserve.org
- "Internet Archive officially a library" , May 2, 2007. Internet Archive https://archive.org/iathreads/post-view.php?id=121377
- McCoy, Adrian (June 24, 2007). "The Internet gives birth to an 'official' online library". https://old.post-gazette.com/pg/07175/796164-96.stm.
- Green, Heather (February 28, 2002). "A Library as Big as the World". Business Week Online. http://www.businessweek.com/technology/content/feb2002/tc20020228_1080.htm.
- "Internet Archive. (2012). Frequently Asked Questions". Internet Archive. https://archive.org/about/faqs.php.
- Thelwall, Mike; Vaughan, Liwen (Spring 2004). "A fair history of the Web? Examining country balance in the Internet Archive". Library & Information Science Research 26 (2): 162–176. doi:10.1016/j.lisr.2003.12.009. http://www.scit.wlv.ac.uk/~cm1993/papers/fair_history_preprint.pdf.
- Rossi, Alexis (October 25, 2013). "Fixing Broken Links on the Internet". Internet Archive. https://blog.archive.org/2013/10/25/fixing-broken-links/.
- "Wayback Machine main page". Internet Archive. https://archive.org/web/.
- "Web.archive.org directory". https://web.archive.org.
- "Internet Archive Forums: What is the oldest page on the Wayback Machine?". https://archive.org/post/60275/what-is-the-oldest-page-on-the-wayback-machine.
- Goel, Vinay (October 23, 2016). "Defining Web pages, Web sites and Web captures". Internet Archive. https://blog.archive.org/2016/10/23/defining-web-pages-web-sites-and-web-captures/.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/index.php.
- "Internet Archive". Internet Archive. https://archive.org/.
- "430 Billion Web Pages Saved. ... Help Us Do More! | Internet Archive Blogs" (in en-US). December 3, 2014. https://blog.archive.org/2014/12/03/430-billion-web-pages-saved-help-us-do-more/.
- "Internet Archive". Internet Archive. https://archive.org/.
- "Internet Archive". Internet Archive. https://archive.org/.
- "Internet Archive". Internet Archive. https://archive.org/.
- "Internet Archive". Internet Archive. https://archive.org/.
- Graham, Mark (2020-09-17). "Cloudflare and the Wayback Machine, joining forces for a more reliable Web" (in en-US). http://blog.archive.org/2020/09/17/internet-archive-partners-with-cloudflare-to-help-make-the-web-more-useful-and-reliable/.
- "archive-it.org". archive-it.org. http://www.archive-it.org/.
- Truman, Gail (January 2016). Web Archiving Environmental Scan. Harvard Library Report. http://nrs.harvard.edu/urn-3:HUL.InstRepos:25658314. Retrieved October 3, 2017.
- "What is the Difference between the General Archive (sometimes called the Wayback Machine) and Archive-It?" . Archive-It How to FAQ. Archive-It. – via Jira.com. https://webarchive.jira.com/wiki/display/ARIH/Archive-It+How-to+FAQ#Archive-ItHow-toFAQ-differencebetween
- "About Archive-It". Archive-It.. http://www.archive-it.org/learn-more.
- Archives, in; Data; Education; Archive, Internet; September 22nd, Libraries |; Comment, 2020 Leave a. "The Internet Archive Will Digitize & Preserve Millions of Academic Articles with Its New Database, "Internet Archive Scholar"" (in en-US). http://www.openculture.com/2020/09/internet-archive-scholar.html.
- Bryan, Newbold (2021-03-09). "Search Scholarly Materials Preserved in the Internet Archive". https://blog.archive.org/2021/03/09/search-scholarly-materials-preserved-in-the-internet-archive/.
- Hoffelder, Nate (July 9, 2013). "Internet Archive Now Hosts 4.4 Million eBooks, Sees 15 Million eBooks Downloaded Each Month" . The Digital Reader. http://www.the-digital-reader.com/2013/07/09/internet-archive-now-hosts-4-4-million-ebooks-sees-15-million-ebooks-downloaded-each-month/
- Kahle, Brewster (May 23, 2008). "Books Scanning to be Publicly Funded" . Internet Archive Forums. https://archive.org/iathreads/post-view.php?id=194217
- "Bulk Access to OCR for 1 Million Books" . Open Library Blog. November 24, 2008. http://blog.openlibrary.org/2008/11/24/bulk-access-to-ocr-for-1-million-books/
- "Book search winding down". MSDN Live Search Blog. May 23, 2008. http://blogs.msdn.com/livesearch/archive/2008/05/23/book-search-winding-down.aspx.
- "Google Books at Internet Archive" . Internet Archive. https://archive.org/details/googlebooks
- "List of Google scans" (search). Internet Archive. https://archive.org/search.php?query=sponsor%3A%28Google%29
- Books imported from Google have a metadata tag of scanner:google for searching purposes. The archive provides a link to Google for PDF copies, but also maintains a local PDF copy, which is viewable under the "All Files: HTTPS" link. As all the other books in the collection, they also provide OCR text and images in open formats, particularly DjVu, which Google Books doesn't offer.
- Brewster Kahle, Aaron Swartz memorial at the Internet Archive , 2013-01-24, via The well-prepared mind , via S.I.Lex . https://wellpreparedmind.wordpress.com/2013/02/07/aaron-swartz-freed-over-900000-public-domain-books-from-googles-restrictions/
- "Internet Archive BookReader". https://archive.org/details/BookReader.
- Kaplan, Jeff (December 10, 2010). "New BookReader!". https://blog.archive.org/2010/12/10/2685/.
- "Internet Archive Search". https://archive.org/search.php?query=mediatype%3A%28texts%29.
- "Internet Archive Search : (language:eng OR language:"English")". Internet Archive. https://archive.org/search.php?query=(language:eng%20OR%20language:%22English%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:fre OR language:"French")". Internet Archive. https://archive.org/search.php?query=(language:fre%20OR%20language:%22French%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:ger OR language:"German")". Internet Archive. https://archive.org/search.php?query=(language:ger%20OR%20language:%22German%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:spa OR language:"Spanish")". Internet Archive. https://archive.org/search.php?query=(language:spa%20OR%20language:%22Spanish%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:Chinese OR language:"chi") AND mediatype:texts". Internet Archive. https://archive.org/search.php?query=(language:Chinese%20OR%20language:%22chi%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:ara OR language:"Arabic")". Internet Archive. https://archive.org/search.php?query=(language:ara%20OR%20language:%22Arabic%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:Dutch OR language:"dut") AND mediatype:texts". Internet Archive. https://archive.org/search.php?query=(language:Dutch%20OR%20language:%22dut%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:Portuguese OR language:"por") AND mediatype:texts". Internet Archive. https://archive.org/search.php?query=(language:Portuguese%20OR%20language:%22por%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:rus OR language:"Russian") AND mediatype:texts". Internet Archive. https://archive.org/search.php?query=(language:rus%20OR%20language:%22Russian%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:urd OR language:"Urdu") AND mediatype:texts". Internet Archive. https://archive.org/search.php?query=(language:urd%20OR%20language:%22Urdu%22)%20AND%20mediatype:texts.
- "Internet Archive Search : (language:Japanese OR language:"jpn") AND mediatype:texts". Internet Archive. https://archive.org/search.php?query=(language:Japanese%20OR%20language:%22jpn%22)%20AND%20mediatype:texts.
- "Internet Archive Search : mediatype:texts AND date:[1800-01-01 TO 1809-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1800-01-01%20TO%201809-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1810-01-01 TO 1819-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1810-01-01%20TO%201819-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1820-01-01 TO 1829-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1820-01-01%20TO%201829-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1830-01-01 TO 1839-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1830-01-01%20TO%201839-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1840-01-01 TO 1849-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1840-01-01%20TO%201849-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1850-01-01 TO 1859-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1850-01-01%20TO%201859-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1860-01-01 TO 1869-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1860-01-01%20TO%201869-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1870-01-01 TO 1879-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1870-01-01%20TO%201879-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1880-01-01 TO 1889-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1880-01-01%20TO%201889-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1890-01-01 TO 1899-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1890-01-01%20TO%201899-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1900-01-01 TO 1909-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1900-01-01%20TO%201909-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1910-01-01 TO 1919-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1910-01-01%20TO%201919-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1920-01-01 TO 1929-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1920-01-01%20TO%201929-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1930-01-01 TO 1939-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1930-01-01%20TO%201939-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1940-01-01 TO 1949-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1940-01-01%20TO%201949-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1950-01-01 TO 1959-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1950-01-01%20TO%201959-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1960-01-01 TO 1969-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1960-01-01%20TO%201969-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1970-01-01 TO 1979-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1970-01-01%20TO%201979-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1980-01-01 TO 1989-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1980-01-01%20TO%201989-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[1990-01-01 TO 1999-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B1990-01-01%20TO%201999-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[2000-01-01 TO 2009-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B2000-01-01%20TO%202009-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[2010-01-01 TO 2019-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B2010-01-01%20TO%2019-12-31%5D.
- "Internet Archive Search : mediatype:texts AND date:[2020-01-01 TO 2029-12-31"]. Internet Archive. https://archive.org/search.php?query=mediatype%3A%28texts%29%20AND%20date%3A%5B2020-01-01%20TO%2029-12-31%5D.
- "FAQ on Controlled Digital Lending (CDL)". National Writers Union. February 13, 2019. https://nwu.org/book-division/cdl/faq/.
- Gonsalves, Antone (December 20, 2006). "Internet Archive Claims Progress Against Google Library Initiative". InformationWeek. http://www.informationweek.com/story/showArticle.jhtml?articleID=196701339.
- "The Open Library Makes Its Online Debut". The Wired Campus (Chronicle of Higher Education). July 19, 2007. http://chronicle.com/wiredcampus/index.php?id=2235?=atwc.
- "Search Inside" (feature). OpenLibrary.org. https://openlibrary.org/search/inside
- Internet Archive (June 25, 2011). "In-Library eBook Lending Program Expands to 1,000 Libraries" . Internet Archive Blogs. June 25, 2011. https://blog.archive.org/2011/06/25/in-library-ebook-lending-program-expands-to-1000-libraries/
- Flood, Alison (22 Jan 2019). "Internet Archive's ebook loans face UK copyright challenge". The Guardian. https://www.theguardian.com/books/2019/jan/22/internet-archives-ebook-loans-face-uk-copyright-challenge.
- Brandom, Russell (June 1, 2020). "Publishers sue Internet Archive over Open Library ebook lending". The Verge. https://www.theverge.com/2020/6/1/21277036/internet-archive-publishers-lawsuit-open-library-ebook-lending.
- For example, the Princeton Theological Seminary Library has described how it and other academic libraries are digitization partners with the Internet Archive: "Partnering with the Internet Archive". https://library.ptsem.edu/partnering-with-the-internet-archive.
- "Internet Archive Search: collection:(texts)". https://archive.org/search.php?query=collection%3A%28texts%29+AND+mediatype%3A%28collection%29&sort=-downloads.
- "The MIT Press". https://archive.org/details/mitpress.
- Hanamura, Wendy (May 30, 2017). "MIT Press Classics Available Soon at Archive.org". https://blog.archive.org/2017/05/30/mit-press-classics-available-soon-at-archive-org/. "For more than eighty years, MIT Press has been publishing acclaimed titles in science, technology, art and architecture. Now, thanks to a new partnership between the Internet Archive and MIT Press, readers will be able to borrow these classics online for the first time."
- Green, Alex (December 1, 2019). "New Takes on Academic Publishing: Three university presses find new ways to keep up with a changing market". https://www.publishersweekly.com/pw/by-topic/industry-news/publisher-news/article/81872-new-takes-on-academic-publishing.html. "Since she became director [of the MIT Press] in 2015, there's little that Brand hasn't reenvisioned at the press. In 2017, the press partnered with the Internet Archive to make its deep backlist available for free at libraries, resurrecting books that had not seen the light of day in generations."
- Freeland, Chris (May 21, 2018). "Internet Archive awarded grant from Arcadia Fund to digitize university press collections". https://blog.archive.org/2018/05/21/internet-archive-awarded-grant-from-arcadia-fund-to-digitize-university-press-collections/. "Internet Archive has received a $1 million dollar grant from Arcadia – a charitable fund of Lisbet Rausing and Peter Baldwin – to digitize titles from university press collections to make them available via controlled digital lending."
- Albanese, Andrew (May 25, 2018). "Internet Archive Lands Grant to Digitize and Lend University Press Collections". https://www.publishersweekly.com/pw/by-topic/industry-news/libraries/article/76974-is-it-time-to-rethink-how-we-do-library-advocacy.html.
- For example: "hdl.loc.gov/loc.gdc/scd0001.00198115083". https://hdl.loc.gov/loc.gdc/scd0001.00198115083. ; "hdl.loc.gov/loc.gdc/scd0001.00060921933". https://hdl.loc.gov/loc.gdc/scd0001.00060921933. ; "hdl.loc.gov/loc.gdc/scd0001.00060927248". https://hdl.loc.gov/loc.gdc/scd0001.00060927248. ; "hdl.loc.gov/loc.gdc/scd0001.00001740908". https://hdl.loc.gov/loc.gdc/scd0001.00001740908. ; "hdl.loc.gov/loc.gdc/scd0001.00027740005". https://hdl.loc.gov/loc.gdc/scd0001.00027740005. .
- "External Web Sites – Finding E-books: A Guide – Library of Congress Bibliographies, Research Guides, and Finding Aids (Virtual Programs & Services, Library of Congress)". https://www.loc.gov/rr/program/bib/ebooks/external.html. "The Internet Archive includes the full text of more than 2.5 million e-books, including e-books supplied by the Library of Congress. Books can be read online or downloaded and read in a variety of formats. E-books from the Internet Archive can also be found through Open Library, an Internet Archive initiative devoted to texts." And: "Devices and Formats – Finding E-books: A Guide – Library of Congress Bibliographies, Research Guides, and Finding Aids (Virtual Programs & Services, Library of Congress)". https://www.loc.gov/rr/program/bib/ebooks/devicesformats.html. "Library of Congress publications are available for free download to the Kindle from the Internet Archive. ... The iPad can be used as an e-reader via apps such as iBooks, which support both ePub (.epub) and PDF (.pdf) formats. Both formats are available from the Internet Archive."
- "Welcome to Audio Archive" . Internet Archive. https://archive.org/details/audio
- Pritchard, Will (August 18, 2017). "How The Great 78 Project is saving half a million songs from obscurity". https://thevinylfactory.com/features/great-78-project-archive-interview/.
- Tirpack, Alex (June 3, 2009). "Warren Zevon live shows hit the web, possible film in the works". Rolling Stone. https://www.rollingstone.com/music/news/warren-zevon-live-shows-hit-the-web-possible-film-in-the-works-20090603.
- "Welcome to Netlabels" . Internet Archive. https://archive.org/details/netlabels
- Boswell, Wendy (October 21, 2006). "Download free music at the Internet Archive". Lifehacker. http://lifehacker.com/208221/download-free-music-at-the-internet-archive. "The Internet Archive has a ginormous collection of free, downloadable music in their NetLabels category ..."
- "Image". Internet Archive. https://archive.org/details/image.
- "Cover Art Archive: Free Image : Download & Streaming : Internet Archive". Internet Archive. https://archive.org/details/coverartarchive.
- "Metropolitan Museum of Art – Gallery Images: Free Image : Download & Streaming : Internet Archive". Internet Archive. https://archive.org/details/metropolitanmuseumofart-gallery.
- "NASA Images". Internet Archive. http://nasaimages.org/.
- "Occupy Wall Street Flickr Archive: Free Image : Download & Streaming : Internet Archive". Internet Archive. https://archive.org/details/flickr-ows.
- "USGS Maps: Free Image : Download & Streaming : Internet Archive". Internet Archive. https://archive.org/details/maps_usgs.
- "Mathematics – Hamid Naderi Yeganeh (Image): Free Image : Download & Streaming : Internet Archive". Internet Archive. https://archive.org/details/mathematicsimage.
- "Welcome to Machinima" . Internet Archive. https://archive.org/details/machinima
- "Internet Archive Search: collection:microfilm". Internet Archive. https://archive.org/search.php?query=collection%3Amicrofilm%20AND%20collection%3Aadditional_collections.
- "Microfilm". Internet Archive. https://archive.org/details/microfilm.
- "Internet Archive Search: Collection: Feature Films". Internet Archive. https://archive.org/search.php?query=collection%3Afeature_films&sort=-%2Fadditional%2Fitem%2Fdownloads.
- "FedFlix". Internet Archive. https://archive.org/details=FedFlix.
- "September 11th Television Archive" . Internet Archive. https://archive.org/details/sept_11_tv_archive
- "Download & Streaming : Open Educational Resources : Internet Archive". Internet Archive. https://archive.org/details/education.
- "TV NEWS : Search Captions. Borrow Broadcasts : TV Archive : Internet Archive". Internet Archive. https://archive.org/details/tv/.
- Fowler, Geoffrey A.; Hagey, Keach (September 18, 2012). "Let's Go to the Videotape: Nonprofit Offers News Clips". The Wall Street Journal Online. https://www.wsj.com/articles/SB10000872396390443720204578002592487339454. (Subscription content?)
- Kahle, Brewster (September 17, 2012). "Launch of TV News Search & Borrow with 350,000 Broadcasts". Internet Archive Blogs. https://blog.archive.org/2012/09/17/launch-of-tv-news-search-borrow-with-350000-broadcasts.
- Brownell, Brett; Benjy Hansen-Brandy (May 22, 2014). "Meet the People Behind the Wayback Machine, One of Our Favorite Things About the Internet". Mother Jones. https://www.motherjones.com/media/2014/05/internet-archive-wayback-machine-brewster-kahle.
- "Brooklyn Museum: Free Image : Download & Streaming : Internet Archive". Internet Archive. https://archive.org/details/brooklynmuseum.
- "Column: Lillian Michelson and her one-of-a-kind film library get a digital Hollywood ending". January 28, 2021. https://www.latimes.com/entertainment-arts/movies/story/2021-01-28/hollywood-history-lillian-michelson-digital-internet-archive.
- "Internet Archive founder turns to new information storage device – the book". The Guardian. August 1, 2011. https://www.theguardian.com/books/2011/aug/01/internet-archive-books-brewster-kahle. "Brewster Kahle, the man behind a project to file every webpage, now wants to gather one copy of every published book"
- "The Internet Archive Classic Software Preservation Project". Internet Archive. https://archive.org/details/clasp.
- "Internet Archive Gets DMCA Exemption To Help Archive Vintage Software". https://archive.org/about/dmca.php.
- Library of Congress Copyright Office (November 27, 2006). "Exemption to Prohibition on Circumvention of Copyright Protection Systems for Access Control Technologies". Federal Register 71 (227): 68472–68480. http://www.copyright.gov/fedreg/2006/71fr68472.html. Retrieved October 21, 2007. "Computer programs and video games distributed in formats that have become obsolete and that require the original media or hardware as a condition of access, when circumvention is accomplished for the purpose of preservation or archival reproduction of published digital works by a library or archive. A format shall be considered obsolete if the machine or system necessary to render perceptible a work stored in that format is no longer manufactured or is no longer reasonably available in the commercial marketplace.".
- Library of Congress Copyright Office (October 28, 2009). "Exemption to Prohibition on Circumvention of Copyright Protection Systems for Access Control Technologies". Federal Register 27 (206): 55137–55139. http://www.copyright.gov/fedreg/2009/74fr55138.pdf. Retrieved December 17, 2009.
- Library of Congress Copyright Office (July 27, 2010). "Exemption to Prohibition on Circumvention of Copyright Protection Systems for Access Control Technologies". Federal Register 75 (143): 43825–43839. https://www.federalregister.gov/articles/2010/07/27/2010-18339/exemption-to-prohibition-on-circumvention-of-copyright-protection-systems-for-access-control.
- Robertson, Adi (October 25, 2013). "The Internet Archive puts Atari games and obsolete software directly in your browser". https://www.theverge.com/2013/10/25/5028974/internet-archives-new-historic-software-collection.
- Ohlheiser, Abby (January 5, 2015). "You can now play nearly 2,400 MS-DOS video games in your browser". Washington Post. https://www.washingtonpost.com/blogs/the-switch/wp/2015/01/05/you-can-now-play-nearly-2400-ms-dos-video-games-in-your-browser/.
- Each New Boot a Miracle by Jason Scott (December 23, 2014) http://ascii.textfiles.com/archives/4471
- collection:softwarelibrary_msdos in the Internet Archive (December 29, 2014) https://archive.org/search.php?query=collection%3Asoftwarelibrary_msdos&page=1
- Graft, Kris (March 5, 2015). "Saving video game history begins right now". http://gamasutra.com/view/news/238156/Saving_video_game_history_begins_right_now.php.
- "Internet Archive's Terms of Use, Privacy Policy, and Copyright Policy". December 31, 2014. https://archive.org/about/terms.php. "Access to the Archive's Collections is provided at no cost to you and is granted for scholarship and research purposes only."
- Lu, Kathy (January 12, 2015). "Time suck alert: 'Pac-Man' among thousands of MS-DOS games available for free". The Kansas City Star. http://www.kansascity.com/entertainment/article6061104.html.
- O'Neil, Lauren (January 7, 2015). "90's kids rejoice as Internet Archive releases 2,300 MS-DOS games for free – Your Community". CBCNEWS. http://www.cbc.ca/newsblogs/yourcommunity/2015/01/90s-kids-rejoice-as-internet-archive-releases-2300-ms-dos-games-for-free.html.
- Campbell, Ian Carlos (November 19, 2020). "The Internet Archive is now preserving Flash games and animations". The Verge. https://www.theverge.com/2020/11/19/21578616/internet-archive-preservation-flash-animations-games-adobe.
- "Table Top Scribe System". https://archive.org/details/tabletopscribesystem.
- Stutz, Michael (March 28, 2007). "Linux to help the Library of Congress save American history". The Linux foundation. https://www.linux.com/news/linux-help-library-congress-save-american-history.
- Strozniak, Peter (December 18, 2015). "Death of a Credit Union: Internet Archive FCU Voluntarily Liquidates". Credit Union Times. https://www.cutimes.com/2015/12/18/death-of-a-credit-union-internet-archive-fcu-volun/.
- "Difficult Times at our Credit Union". November 24, 2015. https://blog.archive.org/2015/11/24/difficult-times-at-our-credit-union/.
- Leeds, Jeff; Mayshark, Jesse Fox (December 1, 2005). "Wrath of Deadheads stalls a Web crackdown". The New York Times. https://www.nytimes.com/2005/12/01/technology/01iht-deadheads.html.
- Lesh, Phil (November 30, 2005). "An Announcement from Phil Lesh". Hotline. PhilLesh.net. http://www.phillesh.net/philzonepages/friends_stuff/hotline-051130.html.
- Kahle, Brewster; Vernon, Matt (December 1, 2005). "Good News and an Apology: GD on the Internet Archive". Live Music Archive Forum. Internet Archive. https://archive.org/post/49553/good-news-and-an-apology-gd-on-the-internet-archive. Authors and date indicate the first posting in the forum thread.
- Broache, Anne (May 7, 2008). "FBI rescinds secret order for Internet Archive records". CNet. http://www.news.com/8301-10784_3-9938603-7.html.
- Nakashima, Ellen (May 8, 2008). "FBI Backs Off From Secret Order for Data After Lawsuit". The Washington Post. https://www.washingtonpost.com/wp-dyn/content/article/2008/05/07/AR2008050703808.html.
- Crocker, Andrew (December 1, 2016). "Internet Archive Received National Security Letter with FBI Misinformation about Challenging Gag Order". Electronic Frontier Foundation. https://www.eff.org/press/releases/internet-archive-received-national-security-letter-fbi-misinformation-about.
- Kahle, Brewster (January 17, 2012). "12 Hours Dark: Internet Archive vs. Censorship". Internet Archive Blogs. https://blog.archive.org/2012/01/17/12-hours-dark-internet-archive-vs-censorship/.
- "Open Content Alliance". opencontentalliance.org. http://www.opencontentalliance.org/.
- Frank, Allegra (August 8, 2016). "Nintendo takes down Nintendo Power collection from Internet Archive after noticing it". http://www.polygon.com/2016/8/8/12405278/nintendo-power-issues-disappear-from-free-online-archive.
- "Indian ISP Ban on Wayback Machine Lifted? Confirmation Awaited". Guiding Tech. 9 August 2017. https://www.guidingtech.com/70862/wayback-machine-ban-india-internet-archive/.
- Kelion, Leo (August 9, 2017). "Bollywood blocks the Internet Archive". BBC. https://www.bbc.com/news/technology-40875528.
- "Turkey restores access to Google Drive after blocking cloud storage services". http://www.hurriyetdailynews.com/turkey-restores-access-to-google-drive-after-blocking-cloud-storage-services.aspx?pageID=238&nID=104784&NewsCatID=339.
- "Turkey Country Report | Freedom on the Net 2017". November 14, 2017. https://freedomhouse.org/report/freedom-net/2017/turkey.
- Lee, Timothy B. (2020-03-28). "Internet Archive offers 1.4 million copyrighted books for free online" (in en-us). https://arstechnica.com/tech-policy/2020/03/internet-archive-offers-thousands-of-copyrighted-books-for-free-online/.
- Freeland, Chris (2020-03-30). "Internet Archive responds: Why we released the National Emergency Library" (in en-US). https://blog.archive.org/2020/03/30/internet-archive-responds-why-we-released-the-national-emergency-library/.
- Cohen, Noam (April 20, 2020). "The National Emergency Library and Its Discontents". Wired. https://www.wired.com/story/the-national-emergency-library-and-its-discontents/.
- Flood, Alison (2020-03-30). "Internet Archive accused of using Covid-19 as 'an excuse for piracy'" (in en-GB). https://www.theguardian.com/books/2020/mar/30/internet-archive-accused-of-using-covid-19-as-an-excuse-for-piracy.
- Freeland, Chris (2020-03-24). "Announcing a National Emergency Library to Provide Digitized Books to Students and the Public" (in en-US). http://blog.archive.org/2020/03/24/announcing-a-national-emergency-library-to-provide-digitized-books-to-students-and-the-public/.
- Hurst-Wahl, Jill (2020-04-20). "Digitization 101: The National Emergency Library". http://hurstassociates.blogspot.com/2020/04/the-national-emergency-library.html.
- HAMPTON, RACHELLE. "The Internet Archive Started an "Emergency" Online Library. Authors Are Furious.". https://slate.com/culture/2020/04/internet-archive-national-emergency-library-controversy.html.
- Flood, Alison (March 30, 2020). "Internet Archive accused of using Covid-19 as 'an excuse for piracy'". The Guardian. https://www.theguardian.com/books/2020/mar/30/internet-archive-accused-of-using-covid-19-as-an-excuse-for-piracy.
- Dwyer, Colin (March 30, 2020). "Authors, Publishers Condemn The 'National Emergency Library' As 'Piracy'". NPR. https://www.npr.org/2020/03/30/823797545/authors-publishers-condemn-the-national-emergency-library-as-piracy.
- Grady, Constance (April 2, 2020). "Why authors are so angry about the Internet Archive's Emergency Library". Vox. https://www.vox.com/culture/2020/4/2/21201193/emergency-library-internet-archive-controversy-coronavirus-pandemic.
- "Internet Archive Controversy". Lotus. 2 May 2020. https://locusmag.com/2020/05/internet-archive-controversy/.
- Lee, Timothy (June 11, 2020). "Internet Archive ends "emergency library" early to appease publishers". Ars Technica. https://arstechnica.com/tech-policy/2020/06/internet-archive-ends-emergency-library-early-to-appease-publishers/.
- Dwyer, Colin (3 June 2020). "Publishers Sue Internet Archive For 'Mass Copyright Infringement'". NPR. https://www.npr.org/2020/06/03/868861704/publishers-sue-internet-archive-for-mass-copyright-infringement.
- "Copyright Alliance Statement on Book Publishers' Infringement Suit Against Internet Archive". https://copyrightalliance.org/news-events/press-releases/june-1-2020/.
- Harris, Elizabeth (11 June 2020). "Internet Archive Will End Its Program for Free E-Books". NY Times. https://www.nytimes.com/2020/06/11/books/internet-archive-national-emergency-library-coronavirus.html.
- Albanese, Andrew (September 1, 2020). "Judge sets tentative schedule for Internet Archive copyright case". https://www.publishersweekly.com/pw/by-topic/digital/copyright/article/84239-judge-sets-tentative-schedule-for-internet-archive-copyright-case.html.
- Ojala, Marydee (January–February 2021). "Controlled digital lending: legal lending or piracy?". Online Searcher 45 (1). https://www.infotoday.com/OnlineSearcher/Articles/Features/Controlled-Digital-Lending-Legal-Lending-or-Piracy-144995.shtml. Retrieved February 18, 2021.
- Albanese, Andrew (December 11, 2020). "The top 10 library stories of 2020". https://www.publishersweekly.com/pw/by-topic/industry-news/libraries/article/85122-the-top-10-library-stories-of-2020.html.
- Panezi, Argyri (28 Mar 2021). "A public service role for digital libraries: the unequal battle against (online) misinformation through copyright law reform and the emergency electronic access to library material". Forthcoming, 31 CORNELL J.L. & PUB. Pol'y (2021). https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3813320. Retrieved 30 July 2021.
- Holt, Kris (7 October 2021). "The Internet Archive's 'Wayforward Machine' paints a grim future for the web". Engadget. https://www.engadget.com/internet-archive-wayforward-machine-web-future-wayback-175936050.html.
- "Imagine the future of the Internet". https://wayforward.archive.org/ia2046/.
- Levy, Karyne (April 29, 2014). "These Are The Ceramic Action Figures For The Heroes Of The Internet". Business Insider (Insider Inc.). https://www.businessinsider.com/the-internet-archives-100-ceramic-statues-2014-4?IR=T.
- "Internet Archive is a treasure trove of material for artists - SFChronicle.com" (in en-US). August 11, 2017. https://www.sfchronicle.com/news/article/Internet-Archive-is-a-treasure-trove-of-material-11751319.php.
- "The Internet Archive's 2019 Artists in Residency Exhibition | Internet Archive Blogs" (in en-US). https://blog.archive.org/2019/06/22/the-internet-archives-2019-artist-in-residency-exhibition/.