Surface transportation has evolved through technology advancements using parallel knowledge areas such as machine learning (ML). ML is the most sophisticated state-of-the-art knowledge branch offering the potential to solve unsettled or difficult-to-solve problems as a data-driven approach. The primary objective of this research is to find the root cause of the slowdown in applying ML to surface transportation systems (STSs) compared to parallel sectors such as health care. The ultimate goal is to identify the prospects, gaps, and means by which ML techniques can be used to help improve safety, mobility, accessibility, level of service, efficiency, security, comfort, quality, cost, integrity, and sustainability in society’s STSs.
1. Machine Learning
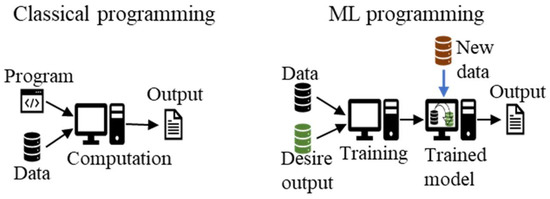
Machine learning is an evolving field that has impacted many applied sciences, including healthcare [
18], the automotive industry [
19], cybersecurity [
20], and robotics [
21,
22]. Unlike classical programming, ML data processing is modeled in advance (
Figure 2). Numerous ML publications cover various applications, algorithms, fundamentals, and theories [
23,
24,
25,
26,
27,
28,
29,
30]. Machine learning is the knowledge of applying data and techniques to imitate human learning competence patterns and behaviors. In their basic form, ML algorithms receive input data, analyze them, and provide output data by learning any perceived patterns and behavior inherent to the data. These algorithms typically apply a set of data, treat it as prior knowledge, train themselves, and search for similar patterns and ingrained behavior in the new data. Access to a large amount of prior knowledge would improve the efficiency of the learning experience.
Figure 2. ML versus analytical approach in programming.
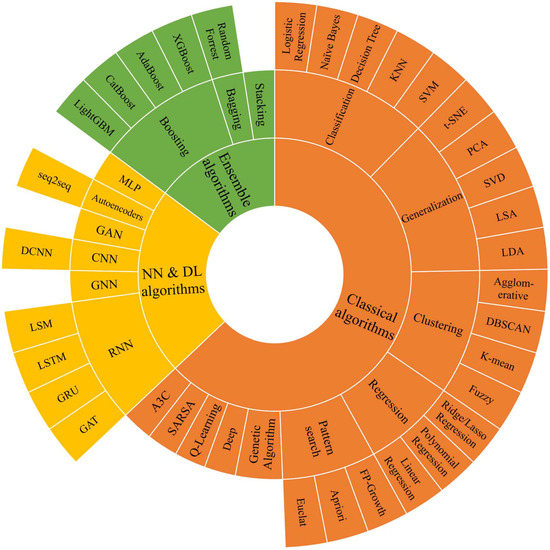
As data-driven tools, ML algorithms learn from input data that contain correct results or functions. Several approaches exist for implementing this simple concept, depending on how the algorithm uses the input data and maintains the existing hyperparameters. These algorithms are organized into three primary categories: (1) classical algorithms, (2) neural network and deep learning algorithms, and (3) ensemble algorithms, as presented in Figure 3 and described below.
Figure 3. ML algorithms’ categories.
1.1. Classical Algorithms
Classical algorithms can be from supervised, unsupervised, or reinforcement learning algorithms. In the supervised learning algorithm, the input dataset includes both the input and desired output data. The algorithm is trained on how the input data are related to the output data. The supervised learning algorithms can be used for regression to predict a continuously variable output or classification to predict predefined classes or groups. The classification models are used for the prediction of the discrete variables. Logistic regression, naive Bayes (NB), supporting vector machine (SVM), decision trees, and k-nearest neighbor (KNN) represent the most popular ML models for supervised learning algorithm classification.
Additionally, popular supervised regression ML algorithms include linear, polynomial, and ridge/lasso regression. The output data in the unsupervised learning algorithm are not fed into the model. Instead, the model only looks at the input data, organizes them based on internally recognized patterns, and clusters them into structured groups. Subsequently, the trained model can predict the appropriate group to which the new input data belong.
The reinforcement learning algorithm is a reward-based algorithm. The algorithm is fed by an environment with predefined rewarding actions. Each action corresponds to a specific reward. The algorithm then experiences the action in that environment and based on the bonuses, learns how to deal with the input data, movement, and maximization of the total compensation. A reinforcement learning algorithm is a form of trial and error that learns from past experiences and adapts to the knowledge to achieve the best conceivable outcome.
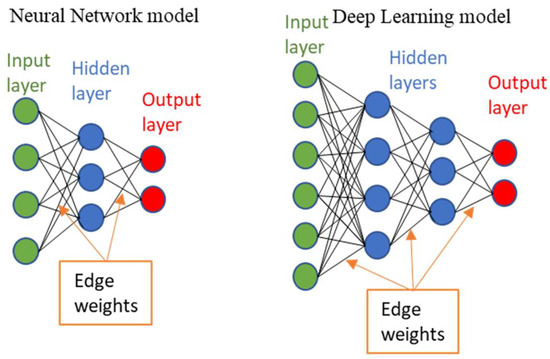
1.2. Neural Networks and Deep Learning Algorithms
Inspired by the human brain’s neural structure, the NN and DL algorithms are based on multi-layered perceptrons. These algorithms contain an input layer, an output layer, and some hidden layers consisting of neurons or perceptrons. These layers are connected through weighted edges, and the training process is based on backpropagation. The input can be any real-world digitized data, such as an image, voice, or text. The input data establish proper edge weights and perceptron activation to improve the output accuracy by matching trained data. Neural network learning algorithms include supervised, unsupervised, reinforcement, clustering, regression, and classification strategies. The only difference between the NN and DL is the number of hidden layers (Figure 4). A DL algorithm can contain several hidden layers, each of which helps to extract a specific feature from the input data.
Figure 4. Neural network and deep learning model format.
Recurrent neural networks are special NNs that allow the model to receive a series as input and another as output. This type of NN is suitable for time-series prediction. Feedforward neural networks (FNNs) send the data in one direction from input to output. Additionally, RNNs have an internal circular structure (loop feedback) in which the output data of one layer can be fed into the same layer again as feedback. Therefore, the output at state t depends on the input data at state t and the network status at state t-1. This property makes RNNs suitable for temporal prediction. Convolutional neural networks (CNNs), another category of NNs, can extract features from a multidimensional graph. These networks apply several convolutional and pooling layers to extract the input graph features. This capability makes CNNs suitable for image and video recognition.
1.3. Ensemble Algorithms
Ensemble algorithms, or multiple learning classifier algorithms, combine numerous learning algorithms to solve a single problem. Ensemble algorithms train several individual ML algorithms and then combine the results by applying specific strategies to improve the accuracy. Homogeneous ensemble learners employ the same ML algorithms (weak classifiers), whereas the heterogeneous ensemble algorithms contain various learners’ algorithm types. As a result, the heterogeneous ensemble is more substantial than the homogeneous ensemble in generalization.
The boosting algorithm, a subcategory of the ensemble ML algorithm, tries to make a robust classifier from some weak classifiers. The algorithm groups input data using several classifiers and strategies to accomplish the best outcome. In this category, well-known algorithms include adaptive boosting (AdaBoost); categorical gradient boosting (CatBoost); light gradient boosted machine (LightGBN); and scalable, portable, and distributed gradient boosting (XGBoost).
The Bagging algorithm is another subcategory that feeds the ensemble learners with a separate pack of the input data to help the weak learner-trained models be independent of each other. Bagging is referred to as the input data class sampling. Random forest (RF) is a well-known classification and regression algorithm based on building several decision trees in the training process. The final result would be the most selected or average of the decision trees’ conclusions. Finally, in the stacking subcategory, the primary ensemble learners use the original training set and generate a new dataset for training in second-level models.
2. Surface Transportation Systems
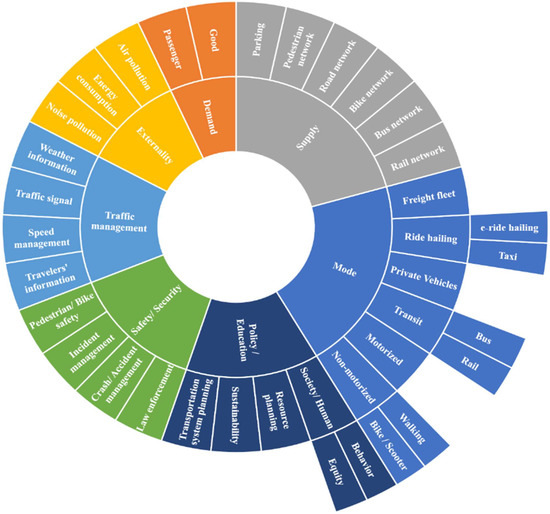
The surface transportation component ecosystem’s entire dynamic is illustrated in Figure 5. The top categories include mode, policy/education, safety/security, traffic management, externality, demand, and supply. Each STS subcategory, independently or in combination with others, has been considered according to interdisciplinary knowledge and technology application areas for performance improvement.
Figure 5. STS ecosystem component dynamics.
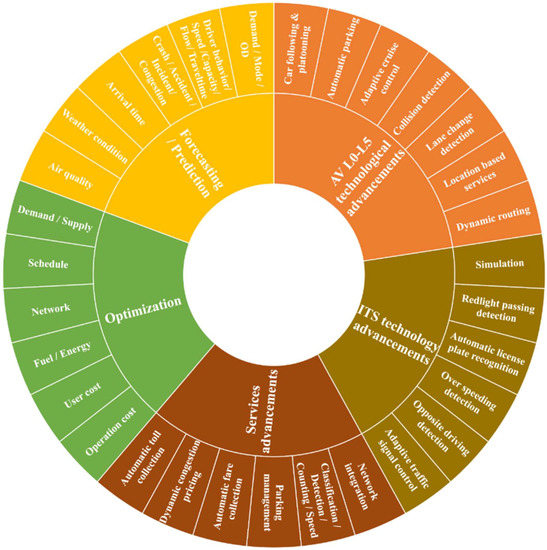
These knowledge and technology areas have addressed mobility challenges and problems from various approaches to make specific advancements. Figure 6 presents multiple aspects of advancements and their subcategories impacting STSs. For instance, autonomous vehicle (AV) research and development by technology providers and academic research have resulted in advanced technologies and enhancements for drivers and the automobile industry. Technologies and enhancements include automated parking technology, car-following and platooning technologies, adaptive cruise control, collision detection warning, lane change warning and maintenance systems, location-based and navigation systems, and dynamic routing services. Intelligent transportation systems, as a multidisciplinary knowledge area, have likewise produced some significant accomplishments during the past three decades (i.e., adaptive traffic signal control, opposite direction driving detection, over-speeding detection, automatic license plate recognition systems, red-light surveillance sensors, and traffic simulations). Each subcategory has fulfilled or improved one or more surface transportation components. For instance, weather condition forecasting improves “weather information” in the “traffic management” component of the STSs.
Figure 6. Application areas in STSs.
This entry is adapted from the peer-reviewed paper 10.3390/app12189156