Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Parkinson’s disease (PD) is a neurodegenerative disease that affects the neural, behavioral, and physiological systems of the brain. This disease is also known as tremor. The common symptoms of this disease are a slowness of movement known as ‘bradykinesia’, loss of automatic movements, speech/writing changes, and difficulty with walking at early stages. To solve these issues and to enhance the diagnostic process of PD, machine learning (ML) algorithms have been implemented for the categorization of subjective disease and healthy controls (HC) with comparable medical appearances.
- Parkinson’s disease
- machine learning
- artificial neural network
- logistic regression
- support vector machine
- classification
1. Parkinson’s Disease: Background
PD is a dynamic sensory system problem that influences the development of an individual. Symptoms of PD start gradually and may begin with a hardly detectable tremor [1]. Tremors are common; however, disorders are often accompanied by rigorousness or slowed mobility [2]. In the beginning phases of PD, one’s face might show slight or zero expressions, and one’s arms may not swing when walking. Voice might turn out to be slurred or soft [3]. PD symptoms deteriorate as the disease progresses over time. Although there is no cure for PD, meds could alleviate the symptoms. Doctors may recommend a medical procedure to control specific areas of the brain and further alleviate symptoms. According to research, India has 7 million elderly people suffering from PD [4]. Medication and surgery are offered to control the symptoms of this subjective disease [5]. The number of Americans living with this subjective disease is close to one million, which is greater than the total number of persons with Lou Gehrig’s disease and multiple sclerosis. By 2030, this number is expected to reach 1.2 million.
People with PD (PWP) have significant variances in their symptoms, reactions to medicines, and adverse treatment effects. Understanding the genetic variations among Parkinson’s patients might provide crucial hints regarding how and why each person’s experience with PD differs. Although the actual etiology of PD is unknown, scientists predict that a mix of genetic and environmental factors causes it. Each factor’s impact varies depending on the individual. Researchers do not know why some people develop Parkinson’s and others do not. About 10 to 15% of Parkinson’s cases are genetic in nature. In certain families, variations (or mutations) in particular genes are inherited or handed down from generation to generation [6]. The molecular basis of this neurodegenerative disease is still not fully known over two decades after the discovery of the first mutation linked to PD. Initially, research on the genetics of Parkinson’s disease (PD) concentrated on uncommon family variants of the condition; however, six genes—LRRK2, alpha-synuclein, Parkin, VPS35, DJ-1, and PINK1—have now been conclusively linked to either an autosomal dominant or recessive form of the disease. Major advancements in the field have been made with the introduction of genome-wide association studies (GWAS) and the use of new technologies, such as next-generation sequencing (NGS) and exome sequencing. A wave of genetic association studies later implicated a number of genetic variants in the disease pathogenesis/protection [7].
Proteomic biomarkers, ideally a biomarker that is predicted to properly represent a disease process, should be available for investigation in the afflicted tissue, such as in the suffering dopaminergic neurons in the case of PD. One of the biggest challenges to creating causal or disease-modifying medicines for PD is the fact that this is not achievable. The benefits of this strategy are clear, for instance, in contemporary tumor treatment that may be customized based on the specific hormone receptor status of the malignant cells. Proteomic disease-associated modifications must be looked for inaccessible bodily fluids such as blood plasma or CSF, as well as in peripheral tissues, as this technique cannot be used in PD. Although it initially appears unlikely, there are signs that the observed mutations may in fact represent at least some components of the disease process in the brain [8].
In terms of risk factors, although the specific reasons for PD are anonymous, certain cases are frequently caused by natural and other factors that play a significant influence in the progression of the disease. Head traumas, an inadequate diet that includes a large number of pesticides or chemical exposure, and sedentary lifestyles are all risk factors. Figure 1 represents the major symptoms of this disease.
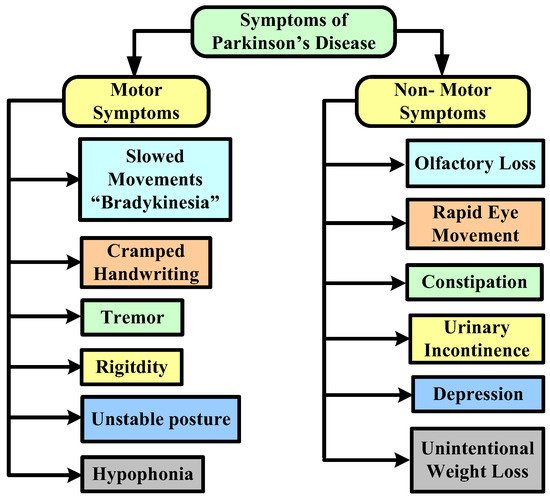
Figure 1. Symptoms of Parkinson’s disease.
Risk factors for PD include age (this disease rarely affects young adults; it typically manifests in middle or later life, and the risk rises with age), hereditary factors (having close relatives who have the disorder increases your probability of having it), sex (men are more likely to get PD than women), and exposure to toxins (ongoing exposure to herbicides and pesticides may slightly increase risk of PD) [9]. Genetic indicators for PD have been used to identify people who have a higher risk of acquiring this disease, to track the disease’s development, and to look at how well treatment prevents the depletion of dopaminergic neurons. Early diagnostic tools for PD include markers including cerebrospinal fluid testing, non-motor clinical signs of PD, and several imaging modalities [10].
2. Machine Learning Techniques Used to Diagnose Parkinson’s Disease
This entry identified the potential to correctly estimate the severity of PD, as measured by clinical metrics, using ML techniques such as SVM, ANN, KNN, naïve Bayes, logistic regression, CART, decision tree, etc. ANN is mostly used in classification and regression problems, where existing nearby features are considered to be relatable. Training datasets and test data are used in the ML algorithm. A technique that gains experience from its previous data and improves itself accordingly is known as ML. It is basically an analysis of algorithms that can generate data automatically. An ML classifier is categorized into two types, supervised and unsupervised. Labeled data fall under supervised, where different approaches of algorithms are used to train models. The categorization of ML algorithms is shown in Figure 2. Artificial Neural Network (ANN) [11] and Multilayer perceptron (MLP) with a back propagation algorithm [12] are also used to diagnose PD.
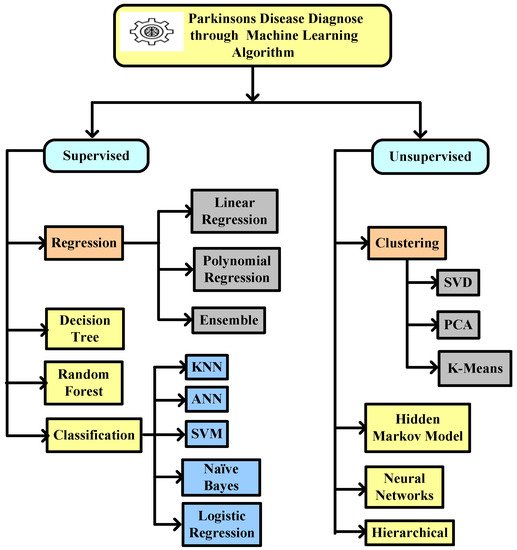
Figure 2. Machine learning algorithm used to diagnose Parkinson’s disease.
The ML-based diagnosis of this subjective disease can be achieved by using symptoms as an attribute for the algorithm. The ML algorithm is used to diagnose the PD severity from the handwriting of an individual [13]. Speech analysis and tremors are also important risk factors used to diagnose PD [14]. Over time, several initiatives have been taken to diagnose PD by various researchers. In [15], the author discussed a unique methodology to discriminate a healthy person from a person with Parkinson’s disease (PWP) by detecting dysphonia. They introduced a new reliable dysphonia test called pitch period entropy (PPE). It is unaffected by a variety of uncontrolled confounding factors such as loud acoustic surroundings and natural, healthy changes in the voice frequency. The dataset was obtained from thirty-one people, where twenty-three were subjective disease patients and eight were healthy, and it contained 195 persistent vowel phonations. The methodology that was used in this research is categorized into three steps: the calculation of feature refinement, the pre-processing and pre-selection of features, and the classification of models. To diagnose the subjective disease, a kernel support vector machine (SVM) classifier was used. By using this algorithm, the model accomplished an accuracy rate of 91.4%.
The main purpose of this [16] research is to differentiate a healthy person from a PWP. In their work, to create a method for diagnosing PD patients using voice disorders, they used a dataset containing 34 persistent vowels, from 34 individuals, where 17 were subjective patients and 17 were healthy. For classification, the SVM technique was used and achieved an accuracy rate of 91.17% by using the first twelve coefficients of the Mel Frequency Cepstral Coefficients (MFCC) by kernel SVM.
To distinguish healthy individuals from subjective diseases, Ref. [17] used a supervised ML algorithm, SVM, for classification purposes. All the data were processed in a tool called weka. Libsvm was used to find the best plausible accuracy on various kernel values for the given dataset. The linear kernel SVM accomplished an accuracy rate of 65.2174%. Similarly, the poly-kernel and RBF kernel accomplished an accuracy rate of 60.8696%.
In [18], the authors discuss a methodology to diagnose PD. Weka tools were used to develop the algorithms for the pre-processing of data, classification methods, clustering, and the analysis of a given dataset. From the experimental results of this research, the accuracy rate achieved from K-nearest neighbor (KNN) + Adaboost.M1 was 91.28%, KNN + Bagging scores 90.76%, and KNN + MLP score 91.28%.
The author proposed a methodology for distinguishing between healthy persons and subjective disease patients. In their research, the data were obtained from 40 individuals where 20 were healthy and 20 were subjective disease patients [19]. A total of 26 speech samples were taken from each individual, including phrases, sentences, words, and numerals. For classification and cross-validation, they used SVM and KNN. The KNN classifier produced an accuracy of 82.50%, whereas the SVM classifier reported an accuracy of 85%.
In [20], the authors examined several voice signal analysis techniques for the diagnosis of this subjective disease. A novel feature termed tunable Q-factor wavelet transform (TQWT) was presented in their work. TQWT excelled in state-of-the-art voice signal computational methods adopted for feature extraction in PD detection. Distinct classifiers were applied to different feature subsets, and the predictions of the classifiers were aggregated using ensemble methods. The best accuracy of the model was reached by MFCCs and TQWT, which are thus key aspects in the problem of PD classification. As a data preparation phase, the minimum redundancy-maximum relevance (mRMR) feature selection approach was applied. In all the feature subsets, Radial Basis Function (RBF) kernel SVM had the greatest accuracy of 86%.
ANN was used by [21] to identify PD. The dataset was obtained from the University of California, Irvine’s machine learning library. 45 attributes were chosen as input values and one outcome for categorization using the MATLAB tool. With an accuracy of 94.93%, their suggested model was able to differentiate healthy individuals from PD subjects.
The author addressed the causes and symptoms of the disease. The severity of this disease and its complications were discussed in their work. Furthermore, their studies established the best detection range for classifying Parkinson’s symptoms [22].
The authors discovered a method for diagnosing PD that included ML and Kalman filtering methods. Tremor activities were applied to detect Parkinson’s symptoms in this method. Sleeping tremors were identified using ML approaches based on local field potentials. The data were obtained from 12 people. The Kalman filter enhanced the attributes of classified results based on the processed data [23].
For evaluating this disease, Ref. [24] examined phonation and acoustic signals. Four distinct ML approaches were used to preprocess and evaluate the data acquired about voice frequencies. Various microphone devices, including smartphones, were used to record the voice signals. For testing the measured accuracy rate and error rate in detection, the voice features acquired using smartphones were loaded into an ML system. The acoustic cardioid (AC) channel had a 94.55% accuracy, a 0.87 area under curve (AUC), and a 19.01% equal error rate (EER). While, by using the smartphone channel, they achieved an accuracy of 92.94%, an AUC of 0.92, and EER of 14.15%, respectively.
Using EEG signals recorded during the completion of verbal fluency tests, Almalaq et al. [25] explored the connections and causality of distinct areas of the brain. Mental demands, such as transitioning between one behavioral task and another, are challenging for those with the subjective disease. Motor and phonemic fluency are among the behavioral tasks. Their approach included verbal generating skills, as well as stimulating several Broca sections of the Brodmann areas (BA44 and BA45).
In [26], the authors presented a neural network (NN) approach for identifying symptoms of the subjective disease using speech data. The algorithm helped to classify symptoms of this disease and balance the data features using the SMOTE algorithm. Furthermore, the techniques of ensemble and Adaboost were used to improve the disease detection rate (accuracy rate). The final AdaBoost ensemble classifier implementation of NNge achieved an accuracy rate of 96.30%.
The authors examined PD subject detection using various ML techniques [27]. They conducted their experiment on both training and test data, where they used 22 acoustic features of 195 sound recordings. To diagnose PD, four machine learning classifiers were used: KNN, SVM, Naive Bayes, and random forest. The Naive Bayes algorithm diagnosed PD patients with 70.26% accuracy and a precision of 0.64 for test data.
In [28], the authors proposed a method to diagnose PD using the selection and extraction of features and pre-processing classification. In their work, for the feature selection task, recursive feature elimination and feature importance methods were used. For classification, various ML algorithms were used, such as SVM, ANN, and Classification and Regression Trees (CART). The accuracy of classification was measured before and after feature selection. Before feature selection, SVM was shown to have 79.98% accuracy, and after selection, it was shown to implement better than that.
The authors proposed a statistical method to detect the subjective disease using voice features including vowels. They used two ML techniques, SVM and KNN, where the accuracy rates obtained were 91.25% and 91.23%, respectively [29].
In [30], the authors suggested a method for evaluating feature sets by comparing performance metrics with various feature sets, such as genetic algorithm-based feature sets and Principal Component Analysis (PCA)-based feature reduction techniques. Using SVM with RBF and genetic algorithm-based feature sets, they were able to achieve an accuracy of 97.57%.
Using L1-norm SVM of feature selection, Ref. [31] suggested a method for identifying PD patients from healthy people by generating a new subset of features from the PD dataset. Their study was validated using the k-fold cross-validation approach. The results of their study’s experiments imply that the suggested approach may be used to reliably forecast the subjective disease and that it can be readily used in healthcare for diagnosis purposes.
According to [32], Linear Discriminant Analysis (LDA) performed better than PCA for distinguishing HC subjects and PD patients; thus, LDA was used as input for the clustering models. The performance of various models was evaluated by comparing the results of the clustering algorithms with the ground truth after a follow-up. In terms of sensitivity, specificity, and accuracy, Hierarchical clustering surpassed DBSCAN and K-means algorithms by 78.13%, 38.89%, and 64%, respectively.
From the above, it was observed that various ML techniques have been applied in recent research works over voice-based PD detection and in handwritten patterns to diagnose PD.
3. Adaptation of the ML Framework
Multiple input variables led to various interpretations. When the input variable is an acoustic voice feature, ML algorithms are preferred to diagnose PD. In the instance of acoustic voice datasets, the primary interpretation for the application of ML was to diagnose the initial signs of PD [33]. In other instances, it was assumed that training models may be quite effective for the early screening of PD because the gold standard was readily available. A particular combination of ML methods, including PCA, was used since the input dataset’s dimensions were reduced. A decision tree or k-mean clustering algorithms are more suitable for analyzing the speech database’s characteristics, and these classifiers may be used to classify voice data for control vs. PD. Due to the fact that the acoustic speech data violated the data in components, it was considered that learning the acoustic speech data using ML techniques such as HMM would be the best approach, which would then be followed by the detection procedure. To determine the risk of PD, a deep CNN classifier using transfer learning and data augmentation approaches can be implemented. Due to the small amount of data, using handwriting data to predict PD presents a significant classification difficulty in the early stages. To achieve high accuracy, the independent usage of the ImageNet and MNIST databases as input sources was utilized.
3.1. Architecture Based on Acoustic Voice Dataset as Input
In [34], the authors proposed a methodology to diagnose PD using stochastic gradient descent (SGD), logistic regression, Extreme Gradient Boosting (XGB), KNN, random forest, and decision tree ML classifier, as shown in Figure 3. In their study, the authors first extracted certain attributes to classify for better understanding. By extracting attributes from the input data, feature extraction improves the accuracy of trained models. By getting rid of the redundant records, this stage decreases the dimensionality of the data. Naturally, it speeds up categorization. By choosing and merging variables into features, it helps acquire the optimum feature from such enormous data sets, while also significantly reducing the volume of data. These characteristics are simple to use while still accurately and uniquely describing the real data set. Secondly, they applied some data mining approaches to classify the HC and affected patients based on various acoustic voice features to predict the accuracy rate. For that, the authors first set the target variables, i.e., the health status of PD patients. Once the target attribute was set, they modified the dataset column that was used as the input after being extracted from the dataset. Finally, the authors made a comparison among all the ML algorithms to check the best accuracy result, which was obtained by a random forest classifier with an accuracy rate of 97.10%, and a minimum accuracy was obtained by SGD and logistic regression, with an accuracy rate of 91.66% for both classifiers.
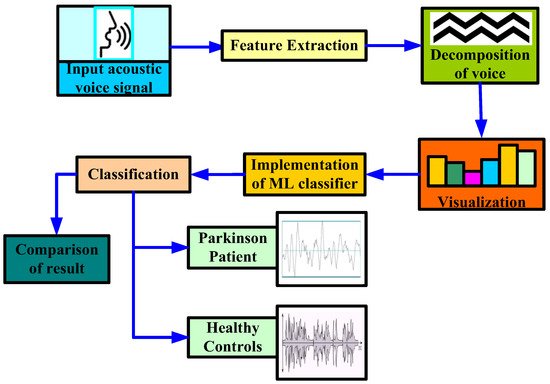
Figure 3. Proposed methodology to diagnose Parkinson’s disease by [34].
3.2. Architecture Based on Handwritten Patterns as Input
A structural Co-occurrence Matrix (SCM)-based technique to diagnose PD as shown in Figure 2 was proposed by [35]. In their research, the features were extracted from the spiral and meander handwriting exams of the Hand PD datasets [36]. Figure 4 represents a methodology with combinations of an exam template (b) and handwritten trace (c). First, the exam segmentation is performed, and it generates two new images: an exam template (b) and a handwritten trace (c). By using digital image processing techniques on a handwritten trace, these images are produced. Secondly, the segmentation of the exam is converted into grayscale for the next level. The third phase is feature extraction from the grayscale images that have been segmented and converted. As shown in Figure 2, these images serve as the SCM’s input images.
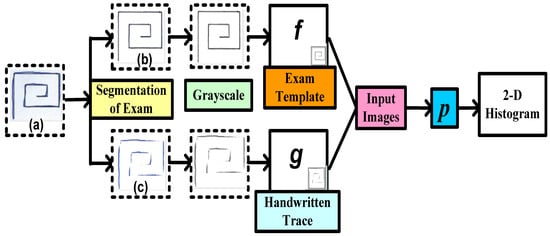
Figure 4. Proposed methodology to diagnose Parkinson’s disease using handwriting in a spiral format by [35].
Analyzing the connection between signals, in this example in a two-dimensional space, is conducted by feature extraction through the SCM.
For this research [35], datasets were collected from 92 individuals, of which 74 were PD patients and 18 were HC. In their proposed work, various algorithms such as SVM, naïve Bayes, and OPF classifiers were applied to the dataset. The highest accuracy was calculated by combining the handwritten trace with the handwriting in a spiral format by using SVM (85.54%).
3.3. Architecture Based on Gait Dataset as Input
A methodology in gait patterns to diagnose PD using ML algorithms was proposed by [37]. According to the authors, gait pattern is very eccentric for each and every human being, but there is a substantial transformation in the gait pattern of HC and PD patients. Table 1 represents the review of ML approaches in gait data to diagnose PD for 18 studies. For this research, the sources of data were the Laboratory for Gait and Neurodynamics, Neurology Outpatient Clinic at Massachusetts General Hospital, Boston, MA, USA, and the University of Michigan and were collected from the participants. The ML algorithms used to diagnose PD for gait symptoms were the least square-SVM, particle swarm optimization, fuzzy KNN, random forest, hidden Markov models, logistic regression, ANN, kernel fisher discriminant, naïve Bayes, linear discriminant analysis, etc. The maximum number of subjects considered in Table 1 is 424, with 156 PD patients and 268 healthy controls, with an accuracy rate of 85.51% using the hidden Markov model algorithm. The minimum number of subjects was 20, with 10 PD patients and 10 healthy controls with an accuracy of 91.9% using a deep convolutional neural network algorithm. For experimental setup, MATLAB R2013b and python were used. It was observed that the maximum accuracy was achieved by using the SVM algorithm with a 100% accuracy rate for the 166 subjects, where 93 were PD patients and 73 were healthy controls. The minimum accuracy was achieved by the random forest algorithm, with a 79.6% accuracy rate for the 80 subjects, where 40 were PD patients and 40 were healthy controls.
Table 1. Comparative studies of machine learning approaches in gait dataset to diagnose PD.
| Reference | Machine Learning Algorithms Used |
Objective | Tools Used | Source of Data | No. of Subjects |
Outcomes |
|---|---|---|---|---|---|---|
| Ye, Q. et al., 2018 [38] | Least square (LS)—SVM, particle swarm optimization (PSO) |
Classification of PD, ALS, HD from HC | Not mentioned | Neurology Outpatient Clinic at Massachusetts General Hospital, Boston, MA, USA [39] |
64, 15 PD + 16 HC + 13 (Amyotrophic lateral sclerosis disease (ALS)) + 20 (Huntington’s disease (HD)) |
Accuracy to diagnose PD from HC—90.32%, accuracy to diagnose HD from HC—94.44%, accuracy to diagnose ALS from HC—93.10% |
| Wahid, F. et al., 2015 [40] | Random forest, SVM, kernel Fisher Discriminant (KFD) |
Classification of PD from HC | MATLAB R2013b | Collected from participants | 49, 23 PD + 26 HC | The accuracy obtained from random forest, SVM, and KFD was 92.6%, 80.4% and 86.2%, respectively. |
| Pham, T.D.and Yan, H., 2018 [41] | LS-SVM | Classification of PD from HC | MATLAB | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Sensitivity—100% and specificity—100% |
| Y. Mittra and V. Rustagi, 2018 [42] | Logistic regression, decision tree, SVM (Linear, RBF, Poly kernel), KNN |
Classification of PD from HC | Not mentioned | Collected from participants |
49, 23 PD + 26 HC | Highest accuracy obtained from SVM (RBF) and random forest—90.39% |
| Klomsae, A. et al., 2018 [43] | Fuzzy KNN | Classification of PD, ALS, HD from HC | Not mentioned | Neurology Outpatient Clinic at Massachusetts General Hospital, Boston, MA, USA [38] | 64, 15 PD + 20 HD + 13 ALS + 16 HC | Accuracy to diagnose PD from HC—96.43%, accuracy to diagnose HD from HC—97.22%, accuracy to diagnose ALS from HC—96.88% |
| Milica et al., 2017 [44] | SVM-RBF | Classification of PD from HC | Python | Collected from participants from Institute of Neurology CCS, School of Medicine, University of Belgrade | 80, 40 PD + 40 HC | Overall accuracy from SVM-RBF—85% |
| Cuzzolin, F. et al., 2017 [45] | HMM | Classification of PD from HC | Not mentioned | Collected from participants | 424, 156 PD + 268 HC | Accuracy—85.51% |
| Félix, J.P. et al., 2019 [46] | SVM, KNN, naïve Bayes, LDA, decision tree |
Classification of PD from HC | MATLAB R2017a | Neurology Outpatient Clinic at Massachusetts General Hospital, Boston, MA, USA [38] |
31, 15 PD + 16 HC | Highest accuracy obtained from SVM, KNN, and decision tree—96.8% |
| Baby, M.S. et al., 2017 [47] | ANN | Classification of PD from HC | MATLAB | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Accuracy—86.75% |
| Andrei et al., 2019 [48] | SVM | Classification of PD from HC | Not mentioned | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Accuracy—100% |
| Priya, S.J. et al., 2021 [49] | ANN | Classification of PD from HC | MATLAB R2018b | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Accuracy—96.28% |
| Perumal, S.V. & Sankar, R., 2016 [50] | SVM, ANN | Classification of PD from HC | MATLAB | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Average Accuracy—86.9% |
| Nancy, Y. et al., 2016 [51] | Q-Backpropagated time delay neural network (Q-BTDNN) | Classification of PD from HC | MATLAB 2013 | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Accuracy—91.49% |
| Oğul, et al., 2020 [52] | ANN | Classification of PD from HC | MATLAB | Laboratory for Gait and Neurodynamics | 166, 93 PD + 73 HC | Classification accuracy—98.3% |
| Li, B. et al., 2020 [53] | Deep CNN | Classification of PD from HC | Not mentioned | Collected from participants | 20, 10 PD + 10 HC | Accuracy—91.9% |
| Gao, C. et al., 2018 [54] | Logistic regression, random forests, SVM, XGBoost |
Classification of PD from HC | Not mentioned | University of Michigan | 80, 40 PD + 40 HC | Highest accuracy obtained from random forests—79.6% |
| Rehman et al., 2019 [55] | SVM, logistic regression | Classification of PD from HC | Python programming | Not mentioned | 303, 119 PD + 184 HC | Average accuracy—97% |
| Natasa et al., 2020 [56] | Random forest, XGBoosting, gradient boosting, SVM(RBF), neural networks |
Classification of PD from HC | Not mentioned | Collected from the participants | 10 PD | Best performance obtained from SVM(RBF) with the sensitivity value 72.34%, 91.49%, 75.00% and specificity value 87.36%, 88.51% and 93.62%, for the FoG, transition and normal activity classes, respectively. |
This entry is adapted from the peer-reviewed paper 10.3390/diagnostics12082003
References
- Toth, C.; Rajput, M.; Rajput, A.H. Anomalies of asymmetry of clinical signs in parkinsonism. Mov. Disord. 2004, 19, 51–57.
- Zappia, M.; Annesi, G.; Nicoletti, G.; Arabia, G.; Annesi, F.; Messina, D.; Pugliese, P.; Spadafora, P.; Tarantino, P.; Carrideo, S. Sex differences in clinical and genetic determinants of levodopa peak-dose dyskinesias in Parkinson disease: An exploratory study. Arch. Neurol. 2005, 62, 601–605.
- Little, M.A.; McSharry, P.E.; Roberts, S.J.; Costello, D.A.E.; Moroz, I.M. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection. Nat. Prec. 2007, 6, 23.
- Surathi, P.; Jhunjhunwala, K.; Yadav, R.; Pal, P.K. Research in Parkinson’s disease in India: A review. Ann. Indian. Acad. Neurol. 2016, 19, 9–20.
- Available online: https://www.healthcareradius.in/clinical/28890-parkinsons-disease-and-the-ageing-indian-population (accessed on 11 June 2022).
- Available online: https://www.parkinson.org/understanding-parkinsons/causes/genetics (accessed on 6 August 2022).
- Kalinderi, K.; Bostantjopoulou, S.; Fidani, L. The genetic background of Parkinson’s dis-ease: Current progress and future prospects. Acta Neurol. Scand. 2016, 134, 314–326.
- Gasser, T. Genomic and proteomic biomarkers for Parkinson disease. Neurology 2009, 72 (Suppl. S2), S27–S31.
- Available online: https://www.mayoclinic.org/diseases-conditions/parkinsons-disease/symptoms-causes/syc-20376055 (accessed on 11 June 2022).
- Martin-Bastida, A.; Pietracupa, S.; Piccini, P. Neuromelanin in parkinsonian disorders: An update. Int. J. Neurosci. 2017, 127, 1116–1123.
- Rawat, A.S.; Rana, A.; Kumar, A.; Bagwari, A. Application of multi layer artificial neural network in the diagnosis system: A systematic review. IAES Int. J. Artif. Intell. 2018, 7, 138.
- Rana, A.; Rawat, A.S.; Bijalwan, A.; Bahuguna, H. Application of Multi Layer (Perceptron) Artificial Neural Network in the Diagnosis System: A Systematic Review. In Proceedings of the 2018 International Conference on Research in Intelligent and Computing in Engineering (RICE), San Salvador, El Salvador, 22–24 August 2018; pp. 1–6.
- Al-Wahishi, A.; Belal, N.; Ghanem, N. Diagnosis of Parkinson’s Disease by Deep Learning Techniques Using Handwriting Dataset. In Proceedings of the International Symposium on Signal Processing and Intelligent Recognition Systems, Chennai, India, 14–17 October 2020.
- Neharika, D.B.; Anusuya, S. Machine Learning Algorithms for Detection of Parkinson’s Disease using Motor Symptoms: Speech and Tremor. IJRTE 2020, 8, 47–50.
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2009, 56, 1015.
- Benba, A.; Jilbab, A.; Hammouch, A.; Sandabad, S. Voiceprints analysis using MFCC and SVM for detecting patients with Parkinson’s disease. In Proceedings of the IEEE 2015 International Conference on Electrical and Information Technologies (ICEIT), Marrakech, Morocco, 25–27 March 2015; pp. 300–304.
- Bhattacharya, I.; Bhatia, M.P.S. SVM classification to distinguish Parkinson disease patients. In Proceedings of the 1st Amrita ACM-WCelebration on Women in Computing in India, Tamilnadu, India, 16–17 September 2010; p. 14.
- Mathur, R.; Pathak, V.; Bandil, D. Parkinson Disease Prediction Using Machine Learning Algorithm. In Emerging Trends in Expert Applications and Security; Springer: Singapore, 2019; pp. 357–363.
- Sakar, B.E.; Isenkul, M.E.; Sakar, C.O.; Sertbas, A.; Gurgen, F.; Delil, S.; Apaydin, H.; Kursun, O. Collection and analysis of a Parkinson speech dataset with multiple types of sound recordings. IEEE J. Biomed. Health Inform. 2013, 17, 828–834.
- Sakar, C.O.; Serbes, G.; Gunduz, A.; Tunc, H.C.; Nizam, H.; Sakar, B.E.; Tutuncu, M.; Aydin, T.; Isenkul, M.E.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable-factor wavelet transform. Appl. Soft Comput. 2019, 74, 255–263.
- Yasar, A.; Saritas, I.; Sahman, M.A.; Cinar, A.C. Classification of Parkinson Disease Data with Artificial Neural Networks. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 675, p. 012031.
- Poewe, W.; Seppi, K.; Tanner, C.M.; Halliday, G.M.; Brundin, P.; Volkmann, J.; Schrag, A.E.; Lang, A.E. Parkinson disease. Nat. Rev. Dis. Primers 2017, 3, 17013.
- Yao, L.; Brown, P.; Shoaran, M. Resting Tremor Detection in Parkinson’s Disease with Machine Learning and Kalman Filtering. In Proceedings of the IEEE Biomedical Circuits and Systems Conference: Healthcare Technology, Cleveland, OH, USA, 17–19 October 2018.
- Almeida, J.S.; RebouçasFilho, P.P.; Carneiro, T.; Wei, W.; Damaševičius, R.; Maskeliūnas, R.; de Albuquerque, V.H.C. Detecting Parkinson’s disease with sustained phonation and speech signals using machine learning techniques. Pattern Recognit. Lett. 2019, 125, 55–62.
- Almalaq, A.; Dai, X.; Zhang, J.; Hanrahan, S.; Nedrud, J.; Hebb, A. Causality graph learning on cortical information flow in Parkinson’s disease patients during behaviour tests. In Proceedings of the 2015 49th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015; pp. 925–929.
- Alqahtani, E.J.; Alshamrani, F.H.; Syed, H.F.; Olatunji, S.O. Classification of Parkinson’s Disease Using NNge Classification Algorithm. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–7.
- Avuçlu, E.; Elen, A. Evaluation of traisn and test performance of machine learning algorithms and Parkinson diagnosis with statistical measurements. Med. Biol. Eng. Comput. 2020, 58, 2775–2788.
- Senturk, Z.K. Early diagnosis of Parkinson’s disease using machine learning algorithms. Med. Hypotheses 2020, 138, 109603.
- Yaman, O.; Ertam, F.; Tuncer, T. Automated Parkinson’s disease recognition based on statistical pooling method using acoustic features. Med. Hypotheses 2020, 135, 109483.
- Aich, S.; Kim, H.; Younga, K.; Hui, K.L.; Al-Absi, A.A.; Sain, M. A Supervised Machine Learning Approach using Different Feature Selection Techniques on Voice Datasets for Prediction of Parkinson’s Disease. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 17–20 February 2019; pp. 1116–1121.
- Haq, A.U.; Li, J.P.; Memon, M.H.; Malik, A.; Ahmad, T.; Ali, A.; Nazir, S.; Ahad, I.; Shahid, M. Feature Selection Based on L1-Norm Support Vector Machine and Effective Recognition System for Parkinson’s Disease Using Voice Recordings. IEEE Access 2019, 7, 37718–37734.
- Khachnaoui, H.; Khlifa, N.; Mabrouk, R. Machine Learning for Early Parkinson’s Disease Identification within SWEDD Group Using Clinical and DaTSCAN SPECT Imaging Features. J. Imaging 2022, 8, 97.
- Paul, S.; Maindarkar, M.; Saxena, S.; Saba, L.; Turk, M.; Kalra, M.; Krishnan, P.R.; Suri, J.S. Bias Investigation in Artificial Intelligence Systems for Early Detection of Parkinson’s Disease: A Narrative Review. Diagnostics 2022, 12, 166.
- Ahmed, I.; Aljahdali, S.; Khan, M.S.; Kaddoura, S. Classification of Parkinson disease based on patient’s voice signal using machine learning. Intell. Autom. Soft Comput. 2021, 32, 705–722.
- De Souza, J.W.; Alves, S.S.; Rebouças, E.D.S.; Almeida, J.S.; RebouçasFilho, P.P. A New Approach to Diagnose Parkinson’s Disease Using a Structural Cooccurrence Matrix for a Similarity Analysis. Comput. Intell. Neurosci. 2018, 2018, 7613282.
- Pereira, C.R.; Pereira, D.R.; Silva, F.A.; Masieiro, J.P.; Weber, S.A.; Hook, C.; Papa, J.P. A new computer vision-based approach to aid the diagnosis of Parkinson’s disease. Comput. Methods Programs Biomed. 2016, 136, 79–88.
- Abdulhay, E.; Arunkumar, N.; Narasimhan, K.; Vellaiappan, E.; Venkatraman, V. Gait and tremor investigation using machine learning techniques for the diagnosis of Parkinson disease. Future Gener. Comput. Syst. 2018, 83, 366–373.
- Ye, Q.; Xia, Y.; Yao, Z. Classification of gait patterns in patients with neurodegenerative disease using adaptive neuro-fuzzy inference system. Comput. Math. Methods Med. 2018, 2018, 9831252.
- Hausdorff, J.M.; Lertratanakul, A.; Cudkowicz, M.E.; Peterson, A.L.; Kaliton, D.; Goldberger, A.L. Dynamic markers of altered gait rhythm in amyotrophic lateral sclerosis. J.Appl. Physiol. 2000, 88, 2045–2053.
- Wahid, F.; Begg, R.K.; Hass, C.J.; Halgamuge, S.; Ackland, D.C. Classification of Parkinson’s Disease Gait Using Spatial-Temporal Gait Features. IEEE J. Biomed. Health Inform. 2015, 19, 1794–1802.
- Pham, T.D.; Yan, H. Tensor Decomposition of Gait Dynamics in Parkinson’s Disease. IEEE Trans. Biomed. Eng. 2018, 65, 1820–1827.
- Mittra, Y.; Rustagi, V. Classification of Subjects with Parkinson’s Disease Using Gait Data Analysis. In Proceedings of the 2018 International Conference on Automation and Computational Engineering (ICACE), Greater Noida, India, 3–4 October 2018; pp. 84–89.
- Klomsae, A.; Auephanwiriyakul, S.; Theera-Umpon, N. String grammar unsupervised possibilistic fuzzy c-medians for gait pattern classification in patients with neurodegenerative diseases. Comput. Intell. Neurosci. 2018, 2018, 1869565.
- Djurić-Jovičić, M.; Belić, M.; Stanković, I.; Radovanović, S.; Kostić, V.S. Selection of gait parameters for differential diagnostics of patients with de novo Parkinson’s disease. Neurol. Res. 2017, 39, 853–861.
- Cuzzolin, F.; Sapienza, M.; Esser, P.; Saha, S.; Franssen, M.M.; Collett, J.; Dawes, H. Metric learning for Parkinsonian identification from IMU gait measurements. Gait Posture 2017, 54, 127–132.
- Felix, J.P.; Vieira, F.H.; Cardoso, Á.A.; Ferreira, M.V.; Franco, R.A.; Ribeiro, M.A.; Araújo, S.G.; Corrêa, H.P.; Carneiro, M.L. A Parkinson’s Disease Classification Method: An Approach Using Gait Dynamics and Detrended Fluctuation Analysis. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4.
- Baby, M.S.; Saji, A.J.; Kumar, C.S. Parkinsons disease classification using wavelet transform based feature extraction of gait data. In Proceedings of the 2017 International Conference on Circuit Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–6.
- Andrei, A.-G.; Tăuțan, A.-M.; Ionescu, B. Parkinson’s Disease Detection from Gait Patterns. In Proceedings of the 2019 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2019; pp. 1–4.
- Priya, S.J.; Rani, A.J.; Subathra, M.S.P.; Mohammed, M.A.; Damaševičius, R.; Ubendran, N. Local Pattern Transformation Based Feature Extraction for Recognition of Parkinson’s Disease Based on Gait Signals. Diagnostics 2021, 11, 1395.
- Perumal, S.V.; Sankar, R. Gait and tremor assessment for patients with Parkinson’s disease using wearable sensors. ICT Express 2016, 2, 168–174.
- Jane, Y.N.; Nehemiah, H.K.; Arputharaj, K. A Q-backpropagated time delay neural network for diagnosing severity of gait disturbances in Parkinson’s disease. J. Biomed. Inform. 2016, 60, 169–176.
- Yurdakul, O.C.; Subathra, M.S.P.; George, S.T. Detection of Parkinson’s Disease from gait using Neighborhood Representation Local Binary Patterns. Biomed. Signal Processing Control. 2020, 62, 102070.
- Li, B.; Yao, Z.; Wang, J.; Wang, S.; Yang, X.; Sun, Y. Improved Deep Learning Technique to Detect Freezing of Gait in Parkinson’s Disease Based on Wearable Sensors. Electronics 2020, 9, 1919.
- Gao, C.; Sun, H.; Wang, T.; Tang, M.; Bohnen, N.I.; Müller, M.L.; Herman, T.; Giladi, N.; Kalinin, A.; Spino, C.; et al. Model-based and Model-free Machine Learning Techniques for Diagnostic Prediction and Classification of Clinical Outcomes in Parkinson’s Disease. Sci. Rep. 2018, 8, 7129.
- Rehman, R.Z.U.; Del Din, S.; Guan, Y.; Yarnall, A.J.; Shi, J.Q.; Rochester, L. Selecting Clinically Relevant Gait Characteristics for Classification of Early Parkinson’s Disease: A Comprehensive Machine Learning Approach. Sci. Rep. 2019, 9, 17269.
- Kleanthous, N.; Hussain, A.J.; Khan, W.; Liatsis, P. A new machine learning based approach to predict Freezing of Gait. Pattern Recognit. Lett. 2020, 140, 119–126.
This entry is offline, you can click here to edit this entry!