1. Physically Based Numerical Groundwater Flow Models
Numerical groundwater flow models simulate the distribution of head by solving the equations of conservation of mass and momentum. Because these equations represent the physical flow system, in order to obtain accurate results accuracy, the physical properties of the aquifer (e.g., hydraulic conductivity, specific storage) as well as the initial and boundary conditions of the system must be properly assigned within the time and space domains of the model [
3]. The physically based models used in the reviewed papers are briefly described as follows.
MODFLOW [
50,
51] is the modular finite difference flow model distributed by the U.S. Geological Survey. It is one of the most popular groundwater modelling programs. Thanks to its modular structure, MODFLOW integrates many modelling capabilities to simulate most types of groundwater modelling problems. The corresponding packages (e.g., solute transport, coupled groundwater/surface-water systems, variable-density flow, aquifer-system compaction and land subsidence, parameter estimation) are well structured and documented and can be activated and used to solve required modelling problems. The source code is free and open source, and can be fixed and modified by anyone with the necessary mathematical and programming skills to improve its capabilities [
52].
SUTRA (Saturated-Unsaturated Transport) [
53] is a 3D groundwater model that simulates solute transport (i.e., salt water) or temperature. The model employs a grid that is based on a finite element and integrated finite difference hybrid method framework. The program then computes groundwater flow using Darcy’s law equation, and solute or transport modelling use similar equations. It is very frequently used for calculation of salinity of infinite homogeneous, isotropic unconfined aquifer.
The Princeton Transport Code (PTC, [
54,
55] is a 3D groundwater flow and contaminant transport simulator. It uses a hybrid coupling of the finite-element and finite-difference methods. The domain is discretised by the algorithm into parallel horizontal layers; the elements within each layer are discretised by finite-element method. The vertical connection between layers is allowed by a finite-difference discretisation. During any iteration, all the horizontal finite-element discretisations are firstly solved independently of each other; then, the algorithm solves the vertical equations connecting the layers using the solution of the horizontal equation.
SHETRAN is a physically-based distributed modelling system for simulating water flow, sediment, and contaminant transport in river basins [
56]. It is often used to model integrated groundwater–surface water systems. SHETRAN simulates surface flows using a diffusive wave approximation to the Saint–Venant equations for 2D overland flow and 1D flow through channel networks. Subsurface flows are modelled using a 3D extended Richards equation formulation, where the saturated and unsaturated zones are represented as a continuum. Surface and subsurface flows exchange is allowed in either direction. The partial differential equations for flow and transport are solved on a rectangular grid by the finite difference methods; the soil zone and aquifer are represented by cells which extend downwards from each of the surface grid elements. Precise river–aquifer exchange flows can be represented by using the local mesh refinement option near river channels.
2. Machine Learning Models
2.1. Artificial Neural Networks (ANNs)
An artificial neural network (ANN) model is a data-driven model that simulates the actions of biological neural networks in the human brain. Typically, an ANN comprises a variable number of elements, called neurons, which are linked by connections. Generally, an ANN is composed of three separate layers: input, hidden, and output layers. Each single layer contains neurons with similar properties. The input layer takes input variables (e.g., past GWL, temperature, precipitation time series); a relative weight (i.e., an adaptive coefficient) is given to each input, which modifies the impact of that input. In the hidden and output layers, each neuron sums its input, and then applies a specific transfer (activation) function to calculate its output. By processing historical time series, the ANN learns the behaviour of the system. An ANN learns by relating a given number of input data with a resulting set of outputs [
57], which is the training process. Training means modifying the network architecture to optimise the network performance, which involves tuning the adjustable parameters: tuning the weights of the connections among nodes, pruning or creating new connections, and/or modifying the firing rules of the single neurons [
58]. The training process can be conducted with various training (learning) algorithms. ANN learning is iterative, comparable to the human learning from experience [
59]. ANNs are very popular for hydrologic modelling and is used to solve many scientific and engineering problems. These models may be ascribed to two categories: feed-forward, which is the most common, and feed-back networks [
60,
61]. The most frequently used family of feed-forward networks is the multilayer perceptron [
62,
63]; it contains a network of layers with unidirectional connections between the layers.
2.2. Radial Basis Function Network (RBF)
RBF network is commonly a three-layer ANN which uses RBF as activation functions in the hidden layer; the network architecture is the same as multilayer perceptron. The number of neurons in the input layer is the same as the input vectors. The radial basis functions in the hidden layer map the input vectors into a high-dimension space [
64]. A linear combination of the hidden layer outputs is used to calculate the neurons in the output layer of the network. The distinctive characteristic of RBF is that the responses increase (or decrease) monotonically with Euclidean distance between the centre and the input vectors [
65].
2.3. Adaptive Neuro-Fuzzy Inference System (ANFIS)
ANFIS, first described by Jang [
36], combines the neural networks with the fuzzy rule-based system. In the fuzzy systems, relationships are represented explicitly in the form of if-then rules [
66,
67]. Different from a typical ANN, which uses sigmoid function to convert the values of variables into normalises values, an ANFIS network converts numeric values into fuzzy values. Firstly, a fuzzy model is developed, where input variables are derived from the fuzzy rules. Then, the neural network tweaks these rules and generates the final ANFIS model [
68]. Usually, an ANFIS model is structured by five layers named according to their operative function, such as ‘input nodes’, ‘rule nodes’, ‘average nodes’, consequent nodes’, and ‘output nodes’, respectively [
69].
2.4. Time Lagged Recurrent Neural Networks (TLRNs)
TLRN are multilayer perceptrons extended with “short-term” memory structures that have local recurrent connections. The approach in TLRNs differs from a regular ANN approach in that the temporal nature of the data is taken into account [
69], allowing accurate processing of temporal (time-varying) information. The most common structure of a TLRN comprises an added feedback loop which introduces the short-term memory in the network [
70] so that it can learn temporal variations from the dataset [
71]. TLRN uses a more advanced training algorithm (back propagation through time) than standard multilayer perceptron [
72]. The main advantage is that the network size of TLRNs is lower than multilayer perceptrons that use extra inputs to represent the past state of the system. Furthermore, TLRNs have a low sensitivity to noise.
2.5. Extreme Learning Machine (ELM)
ELM is a training algorithm for the single-layer feed-forward-neural network (SLFFNN). Input weights and biases values of the nodes in the hidden layer are randomly determined according to continuous probability distribution with probability of 1, so as to be able to train N separate samples. Compared with conventional neural networks, in ELM, only the number of hidden layer neurons needs to be tuned, and no adjustments are required for parameters such as learning rate and learning epochs. Training of ELM is conducted quickly and is considered a universal approximator [
73,
74,
75].
2.6. Bayesian Network (BN)
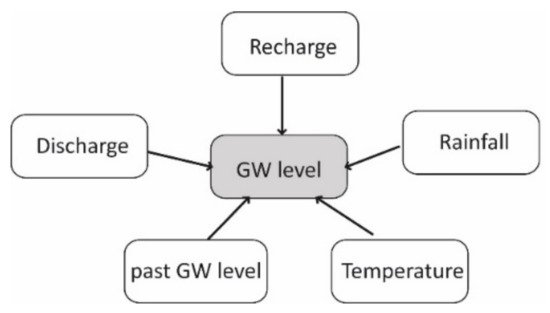
The Bayesian networks (Figure 1) are statistical-based models which compute the conditional probability associated with the occurrence of an event by using the Bayes’ rule. A typical Bayesian network is composed of a set of variables where their conditional dependencies are represented by a directed acyclic graph.
Figure 1. Example of the structure of a Bayesian model applied to groundwater-level study.
Connections define the conditional dependencies among variables (i.e., nodes) [
76]. The dependencies are quantified by conditional probabilities for each node through a conditional table of probabilities. Usually, BNs are built by software that generates many network structures with the input parameters.
2.7. Instance-Based Weighting (IBW)
Instance-based algorithms derive from the nearest-neighbour pattern classifier [
77], which is modified and extended by introducing a weighting function. IBW models are also inspired by exemplar-based models of categorisation [
78]. Different from other machine learning algorithms, which return an explicit target function after learning from the training dataset, instance-based algorithms simply save the training dataset in memory [
79]. For any new data, the algorithm first finds its n nearest neighbour in the training set and delays the processing effort until a new instance needs to be classified. IBW has many advantages such as the low training cost, the efficiency gained through solution reuse [
80], ability to model complex target functions, and the capability to describe probabilistic concepts [
81]. However, when irrelevant features are present, their performance decreases; an accurate distinction of relevant features can be achieved through feature weighting to ensure acceptable performance. IBW does not need to be trained and the results are less influenced by the training data size. Inverse-distance weighting is a special case of instance-based weighting with the weighting factor p = 2 [
82].
2.8. Support Vector Machine (SVM)
SVM are kernel-based neural networks developed by Vapnik [
83] to overcome the several weaknesses which affect the ANNs’ overall generalisation capability [
84], including possibilities of getting trapped in local minima during training, overfitting the training data, and subjectivity in the choice of model architecture [
85]. The SVM is based on statistical learning theory [
86]; in particular, it is based on structural risk minimisation (SRM) instead of empirical risk minimisation (ERM) of ANNs. The SVM minimises the empirical error and model complexity simultaneously, which can improve the generalisation ability of the SVM for classification or regression problems in many disciplines. This is achieved by minimising an upper bound of the testing error rather than minimising the training error [
79]; the solution of SVM with a well-defined kernel is always globally optimal, while many other machine learning tools (e.g., ANNs) are subjected to local optima; finally, the solution is represented sparsely by Supporting Vectors, which are typically a small subset of all training examples [
87]. For further details, see refs. [
63,
86,
88,
89].
2.9. Decision Trees (DT)
Decision tree models [
90] are based on the recursive division of the response data into many parts along any of the predictor variables in order to minimise the residual sum of squares (RSS) of the data within the resulting subgroups (i.e., “nodes” in the terminology of tree models) [
91]. The number of nodes increases during the process of splitting along predictors. The tree-growing process stops when the within-node RSS is below a specified threshold or when a minimum specified number of observations within a node is reached [
92]. However, the modeller places minimal limitations upon tree-fitting process, and fitted trees may be more complex than is actually warranted by the data available. The problem of overfitting results is then managed by the ‘pruning’ algorithms, which aid the modeller in the selection of a parsimonious description of interactions between response and predictors, fitting trees for the optimum structure for any level of complexity [
91]. Because no prior assumptions are made about the nature of the relationships among predictors, and between predictors and response, decision trees are extremely flexible.
2.10. Random Forest (RF)
Random forests work by constructing groups of decision trees during the training process, representing a distinct instance of the classification of data input. Each tree is developed by independently sampling the values of a random vector with the same distribution for all trees in the forest [
93].
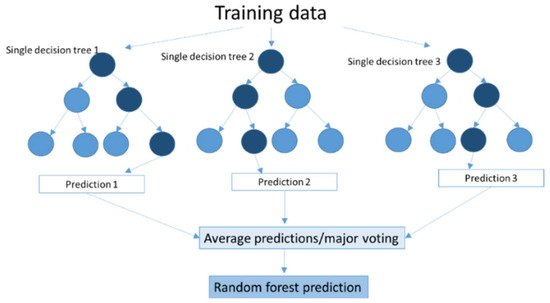
The random forest technique considers the instances individually so that the trees are run in parallel; there is no interaction between these trees while building the trees. The prediction with the majority of votes or an average of the prediction is taken as the selected prediction (
Figure 2). The RF algorithm was created to overcome the limitations of DT, reducing the overfitting of datasets and increasing prediction accuracy. The decision tree grows to the largest possible size without being pruned in accordance with the number of trees and the number of predictor variables [
94].
Figure 2. Scheme of Random Forest.
2.11. Gradient-Boosted Regression Trees (GBRT)
Gradient-Boosted Regression trees are ensemble techniques in which weak predictors are grouped together to enhance their performance [
95]. Learning algorithms are combined in series to achieve a strong learner (“boosting”) from different weak learners (i.e., the decision trees) connected sequentially. Each tree attempts to minimise the errors of the previous tree. After the initial tree is generated from the data, subsequent trees are generated using the residuals from the previous tree. At each step, trees are weighted, with the lower-performing trees weighted the highest; this allows the improvement of performance at each iteration. A variety of loss functions can be used to detect the residuals.
This entry is adapted from the peer-reviewed paper 10.3390/w14152307