Electrical energy is consumed at the same time as it is generated, since its storage is unfeasible. Therefore, short-term load forecasting is needed to manage energy operations. In Europe, owing to directives and new technologies, prediction systems will be on a quarter-hour basis. Therefore, a predictive system may not dispose of sufficient time to compute all future forecasts. Prediction systems perform calculations throughout the day, calculating the same forecasts repeatedly as the predicted time approaches. However, there are forecasts that are no more accurate than others that have already been made. If previous forecasts are used preferentially over these, then computational burden will be saved while accuracy increases. In this way, it will be possible to optimize the schedule of future quarter-hour systems and fulfill the execution time limits. A proposed algorithm estimates which forecasts provide greater accuracy than previous ones, and then it makes a forecasting schedule.
- short-term load forecasting
- computational burden
- forecasting schedule
1. Introduction
Short-term load forecasting (STLF) is used to manage the production and distribution of electricity, and operate electricity markets from the current hour to the following days. If the electricity operator overestimates future electricity load, there will be extra production costs that will lead to economic losses. On the other hand, if the electricity demand is underestimated, power plants may not have sufficient reserves for their generators to meet the energy demanded by the grid, compromising its stability and risking the possibility of a blackout. In addition, an accurate demand forecast indirectly facilitates the management of electrical energy from renewable energies. In addition to electricity operators, other entities benefit from accurate electricity load forecasts, such as power marketers, independent system operators, or load aggregators.
Forecasting electricity load is a complex problem, which has been approached through various methods and from different points of view over the last few decades, which has led to a great variety of forecasting algorithms implemented in different electricity networks.
Many techniques are based on neural networks [1] [2] [3] [4] [5]. Other algorithms use statistical methods [6] [7]. Hybrid systems that combine neural networks with other techniques are also common [8] [9] [10] [11].
1.1. Main Problem
STLF systems calculate forecasts frequently most likely hourly. The system must obtain fast forecasts, so the operator can read the results and manage the actions that adjust to future load. The latest measurement systems tend to use quarter-hour intervals. The STLF systems that currently work with hourly intervals will considerably increase their computational burden, whenever they change to quarter-hour intervals. They will have to forecast four times more values due to increased granularity and they will do this four times more often, due to an increase in frequency. This paper addresses the problem of computational burden while attempting to increase the accuracy of the STLF systems already implemented.
The Spanish transmission system operator (TSO) is Red Eléctrica de España (REE) and it is working on hourly intervals. It needs forecasts for 19 electrical regions, which is 19 times more calculations than a single STLF, with a total of 2.5 s for every hour that is predicted nationwide. Due to time limits for submitting predictions, it is not always feasible to calculate all future hours. Therefore, there is a schedule that determines which future intervals are predicted during each hour of the day.
The REE forecasting system cannot keep the previous forecasting schedule with quarter-hour intervals, since it is too computationally heavy to work within the time restriction. Therefore, there is need for a new schedule to forecast only the most useful intervals. Furthermore, the new schedule must be based on a criterion that numerically determines which predictions are most useful. Satisfying the need for a systematic method to optimize schedules is the main motivation of this work.
1.2. Solution Approach
It was assumed that as we approach the forecast moment, the forecast becomes more accurate. However, this hypothesis does not always hold true. There is an obvious trend in which accuracy increases as more recent information (weather and load) becomes available. Nevertheless, sometimes, there seem to be some periods in which new forecasts are actually less accurate. If accuracy loss periods can be known in advance, then the unproductive forecasts made at these times can be spared, saving computational effort while achieving a more accurate forecast. This work aims to determine the optimal schedule of forecasts so that the system only computes new forecasts when an accuracy improvement is expected.
The forecast needs to be computed within a time limit; therefore, each computer has a limit of N hourly values, beyond which the forecast would arrive late. This limit depends on the time allowed and the calculation speed, which again depends on the computer itself and on the forecasting algorithm used. In order to select the best N forecasts that can be calculated at each moment, a method to prioritize them needs to be developed. In addition, even if all predictions can be calculated, they may be counterproductive, since some of them have a greater predictive error than some of the previous ones.
2. Literature Review
The STLF field is extensive, since innumerable works have been published for decades; consequently, reviews of the state of the art have been published, such as those made by Mamum et al. [12], Hippert et al. [13], or Hong et al. [14].
The previous work on the STLF system used in this paper [15] compared the autoregressive and neural models used. The research defined which one performs better in different contexts, being determined by the model configuration, availability of data and the use of exogenous variables. On the other hand, the proposed research took into account the performance of the same model for different time lapses.
Other researchers [16] [17] [18] [19] [20] [21] [22] built and compared different STLF mathematical models employing error measures as performance indicators. After that, they did not consider how to apply those models in an optimized schedule, to avoid producing larger errors than past predictions that had already been calculated. J. Mohammed et al. [23] did something similar, which also included reliability indicators to assess the model’s performance.
Another example is the work carried out by G. Veljanovski et al. [24], in which they proposed a forecasting system based on a neural network. They did not consider the best time at which to obtain data and execute the computation.
Weyermüller et al. [25] built a minimalistic adaptive neuro-fuzzy inference model. It forecasts the load of one hour 24 h before, so this research could be applied to organize the calculation schedule if more forecast hours are added to the model.
The present work could complement automatic forecasting systems, since it offers an automated extra step at the end of the modeling process, in order to obtain an optimized execution schedule. An example of automatically modeled systems is the work conducted by L. Shufen et al. [26], in which they proposed an algorithm to automate time series forecasting for nonexperts.
The analysis proposed in this work could be applied to future works of theoretical research. For example, the research by T. Panapongpakorn et al. [27] or the work by D. Shuai [28].
Jiang et al. [29] examined their model for different anticipation times; they also compared different STLF models, taking into account error and computation times. However, anticipation times varied just from 5 min to 16 h ahead and they were used to assess models, in the same way that calculation times were employed to compare entire models.
There is research which focuses on reducing computational burden, such as that by A. McIlvenna et al. [30]. This research aims to optimize the use of a previously built forecasting system regardless of which one it is.
With a different approach, M. Weimar et al. [31] evaluated the improvement of a STLF system according to the economic savings with an econometric model. This is an example of how improving accuracy offers benefits that overcome developing costs.
3. Forecasting System Employed
The STLF system used in this research, during testing, is that developed by the UMH [8], which was implemented in REE. The system has been operating for more than 4 years, and during this time REE and UMH have continued to collaborate in continuous improvement efforts [15] [32].
4. Methodology
The time a computer needs to calculate a set of predictions depends on three factors: the time that it takes to load new input data (I), the number of forecasts (n), and the time that it takes to make each prediction (P). So, the run time (t) can be modeled with the linear Equation (1).
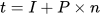 |
(1) |
Variables I and P depend on the computer and code employed. At the beginning of each hour, the forecasting system loads new input data (temperatures and previous measured load).
As mentioned before, due to the limitation of accuracy or computational burden, for each execution, there is a maximum number, N, of predictions that can be performed without exceeding the response time limit. Therefore, for each execution period, up to N predictions with greater value can be selected.
The result obtained by applying the proposed algorithm is a schedule, which defines the predictions to be executed at each hour of the day. The algorithm does not depend on the mathematical model used, but on the errors that it makes regarding historical records. Therefore, the major benefit of applying the algorithm is the error reduction sparing us from calculations with worse errors than previous ones already executed. In this way, it can be applied to a system that is organized by time intervals and it is possible to choose which intervals to predict in each hour of the day.
The Figure 1 shows how to use the algorithm in a forecasting system. First, the maximum number of predictions that can be calculated per interval is obtained, which depends on available time and computing power. At the same time, the previous year can be predicted to calculate historical error records. Finally, the algorithm is applied to obtain a schedule that will serve to forecast load during the next year.
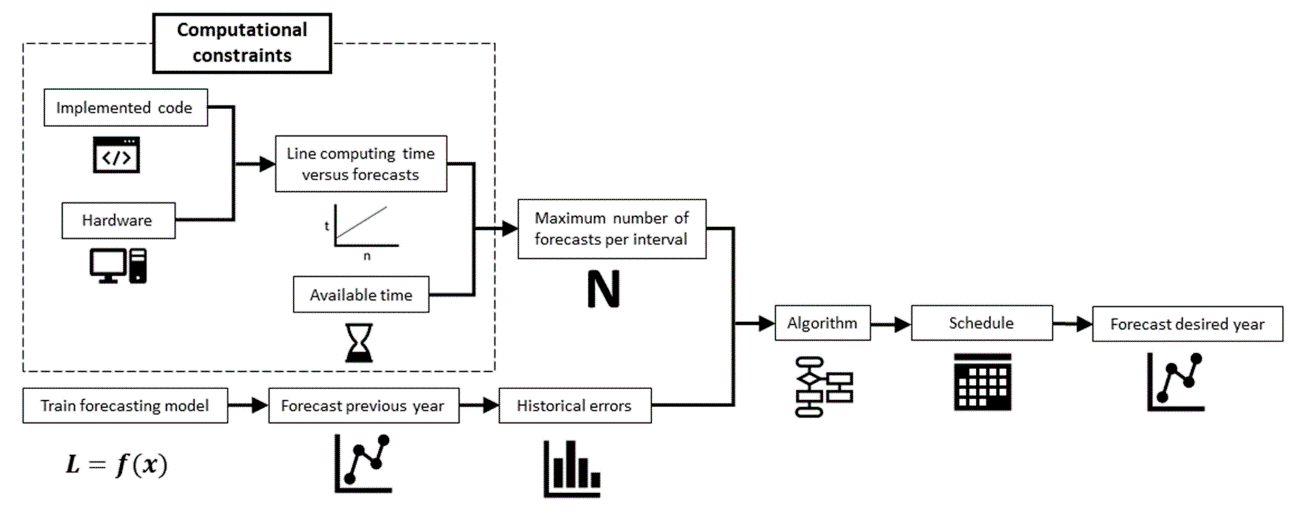 Figure 1. Process summary.
Figure 1. Process summary.
Other scheduling alternatives have been tested to compare the performance of the proposed algorithm. They are explained in Table 1.
 Table 1. Scheduling options.
Table 1. Scheduling options.
5. Proposed Algorithm
To measure the value of a prediction, a numerical indicator called accuracy improvement expectation (AIE) is used. As the name suggests, it reflects the expectation of improvement in accuracy of a predicted demand if it is recalculated. To calculate this parameter, historical records of predictions calculated under the same conditions are used; that is, forecasts calculated at the same time of day with the same advance period.
The implemented algorithm prioritizes the hourly forecasts according to larger AIE over the results of a full year, so only the first N values will be predicted in order to adhere to the time allowed.
Before executing the algorithm, it is necessary to determine the number of maximum forecasts, N, that the computer employed can execute. This is determined empirically by its computational speed and the calculation time limit.
6. Accuracy Results of Optimized Scheduling
In order to test the proposed algorithm, the year 2019 has been predicted. The accuracy average has been calculated for all the advances of all the hours of the year. Random selection performs worse for almost all cases; it is also inconsistent, so it is ruled out as a candidate. On the contrary, the proposed algorithm offers significantly better precision than the rest of the methods.
The year 2019 has been predicted with every method. In most advances, the optimized algorithm performs better than other methods. As a final result, the year 2019 has been predicted with the current REE schedule, the algorithm, and by calculating all future hours. Except for the ninth day in advance, the algorithm always offers better accuracy. The Optimized Algorithm has a global improvement compared to the current schedule.
7. Computational burden
Last-day selection and optimized algorithm manage to compute predictions under 7 min and the first one requires less time. However, the optimized algorithm offers better accuracy in most cases.
The Spanish electricity system operator requires future load of 19 electrical regions. Nowadays, the entire forecasting horizon spans up to 240 h, thus the total of future loads that can be predicted extends to 4560, which require 10.16 min. However, if the quarter-hour system is employed, the number of future intervals to forecast will multiply by four. This new system will entail 18,240 numbers to be calculated in 40.62 min, which is unfeasible since REE requires results before 7 min have passed.
According to Equation (1) and quarter-hour intervals, the maximum number of forecasts to compute in 7 min is 3140. So, there is time to forecast 165 intervals in every electrical region. Therefore 165 is the maximum value that can be used on the algorithm as number N of forecasts.
8. Conclusions
This research has developed an algorithm that organizes the calculation schedule of a STLF system throughout the day. The schedule obtained is adapted to the computational capacity of the computer while actually increasing the system accuracy. The methodology can be applied to any forecasting technique, even if computational burden is not an issue because it has been proven that limiting the number of forecasts can be beneficial for accuracy, as it has been demonstrated for the case of REE.
On the other hand, according to results, the main contribution of the work is to reduce the computational load of a predictive system without sacrificing accuracy. This will allow a transition to the quarter-hour system with an optimal execution schedule.
This paper offers a first approach to improving forecasting systems through calculation planning. Applying a similar study to other time series prediction systems could improve them in a similar way. As future work, it is proposed to use the algorithm to plan the new quarter-hour system of the Spanish TSO.
This entry is adapted from the peer-reviewed paper 10.3390/en15103670
References
- Weicong Kong; Zhao Yang Dong; David J. Hill; Fengji Luo; Yan Xu; Short-Term Residential Load Forecasting Based on Resident Behaviour Learning. IEEE Transactions on Power Systems 2017, 33, 1087-1088, 10.1109/tpwrs.2017.2688178.
- Qifang Chen; Mingchao Xia; Teng Lu; Xichen Jiang; Wenxia Liu; Qinfei Sun; Short-Term Load Forecasting Based on Deep Learning for End-User Transformer Subject to Volatile Electric Heating Loads. IEEE Access 2019, 7, 162697-162707, 10.1109/access.2019.2949726.
- Dong-Xiao Niu; Qiang Wanq; Jin-Chao Li; Short term load forecasting model using support vector machine based on artificial neural network. 2005 International Conference on Machine Learning and Cybernetics 2005, 7, 4260, 10.1109/icmlc.2005.1527685.
- Singh, S.; Hussain, S.; Bazaz, M.A. Short Term Load Forecasting Using Artificial Neural Network. In Proceedings of the 2017 Fourth International Conference on Image Information Processing (ICIIP), Shimla, India, 21–23 December 2017; p. 5.
- Kunjin Chen; Kunlong Chen; Qin Wang; Ziyu He; Jun Hu; Jinliang He; Short-Term Load Forecasting With Deep Residual Networks. IEEE Transactions on Smart Grid 2018, 10, 3943-3952, 10.1109/tsg.2018.2844307.
- Pu Wang; Bidong Liu; Tao Hong; Electric load forecasting with recency effect: A big data approach. International Journal of Forecasting 2016, 32, 585-597, 10.1016/j.ijforecast.2015.09.006.
- Yang, L.; Yang, H. A Combined ARIMA-PPR Model for Short-Term Load Forecasting. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies—Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; pp. 3363–3367.
- Miguel López; Sergio Valero; Ana Rodriguez; Iago Veiras; Carolina Senabre; New online load forecasting system for the Spanish Transport System Operator. Electric Power Systems Research 2017, 154, 401-412, 10.1016/j.epsr.2017.09.003.
- Filippo Maria Bianchi; Enrico De Santis; Antonello Rizzi; Alireza Sadeghian; Short-Term Electric Load Forecasting Using Echo State Networks and PCA Decomposition. IEEE Access 2015, 3, 1931-1943, 10.1109/access.2015.2485943.
- Ma, Y.; Zhang, Q.; Ding, J.; Wang, Q.; Ma, J. Short Term Load Forecasting Based on iForest-LSTM. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 2278–2282.
- Oveis Abedinia; Nima Amjady; Hamidreza Zareipour; A New Feature Selection Technique for Load and Price Forecast of Electrical Power Systems. IEEE Transactions on Power Systems 2016, 32, 62-74, 10.1109/tpwrs.2016.2556620.
- Abdullah Al Mamun; Sohel; Naeem Mohammad; Samiul Haque Sunny; Debopriya Roy Dipta; Eklas Hossain; A Comprehensive Review of the Load Forecasting Techniques Using Single and Hybrid Predictive Models. IEEE Access 2020, 8, 134911-134939, 10.1109/access.2020.3010702.
- H.S. Hippert; Carlos Eduardo Pedreira; R.C. Souza; Neural networks for short-term load forecasting: a review and evaluation. IEEE Transactions on Power Systems 2001, 16, 44-55, 10.1109/59.910780.
- Tao Hong; Shu Fan; Probabilistic electric load forecasting: A tutorial review. International Journal of Forecasting 2016, 32, 914-938, 10.1016/j.ijforecast.2015.11.011.
- Miguel López; Carlos Sans; Sergio Valero; Carolina Senabre; Empirical Comparison of Neural Network and Auto-Regressive Models in Short-Term Load Forecasting. Energies 2018, 11, 2080, 10.3390/en11082080.
- Sethi, R.; Kleissl, J. Comparison of Short-Term Load Forecasting Techniques. In Proceedings of the 2020 IEEE Conference on Technologies for Sustainability (SusTech), Santa Ana, CA, USA, 23–25 April 2020; pp. 1–6.
- Jie-sheng, W.; Qing-wen, Z. Short-term electricity load forecast performance comparison based on four neural network models. In Proceedings of the The 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 2928–2932
- Mehmood, S.T.; El-Hawary, M. Performance Evaluation of New and Advanced Neural Networks for Short Term Load Forecasting. In Proceedings of the 2014 IEEE Electrical Power and Energy Conference, Calgary, AB, Canada, 12–14 November 2014; pp. 202–207
- Xiaorong Sun; Peter B. Luh; Kwok Cheung; Wei Guan; Laurent D. Michel; S. S. Venkata; Melanie T. Miller; An Efficient Approach to Short-Term Load Forecasting at the Distribution Level. IEEE Transactions on Power Systems 2015, 31, 2526-2537, 10.1109/tpwrs.2015.2489679.
- Rafi, S.H.; Nahid-Al-Masood, N.-A.-M. Highly Efficient Short Term Load Forecasting Scheme Using Long Short Term Memory Network. In Proceedings of the 2020 8th International Electrical Engineering Congress (iEECON), Chiang Mai, Thailand, 4–6 March 2020; pp. 1–4
- Weicong Kong; Zhao Yang Dong; Youwei Jia; David J. Hill; Yan Xu; Yuan Zhang; Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Transactions on Smart Grid 2017, 10, 841-851, 10.1109/tsg.2017.2753802.
- Shafiul Hasan Rafi; Nahid- Al Masood; Shohana Rahman Deeba; Eklas Hossain; A Short-Term Load Forecasting Method Using Integrated CNN and LSTM Network. IEEE Access 2021, 9, 32436-32448, 10.1109/access.2021.3060654.
- Mohammed, J.; Bahadoorsingh, S.; Ramsamooj, N.; Sharma, C. Performance of exponential smoothing, a neural network and a hybrid algorithm to the short term load forecasting of batch and continuous loads. In Proceedings of the 2017 IEEE Manchester Power Tech, Manchester, UK, 18–22 June 2017; pp. 1–6.
- Veljanovski, G.; Atanasovski, M.; Kostov, M.; Popovski, P. Application of Neural Networks for Short Term Load Forecasting in Power System of North Macedonia. In Proceedings of the 2020 55th International Scientific Conference on Information, Communication and Energy Systems and Technologies (ICEST), Niš, Serbia, 10–12 September 2020; pp. 99–101.
- Weyermüller, E.; Vermeulen, H.J.; Groch, M. Short-Term Load Forecasting using Minimalistic Adaptive Neuro Fuzzy Inference Systems. In Proceedings of the 2020 International SAUPEC/RobMech/PRASA Conference, Cape Town, South Africa, 29–31 January 2020; pp. 1–6.
- Shufen Liu; Songyuan Gu; Tie Bao; An Automatic Forecasting Method for Time Series. Chinese Journal of Electronics 2017, 26, 445-452, 10.1049/cje.2017.01.011.
- Panapongpakorn, T.; Banjerdpongchai, D. Short-Term Load Forecast for Energy Management Systems Using Time Series Analysis and Neural Network Method with Average True Range. In Proceedings of the 2019 First International Symposium on Instrumentation, Control, Artificial Intelligence, and Robotics (ICA-SYMP), Bangkok, Thailand, 16–18 January 2019; pp. 86–89.
- Di, S. Power System Short Term Load Forecasting Based on Weather Factors. In Proceedings of the 2020 3rd World Conference on Mechanical Engineering and Intelligent Manufacturing (WCMEIM), Shanghai, China, 4–6 December 2020; pp. 694–698.
- Huaiguang Jiang; Yingchen Zhang; Eduard Muljadi; Jun Jason Zhang; David Wenzhong Gao; A Short-Term and High-Resolution Distribution System Load Forecasting Approach Using Support Vector Regression With Hybrid Parameters Optimization. IEEE Transactions on Smart Grid 2016, 9, 3341-3350, 10.1109/tsg.2016.2628061.
- Amelia McIlvenna; Andrew Herron; Joshua Hambrick; Ben Ollis; James Ostrowski; Reducing the computational burden of a microgrid energy management system. Computers & Industrial Engineering 2020, 143, 106384, 10.1016/j.cie.2020.106384.
- Weimar, M.; Somani, A.; Etingov, P.; Miller, L.; Makarov, Y.; Loutan, C.; Katzenstein, W. Benefit Cost Analysis of Improved Forecasting for Day-Ahead Hourly Regulation Requirements. In Proceedings of the 2018 IEEE Power Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018; pp. 1–5.
- Miguel López; Carlos Sans; Sergio Valero; Carolina Senabre; Classification of Special Days in Short-Term Load Forecasting: The Spanish Case Study. Energies 2019, 12, 1253, 10.3390/en12071253.