Polygenic diseases, which are genetic disorders caused by the combined action of multiple genes, pose unique and significant challenges for the diagnosis and management of affected patients. A major goal of cardiovascular medicine has been to understand how genetic variation leads to the clinical heterogeneity seen in polygenic cardiovascular diseases (CVDs). Recent advances and emerging technologies in artificial intelligence (AI), coupled with the ever-increasing availability of next generation sequencing (NGS) technologies, now provide researchers with unprecedented possibilities for dynamic and complex biological genomic analyses. Combining these technologies may lead to a deeper understanding of heterogeneous polygenic CVDs, better prognostic guidance, and, ultimately, greater personalized medicine. Advances will likely be achieved through increasingly frequent and robust genomic characterization of patients, as well the integration of genomic data with other clinical data, such as cardiac imaging, coronary angiography, and clinical biomarkers.
1. Introduction
Multiple diseases of the cardiovascular system are associated with genetic polymorphisms including both common conditions, such as hypercholesterolemia [
1,
2] and less common conditions, such as cardiac channelopathies [
3], cardiomyopathies [
4], aortopathies [
5], and various structural and congenital diseases of the heart and great vessels [
6]. Given that the fields of cardiovascular genetics and precision medicine are rapidly evolving, it is unsurprising that recently published guidelines include an increased focus on genetic testing. The 2020 Scientific Statement From the American Heart Association (AHA) on Genetic Testing for Inherited Cardiovascular Diseases recommended testing specific genes in certain monogenic cardiovascular diseases (CVDs) in appropriate clinical circumstances [
7] (e.g.,
LDLR,
APOB, and
PCSK9 genes for familial hypercholesterolemia, and
TTN,
LMNA,
MYH7,
TNNT2,
BAG3,
RBM20,
TNNC1,
TNNI3,
TPM1,
SCN5A, and
PLN genes for dilated cardiomyopathy). The 2021 Scientific Statement from the AHA on Genetic Testing for Heritable Cardiovascular Diseases in Pediatric Patients also recommended cardiovascular genetic testing in children as an important component in determining the risk of developing heritable cardiovascular diseases in adulthood [
8].
Artificial intelligence (AI) is a discipline of computer science that aims to mimic human thought processes, learning capacity, and knowledge storage [
11]. A central tenet of AI is learning the value of potential choices rather than rigidly following predetermined thresholds or procedures, e.g., optimizing the selection of variants to maximize the predictive accuracy for disease risk rather than using a predetermined list. AI involves several components, including machine learning and deep learning, with increasing potential to explore novel CVD genotypes and phenotypes, among many other exciting opportunities.
2. Genetic Testing Gap in Cardiovascular Diseases
The majority of CVDs and cardiovascular risk factors have a significant genetic component, which is most commonly polygenic in origin [
1,
2]. Current clinical practice utilizes a patient’s medical history, family history, physical examination, cardiac biomarkers, and various modalities of cardiac imaging to establish diagnoses and to stratify risks. Despite rapid advances and availability of genetic testing panels, clinicians seldom utilize genetic testing as part of their initial patient assessments beyond cases with a known family history of genetic, inherited CVDs (e.g., HCM, arrhythmogenic right ventricular cardiomyopathy (ARVC), long QT syndrome (LQTS), or catecholaminergic polymorphic ventricular tachycardia (CPVT)). This lack of routine testing as part of care pathway creates a “diagnostic gap” (i.e., a delay in time from disease manifestation to establishing a definitive diagnosis) that can lead to inappropriate or ineffective treatment in patients suffering from inherited CVDs.
Despite its demonstrated clinical relevance, current guidelines only recommend genomic testing for a small number of cardiac conditions (e.g., HCM, familial hypercholesterolemia), limited by the relatively few genetic tests that are currently available and the lack of strong studies in cardiovascular genetics [
13,
14]. For example, Brugada syndrome has a large number of potentially pathogenic genetic variants (e.g.,
CACNA1C,
GPD1L,
HEY2,
PKP2,
RANGRF,
SCN10A,
SCN1B,
SCN2B,
SCN3B,
SLMAP, and
TRPM4) but current guidelines continue to recommend a comprehensive genetic analysis for only Brugada syndrome caused by the
SCN5A genetic variant [
15,
16]. With advancements in genetic testing technologies, preemptive genetic testing for various cardiomyopathies may be useful in the presence of an asymptomatic type 1 Brugada ECG pattern, family history of dilated cardiomyopathy, or the development of spontaneous coronary artery dissection (SCAD).
3. Next Generation Sequencing (NGS) in the Modern Clinic
Genomics is becoming nearly ubiquitous in biomedical research [
17]. Large-scale sequencing efforts have revolutionized our understanding of the complex genetic interrelationships involved in the pathogenesis of most cardiovascular conditions [
18]. The tremendous advancements in genomic research are largely driven by the advent of NGS, which has led to the discovery of novel associations and the ability to more easily assess genetic heterogeneity across patients. Several categories of NGS include: (1) whole genome sequencing (WGS); (2) whole exome sequencing (WES), where the sequencing is concentrated over the protein-coding regions of the genome (~2% of the genome); and (3) gene panels, where very deep coverage (>100× coverage) is generated for a select number of genes. Both WGS and WES allow for the accurate identification of single-nucleotide variants (SNVs), large copy number variations (CNVs), small insertion deletions (InDels), and information on variant frequencies in different populations [
19]. Because WGS examines the noncoding regions of the genome, it offers a more comprehensive appraisal of both small and large genomic risk variants for CVDs. However, WGS is more costly and time-consuming than WES, and may be limited by lower depth [
20,
21]. Conversely, the results of WES, while more limited in scope, are typically viewed as more straightforward to interpret and historically have been a useful method to identify variants causing Mendelian disease. Panel-based NGS relies on high sequencing depth of previously determined important genetic loci, making this kind of testing more resource-efficient. However, the narrow focus of this type of assay results in decreased power to detect novel associations and is often less effective for assessing other types of genetic alterations, such as structural variants. Although NGS is now widely used due to its speed, robustness, and cost-effectiveness, orthogonal confirmation with the traditional Sanger sequencing method is sometimes still required for validation prior to clinical use [
22,
23,
24].
Nonetheless, the implementation of AI to NGS and genomics has already been shown to accurately predict the consequences of genetic risk factors in CVDs [
25,
26], show the noncoding-variant effects in CVDs [
27,
28], find patients with cardiac amyloidosis [
29,
30], and initiate specific therapies from tumor sequencing [
31] by integrating with electronic health records (EHRs) in several academic and medical institutions. Additionally, there are several direct-to-consumer genomics companies that use AI along with WGS and WES; however, to date, these applications have been limited by a lack of transparency in the algorithms they utilize due to their proprietary nature and commercial competition, as well as a lack of a consistent validation cohort, genomic guided clinical trials, and high-quality phenotype data that are consistently encoded and managed. Although some direct-to-consumer companies have collaborated with academic institutions and published their methodologies, evidence for their clinical relevance remains scarce.
4. Introduction of AI to Clinical Cardiovascular Genetics
AI encompasses a broad range of applications for automated reasoning and inference, and is starting to have a major impact on clinical assessment and diagnosis. For example, in both United States of America (US) and United Kingdom (UK) datasets, AI outperformed human radiologists in screening mammography (greater than the AUC-ROC for the average radiologist by an absolute margin of 11.5%) and significantly reduced false positives and false negatives [
32]. The most widely used groups of methods for pattern recognition in genomics include machine learning (ML) and deep learning (DL). Other AI approaches, for example natural language processing (NLP) and cognitive computing, are also starting to play a role in cardiovascular clinical care to enable more natural interactions between clinicians and computational systems [
33,
34,
35]. Notably, the Food and Drug Administration (FDA) has been rapidly approving AI/ML-based medical devices and algorithms. Therefore, it is crucial for medical professionals to understand how best to utilize them. In a recent study using a web-based search for announcements of FDA approvals of AI/ML-based medical devices and algorithms, of the 64 found, 30 (46.9%), 16 (25.0%), and 10 (15.6%) were developed for the fields of radiology, cardiology, and internal medicine/general practice, respectively [
36]. These AI approaches fundamentally work to train programs to recognize relationships within data.
Table 2 provides examples of variant calling, reporting, and interpretation AI.
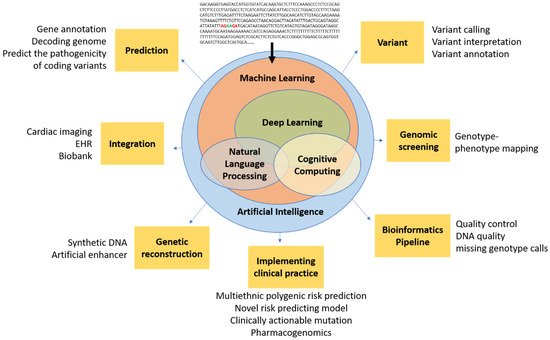
Figure 1 demonstrates the potential of AI in cardiovascular genetics.
Figure 1. Conceptual schematic for artificial intelligence in cardiovascular genetics. Artificial intelligence encompasses a spectrum of concepts, including machine learning, NLP, and cognitive computing, which are generally enabled by deep learning and could ultimately be used in cardiovascular genomics for prediction, integration, reconstruction, bioinformatic techniques (e.g., pipeline, screening, variant analysis), and clinical practice. Artificial intelligence has the potential to filter raw genetic data into novel insights that could inform future clinical trials and, ultimately, clinical practice.
Table 2. Examples of variant calling, reporting, and interpretation AI.
| Name |
Algorithms |
Example Function |
| DeepVariant [37] |
Deep convolutional neural network (CNN) |
Variant calling from short-read sequencing by reconstructing DNA alignments as an image |
| Clairvoyante [38] |
A multi-task convolutional deep neural network |
(1) Variant calling in single molecule sequencing
(2) Predicts variant types (SNP or indel), zygosity, and alleles at the same time |
| Skyhawk [39] |
Neural network |
Mimics the process of expert review for clinically significant genomics variants identification |
| DeepBind [40] |
Deep CNN |
Predicts the binding sites of DNA-binding proteins and RBPs |
| iDeep [41] |
Deep belief networks (DBN) and CNN |
Cross-domain features and sequence information |
| DeepSEA [42] |
Deep CNN |
Predicts functional consequences of noncoding variants |
| DeepNano [43] |
Recurrent neural networks (RNN) |
Base calling in MinION nanopore reads |
| SpliceAI [44] |
Deep neural network (DNN) |
(1) Predicts splice junctions from an arbitrary pre-mRNA transcript sequence
(2) Predicts noncoding genetic variants that cause cryptic splicing |
| DeepGestalt [45] |
DNN |
Distinguishes more than 200 rare diseases based on patient face images, which could also separate different genetic subtypes (e.g., Noonan syndrome) |
| DeepPVP [46] |
DNN |
Variant prioritization by integrating patients’ phenotype information |
| DeepSVR [47] |
Deep learning and random forest models |
Predicts somatic variants confirmed by orthogonal validation sequencing data |
| DeepGene [48] |
DNN |
Extracts the high-level features between combinatorial somatic point mutations and cancer types.
Classify cancer type |
| Deep AE [49] |
Autoencoder |
gene expression data |
| DeepMethyl [50] |
|
Predicts methylation states of DNA CpG dinucleotides |
| BioVec [51] |
|
Feature representation |
| DeepMotif [52] |
Deep convolutional/highway MLP framework |
Sequential data about gene regulation |
| DeepChrome [53] |
Deep CNN |
Sequential data about gene regulation
Classifies gene expression using histone modification data as input. |
| Chiron [54] |
Deep learning model |
Translates the raw signal to DNA sequence |
| Variational Autoencoders [55] |
Autoencoder |
Predicts drug response |
| GARFIELD-NGS [56] |
Deep CNN |
Dissects false and true variants in exome sequencing |
| DeepGS [57] |
Deep CNN |
Predicts phenotypes from genotypes |
| DANN [58] |
DNN |
Predicts deleterious annotation or pathogenicity of genetic variants |
| DanQ [59] |
Hybrid model Deep RNN and CNN |
Quantifies the function of non-coding DNA |
| ProLanGO [60] |
RNN |
Protein function prediction |
| BCC-NER [61] |
NLP |
Bidirectional and contextual clues named entity tagger for gene/protein mention recognition |
| BioNLP [62] |
NLP |
Gene regulation network |
| SpaCy [63] |
NLP |
Tagging, parsing, and entity recognition |
5. Current Limitations in Genomics and Potential Solutions with AI
5.1. Lack of Clinical and Technical Guidelines for Cardiovascular Genetics
Currently in clinical cardiovascular genetics, the guidelines do not specify which genes should be tested or how to validate the results. For example, the 2019 HRS Expert Consensus Statement on Evaluation, Risk Stratification, and Management of Arrhythmogenic Cardiomyopathy did not define how genetic testing should be validated or carried out in ARVC and other arrhythmogenic cardiomyopathies [
107]. Similarly, the 2020 and 2021 scientific statements from the AHA on Genetic Testing for Heritable Cardiovascular Diseases in adult and pediatric patients did not specify how genetic testing should be validated or carried out in heritable cardiovascular diseases [
7,
8].
At a more rudimentary level, the Clinical Laboratory Improvement Amendment (CLIA) and the College of American Pathologists (CAP) have left many inconsistencies and regulatory gaps in their guidance for wet and dry labs [
108], resulting in heterogeneous variant reporting. Moreover, CAP/CLIA regulations only require that validation is performed in the production environment, which may lead to unexpected errors in the production phase. Bioinformatics pipelines should be validated and tested for how precisely and sensitively variants are called in wet labs. Technical variability in the QC process, such as consistency of sequencing [
109], QC standardization [
110], and DNA quality [
111,
112], has been highly problematic; however, with current technologies, the accuracy of SNV is generally very robust (particularly if 30x or greater sequencing coverage is available).
Another major barrier to current cardiovascular genetic research is the lack of professional recommendations for the clinical integration of genomics. Several clinical research projects using different genomics databases (e.g., UK Biobank [
67], MESA [
122], and ARIC [
123]) have demonstrated accurate ML model discrimination and calibration (e.g., Brier score) for CVD risk prediction using genetics, but there are as yet no specific guidelines for genetic testing in clinical practice or regulatory guidance for direct-to-consumer products.
5.2. Variant Calling, Reporting, and Interpretation
Variant calling is used to identify the differences between an individual genome and a reference genome. Despite CLIA approval, there are no guidelines for approval of informatics pipelines for variant calling. There are several variant-related tasks (e.g., read alignment, variant calling, reporting, and interpretation) currently used in genomics screening, the identification of probands, and cascade testing in CVD where AI could be applied. The discrepancies in variant calling between labs, largely because of the lack of clear guidelines, are magnified when undertaking the task of distinguishing true genetic variants from spurious differences introduced by sequencing errors, alignments errors, and other technical artifacts. Other limitations of variant calling include a lack of consensus between variant calling pipelines when analyzing the same data [
125], variable accuracies of variant calling algorithms when using different AI technologies, and comparison sequencing of only a limited gene panel. Importantly, AI-driven software, such as DeepVariant, Clairvoyante [
38], and Skyhawk [
39], have already been used to automatically recognize and prioritize variants with substantially improved accuracy when compared to more traditional statistical models. For example, Google’s DeepVariant uses image recognition techniques and pre-trained models (e.g., inception-v3, variants of CNN model [
87]) to pre-process inputs, make inferences, call variants, and then output variant calling format (VCF) files with the variant information. This represents a potential AI solution to the current inconsistencies in variant calling.
5.3. Combining Genomics with Other Clinical Data Types
Cardiovascular genetics is challenging because both the clinical variables associated with CVDs and the genomics data are heterogeneous and often involve complex interactions between a patient’s genetics and environmental factors. This challenge is largely why applying AI to these multiple types of data is a very promising research direction, and may be especially useful in classifying genome-phenome relationships in CVD using EHRs [
133]. For example, combining genomic data describing different septal morphologies of HCM [
134,
135] with clinical information from echocardiography and angiography could help personalize therapy for individual patients (e.g., deciding if a particular HCM patient needs an ICD). Echo-guided genetic testing or genetic-guided PCI [
136] and DAPT duration (e.g., high- vs. low-risk bleeding loci) would also be useful applications of this technology. Another potential application worth researching is the diagnosis of diastolic dysfunction using a combination of echo parameters (e.g., LAVI, E/A ratio, annular e’ velocity, and peak TR velocity) and genetic predispositions since normal diastolic function changes with age [
70,
71,
137]. Precision statin therapy is another potential application for the integration of multiple data types by AI. For instance, in a young female without traditional atherosclerotic risk factors, a combination of genetic testing (e.g., Lp (a), apo C genes) and cardiac imaging (e.g., coronary CT) may reveal a clinical need for preventative statin therapy, which would otherwise never be considered.
5.4. Lack of Population Specific Analysis Tools
Across all fields of medicine and research, population-specific analysis tools and databases that can detect population-specific risk factors are urgently needed. Unfortunately, in most cases, including in CV research, significant disparities in research for different ethnicities remain. The pooled cohort equations (PCE) is the cornerstone for atherosclerotic cardiovascular disease (ASCVD) risk stratification and statin treatment decisions [
14]. However, the PCE computation mainly focuses on the Caucasian population and overestimates ASCVD risk in Asian and Hispanic populations. Although PCE computations exclude genetic components, the ethnicity disparity is not limited to cardiovascular genetic research [
150]. While genomic research in Asian ancestry and African ancestry has increased in recent times [
151,
152], more than 90% of genomic research has been conducted in patients of mainly European ancestry [
153,
154]. Furthermore, while most GWAS attempts can control bias of population stratification, fully correcting for population stratification can be challenging and the lack of ethnic diversity included can affect the analysis of gene–environment interactions [
155]. Therefore, a major challenge for applying AI more widely is the lack of publicly available non-European genetic databases. In addition, PRS is an emerging technique for assigning genetic risk to individual outcomes that outperforms traditional risk scores [
156], but the performance of translating PRS from European ancestry to different ethnicities is largely unknown and not validated [
157]. The AI technique of transfer learning could potentially be used to bridge this gap.
6. Current Limitations in AI Cardiovascular Genetics
Despite steadfast advances, implementing AI in cardiovascular genomics still faces several challenges, including generalizability of results, the required construction of large genomic datasets, and limited computing power. Ultimately, the largest barrier remains the ability of clinicians to implement findings from AI studies.
The first challenge that plagues AI is overfitting an algorithm to a dataset that may adversely affect the generalizability of the results. Generalizability can be partially assessed by evaluating the overfitting of a new dataset. For instance, the results of applying DL models to diabetic retinopathy could not be replicated in different datasets [
164,
165], and AI methods lack validation data when applied to disease-associated non-coding variants [
166,
167].
Despite the promise of various AI methods, genomic datasets themselves have built-in limitations: the costs incurred remains a large barrier to performing thorough studies; heterogeneous genetic conditions, such as dilated cardiomyopathy, lack known outputs; and the rarity of specific conditions results in unbalanced case-control studies. These are important limitations when considering the construction of a genomics dataset. Currently, there is not a consensus or indication for genetic testing across several entities within CVD. For patients who undergo genetic testing, the sample can undergo a variety of sequencing techniques that differ between vendors, affecting the quality of the resulting data and confounding interpretation.
An equally important barrier to integrating AI study results into clinical practice is the fact that physicians currently lack the necessary access as well as education and training to interpret results from AI studies on genomic data [
173,
174]. To facilitate clinical adoption, AI can fill the gap in knowledge in clinical practice with automated analysis to detect clinically actionable mutations. However, there is a figurative territorial embargo which limits medical genetics to trained specialists because of the complexity of handling genomic data, rather than a democratization and availability of this technology to all clinicians and patients. Emerging technology, such as homomorphic encryption or blockchains, which can provide an immediate and transparent exchange of encrypted data simultaneously to multiple parties, may be able to fill this gap by at least ensuring data security in handling genomic data. However, there is no process for lifelong interrogation of such data, nor is there specialty infrastructure or funding processes capable of handling that. Most importantly, the main challenge is “trust” in data stewardship. AI has the promise to do automated analyses, but there is no agreement over the format, interpretation, reliability, or reproducibility of the results.
Finally, the quality of genomic data between direct-to-consumer companies and clinical or academic institutions may affect the availability and accuracy of “raw data” for AI to analyze. Genotyping data from direct-to-consumer companies, even those that are CLIA certified, contain errors and potentially high false-positive rates (up to 40%) [
178]. For example, there is inconsistent labelling of
COL3A1 and
COL5A1 mutations (known to be associated with Ehlers–Danlos syndrome and SCAD) between laboratories [
178]. Therefore, standard measures for correlating and combining data from direct-to-consumer and data from clinical or academic institutions are urgently needed. Beyond the technical issues of how variants are reported, there are also substantial privacy concerns involved when sharing genetic data with a direct-to-consumer company. As a minimum, advanced encryption is certainly required to maintain patient privacy.
This entry is adapted from the peer-reviewed paper 10.3390/life12020279