Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Subjects:
Computer Science, Information Systems
General overview of the different mentioned paradigms needs to be provided in order to be oriented in the computing field. For clarity and consistency, each paradigm is carefully discussed concisely in the oncoming text. The reason for discussing each of these paradigms is to have an overview that will guide the understanding of the research goal for this paper, which is primarily the information security and privacy aspects for each paradigm.
- computing
- survey
- security
- privacy
- distributed systems
1. Cloud-Related Aspects
Historically, the growth and expansion of the infrastructures of many companies have come from evolving technologies and innovations. Cloud computing is seen as a unique solution to provide applications for enterprises [11]. It uses different components such as hardware and software to render services, especially over the Internet. The possibility of accessing various data and applications provided was originally made straightforward by Cloud computing.
Several industrial giants and standardization bodies attempted to define Cloud computing in their understandings and views. The National Institute of Standards and Technology (NIST) is widely considered to provide the most reliable and precise definition for Cloud computing as “a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction” [12].
Five different models particularly characterize Cloud computing: on-demand self-service, broad network access, multi-tenancy and resource pooling, rapid elasticity, and scalability. Generally, more Cloud computing resources can be provided as required by manufacturers and different enterprises while avoiding interactions with humans involving service providers, e.g., database instances, storage space, virtual machines, and many others. Having access to corporate Cloud accounts is essential as it helps corporations to virtualize the various services, Cloud usage, and supply of services as demanded [13].
Simultaneously, there is a need for broad network access, i.e., accessing capabilities via established channels across the network advance the use of heterogeneous thick and thin customer devices such as workstations, tablets, laptops, and mobile phones [14]. This access leads to the resource pooling aspect, i.e., computing resources from the provider are grouped using a particular multi-tenant model used in serving various clients. The unseen and non-virtual resources are carefully allocated and reallocated according to the customer’s needs. Usually, customers do not understand or access the spot-on position or area provided. However, location specification can be established at an advanced state of situation or abstraction followed by various examples of resources such as network bandwidth, processing, memory, and storage [15].
Such a massive heterogeneous environment leads to the scalability aspect [16]. The growth of a client marketplace or business is made possible due to the tremendous ability to create specific Cloud resources, enabling improvement or reducing costs. Sometimes, changes might occur on the user’s need for Cloud computing, which will be immediately responded to by the platform or system.
Finally, the resource use is keenly observed, regulated, and feedback is given to established billing based on usage (e.g., accounts of frequent customers, bandwidth, processing, and storage). The proper reporting of essential services used can be done transparently if the used resources are adequately looked into, controlled and account is given [12].
From the architectural perspective, big, medium, and small enterprises use Cloud computing technology to save or store vital data in the Cloud, enabling them to access this stored information from any part of the world via connecting to the Internet. Service-oriented and event-driven architectures are the main combination that makes up the Cloud computing architecture. The two important parts dividing the Cloud computing architecture are naturally Front End (FE) and Back End (BE) [17].
As seen in Figure 1, various components are involved in the computing architecture [6]. Furthermore, we take a brief look at each architecture’s different features. Furthermore, we can see that a network connects both front and back ends via the wired or wireless medium.
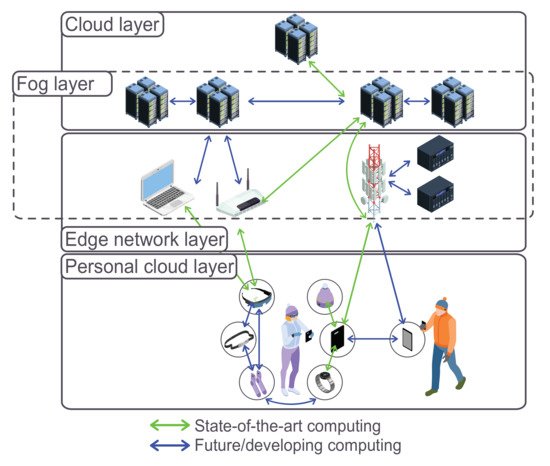
Figure 1. Most common task offloading models.
2. Edge-Related Aspects
As a new generation of computational offloading, Edge arrived to allocate the resources at the network edge, i.e., closer to various office and home appliances such as mobile devices, Internet of Things (IoT) devices, clients, and client’s sensors. In recent years, there has been fast growth in industrial and research investment in Edge computing. The pivot for Edge computing is the physical availability and closeness, of which end-to-end latency is influenced by this essential point of Cloudlets, with bandwidth achievable economically, trust creation, and ability to survive [18].
Communication overheads between a customer and a server site are reduced due to a decrease in actual transmission distances (in terms of geography and number of hops) brought about by the Edge computing in the network. As one of the definitions, “Edge computing is a networking philosophy focused on bringing computing as close to the source of data as possible to reduce latency and bandwidth use. In simpler terms, Edge computing means running fewer processes in the Cloud and moving those processes to local places, such as on a user’s computer, an IoT device, or an Edge server” [19]. Some other definitions of Edge computing are “a physical compute infrastructure positioned on the spectrum between the device and the hyper-scale Cloud, supporting various applications. Edge computing brings processing capabilities closer to the end-user/device/source of data which eliminates the journey to the Cloud data center and reduces latency” [20]. There are several cases in which architectural designs are specifically intended, considering their work plan and setting up the infrastructure is based on its need.
Considered a state-of-the-art paradigm, Edge computing takes services and applications from the Cloud known to be centralized to the nearest sites to the main source and offers computational power to process data. It also provides added links for connecting the Cloud and the end-user devices. One of the best ways to solve or reduce Cloud computing issues is to make sure there is an increase in Edge nodes in a particular location, which will also help in decreasing the number of devices attributed to a sole Cloud [21].
Overall, the main Edge service consumers are resource-constrained devices, e.g., wearables, tracker bands for fitness and medical uses, or smartphones [22]. Fog devices, in turn, subdues the shortcomings of Cloud by transferring some of the core functions of Cloud towards the network Edge while keeping the Cloud-like operation possible [23], e.g., Edge and Fog nodes may act as interfaces attaching these devices to the Cloud [24].
A typical Edge computing architecture comprises three important nodes (see Figure 1): the Cloud, local Edge, and the Edge Device. Notably, Local Edge involves a well-defined structure with several sublayers of different Edge servers with a bottom-up power flow in computation. Both Access Points (APs) and Base Stations (BSs) are Edge servers situated at the sublayer considered to be the lowest together with proximity-based communications [25]. These are particularly installed to obtain data during communication from various Edge devices, returning a control flow using several wireless interfaces.
Cellular BSs transmit the data to the Edge servers found in the (upper) sublayer after receiving data from Edge devices. Here, the upper sublayer is particularly concerned with operating computation work. Very fundamental analysis and computation are done after data are forwarded from BSs. At a recent Edge server, the computational restriction is placed such that if the difficulty in a given work surpasses it, the work is offloaded and sent to the upper sublayers with adequate computation abilities. A chain of flow control is then concluded by these servers with passing back to the access points, and finally, in the end, send them to Edge devices [26].
The Edge architecture allowed to switch more delay intolerant applications closer to the computation demanders, e.g., Augmented/Virtual/Mixed Reality (AR/VR/MR) gaming, cellular offloading, etc., all together following the proximity-driven nature of the paradigm [27]. Generally, there are two approaches to the proximity between the Edge and user’s equipment: physical and logical proximity.
Physical proximity refers to the exact distance between the top segment of data computation and user equipment. Logical proximity refers to the count of hops between the Edge computing segment and the users’ equipment. There are potential occurrences of congestion because of the lengthy route caused by multiple hops, leading to increased latency issues. To avoid queuing that can result in delays, logical proximity needs to limit such events at the back-haul of the computing network systems.
Despite the shortcomings of the normal Cloud paradigm innovations to match up with great demands, given lower energy level, real-time, and in particular security and privacy aspects, the Edge paradigm is not considered a substitute for the Cloud paradigm. Edge and Cloud paradigms are known to assist each other in a cordial manner in several situations. The Cloud and Edge paradigms cooperate in some network areas, including autonomous cars, industrial Internet, as well as smart cities, offices and homes. Importantly, Edge and Cloud paradigm collaboration offers many chances for reduced latency in robust software such as autonomous cars, network assets of companies, and information analysis on the IoT [28].
Nevertheless, Edge operation is executed through supported capabilities from several actors. Cellular LTE, short-range Bluetooth Low Energy (BLE), Zigbee, and Wi-Fi are various technologies that create connectivity by linking endpoint equipment and nodes of the Edge computing layer. There is great importance for access modalities as it establishes the endpoint equipment bandwidth availability, the connection scope, and the various device type assistance rendered [29].
3. Fog-Related Aspects
Access gateways or set-top-boxes are end devices that can accommodate Fog computing services. The new paradigm infrastructure permits applications to operate nearby to observe activities easily and handle huge data originating from individuals, processes, or items. The creation of automated feedback is a driving value for the Fog computing concept [30]. Customers benefit from Fog and Cloud services, such as storage, computation, application services, and data provision. In general, it is possible to separate Cloud from Fog, which is closer to clients in terms of proximity, mobile assistance for mobility, and dense location sharing [31], while keeping the Cloud functionality in a distributed and transparent for the user manner.
According to NIST, “Fog computing is a layered model for enabling ubiquitous access to a shared continuum of scalable computing resources. The model facilitates the deployment of distributed, latency-aware applications and services, and consists of fog nodes (physical or virtual), residing between smart end-devices and centralized (cloud) services. The fog nodes are context aware and support common data management and communication system. They can be organized in clusters – either vertically (to support isolation), horizontally (to support federation), or relative to fog nodes’ latency-distance to the smart end-devices” [32]. Generally, Fog computing is considered to be an extension or advancement of Cloud computing, as the latter one ideally focuses mostly on a central system for computing, and it occurs on the upper section of the layers, and Fog is responsible for reducing the load at the Edge layer, particularly at the entrance points and for resource-constrained devices [33].
The use of the term “Fog Computing” and “ Edge Computing” refers to the hosting and performing duties from the network end by Fog devices instead of having a centralized Cloud platform. This means putting certain processes, intelligence, and resources to the Cloud’s Edge rather than deriving use and storage in the Cloud. Fog computing is rated as the future huge player when it comes to the Internet of Everything (IoE) [34], and its subgroup of the Internet of Wearable Things (IoWT) [35].
Communication, storage, control, decision-making, and computing close to the Edge of the network are specially chosen by Fog architecture. Here, the executions and data storage are executed to solve the shortcomings of the current infrastructure to access critical missions and use cases, e.g., the data density. OpenFog consortium defines Fog computing as “a horizontal, system-level architecture that distributes computing, storage, control, and networking functions closer to the users along a Cloud-to-thing continuum” [36]. Another definition explains Fog as “an alternative to Cloud computing that puts a substantial amount of storage, communication, control, configuration, measurement, and management at the Edge of a network, rather than establishing channels for the centralized Cloud storage and use, which extends the traditional Cloud computing paradigm to the network Edge” [37].
The deployment of Fog computing systems is somewhat similar to Edge but dedicated to applications that require higher processing power while still being closer to the user. This explains why devices belonging to the Fog are heterogeneous, raising the question of the ability of Fog computing to overcome the newly created adversaries of managing resources and problem-solving in this heterogeneous setup. Therefore, investigation of related areas such as simulations, resource management, deployment matters, services, and fault tolerance are very simple requirements [38].
As of today, Fog computing architecture lacks standardization, and until recently, there is no definite architecture with given criteria. Despite so, many research articles and journals have managed to develop their versions of Fog computing architecture. In this section, an attempted explanation is detailed in an understanding manner, which describes the different components which make up the general architecture [38].
Generally, most of the research projects performed on Fog computing have mostly been represented as a three-layer model in its architecture [39], see Figure 2. Moreover, there is a detailed N-layer reference architecture [40], established by the OpenFog Consortium, being regarded as an improvement to the three-layer model. However, we will be looking at a three-layer architecture.
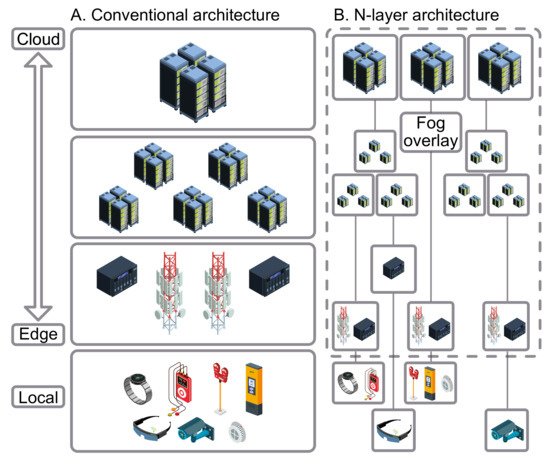
Figure 2. Most commonly analyzed computing architectures.
Fog computing is considered to be non-trivial addition regarding Cloud computing based on Cloud-to-Things setup. In fact, it displays a middle layer (also known as the Fog layer), closing the gap between the local end devices and Cloud infrastructure [41].
Notably, and as in the Cloud, the Fog layer also uses local virtualization technologies. On the other hand, taking into consideration the available resources, it will be more adequate to implement virtualization with container-based solutions [38]. It should also be remembered that Fog nodes found in this layer are large in number. Based on OpenFog Consortium, Fog node is referred to as “the physical and logical network element that implements Fog computing services” [42]. Fog nodes have the capability of performing computation, transmission, and also storing data temporarily and are located in between the Cloud and end-user devices [43].
The essential pushes for the eminent migration from Cloud computing to Fog computing are caused by load from computations and bringing Cloud computing close to Edge. Several characteristics define Fog computing by the tremendous variety of applications and IoT design services [44]. The major one corresponds to the extreme heterogeneity of the ecosystem, which provides services between centralized Cloud and different devices found at the Edge, such as end-user applications via Fog. The heterogeneity of Fog computing servers comprises shared locations with hierarchically structured blocks.
At the same time, the entire system is highly distributed geographically. Fog computing models consist of extensively shared deployments in actuality to offer a Quality of Service (QoS) regarding mobile and non-mobile user appliances [45]. The nodes and sensors of the Fog computing are geographically shared in the case of various stage environments, for instance, monitoring different aspects such as chemical vats, healthcare systems, sensors, and the climate.
The ability to effectively react to the primary goal and objective can be called cognition. Customers’ requirements are better alerted by analytics in a Fog-focused data gateway, which helps give a good position to understand where to make a transmission, storage possibilities, and the control operations along the whole process from Cloud to the Internet of Things continuum. Customers enjoy the best experience due to applications’ closeness to user devices and creating a better precision and reactiveness concerning the clients’ needs [46].
4. Differences and Similarities of Paradigms
The main goal of Fog and Edge paradigms are similar in some areas, unlike the Cloud. Both of those bring the capabilities of the Cloud closer to the users and offer customers with lower latency services while making sure, on the one hand, that highly delay-tolerant applications would achieve the required QoS, and, on the other hand, lowering the overall network load [47]. It is not straightforward to differentiate and compare Cloud, Edge, and Fog Computing. This subsection attempts to discern and look into similar features between the computing paradigms [48]. The differences and similarities of the various paradigms are summarized in Table 1.
Table 1. Comparison on different computing paradigms.
Nonetheless, it is essential to overview each of these indicated paradigms to address security and privacy aspects in Cloud, Edge, and Fog paradigms. This subsection described some fundamental features that constitute each of the said paradigms, making them unique in their ways. We looked into the different architectures, how these paradigms are characterized and how beneficial they are to the industries, and addressed some scenarios in which they are applied.
Cloud being a centralized architecture and an IoT promoter has several shortcomings such as high latency, location sensibility, and computation time, just to name a few. Researchers then suggested upgraded technologies known as Edge and Fog paradigms to lessen the burden on Cloud systems and resolve the issues indicated. Ultimately, we see that those two paradigms have helped decrease the large quantity of data sent to the Cloud.
Finally, the Edge paradigm is advantageous over the Cloud paradigm, especially regarding security and privacy. However, the Fog paradigm consisting of Fog nodes is regarded as an outstanding architecture uniquely created so that IoT appliances render improved services and support. Next, we shall present some security and privacy analyses relating to Cloud, Edge, and Fog paradigms, respectively.
This entry is adapted from the peer-reviewed paper 10.3390/s22030927
This entry is offline, you can click here to edit this entry!