Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
A machine learning (ML) model is ideally trained using an optimal number of features and will capture fine details in the prediction task, such as holidays, without underperforming when the forecast window increases from one day to one week.
- recurrent neural networks
- transformers
- forecasting
- restaurant sales prediction
1. Introduction
Small and medium-sized restaurants often have trouble forecasting sales due to a lack of data or funds for data analysis. The motivation for forecasting sales is that every restaurant has time-sensitive tasks which need to be completed. For example, a local restaurant wants to make sales predictions on any given day to schedule employees. The idea is that a proper sales prediction will allow the restaurant to be more cost-effective with employee scheduling. Traditionally, this forecasting task is carried out intuitively by whoever is creating the schedule, and sales averages commonly aid in the prediction. Managers do not need to know the minute-to-minute sales amounts to schedule employees. So, we focus on finding partitions of times employees are working, such as dayshift, middle shift, and nightshift. No restaurant schedules employees one day at a time, so predictions need to be made one-week into the future to be useful in the real world. Empirical evidence by interviewing retail managers has pointed to the most important forecasted criteria to be guest counts and sales dollars and that these should be forecasted with high accuracy [1]. Restaurants tend to conduct these types of predictions in one of three ways: (1) through a manager’s good judgment, (2) through economic modeling, or (3) through time series analysis [2]. A similar restaurant literature review on several models/restaurants [3] shows how the data is prepared will highly influence the method used. Good results can be found using many statistical models, machine learning models, or deep learning models, but they all have some drawbacks [3], expected by the ‘No Free Lunch’ theorem. A qualitative study was conducted in 2008 on seven well-established restaurant chains in the same area as the restaurant in our case study. The chains had between 23 and 654 restaurants and did between $75 million and $2 billion in sales. Most used some sort of regression or statistical method as the forecasting technique, while none of them used ARIMA or neural networks [4]. ARIMA models have fallen out of favor for modeling complex time series problems providing a good basis for this work to verify if neural network research has improved enough to be relevant in the restaurant forecasting environment.
In the modern landscape, neural networks and other machine learning methods have been suggested as powerful alternatives to traditional statistical analysis [5,6,7,8,9]. There are hundreds [10] of new methods and models being surveyed and tested, many of which are deep learning neural networks, and progress is being seen in image classification, language processing, and reinforcement learning [5]. Even convolutional neural networks have been shown to provide better results than some of the ARIMA models [6]. Traditionally, critics have stated that many of these studies are not forecasting long enough into the future, nor do they compare enough to old statistical models instead of trendy machine learning algorithms. Following, machine learning techniques can take a long time to train and tend to be ‘black boxes’ of information [10]. Although some skepticism has been seen towards neural network methods, recurrent networks are showing improvements over ARIMA and other notable statistical methods. Especially when considering the now popular recurrent LSTM model, improvements were seen when comparing to ARIMA models [8,9], although the works do not compare the results with a larger subset of machine learning methods. Researchers have recently begun improving the accuracy of deep learning forecasts over larger multi-horizon windows and are also beginning to incorporate hybrid deep learning-ARMIA models [7]. Safe lengths of forecast horizons and techniques for increasing the forecasting window for recurrent networks are of particular interest [11]. Likewise, methods for injecting static features as long-term context have resulted in new architectures which implement transformer layers for short-term dependencies and special self-attention layers to capture long-range dependencies [5].
2. Baseline Results
In Figure 1, the actual value in blue with our prediction line in orange was seen. The mean absolute error (MAE) score for the Use-Yesterday prediction is 403. Our data is correlated weekly instead of daily, which yields a high error. This does show the upper bounds prediction error, so it is a simple goal to achieve better results. In Figure 2, the result of the Use-Last-Week prediction on the test dataset was seen. The MAE score for Use-Last-Week prediction is 278. As expected, a large increase was seen over the previous baseline due to the weekly seasonality, and it was considered this to be a well-reasoned prediction. There are issues regarding zero-sale days as they propagate errors forward.

Figure 1. Use-Yesterday Prediction. The most basic possible prediction model assumes that predicted day D (t) is exactly the previous day D (t − 1). The MAE baseline generated is 403, and the prediction shape does not fit the test set well.
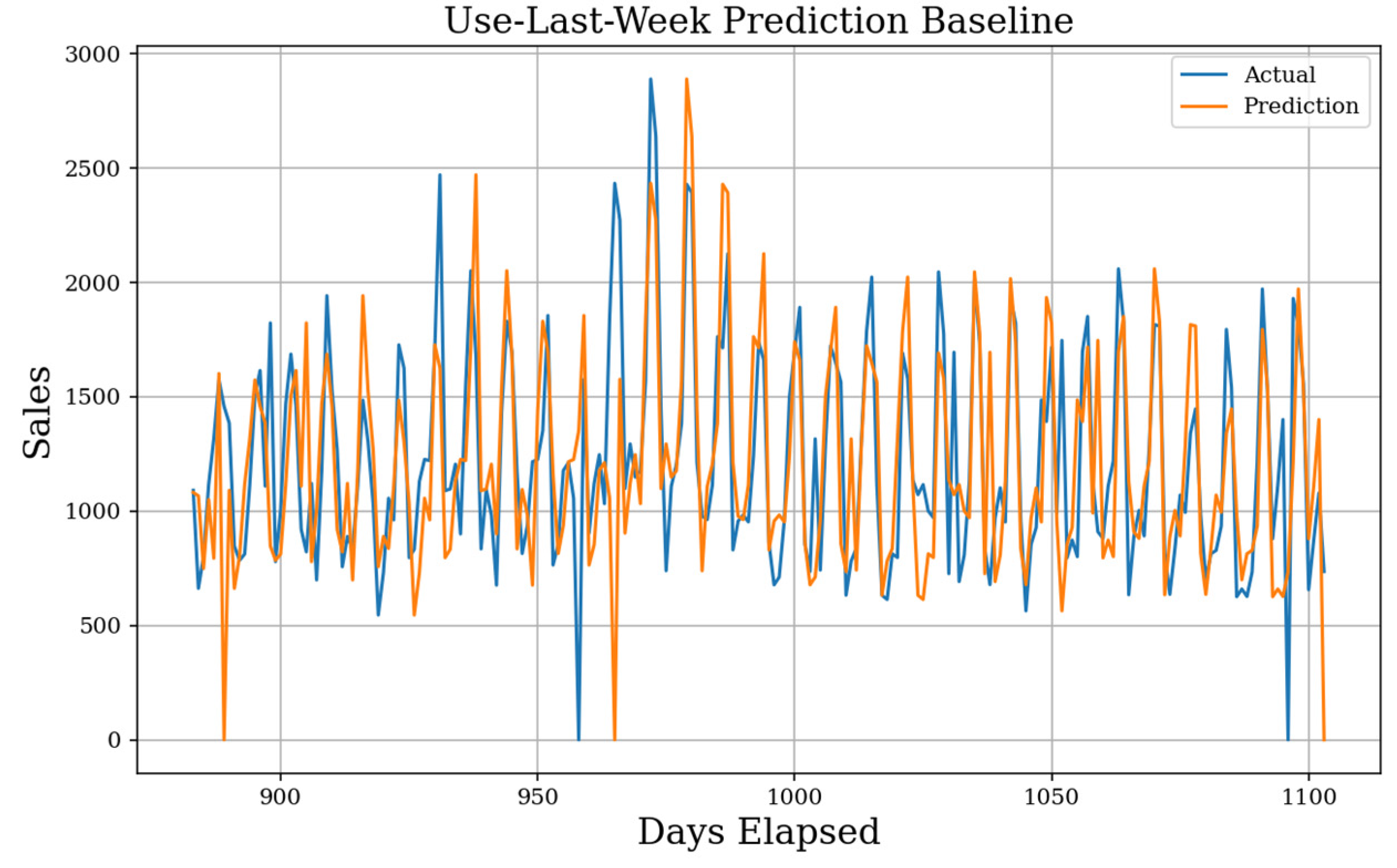
Figure 2. Use-Last-Week Prediction. Using the weekly seasonality, the next prediction baseline expects day D (t) is exactly the previous weekday D (t − 7). The MAE baseline generated is 278, and the prediction shape fails when experiencing extreme values.
In Figure 3, it was seen that the result of the Use-Last-Week-Enhanced prediction. The MAE score for the prediction is 239 showing a large improvement over simpler baselines and is even sensitive to change over time as short-term increases or decreases will be caught by the next week. This simple model boasts a sMAPE of 21.5%, which is very good. Although it is sensitive to changing patterns, the prediction will never propagate error from a holiday forward as badly as the other baselines.
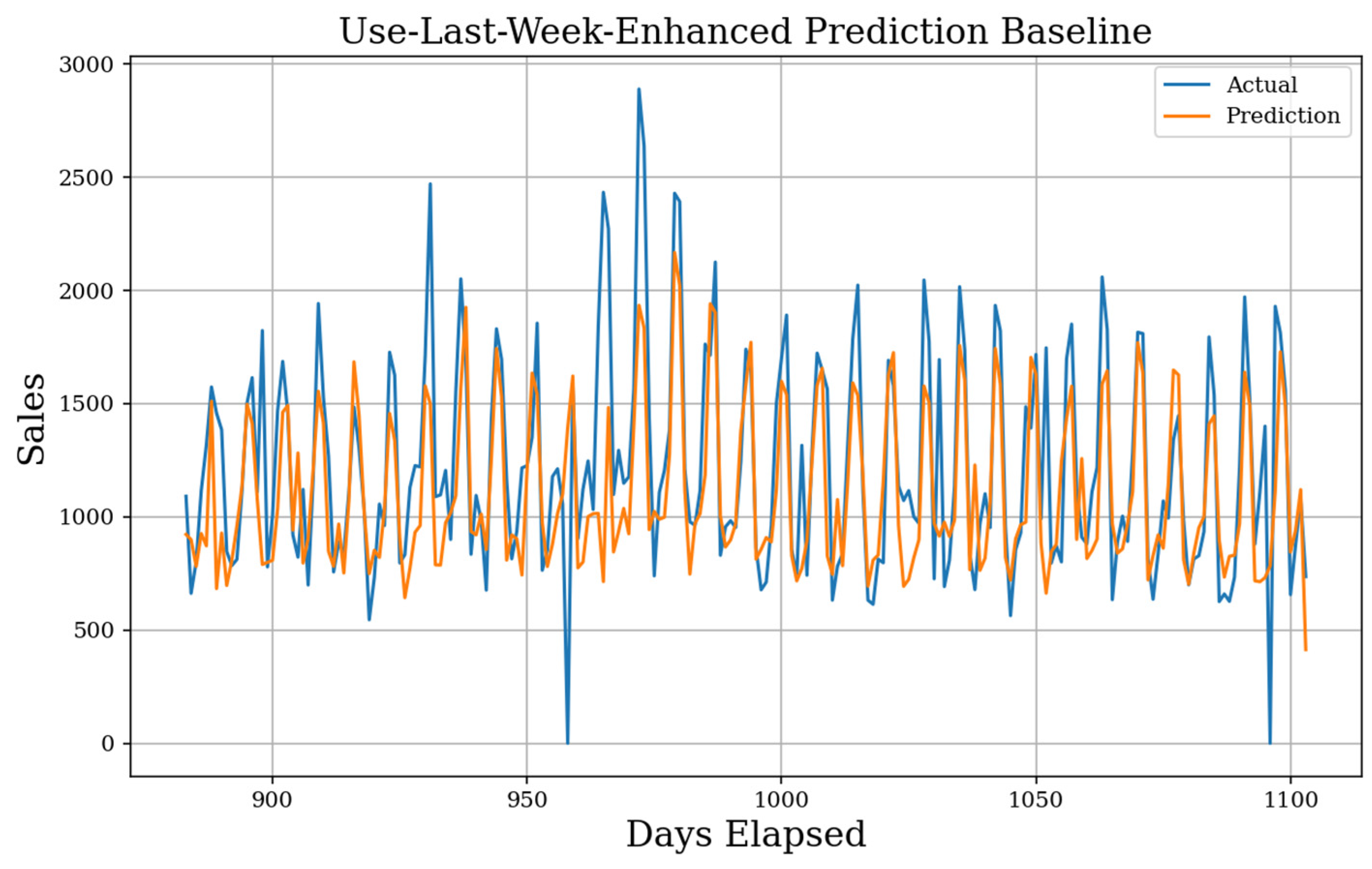
Figure 3. Enhanced Use-Last-Week Actual Prediction. Using the weekly seasonality and the mean weekday average, the final prediction baseline implements a simple history. The MAE baseline generated is 239, the sMAPE is 21.5%, and the gMAE is 150.
3. Feature Test Results
Figure 4 shows the rankings of the top 25 features in the actual dataset and their associated F-Scores. This ranking step is completed for each of the actual, daily differenced, and weekly differenced datasets and the results can be seen in the Supplementary Materials Figures S10–S12. Since the Temporal Fusion Transformer (TFT) model injects static context and does not need the 14 days of previous sales, we also give the top feature rankings with the 14 days removed in Supplementary Materials Figures S13–S16. Examining the results of the actual dataset, we see by far the most highly correlated features are the weekly average sales, the sales from one week ago, and the sales from two weeks ago. One feature of note, the year scores high, even though predicting sales by the year is not a good metric in reality. Since the actual dataset has a built-in trend, the feature seems more contextual than it really is. The daily differenced dataset, which has successfully removed trend, shows the highest scoring features as Monday and Saturday, as well as sales from one and two weeks ago as before. Although scores are not at high as before, there is still a good correlation, and features relying on trends do not rank highly such as before. Finally, the weekly differenced rankings show further diminished F-Scores. Sales from the day one week prior remain a consistent, highly correlated feature. Since the most correlation between instances has been removed by weekly differencing, holidays are ranked more highly than most other features.
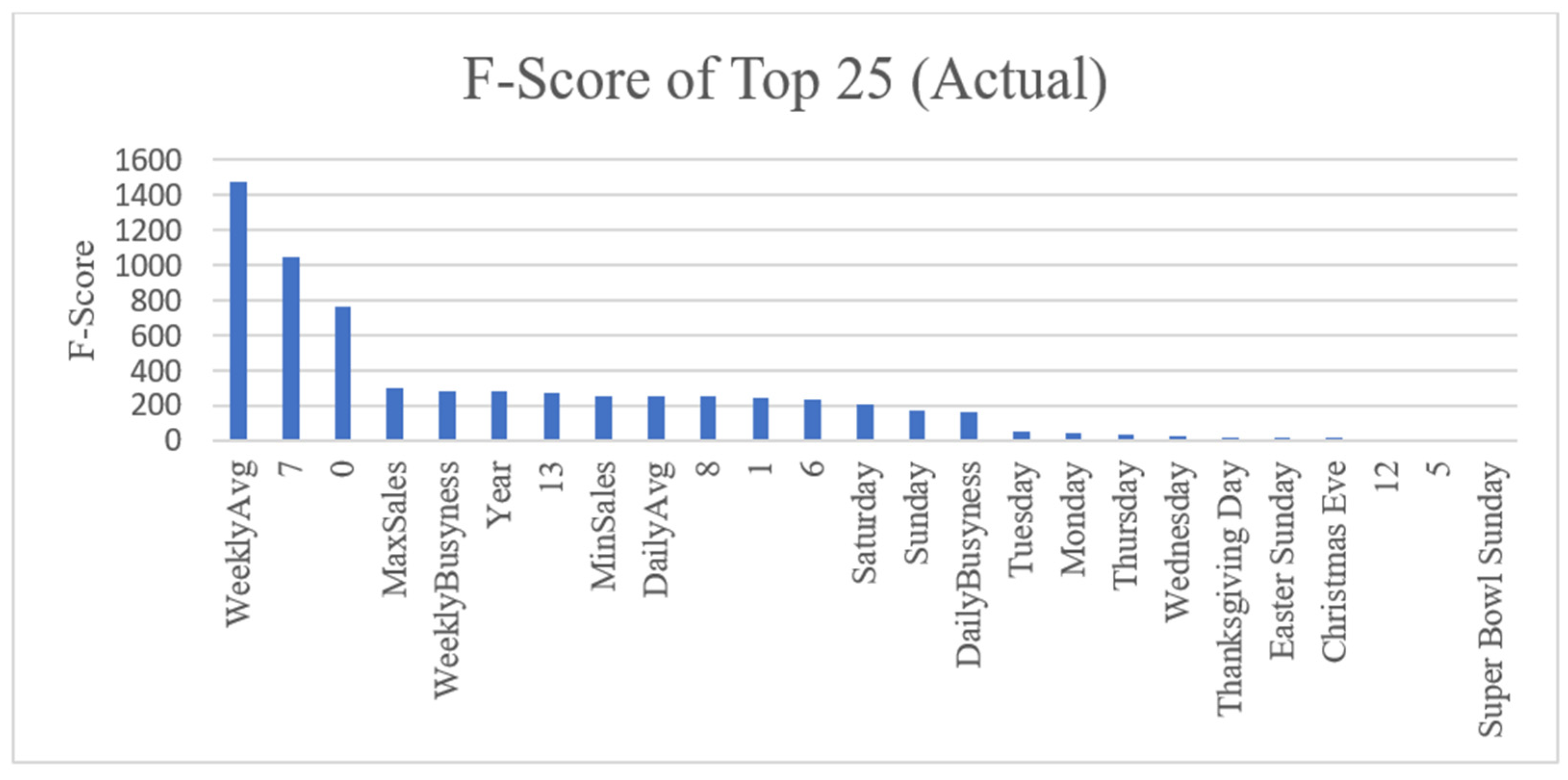
Figure 4. F-score for Top Features (Actual). The top 25 features as ranked by their F-scores. Weekly sales average is the highest scoring feature by far with other statistical metrics and days of the week following. Numbers 0–13 mark how many days until removal from the prediction window, so temporarily 13 is yesterday, 7 is one week ago, and 0 is two weeks ago.
The test to find the optimal number of features is completed for each model on each of the actual, daily differenced, and weekly differenced datasets for one-day and one-week forecast horizons. First, we examine the one-day results, followed by the extension to one-week. Figures for one-day results beyond the actual dataset can be seen in Supplementary Materials Figures S16–S21. The one-day actual feature test, shown in Figure 5, shows very promising results for the RNN models with LSTM using 22 features and GRU using 10, both scoring higher than other models. Other than some ensemble and linear non-RNN methods, most models received the highest MAE score from a smaller number of features on the actual dataset due to the high correlation of just a few features. This behavior is seen clearly in Figure 6 where all RNN models perform much worse after selecting more than 20 features. The one-day daily differenced feature test shows worse MAE scores overall, and the RNN models perform severely worse. Due to daily differencing linearly separating each instance, the best performing models may make use of more features. Kernel Ridge regression with 72 features received the best MAE in this stage and is comparable to the best results in the actual dataset. Ridge regression steadily decreased in MAE as the features increased, but RNN models fluctuated with an upward trend instead of improving, giving the best results with fewer features. The final weekly differenced one-day feature test gives steadily worse results for all models, and the RNN models are outperformed again by most other ML methods. For most models, except for some tree-based methods, the MAE never decreases beyond adding a small sampling of features, around 14 features for many models. For one-day feature testing, we acquire the best results overall from the actual data using few features and daily differenced data using many features, with the weekly differenced results underperforming overall with a middling number of features.

Figure 5. Best One-Day Forecast MAE Found Across 73 Features (Actual). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Materials Figure S10, for one-day forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name.

Figure 6. All RNN Models and Ridge One-Day Forecast MAE Across 73 Features (Actual). We show how the number of features affects the MAE score for one-day forecasting in the actual dataset.
The one-week feature tests are comparable to the one-day tests in many cases, and the resulting figures can be examined in detail in the Supplementary Materials Figures S22–S27. Due to forecasting for seven time steps instead of just one, we acquire slightly higher MAE results overall. For the actual dataset, the LSTM model is still the best, with only 24 features included, and both GRU models performed very well. All high-scoring, non-recurrent models find the best results with an increased number of features, 60 or more in most cases. Although we observe a high correlation in features, most of the correlation is only useful for the t + 1th position, and the models need additional features to help forecast the remaining six days. Other than higher overall MAE scores and more features used on average, the results from the one-week feature test are very similar to the one-day results.
4. One-Day Forecasting Results
The best model for forecasting one-day into the future implements the kernel ridge algorithm with a test MAE of 214, sMAPE of 19.6%, and a gMAE of 126, although all 25 top models are shown in Table 1. The dataset used was the daily differenced dataset, and the forecast result is seen in Figure 7. This is the best individual MAE score among all models. The TFT model with fewer features forecasted over the actual dataset also did well with an MAE of 220, sMAPE of 19.6%, and a gMAE of 133. This model better captures special day behaviors but is less adaptive since it uses fewer features. The ensemble Stacking method also received good results using the actual dataset, making it comparable to the TFT model. Otherwise, many models outperformed the best Use-Last-Week-Enhanced baseline. When examining datasets, daily differencing consistently achieves scores higher than the actual or weekly differenced dataset, especially with linear models. RNN models require the actual dataset to achieve results which are better than the baseline and still perform worse in some cases. The actual dataset still achieves below baseline results with other ML models as well; they are just not as good as seen when differencing daily. Finally, the weekly differenced dataset provides results almost entirely worse than the baseline, with the best result coming from the Voting ensemble. The full table of test results with all models is given in Supplementary Materials Table S9, and we give some figure examples from high performing or interesting forecasts in Supplementary Materials Figures S28–S35.
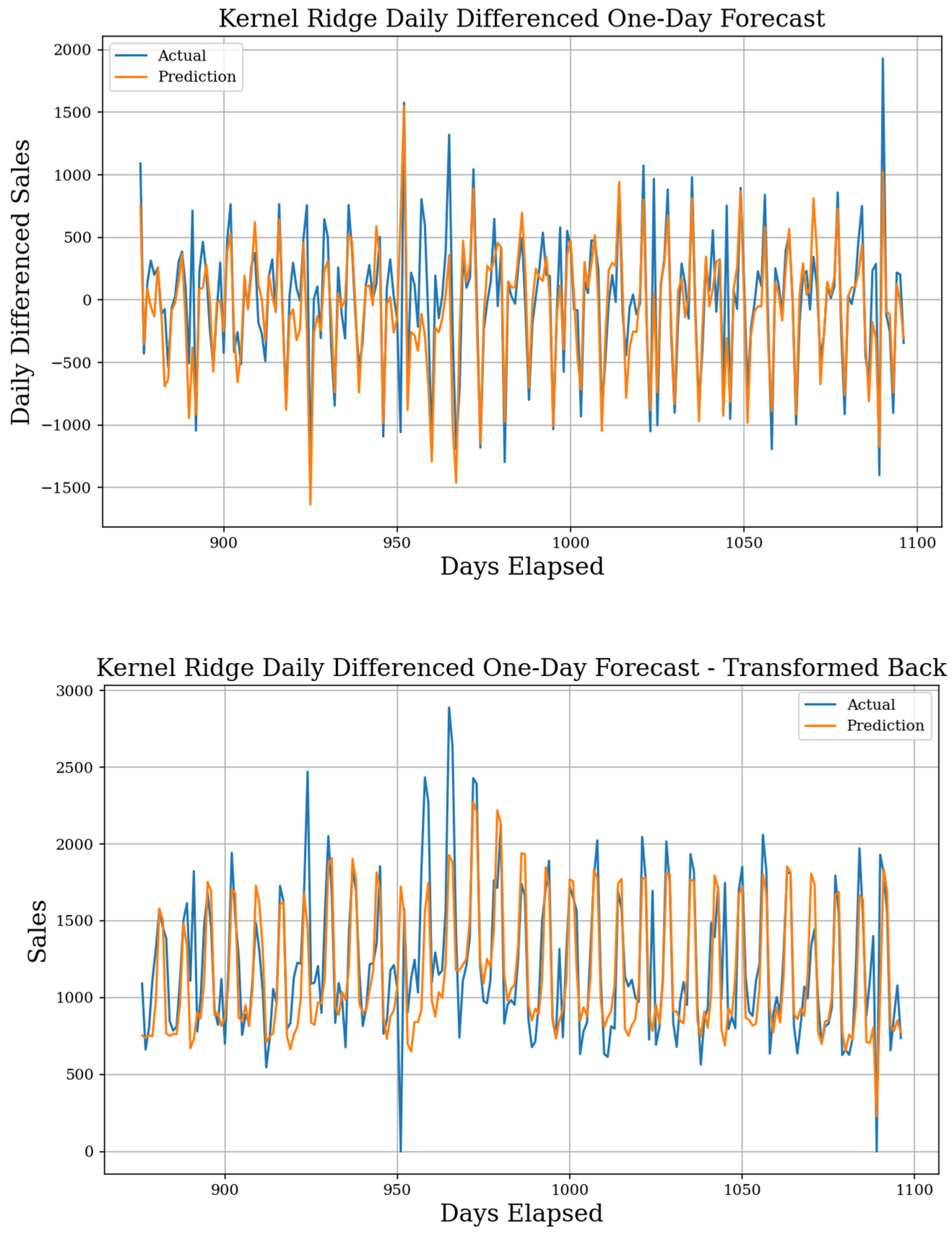
Figure 7. Kernel Ridge Daily Differenced One-Day Forecast. MAE of 214, sMAPE of 19.6%, and gMAE of 126, with 72 features. Original predictions (top) and the transformed back version (bottom) are both shown. This shows the best performing one-day forecast.
Table 1. Top 25 One-Day Forecast Results. We show the top 25 results for one-day forecasting from all tests, sorted by dataset, then ranked from best to worst. The model, test MAE, sMAPE, gMAPE, and the dataset used to achieve the result are all given. Some best and worst results from each dataset and the baseline are highlighted. The table is sorted by MAE then dataset, and the best results are seen in the Actual and Daily datasets.
| Model | Type | MAE | sMAPE | gMAE | Dataset |
|---|---|---|---|---|---|
| Stacking | NR | 220 | 0.195 | 142 | Actual |
| TFT Less Features | R | 220 | 0.196 | 133 | Actual |
| Bayesian Ridge | NR | 221 | 0.195 | 144 | Actual |
| Linear | NR | 221 | 0.195 | 144 | Actual |
| Ridge | NR | 221 | 0.195 | 144 | Actual |
| SGD | NR | 221 | 0.195 | 144 | Actual |
| LSTM | R | 222 | 0.196 | 131 | Actual |
| Lasso | NR | 226 | 0.201 | 147 | Actual |
| GRU | R | 227 | 0.2 | 144 | Actual |
| Extra Trees | NR | 231 | 0.204 | 128 | Actual |
| Use-Last-Week-Enhanced | NR | 239 | 0.215 | 150 | Actual |
| TFT All Features | R | 244 | 0.215 | 159 | Actual |
| Kernel Ridge | NR | 214 | 0.196 | 126 | Daily |
| Ridge | NR | 216 | 0.195 | 144 | Daily |
| Bayesian Ridge | NR | 217 | 0.196 | 146 | Daily |
| Linear | NR | 219 | 0.198 | 137 | Daily |
| Lasso | NR | 223 | 0.201 | 141 | Daily |
| Stacking | NR | 223 | 0.2 | 148 | Daily |
| XGB | NR | 241 | 0.214 | 152 | Daily |
| Voting | NR | 238 | 0.213 | 144 | Weekly |
| Stacking | NR | 242 | 0.215 | 139 | Weekly |
| Bayesian Ridge | NR | 245 | 0.218 | 142 | Weekly |
| Kernel Ridge | NR | 245 | 0.219 | 144 | Weekly |
| Linear Regression | NR | 245 | 0.217 | 140 | Weekly |
| Lasso | NR | 246 | 0.218 | 141 | Weekly |
4. One-Week Forecasting Results
When reviewing Table 2, the best model MAE score over one-week is the TFT model with fewer features achieving an MAE of 219, sMAPE of 20.2%, and a gMAE of 123 using the actual sales dataset. The forecast, seen in Figure 8, shows a perfect capture of the two holidays. However, the GRU and LSTM models both achieve a better sMAPE of 19.5% and 19.7%, respectively, and they both have better gMAE scores. The GRU model is hindered by a very high deviation between the starting days, and a Sunday start gave the best results. No other results achieved better scores than the Use-Last-Week-Enhanced baseline. The best performing non-recurrent models were ensemble methods Extra Trees, Stacking, and Voting, all on the actual dataset. When examining datasets, the only results better than the baselines came from the Actual dataset. Although, it is likely most accurate to say that only our recurrent algorithms performed well, and the actual dataset is the only one conducive for training recurrent models. The weekly differenced dataset does perform better than the daily differenced dataset here in terms of MAE, although the sMAPE is massive. Examining the forecasts shows models which are predicting close to zero-difference to achieve results approaching the Use-Last-Week baseline, which explains decent MAE but high sMAPE. The daily differenced dataset is not capable of making good predictions when using this forecasting method on a long window. The best result is the Lasso model with only an MAE of 280, sMAPE of 101.6%, and a gMAE of 162. The full table of test results with all models is given in Supplementary Materials Table S10, and we give some figure examples from high performing or interesting forecasts in Supplementary Materials Figures S36–S43.

Figure 8. Transformer Less Features Actual One-Week Forecast. The best start day MAE of 216 is found when starting on Tuesday. A sMAPE of 20.2% and gMAE of 123 show we may look for more improvements in the future, as results are not as good overall as one-day. A mean MAE of 218 and a standard deviation of 1.29 are found with 17 features. TFT perfectly captures the two holiday zero-sale days without acknowledging the zero-sale ‘hurricane day’.
Table 2. Top 25 One-Week Forecast Results. We show the top 25 results for one-week forecasting from all tests, sorted by dataset, then ranked from best to worst. The model, test MAE, sMAPE, gMAPE, and the dataset used to achieve the result are given. One-week specific metrics such as best start day, the mean of each weekday start, and the standard deviation between each start are also included. Best results are bolded. RNN models with the Actual dataset are the only results to beat the baseline Use-Last-Week-Enhanced. Alternate methodologies for extending non-RNN models to longer horizon windows must be explored further and sorted by MAE then dataset.
| Model | Type | MAE | sMAPE | gMAE | Dataset | Weekday | Mean | Std Dev |
|---|---|---|---|---|---|---|---|---|
| TFT Less Features | R | 215 | 0.202 | 123 | Actual | Friday | 222 | 3.363 |
| GRU | R | 218 | 0.195 | 116 | Actual | Sunday | 233 | 13.477 |
| LSTM | R | 222 | 0.197 | 134 | Actual | Thursday | 228 | 5.339 |
| Use-Last-Week-Enhanced | NR | 230 | 0.203 | 139 | Actual | Tuesday | 232 | 2.437 |
| GRU+ | R | 233 | 0.204 | 136 | Actual | Wednesday | 246 | 14.612 |
| ExtraTrees | NR | 235 | 0.206 | 145 | Actual | Wednesday | 240 | 4.085 |
| Stacking | NR | 237 | 0.208 | 146 | Actual | Tuesday | 243 | 4.634 |
| Voting | NR | 237 | 0.209 | 140 | Actual | Friday | 246 | 8.256 |
| Kernel Ridge | NR | 239 | 0.213 | 143 | Actual | Wednesday | 244 | 4.229 |
| SGD | NR | 240 | 0.214 | 140 | Actual | Tuesday | 249 | 7.712 |
| Bayesian Ridge | NR | 242 | 0.216 | 145 | Actual | Wednesday | 248 | 3.408 |
| Lasso | NR | 243 | 0.218 | 147 | Actual | Thursday | 248 | 2.979 |
| Transformer | R | 267 | 0.239 | 153 | Actual | Wednesday | 268 | 1.131 |
| Lasso | NR | 280 | 1.016 | 162 | Daily | Sunday | 287 | 6.53 |
| Lasso | NR | 253 | 1.284 | 137 | Weekly | Sunday | 256 | 3.156 |
| Ridge | NR | 256 | 1.274 | 144 | Weekly | Sunday | 261 | 3.403 |
| Kernel Ridge | NR | 257 | 1.274 | 146 | Weekly | Sunday | 262 | 3.436 |
| Elastic | NR | 257 | 1.327 | 153 | Weekly | Sunday | 259 | 1.495 |
| SGD | NR | 257 | 1.28 | 148 | Weekly | Monday | 261 | 2.978 |
| LinSVR | NR | 258 | 1.405 | 149 | Weekly | Sunday | 260 | 1.939 |
| Bayesian Ridge | NR | 259 | 1.304 | 151 | Weekly | Sunday | 260 | 1.21 |
| Stacking | NR | 260 | 1.281 | 151 | Weekly | Monday | 264 | 2.694 |
| Transformer | R | 263 | 1.371 | 147 | Weekly | Tuesday | 278 | 9.849 |
| RNN | R | 273 | 1.722 | 162 | Weekly | Sunday | 278 | 2.95 |
| GRU | R | 273 | 1.674 | 154 | Weekly | Sunday | 279 | 4.318 |
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/make4010006/s1,
Figure S10: F-score for Top Features (Actual). The top 25 features as ranked by their F-scores. Weekly sales average is the highest scoring feature by far with other statistical metrics and days of the week following. Figure S11: F-score for Top Features (Daily Differenced). The top 25 features as ranked by their F-scores. The day of the week and some statistical measures are high-ranking features here. Some impactful holidays also are in the top 25. Figure S12: F-score for Top Features (Weekly Differenced). The top 25 features as ranked by their F-scores. Only the previous week’s sales have a F-score above 100. Only one statistical feature remains at the top, and the most relevant features are holidays. Figure S13: F-score for Transformer Top Features (Actual). The top 25 features as ranked by their F-scores. With temporal associations built by the model, feature selection can be completed without considering lookback days specifically. Figure S14: F-score for Transformer Top Features (Daily Difference). The top 25 features as ranked by their F-scores. With temporal associations built by the model, feature selection can be completed without considering lookback days specifically. Figure S15: F-score for Transformer Top Features (Weekly Difference). The top 25 features as ranked by their F-scores. With temporal associations built by the model, feature selection can be completed without considering lookback days specifically. Figure S16: Best One-Day Forecast MAE Found Across 73 Features (Actual). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Figure S10, for one-day forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name. Figure S17: All RNN Models and Ridge One-Day Forecast MAE Across 73 Features (Actual). We show how the number of features affects the MAE score for one-day forecasting in the actual dataset. Figure S18: Best One-Day Forecast MAE Found Across 77 Features (Daily Difference). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Figure S11, for one-day forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name. Figure S19: All RNN Models and Ridge One-Day Forecast MAE Across 77 Features (Daily Difference). We show how the number of features affects the MAE score for one-day forecasting in the daily differenced dataset. Figure S20: Best One-Day Forecast MAE Found Across 77 Features (Weekly Difference). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Figure S12, for one-day forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name. Figure S21: All RNN Models and Ridge One-Day Forecast MAE Across 77 Features (Weekly Difference). We show how the number of features affects the MAE score for one-day forecasting in the weekly differenced dataset. Weekly differenced dataset shows little improvement as features are added. Figure S22: Best One-Week Forecast MAE Found Across 71 Features (Actual). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Figure S10, for one-week forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name. It is promising that most RNN models perform well in this stage, but we are wary of overfitting. Figure S23: All RNN Models and Ridge One-Day Forecast MAE Across 71 Features (Actual). We show how the number of features affects the MAE score for one-week forecasting in the actual dataset. Figure S24: Best One-Week Forecast MAE Found Across 74 Features (Daily Difference). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Figure S11, for one-week forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name. Figure S25 All RNN Models and Ridge One-Week Forecast Across 74 Features (Daily Difference). The ridge example shows how the number of features affects the MAE score for one-week forecasting in the daily differenced dataset. Figure S26: Best One-Week Forecast MAE Found Across 74 Features (Weekly Difference). Recurrent (orange) and non-recurrent (blue) models are trained with an iteratively increasing number of ranked features, seen in Supplementary Figure S12, for one-week forecasting. The lowest MAE for each model is recorded with the number of features next to the model’s name. Good results from RNN models are promising, but need to be verified in a fair final test. Figure S27: All RNN Models and Ridge One-Week Forecast Across 74 Features (Weekly Difference). The ridge example shows how the number of features affects the MAE score for one-week forecasting in the weekly differenced dataset. Figure S28: Stacking Actual One-Day Forecast. MAE of 220, sMAPE of 19.5%, and a gMAE of 142, with 25 features. Figure S29: Extra Trees Actual One-Day Forecast. MAE of 231, sMAPE of 20.4%, and a gMAE of 128, with 29 features. Figure S30: Kernel Ridge Daily Differenced One-Day Forecast. MAE of 214, sMAPE of 19.6%, and a gMAE of 126, with 72 features. Original predictions (first) and then transformed back version (second) are both shown. Figure S31: Voting Weekly Differenced One-Day Forecast. MAE of 238, sMAPE of 21.3%, and a gMAE of 144, with 12 features. Figure S32: Transformer Less Features Actual One-Day Forecast. MAE of 220, sMAPE of 19.6%, and a gMAE of 133, with 17 features. Figure S33: LSTM Actual One-Day Forecast. MAE of 222, sMAPE of 19.6%, and a gMAE of 131, with 22 features. Figure S34: Transformer Less Features Daily Differenced One-Day Forecast. MAE of 270, sMAPE of 23.1%, and a gMAE of 176, with 13 features. Figure S35: LSTM Weekly Differenced One-Day Forecast. MAE of 263, sMAPE of 23.8%, and a gMAE of 159, with seven features. Figure S36: Extra Trees Actual One-Week Forecast. The best start day MAE of 235, sMAPE of 20.6%, and gMAE of 145, are found when starting predictions on Wednesday. A mean MAE of 240 and a standard deviation of 4.085 are found with 69 features. Figure S37: Stacked Daily Differenced One-Week Forecast. The best start day MAE of 282, sMAPE of 100.02%, and gMAE of 168, are found when starting predictions on Sunday. A mean MAE of 289 and a standard deviation of 4.93 are found with 58 features. Figure S38: Lasso Weekly Differenced One-Week Forecast. The best start day MAE of 253, sMAPE of 128.4%, and gMAE of 137, are found when starting predictions on Sunday. A mean MAE of 256 and a standard deviation of 3.15 are found with 55 features. Figure S39: Transformer Less Features Actual One-Week Forecast. The best start day MAE of 215, sMAPE of 20.2%, and gMAE of 123, are found when starting on Friday. A mean MAE of 222 and a standard deviation of 3.36 are found with 17 features. Figure S40: LSTM Daily Differenced One-Week Forecast. The best start day MAE of 292, sMAPE of 117.5%, and gMAE of 173, ares found when starting predictions on Sunday. A mean MAE of 310 and a standard deviation of 15.68 are found with 21 features. Figure S41: RNN Weekly Differenced One-Week Forecast. The best start day MAE of 273, sMAPE of 172.2%, and gMAE of 162, are found when starting predictions on Sunday. A mean MAE of 278 and a standard deviation of 2.95 are found with 7 features. Figure S42: Transformer Less Features Daily Differenced One-Week Forecast. The best start day MAE of 285, sMAPE of 108.1%, and gMAE of 179, are found when starting predictions on Wednesday. A mean MAE o 294 and a standard deviation of 7.2 are found with 13 features. Figure S43: Transformer Less Features Weekly Differenced One-Week Forecast. The best start day MAE of 263, sMAPE of 137.1%, and gMAE of 147, are found when starting predictions on Tuesday. A mean MAE of 278 and a standard deviation of 2.95 are found with less features. Table S9: One-Day Forecast Actual Full Results. The Supplementary Table displays the model, test MAE, sMAPE, gMAPE, and the dataset used to achieve the result. We display the full results of all models from all three datasets. Best results from each dataset and the baseline are bolded. Best results are seen in the Actual and Daily datasets. Many recurrent models have trouble scoring below the baseline. Table S10: One-Week Forecast Actual Full Results. The Supplementary Table displays the model, test MAE, sMAPE, gMAPE, and the dataset used to achieve the result. One-week specific metrics like best start day, the mean of each weekday start, and the standard deviation between each start are also included. Best results, by MAE, for each dataset and the baseline are bolded. RNN models with the Actual dataset are the only results to beat the baseline Use-Last-Week-Enhanced. Different methodologies for extending non-RNN models to longer horizon windows are required.
This entry is adapted from the peer-reviewed paper 10.3390/make4010006
This entry is offline, you can click here to edit this entry!