Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Due to its increasing incidence, skin cancer, and especially melanoma, is a serious health disease today. The high mortality rate associated with melanoma makes it necessary to detect the early stages to be treated urgently and properly. This is the reason why many researchers in this domain wanted to obtain accurate computer-aided diagnosis systems to assist in the early detection and diagnosis of such diseases.
- skin lesion
- image processing
- machine learning
- deep learning
- neural networks
- image classifiers
- image segmentation
- melanoma detection
- statistic performances
- review
1. Introduction
Melanoma (Me) is known as the deadliest type of skin cancer [1], the incidence of its occurrence increasing for both men and women worldwide every year [2,3]. According to Sun X. et al. [4] the main cause of Me occurrence is exposure to ultraviolet radiation. Due to this excessive exposure, some mutations that occur at the level of melanocytes can lead to Me genesis. Even though it is one of the deadliest types of skin cancers, many studies showed that early detection of Me leads to its treatment in 90% of cases [5]. Currently, the standard method of Me diagnosis is visual analysis by a specialist. However, this method can be time-consuming. Moreover, it can lead to misdiagnosis due to the complexity of providing the diagnosis. The following aspects need to be considered: the number of parameters that need to be analyzed (color, shape, texture, edge, asymmetry, etc.), the fatigue, and the lack of experience of the specialist [6,7,8]. In most cases, the dermoscopic images are acquired and analyzed by the dermatologist, thus achieving a maximum of 84% examination accuracy (ACC) [9,10], which is insufficient. Therefore, the help of a computer-aided diagnosis (CAD) system for Me diagnosis from images is more than necessary [11].
Over time, a lot of researchers have put their ideas together to try to develop an automatic Me detection system based on machine learning (ML) that provides a quick result with high ACC, even if the complexity of skin lesion (SL) images analysis presented many problems [12,13]. In reality, it is a rather complex task to find a suitable diagnosis algorithm due to the presence of artifacts, such as the presence of hair around or even in the lesion, different lesion dimensions, color and shapes, the presence of blood vessels, and other artifacts [14], as seen in Figure 1.
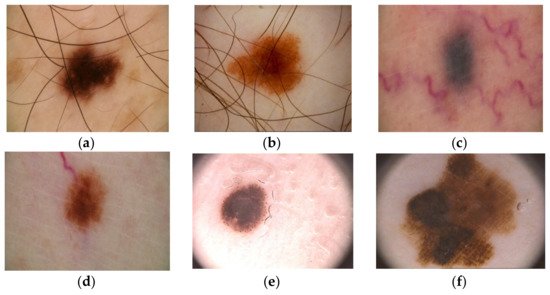
Figure 1. Artifacts in Me images collected from the ISIC 2016 dataset [14]: (a–b)—presence of hair, (c-d)—presence of blood vessels, (e,f)—presence of oil drops.
The inconveniences caused by these factors led the authors to expand their research a lot but, in principle, most approaches use the same classical method in which the first step is the preprocessing step, followed by segmentation, feature extraction, and then the classification step. The main workflow of the classical method is as shown in Figure 2.
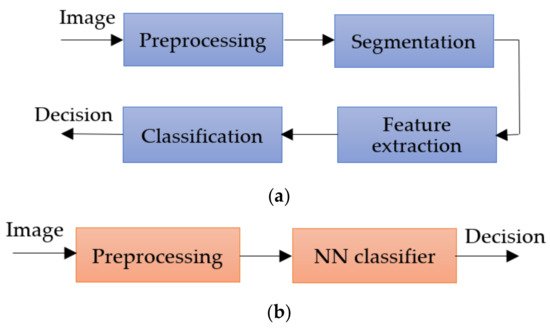
Figure 2. Methods workflow for Me detection: (a) classical method, (b) NN approach.
The preprocessing step consists of applying primary operations such as the following: noise removal, data augmentation, resizing, brightness grayscale transformation or brightness corrections, binarization, and, mainly, intensity and contrast enhancement [15]. As the Me images have a high variability of content, the segmentation step is a much-debated topic and a difficult task. This step represents the part of the algorithm that makes possible the image splitting into several sets of pixels [16], with the extraction of regions of interest (RoI) by an automatic or semiautomatic process as the end result [17]. Among the most commonly used techniques for Me detection and segmentation are artificial neural network-based methods (NNs). Considering the variability of Me images, the first-mentioned method (Figure 2a) cannot provide the best results. After the segmentation, the feature extraction step is usually applied. This task consists of reducing the dimensions of the data representation such that this becomes more administrable. Thus, data processing becomes faster and easier, without losing important information. Even so, it is known as a large consumer of resources due to the high number of variables. Generally, if the feature extraction is well done, the detection ACC will increase significantly [16]. In the past, most authors [18,19,20] used the ABCD (Asymmetry, Border, Color, Differential structure) rule as a feature extraction-based method for Me detection, while presently others use deep learning (DL) techniques to make the feature extraction better. The last, and the most discussed step in our review, is the classification step. The goal of this step is to assign a class to an RoI from an image. Manual classification is hard and time-consuming and therefore the interest for developing an accurate automatic classification algorithm increased in last years.
Nowadays, whether it is about segmentation, feature extraction, or classification, the tendency is to use the benefits of Artificial Intelligence (AI) using NN and DL techniques to obtain more accurate results. The main goal of AI is the reproduction of human intelligence, with applications in domains such as autonomous vehicles, search engines, art creation, or medical diagnosis. In the case of Me detection by applying AI, promising results were obtained, reaching a level where only visual inspection of SL is no longer a reliable solution. Known as a subset of the AI, the classical ML algorithms were proposed first as a solution for automatic Me detection. Mainly, ML uses the previous experience to improve the given results [21]. The system first extracts the needed features to create the training data. After the training data are obtained, supervised or unsupervised learning is used in the learning process. Generally, most papers used the supervised learning models, being more accurate. As has been observed also in other areas in which it is applied, the classical ML-based methods showed promising results, but also some limitations. For example, a large amount of data are needed to train the system, the learning phase takes a long time, and ML presents a high error-susceptibility. Thus, the authors turned their attention to NN and DL techniques.
NNs consist of a collection of neurons that simulates the function of neurons in a human being. In such a network, the neurons are connected to each other, each connection being assigned a weight, helping the neurons to give the necessary output. The authors prefer the NNs because they present benefits, such as distributed memory, the possibility of giving good results with a small amount of information, or the possibility of parallel processing. For training, the system error is calculated by taking the difference between the predicted value and the output target. Using this calculated error, the system adjusts its weights until the error is minimized.
2. Neural Networks Used in Melanoma Detection, Segmentation, and Classification
According to the current study related to SL detection, segmentation, and classification papers in the literature, it turned out that the majority of these kinds of tasks used NNs, CNNs, DCNNs (Deep Convolutional Neural Networks), and TL for NNs. It can be observed that the trend throughout the years, in general, and not strictly related to SL diagnosis systems, is that researchers used to design deep networks with a lot of hidden layers (either convolutional or fully connected layers) to obtain better results. It is normal that, when this happened at first, the time complexity for training, classification, detection, or segmentation was somehow neglected, all works being more focused on better statistical performance (required by diagnostic specialists). As a consequence, the majority of works related to Me detection, segmentation and/or classification systems are based on NNs. Table 1 illustrates the most used NNs in such applications. As we are mostly interested in the usage trend of NNs used in Me diagnosis, this section presents the architecture of the basic NNs widely used in these kinds of applications.
Table 1. Family of NNs used for Me diagnosis used in references.
| NN family | Representatives | References |
|---|---|---|
| ResNet | ResNet 34, ResNet 50, SEResNet 50, ResNet 101, ResNet 152, FCRN | [5,6,31,38,39,40,41,42,43,44,45,46,47,48,49,50] |
| Inception/GoogLeNet | GoogLeNet (Inception v2), InceptionResNet-v2, Inception v3, Inception v4 | [5,36,40,41,42,43,45,46,49,50,51,52] |
| U-Net | U-Net | [43,49,53,54,55,56,57,58,59,60,61,62,63] |
| GAN | GAN, SPGGAN, DCGAN, DDGAN, LAPGAN, PGAN | [6,52,56,64,65,66,67,68,69,70,71] |
| DenseNet | DenseNet 121, DenseNet 161, DenseNet 169, DenseNet 201 | [1,31,40,41,49,50,52,67,71,72] |
| AlexNet | AlexNet | [6,12,45,46,73,74,75,76] |
| Xception | Xception | [40,42,43,46,49,52,67] |
| EfficientNet | EfficientNet, EfficientNetB5, EfficientNetB6 | [47,77,78,79,80,81,82,83] |
| VGG | VGG 16, VGG 19 | [40,43,45,46,47,54,84,85] |
| NASNet | NASNet, NASNet-Large | [5,31,42,86] |
| MobileNet | MobileNet, MobileNet2 | [40,43,47,87] |
| YOLO | YOLO v3, YOLO v4, YOLO v5 | [88,89,90] |
| FrNet | FrNet | [91] |
| Mask R_CNN | Mask R_CNN | [92] |
Following the investigation of the Web of Science DB between the years 2018 and 2020 (Figure 3), it can be found that the most used NN in the detection of Me were those in the family ResNet, followed by the families: VGG, GoogLeNet, and AlexNet. For the year 2021, the tendency is for ResNet and VGG networks (Figure 4). Figure 3 marks the number of appearances in the years 2018, 2019, and 2020, and Figure 4 the percentage of appearances in 2021 (unfinished year).
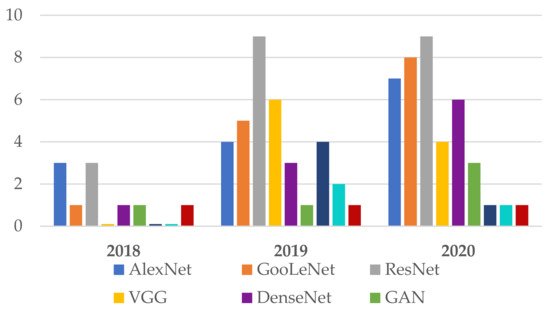
Figure 3. Frequently NNs used in Me detection between 2018 and 2020.
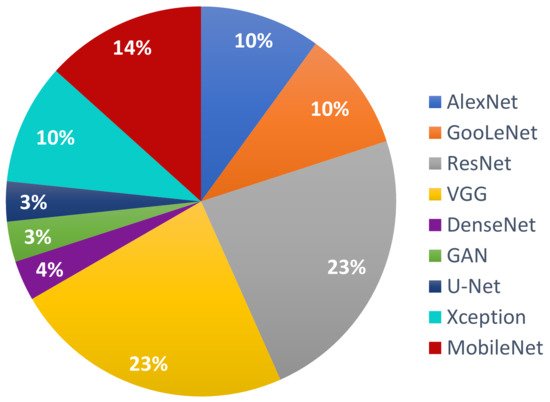
Figure 4. The most used NNs for Me detection in 2021 (percentage).
2.1. AlexNet
AlexNet [93] is one of the first CNNs widely used in SL classification tasks via TL. The basic architecture (Figure 5) is composed of eight layers, out of which five are convolutional layers (Conv) and three are fully connected layers (FC). The first and second layers are followed by Max Pooling layers (MPX) and Local Response Normalization (LRN), while the third, fourth, and fifth are followed by ReLU (Rectified Linear Units) [94]. The last layer (Softmax layer) has 1000 neurons and is used for the classification task (1000 classes). The number of layers specified in the above architecture is not what makes AlexNet special. AlexNet replaced the Tanh function with ReLU for speed enhancement in terms of training time. In Figure 5, at each layer, the number of neurons is specified.
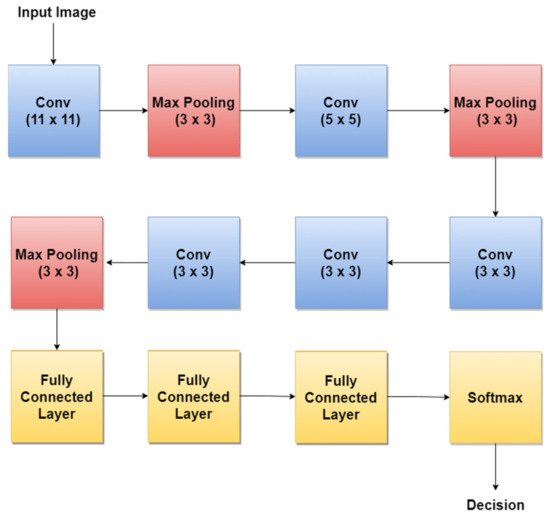
Figure 5. AlexNet basic architecture.
For example, in 2018, the authors in [45] trained AlexNet using TL, together with three other architectures: GoogLeNet, ResNet, and VGGNet to achieve a better ACC in such classification tasks. By training AlexNet to classify SL, the authors obtained an average ACC of about 85%. Other research papers such as: [12,73,74] used the trained AlexNet for SL diagnosis.
2.2. GoogLeNet/Inception
GoogLeNet, also named Inception v1, is a CNN proposed by researchers at Google in 2014 [95]. Its architecture was the winner of the ILSVRC 2014 image classification challenge (ImageNet Large Scale Visual Recognition Challenge 2014) and performed better in terms of error rate compared with previous winners: AlexNet in 2012 and ZG-Net in 2013. New features of GoogLeNet are the following: 1 × 1 convolution, global average pooling, an Inception module, and an auxiliary classifier for training. The 1 × 1 convolution blocks were introduced to decrease the number of parameters in general (weights and biases), which of course led to a depth increase of the architecture. The network’s basic block is the Inception module, where 1 × 1, 3 × 3, 5 × 5 convolutions, and 3 × 3 Max Pooling blocks perform in parallel. The outputs of these blocks are concatenated and fed to the next layer. The Inception module was introduced since different convolutions blocks of different sizes handle objects better at multiple scales. Figure 6 illustrates the components of the Inception module used in GoogLeNet.
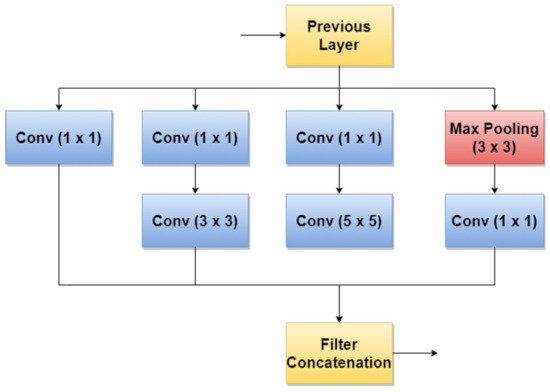
Figure 6. Inception module used in GoogLeNet.
A simplified architecture of GoogLeNet is 22 layers deep (Figure 7). The network takes a color image (RGB) of size 224 × 224 pixels as input and provides the classification result (out of 1000 classes) as output, using a Softmax layer of 1000 neurons. Another important aspect to mention is that all convolutions inside the architecture use ReLU as an activation function.
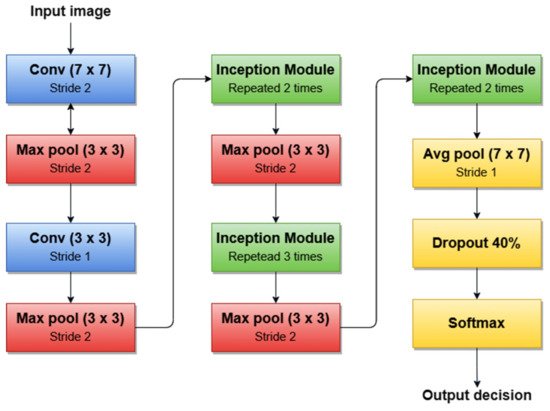
Figure 7. GoogleNet architecture’s simplified block diagram.
For example, the authors in [45] used the first version of GoogLeNet (Inception v1) as the basic CNN from which they started TL for SL diagnosis. Additionally, the authors in [5] (published in 2020) trained Goog-LeNet for the Me classification task, which shows that this architecture added a lot of value with its newly introduced features. Recently, a series of published SL diagnosis systems used newer versions of GoogLeNet. For instance [43] related to Me and the nevus SL classification task uses the Inception v3 NN [96] with 42 layers deep. Figure 8 illustrates the overall architecture of the Inception v3 network.
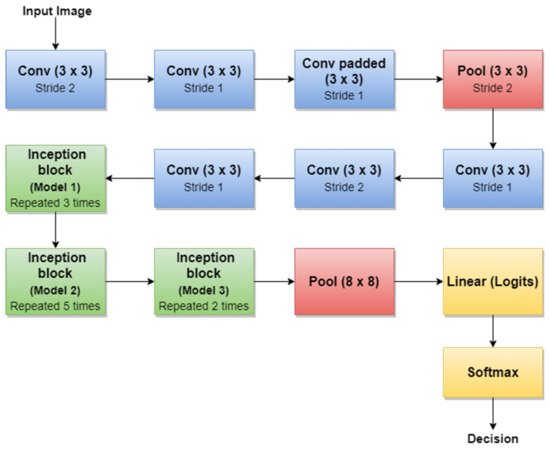
Figure 8. Inception v3 basic architecture.
An important observation is that Batch Norm (Batch Normalization) and ReLU blocks are used after each convolution. The basic idea of Inception v3 NN and what makes it more special than the first version (GoogLeNet—Inception v1) is to reduce the number of connections/parameters without decreasing the network efficiency. This is one of the reasons why researchers also investigate the performance of this CNN in their applications. Inception v3 uses “Factorizing convolutions” by replacing the 5 × 5 convolution filter represented in Figure 6 with two convolution filters 3 × 3. This procedure reduces the number of parameters from 25 to 18. The same technique was also used in VGG Net [97]. Another important novelty introduced by Inception v3 is related to factorization into asymmetric convolutions which means that a 3 × 3 convolution filter will be replaced by one 3 × 1 convolution filter followed by one 1 × 3 convolution filter.
2.3. VGG Networks
VGG is a NN family with the first representative VGG 16, which is widely used in SL diagnosis. VGG16 [98] is slightly similar to, but larger, than AlexNet, being 16 layers deep and containing only small 3 × 3 convolution filters (Figure 9). For instance, the authors in [45,47,53] used a TL technique to train VGG 16 to achieve SL diagnosis.

Figure 9. VGG 16 network architecture [98].
VGG 16 model achieves a 92.7% top-5 test ACC in ImageNet BD (14 million images belonging to 1000 classes) and was the winner of ILSVRC-2014. With this model, an improvement can be seen over AlexNet, since it replaces large filters such as 11 × 11 and 5 × 5 with multiple smaller 3 × 3 filters, making the network deeper (ascending trend for obtaining a better ACC). The same behavior of “Factorizing Convolutions” was also used in GoogLeNet Inception v3.
VGG 19, shown in Figure 10 [98], is another VGG network used in SL (especially Me) diagnostic research papers in the literature. This time, the model becomes deeper (19 layers, out of which 3 are fully connected layers). According to our survey, examples of paper works related to SL diagnosis are [43,47]. Both papers mentioned as examples were published in 2020 and represent comparative studies between multiple networks to find the most accurate and precise ones for SL diagnosis tasks. What can also be noticed is that, in terms of compared networks, apart from VGG 16 and VGG 19, other deeper networks such as ResNet-50 (50 layers deep) and DenseNet-201 (201 layers deep) are involved. This means that the trend in using NNs for SLs diagnosis is to use deeper networks to achieve better ACC and precision. Of course, this can lead to more and more network parameters and large computation time in terms of the learning task, which will continue to be a subject of research.

Figure 10. VGG 19 network architecture [98].
2.4. ResNet
As we mentioned in the previous sections, the general trend for segmentation, detection, and classification tasks is to use deeper NNs. However, it was demonstrated that, as we go deeper with more and more layers with “plain” networks, the training error will start to increase over time. Therefore, very deep NNs are in general hard to train because of vanishing and exploding gradients kind of problems. To avoid this issue, researchers introduced “skip connections” in the networks which allow them to take the activation from one layer and feed it to another layer, even much deeper in the NN. This allows building “Residual” networks, instead of “Plain” networks, thus building very deep NNs (over hundreds of layers deep). The newly introduced “Residual” network [99] solves the problem of the vanishing gradient in deep NNs by allowing the shortcut presented in Figure 11. In this way, the gradient can flow through. With this new feature, ResNet won first place in the ILSVRC 2015 competition with an error rate of 3.57%. It also won the COCO 2015 competition for detection and segmentation problems.
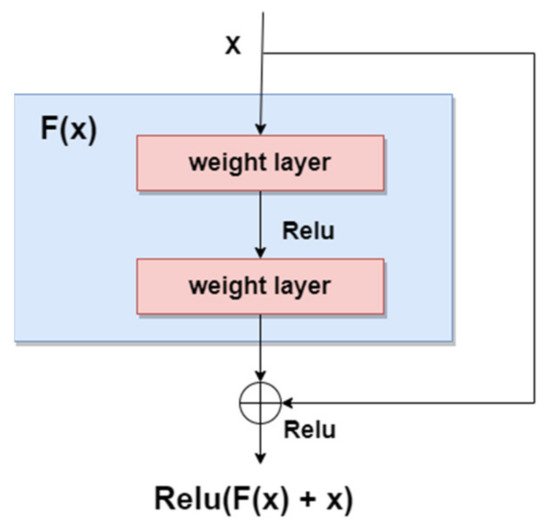
Figure 11. Residual block.
According to our search related to SLs diagnosis (Table 1), in terms of the ResNet family, the most used NNs for detection, segmentation, and classification task, are ResNet-34, ResNet-50, ResNet-101, and ResNet-152. As can be seen in Figure 12, ResNet-152 is a 152-layer-deep CNN composed of residual blocks which solve the vanishing gradient issue when training deep NNs. An example of an SL diagnosis paper that uses ResNet-34 is [47]. Another residual network used in SL diagnosis tasks is ResNet-50 (50 layers deep), which was used for instance in [41,43,47,50], all published in 2020. A residual network 101 layers deep, used in SL diagnosis, is ResNet-101 ([5,42,43,50], all published in 2020). Of course, there are also other studies, such as [38,39,48,96], that use a deeper “residual” network (representing the trend of using more deeper networks for better ACC) called ResNet-152 (152 layers deep).
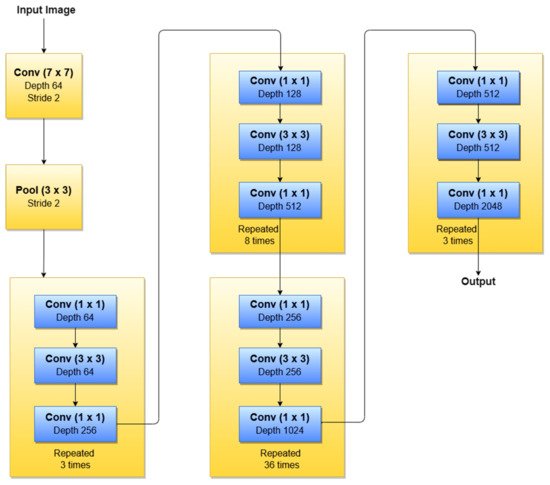
Figure 12. ResNet-152 basic architecture.
2.5. YOLO Networks
YOLO (You Only Look Once) is a CNN widely used in real-time object detection tasks and commonly used network in Me detection papers (usually YOLO v3 and YOLO v4). According to [100], YOLO is a “new approach to object detection” by using a single NN to “predict bounding boxes and class probabilities directly from full images in one evaluation”. YOLO is composed of 24 convolutional layers followed by two fully connected layers which were pre-trained on ImageNet DB, similarly to other commonly used networks. As can be seen in Figure 13 [101], the network contains some alternating 1 × 1 convolution filters which are mainly used to reduce the features space from the preceding layers. This looks similar to what GoogLeNe—Inception v3 introduced. There are multiple versions of YOLO, out of which, according to our research, the most used CNNs for Me detection tasks are YOLO v3 and YOLO v4 [88].
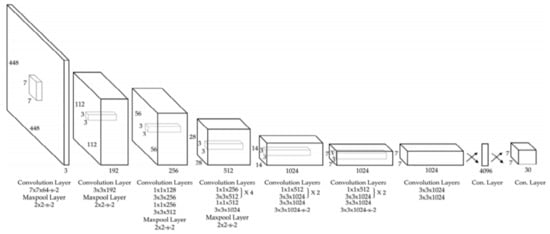
Figure 13. YOLO v3 architecture [101].
YOLO v3 is an incremental improvement of the previous YOLO v2 which was based on DarkNet-19 network. According to the authors in [102], the network is bigger than YOLO v2, with increased ACC, and is fast enough. The authors proposed a hybrid approach between DarkNet-19 and a residual network (inspired from ResNet). The new architecture is based on 53 convolutional layers called DarkNet-53. As we already mentioned, YOLO v3 is used in Me detection tasks. For instance, the authors in [89,90] used YOLO v3 for benign/malignant Me or seborrheic keratosis detection. There is also the YOLO v4 version with an increasing speed, used in Me detection and segmentation [88].
2.6. Xception Network
Xception is another CNN used in SL diagnosis tasks. For instance, new related papers are [42,43], both being published in 2020. According to [103], this network was inspired by GoogLeNet Inception NN also developed by Google researchers and was meant to obtain better performance by replacing the standard Inception modules with depthwise separable convolutions. The Xception architecture (Figure 14), which outperforms Inception v3, contains 36 convolutional layers structured in 14 modules, all with residual connections around them [104].
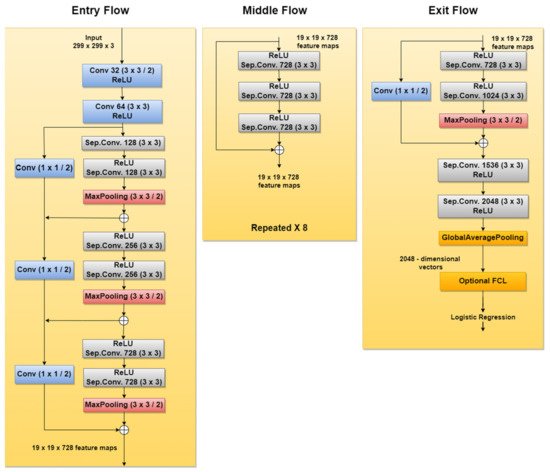
Figure 14. Xception network architecture.
2.7. MobileNet
MobileNet is a type of NN designed for mobile and embedded vision applications [105]. Since this CNN is deployed on mobile devices, memory usage should be taken seriously into consideration. Therefore, to decrease the complexity and to reduce the model size, the architecture is based on depthwise separable convolution blocks, as in the case of Xception NN described in the previous section.
There are multiple versions of MobileNet, out of which, according to this research, MobileNet-v1 and MobileNet-v2 are the most used in SL diagnosis papers. For instance [43,47], both published in 2020, use MobileNet-v1; meanwhile, newer papers such as [87] use MobileNet-v2 (deeper and improved version of MobileNet-v1) in such applications.
As we already mentioned, MobileNet NN reduces the complexity and number of network parameters using depthwise separable convolutions (1 × 1 convolution applied on each of the RGB channels). However, it also uses pointwise convolution with a 1 × 1 kernel (depth equal to the number of channels of the image) which iterates through every single point. To this end, MobileNet-v1 uses 13 blocks composed of depthwise separable convolution and pointwise convolution. However, researchers were focused on obtaining better results. Therefore, MobileNet-v2 came about as an improved version of MobileNet-v1. The first important change was marked by the fact that the network is now composed of 17 bottleneck blocks, each of them containing an expansion module, a depthwise separable convolution, and a pointwise convolution. The expansion block was introduced to increase the size of the representation within the bottleneck block to allow the NN to learn a richer function. The pointwise convolution will then “down” project the data so that they reach the initial size. Another important issue introduced in MobileNet-v2 is the residual connections around the bottleneck blocks, to solve the “vanishing gradient” problem, as in the case of ResNet. Of course, both versions end with a Max Pooling layer, followed by Fully Connected layers, and finally followed by a Softmax layer.
2.8. EfficientNet
As we have already mentioned in previous sections, researchers tend to obtain better results in terms of ACC and other performance metrics. For this to happen, the trend is to design deeper CNNs. For example, ResNet can be scaled up to ResNet 200 by increasing the number of layers. Authors in [106] propose a novel model scaling approach that uses compound coefficients to scale up CNNs in a more structured manner. This method uniformly scales each dimension with a fixed set of scaling coefficients. The authors also demonstrated the effectiveness of the proposed method on scaling up MobileNets and ResNets. In the same paper, they also build different versions of EfficientNet (EfficientNet B0–B7), all of them with better ACC than the networks with which they were compared. Another example of a recent paper [47] used EfficientNet to improve ACC for pigmented SL classification. The architecture (Figure 15) is based on MBConv blocks (inverted residual blocks), originally applied on MobileNet-v2 [107].
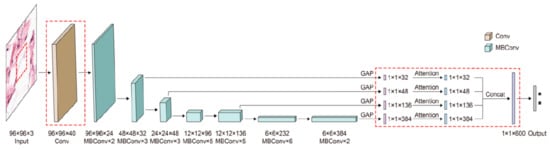
Figure 15. EfficientNet architecture [107].
2.9. DenseNet
DenseNet is a CNN family often used in SL diagnosis. Examples of papers using DenseNet (especially DenseNet-201) are ([1,41,47], all of them published in 2020). Therefore, DenseNet represents a trend for recently published papers because of its efficiency and better ACC. The reason is that, in the initial paper [108], the authors introduced densely connected layers, thus modifying the standard CNN architecture as in Figure 16. In DenseNet, each layer is fed with additional inputs from all preceding layers and provides its own input/feature map to all subsequent layers. In this way, each layer obtains knowledge from previous layers. Therefore, it is obvious that this becomes more powerful than ResNet, obtaining a stronger gradient flow, more diversified features, and a smaller network size. DenseNet-121, DenseNet-169, DenseNet-201, and DenseNet-264 are DenseNet networks presented in different works.
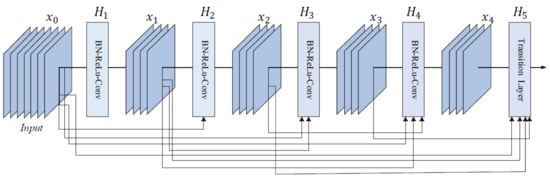
Figure 16. Five-layer DenseNet architecture [108].
2.10. U-Net
Recent papers such as [58] used U-Net CNN for SL segmentation. As can be seen in Figure 16, U-Net has a “U” form, being composed of 23 convolutional layers. After each max pooling operation, the number of feature channels is increased by the previous number of feature channels, multiplied by two. The number of channels is increased until it reaches 1024 and then starts to decrease (dividing by 2, after each 2 × 2 up-conv block). This architecture contains four sections: the encoder, the bottleneck, the decoder, and the skip connections (Figure 17). The bottleneck layer is a section between the down-sampling path (encoder) and up-sampling path (decoder), containing the smallest size of the feature map and the biggest number of filters. The skip connections are between the corresponding blocks of the encoder and decoder.
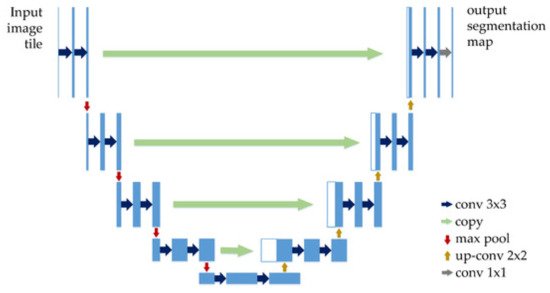
Figure 17. U-Net architecture [110].
According to the original paper [109], U-Net achieved very good performance on very different biomedical segmentation applications. This is one of the important reasons why researchers tend to use it in Me detection and segmentation-related papers.
2.11. Generative Adversarial Network
The Generative Adversarial Network (GAN) is another type of artificial NN that was used in the design of Me and SL diagnosis and segmentation systems. The GAN is composed of two different networks (main blocks), as can be seen in Figure 18. The first one is the generator network which learns how to generate real-like data, while the second one is a discriminator network which learns how to detect fake data and not to classify them as real data. Both networks are competing and playing an adversarial zero-sum game [111]. The main blocks try to optimize objective functions. GAN was proposed for image synthesis tasks. Starting from this idea, the GAN is used in melanoma segmentation as a generative model based on supervised learning.
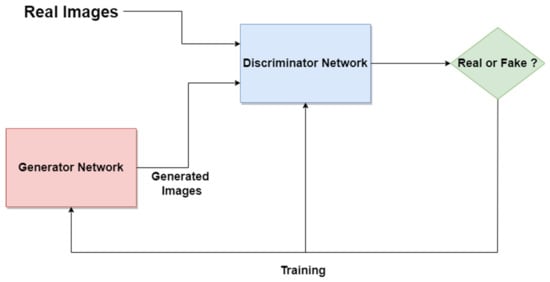
Figure 18. GAN standard network architecture.
According to our research, examples of research papers in this domain are [64,65,66,112], all of them proposing modified variants of GANs, such as SPGGAN (Self-attention Progressive Growing of Generative Adversarial Network), DCGAN (Deep Convolutional Generative Adversarial Network), DDGAN (Deeply Discriminated Generative Adversarial Network), LAPGAN (Laplacian Generative Adversarial Network), etc. There were other research papers involving the combination of GANs with other CNNs, such as Xception, Inception v3, etc. One example is [52], which presents an ensemble strategy of group decision for an accurate diagnosis.
This entry is adapted from the peer-reviewed paper 10.3390/s22020496
This entry is offline, you can click here to edit this entry!