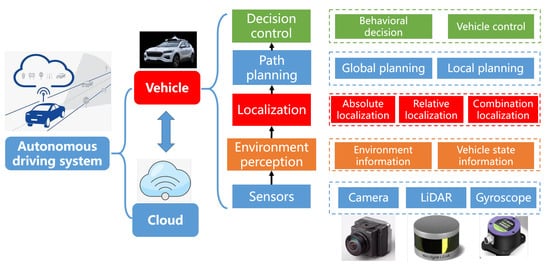
An autonomous driving system consists of perception, planning, decision, and control, which is illustrated in. The perception subsystem is the basis for other subsystems. It takes data captured from different sensors as input to obtain vehicle’s position and location, also including the size and direction of surrounding objects.
- electric vehicles
- autonomous driving
- deep learning
- 3D object detection
1. Introduction
An autonomous driving system consists of perception, planning, decision, and control, which is illustrated in Figure 1 . The perception subsystem is the basis for other subsystems. It takes data captured from different sensors as input to obtain vehicle’s position and location, also including the size and direction of surrounding objects. Autonomous driving vehicles [1][2][3] are often equipped with a variety of sensors, including LiDARs, cameras, millimeter-wave radars, GPS, and so on, which are illustrated in Figure 2 .

A perception subsystem needs to be accurate and robust to ensure safe driving. It is composed of several important modules, such as object detection, tracking, Simultaneous Localization and Mapping (SLAM), etc. Object detection is a fundamental ability and aims to detect all interested objects to achieve their location and categories from captured data, such as images or point clouds. Images are captured by cameras and can provide rich texture information. Cameras are cheap but cannot achieve accurate depth information, and they are sensitive to changes in illumination and weather, such as low luminosity at night-time and extreme brightness disparity when entering or leaving tunnels, rainy, or snowy weather. Point clouds are captured by LiDARs and can provide accurate 3D spatial information. They are robust to weather and extreme lighting conditions and demonstrate sparsity and ununiformity in spatial distribution. In addition, LiDARs are expensive sensors. Therefore, considering the complementary characteristics between point clouds and images, cameras and LiDARs are used as indispensable sensors to ensure intelligent vehicles’ driving safety.
Notably, failure to detect objects might lead to safety-related incidents. It may result in traffic accidents, threatening human lives for failed detection of a leading vehicle [4]. To avoid collision with surrounding vehicles and pedestrians, object detection is an essential technique to analyze perceived images and point clouds, which needs to identify and localize objects. The general framework is illustrated in Figure 3 . With the development of deep learning, 2D object detection is an extensive research topic in the field of computer vision. CNN-based 2D object detections [5][6][7][8] have an excellent performance in some public datasets [9][10][11]. However, 2D object detection only provide 2D bounding boxes and can not provide depth information of objects that is crucial for safe driving. Compared with 2D object detection, 3D object detection provides more spatial information, such as location, direction, and object size, which makes it become more significant in autonomous driving. 3D detection needs to estimate more parameters for 3D-oriented boxes of objects, such as central 3D coordinates, length, width, height, and deflection angle of a bounding box. In addition, 3D object detection still faces arduous problems, including the complex interaction between objects, occlusion, changes in perspective and scale, and limited information provided by 3D data.
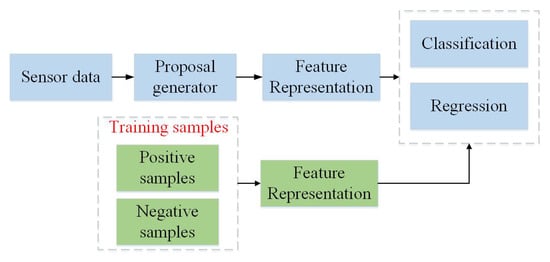
In this paper, we present a review of 3D object detection methods to summarize the development and challenges of 3D object detection. We analyze the potential advantages and limitations of these methods. The existing 3D object detection methods are divided into image-based methods, point cloud-based methods, and multimodal fusion-based methods. A general framework of the existing object detection methods is shown in Figure 3 . The categories and their limitations are briefly described in Table 1 .
| Mode | Methodology | Limitations | |
|---|---|---|---|
| Image | Apply images to predict bounding boxes of 3D objects. 2D bounding boxes are predicted and then are extrapolated to 3D by reprojection constraints or regression model. | Depth information is deficient and the accuracy of detection results is low. | |
| point cloud | Projection | Project a point cloud into a 2D plane and utilize 2D detection frameworks to regress 3D bounding boxes on projected images. | There is information loss in the process of projection. |
| Volumetric | Conduct voxelization to achieve 3D voxels and generate representation by using convolutional operations in Voxels to predict 3D bounding boxes of objects. | Expensive 3D convolutional operations increase inference time. The computation is heavy. | |
| PointNet | Apply raw point cloud to predict 3D bounding boxes of objects directly. | Large scale of point cloud increases running time. It is difficult to generate region proposals. | |
| Multi-sensor Fusion | Fuse image and point cloud to generate prediction on 3D bounding boxes. It is robust and complement each other. | Fusion methods are computationally expensive and are not mature enough. | |
2. Image-Based 3D Object Detection Methods
RGB-D images can provide depth information, which are used in some works. For example, Chen et al. [12] apply the poses of 3D bounding boxes to establish the energy function, and they use structured SVM for training to minimize the energy function. In DSS [13], multi-scale 3D RPN network is used to recommend objects on stereo images, which can detect objects of different sizes. Deng et al. [14] use the 2.5D method for object detection. They establish a model to detect 2D objects, and then convert 2D targets to 3D space to realize 3D object detection. Due to the large computation of RGB-D images, monocular images are used for 3D object detection.
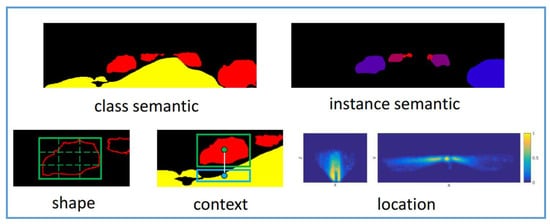
In early days, Chen et al. propose Mono3d [15], which uses monocular images to generate 3D candidates, and then uses semantics, context information, hand-designed shape features, and location priors, which are illustrated in Figure 4 , to score each candidates through energy model. Based on these candidates, Fast RCNN is used to further refine the 3D bounding boxes by location regression. The network improves the detection performance, but it is dependent on the object classes and needs a large number of candidates to achieve high recall, which leads to computational cost increase. To overcome this limitation, Pham and Jeon propose DeepStereoOP architecture [16] that is a class-independent algorithm, which exploits not noly RGB images but also depth inforamtion.
Hu et al. [17] propose a multi-task framework to associate detections of objects in motion over time and estimate 3D bounding boxes information from a sequential images. They leverage 3D box depth-ordering matching for robust instance association and use 3D trajectory prediction for identification of occluded vehicles. Considering benefits from multi-task learning, Center3D [18] is proposed to efficiently estimate 3D location of objects and depth using only monocular images. It is an extension of CenterNet [19].
In recent years, 3D object detection from a 2D perspective has attracted the attention of many researchers. Lahoud and Ghanem [20] propose a 2D driven 3D object detection method to reduce the search space of 3D object. They apply manual features to train multi-layer perceptron network to predict 3D boxes. Later, they extend the work [21] and propose a multimodal region proposal network to generate region proposals, which uses an extended 2D boxes to generate 3D boxes. MonoDIS [22] leverages a novel disentangling transformation for 2D and 3D detection losses and a self-supervised confidence score for 3D bounding boxes.
3. Point Cloud-Based 3D Object Detection Methods
3D processing directly uses the raw point cloud as the network input to extract the suitable point cloud features. For example, 3D FCN [23] and Vote3Deep [24] directly use a 3D convolution network to detect 3D bounding boxes of objects. However, the point cloud is sparse and the computation of 3D CNN is expensive. Additionally, affected by the receptive field, the traditional 3D convolution network cannot effectively learn the local features of different scales. To learn more effective spatial geometric representation from point cloud, some specific network frameworks have been proposed for point cloud, such as PointNet [25], PointNet++ [26], PointCNN [27], Dynamic Graph CNN [28], and Point-GNN [29]. PointNets [25][26] can directly process LiDAR point clouds and extract point cloud features through the MaxPooling symmetric function to solve the disorder problem of points. The network architecture of PontNet is illustrated in Figure 5 . Thanks to the networks, the performance of 3D object detection is improved but the computation of point-based methods is expensive, especially when the information of large scenes are captured by using Velodyne LiDAR HDL-64E and there are more than 100K points in one scan. Therefore, some preprocessing operations need to be conducted, such as downsampling.

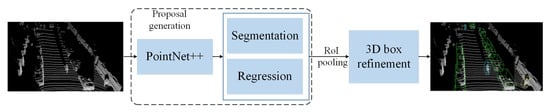
After the point cloud features learning models are proposed, PointRCNN [30] constructs a PointNet++-based architecture to detect 3D objects, which is simply illustrated in Figure 6 . Through the bottom-up 3D PRN, the subnetwork is used to transform the proposals information into standard coordinates to learn better local spatial features. By combining with the global semantic features of each point, the accuracy of the detected bounding boxes is improved. Similarly, Yang et al. [31] add a proposal generation module based on spherical anchor, which uses PointNet++ as the backbone network to extract semantic context features for each point. At the same time, in the second stage of boxes prediction, an IoU estimation branch is added for postprocessing, which further improves the accuracy of object detection.
Benifical from multi-task learning, LiDARMTL [32] utilizes a encoder–decoder architecture to predict perception parameters for 3D object detection and road understanding, which can be leveraged for online localization. Although the location accuracy of the object is improved compared with the previous methods, the calculation burden is heavy due to the large scale of the point cloud. To deal with the drawback, AFDet [33] adopts an anchor-free and Non-Maximum Suppresion-free single-stage framework to detect objects, which has the advantage in embedded systems.
With the help of point cloud data, the performance of 3D object detection is significantly improved. In general, the accuracy of 3D bounding boxes with image-based methods is much less than point cloud-based methods. Currently, LiDAR point cloud-based 3D object detection has become a main trends, but point cloud cannot provide texture information to efficiently discrimate categories of objects. Moreover, the density of points decreases when the distance between object and LiDAR increases, which affects the performance of detectors, while images can still capture faraway objects. Therefore, multi-sensor fusion-based methods are proposed to improve the overall performance.
4. Multi-Sensor Fusion-Based 3D Object Detection Methods
Considering the advantages and disadvantages of image-based and point cloud-based methods, some methods try to apply fuse both modalities with different strategies. The fusion of LiDAR point cloud and images is done to conduct a projection transformation of the point cloud, and then to integrate the multi-view projected plane with the image by different feature fusion schemes, such as MV3D [34], AVOD [35], etc. There are three fusion schemes, including early fusion, late fusion, and deep fusion, which are illustrated in Figure 7 . MV3D aggregates features by using a deep fusion scheme, where feature maps can hierarchically interact with others. AVOD is the first approach to introduce early fusion. The features of each modality proposal are merged and a FC layer is followed to output category and coordinates of 3D box for each proposal. These methods lose space information in the projection transformation process and the detection performance of small targets is poor. In addition, ROI feature fusion only uses advanced features, and the sparsity of LiDAR point cloud limits the fusion-based methods.
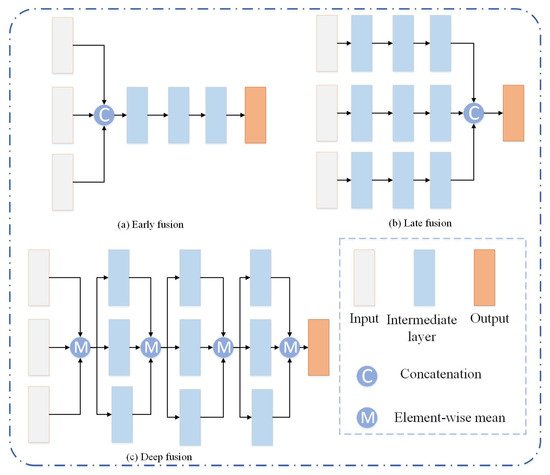
To address the problem of information loss, 3D-CVF [36] combines the features of camera and LiDAR by using the cross-view spatial feature fusion strategy. Autocalibrated projection is applied to transform the image features to a smooth spatial feature map with the highest correspondence to the LiDAR features in the BEV domain. A gated feature fusion network is used mix the features appropriately. Additionally, the fusion methods based on BEV or voxel format are not accurate enough. Thus, PI-RCNN [37] proposes a novel fusion method named Point-based Attentive Cont-conv Fusion module to fuse multi-sensor features directly on 3D points. Except for continuous convolution, Point-Pooling and Attentive Aggregation are used to fuse features expressively.
In the process of 3D object detection, inconsistency between the localization and classification confidence is a critical issue [38]. To solve the problem, a consistency enforcing loss is utilized to increase the consistency of both the localization and classification in EPNet [39]. Moreover, the point features is enhanced with semantic image features in a point-wise manner without image annotations.
Besides fusion of camera and LiDAR, radar data are also used for 3D object detection [40][41]. CenterFusion [40] first associates radar detections to corresponding objects in the 3D space. Then, these radar detections are mapped into image plane to complement features of images in a middle-fusion method.
This entry is adapted from the peer-reviewed paper 10.3390/wevj12030139
References
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361.
- Agarwal, S.; Vora, A.; Pandey, G.; Williams, W.; Kourous, H.; McBride, J. Ford multi-AV seasonal dataset. Int. J. Robot. Res. 2020, 39, 1367–1376.
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST multi-spectral day/night data set for autonomous and assisted driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948.
- Elmquist, A.; Negrut, D. Technical Report TR-2016-13; Simulation-Based Engineering Lab, University of Wisconsin-Madison: Madison, WI, USA, 2017.
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125.
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767.
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803.
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448.
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255.
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338.
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision, Proceedings of the Computer Vision—ECCV 2014, 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755.
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.; Ma, H.; Fidler, S.; Urtasun, R. 3d object proposals for accurate object class detection. In Advances in Neural Information Processing Systems, Proceedings of the Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; DBLP: Trier, Germany, 2015; pp. 424–432.
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816.
- Deng, Z.; Jan Latecki, L. Amodal detection of 3d objects: Inferring 3d bounding boxes from 2d ones in rgb-depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5762–5770.
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156.
- Pham, C.C.; Jeon, J.W. Robust object proposals re-ranking for object detection in autonomous driving using convolutional neural networks. Signal Process. Image Commun. 2017, 53, 110–122.
- Hu, H.N.; Cai, Q.Z.; Wang, D.; Lin, J.; Sun, M.; Krahenbuhl, P.; Darrell, T.; Yu, F. Joint monocular 3D vehicle detection and tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5390–5399.
- Tang, Y.; Dorn, S.; Savani, C. Center3D: Center-based monocular 3D object detection with joint depth understanding. In DAGM German Conference on Pattern Recognition, Proceedings of the DAGM GCPR 2020: Pattern Recognition, 42nd DAGM German Conference, DAGM GCPR 2020, Tübingen, Germany, 28 September–1 October 2020; Proceedings 42; Springer International Publishing: Cham, Switzerland, 2021; pp. 289–302.
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578.
- Lahoud, J.; Ghanem, B. 2d-driven 3d object detection in rgb-d images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4622–4630.
- Rahman, M.M.; Tan, Y.; Xue, J.; Shao, L.; Lu, K. 3D object detection: Learning 3D bounding boxes from scaled down 2D bounding boxes in RGB-D images. Inf. Sci. 2019, 476, 147–158.
- Simonelli, A.; Bulo, S.R.; Porzi, L.; Lopez-Antequera, M.; Kontschieder, P. Disentangling monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1991–1999.
- Li, B. 3d fully convolutional network for vehicle detection in point cloud. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1513–1518.
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361.
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660.
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; DBLP: Trier, Germany, 2017; pp. 5099–5108.
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. Adv. Neural Inf. Process. Syst. 2018, 31, 828–838.
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M. Dynamic graph cnn for learning on point clouds. arXiv 2018, arXiv:1801.07829.
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual. 14–19 June 2020; pp. 1711–1719.
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779.
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1951–1960.
- Feng, D.; Zhou, Y.; Xu, C.; Tomizuka, M.; Zhan, W. A Simple and Efficient Multi-task Network for 3D Object Detection and Road Understanding. arXiv 2021, arXiv:2103.04056.
- Ge, R.; Ding, Z.; Hu, Y.; Wang, Y.; Chen, S.; Huang, L.; Li, Y. Afdet: Anchor free one stage 3d object detection. arXiv 2020, arXiv:2006.12671.
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915.
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, A.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8.
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In European Conference on Computer Vision, Proceedings of the ECCV 2020: Computer Vision—ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVII 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 720–736.
- Xie, L.; Xiang, C.; Yu, Z.; Xu, G.; Yang, Z.; Cai, D.; He, X. PI-RCNN: An efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12460–12467.
- Dai, D.; Wang, J.; Chen, Z.; Zhao, H. Image guidance based 3D vehicle detection in traffic scene. Neurocomputing 2021, 428, 1–11.
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In European Conference on Computer Vision, Proceedings of the ECCV 2020: Computer Vision—ECCV, 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 35–52.
- Nabati, R.; Qi, H. Centerfusion: Center-based radar and camera fusion for 3d object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual. 5–9 January 2021; pp. 1527–1536.
- Long, Y.; Morris, D.; Liu, X.; Castro, M.; Chakravarty, P.; Narayanan, P. Radar-Camera Pixel Depth Association for Depth Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual. 19–25 June 2021; pp. 12507–12516.