Transfer learning is a machine learning approach that reuses a learning method developed for a task as the starting point for a model on a target task. The goal of transfer learning is to improve performance of target learners by transferring the knowledge contained in other (but related) source domains. As a result, the need for large numbers of target-domain data is lowered for constructing target learners. Due to this immense property, transfer learning techniques are frequently used in ultrasound breast cancer image analyses. In this study, we focus on transfer learning methods applied on ultrasound breast image classification and detection from the perspective of transfer learning approaches, pre-processing, pre-training models, and convolutional neural network (CNN) models. Finally, comparison of different works is carried out, and challenges—as well as outlooks—are discussed.
- transfer learning
- breast cancer
- ultrasound
1. Introduction
Breast cancer is the second leading cause of death in women; 12.5% of women from different societies worldwide are diagnosed with breast cancer [1]. According to previous studies, early detection of breast cancer is crucial because it can contribute to up to a 40% decrease in mortality rate [2,3]. Currently, the ultrasound imaging technique has emerged as a popular imaging modality for the diagnoses of breast cancer, especially in young women with dense breasts [4]. This is because ultrasound (US) imaging is a non-invasive procedure and it can efficiently capture tissue properties [5,6,7]. Studies have shown that the false negative recognition rate in other breast diagnosis methods, such as biopsy and mammography (MG), decreased on using different modalities, such as US imaging [2]. Additionally, ultrasound imaging methods can be used to improve the tumor detection rate by up to 17% during breast cancer diagnoses [6]. Furthermore, the number of non-essential biopsies can be decreased by approximately 40%, thereby reducing medication costs [5]. An additional benefit of ultrasound imaging is that it uses non-ionizing radiation, which does not negatively affect health and requires relatively simple technology [7]. Therefore, ultrasound scanners are cheaper and more portable than mammography [5,6,7,8]. However, ultrasonic systems are not a standalone modality for breast cancer diagnoses [6,7]; instead, they are integrated with mammography and histological observations to validate results [8]. To improve the diagnostic capacity of ultrasound imaging, several studies have employed existing technologies [9]. Machine learning has solved many of the problems associated with ultrasound in terms of the classification, detection, and segmentation of breast cancer, such as false positive rates, limitation in indicating changes caused by cancer, lower applicability for treatment monitoring, and subjective judgments [10,11,12]. However, many machine learning methods perform well only under a common assumption, i.e., the training and test data are obtained from the same feature space and have the same distribution [13]. When the distribution changes, most numerical values of the models need to be constructed from scratch using newly collected training data [11,12,13]. In medical applications, including breast ultrasound imaging, it is difficult to collect the required training data and construct models in this manner [14]. Thus, it is advisable to minimize the need and effort required for acquiring the training data [13,14]. In such scenarios, transfer learning from one task to the target task would be desirable [15]. Transfer learning enables the use of a model previously trained on another domain as the target for learning [16]. Thus, it reduces the need and effort required to collect additional training data for learning [10,11,12,13,14,15,16].
Transfer learning is based on the principle that previously learned knowledge can be exceptionally implemented to solve new problems in a more efficient and effective manner [17,18]. Thus, transfer learning requires established machine learning approaches that retain and reuse previously learned knowledge [19,20,21]. Transfer learning was recently applied to breast cancer imaging in 2016, following the emergence of several convolutional neural network (CNN) models, including AlexNet, VGGNet, GoogLeNet, ResNet, and Inception, to solve visual classification tasks in natural images that are trained on natural image database such as ImageNet [22]. The first application of transfer learning to breast cancer imaging was reported in 2016 by Hyunh et al., where they assessed the performance achieved by using features transferred from pre-trained deep CNNs for classifying breast cancer through computer-aided diagnosis (CADx) [23]. Following this, Byra et al. published a paper where they proposed a neural transfer learning approach for breast lesion classification through ultrasound [24]. Shortly after this, Yap et al. [25] published their work, which proposed the use of deep neural learning methods for breast cancer detection; they studied three different methods—a patch-based LeNet approach, a U-Net model, and a transfer learning method—with a pre-trained fully convolutional network, AlexNet. Following these works, a large number of articles have been published in the area of applying transfer learning for breast ultrasound imaging [26,27,28,29].
2. Transfer Learning
2.1. Overview of Transfer Learning
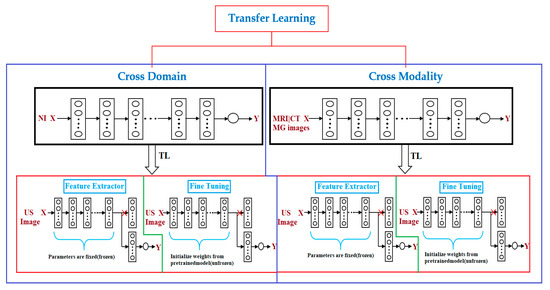
2.2. Advantages of Transfer Learning
2.3. Transfer Learning Approaches
2.4. Pre-Training Model and Dataset
-
ImageNet: ImageNet is a large image database designed for use in image recognition [77,78,79]. It comprise more than 14 million images that have been hand-annotated to indicate the pictured objects. ImageNet is categorized into more than 20,000 categories with a typical category consisting of several images. The third-party image URLs repository of annotations is freely accessible directly from ImageNet, although ImageNet does not own the images.
2.5. Pre-Processing
2.6. Convolutional Neural Network
A CNN is a feed-forward neural network commonly used in ultrasound breast cancer image analysis [84]. The main advantage of the CNN is its accuracy in image recognition; however, it involves a high computational cost and requires numerous training data [85]. A CNN generally comprises an input layer, one or many convolution layers, pooling layers, and a fully connected layer [74]. The following are the most commonly used CNN models used for transfer learning with breast ultrasound images [84].
-
AlexNet: the AlexNet architecture is composed of eight layers. The first layers of AlexNet are the convolutional layers, and the next layer is a max-pooling layer for data dimension reduction [77,78,79]. AlexNet uses a rectified linear unit (ReLU) for the activation function, which offers faster training than other activation functions. The remaining three layers are the fully connected layers.
-
VGGNet: VGG16 was the first CNN introduced by the Visual Geometry Group (VGG); this was followed by VGG19; VGG16 and VGG19 becoming two excellent architectures on ImageNet [85]. VGGNet models afford better performance than AlexNet by superseding large kernel-sized filters with various small kernel-sized filters; thus, VGG16 and VGG19 comprise 13 and 16 convolution layers, respectively [84,85,86].
-
Inception: this is a GoogLeNet model focused on improving the efficiency of VGGNet from the perspective of memory usage and runtime without reducing performance accuracy [86,87,88,89]. To achieve this, it removes the activation functions of VGGNet that are iterative or zero [86]. Therefore, GoogLeNet came up with and added a module known as Inception, which approximates scattered connections between the activation functions [87]. Following InceptionV1, the architecture was improved in three subsequent versions [88,89]. InceptionV2 used batch normalization for training, and InceptionV3 introduced the factorization method to enhance the computational complexity of convolution layers. InceptionV4 brought about a similar comprehensive type of Inception-V3 architecture with a larger number of inception modules [89].
3. Discussion
It is evident that transfer learning has been incorporated in various application areas of ultrasound imaging analyses [15,16]. Although transfer learning methods have constantly been improving the existing capabilities of machine learning in terms of different aspects for breast ultrasound analyses, there still exists room for improvement [84,85,86,87,88,89].
In [26], the results depict several issues related to neural transfer learning. First, the image reconstruction procedures implemented in medical scanners should be considered. It is important to understand how medical images are acquired and reconstructed [80,81,82,83]. However, there is limited information regarding the image reconstruction algorithms implemented in ultrasound scanners. Typically, researchers involved in computer-aided diagnoses (CADx) system development agree that a particular system might not perform well on data acquired at another medical center using different scanners and protocols [87]. Their study [26] clearly shows that this issue might also be related to the CADx system being developed using data recorded in the same medical center.
In [24], the authors presented that the lack of demographic variations in race and ethnicity in the training data can negatively influence the detection and survival outcomes for underrepresented patient groups. They recommended that future works should seek to create a deep learning architecture with pre-training data collected from different imaging modalities. This pre-trained model can be useful for devising new automated detection systems based on medical imaging.
In [27], the performance of fine-tuning is demonstrated to be better than that of the feature extracting algorithm utilizing directly extracted CNN features; the authors obtained higher AUC values for the main dataset. However, the implementation of the fine-tuning approach is by far challenging and difficult, relative to the feature extracting approach [24,25,26,27,28,29]. It requires replacement of the fully connected layers in the initial CNN with custom layers [84]. Additionally, identifying the layers of the initial model that should be trained in the course of fine-tuning is difficult [84]. Moreover, to obtain enhanced performance on the test data, the parameters must be optimally selected, and constructing a fine-tuning algorithm is time consuming [85]. Furthermore, with a small dataset, fine-tuning may not be advisable, and it would be wiser to address such cases using a feature extraction approach [75,76].
Therefore, several important research issues need to be addressed in the area of transfer learning for breast cancer diagnoses via ultrasound imaging. In [29], the authors hypothesized that learning methods pre-trained on natural images, such as the ImageNet database, are not suitable for breast cancer ultrasound images because these are gray-level, low-contrast, and texture-rich images. They examined the implementation of a cross-modal fine-tuning approach, in which they used networks that were pre-trained on mammography (X-ray) images to classify breast lesions in MRI images. They found that cross-modal transfer learning with mammography and breast MRI would be beneficial to enhance the breast cancer classification performance in the face of limited training data. This work can be used to improve breast ultrasound imaging by applying cross-modal transfer learning from a network pre-trained on mammography or other modalities.
The phenomenon of color conversion is extensively employed in ultrasound image analyses [27]. In [27], the authors showed that color distribution is an important constraint that should be considered when attempting to efficiently utilize transfer learning with pre-trained models. With the application of color conversion, it was proved that one could make use of the pre-trained CNN more efficiently [84,85,86]. By utilizing the matching layer (ML), they were able to obtain better classification performance. The ML developed was proved to perform the same when using other datasets as well [27]. Thoroughly studying these applications and improving the performance of transfer learning should be another potential research direction.
This entry is adapted from the peer-reviewed paper 10.3390/cancers13040738