The observation of randomness patterns serves as guidance for the craft of probabilistic modelling. The most used count models—Binomial, Poisson, Negative Binomial—are the discrete Morris’ natural exponential families whose variance is at most quadratic on the mean, and the solutions of Katz–Panjer recurrence relation, aside from being members of the generalised power series and hypergeometric distribution families, and this accounts for their many advantageous characteristics. Some other basic count models are also described, as well as models with less obvious but useful randomness patterns in connection with maximum entropy characterisations, such as Zipf and Good models. Simple tools, such as truncation, thinning, or parameter randomisation, are straightforward ways of constructing other count models.
- discrete models
- count random variables
- Panjer’s family
- hierarchical models
For any 𝒮={𝑥𝑘}𝑘∈𝕂, with 𝕂⊆ℕ0={0,1,…}, and for any sequence {𝑝𝑘}𝑘∈𝕂 such that 𝑝𝑘≥0 for any 𝑘∈𝕂 and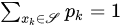
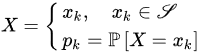
is a discrete lattice random variable with support 𝒮 and probability mass function {𝑝𝑘}𝑘∈𝕂. If 𝑥𝑘=𝑘∈ℕ0, X is a count random variable.
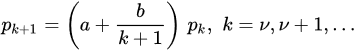 ) or mathematical properties (for instance, the variance being at most a quadratic function of the expectation) also define interesting families of discrete random variables. On the other hand, asymptotic properties such as arithmetic properties, namely, infinite divisibility, discrete self-decomposability, and stability, serve as guidance in model choice.
) or mathematical properties (for instance, the variance being at most a quadratic function of the expectation) also define interesting families of discrete random variables. On the other hand, asymptotic properties such as arithmetic properties, namely, infinite divisibility, discrete self-decomposability, and stability, serve as guidance in model choice.This entry is adapted from the peer-reviewed paper 10.3390/encyclopedia4030089
References
- Gani, J. The Craft of Probabilistic Modelling: A Collection of Personal Accounts; Springer: New York, NY, USA, 1986.