Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is an old version of this entry, which may differ significantly from the current revision.
Inductive relationship prediction for knowledge graphs, as an important research topic, aims to predict missing relationships between unknown entities and many practical applications. Most of the existing approaches to this problem use closed subgraphs to extract features of target nodes for prediction; however, there is a tendency to ignore neighboring relationships outside the closed subgraphs, which leads to inaccurate predictions. In addition, they ignore the rich commonsense information that can help filter out less compelling results.
- inductive relation prediction
- commonsense
- dual attention
- contrastive learning
1. Introduction
Knowledge graphs (KGs) are composed of organized knowledge in the form of factual triples (entity, relation, entity), and they form a collection of interrelated knowledge, thereby facilitating downstream tasks such as question answering [1], relation extraction [2], and recommendation systems [3]. However, even state-of-the-art KGs suffer from an issue of incompleteness [4,5], such as FreeBase [6] and WikiData [7]. To solve this issue, many studies have been proposed mining missing triples in KGs, in which the embedding-based methods become a dominant paradigm, such as TransE [8], ComplEx [9], RGCN [10], and CompGCN [11]. In particular, certain scholars have explored knowledge graph completion under low-data regime conditions [12]. In actuality, the aforementioned methods are often only suitable for transductive scenarios, which assumes that the set of entities in KGs is fixed.
However, KGs undergo continuous updates, whereby new entities and triples are incorporated to store additional factual knowledge, such as new users and products on e-commerce platforms. Predicting the relation links between new entities requires inductive reasoning capabilities, which implies that generality should be derived from existing datasets and extended to a broader spectrum of fields, as shown in Figure 1. The crux of the inductive relation prediction [13] resides in utilizing information that is not specifically tied to a particular entity. A representative strategy in inductive relation prediction techniques is rule mining [14], which extracts first-order logic rules from a given KG and employs weighted combinations of these rules for inference. Each rule can be regarded as a relational path, comprising a set of relations from the head entity to the tail entity, which signifies the presence of a target relationship between two entities. For example, consider the straightforward rule (X, part_of, Y) ∧ (Y, located_in, Z) → (X, lives_in, Z), which was derived from the KG depicted in Figure 1a. These relational paths exist in symbolic forms and are independent of particular entities, thus rendering them inductive and highly interpretable.
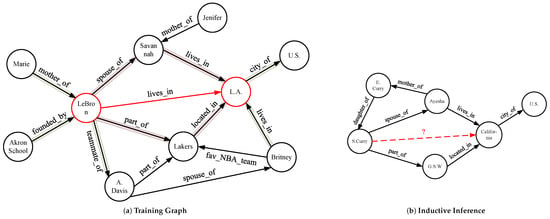
Figure 1. An explanatory case in inductive relation prediction, which learned from a (a) training graph, and generalizes to be (b) without any shared entities for inference. A red dashed line denotes the relation to be predicted.
Motivated by graph neural networks (GNNs) that have the ability of aggregating local information, researchers have recently proposed GNN-based inductive models. GraIL [15] models the subgraphs of target triples to capture topologies. Based on GraIL, some works [16,17,18] have further utilized enclosing subgraphs for inductive prediction. Recent research has also considered few-shot settings for handling unseen entities [19,20]. SNRI [21] extracts the neighbor features of target node and path features, solves the problem of sparse subgraphs, and introduces mutual information (MI) maximization to model from a global perspective, which improves the prediction effect of inductive relationships.
2. Relation Prediction Methods
To improve the integrity of KGs, state-of-the-art approaches use either internal KG structures [8,15] or external KG information [22,23].
Transduction methods. Transduction methods are used to learn entity-specific embeddings for each node, and they have one thing in common: reasoning about the original KG. However, it is difficult to predict missing links between unseen nodes. For example, TransE [8] is based on translation, while RGCN [10] and CompGCN [11] are based on GNN. the main difference between them is the scoring function and whether or not the structural information in the KG is utilized. wang et al. proposed to obtain global structural information about an entity by using a global neighborhood aggregator to solve the problem of sparse local structural information under certain snapshots [24]. Meng et al. proposed a multi-hop path inference model based on sparse temporal knowledge graph [25]. Recently, Wang et al. proposed knowledge graph complementation with multi-level interactions, in which entities and relations interact at both fine- and coarse-grained levels [26].
Induction methods. Inductive methods can be used to learn how to reason over unseen nodes. The methods fall into two main categories: rule-based methods and graph-based methods. Rule-based methods aim to learn logical reasoning rules that are entity-independent. For example, NeuralLP [14] and DRUM [27] integrate neural networks with symbolic rules to learn logical rules and rule confidence in an end-to-end microscopic manner.
In terms of graph-based approaches, in recent years, researchers have drawn inspiration from the local information aggregation capability of graph neural networks and incorporated graph neural networks (GNNs) into their models. GraIL [15] demonstrated inductive prediction by extracting closed subgraphs of the target triad to capture the topology of the target nodes. TACT [16] built on this model by introducing subgraphs in the correlation of relations and constructed a relational correlation network (RCN) to enhance the coding of subgraphs. CoMPLIE [17] proposed a node-edge communication message propagation network to enhance the interaction between nodes and edges and naturally handle asymmetric or antisymmetric relations to enhance the adequate flow of relational information. ConGLR [13] formulated a contextual graph to represent subgraphs of relational paths, where two GCNs are applied to handle closed subgraphs and contexts, where different layers utilize the corresponding outputs in an interactive manner to better represent features. RE-PORT [28] aggregates relational paths and contexts to capture the linkages and intrinsic properties of entities through a unified layered transformation framework. However, the RE-PORT model is not selected as a comparison model in the experimental part of this paper since its experimental metrics are different from other state-of-the-art models. RMPI [29] uses a novel relational message-passing network for complete inductive knowledge graph completion. SNRI [21] extracts nodes' neighbor-relationship features and path embeddings to fully utilize an entity's complete neighborhood relationship information for better generalization. However, all these approaches just add extra simple processing load and do not fully utilize the overall structural features of KGs. Unlike SNRI, CNIA preserves the integrated neighbor relations, utilizes the dual attention mechanism to process the structural features of the subgraphs and introduces common-sense reordering.
3. Commonsense Knowledge
Commonsense knowledge is a key component in solving bottlenecks in artificial intelligence and knowledge engineering technologies. And the acquisition of commonsense knowledge is a fundamental problem in the field. The earliest construction methods involved experts manually defining the architecture and types of relationships of a knowledge base. Lenat [30] constructed one of the oldest knowledge bases, CYC, in the 1980s.However, expert construction methods require a lot of human and material resources. Therefore, researchers started to develop semi-structured and unstructured text extraction methods. YAGO [31] constructed a common-sense knowledge base containing more than 1 million entities and 5 million facts derived from semi-structured Wikipedia data and harmonized with WordNet through a well-designed combination of rule-based and heuristic methods.
The above approach prioritizes encyclopedic knowledge and structure storage by creating well-defined entity spaces and corresponding relational systems. However, actual general knowledge structures are more loosely organized and are difficult to apply to models of two entities with known relationships. Therefore, existing solutions model entity parts as natural language phrases and relationships as any concepts that can connect entities. For example, the OpenIE approach reveals properties of open text entities and relationships. However, the method is extractive and it is difficult to obtain semantic information about the text.
The above approach prioritizes encyclopedic knowledge and structure storage by creating well-defined entity spaces and corresponding relational systems. However, actual general knowledge structures are more loosely organized and are difficult to apply to models of two entities with known relationships. Therefore, existing solutions model entity parts as natural language phrases and relationships as any concepts that can connect entities. For example, the OpenIE approach reveals properties of open text entities and relationships. However, the method is extractive and it is difficult to obtain semantic information about the text.
This entry is adapted from the peer-reviewed paper 10.3390/app14052044
This entry is offline, you can click here to edit this entry!