The upsurge of autonomous vehicles in the automobile industry will lead to better driving experiences while also enabling the users to solve challenging navigation problems. Reaching such capabilities will require significant technological attention and the flawless execution of various complex tasks, one of which is ensuring robust localization and mapping. Herein, a discussion of the contemporary methods of extracting relevant features from equipped sensors and their categorization as semantic, non-semantic, and deep learning methods is presented. Representativeness, low cost, and accessibility are crucial constraints in the choice of the methods to be adopted for localization and mapping tasks.
- autonomous driving
- feature extraction
- mapping
- localization
- automotive security
1. Introduction
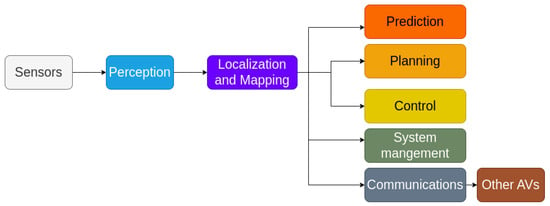
2. Feature Extraction
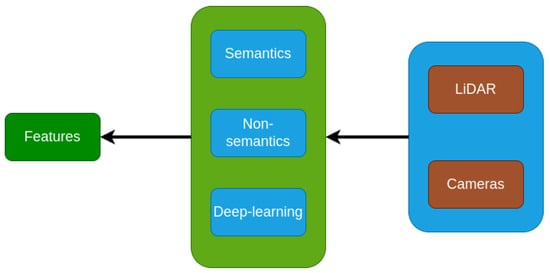
2.1. Semantic Features
2.2. Non-Semantics Features
2.3. Deep Learning Features
-
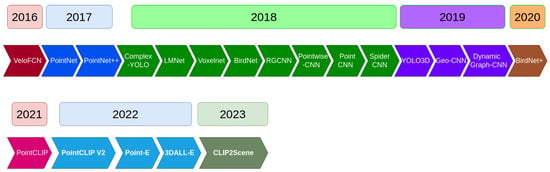
MixedCNN-based Methods: Convolutional Neural Network (CNN) is one of the most common methods used in computer vision. These types of methods use mathematical operations called ’convolution’ to extract relevant features [50]. VeloFCN [51] is a projection-based method and one of the earliest methods that uses CNN for 3D vehicle detection. The authors used a three convolution layer structure to down-sample the input front of the view map, then up-sample with a deconvolution layer. The output of the last procedure is fed into a regression part to create a 3D box for each pixel. Meanwhile, the same results were entered for classification to check if the corresponding pixel was a vehicle or not. Finally, they grouped all candidates’ boxes and filtered them by a Non-Maximum Suppression (NMS) approach. In the same vein, LMNet [52] increased the zone of detection to find road objects by taking into consideration five types of features: reflectance, range, distance, side, height. Moreover, they change the classical convolution by the dilated ones. The Voxelnet [53] method begins with the process of voxelizing the set of points cloud and passing it through the VFE network (explained below) to obtain robust features. After that, a 3D convolutional neural network is applied to group voxels features into a 2D map. Finally, a probability score is calculated using an RPN (Region Proposal Network). The VFE network aims to learn features of points by using a multi-layer-perceptron and a max-pooling architecture to obtain point-wise features. This architecture concatenates features from the MLP output and the MLP + Maxpooling. This process is repeated several times to facilitate the learning. The last iteration is fed to an FCN to extract the final features. BirdNet [54] generates a three-channel bird eye’s view image, which encodes the height, intensity, and density information. After that, a normalization was performed to deal with the inconsistency of the laser beams of the LiDAR devices. BirdNet uses a VGG16 architecture to extract features, and they adopt a Fast-RCNN to perform object detection and orientation. BirdNet+ [55] is an extension of the last work, where they attempted to predict the height and vertical position of the centroid object in addition to the processing of the source (BirdNet) method. This field is also approached by transfer learning, like in Complex-YOLO [56], and YOLO3D [57]. Other CNN-based method include regularized graph CNN (RGCNN) [58], Pointwise-CNN [59], PointCNN [60], Geo-CNN [61], Dynamic Graph-CNN [62] and SpiderCNN [63].
-
Other Methods: These techniques are based on different approaches. Ref. [64] is a machine learning-based method where the authors try to voxelize the set of points cloud into 3D grid cells. They extract features just from the non-empty cells. These features are a vector of six components: mean and variance of the reflectance, three shape factors, and a binary occupancy. The authors proposed an algorithm to compute the classification score, which takes in the input of a trained SVM classification weight and features, then a voting procedure is used to find the scores. Finally, a non-maximum suppression (NMS) is used to remove duplicate detection. Interesting work is done in [65], who tried to present a new architecture of learning that directly extracts local and global features from the set of points cloud. The 3D object detection process is independent of the form of the points cloud. PointNet shows a powerful result in different situations. PointNet++ [66] extended the last work of PointNet, thanks to the Furthest Point Sampling (FPS) method. The authors created a local region by clustering the neighbor point and then applied the PointNet method in each cluster region to extract local features. Ref. [67] introduces a novel approach using LiDAR range images for efficient pole extraction, combining geometric features and deep learning. This method enhances vehicle localization accuracy in urban environments, outperforming existing approaches and reducing processing time. Publicly released datasets support further research and evaluation. The research presents PointCLIP [68], an approach that aligns CLIP-encoded point clouds with 3D text to improve 3D recognition. By projecting point clouds onto multi-view depth maps, knowledge from the 2D domain is transferred to the 3D domain. An inter-view adapter improves feature extraction, resulting in better performance in a few shots after fine-tuning. By combining PointCLIP with supervised 3D networks, it outperforms existing models on datasets such as ModelNet10, ModelNet40 and ScanObjectNNN, demonstrating the potential for efficient 3D point cloud understanding using CLIP. PointCLIP V2 [69] enhances CLIP for 3D point clouds, using realistic shape projection and GPT-3 for prompts. It outperforms PointCLIP [68] by +42.90%, +40.44%, and +28.75% accuracy in zero-shot 3D classification. It extends to few-shot tasks and object detection with strong generalization. Code and prompt details are provided. The paper [70] presents a "System for Generating 3D Point Clouds from Complex Prompts and proposes an accelerated approach to 3D object generation using text-conditional models. While recent methods demand extensive computational resources for generating 3D samples, this approach significantly reduces the time to 1–2 min per sample on a single GPU. By leveraging a two-step diffusion model, it generates synthetic views and then transforms them into 3D point clouds. Although the method sacrifices some sample quality, it offers a practical tradeoff for scenarios, prioritizing speed over sample fidelity. The authors provide their pre-trained models and code for evaluation, enhancing the accessibility of this technique in text-conditional 3D object generation. Researchers have developed 3DALL-E [71], an add-on that integrates DALL-E, GPT-3 and CLIP into the CAD software, enabling users to generate image-text references relevant to their design tasks. In a study with 13 designers, the researchers found that 3DALL-E has potential applications for reference images, renderings, materials and design considerations. The study revealed query patterns and identified cases where text-to-image AI aids design. Bibliographies were also proposed to distinguish human from AI contributions, address ownership and intellectual property issues, and improve design history. These advances in textual referencing can reshape creative workflows and offer users faster ways to explore design ideas through language modeling. The results of the study show that there is great enthusiasm for text-to-image tools in 3D workflows and provide guidelines for the seamless integration of AI-assisted design and existing generative design approaches. The paper [72] introduces SDS Complete, an approach for completing incomplete point-cloud data using text-guided image generation. Developed by Yoni Kasten, Ohad Rahamim, and Gal Chechik, this method leverages text semantics to reconstruct surfaces of objects from incomplete point clouds. SDS Complete outperforms existing approaches on objects not well-represented in training datasets, demonstrating its efficacy in handling incomplete real-world data. Paper [73] presents CLIP2Scene, a framework that transfers knowledge from pre-trained 2D image-text models to a 3D point cloud network. Using a semantics-based multimodal contrastive learning framework, the authors achieve annotation-free 3D semantic segmentation with significant mIoU scores on multiple datasets, even with limited labeled data. The work highlights the benefits of CLIP knowledge for understanding 3D scenes and introduces solutions to the challenges of unsupervised distillation of cross-modal knowledge.
2.4. Discussion
-
Time and energy cost: being easy to detect and easy to use in terms of compilation and execution.
-
Representativeness: detecting features that frequently exist in the environment to ensure the matching process.
-
Accessibility: being easy to distinguish from the environment.
2.5. Challenges and Future Directions
-
Features should be robust against any external effect like weather changes, other moving objects, e.g., trees that move in the wind.
-
Provide the possibility of re-use in other tasks.
-
The detection system should be capable to extract features even with a few objects in the environment.
-
The proposed algorithms to extract features should not hurt the system by requiring long execution time.
-
One issue that should be taken into consideration is about safe and dangerous features. Each feature must provide a degree of safety (expressed as percentage), which helps to determine the nature of the feature and where they belong to, e.g., belonging to the road is safer than being on the walls.
| Paper | Features Type | Concept | Methods | Features-Extracted | Time and Energy Cost | Representativeness | Accessibility | Robustness |
|---|---|---|---|---|---|---|---|---|
| [6][7], [18][23], [24][25]. |
- Semantic | - General | - Radon transform - Douglas & Peukers algorithm - Binarization - Hough transform - Iterative-End- Point-Fit (IEPF) - RANSAC |
- Road lanes - lines - ridges Edges - pedestrian crossings lines |
- Consume a lot | - High | - Hard | - Passable |
| [9][10], [18]. |
- Semantic | - General | - The height of curbs between 10 cm and 15 cm - RANSAC |
- Curves | - Consume a lot | - High | - Hard | - Passable |
| [11][12], [13][14], [15][16], [17][18], [27]. |
- Semantic | - Probabilistic - General |
- Probabilistic Calculation - Voxelisation |
- Building facades - Poles |
- Consume a lot | - Middle | - Hard | - Low |
| [29][30], [31][33], [34][35], [38][39], [40][41], [36][42], [43][44], [45][46], [47]. |
- Non-Semantic | - General | - PCA - DAISY - Gaussian kernel - K-medoids - K-means - DBSCAN - RANSAC - Radius Outlier Removal filter - ORB - BRIEFFAST-9 |
- All the environment | - Consume less | - High | - Easy | - High |
| [48][50], [51][52], [53][54], [55][56], [57][58], [59][60], [61][62], [63][64], [65][66]. |
- Deep-learning | - Probabilistic - Optimization - General |
- CNN - SVM - Non-Maximum Suppression - Region Proposal Network - Multi Layer Perceptron - Maxpooling - Fast-RCNN - Transfer learning |
- All the environment | - Consume a lot | - High | - Easy | - High |
This entry is adapted from the peer-reviewed paper 10.3390/machines12020118
References
- Road Traffic Injuries; World Health Organization: Geneva, Switzerland, 2021; Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 2 July 2021).
- Du, H.; Zhu, G.; Zheng, J. Why travelers trust and accept self-driving cars: An empirical study. Travel Behav. Soc. 2021, 22, 1–9.
- Kopestinsky, A. 25 Astonishing Self-Driving Car Statistics for 2021. PolicyAdvice. 2021. Available online: https://policyadvice.net/insurance/insights/self-driving-car-statistics/ (accessed on 2 July 2021).
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469.
- Jo, K.; Kim, J.; Kim, D.; Jang, C.; Sunwoo, M. Development of autonomous car-part i: Distributed system architecture and development process. IEEE Trans. Ind. Electron. 2014, 61, 7131–7140.
- Kim, D.; Chung, T.; Yi, K. Lane map building and localization for automated driving using 2D laser rangefinder. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Republic of Korea, 28 June–1 July 2015; pp. 680–685.
- Im, J.; Im, S.; Jee, G.-I. Extended Line Map-Based Precise Vehicle Localization Using 3D LiDAR. Sensors 2018, 18, 3179.
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66.
- Zhang, Y.; Wang, J.; Wang, X.; Li, C.; Wang, L. A real-time curb detection and tracking method for UGVs by using a 3D-LiDAR sensor. In Proceedings of the 2015 IEEE Conference on Control Applications (CCA), Sydney, Australia, 21–23 September 2015; pp. 1020–1025.
- Wang, L.; Zhang, Y.; Wang, J. Map-Based Localization Method for Autonomous Vehicles Using 3D-LiDAR. IFAC-PapersOnLine 2017, 50, 276–281.
- Sefati, M.; Daum, M.; Sondermann, B.; Kreisköther, K.D.; Kampker, A. Improving vehicle localization using semantic and pole-like landmarks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 13–19.
- Kummerle, J.; Sons, M.; Poggenhans, F.; Kuhner, T.; Lauer, M.; Stiller, C. Accurate and efficient self-localization on roads using basic geometric primitives. In Proceedings of the 2019 IEEE International Conference on Robotics and Automation (IEEE ICRA 2019), Montreal, QC, Canada, 20–24 May 2019; pp. 5965–5971.
- Zhang, C.; Ang, M.H.; Rus, D. Robust LiDAR Localization for Autonomous Driving in Rain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2018, Madrid, Spain, 1–5 October 2018; pp. 3409–3415.
- Weng, L.; Yang, M.; Guo, L.; Wang, B.; Wang, C. Pole-Based Real-Time Localization for Autonomous Driving in Congested Urban Scenarios. In Proceedings of the 2018 IEEE International Conference on Real-time Computing and Robotics (RCAR), Kandima, Maldives, 1–5 August 2018; pp. 96–101.
- Lu, F.; Chen, G.; Dong, J.; Yuan, X.; Gu, S.; Knoll, A. Pole-based Localization for Autonomous Vehicles in Urban Scenarios Using Local Grid Map-based Method. In Proceedings of the 5th International Conference on Advanced Robotics and Mechatronics, ICARM 2020, Shenzhen, China, 18–21 December 2020; pp. 640–645.
- Schaefer, A.; Büscher, D.; Vertens, J.; Luft, L.; Burgard, W. Long-term vehicle localization in urban environments based on pole landmarks extracted from 3-D LiDAR scans. Rob. Auton. Syst. 2021, 136, 103709.
- Gim, J.; Ahn, C.; Peng, H. Landmark Attribute Analysis for a High-Precision Landmark-based Local Positioning System. IEEE Access 2021, 9, 18061–18071.
- Pang, S.; Kent, D.; Morris, D.; Radha, H. FLAME: Feature-Likelihood Based Mapping and Localization for Autonomous Vehicles. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5312–5319.
- Yuming, H.; Yi, G.; Chengzhong, X.; Hui, K. Why semantics matters: A deep study on semantic particle-filtering localization in a LiDAR semantic pole-map. arXiv 2023, arXiv:2305.14038v1.
- Dong, H.; Chen, X.; Stachniss, C. Online Range Image-based Pole Extractor for Long-term LiDAR Localization in Urban Environments. In Proceedings of the 2021 European Conference on Mobile Robots (ECMR), Bonn, Germany, 31 August–3 September 2021.
- Huang, B.; Zhao, J.; Liu, J. A Survey of Simultaneous Localization and Mapping with an Envision in 6G Wireless Networks. 2019, pp. 1–17. Available online: https://arxiv.org/abs/1909.05214 (accessed on 5 July 2021).
- Piasco, N.; Sidibé, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on Visual-Based Localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109.
- Shipitko, O.; Kibalov, V.; Abramov, M. Linear Features Observation Model for Autonomous Vehicle Localization. In Proceedings of the 16th International Conference on Control, Automation, Robotics and Vision, ICARCV 2020, Shenzhen, China, 13–15 December 2020; pp. 1360–1365.
- Shipitko, O.; Grigoryev, A. Ground vehicle localization with particle filter based on simulated road marking image. In Proceedings of the 32nd European Conference on Modelling and Simulation, Wilhelmshaven, Germany, 22–26 May 2018; pp. 341–347.
- Shipitko, O.S.; Abramov, M.P.; Lukoyanov, A.S. Edge Detection Based Mobile Robot Indoor Localization. International Conference on Machine Vision. 2018. Available online: https://www.semanticscholar.org/paper/Edge-detection-based-mobile-robot-indoor-Shipitko-Abramov/51fd6f49579568417dd2a56e4c0348cb1bb91e78 (accessed on 17 July 2021).
- Wu, F.; Wei, H.; Wang, X. Correction of image radial distortion based on division model. Opt. Eng. 2017, 56, 013108.
- Weng, L.; Gouet-Brunet, V.; Soheilian, B. Semantic signatures for large-scale visual localization. Multimed. Tools Appl. 2021, 80, 22347–22372.
- Hekimoglu, A.; Schmidt, M.; Marcos-Ramiro, A. Monocular 3D Object Detection with LiDAR Guided Semi Supervised Active Learning. 2023. Available online: http://arxiv.org/abs/2307.08415v1 (accessed on 25 January 2024).
- Hungar, C.; Brakemeier, S.; Jürgens, S.; Köster, F. GRAIL: A Gradients-of-Intensities-based Local Descriptor for Map-based Localization Using LiDAR Sensors. In Proceedings of the IEEE Intelligent Transportation Systems Conference, ITSC 2019, Auckland, New Zealand, 27–30 October 2019; pp. 4398–4403.
- Hungar, C.; Fricke, J.; Stefan, J.; Frank, K. Detection of Feature Areas for Map-based Localization Using LiDAR Descriptors. In Proceedings of the 16th Workshop on Posit. Navigat. and Communicat, Bremen, Germany, 23–24 October 2019.
- Gu, B.; Liu, J.; Xiong, H.; Li, T.; Pan, Y. Ecpc-icp: A 6d vehicle pose estimation method by fusing the roadside LiDAR point cloud and road feature. Sensors 2021, 21, 3489.
- Burt, A.; Disney, M.; Calders, K. Extracting individual trees from LiDAR point clouds using treeseg. Methods Ecol. Evol. 2019, 10, 438–445.
- Charroud, A.; Yahyaouy, A.; Moutaouakil, K.E.; Onyekpe, U. Localisation and mapping of self-driving vehicles based on fuzzy K-means clustering: A non-semantic approach. In Proceedings of the 2022 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 8–19 May 2022.
- Charroud, A.; Moutaouakil, K.E.; Yahyaouy, A.; Onyekpe, U.; Palade, V.; Huda, M.N. Rapid localization and mapping method based on adaptive particle filters. Sensors 2022, 22, 9439.
- Charroud, A.; Moutaouakil, K.E.; Yahyaouy, A. Fast and accurate localization and mapping method for self-driving vehicles based on a modified clustering particle filter. Multimed. Tools Appl. 2023, 82, 18435–18457.
- Zou, Y.; Wang, X.; Zhang, T.; Liang, B.; Song, J.; Liu, H. BRoPH: An efficient and compact binary descriptor for 3D point clouds. Pattern Recognit. 2018, 76, 522–536.
- Kiforenko, L.; Drost, B.; Tombari, F.; Krüger, N.; Buch, A.G. A performance evaluation of point pair features. Comput. Vis. Image Underst. 2016, 166, 66–80.
- Logoglu, K.B.; Kalkan, S.; Temize, A.l. CoSPAIR: Colored Histograms of Spatial Concentric Surflet-Pairs for 3D object recognition. Rob. Auton. Syst. 2016, 75, 558–570.
- Buch, A.G.; Kraft, D. Local point pair feature histogram for accurate 3D matching. In Proceedings of the 29th British Machine Vision Conference, BMVC 2018, Newcastle, UK, 3–6 September 2018; Available online: https://www.reconcell.eu/files/publications/Buch2018.pdf (accessed on 20 July 2021).
- Zhao, H.; Tang, M.; Ding, H. HoPPF: A novel local surface descriptor for 3D object recognition. Pattern Recognit. 2020, 103, 107272.
- Wu, L.; Zhong, K.; Li, Z.; Zhou, M.; Hu, H.; Wang, C.; Shi, Y. Pptfh: Robust local descriptor based on point-pair transformation features for 3d surface matching. Sensors 2021, 21, 3229.
- Yang, J.; Zhang, Q.; Xiao, Y.; Cao, Z. TOLDI: An effective and robust approach for 3D local shape description. Pattern Recognit. 2017, 65, 175–187.
- Prakhya, S.M.; Lin, J.; Chandrasekhar, V.; Lin, W.; Liu, B. 3DHoPD: A Fast Low-Dimensional 3-D Descriptor. IEEE Robot. Autom. Lett. 2017, 2, 1472–1479.
- Hu, Z.; Qianwen, T.; Zhang, F. Improved intelligent vehicle self-localization with integration of sparse visual map and high-speed pavement visual odometry. Proc. Inst. Mech. Eng. Part J. Automob. Eng. 2021, 235, 177–187.
- Li, Y.; Hu, Z.; Cai, Y.; Wu, H.; Li, Z.; Sotelo, M.A. Visual Map-Based Localization for Intelligent Vehicles from Multi-View Site Matching. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1068–1079.
- Ge, G.; Zhang, Y.; Jiang, Q.; Wang, W. Visual features assisted robot localization in symmetrical environment using laser slam. Sensors 2021, 21, 1772.
- DBow3. Source Code. 2017. Available online: https://github.com/rmsalinas/DBow3 (accessed on 26 July 2021).
- Holliday, A.; Dudek, G. Scale-invariant localization using quasi-semantic object landmarks. Auton. Robots 2021, 45, 407–420.
- Wu, Y.; Wang, Y.; Zhang, S.; Ogai, H. Deep 3D Object Detection Networks Using LiDAR Data: A Review. IEEE Sens. J. 2021, 21, 1152–1171.
- Wikipedia. Convolutional Neural Network. Available online: https://en.wikipedia.org/wiki/Convolutional_neural_network (accessed on 28 July 2021).
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3D LiDAR using fully convolutional network. Robot. Sci. Syst. 2016, 12.
- Minemura, K.; Liau, H.; Monrroy, A.; Kato, S. LMNet: Real-time multiclass object detection on CPU using 3D LiDAR. In Proceedings of the 2018 3rd Asia-Pacific Conference on Intelligent Robot Systems (ACIRS 2018), Singapore, 21–23 July 2018; pp. 28–34.
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499.
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; García, F.; Escalera, A.D.L. BirdNet: A 3D Object Detection Framework from LiDAR Information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523.
- Barrera, A.; Guindel, C.; Beltrán, J.; García, F. BirdNet+: End-to-End 3D Object Detection in LiDAR Bird’s Eye View. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Virtual, 20–23 September 2020.
- Simon, M.; Milz, S.; Amende, K.; Gross, H.-M. Complex-YOLO: Real-time 3D Object Detection on Point Clouds. arXiv 2018, arXiv:1803.06199. Available online: https://arxiv.org/abs/1803.06199 (accessed on 27 July 2021).
- Ali, W.; Abdelkarim, S.; Zidan, M.; Zahran, M.; Sallab, A.E. YOLO3D: End-to-end real-time 3D oriented object bounding box detection from LiDAR point cloud. Lect. Notes Comput. Sci. 2019, 11131 LNCS, 716–728.
- Te, G.; Zheng, A.; Hu, W.; Guo, Z. RGCNN: Regularized graph Cnn for point cloud segmentation. In Proceedings of the MM ’18 —26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 746–754.
- Hua, B.S.; Tran, M.K.; Yeung, S.K. Pointwise Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 984–993.
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on X-transformed points. Adv. Neural Inf. Process. Syst. 2018, 2018, 820–830.
- Lan, S.; Yu, R.; Yu, G.; Davis, L.S. Modeling local geometric structure of 3D point clouds using geo-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 998–1008.
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph Cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12.
- Xu, Y.; Fan, T.; Xu, M.; Zeng, L.; Qiao, Y. SpiderCNN: Deep learning on point sets with parameterized convolutional filters. Lect. Notes Comput. Sci. 2018, 11212 LNCS, 90–105.
- Wang, D.Z.; Posner, I. Voting for voting in online point cloud object detection. In Robotics: Science and Systems; Sapienza University of Rome: Rome, Italy, 2015; Volume 11.
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the—30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85.
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 2017, 5100–5109.
- Hao, D.; Xieyuanli, C.; Simo, S.; Cyrill, S. Online Pole Segmentation on Range Images for Long-term LiDAR Localization in Urban Environments. arXiv 2022, arXiv:2208.07364v1.
- Zhang, R.; Guo, Z.; Zhang, W.; Li, K.; Miao, X.; Cui, B.; Qiao, Y.; Gao, P.; Li, H. PointCLIP: Point Cloud Understanding by CLIP. . 2021. Available online: http://arxiv.org/abs/2112.02413v1 (accessed on 28 July 2021).
- Zhu, X.; Zhang, R.; He, B.; Zeng, Z.; Zhang, S.; Gao, P. PointCLIP V2: Adapting CLIP for Powerful 3D Open-world Learning. arXiv 2022, arXiv:2211.11682v1.
- Nichol, A.; Jun, H.; Dhariwal, P.; Mishkin, P.; Chen, M. Point-E: A System for Generating 3D Point Clouds from Complex Prompts. arXiv 2022, arXiv:2212.08751v1.
- Liu, V.; Vermeulen, J.; Fitzmaurice, G.; Matejka, J. 3DALL-E: Integrating Text-to-Image AI in 3D Design Workflows. In Proceedings of the Woodstock ’18: ACM Symposium on Neural Gaze Detection, Woodstock, NY, USA, 3–5 June 2018; ACM: New York, NY, USA, 2018; p. 20.
- Kasten, Y.; Rahamim, O.; Chechik, G. Point-Cloud Completion with Pretrained Text-to-image Diffusion Models. arXiv 2023, arXiv:2306.10533v1.
- Chen, R.; Liu, Y.; Kong, L.; Zhu, X.; Ma, Y.; Li, Y.; Hou, Y.; Qiao, Y.; Wang, W. CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP. arXiv 2023, arXiv:2301.04926v2.