The interconnectivity of advanced biological systems is essential for their proper functioning. In modern connectomics, biological entities such as proteins, genes, RNA, DNA, and metabolites are often represented as nodes, while the physical, biochemical, or functional interactions between them are represented as edges. Among these entities, metabolites are particularly significant as they exhibit a closer relationship to an organism’s phenotype compared to genes or proteins. Moreover, the metabolome has the ability to amplify small proteomic and transcriptomic changes, even those from minor genomic changes. Metabolic networks, which consist of complex systems comprising hundreds of metabolites and their interactions, play a critical role in biological research by mediating energy conversion and chemical reactions within cells.
- metabolic connectome
- network models
- disease diagnosis
- drug discovery
1. Introduction
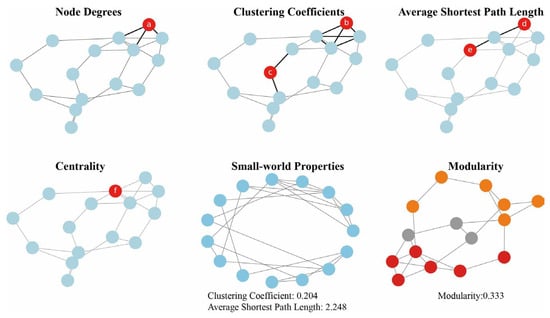
2. Construction Methods of Metabolic Networks
| Metabolic Network | Method/Model | Language | Source |
|---|---|---|---|
| Correlation-based | Pearson correlation And Spearman rank correlation | Python | https://github.com/aishapectyo/Correlations-Pearson-Spearman (accessed on 28 November 2023) |
| Distance correlation [20] | Python | https://github.com/vnmabus/dcor (accessed on 28 November 2023) | |
| Gaussian graphical model | R | https://github.com/donaldRwilliams/BGGM (accessed on 28 November 2023) | |
| Causal-based | Causal inference model [21] | Python | https://github.com/BiomedSciAI/causallib (accessed on 28 November 2023) |
| Structural equation model | R | https://github.com/yrosseel/lavaan (accessed on 28 November 2023) | |
| Dynamic causal model | Python | https://github.com/tmdemelo/pydcm (accessed on 28 November 2023) | |
| Pathway-based | Pathway | Python | https://github.com/iseekwonderful/PyPathway (accessed on 28 November 2023) |
| Chemical structure similarity-based | Chemical structure similarity | Python | https://github.com/labsyspharm/lsp-cheminformatics (accessed on 28 November 2023) |
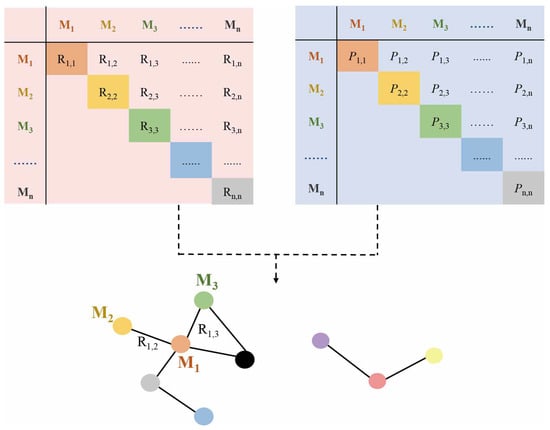
2.1. Correlation-Based Metabolic Network
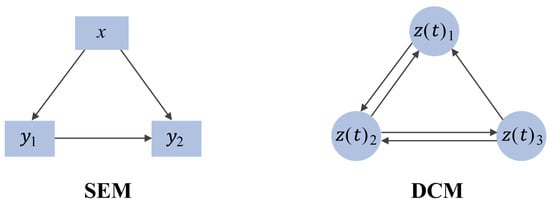
2.2. Causal-Based Metabolic Network
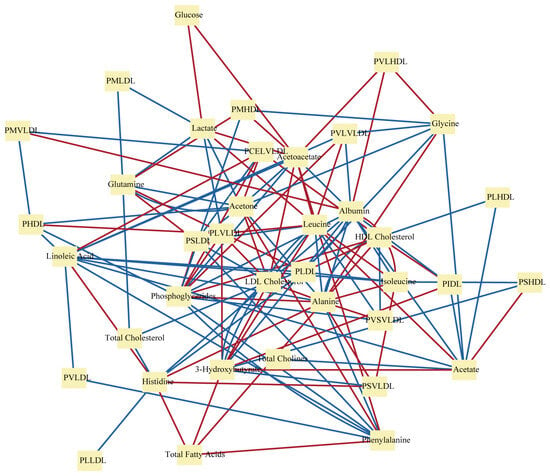
2.3. Pathway-Based Metabolic Network
2.4. Metabolic Network Based on Chemical Structure Similarity
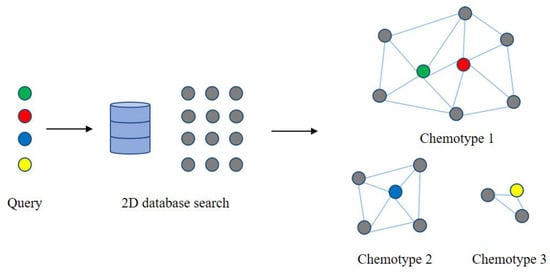
3. Application of Metabolic Network
3.1. Metabolic Networks in Disease Mechanisms
3.2. Metabolic Networks in Disease Prediction and Diagnosis
3.3. Drug Discovery and Disease Treatment
4. Conclusions
This entry is adapted from the peer-reviewed paper 10.3390/metabo14020093